













Sistemas RAG combinam o poder de mecanismos de recuperação e modelos de linguagem, permitindo-lhes gerar respostas relevantes em contexto e bem fundamentadas. No entanto, avaliar o desempenho e identificar possíveis modos de falha em sistemas RAG pode ser extremamente difícil.
Por isso, surge o Triângulo RAG – um conjunto de três métricas que abordam as três etapas principais de execução de um sistema RAG: Relevância do Contexto, Fundamentação e Relevância da Resposta. Neste post de blog, vou explorar os detalhes do Triângulo RAG e orientá-lo através do processo de configuração, execução e análise da avaliação de um sistema RAG.
Introdução ao Triângulo RAG:
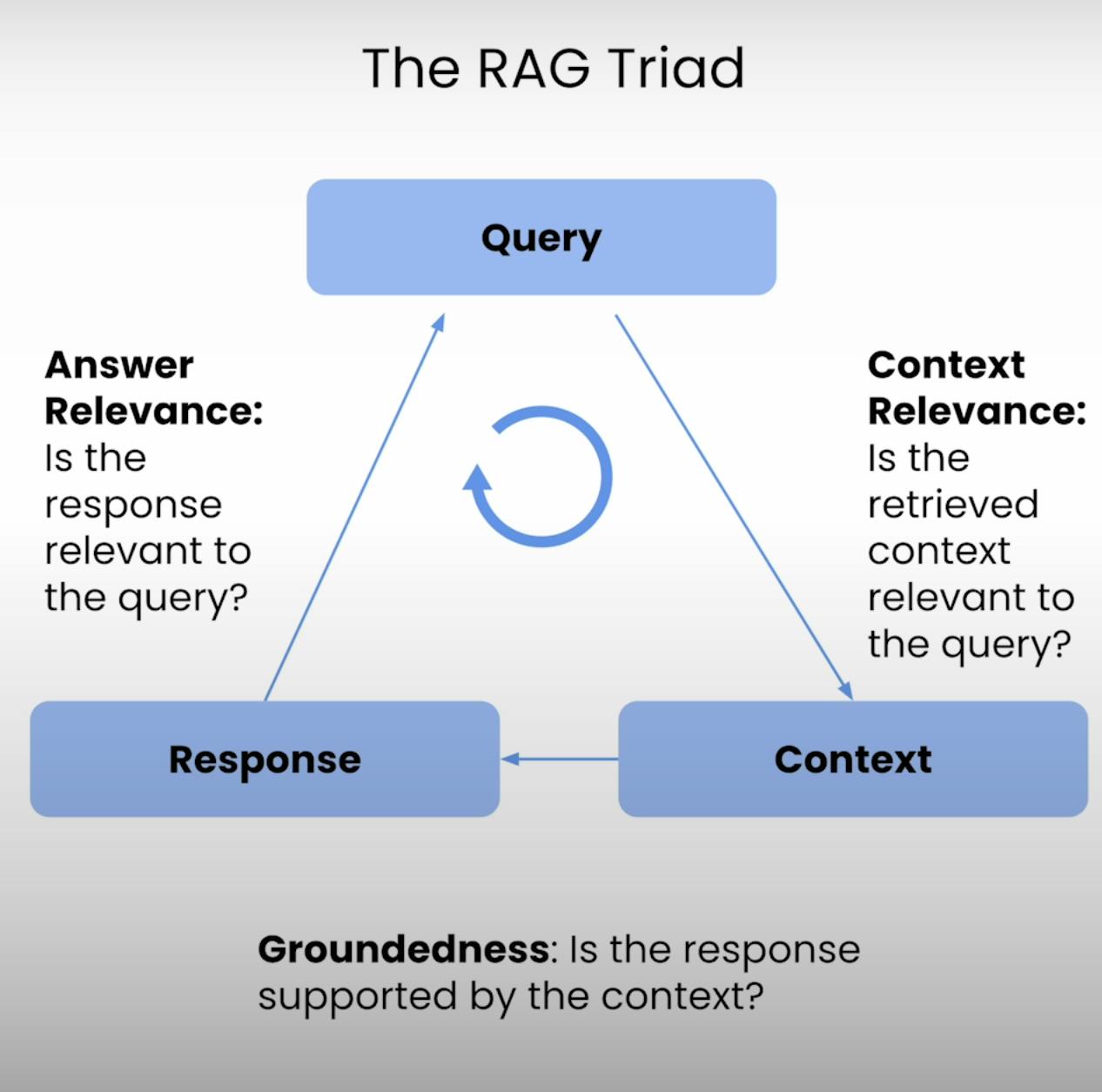
No cerne de qualquer sistema RAG reside um delicado equilíbrio entre recuperação e geração. O Triângulo RAG fornece uma estrutura abrangente para avaliar a qualidade e os possíveis modos de falha deste equilíbrio. Vamos desmembrar os três componentes.
A. Context Relevance:
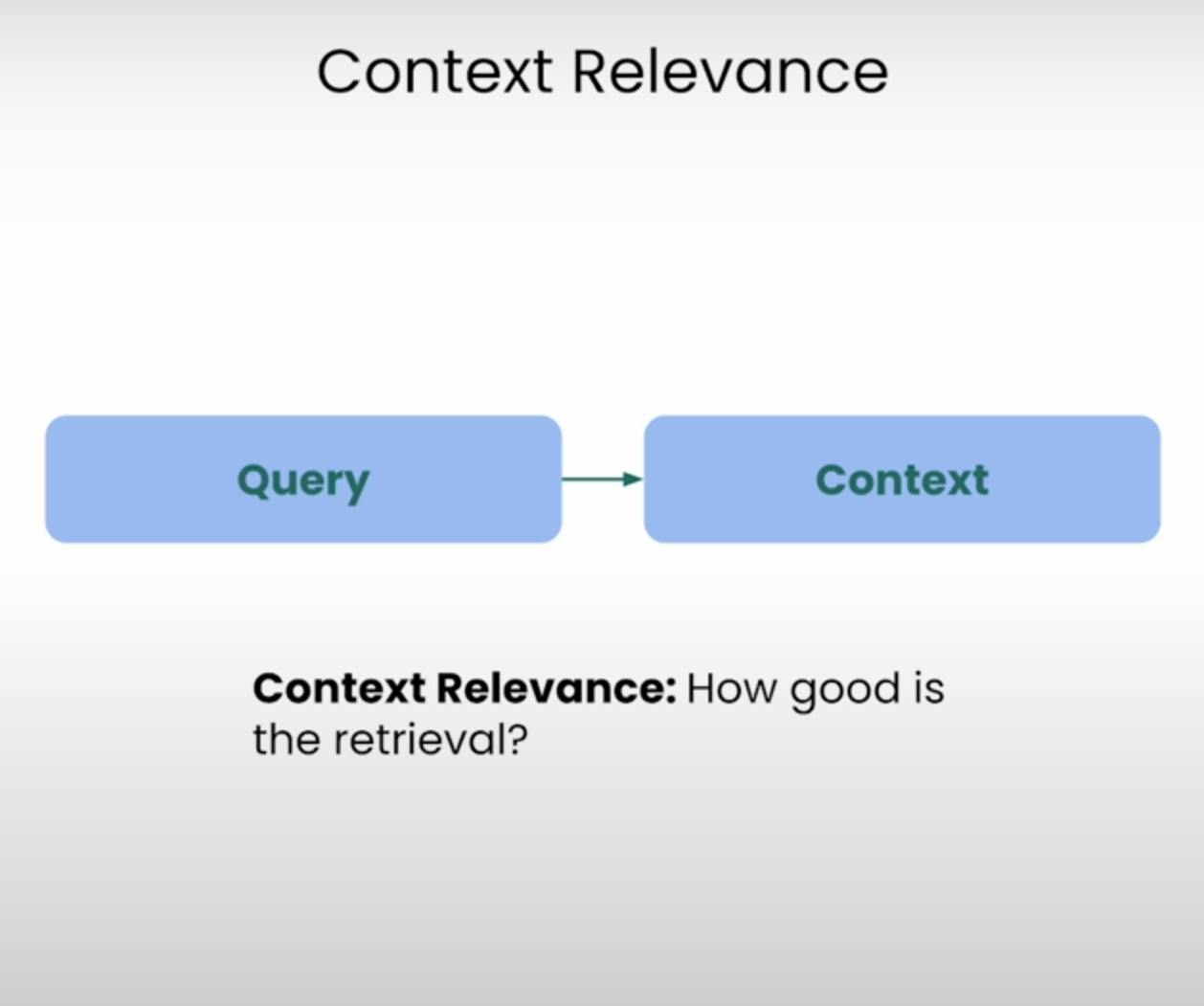
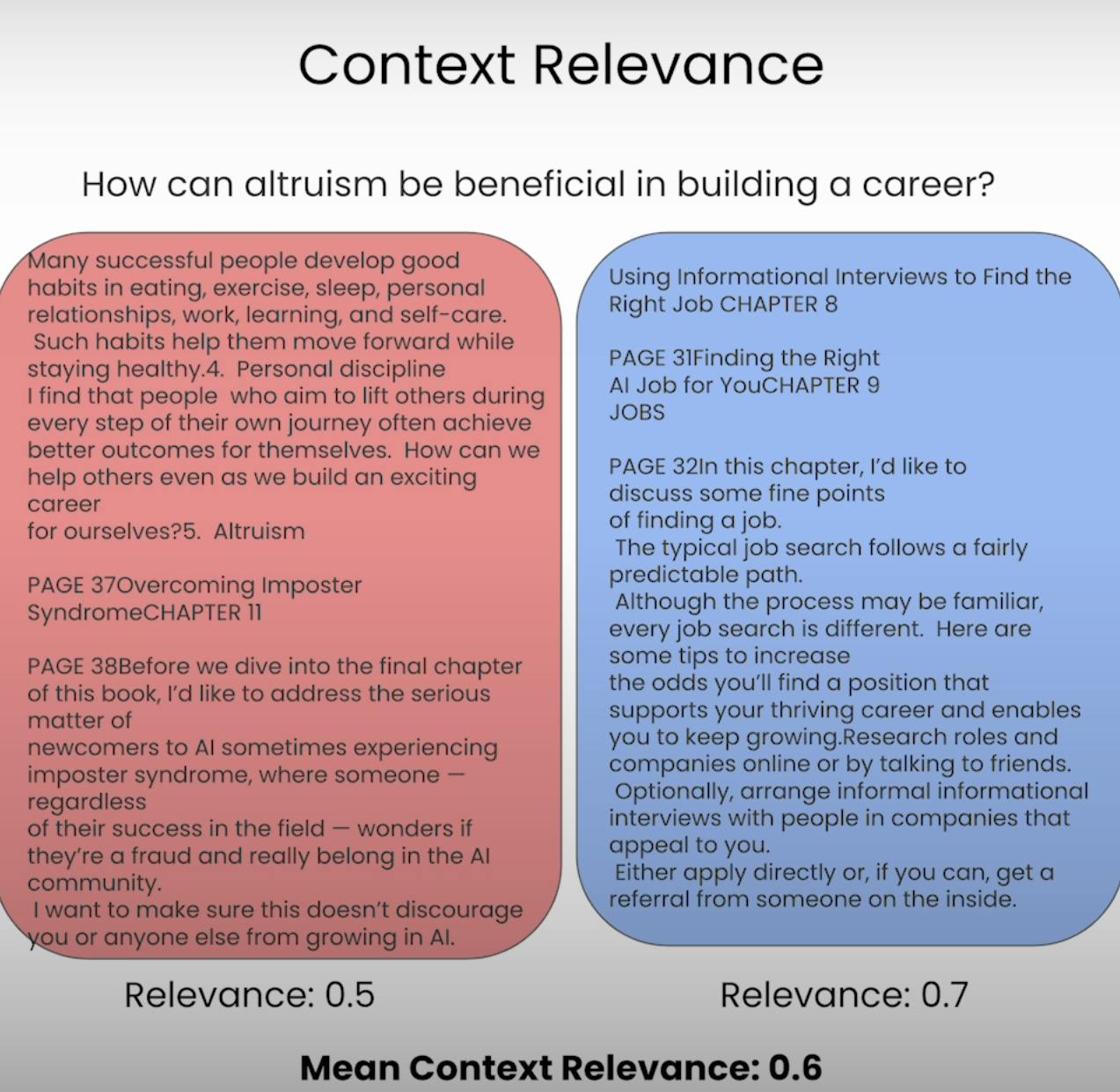
Imagine ser esperado para responder a uma pergunta, mas a informação que recebeu é completamente irrelevante. É exatamente isso que um sistema RAG busca evitar. A Relevância do Contexto avalia a qualidade do processo de recuperação, verificando a relevância de cada pedaço de contexto recuperado em relação à consulta original. Avaliando a relevância do contexto recuperado, podemos identificar potenciais problemas no mecanismo de recuperação e fazer os ajustes necessários.

B. Groundedness:
Você já teve uma conversa em que alguém parecia estar inventando fatos ou fornecendo informações sem uma base sólida? Isso é equivalente a um sistema RAG que carece de fundamentação. A fundamentação avalia se a resposta final gerada pelo sistema está bem fundamentada no contexto recuperado. Se a resposta contém afirmações ou reivindicações que não são suportadas pelas informações recuperadas, o sistema pode estar alucinando ou dependendo excessivamente de seus dados de pré-treinamento, levando a possíveis imprecisões ou vieses.
C. Answer Relevance:
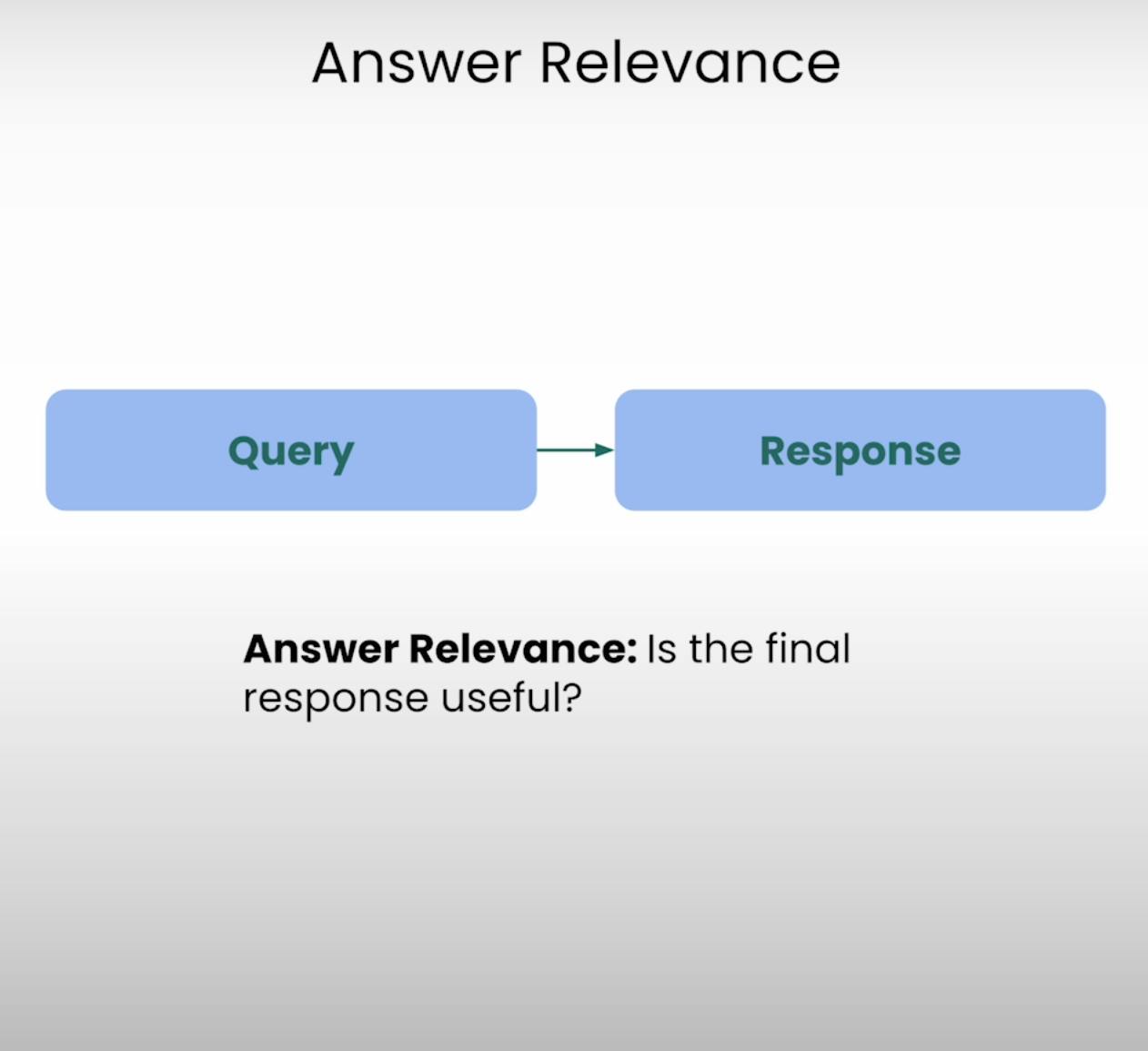
Imagine pedir orientações para o café mais próximo e receber uma receita detalhada para assar um bolo. Esse é o tipo de situação que a Relevância da Resposta visa prevenir. Este componente do Triângulo RAG avalia se a resposta final gerada pelo sistema é realmente relevante para a consulta original. Ao avaliar a relevância da resposta, podemos identificar casos em que o sistema pode ter mal interpretado a pergunta ou desviado do tópico pretendido.

Configurando a Avaliação do Triângulo RAG
Antes de mergulharmos no processo de avaliação, precisamos estabelecer as bases. Vamos percorrer os passos necessários para configurar a avaliação do Triângulo RAG.
A. Importing Libraries and Establishing API Keys:
Primeiro, precisamos importar as bibliotecas e módulos necessários, incluindo a chave de API da OpenAI e o provedor de LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
Em seguida, carregaremos e indexaremos o corpus de documentos com o qual o nosso sistema RAG trabalhará. No nosso caso, estaremos usando um documento PDF sobre “Como Construir uma Carreira no AI” de Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

No núcleo da avaliação do Triângulo RAG estão as funções de feedback – funções especializadas que avaliam cada componente do triângulo. Vamos definir essas funções usando a biblioteca TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Executando o Aplicativo e Avaliação RAG
Com a configuração completa, é hora de colocar nosso sistema RAG e o framework de avaliação em ação. Vamos percorrer os passos envolvidos na execução do aplicativo e na gravação dos resultados da avaliação.
A. Preparing the Evaluation Questions:
Primeiro, carregaremos um conjunto de perguntas de avaliação que queremos que nosso sistema RAG responda. Essas perguntas servirão como base para nosso processo de avaliação.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Em seguida, configuraremos o gravador TruLens, que nos ajudará a registrar os prompts, respostas e resultados da avaliação em um banco de dados local.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
Enquanto o aplicativo RAG é executado em cada pergunta de avaliação, o gravador TruLens capturará diligentemente os prompts, respostas, resultados intermediários e pontuações de avaliação, armazenando-os em um banco de dados local para análise posterior.
Analisando os Resultados da Avaliação
Com os dados de avaliação à nossa disposição, é hora de analisar e obter insights. Vamos ver as várias maneiras de analisar os resultados e identificar áreas potenciais para melhoria.
A. Examining Individual Record-Level Results:
Às vezes, o demônio está nos detalhes. Examinando os resultados em nível de registro individual, podemos obter uma compreensão mais profunda das forças e fraquezas do nosso sistema RAG.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Este trecho de código nos dá acesso aos prompts, respostas e pontuações de avaliação para cada registro individual, permitindo-nos identificar instâncias específicas em que o sistema pode ter enfrentado dificuldades ou se destacado.
B. Viewing Aggregate Performance Metrics:
Vamos dar um passo atrás e analisar o panorama geral. A biblioteca TrueLens nos fornece um quadro de liderança que agrega as métricas de desempenho em todos os registros, oferecendo uma visão de alto nível do desempenho geral do nosso sistema RAG.
tru.get_leaderboard(app_ids=[])
Este quadro de liderança exibe as pontuações médias para cada componente do Triângulo RAG, juntamente com métricas como latência e custo. Ao analisar essas métricas agregadas, podemos identificar tendências e padrões que podem não ser evidentes no nível do registro.
C. Exploring the TrueLens Streamlit Dashboard:
Além do CLI, a TrueLens também oferece um painel Streamlit que fornece uma GUI para explorar e analisar os resultados da avaliação. Com alguns comandos simples, podemos lançar o painel.
tru.run_dashboard()
Uma vez que o painel está funcionando, temos uma visão abrangente do desempenho do nosso sistema RAG. De relance, podemos ver as métricas agregadas para cada componente do Triângulo RAG, bem como informações sobre latência e custo.
Ao selecionar nosso aplicativo no menu suspenso, podemos acessar uma visão detalhada do nível do registro dos resultados da avaliação. Cada registro é exibido de forma organizada, incluindo o prompt de entrada do usuário, a resposta do sistema RAG e as pontuações correspondentes para Relevância da Resposta, Relevância do Contexto e Fundamentação.
Ao clicar em um registro individual, obtemos mais insights. Podemos explorar a cadeia de raciocínio por trás de cada pontuação de avaliação, explicando o processo de pensamento do modelo de linguagem que realiza a avaliação. Este nível de transparência é útil para identificar possíveis modos de falha e áreas para melhoria.
Vamos supor que encontramos um registro onde a pontuação de Groundedness é baixa. Ao analisar os detalhes, podemos descobrir que a resposta do sistema RAG contém declarações que não estão bem enraizadas no contexto recuperado. O dashboard nos mostrará exatamente quais declarações carecem de evidências de apoio, permitindo-nos identificar a causa raiz do problema.
O dashboard TrueLens Streamlit é mais do que apenas uma ferramenta de visualização. Ao utilizar suas capacidades interativas e insights orientados por dados, podemos tomar decisões informadas e adotar ações direcionadas para melhorar o desempenho de nossas aplicações.
Técnicas Avançadas de RAG e Melhoria Iterativa
A. Introducing the Sentence Window RAG Technique:
Uma técnica avançada é o RAG de Janela de Sentença, que aborda um modo de falha comum dos sistemas RAG: tamanho de contexto limitado. Ao aumentar o tamanho da janela de contexto, o RAG de Janela de Sentença visa fornecer ao modelo de linguagem mais informações relevantes e abrangentes, potencialmente melhorando a Relevância do Contexto e a Groundedness do sistema.
B. Re-evaluating with the RAG Triad:
Após implementar a técnica de RAG de Janela de Sentença, podemos testá-la novamente avaliando-a usando o mesmo framework RAG Triad. Desta vez, focaremos nossa atenção nas pontuações de Relevância do Contexto e Groundedness, procurando melhorias nessas áreas como resultado do aumento do tamanho do contexto.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Embora a técnica de RAG de Janela de Sentença possa potencialmente melhorar o desempenho, o tamanho ideal da janela pode variar dependendo do caso de uso específico e do conjunto de dados. Uma janela pequena pode não fornecer o suficiente de contexto relevante, enquanto uma janela muito grande poderia introduzir informações irrelevantes, afetando a Groundedness e a Relevância das Respostas do sistema.
Ao experimentar com diferentes tamanhos de janela e reavaliar usando o Triângulo RAG, podemos encontrar o ponto ideal que equilibra a relevância do contexto com a fundamentação e a relevância da resposta, levando a um sistema RAG mais robusto e confiável.
Conclusão:
O Triângulo RAG, composto por Relevância do Contexto, Fundamentação e Relevância da Resposta, mostrou-se uma estrutura útil para avaliar o desempenho e identificar possíveis modos de falha em sistemas de Geração Aumentada por Recuperação.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems