













Introdução
Neste tutorial, você construirá uma aplicação em Python capaz de extrair áudio de um vídeo de entrada, transcrever o áudio extraído, gerar um arquivo de legenda com base na transcrição e, em seguida, adicionar a legenda a uma cópia do vídeo de entrada.
Para construir esta aplicação, você usará o FFmpeg para extrair o áudio de um vídeo de entrada. Você usará o Whisper da OpenAI para gerar uma transcrição para o áudio extraído e então usar essa transcrição para gerar um arquivo de legenda. Além disso, você usará o FFmpeg para adicionar o arquivo de legenda gerado a uma cópia do vídeo de entrada.
O FFmpeg é uma suíte de software poderosa e de código aberto para lidar com dados multimídia, incluindo tarefas de processamento de áudio e vídeo. Ele fornece uma ferramenta de linha de comando que permite aos usuários converter, editar e manipular arquivos multimídia com uma ampla variedade de formatos e codecs.
O Whisper da OpenAI é um sistema de reconhecimento automático de fala (ASR) projetado para converter linguagem falada em texto escrito. Treinado em uma vasta quantidade de dados supervisionados multilíngues e multitarefas, ele se destaca na transcrição de conteúdo de áudio diversificado com alta precisão.
Ao final deste tutorial, você terá uma aplicação capaz de adicionar legendas a um vídeo:
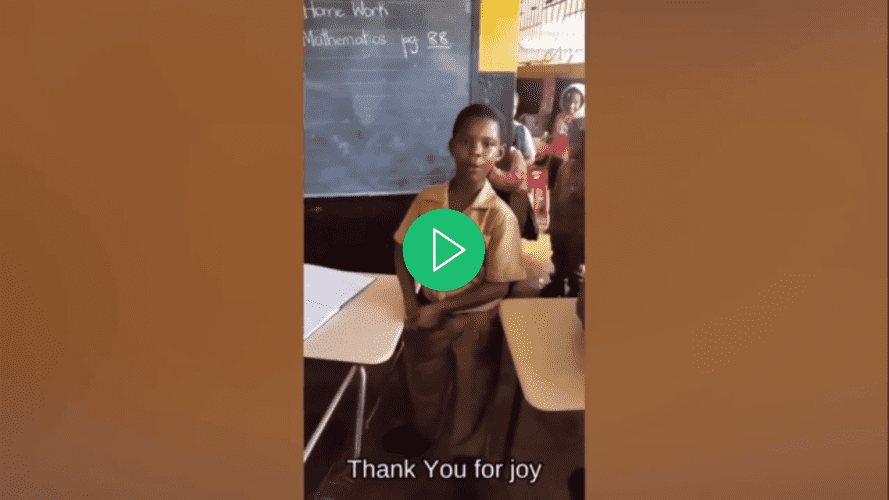
Pré-requisitos
Para seguir este tutorial, o leitor precisará das seguintes ferramentas:
-
FFmpeg instalado.
-
Compreensão básica de Python. Você pode seguir esta série de tutoriais para aprender a programar em Python.
Passo 1 — Criando o Diretório Raiz do Projeto
Nesta seção, você criará o diretório do projeto, baixará o vídeo de entrada, criará e ativará um ambiente virtual e instalará os pacotes Python necessários.
Abra uma janela de terminal e navegue até uma localização adequada para o seu projeto. Execute o seguinte comando para criar o diretório do projeto:
Navegue até o diretório do projeto:
Baixe este vídeo editado e armazene-o no diretório raiz do seu projeto como input.mp4. O vídeo mostra uma criança chamada Rushawn cantando “Beautiful Day” de Jermaine Edward. O vídeo editado que você vai usar neste tutorial foi retirado do seguinte vídeo do YouTube:
Crie um novo ambiente virtual e nomeie-o como env:
Ative o ambiente virtual:
Agora, use o seguinte comando para instalar os pacotes necessários para construir esta aplicação:
Com o comando acima, você instalou as seguintes bibliotecas:
-
faster-whisper: é uma versão redesenhada do modelo Whisper da OpenAI que aproveita o CTranslate2, um motor de inferência de alto desempenho para modelos de Transformer. Esta implementação alcança até quatro vezes mais velocidade do que openai/whisper com precisão comparável, tudo isso consumindo menos memória. -
ffmpeg-python: é uma biblioteca Python que fornece uma cobertura em torno da ferramenta FFmpeg, permitindo aos usuários interagir com as funcionalidades do FFmpeg em scripts Python facilmente. Através de uma interface Pythonica, permite tarefas de processamento de vídeo e áudio, como edição, conversão e manipulação.
Execute o seguinte comando para salvar pacotes que foram instalados usando pip no ambiente virtual em um arquivo chamado requirements.txt:
O arquivo requirements.txt deve se parecer com o seguinte:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
Nesta seção, você criou o diretório do projeto, baixou o vídeo de entrada que será usado neste tutorial, configurou um ambiente virtual, ativou-o e instalou os pacotes Python necessários. Na próxima seção, você irá gerar uma transcrição para o vídeo de entrada.
Passo 2 — Gerando a transcrição do vídeo
Nesta seção, você criará o script Python onde a aplicação irá residir. Dentro deste script, você utilizará a biblioteca ffmpeg-python para extrair a faixa de áudio do vídeo de entrada baixado na seção anterior e salvá-la como um arquivo WAV. Em seguida, você usará a biblioteca faster-whisper para gerar uma transcrição para o áudio extraído.
No diretório raiz do seu projeto, crie um arquivo chamado main.py e adicione o seguinte código a ele:
Aqui, o código começa importando várias bibliotecas e módulos, incluindo time, math, ffmpeg de ffmpeg-python, e um módulo personalizado chamado WhisperModel de faster_whisper. Essas bibliotecas serão usadas para o processamento de vídeo e áudio, transcrição e geração de legendas.
Em seguida, o código define o nome do arquivo de vídeo de entrada, armazena-o em uma constante chamada input_video, e depois armazena o nome do arquivo de vídeo sem a extensão .mp4 em uma constante chamada input_video_name. Definir o nome do arquivo de entrada aqui permitirá que você trabalhe com vários vídeos de entrada sem sobrescrever os arquivos de legenda e de vídeo de saída gerados para eles.
Adicione o seguinte código ao final do seu arquivo main.py:
O código acima define uma função chamada extract_audio() que é responsável por extrair o áudio do vídeo de entrada.
Primeiro, define o nome do áudio que será extraído como um nome formado acrescentando audio- ao nome base do vídeo de entrada com uma extensão .wav, e armazena este nome em uma constante chamada extracted_audio.
Em seguida, o código chama o método ffmpeg.input() da biblioteca ffmpeg para abrir o vídeo de entrada e cria um objeto de fluxo de entrada chamado stream.
O código então chama o método ffmpeg.output() para criar um objeto de fluxo de saída com o fluxo de entrada e o nome do arquivo de áudio extraído definido.
Após definir o fluxo de saída, o código chama o método ffmpeg.run(), passando o fluxo de saída como parâmetro para iniciar o processo de extração de áudio e salvar o arquivo de áudio extraído no diretório raiz do seu projeto. Adicionalmente, um parâmetro booleano, overwrite_output=True, é incluído para substituir qualquer arquivo de saída pré-existente pelo recém-gerado caso tal arquivo já exista.
Por fim, o código retorna o nome do arquivo de áudio extraído.
Adicione o seguinte código abaixo da função extract_audio():
Aqui, o código define uma função chamada run() e então a chama. Esta função chama todas as funções necessárias para gerar e adicionar legendas a um vídeo.
No interior da função, o código chama a função extract_audio() para extrair áudio de um vídeo e então armazena o nome do arquivo de áudio retornado em uma variável chamada extracted_audio.
Volte ao seu terminal e execute o seguinte comando para rodar o script main.py:
Após executar o comando acima, a saída do FFmpeg será exibida no terminal e um arquivo chamado audio-input.wav, contendo o áudio extraído do vídeo de entrada, será armazenado no diretório raiz do seu projeto.
Volte para o seu arquivo main.py e adicione o seguinte código entre as funções extract_audio() e run():
O código acima define uma função chamada transcrever, responsável por transcrever o arquivo de áudio extraído do vídeo de entrada.
Primeiramente, o código cria uma instância do objeto WhisperModel e define o tipo de modelo como small. O Whisper da OpenAI possui os seguintes tipos de modelo: tiny, base, small, medium e large. O modelo tiny é o menor e mais rápido, enquanto o modelo large é o maior, mais lento, mas mais preciso.
Em seguida, o código chama o método model.transcribe() com o áudio extraído como argumento para recuperar a função de segmentos e as informações do áudio, armazenando-as nas variáveis info e segments, respectivamente. A função de segmentos é um gerador Python, então a transcrição só começará quando o código iterar sobre ela. A transcrição pode ser concluída coletando os segmentos em uma list ou em um loop for.
Posteriormente, o código armazena o idioma detectado no áudio em uma constante chamada info e o imprime no console.
Depois de imprimir o idioma detectado, o código reúne os segmentos de transcrição em uma lista para executar a transcrição e armazena os segmentos reunidos em uma variável também chamada de `segments`. O código então faz um loop sobre a lista de segmentos de transcrição e imprime o tempo de início, tempo de término e texto de cada segmento no console.
Finalmente, o código retorna o idioma detectado no áudio e os segmentos de transcrição.
Adicione o seguinte código dentro da função `run()`:
O código adicionado chama a função `transcribe` com o áudio extraído como argumento e armazena os valores retornados em constantes nomeadas `language` e `segments`.
Volte ao seu terminal e execute o seguinte comando para executar o script `main.py`:
A primeira vez que você executar este script, o código irá primeiro baixar e armazenar em cache o modelo Whisper Small. As execuções subsequentes serão muito mais rápidas.
Após executar o comando acima, você deverá ver a seguinte saída no console:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
A saída acima mostra que o idioma detectado no áudio é inglês (`en`). Além disso, mostra o tempo de início e término de cada segmento de transcrição em segundos e o texto.
Aviso: Embora o reconhecimento de fala Whisper da OpenAI seja muito preciso, não é 100% preciso. Pode estar sujeito a limitações e erros ocasionais, especialmente em cenários linguísticos ou de áudio desafiadores. Portanto, sempre verifique a transcrição manualmente.
Nesta seção, você criou um script Python para a aplicação. Dentro do script, ffmpeg-python foi utilizado para extrair o áudio do vídeo baixado e salvá-lo como um arquivo WAV. Em seguida, a biblioteca faster-whisper foi utilizada para gerar uma transcrição para o áudio extraído. Na próxima seção, você irá gerar um arquivo de legenda com base na transcrição e então adicionará a legenda ao vídeo.
Passo 3 — Gerando e adicionando a legenda ao vídeo
Nesta seção, primeiro, você entenderá o que é um arquivo de legenda e como ele é estruturado. Em seguida, você usará os segmentos de transcrição gerados na seção anterior para criar um arquivo de legenda. Após criar o arquivo de legenda, você utilizará a biblioteca ffmpeg-python para adicionar o arquivo de legenda a uma cópia do vídeo de entrada.
Entendendo Legendas: Estrutura e Tipos
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Índice da legenda: Um número sequencial que indica a ordem da legenda no arquivo.
-
Temporizações: Marcadores de início e fim que especificam quando o texto da legenda deve ser exibido. As temporizações geralmente são formatadas como
HH:MM:SS,sss(horas, minutos, segundos, milissegundos). -
Texto da Legenda: O texto real da entrada da legenda, representando conteúdo falado ou escrito. Este texto é exibido na tela durante o intervalo de tempo especificado.
Por exemplo, uma entrada de legenda em um arquivo SRT pode ser assim:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
Neste exemplo, o índice é 1, as temporizações indicam que a legenda deve ser exibida de 10.5 segundos a 15 segundos, e o texto da legenda é Este é um exemplo de legenda.
As legendas podem ser divididas em dois tipos principais:
-
Legendas suaves: Também conhecidas como legendas ocultas, são armazenadas externamente como arquivos separados (como SRT) e podem ser adicionadas ou removidas independentemente do vídeo. Elas proporcionam flexibilidade ao espectador, permitindo alternância, troca de idioma e personalização de configurações. No entanto, sua eficácia depende do suporte do player de vídeo, e nem todos os players acomodam universalmente legendas suaves.
-
Legendas fixas: São permanentemente incorporadas nos quadros de vídeo durante a edição ou codificação, permanecendo uma parte fixa do vídeo. Embora garantam visibilidade constante, mesmo em players que não suportam arquivos de legendas externos, as modificações ou desativação exigem a recodificação do vídeo inteiro, limitando o controle do usuário
Criando o arquivo de legenda
Volte para o seu arquivo main.py e adicione o seguinte código entre as funções transcribe() e run():
Aqui, o código define uma função chamada format_time(), que é responsável por converter o tempo de início e fim de um segmento de transcrição fornecido em segundos para um formato de tempo compatível com legendas, exibindo horas, minutos, segundos e milissegundos (HH:MM:SS,sss).
O código primeiro calcula horas, minutos, segundos e milissegundos a partir do tempo fornecido em segundos, formata-os adequadamente e, em seguida, retorna o tempo formatado.
Adicione o seguinte código entre as funções format_time() e run():
O código adicionado define uma função chamada generate_subtitle_file(), que recebe como parâmetros o idioma detectado no áudio extraído e os segmentos de transcrição. Esta função é responsável por gerar um arquivo de legenda SRT com base no idioma e nos segmentos de transcrição.
Primeiro, o código define o nome do arquivo de legenda para um nome formado pela concatenação de sub- e o idioma detectado ao nome base do vídeo de entrada com a extensão “.srt” e armazena esse nome em uma constante chamada subtitle_file. Além disso, o código define uma variável chamada text, onde você armazenará as entradas de legenda.
Em seguida, o código itera pelos segmentos transcritos, formata os tempos de início e fim usando a função format_time(), usa esses valores formatados juntamente com o índice do segmento e o texto para criar uma entrada de legenda e adiciona uma linha em branco para separar cada entrada de legenda.
Finalmente, o código cria um arquivo de legenda no diretório raiz do seu projeto com o nome definido anteriormente, adiciona as entradas de legenda ao arquivo e retorna o nome do arquivo de legenda.
Adicione o seguinte código ao final da sua função run():
O código adicionado chama a função generate_subtitle_file() com o idioma detectado e os segmentos de transcrição como argumentos, e armazena o nome do arquivo de legenda retornado em uma constante chamada subtitle_file.
Volte ao seu terminal e execute o seguinte comando para executar o script main.py:
Após executar o comando acima, um arquivo de legenda com o nome sub-input.en.srt será salvo no diretório raiz do seu projeto.
Abra o arquivo de legenda sub-input.en.srt e você deverá ver algo semelhante ao seguinte:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Adicionando legendas a vídeos
Adicione o seguinte código entre as funções generate_subtitle_file() e run():
Aqui, o código define uma função chamada add_subtitle_to_video(), que recebe como parâmetros um valor booleano usado para determinar se deve adicionar uma legenda suave ou dura, o nome do arquivo de legenda e o idioma detectado na transcrição. Esta função é responsável por adicionar legendas suaves ou duras a uma cópia do vídeo de entrada.
Primeiro, o código utiliza o método ffmpeg.input() com o vídeo de entrada e o arquivo de legenda para criar objetos de fluxo de entrada para o vídeo de entrada e o arquivo de legenda e os armazena em constantes nomeadas video_input_stream e subtitle_input_stream respectivamente.
Após a criação dos fluxos de entrada, o código define o nome do arquivo de vídeo de saída como um nome formado anexando output- ao nome base do vídeo de entrada com a extensão “.mp4”, e armazena este nome em uma constante chamada output_video. Além disso, define o nome da faixa de legenda como o nome do arquivo de legenda sem a extensão .srt e armazena este nome em uma constante chamada subtitle_track_title.
Em seguida, o código verifica se o booleano soft_subtitle está definido como True, indicando que deve adicionar uma legenda suave.
Se esse for o caso, o código chama o método ffmpeg.output() para criar um objeto de fluxo de saída com os fluxos de entrada, o nome do arquivo de vídeo de saída e as seguintes opções para o vídeo de saída:
-
"c": "copy": Especifica que o codec de vídeo e outros parâmetros de vídeo devem ser copiados diretamente da entrada para a saída sem re-codificação. -
"c:s": "mov_text": Especifica que o codec de legenda e os parâmetros também devem ser copiados da entrada para a saída sem re-encode.mov_texté um codec de legenda comum usado em arquivos MP4/MOV. -
”metadata:s:s:0”: f"language={subtitle_language}": Define os metadados de idioma para o fluxo de legenda. O idioma é definido com o valor armazenado emsubtitle_language -
"metadata:s:s:0": f"title={subtitle_track_title}": Define os metadados de título para o fluxo de legenda. O título é definido com o valor armazenado emsubtitle_track_title
Por fim, o código chama o método ffmpeg.run(), passando o fluxo de saída como parâmetro para adicionar a legenda suave ao vídeo e salvar o arquivo de vídeo de saída no diretório raiz do seu projeto.
Adicione o seguinte código ao final da sua função add_subtitle_to_video():
O código destacado será executado se a booleana soft_subtitle estiver definida como False, indicando que deverá adicionar uma legenda fixa.
Se for o caso, primeiro, o código chama o método ffmpeg.output() para criar um objeto de fluxo de saída com o fluxo de vídeo de entrada, o nome do arquivo de vídeo de saída e o parâmetro vf=f"subtitles={subtitle_file}". O vf significa “filtro de vídeo” e é usado para aplicar um filtro ao fluxo de vídeo. Neste caso, o filtro aplicado é a adição da legenda.
Por fim, o código chama o método ffmpeg.run(), passando o fluxo de saída como parâmetro para adicionar a legenda fixa ao vídeo e salvar o arquivo de vídeo de saída no diretório raiz do seu projeto.
Adicione o código destacado à função run():
O código destacado chama o add_subtitle_to_video() com o parâmetro soft_subtitle definido como True, o nome do arquivo de legenda e o idioma da legenda para adicionar uma legenda suave a uma cópia do vídeo de entrada.
Volte ao terminal e execute o seguinte comando para executar o script main.py:
Após executar o comando acima, um arquivo de vídeo de saída chamado output-input.mp4 será salvo no diretório raiz do seu projeto.
Abra o vídeo usando o seu reprodutor de vídeo preferido, selecione uma legenda para o vídeo e observe como a legenda só será exibida quando você a selecionar:
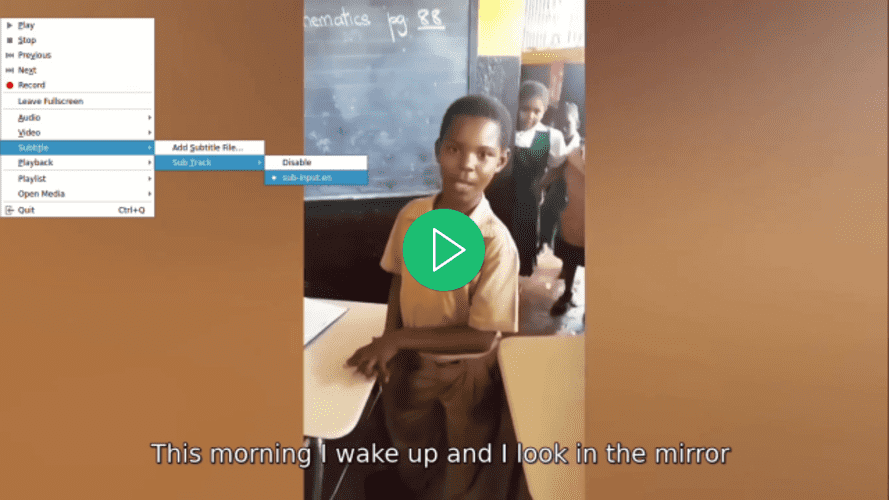
Volte para o arquivo main.py, navegue até a função run(), e na chamada da função add_subtitle_to_video(), defina o parâmetro soft_subtitle como False:
Aqui, você define o parâmetro soft_subtitle como False para adicionar legendas rígidas ao vídeo.
Volte ao seu terminal e execute o seguinte comando para executar o script main.py:
Após executar o comando acima, o arquivo de vídeo output-input.mp4 localizado no diretório raiz do seu projeto será sobrescrito.
Abra o vídeo usando seu reprodutor de vídeo preferido, tente selecionar uma legenda para o vídeo e observe como uma não está disponível, mas uma legenda está sendo exibida:

Nesta seção, você obteve uma compreensão da estrutura de um arquivo de legenda SRT e utilizou os segmentos de transcrição da seção anterior para criar um. Em seguida, a biblioteca ffmpeg-python foi usada para adicionar o arquivo de legenda gerado ao vídeo.
Conclusão
Neste tutorial, você utilizou as bibliotecas Python ffmpeg-python e faster-whisper para construir uma aplicação capaz de extrair áudio de um vídeo de entrada, transcrever o áudio extraído, gerar um arquivo de legenda com base na transcrição e adicionar a legenda a uma cópia do vídeo de entrada.