













In de beginjaren van de computer werden taken sequentieel afgehandeld. Naarmate de schaal groeide met miljoenen gebruikers, werd deze aanpak onpraktisch. Asynchrone verwerking maakte het mogelijk om meerdere taken gelijktijdig af te handelen, maar het beheren van threads/processen op één machine leidde tot beperkingen en complexiteit.
Hier komt gedistribueerde parallelle verwerking om de hoek kijken. Door de werklast over meerdere machines te verdelen, elk toegewijd aan een deel van de taak, biedt het een schaalbare en efficiënte oplossing. Als je een functie hebt om een grote batch bestanden te verwerken, kun je de werklast verdelen over meerdere machines om bestanden gelijktijdig te verwerken in plaats van ze sequentieel op één machine af te handelen. Bovendien verbetert het de prestaties door gebruik te maken van gecombineerde middelen en biedt het schaalbaarheid en fouttolerantie. Naarmate de eisen toenemen, kun je meer machines toevoegen om de beschikbare middelen te vergroten.
Het is uitdagend om gedistribueerde toepassingen op schaal te bouwen en uit te voeren, maar er zijn verschillende frameworks en tools om je hierbij te helpen. In deze blogpost zullen we één zo’n open-source gedistribueerd computerframework bekijken: Ray. We zullen ook kijken naar KubeRay, een Kubernetes-operator die naadloze integratie van Ray met Kubernetes-clusters mogelijk maakt voor gedistribueerde berekeningen in cloud-native omgevingen. Maar laten we eerst begrijpen waar gedistribueerde parallelisme van pas komt.
Waar helpt gedistribueerde parallelle verwerking?
Elke taak die profiteert van het splitsen van de werklast over meerdere machines kan gebruikmaken van gedistribueerde parallelle verwerking. Deze benadering is bijzonder nuttig voor scenario’s zoals webcrawlen, grootschalige data-analyse, training van machine learning-modellen, real-time stroomverwerking, genomische data-analyse en videorendering. Door taken over meerdere knooppunten te verdelen, verbetert gedistribueerde parallelle verwerking de prestaties aanzienlijk, verkort het de verwerkingstijd en optimaliseert het het gebruik van middelen, waardoor het essentieel is voor toepassingen die een hoge doorvoer en snelle gegevensverwerking vereisen.
Wanneer Gedistribueerde Parallelle Verwerking Niet Nodig Is
- Kleine toepassingen: Voor kleine datasets of toepassingen met minimale verwerkingsvereisten is de overhead van het beheren van een gedistribueerd systeem mogelijk niet gerechtvaardigd.
- Sterke datadependenties: Als taken sterk onderling afhankelijk zijn en niet gemakkelijk kunnen worden parallel verwerkt, biedt gedistribueerde verwerking mogelijk weinig voordeel.
- Real-time beperkingen: Sommige real-time toepassingen (bijv. financiën en ticketboekingswebsites) vereisen extreem lage latentie, wat mogelijk niet haalbaar is met de extra complexiteit van een gedistribueerd systeem.
- Beperkte middelen: Als de beschikbare infrastructuur de overhead van een gedistribueerd systeem niet kan ondersteunen (bijv. onvoldoende netwerkbandbreedte, beperkt aantal knooppunten), kan het beter zijn om de prestaties van een enkele machine te optimaliseren.
Hoe Ray Helpt Met Gedistribueerde Parallelle Verwerking
Ray is een gedistribueerd parallel verwerkingsraamwerk dat alle voordelen van gedistribueerd computergebruik en oplossingen voor de uitdagingen die we hebben besproken, zoals fouttolerantie, schaalbaarheid, contextbeheer, communicatie, enzovoort, omvat. Het is een Pythonisch raamwerk, dat het gebruik van bestaande bibliotheken en systemen mogelijk maakt. Met de hulp van Ray hoeft een programmeur zich geen zorgen te maken over de onderdelen van de parallelle verwerkingslaag. Ray zorgt voor de planning en autoscaling op basis van de opgegeven resourcevereisten.
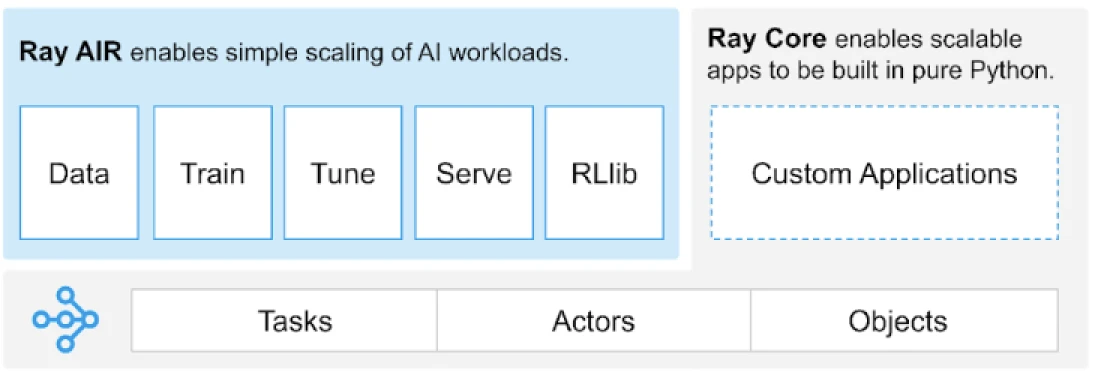
Ray biedt een universele API van taken, actoren en objecten voor het bouwen van gedistribueerde applicaties.
(Afbeeldingsbron)
Ray biedt een set bibliotheken die zijn gebouwd op de kernprimitive, d.w.z. Taken, Actoren, Objecten, Stuurprogramma’s en Taken. Deze bieden een veelzijdige API om te helpen bij het bouwen van gedistribueerde applicaties. Laten we eens kijken naar de kernprimitive, ook wel Ray Core genoemd.
Ray Core Primitive
- Taken: Ray-taken zijn willekeurige Python-functies die asynchroon worden uitgevoerd op afzonderlijke Python-werkers op een Ray-clusterknoop. Gebruikers kunnen hun hulpbronnenvereisten specificeren in termen van CPU’s, GPU’s en aangepaste hulpbronnen, die door de clusterplanner worden gebruikt om taken te verdelen voor parallelle uitvoering.
- Actoren: Wat taken zijn voor functies, zijn actoren voor klassen. Een acteur is een staatvolle werker, en de methoden van een acteur worden gepland op die specifieke werker en kunnen de staat van die werker benaderen en veranderen. Net als taken ondersteunen actoren CPU-, GPU- en aangepaste hulpbronnenvereisten.
- Objecten: In Ray creëren en berekenen taken en actoren objecten. Deze externe objecten kunnen overal in een Ray-cluster worden opgeslagen. Objectreferenties worden gebruikt om naar hen te verwijzen, en ze worden gecached in de gedistribueerde gedeelde geheugenobjectopslag van Ray.
- Drivers: De programmaroot, of het “hoofd” programma: dit is de code die
ray.init()uitvoert. - Jobs: De verzameling van taken, objecten en actoren die (recursief) afkomstig zijn van dezelfde driver en hun runtime-omgeving.
Voor informatie over primitieve elementen kunt u de Ray Core-documentatie doorlezen.
Belangrijke methoden van Ray Core
Hieronder staan enkele van de belangrijkste methoden binnen Ray Core die vaak worden gebruikt:
-
ray.init()– Start de Ray-runtime en maak verbinding met het Ray-cluster.import ray ray.init()
-
@ray.remote– Decorator die aangeeft dat een Python-functie of -klasse moet worden uitgevoerd als een taak (remote functie) of acteur (remote klasse) in een ander proces@ray.remote def remote_function(x): return x * 2
-
.remote– Postfix voor de remote functies en klassen; remote bewerkingen zijn asynchroonresult_ref = remote_function.remote(10)
-
ray.put()– Plaats een object in de in-memory object store; retourneert een objectreferentie die wordt gebruikt om het object door te geven aan elke remote functie of methodeoproep.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Haal een remote object(en) op uit de object store door de objectreferentie(s) op te geven.result = ray.get(result_ref) original_data = ray.get(data_ref)
Hier is een voorbeeld van het gebruik van de meeste basisfuncties:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Het gebruik van .remote om een taak te maken
future = calculate_square.remote(5)
# Haal het resultaat op
result = ray.get(future)
print(f"The square of 5 is: {result}")Hoe werkt Ray?
Een Ray-cluster is als een team van computers dat het werk van het uitvoeren van een programma deelt. Het bestaat uit een hoofdknoop en meerdere werkknopen. De hoofdknoop beheert de clusterstatus en planning, terwijl werkknopen taken uitvoeren en actoren beheren
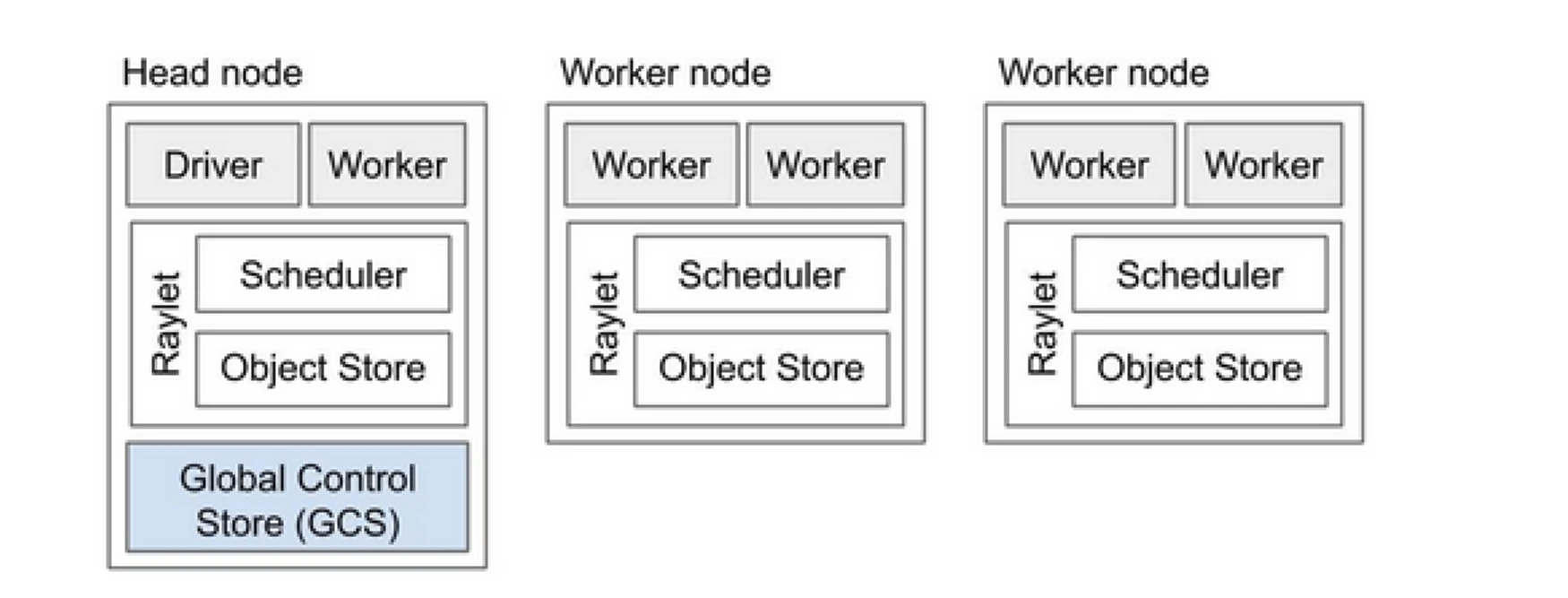
Componenten van Ray-cluster
- Global Control Store (GCS): De GCS beheert de metadata en de wereldwijde status van de Ray-cluster. Het volgt taken, actoren en beschikbaarheid van resources bij, zodat alle knopen een consistente weergave van het systeem hebben.
- Scheduler: De scheduler verdeelt taken en actoren over beschikbare knopen. Het zorgt voor efficiënt gebruik van resources en het balanceren van de belasting door resourcevereisten en taakafhankelijkheden in overweging te nemen.
- Hoofdknoop: De hoofdknoop regelt de hele Ray-cluster. Het draait de GCS, behandelt taakplanning en bewaakt de gezondheid van werknodes.
- Werkknopen: Werkknopen voeren taken en actoren uit. Ze voeren de daadwerkelijke berekeningen uit en slaan objecten op in hun lokale geheugen.
- Raylet: Het beheert gedeelde resources op elke knoop en wordt gedeeld tussen alle gelijktijdig draaiende taken.
Je kunt de Ray v2 Architecture-doc bekijken voor meer gedetailleerde informatie.
Werken met bestaande Python-toepassingen vereist niet veel veranderingen. De benodigde wijzigingen zouden voornamelijk betrekking hebben op de functie of klasse die natuurlijk moet worden gedistribueerd. U kunt een decorator toevoegen en deze omzetten in taken of actoren. Laten we een voorbeeld hiervan bekijken.
Een Python-functie converteren naar een Ray-taak
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Een Python-klasse converteren naar een Ray-actor
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Informatie opslaan in Ray-objecten
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Om meer te weten te komen over het concept, ga naar de documenten over Ray Core Key Concept.
Ray versus de traditionele benadering van gedistribueerde parallelle verwerking
Hieronder volgt een vergelijkende analyse tussen de traditionele (zonder Ray) benadering en Ray op Kubernetes om gedistribueerde parallelle verwerking mogelijk te maken.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Implementatie | Handmatige setup en configuratie | Geautomatiseerd met KubeRay Operator |
| Schalen | Handmatig schalen | Automatisch schalen met RayAutoScaler en Kubernetes |
| Fouttolerantie | Aangepaste fouttolerantiemechanismen | Ingebouwde fouttolerantie met Kubernetes en Ray |
| Resourcebeheer | Handmatige toewijzing van resources | Geautomatiseerde resource-toewijzing en beheer |
| Load Balancing | Aangepaste load-balancing oplossingen | Ingebouwde load balancing met Kubernetes |
| Afhankelijkheidsbeheer | Handmatige installatie van afhankelijkheden | Consistente omgeving met Docker-containers |
| Clustercoördinatie | Complex en handmatig | Vereenvoudigd met Kubernetes service discovery en coördinatie |
| Ontwikkelingslasten | Hoog, met aangepaste oplossingen nodig | Verminderd, met Ray en Kubernetes die veel aspecten afhandelen |
| Flexibiliteit | Beperkte aanpassingsmogelijkheden aan veranderende werkbelastingen | Hoge flexibiliteit met dynamische schaalvergroting en resourceallocatie |
Kubernetes biedt een ideaal platform voor het draaien van gedistribueerde applicaties zoals Ray vanwege de robuuste orkestratiemogelijkheden. Hieronder staan de belangrijkste punten die de waarde van het draaien van Ray op Kubernetes benadrukken:
- Resourcebeheer
- Schaalbaarheid
- Orkestratie
- Integratie met ecosysteem
- Eenvoudige implementatie en beheer
KubeRay Operator maakt het mogelijk om Ray op Kubernetes te draaien.
Wat is KubeRay?
De KubeRay Operator vereenvoudigt het beheer van Ray-clusters op Kubernetes door taken zoals implementatie, schaling en onderhoud te automatiseren. Het gebruikt Kubernetes Custom Resource Definitions (CRD’s) om Ray-specifieke resources te beheren.
KubeRay CRD’s
Het heeft drie verschillende CRD’s:
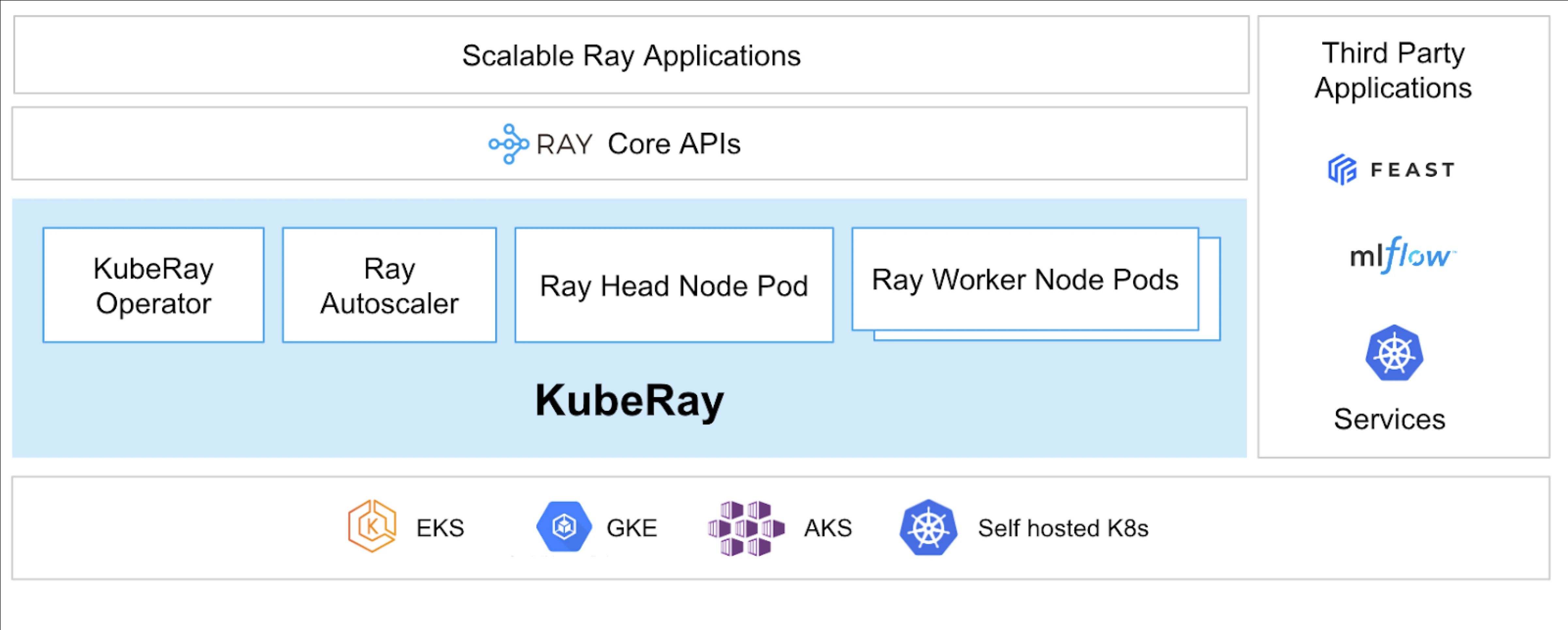
- RayCluster: Deze CRD helpt bij het beheren van de levenscyclus van RayCluster en zorgt voor AutoScaling op basis van de gedefinieerde configuratie.
- RayJob: Het is handig wanneer er een eenmalige taak is die u wilt uitvoeren in plaats van een standby RayCluster constant te laten draaien. Het maakt een RayCluster aan en dient de taak in wanneer deze gereed is. Zodra de taak is voltooid, verwijdert het de RayCluster. Dit helpt bij het automatisch recyclen van de RayCluster.
- RayService: Dit maakt ook een RayCluster aan, maar implementeert een RayServe-toepassing erop. Deze CRD maakt het mogelijk om in-place updates van de toepassing uit te voeren, waardoor upgrades en updates zonder downtime mogelijk zijn om de hoge beschikbaarheid van de toepassing te garanderen.
Gebruiksscenario’s van KubeRay
Het implementeren van een on-demand model met behulp van RayService
RayService stelt u in staat om modellen on-demand in een Kubernetes-omgeving te implementeren. Dit kan met name handig zijn voor toepassingen zoals afbeeldingsgeneratie of tekstextractie, waar modellen alleen worden geïmplementeerd wanneer dat nodig is.
Hier is een voorbeeld van stabiele diffusie. Zodra het wordt toegepast in Kubernetes, zal het een RayCluster creëren en ook een RayService uitvoeren, die het model zal bedienen totdat u deze resource verwijdert. Het stelt gebruikers in staat om controle te hebben over resources.
Het trainen van een model op een GPU-cluster met behulp van RayJob
RayService voldoet aan verschillende eisen van de gebruiker, waarbij het model of de toepassing wordt ingezet totdat het handmatig wordt verwijderd. In tegenstelling hiermee maakt RayJob eenmalige taken mogelijk voor gebruiksscenario’s zoals het trainen van een model, het voorverwerken van gegevens of inferentie voor een vast aantal gegeven prompts.
Voer Inferentie Server uit op Kubernetes met behulp van RayService of RayJob
Gewoonlijk draaien we onze toepassing in Deployments, die de continue updates onderhouden zonder downtime. Op dezelfde manier kan dit in KubeRay worden bereikt met behulp van RayService, dat het model of de toepassing implementeert en de continue updates afhandelt.
Er kunnen echter gevallen zijn waarin u gewoon batchinferentie wilt uitvoeren in plaats van de inferentieservers of toepassingen lange tijd te laten draaien. Dit is waar u RayJob kunt gebruiken, dat vergelijkbaar is met de Kubernetes Job-resource.
Beeldclassificatie Batch Inferentie met Huggingface Vision Transformer is een voorbeeld van RayJob, dat Batch Inferentie uitvoert.
Dit zijn de gebruiksscenario’s van KubeRay, waardoor u meer kunt doen met de Kubernetes-cluster. Met behulp van KubeRay kunt u gemengde workloads uitvoeren op dezelfde Kubernetes-cluster en werklastplanning voor op GPU’s gebaseerde workloads uitbesteden aan Ray.
Conclusie
Gedistrueerde parallelle verwerking biedt een schaalbare oplossing voor het verwerken van grootschalige, hulpbronnenintensievere taken. Ray vereenvoudigt de complexiteit van het bouwen van gedistribueerde toepassingen, terwijl KubeRay Ray integreert met Kubernetes voor naadloze implementatie en schaling. Deze combinatie verbetert de prestaties, schaalbaarheid en fouttolerantie, waardoor het ideaal is voor webcrawling, data-analyse en machine learning-taken. Door gebruik te maken van Ray en KubeRay kunt u efficiënt gedistribueerde computing beheren en voldoen aan de eisen van de data-gedreven wereld van vandaag met gemak.
Niet alleen dat, maar naarmate onze computebronnen veranderen van CPU naar GPU-gebaseerd, wordt het belangrijk om een efficiënte en schaalbare cloudinfrastructuur te hebben voor allerlei toepassingen, of het nu AI of grootschalige gegevensverwerking betreft.
Als u deze post informatief en boeiend vond, hoor ik graag uw gedachten hierover, dus begin een gesprek op LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray