













Converter seus dados brutos em informações organizadas e acionáveis pode parecer complexo. Bem, não quando você tem uma solução rápida e eficiente. Não se preocupe! Este tutorial do AWS Glue, adequado para iniciantes, está aqui para ajudar.
Neste tutorial, você aprenderá as etapas cruciais de configuração e execução de transformações de dados com o AWS Glue.
Explore e otimize a preparação de dados para análises baseadas em nuvem!
Pré-requisitos
Antes de trabalhar com o AWS Glue, certifique-se de ter uma conta ativa na Amazon Web Services (AWS) com faturamento habilitado. Uma conta gratuita será suficiente para este tutorial.
Criando uma função IAM para o AWS Glue
Antes de executar uma tarefa de transformação, você deve criar uma função de Gerenciamento de Identidade e Acesso (IAM) que conceda permissão ao serviço AWS Glue. Essa função define que tipo de recursos o AWS Glue tem permissão para acessar em sua conta da AWS.
Para criar a função IAM, siga as etapas abaixo:
1. Abra o navegador da web de sua preferência e faça login no Console de Gerenciamento da AWS.
2. Pesquise e selecione IAM na lista de resultados para acessar o console do IAM.
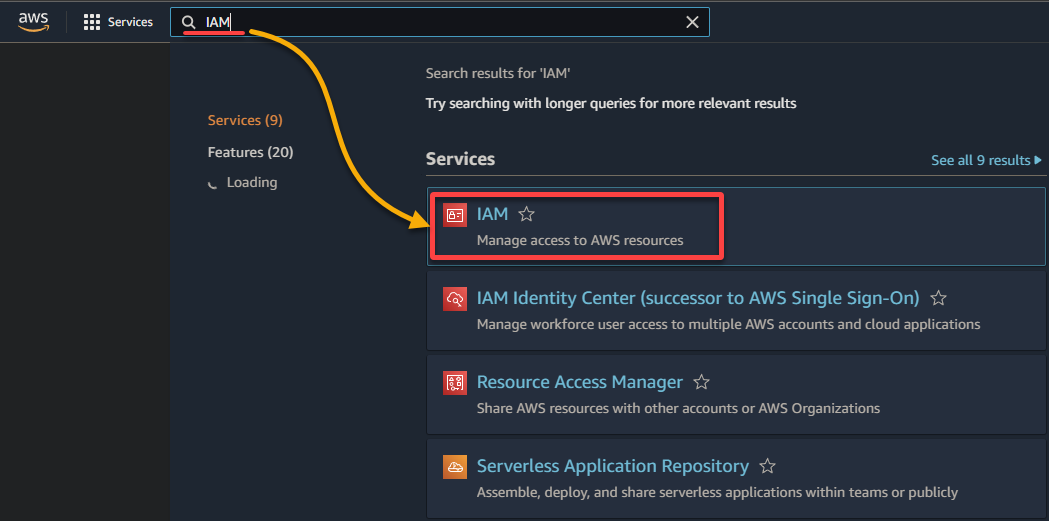
3. No console do IAM, navegue até Funções (painel esquerdo) e clique em Criar função (canto superior direito), redirecionando seu navegador para uma nova página dedicada à configuração da função.

4. Agora, configure as seguintes definições para a função:
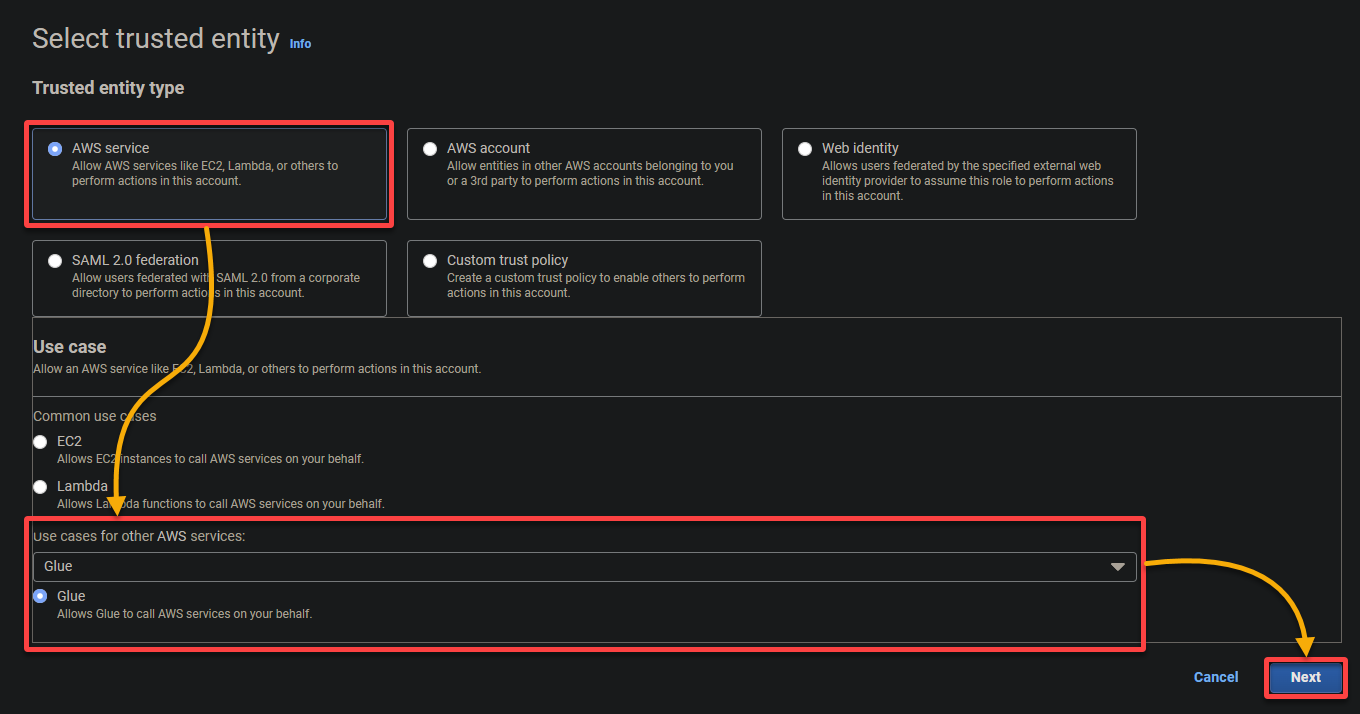
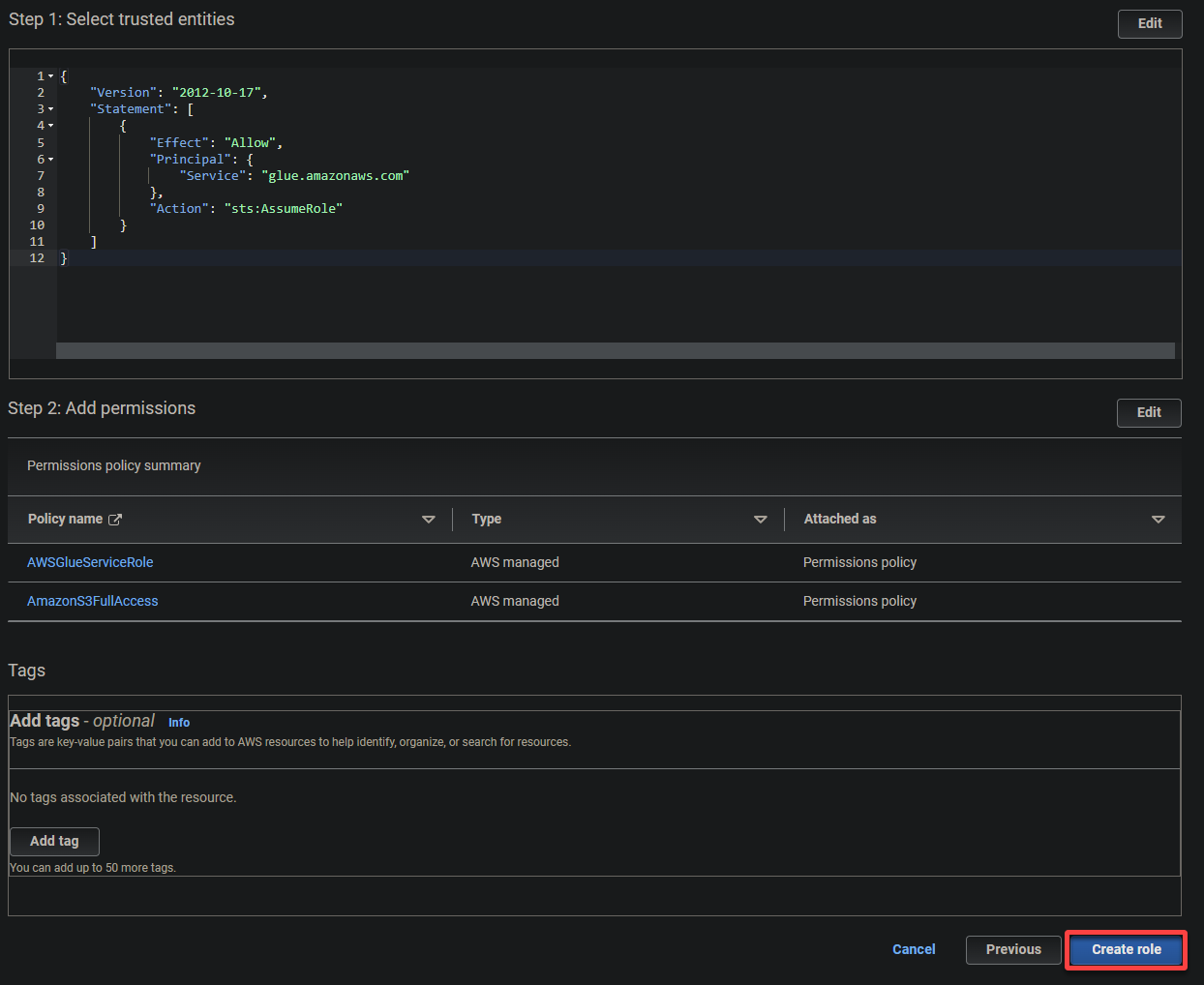
- Tipo de entidade confiável – Selecione serviço da AWS para que um serviço da AWS confie na função. Fazê-lo permite que esse serviço assuma a função e aja em seu nome.
- Caso de uso – Escolha Glue na seção Casos de uso para outros serviços da AWS, já que você criará a função do IAM especificamente para o AWS Glue, e clique em Avançar.
5. Pesquise e selecione as seguintes políticas e clique em Avançar.
- AWSGlueServiceRole – Concede ao serviço AWS Glue as permissões necessárias para realizar suas operações.
- S3FullAccess – Concede acesso total aos recursos S3, permitindo que o AWS Glue leia e escreva em buckets S3.
O AWS Glue precisa de permissões extensas para ler e escrever em buckets S3 para realizar suas tarefas de extração, transformação e carregamento (ETL) de dados de forma eficaz.
? Ao evitar conceder permissões excessivas e desnecessárias, você pode evitar riscos de segurança.
6. Forneça um nome descritivo para a função (por exemplo, papel_glue) e uma descrição.
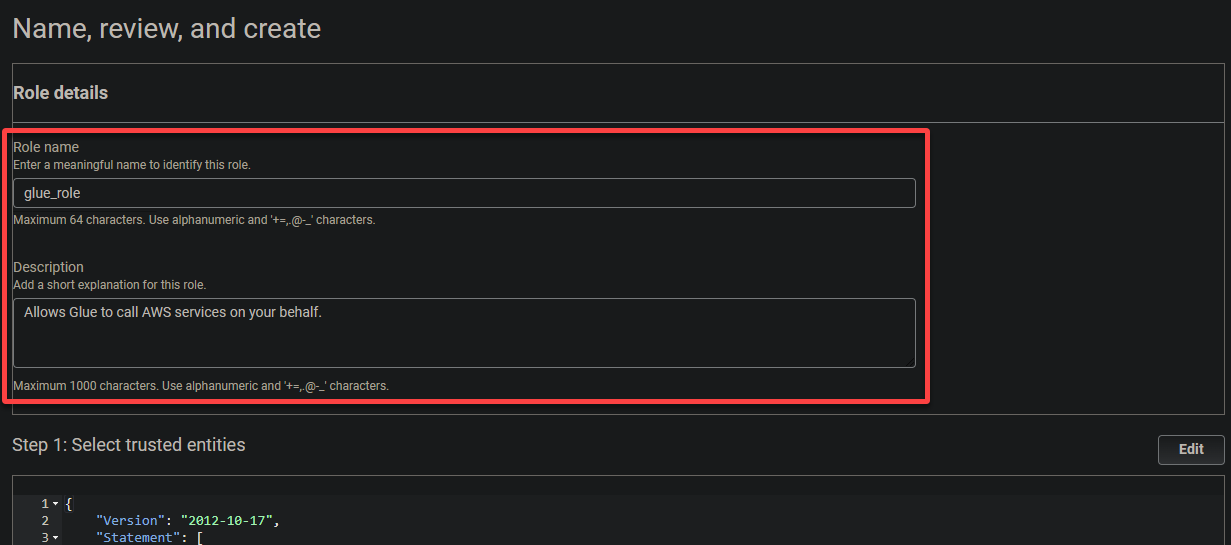
7. Por fim, role para baixo, revise suas configurações e clique em Criar função (canto inferior direito) para finalizar a criação da função.
Criando um Bucket S3 e Fazendo Upload de um Arquivo de Amostra
Agora que você tem uma função IAM para o AWS Glue, você precisa de um lugar para armazenar seus dados, especificamente, um bucket S3. Um bucket S3 fornece um local centralizado para armazenar os dados que o AWS Glue processará.
Neste exemplo, o AWS Glue usará o AWS S3 como um repositório de dados para várias operações, como extração de dados, transformação e carregamento (ETL).
Para criar um bucket S3 e carregar um arquivo de amostra, siga estas etapas:
1. Baixe um arquivo de dados de amostra (exemplo do conjunto de dados Every Politician) para sua máquina local. Este arquivo contém uma coleção não estruturada de registros para servir como entrada para o trabalho de transformação do AWS Glue.
2. Procure e selecione o serviço S3 para acessar o console do S3.
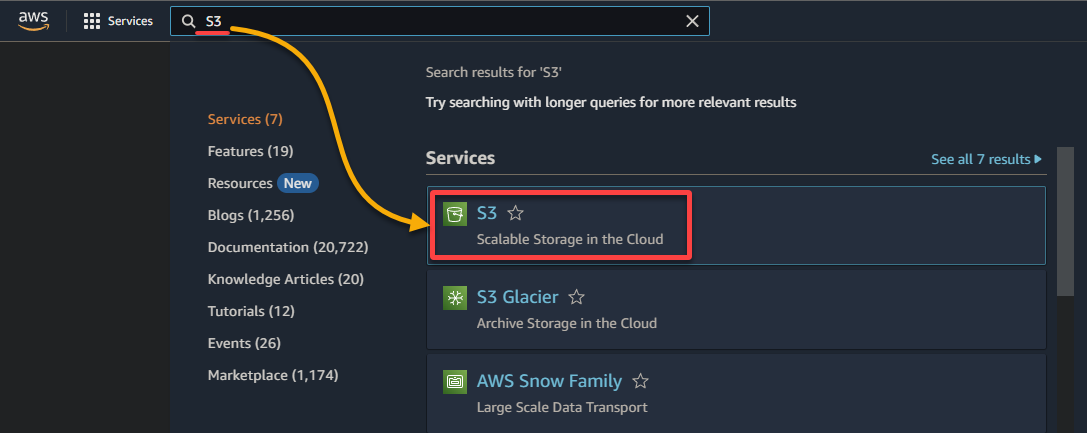
3. Clique em Criar um bucket para iniciar a criação de um novo bucket S3.

4. Agora, forneça um nome único para o seu bucket (ou seja, sampledata54675) e selecione a região onde o bucket deve ser localizado.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
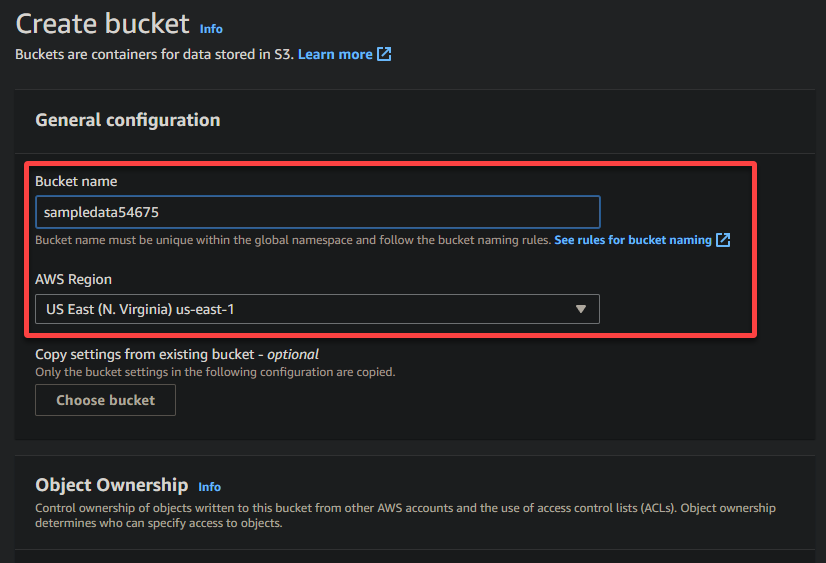
5. Role para baixo, mantenha outras opções como estão e clique em Criar bucket para criar o bucket.

6. Uma vez criado, clique no hiperlink para o bucket S3 recém-criado para navegar até o bucket.

7. Clique em Upload e localize o arquivo de amostra que deseja carregar.
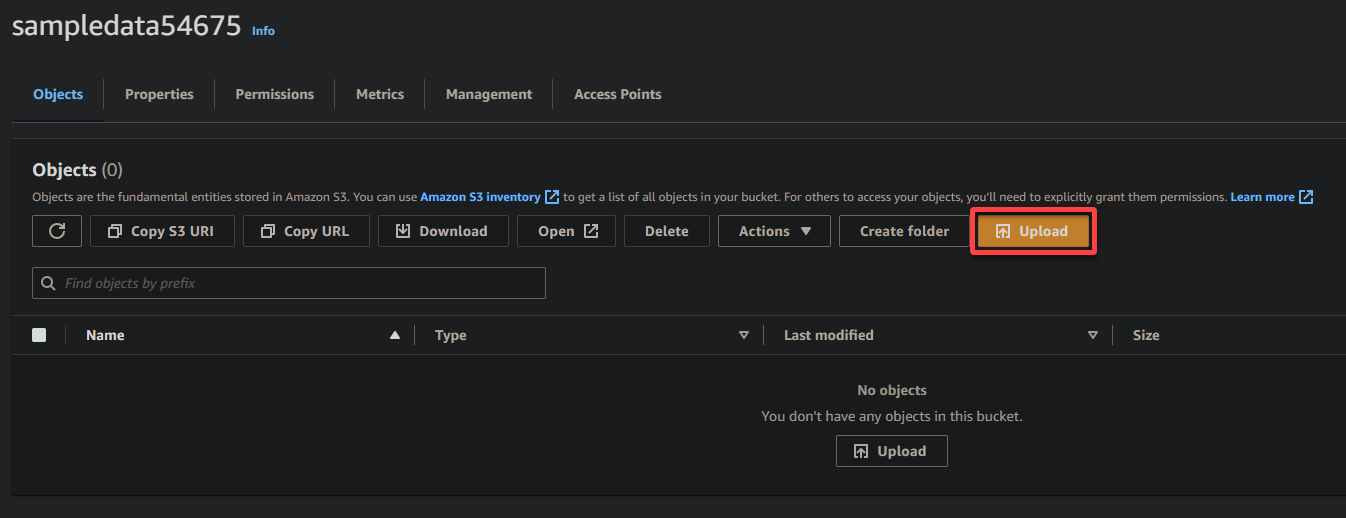
8. Por último, mantenha outras configurações como estão e clique em Enviar para enviar o arquivo de exemplo para o bucket recém-criado.
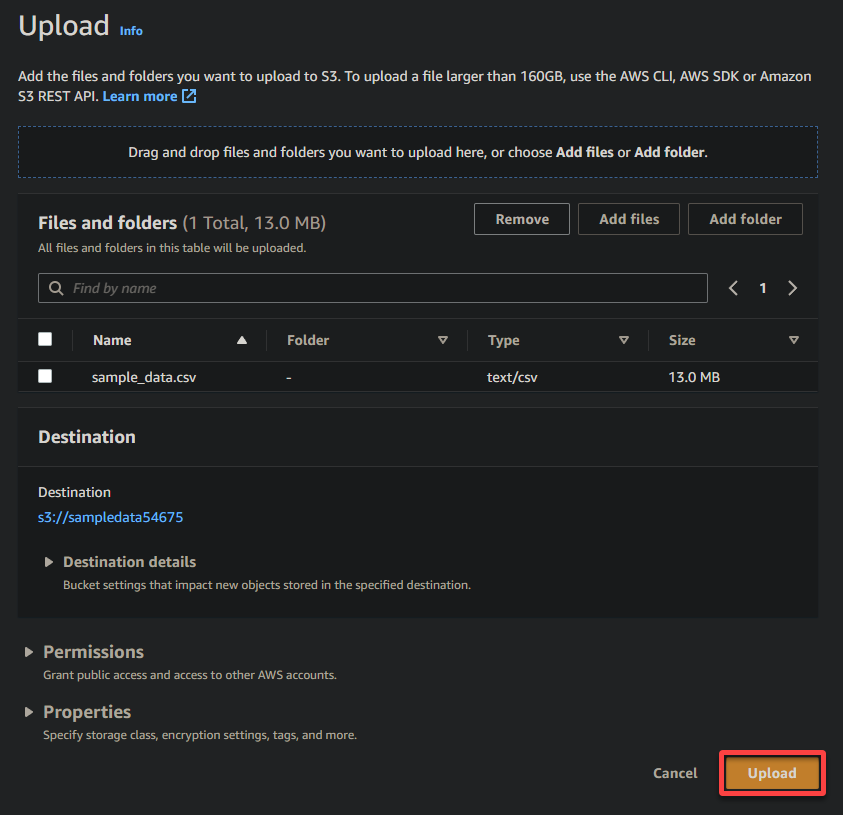
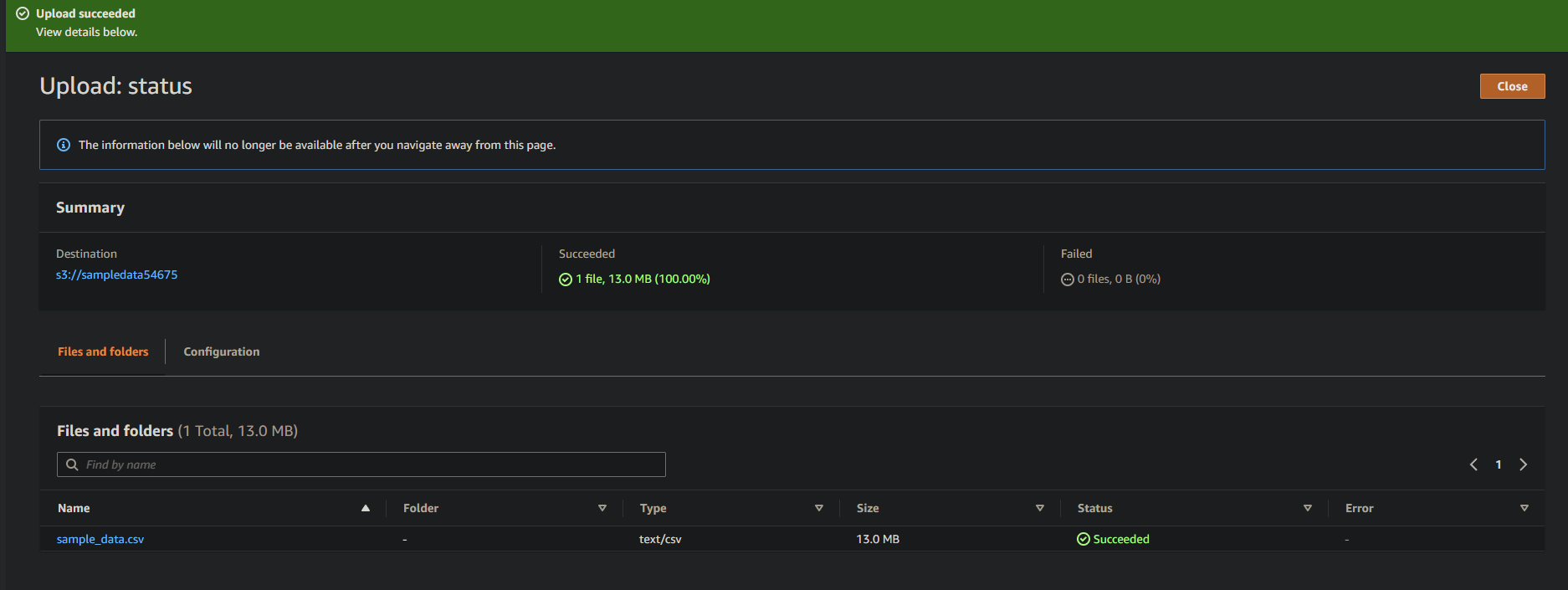
Se bem-sucedido, você verá seu arquivo recém-carregado no seu bucket, conforme mostrado abaixo.
Criando um Rastreador do Glue para Escanear e Catalogar Dados
Você acabou de enviar dados de exemplo para o seu bucket S3, mas como está atualmente não estruturado, você precisa de um meio de ler os dados e construir um catálogo de metadados. Como? Criando um rastreador do Glue que escaneia e cataloga automaticamente os dados.
Para criar um rastreador do Glue, siga as etapas abaixo:
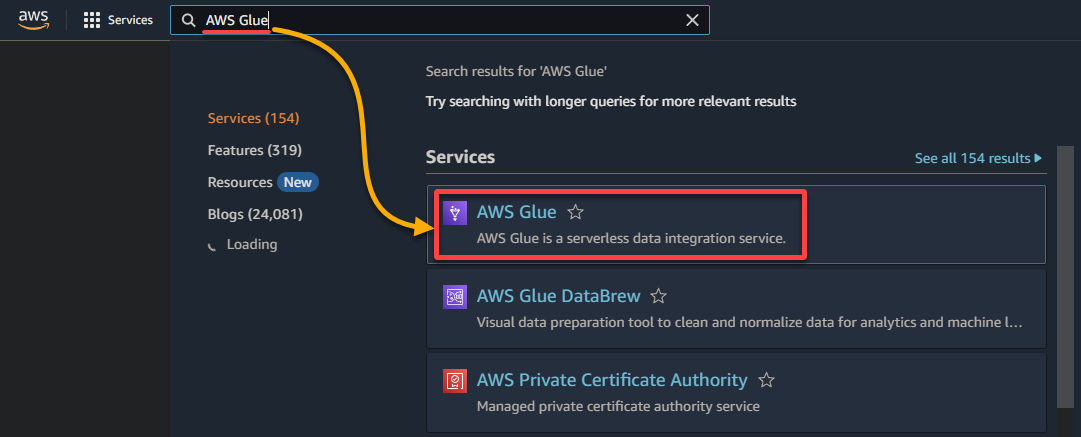
1. Navegue até o console do AWS Glue via o Console de Gerenciamento da AWS, conforme mostrado abaixo.
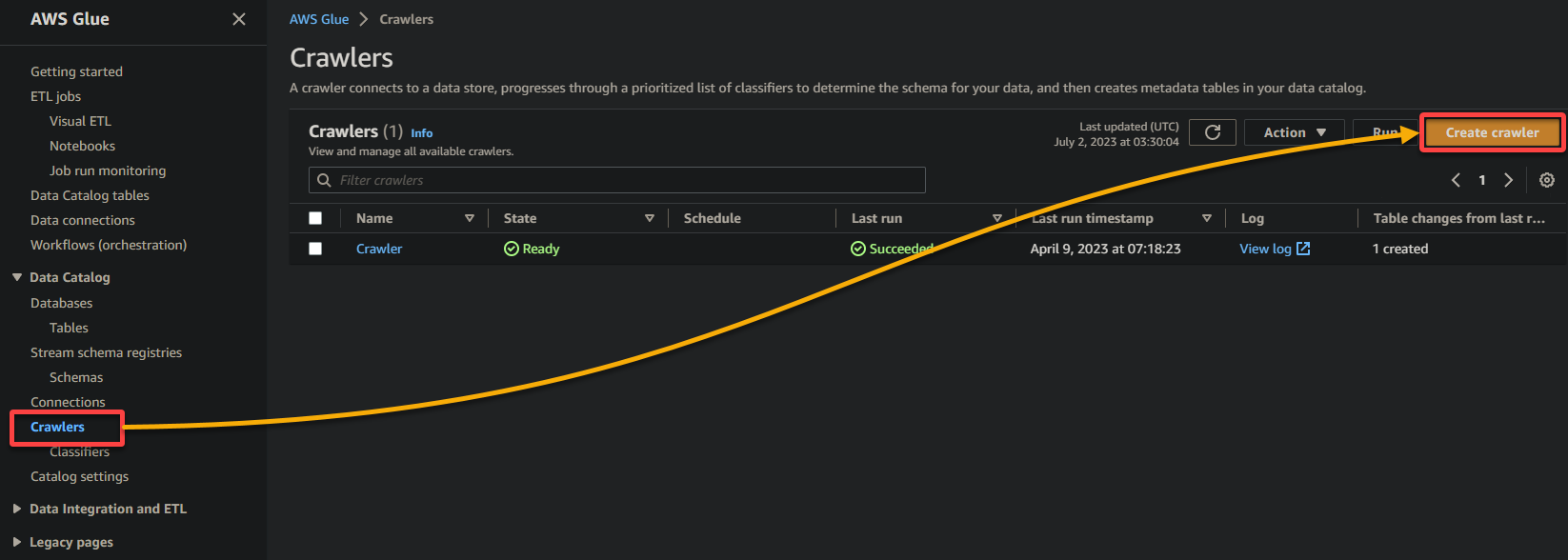
2. Em seguida, navegue até Rastreador (painel esquerdo) e clique em Adicionar rastreador (canto superior direito) para iniciar a criação de um novo rastreador do Glue.
3. Forneça um nome descritivo (ou seja, rastreador_glue) e uma descrição para o rastreador, mantenha outras configurações como estão e clique em Próximo.
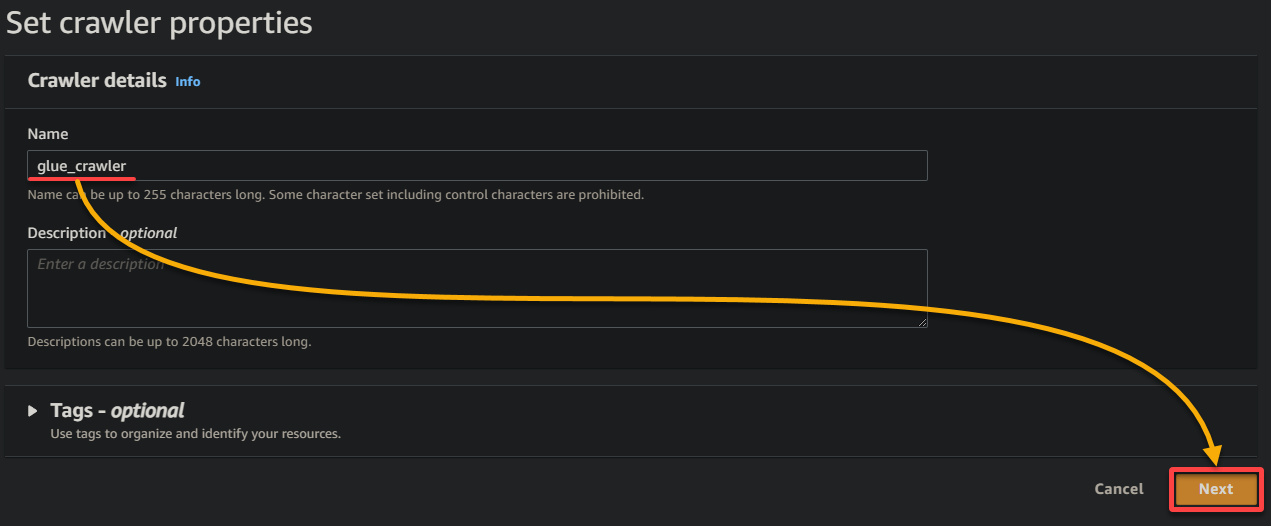
4. Agora, clique em Adicionar uma fonte de dados em Fontes de dados para iniciar a adição de uma nova fonte de dados ao rastreador.
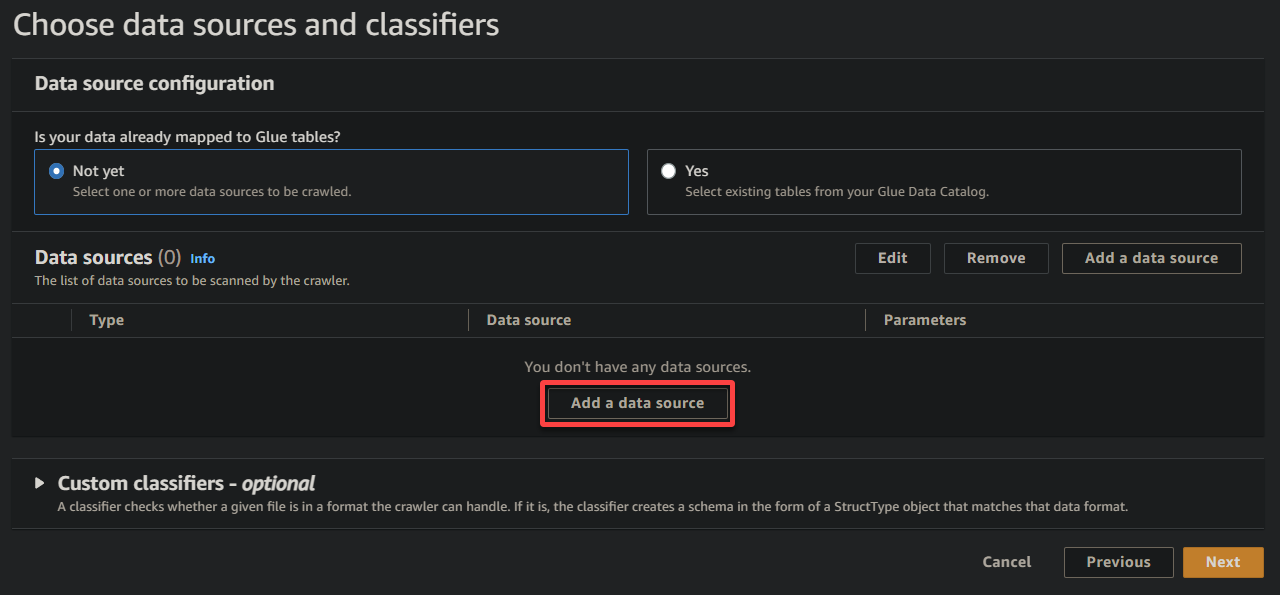
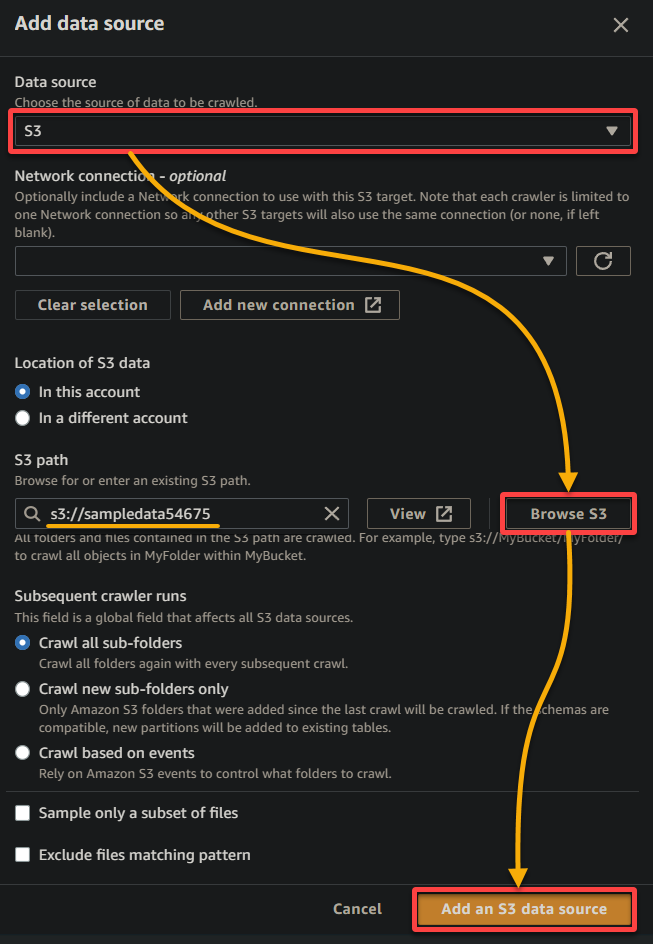
5. Na janela pop-up, configure a fonte de dados da seguinte forma:
- Fonte de dados – Selecione S3 pois seus dados estão no seu bucket S3.
- Caminho S3 – Clique em Procurar no S3 e escolha o bucket que contém seus dados de exemplo carregados (sampledata54675).
- Mantenha as outras configurações como estão e clique em Adicionar uma fonte de dados do S3 para adicionar os dados de exemplo ao rastreador.
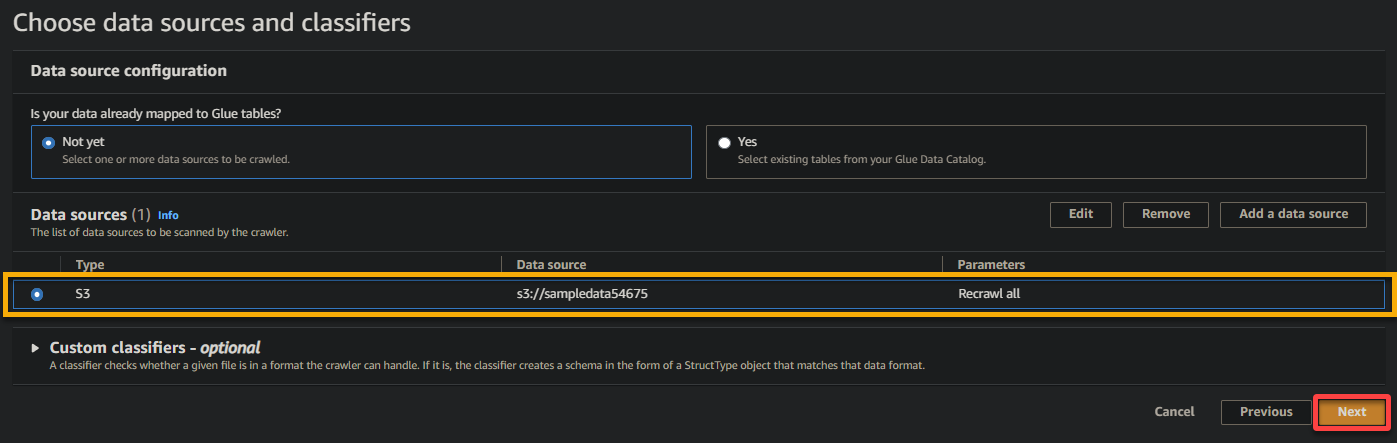
6. Uma vez configurado, verifique a fonte de dados, conforme mostrado abaixo, e clique em Avançar para continuar.
7. Na próxima tela, selecione a função IAM que você criou anteriormente (glue_role), mantenha as outras configurações como estão e clique em Avançar.
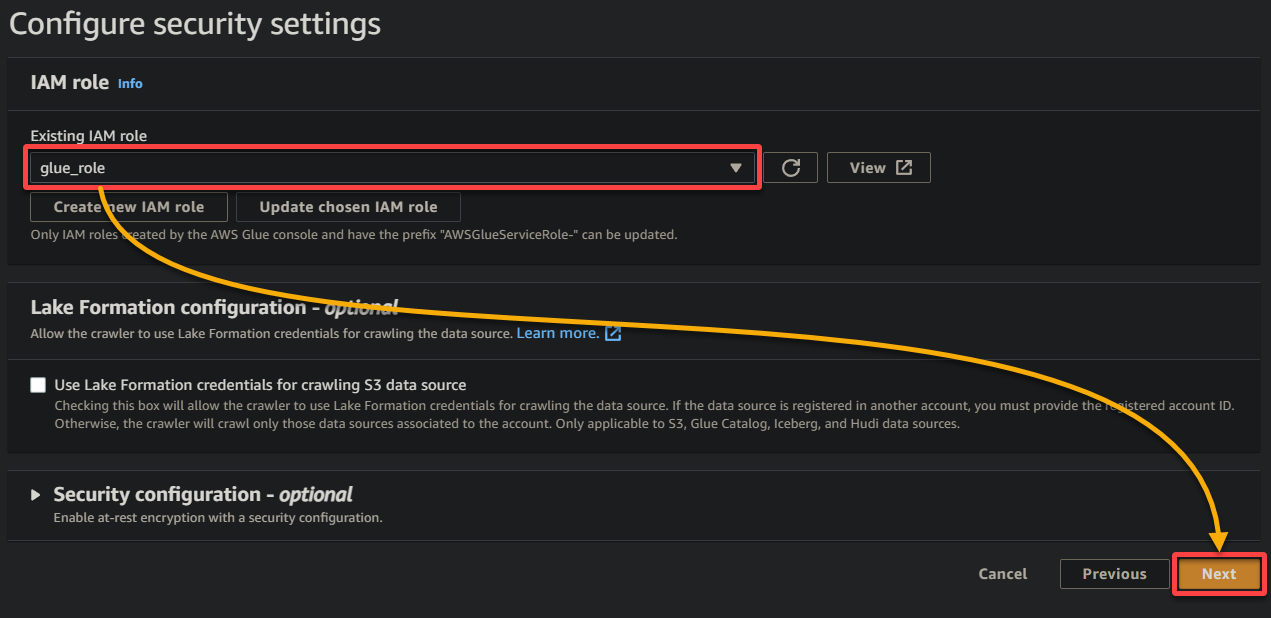
8. Em saída e agendamento, clique em Adicionar banco de dados para iniciar a adição de um novo banco de dados para armazenar os dados processados e metadados gerados pelo seu rastreador do Glue. Essa ação abrirá uma nova guia do navegador, onde você configurará os detalhes do seu banco de dados (passo oito).
Este banco de dados fornece uma representação estruturada dos dados para consulta e análise.
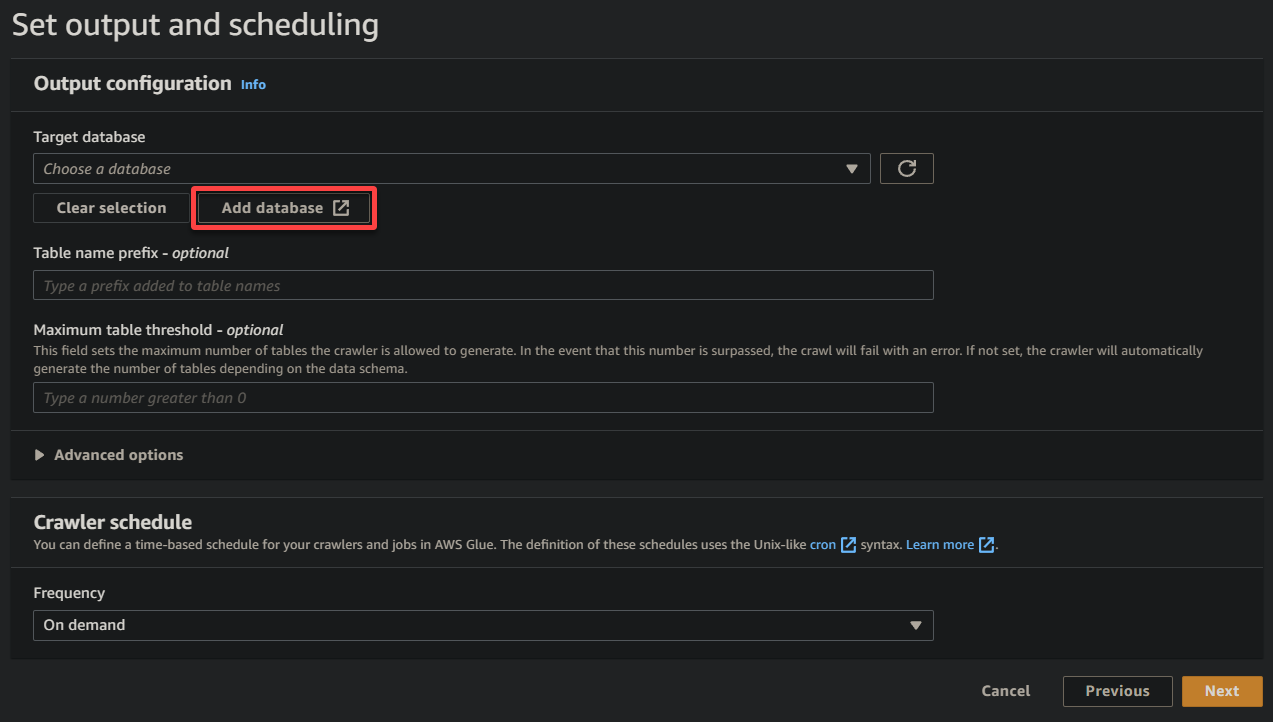
9. Na nova guia do navegador, forneça um nome descritivo para o banco de dados (ou seja, glue_database) e clique em Criar banco de dados para criar o banco de dados.
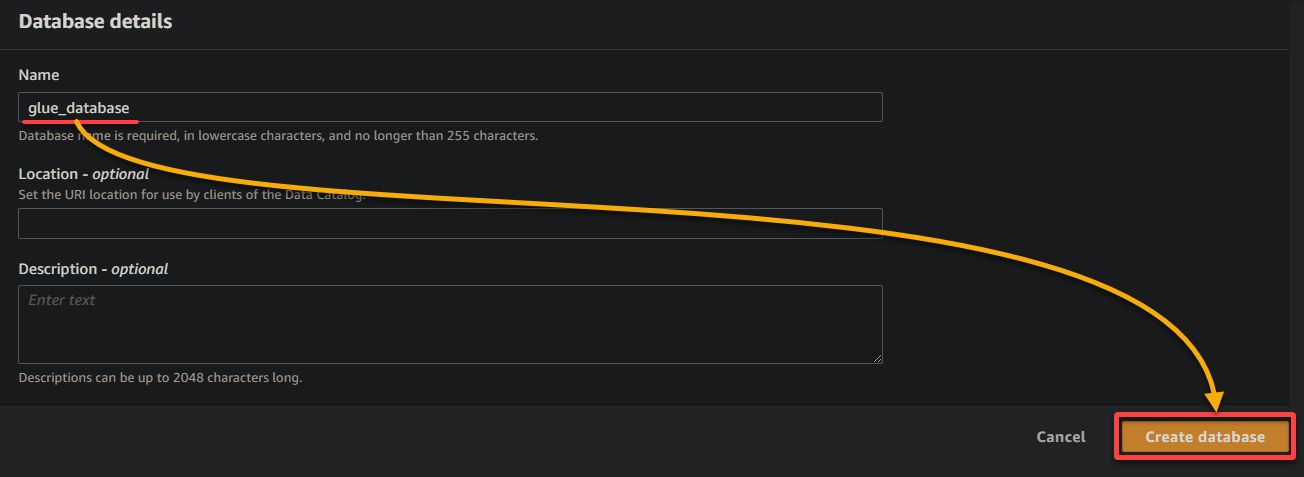
10. Volte para a guia do navegador anterior, selecione o banco de dados recém-criado (glue_database) no menu suspenso, mantenha as outras configurações como estão e clique em Avançar.
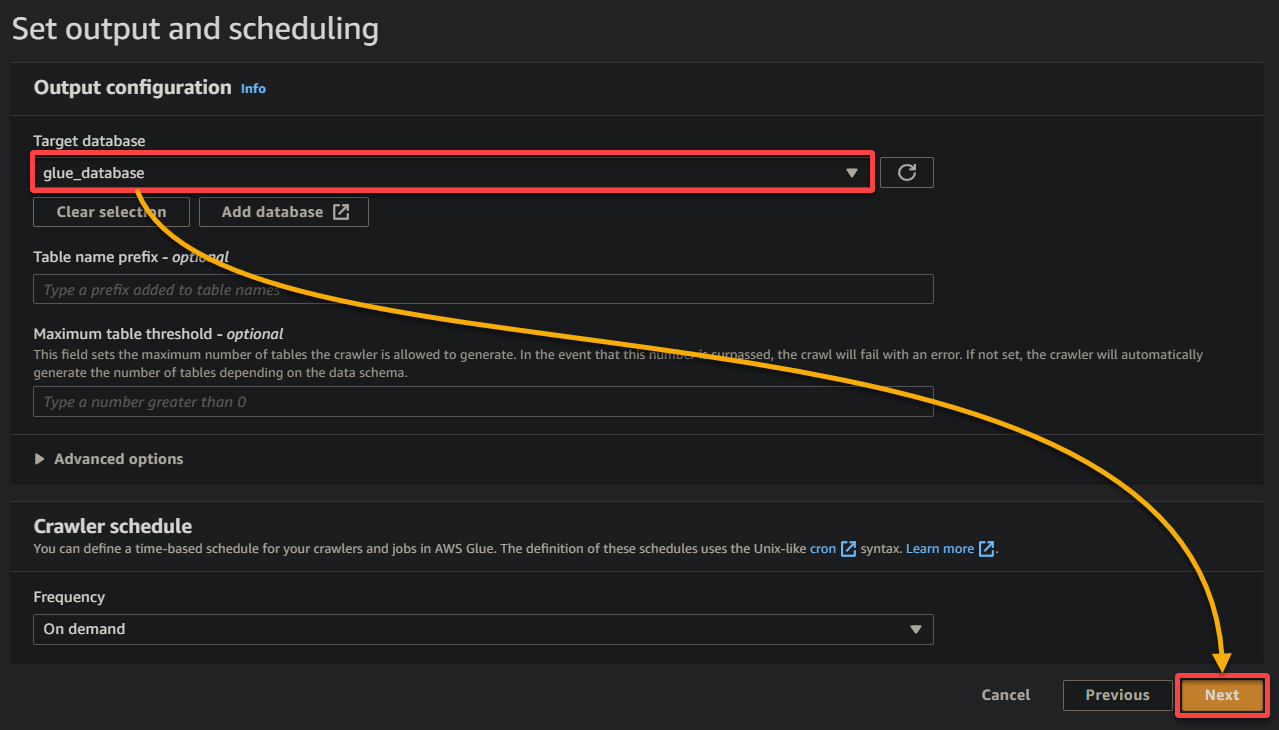
11. Por fim, revise suas configurações na tela final para garantir que estão corretas e clique em Criar rastreador (canto inferior direito) para criar o novo rastreador.
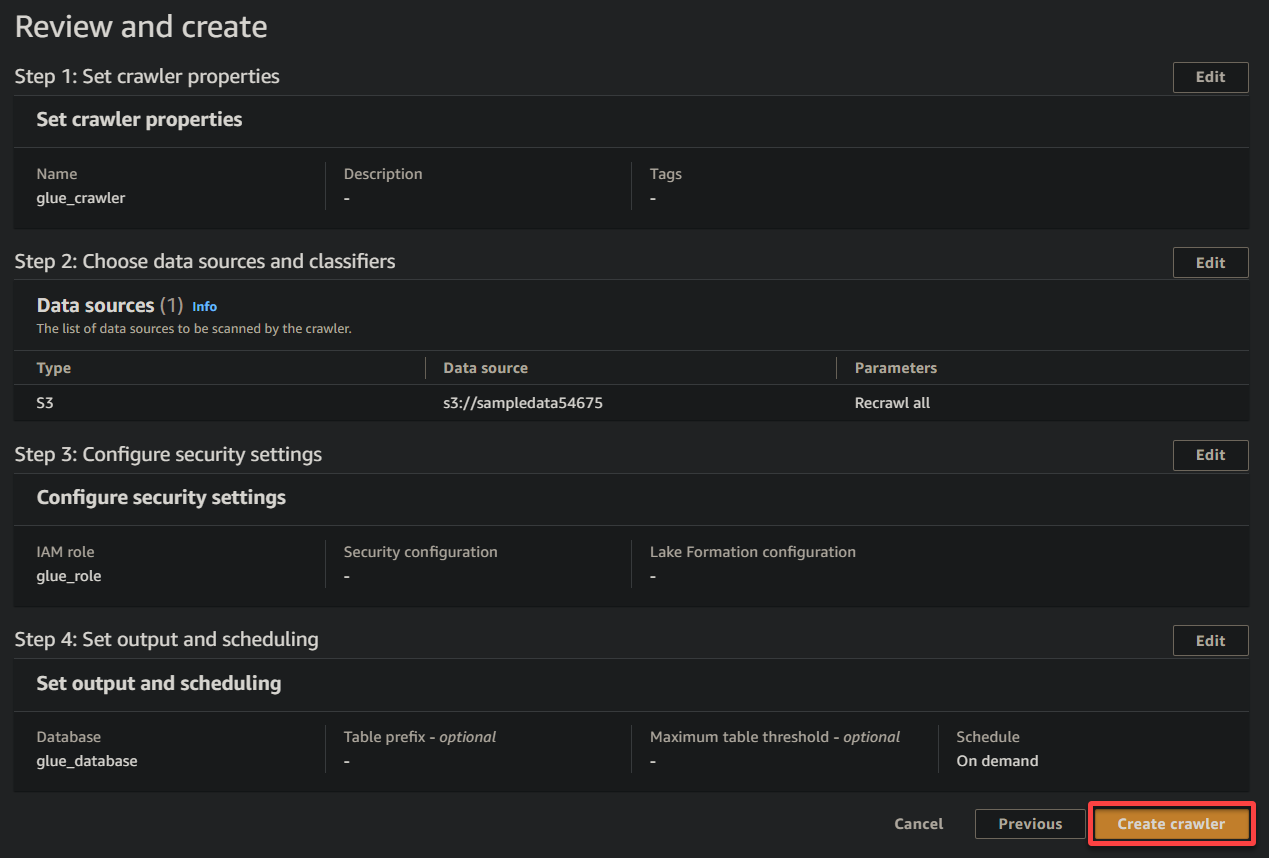
Se tudo correr bem, você verá uma tela confirmando a criação bem-sucedida do rastreador. Não feche esta tela ainda; você executará este rastreador na próxima seção.
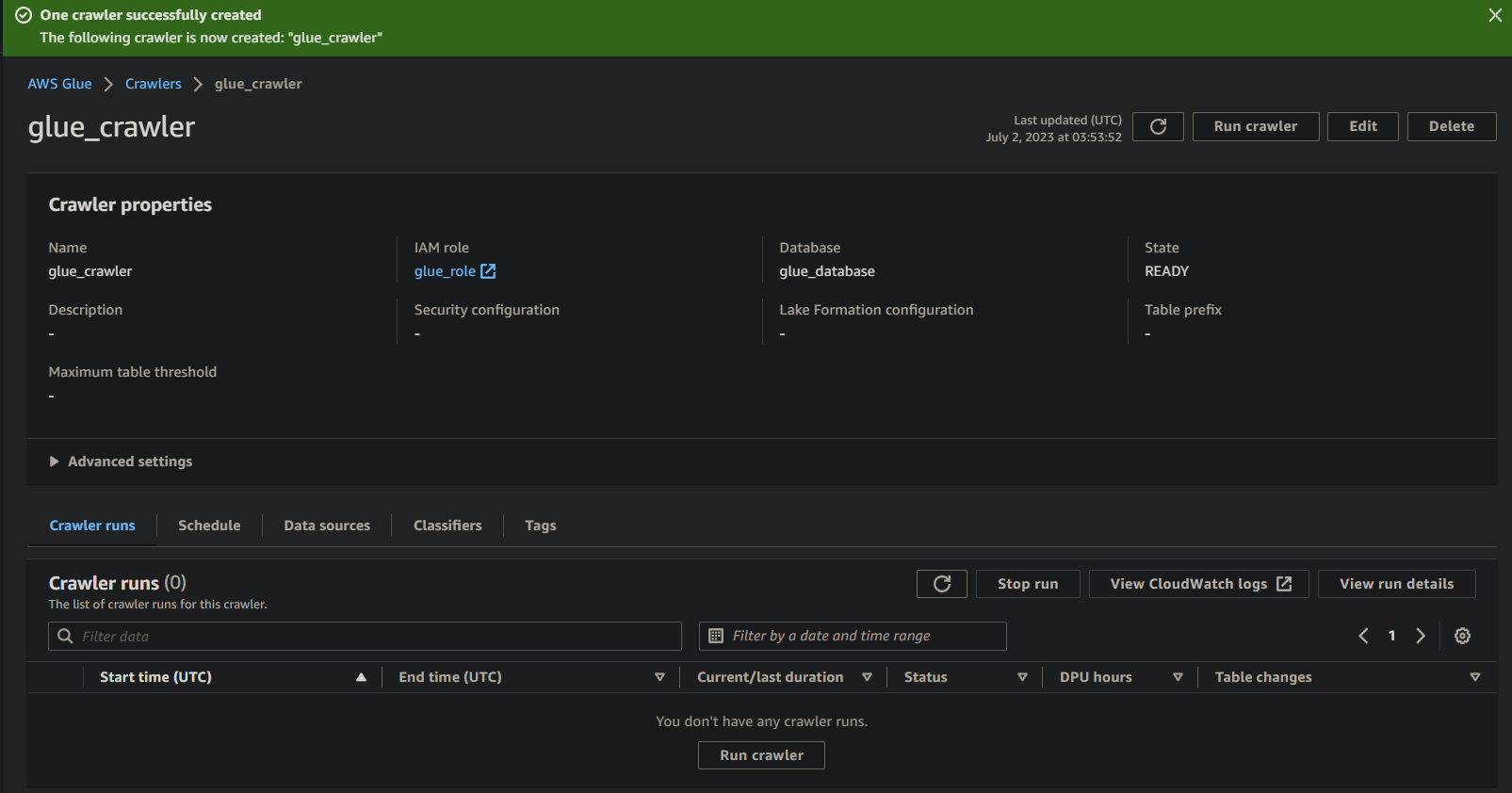
Executando o Crawler do Glue para Construir um Catálogo de Metadados
Com um novo crawler à sua disposição, executar o crawler é essencial para iniciar o processo de varredura e catalogação. Seu crawler do Glue construirá um catálogo de metadados que fornece uma representação estruturada dos seus dados para fins de consulta e análise.
Para executar o crawler do Glue recém-criado:
1. Na página de detalhes do crawler, clique em Executar crawler na guia Execuções do crawler para iniciar a execução do crawler.
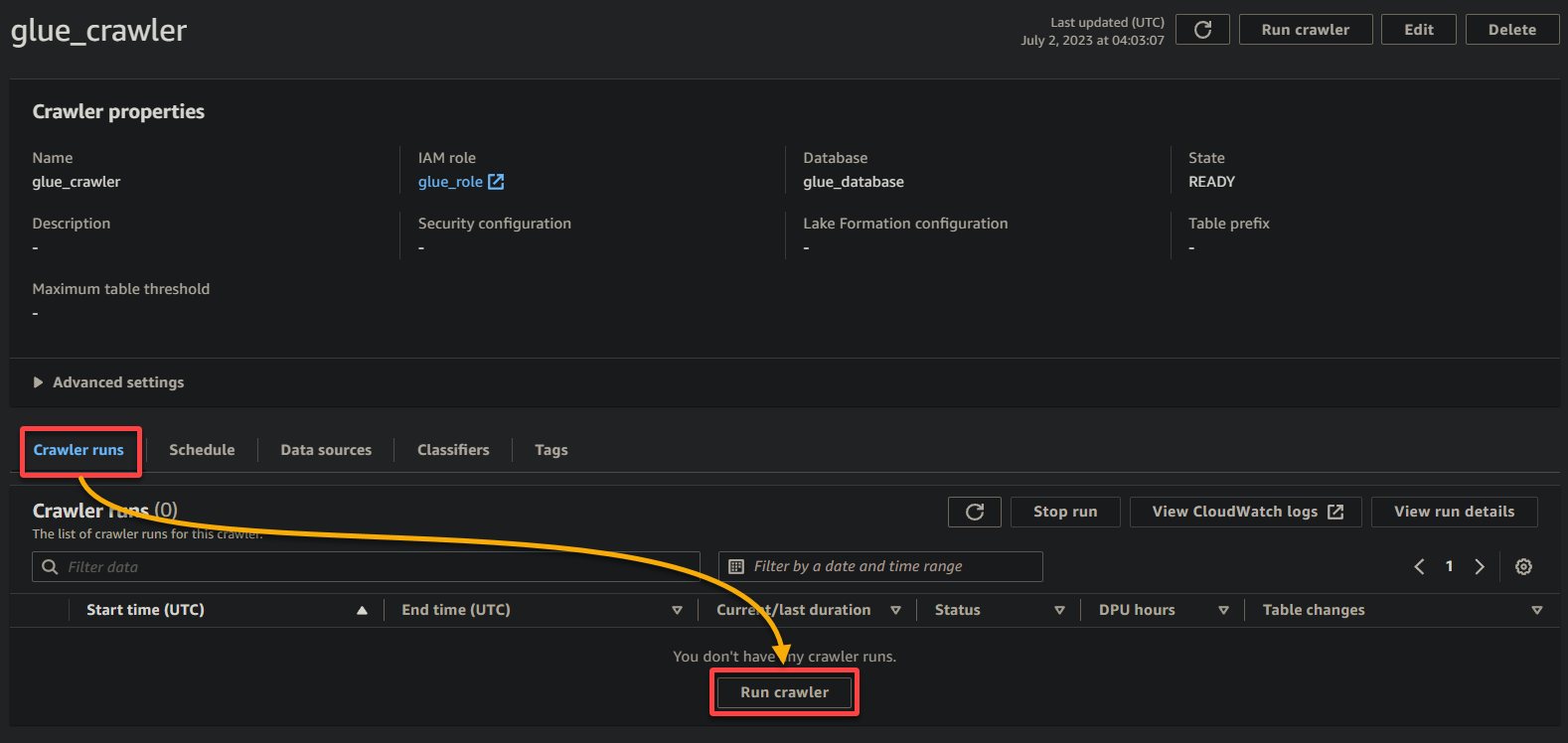
Assim que o crawler começar a ser executado, você verá seu status e progresso na página de detalhes do crawler.
Dependendo do tamanho e complexidade dos seus dados, o crawler pode levar algum tempo para concluir sua execução. Você pode atualizar periodicamente a página para ver o status atualizado do crawler.
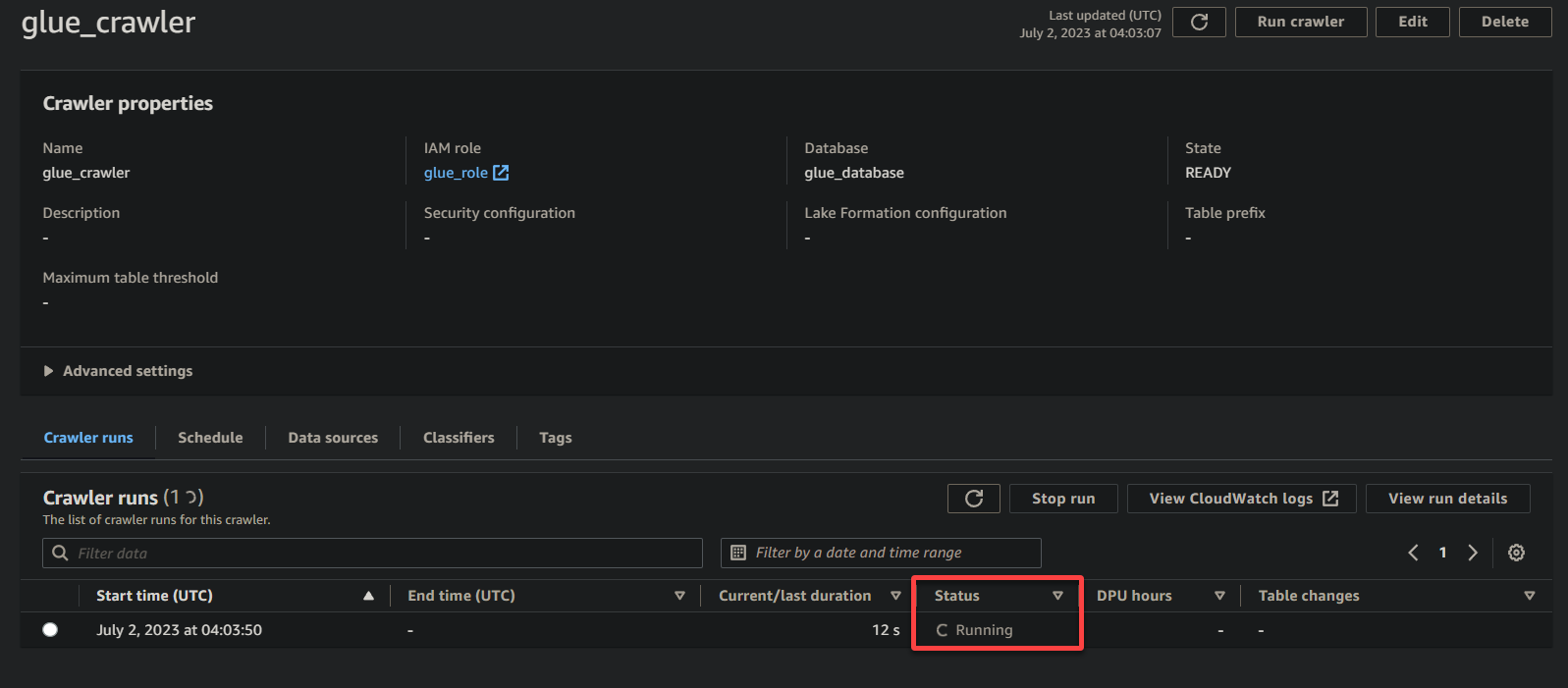
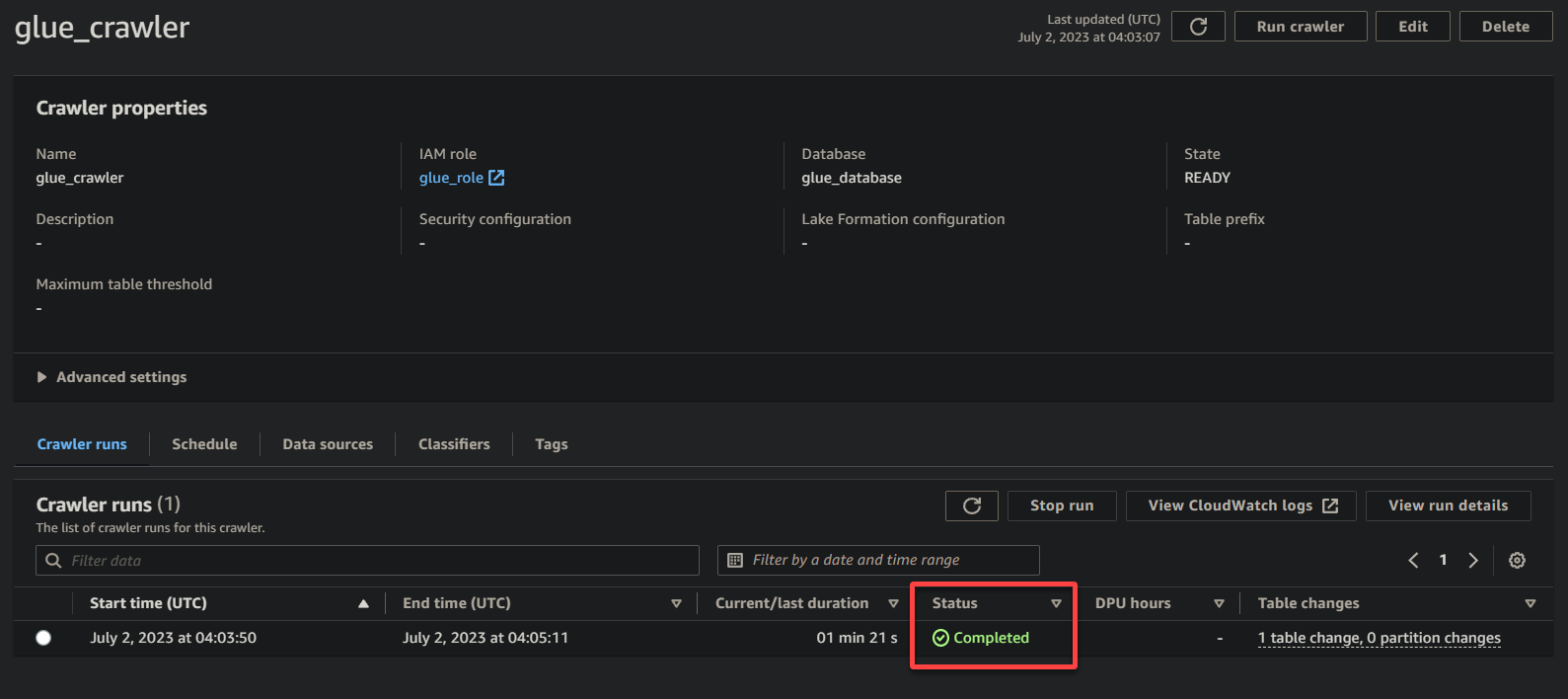
Após a conclusão da execução do crawler, o status mudará para Concluído, como mostrado abaixo. Neste ponto, você pode prosseguir com a consulta dos seus dados.
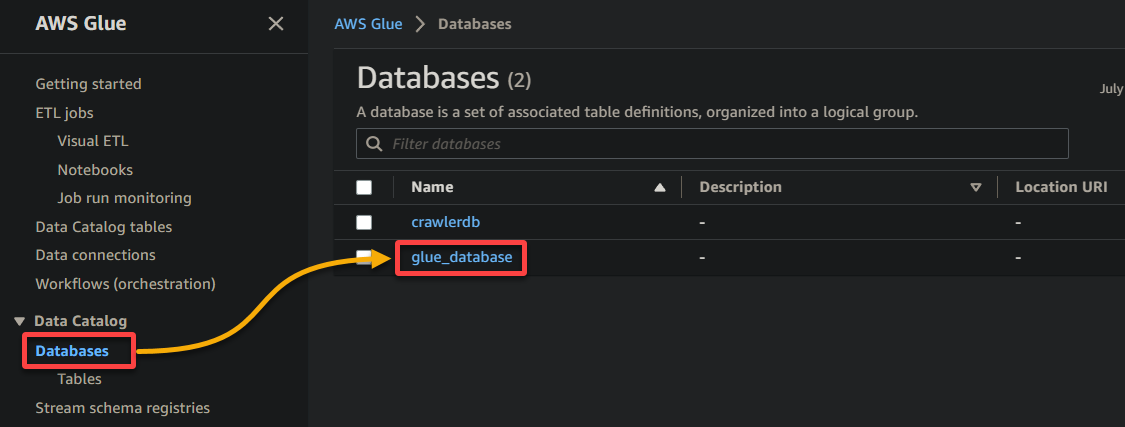
2. Em seguida, navegue até Banco de dados (painel esquerdo) e clique no seu banco de dados para acessar suas propriedades e tabelas.
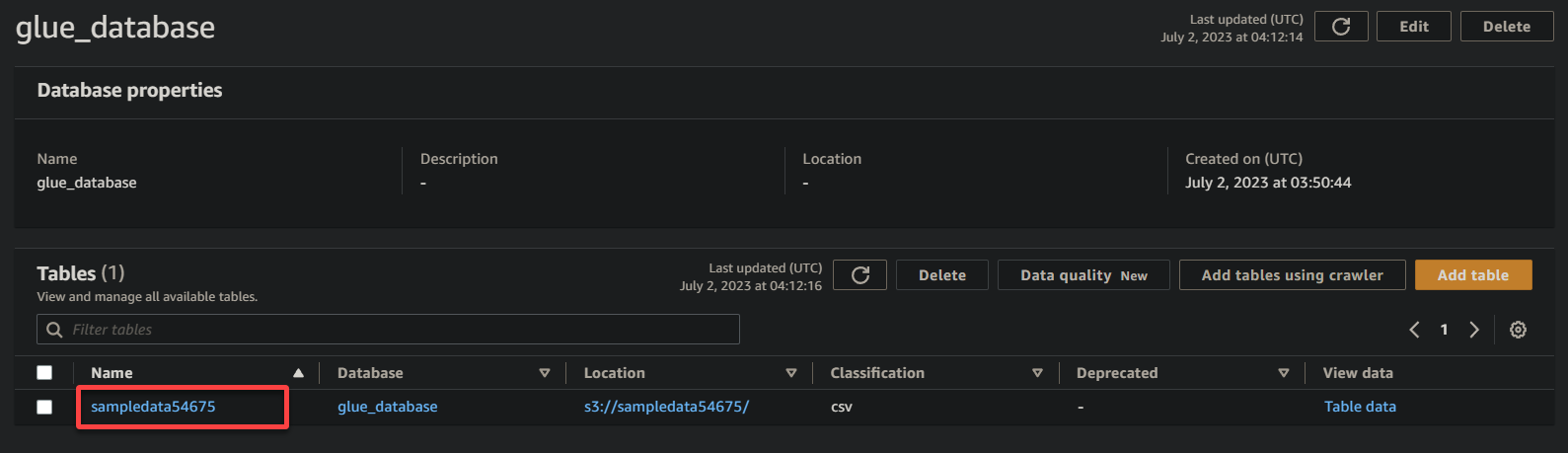
3. Por fim, clique no nome do seu bucket (sampledata54675), agora uma tabela, para visualizar os dados armazenados nele.
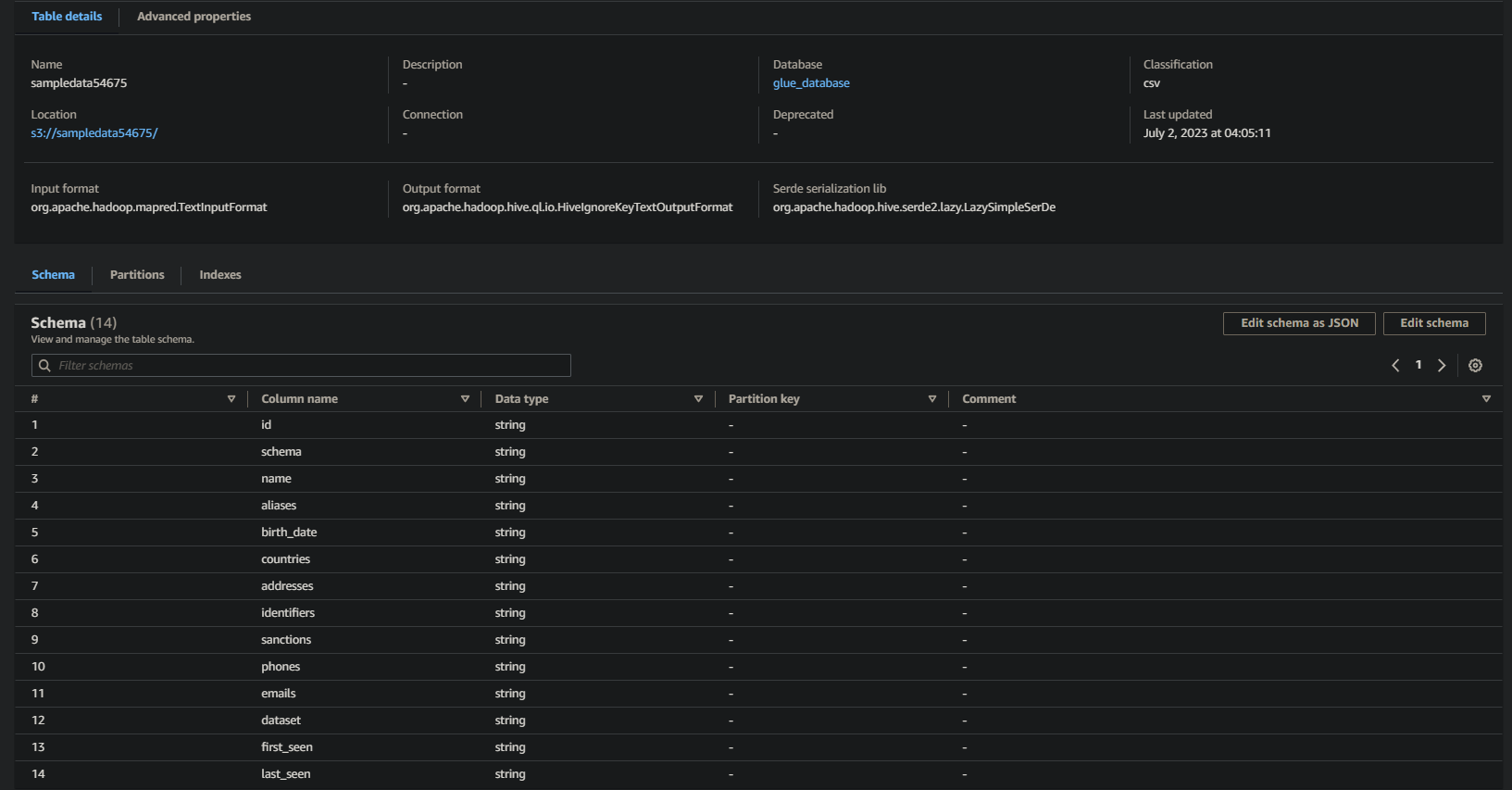
Se bem-sucedido, você verá informações semelhantes às abaixo. Essas informações confirmam que os dados foram transformados com sucesso na tabela do banco de dados, fornecendo detalhes valiosos.
Consulta de Dados Catalogados via AWS Athena
Agora que seus dados estão disponíveis no AWS Glue Data Catalog, você pode usar várias ferramentas para consultar e analisar seus dados. Uma dessas ferramentas é o AWS Athena, um serviço de consulta interativa que permite analisar dados na nuvem usando SQL padrão.
Para consultar os dados usando o AWS Athena, siga as etapas abaixo:
1. Procure e acesse o console do Athena.
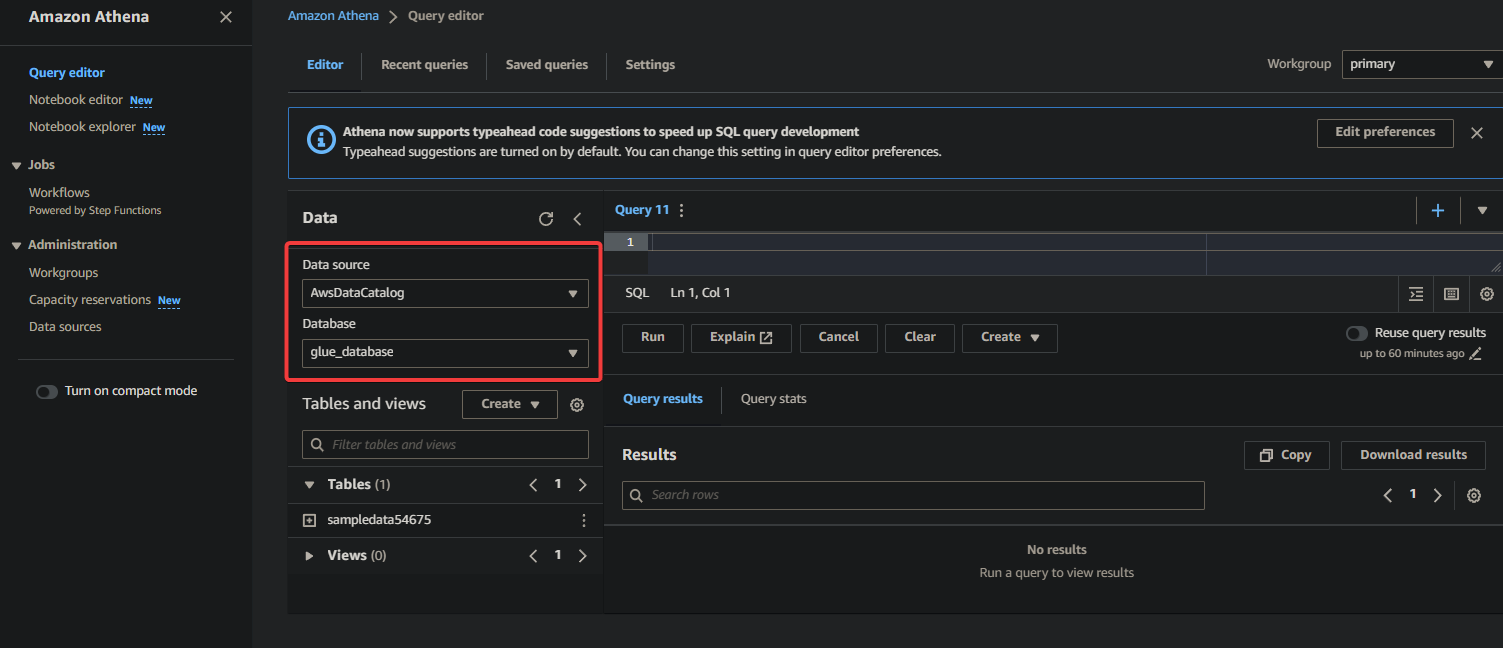
2. Selecione o banco de dados onde seus dados estão catalogados na seção Dados da seguinte forma:
- Fonte de dados – Selecione AwsDataCatalog para indicar que você deseja consultar os dados catalogados no AWS Glue.
- Banco de dados – Selecione o banco de dados apropriado no campo de seleção (ou seja, glue_database).
? Se você não encontrar o banco de dados desejado na lista suspensa, certifique-se de que o rastreador tenha concluído sua execução e catalogado os dados.
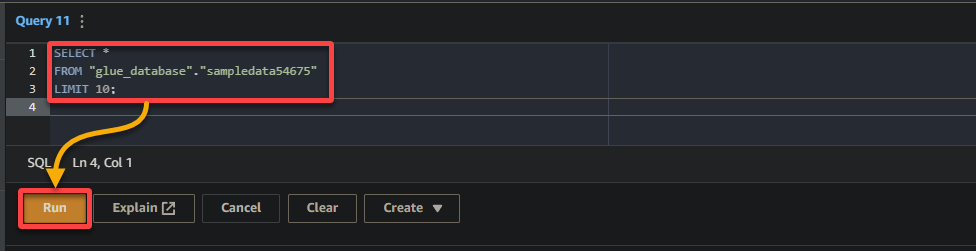
3. Por fim, preencha e execute a seguinte consulta no editor à direita.
Esta consulta retorna as primeiras 10 linhas da tabela sampledata54675 no banco de dados glue_database. Sinta-se à vontade para modificar a consulta para atender aos seus requisitos específicos.
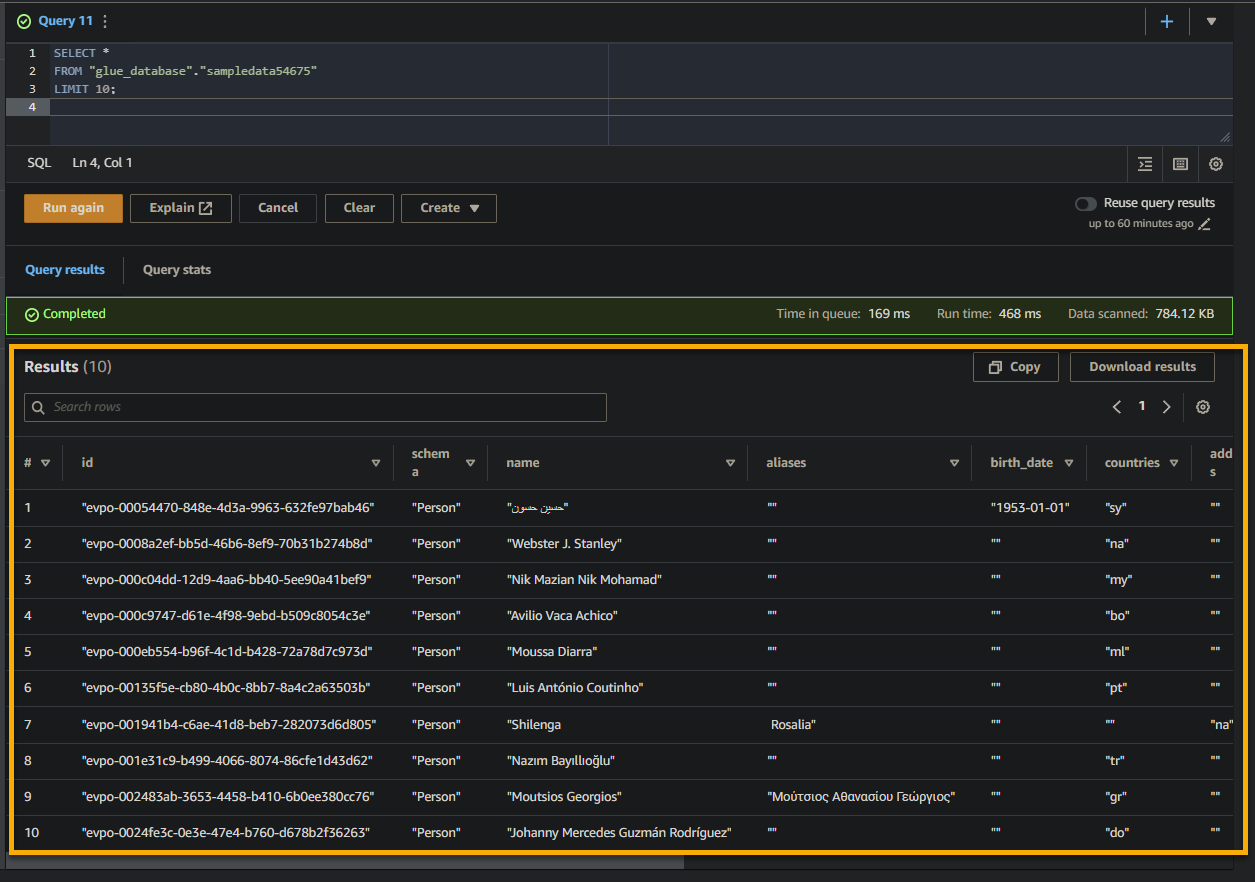
Se a consulta for bem-sucedida, você verá os resultados no painel Resultado, conforme mostrado abaixo. Os resultados contêm informações sobre os registros armazenados na tabela com base na sua consulta SQL.
Preste atenção nos nomes das colunas, nos tipos de dados e nos valores retornados no conjunto de resultados. Essas informações ajudam a entender a estrutura e o conteúdo dos dados consultados.
Conclusão
Neste tutorial, você aprendeu o básico sobre como usar o AWS Glue para criar um Crawler Glue, catalogar seus dados e consultar dados usando o AWS Athena. A preparação e análise de dados são essenciais para qualquer aplicativo orientado a dados. E ferramentas como o AWS Glue oferecem uma maneira rápida de extrair, transformar e carregar (ETL) dados de várias fontes em uma tabela de banco de dados.
Com o AWS Glue, agora você pode gerenciar e organizar rapidamente dados, permitindo que você se concentre mais na análise e na obtenção de insights a partir de seus dados. Mas o que você viu é apenas a ponta do iceberg. Explore a ampla gama de capacidades e funcionalidades que o AWS Glue pode oferecer!
Por que não aproveitar as conexões do AWS Glue para integrar perfeitamente com outros serviços da AWS, como Amazon RDS ou Amazon Redshift? Essa integração permite que você construa pipelines de ETL complexos e alcance ainda maiores capacidades de análise de dados.