













Nos primórdios da computação, as aplicações lidavam com tarefas de forma sequencial. À medida que a escala cresceu com milhões de usuários, essa abordagem tornou-se impraticável. O processamento assíncrono permitiu lidar com várias tarefas simultaneamente, mas gerenciar threads/processos em uma única máquina levou a limitações de recursos e complexidade.
É aqui que entra o processamento paralelo distribuído. Ao espalhar a carga de trabalho por várias máquinas, cada uma dedicada a uma parte da tarefa, oferece uma solução escalável e eficiente. Se você tem uma função para processar um grande lote de arquivos, pode dividir a carga de trabalho entre várias máquinas para processar arquivos simultaneamente, em vez de lidar com eles sequencialmente em uma única máquina. Além disso, melhora o desempenho ao aproveitar os recursos combinados e fornece escalabilidade e tolerância a falhas. À medida que as demandas aumentam, você pode adicionar mais máquinas para aumentar os recursos disponíveis.
É desafiador construir e executar aplicações distribuídas em grande escala, mas existem várias estruturas e ferramentas para ajudar. Neste post do blog, vamos examinar uma dessas estruturas de computação distribuída de código aberto: Ray. Também veremos o KubeRay, um operador Kubernetes que permite a integração perfeita do Ray com clusters Kubernetes para computação distribuída em ambientes nativos da nuvem. Mas primeiro, vamos entender onde o paralelismo distribuído ajuda.
Onde o Processamento Paralelo Distribuído Ajuda?
Qualquer tarefa que se beneficie de dividir sua carga de trabalho entre várias máquinas pode utilizar processamento paralelo distribuído. Essa abordagem é particularmente útil para cenários como rastreamento da web, análise de dados em larga escala, treinamento de modelos de aprendizado de máquina, processamento de fluxo em tempo real, análise de dados genômicos e renderização de vídeo. Ao distribuir tarefas entre múltiplos nós, o processamento paralelo distribuído melhora significativamente o desempenho, reduz o tempo de processamento e otimiza a utilização de recursos, tornando-se essencial para aplicações que requerem alta taxa de transferência e manipulação rápida de dados.
Quando o Processamento Paralelo Distribuído Não é Necessário
- Aplicações em pequena escala: Para conjuntos de dados pequenos ou aplicações com requisitos de processamento mínimos, o custo de gerenciar um sistema distribuído pode não ser justificado.
- Fortes dependências de dados: Se as tarefas são altamente interdependentes e não podem ser facilmente paralelizadas, o processamento distribuído pode oferecer pouco benefício.
- Restrições de tempo real: Algumas aplicações em tempo real (por exemplo, finanças e sites de reserva de ingressos) requerem latência extremamente baixa, que pode não ser alcançada com a complexidade adicional de um sistema distribuído.
- Recursos limitados: Se a infraestrutura disponível não pode suportar o custo de um sistema distribuído (por exemplo, largura de banda de rede insuficiente, número limitado de nós), pode ser melhor otimizar o desempenho de uma única máquina.
Como o Ray Ajuda Com o Processamento Paralelo Distribuído
Ray é um framework de processamento paralelo distribuído que encapsula todos os benefícios da computação distribuída e soluções para os desafios que discutimos, como tolerância a falhas, escalabilidade, gerenciamento de contexto, comunicação, e assim por diante. É um framework Pythonico, permitindo o uso de bibliotecas e sistemas existentes para trabalhar com ele. Com a ajuda do Ray, um programador não precisa lidar com as peças da camada de processamento paralelo. O Ray cuidará do agendamento e escalonamento automático com base nos requisitos de recursos especificados.
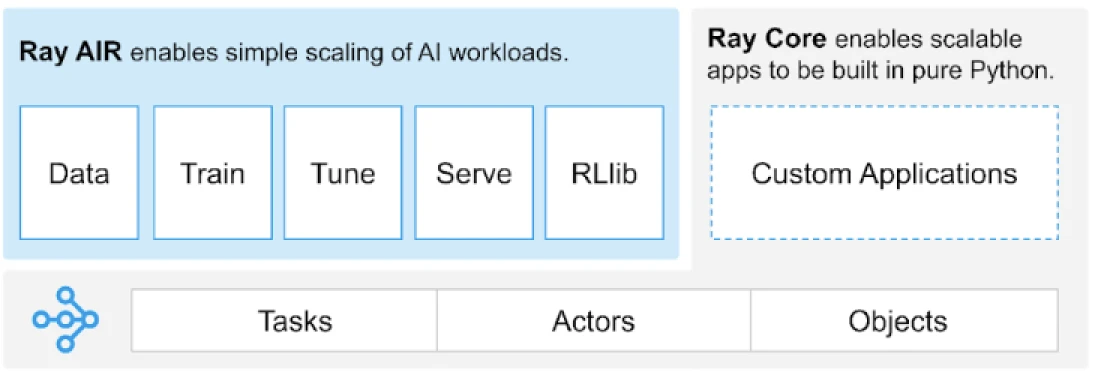
O Ray fornece uma API universal de tarefas, atores e objetos para construir aplicações distribuídas.
(Fonte da imagem)
O Ray fornece um conjunto de bibliotecas construídas sobre os primitivos principais, ou seja, Tarefas, Atores, Objetos, Drivers e Jobs. Estes fornecem uma API versátil para ajudar a construir aplicações distribuídas. Vamos dar uma olhada nos primitivos principais, também conhecidos como Ray Core.
Primitivos Principais do Ray
- Tarefas: Tarefas Ray são funções Python arbitrárias que são executadas de forma assíncrona em trabalhadores Python separados em um nó de cluster Ray. Os usuários podem especificar seus requisitos de recursos em termos de CPUs, GPUs e recursos personalizados, que são usados pelo escalonador do cluster para distribuir tarefas para execução paralelizada.
- Atores: O que as tarefas são para funções, os atores são para classes. Um ator é um trabalhador com estado, e os métodos de um ator são agendados naquele trabalhador específico e podem acessar e modificar o estado desse trabalhador. Assim como as tarefas, os atores suportam requisitos de recursos de CPU, GPU e personalizados.
- Objetos: No Ray, tarefas e atores criam e computam objetos. Esses objetos remotos podem ser armazenados em qualquer lugar em um cluster Ray. Referências de Objetos são usadas para se referir a eles, e eles são armazenados em cache na memória compartilhada distribuída do Ray.
- Drivers: A raiz do programa, ou o programa “principal”: este é o código que executa
ray.init() - Trabalhos: A coleção de tarefas, objetos e atores originados (recursivamente) do mesmo driver e seu ambiente de execução
Para informações sobre primitivas, você pode consultar a documentação do Ray Core.
Principais Métodos do Ray Core
Abaixo estão alguns dos principais métodos dentro do Ray Core que são comumente usados:
-
ray.init()– Iniciar o runtime do Ray e conectar ao cluster Ray.import ray ray.init()
-
@ray.remote– Decorador que especifica uma função ou classe Python a ser executada como uma tarefa (função remota) ou ator (classe remota) em um processo diferente@ray.remote def remote_function(x): return x * 2
-
.remote– Sufixo para funções e classes remotas; operações remotas são assíncronasresult_ref = remote_function.remote(10)
-
ray.put()– Colocar um objeto no armazenamento de objetos em memória; retorna uma referência de objeto usada para passar o objeto para qualquer chamada de função ou método remoto.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Obter um ou mais objetos remotos do armazenamento de objetos especificando as referências de objeto.result = ray.get(result_ref) original_data = ray.get(data_ref)
Aqui está um exemplo de uso da maioria dos métodos-chave básicos:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Usando .remote para criar uma tarefa
future = calculate_square.remote(5)
# Obter o resultado
result = ray.get(future)
print(f"The square of 5 is: {result}")Como o Ray Funciona?
O Cluster Ray é como uma equipe de computadores que compartilham o trabalho de executar um programa. Ele consiste em um nó principal e vários nós trabalhadores. O nó principal gerencia o estado do cluster e o agendamento, enquanto os nós trabalhadores executam tarefas e gerenciam atores
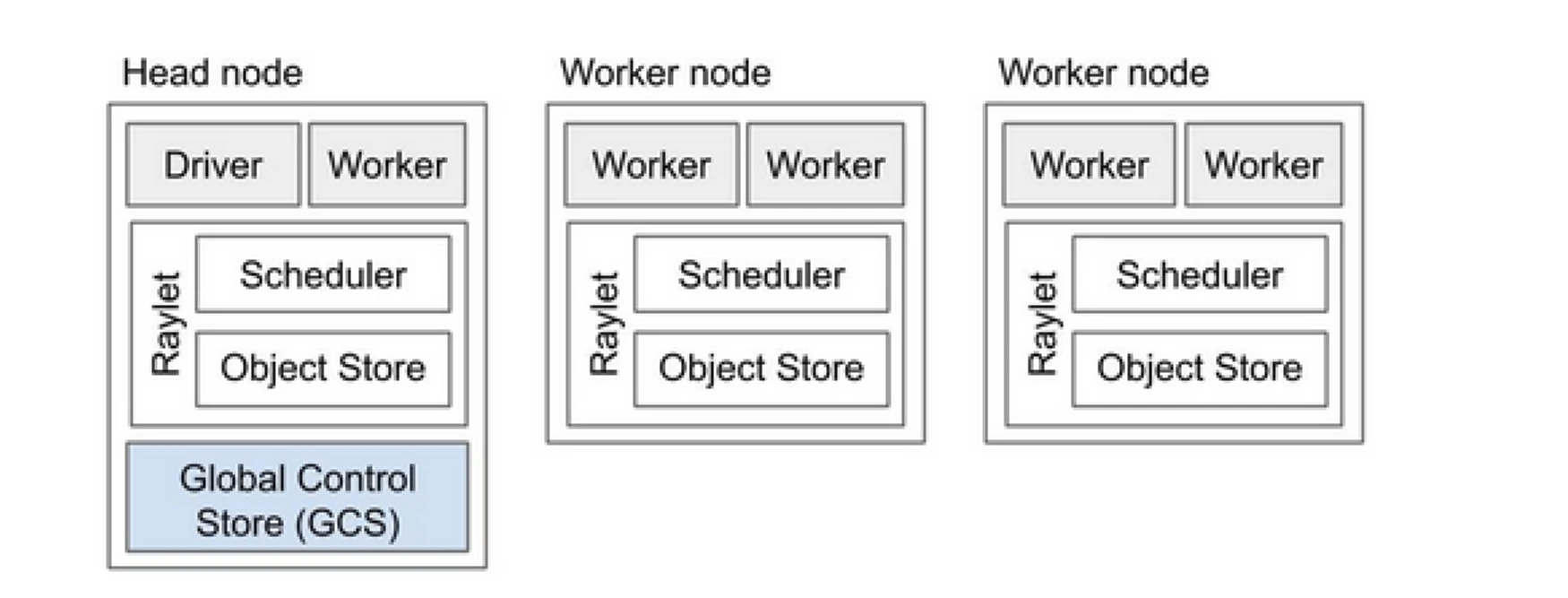
Componentes do Cluster Ray
- Armazenamento de Controle Global (GCS): O GCS gerencia os metadados e o estado global do cluster Ray. Ele rastreia tarefas, atores e a disponibilidade de recursos, garantindo que todos os nós tenham uma visão consistente do sistema.
- Agendador: O agendador distribui tarefas e atores entre os nós disponíveis. Ele garante a utilização eficiente de recursos e o balanceamento de carga, considerando os requisitos de recursos e as dependências das tarefas.
- Nó principal: O nó principal orquestra todo o cluster Ray. Ele executa o GCS, lida com o agendamento de tarefas e monitora a saúde dos nós trabalhadores.
- Nós trabalhadores: Os nós trabalhadores executam tarefas e atores. Eles realizam os cálculos reais e armazenam objetos em sua memória local.
- Raylet: Ele gerencia recursos compartilhados em cada nó e é compartilhado entre todos os trabalhos que estão sendo executados simultaneamente.
Você pode conferir o documento da Arquitetura Ray v2 para obter informações mais detalhadas.
Trabalhar com aplicações Python existentes não requer muitas mudanças. As alterações necessárias seriam principalmente em torno da função ou classe que precisa ser distribuída naturalmente. Você pode adicionar um decorador e convertê-lo em tarefas ou atores. Vamos ver um exemplo disso.
Convertendo uma Função Python em uma Tarefa Ray
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Convertendo uma Classe Python em um Ator Ray
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Armazenando Informações em Objetos Ray
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Para saber mais sobre seu conceito, consulte a documentação de Conceitos Principais do Ray Core.
Ray vs Abordagem Tradicional de Processamento Paralelo Distribuído
Abaixo está uma análise comparativa entre a abordagem tradicional (sem Ray) e Ray no Kubernetes para habilitar o processamento paralelo distribuído.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Implantação | Configuração e setup manual | Automatizado com o Operador KubeRay |
| Escala | Escala manual | Escala automática com RayAutoScaler e Kubernetes |
| Tolerância a Falhas | Mecanismos de tolerância a falhas personalizados | Tolerância a falhas integrada com Kubernetes e Ray |
| Gerenciamento de Recursos | Alocação manual de recursos | Alocação e gerenciamento automatizados de recursos |
| Balanceamento de Carga | Soluções personalizadas de balanceamento de carga | Balanceamento de carga embutido com Kubernetes |
| Gerenciamento de Dependências | Instalação manual de dependências | Ambiente consistente com contêineres Docker |
| Coordenação de Cluster | Complexo e manual | Simplificado com descoberta de serviço e coordenação do Kubernetes |
| Custo de Desenvolvimento | Alto, com soluções personalizadas necessárias | Reduzido, com Ray e Kubernetes lidando com muitos aspectos |
| Flexibilidade | Adaptação limitada a cargas de trabalho em mudança | Alta flexibilidade com escalonamento dinâmico e alocação de recursos |
O Kubernetes fornece uma plataforma ideal para executar aplicações distribuídas como o Ray devido às suas robustas capacidades de orquestração. Abaixo estão os principais pontos que valorizam a execução do Ray no Kubernetes:
- Gerenciamento de recursos
- Escalabilidade
- Orquestração
- Integração com o ecossistema
- Implantação e gerenciamento fáceis
O KubeRay Operator possibilita a execução do Ray no Kubernetes.
O que é KubeRay?
O KubeRay Operator simplifica o gerenciamento de clusters Ray no Kubernetes, automatizando tarefas como implantação, escalonamento e manutenção. Ele utiliza as Definições de Recursos Personalizados (CRDs) do Kubernetes para gerenciar recursos específicos do Ray.
CRDs do KubeRay
Tem três CRDs distintos:
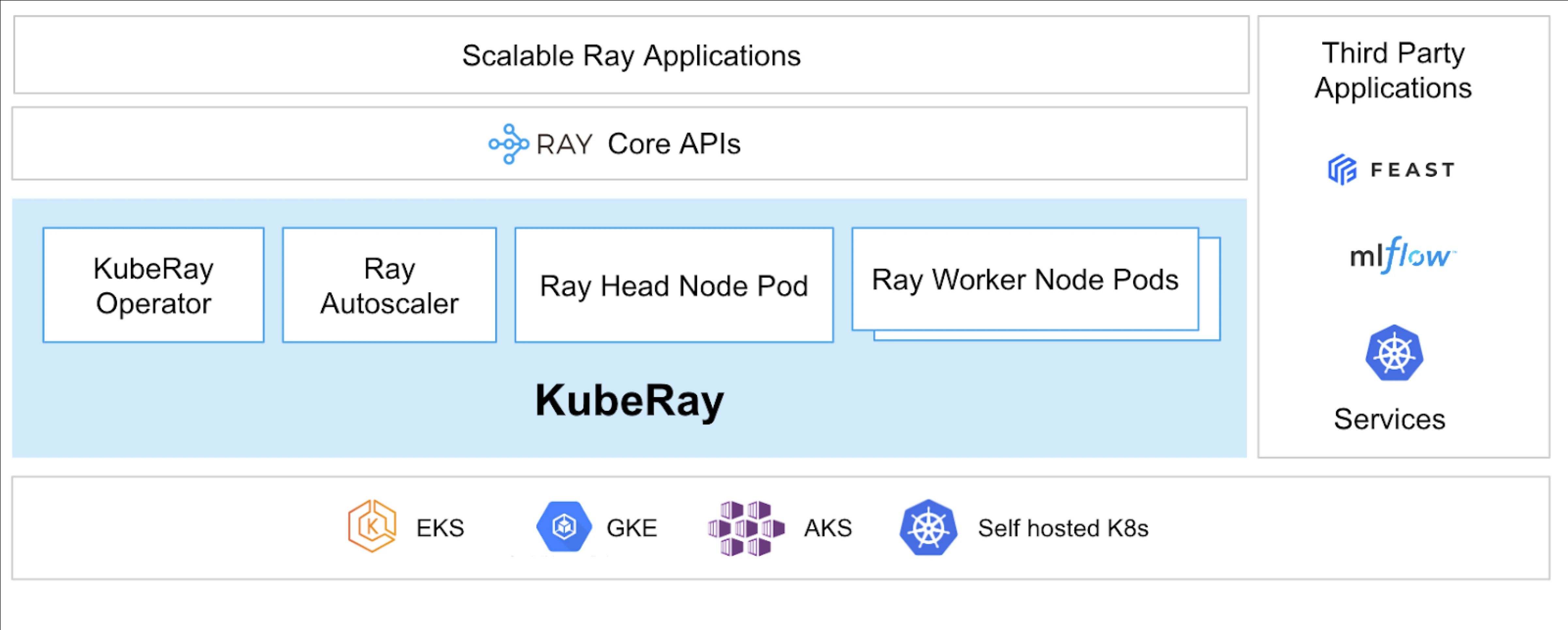
- RayCluster: Este CRD ajuda a gerenciar o ciclo de vida do RayCluster e cuida do dimensionamento automático com base na configuração definida.
- RayJob: É útil quando há um trabalho único que você deseja executar em vez de manter um RayCluster standby o tempo todo. Ele cria um RayCluster e envia o trabalho quando estiver pronto. Assim que o trabalho estiver concluído, ele exclui o RayCluster. Isso ajuda na reciclagem automática do RayCluster.
- RayService: Isso também cria um RayCluster, mas implanta um aplicativo RayServe nele. Este CRD torna possível fazer atualizações no local do aplicativo, fornecendo atualizações sem tempo de inatividade para garantir a alta disponibilidade do aplicativo.
Casos de uso do KubeRay
Implantando um Modelo Sob Demanda Usando RayService
O RayService permite implantar modelos sob demanda em um ambiente Kubernetes. Isso pode ser particularmente útil para aplicativos como geração de imagens ou extração de texto, onde os modelos são implantados apenas quando necessário.
Aqui está um exemplo de difusão estável. Uma vez aplicado no Kubernetes, ele criará um RayCluster e também executará um RayService, que servirá o modelo até que você exclua este recurso. Isso permite que os usuários tenham controle sobre os recursos.
Treinar um Modelo em um Cluster de GPU Usando RayJob
O RayService atende a diferentes requisitos do usuário, mantendo o modelo ou aplicação implantado até que seja excluído manualmente. Em contraste, o RayJob permite trabalhos únicos para casos de uso como treinamento de modelo, pré-processamento de dados ou inferência para um número fixo de prompts fornecidos.
Executar Servidor de Inferência no Kubernetes Usando RayService ou RayJob
Geralmente, executamos nossa aplicação em Implantações, que mantêm as atualizações contínuas sem tempo de inatividade. Da mesma forma, no KubeRay, isso pode ser alcançado usando o RayService, que implanta o modelo ou aplicação e lida com as atualizações contínuas.
No entanto, pode haver casos em que você só deseja fazer inferência em lote em vez de executar os servidores de inferência ou aplicações por um longo período. É aqui que você pode aproveitar o RayJob, que é semelhante ao recurso Job do Kubernetes.
A Classificação de Imagens em Lote com o Huggingface Vision Transformer é um exemplo de RayJob, que realiza Inferência em Lote.
Estes são os casos de uso do KubeRay, permitindo que você faça mais com o cluster Kubernetes. Com a ajuda do KubeRay, você pode executar cargas de trabalho mistas no mesmo cluster Kubernetes e descarregar o agendamento de cargas de trabalho baseadas em GPU para o Ray.
Conclusão
O processamento paralelo distribuído oferece uma solução escalável para lidar com tarefas de grande escala e que consomem muitos recursos. O Ray simplifica as complexidades de construção de aplicações distribuídas, enquanto o KubeRay integra o Ray com o Kubernetes para implantação e escalonamento sem costura. Essa combinação melhora o desempenho, a escalabilidade e a tolerância a falhas, tornando-a ideal para rastreamento da web, análise de dados e tarefas de aprendizado de máquina. Ao aproveitar o Ray e o KubeRay, você pode gerenciar de forma eficiente a computação distribuída, atendendo às demandas do mundo orientado a dados de hoje com facilidade.
Não só isso, mas à medida que nossos tipos de recursos computacionais estão mudando de CPU para GPU, torna-se importante ter uma infraestrutura em nuvem eficiente e escalável para todos os tipos de aplicações, seja IA ou processamento de grandes dados.
Se você achou este post informativo e envolvente, adoraria ouvir seus pensamentos sobre este post, então comece uma conversa no LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray