













Wil het management alles weten over de financiën en productiviteit van uw bedrijf, maar wil het geen cent uitgeven aan eersteklas IT-beheertools? Beland niet in de situatie waarin u verschillende tools gebruikt voor inventaris, facturering en ticketingsystemen. U heeft slechts één centraal systeem nodig. Waarom overweegt u niet Power BI Python?
Power BI kan saaie en tijdrovende taken omzetten in geautomatiseerde processen. En in deze tutorial leert u hoe u uw gegevens op manieren kunt slicen en combineren die u zich niet kunt voorstellen.
Kom op en bespaar uzelf de stress van het doorzoeken van complexe rapporten!
Vereisten
Deze tutorial zal een praktische demonstratie zijn. Als u wilt meedoen, zorg er dan voor dat u het volgende heeft:
- Power BI-abonnement – De gratis proefversie volstaat.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop geïnstalleerd op uw Windows Server – Deze tutorial maakt gebruik van Power BI Desktop v2.105.664.0.
- MySQL Server geïnstalleerd – Deze tutorial maakt gebruik van MySQL Server v8.0.29.
- Een on-premises data gateway geïnstalleerd op externe apparaten die van plan zijn om een Desktop-versie te gebruiken.
- Visual Studio Code (VS Code) – Deze tutorial maakt gebruik van VS Code v17.2
- Python v3.6 of later geïnstalleerd – Deze tutorial maakt gebruik van Python v3.10.5.
- DBeaver geïnstalleerd – Deze tutorial maakt gebruik van DBeaver v22.0.2.
Het bouwen van een MySQL-database
Power BI kan gegevens prachtig visualiseren, maar je moet deze ophalen en opslaan voordat je bij de visualisatie van de gegevens komt. Een van de beste manieren om gegevens op te slaan is in een database. MySQL is een gratis en krachtige database-tool.
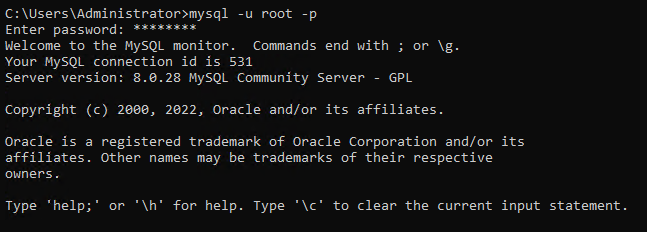
1. Open opdrachtprompt als administrator, voer de onderstaande mysql-opdracht uit en voer de rootgebruikersnaam (-u) en het wachtwoord (-p) in wanneer daarom wordt gevraagd.
Standaard heeft alleen de rootgebruiker toestemming om wijzigingen in de database aan te brengen.
2. Voer vervolgens de onderstaande query uit om een nieuwe databasegebruiker (CREATE USER) met een wachtwoord (IDENTIFIED BY) aan te maken. Je kunt de gebruiker anders noemen, maar de keuze in deze handleiding is ata_levi.

3. Nadat je een gebruiker hebt aangemaakt, voer je de onderstaande query uit om de nieuwe gebruiker machtigingen te verlenen (ALLE PRIVILEGES), zoals het maken van een database op de server.

4. Voer nu het \q commando hieronder uit om uit te loggen bij MySQL.

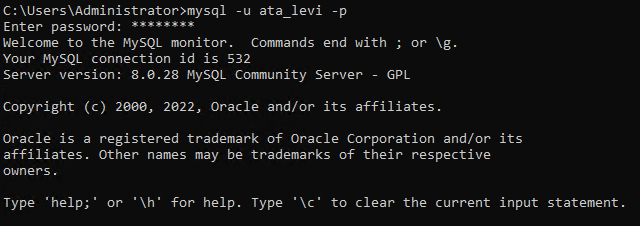
5. Voer de onderstaande mysql-opdracht uit om in te loggen als de nieuw aangemaakte databasegebruiker (ata_levi).
6. Als laatste voer je de volgende query uit om een nieuwe DATABASE genaamd ata_database aan te maken. Maar natuurlijk kun je de database anders noemen.

Het beheren van MySQL-databases met DBeaver
Bij het beheren van databases heb je meestal SQL-kennis nodig. Maar met DBeaver heb je een GUI om je databases in een paar klikken te beheren, en DBeaver zal de SQL-opdrachten voor je uitvoeren.
1. Open DBeaver vanaf je bureaublad of het Startmenu.
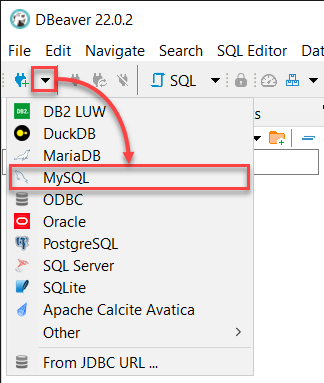
2. Wanneer DBeaver opent, klik dan op de dropdown Nieuwe Databaseverbinding en selecteer MySQL om verbinding te maken met je MySQL-server.
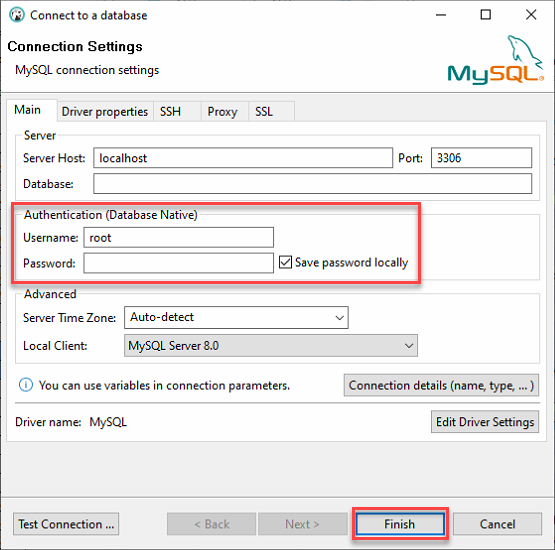
3. Log in op je lokale MySQL-server met het volgende:
- Houd de Serverhost als localhost en de Poort op 3306 aangezien je verbinding maakt met een lokale server.
- Voorzie de inloggegevens (Gebruikersnaam en Wachtwoord) van de ata_levi-gebruiker uit stap twee van de sectie “Een MySQL-database bouwen” en klik op Voltooien om in te loggen bij MySQL.
4. Breid nu je database (ata_database) uit onder de Database Navigator (linkerpaneel) → klik met de rechtermuisknop op Tabellen en selecteer Nieuwe tabel maken om het maken van een nieuwe tabel te starten.
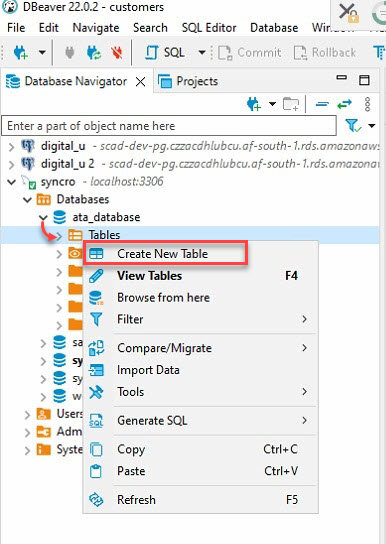
5. Geef je nieuwe tabel een naam, maar de keuze in deze tutorial is ata_Table, zoals hieronder weergegeven.
Zorg ervoor dat de tabelnaam overeenkomt met de tabelnaam die je zult specificeren in de to_sql (“Tabelnaam”) methode in stap zeven van de sectie “API-gegevens verkrijgen en consumeren”.
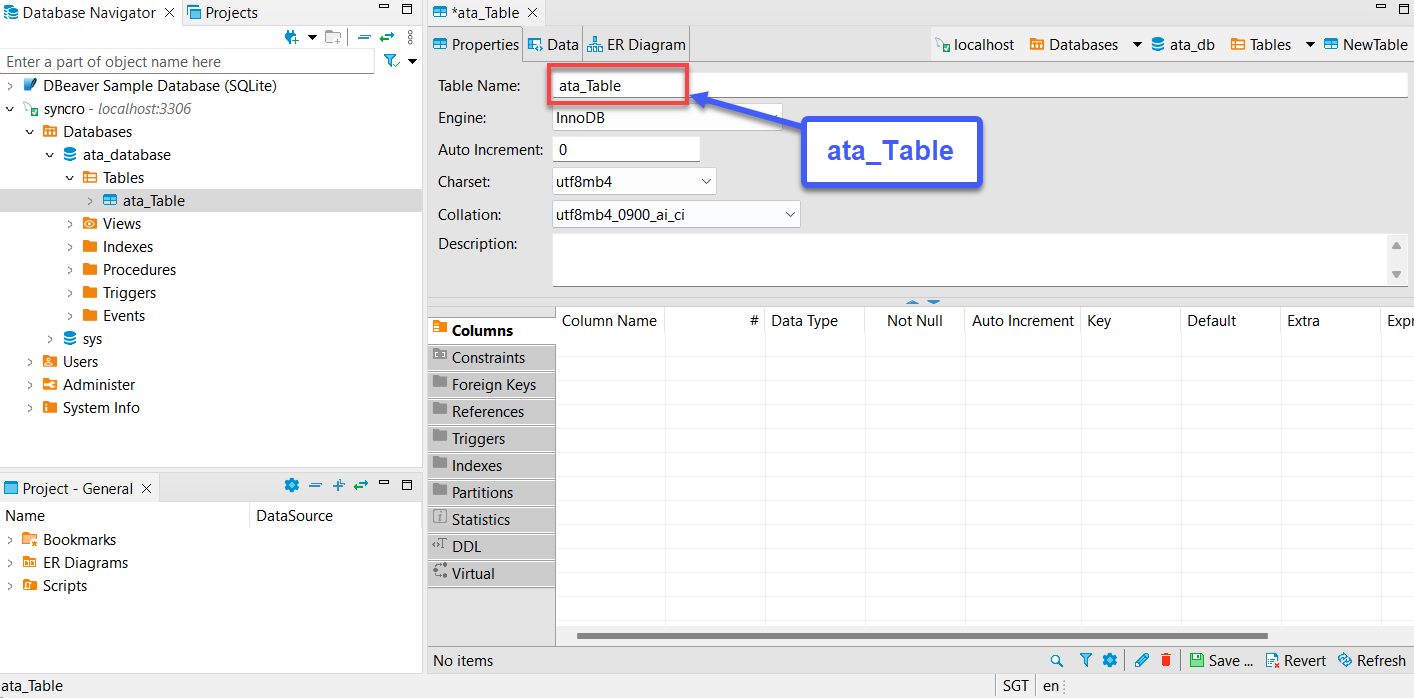
6. Breid vervolgens de nieuwe tabel (ata_table) uit → klik met de rechtermuisknop op Kolommen → Maak nieuwe kolom aan om een nieuwe kolom te maken.
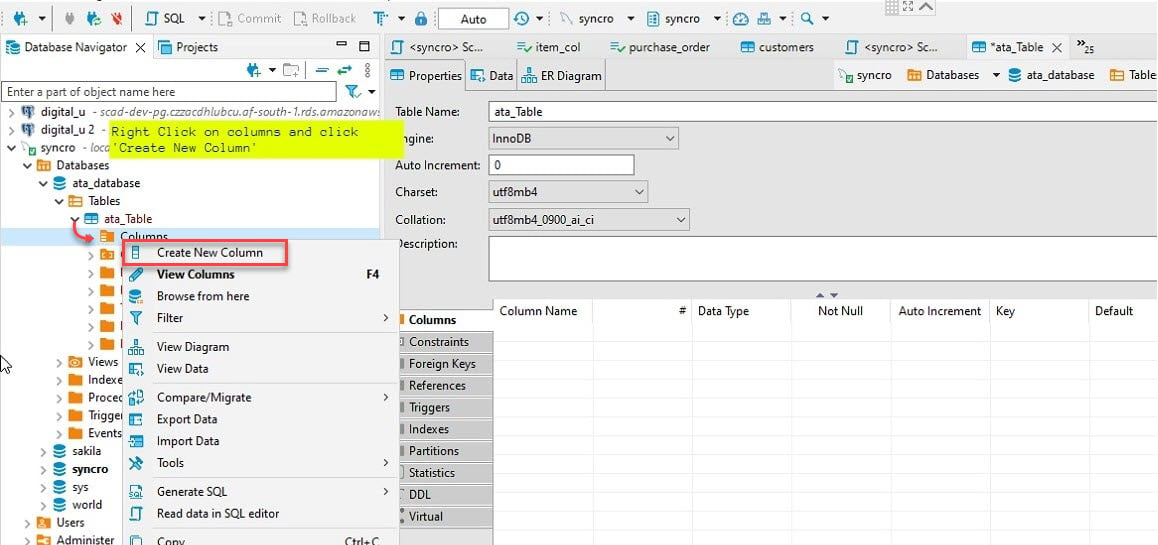
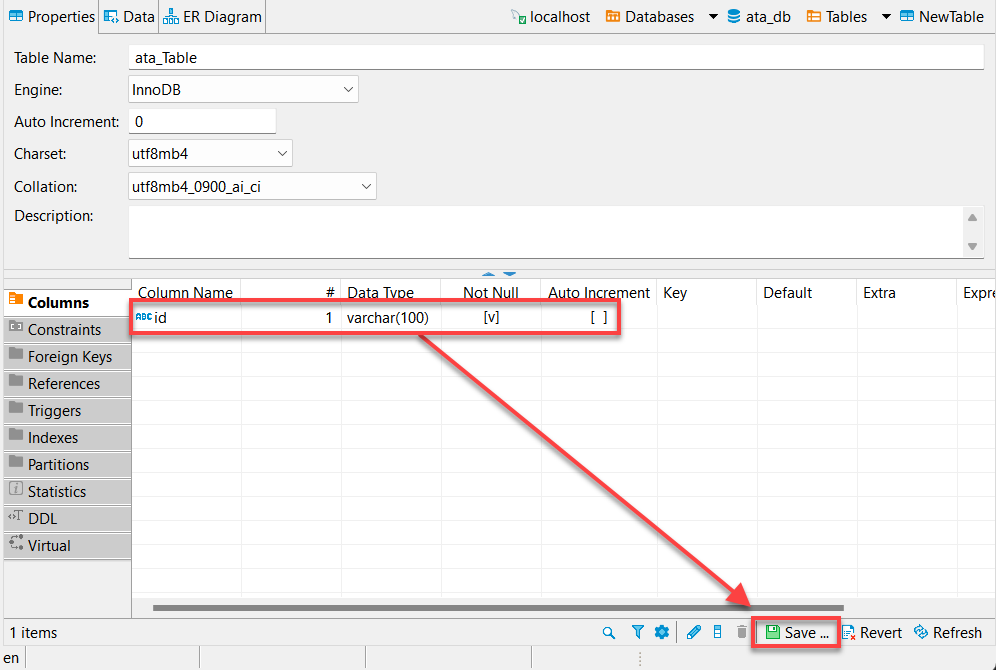
7. Geef een kolomnaam op, zoals hieronder weergegeven, vink het vakje Niet Null aan en klik op OK om de nieuwe kolom te maken.
Ideaal gezien wil je een kolom toevoegen met de naam “id”. Waarom? De meeste API’s zullen een id hebben, en het Python pandas-dataframe zal automatisch de andere kolommen invullen.
8. Klik op Opslaan (rechtsonder) of druk op Ctrl+S om de wijzigingen op te slaan zodra je de nieuw gecreëerde kolom (id) hebt geverifieerd, zoals hieronder weergegeven.
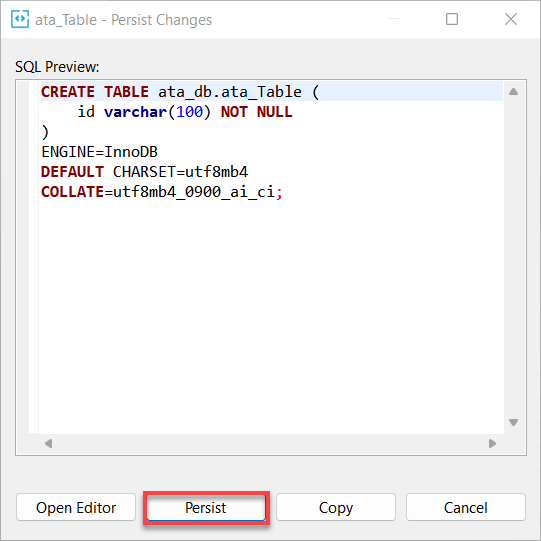
9. Klik tot slot op Persist om de wijzigingen die je hebt aangebracht in de database te behouden.
API-gegevens verkrijgen en consumeren
Nu je de database hebt gemaakt om gegevens op te slaan, moet je de gegevens ophalen van je respectieve API-provider en deze naar je database pushen met Python. Je zult je gegevens bronnen om te visualiseren op Power BI.
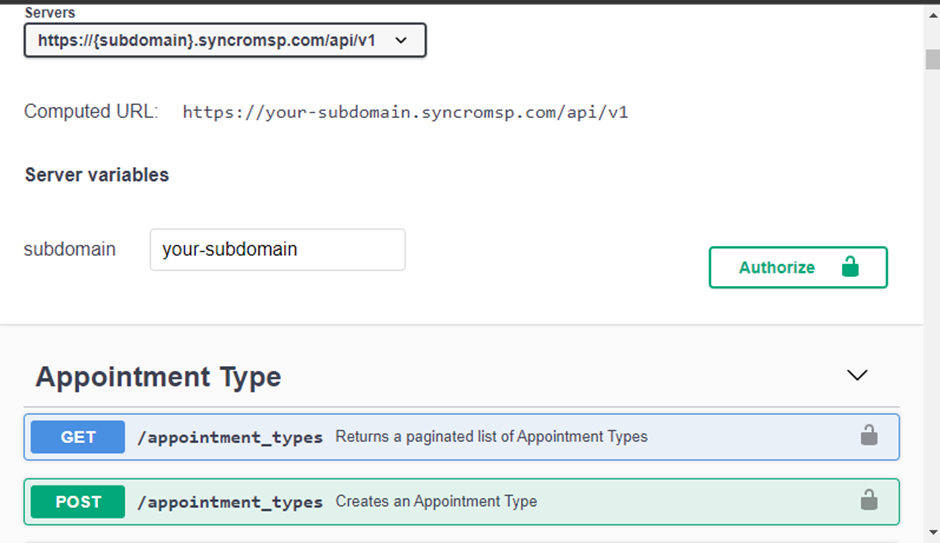
Om verbinding te maken met je API-provider, heb je drie belangrijke stukken informatie nodig: de autorisatiemethode, de API-basis-URL en het API-eindpunt. Als je twijfelt over hoe je deze informatie kunt verkrijgen, bezoek dan de documentatiesite van je API-provider.
Hieronder is een documentatiepagina van Syncro.
1. Open VS Code, maak een Python-bestand en geef het bestand een naam op basis van de API-gegevens die worden verwacht vanuit het bestand. Dit bestand zal verantwoordelijk zijn voor het ophalen en pushen van de API-gegevens naar je database (databaseverbinding).
Er zijn meerdere Python-bibliotheken beschikbaar om te helpen bij de databaseverbinding, maar je zult in deze tutorial SQLAlchemy gebruiken.
Voer de onderstaande pip-opdracht uit in de terminal van VS Code om SQLAlchemy op je omgeving te installeren.

2. Maak vervolgens een bestand genaamd connection.py, vul de onderstaande code in, vervang de waarden indien nodig en sla het bestand op.
Zodra je scripts begint te schrijven om met je database te communiceren, moet er een verbinding met de database worden gemaakt voordat de database enige opdracht accepteert.
Maar in plaats van de databaseverbindingssnaren voor elk script opnieuw te schrijven, is de onderstaande code toegewijd om deze verbinding te maken en kan worden aangeroepen/gereferentieerd door andere scripts.
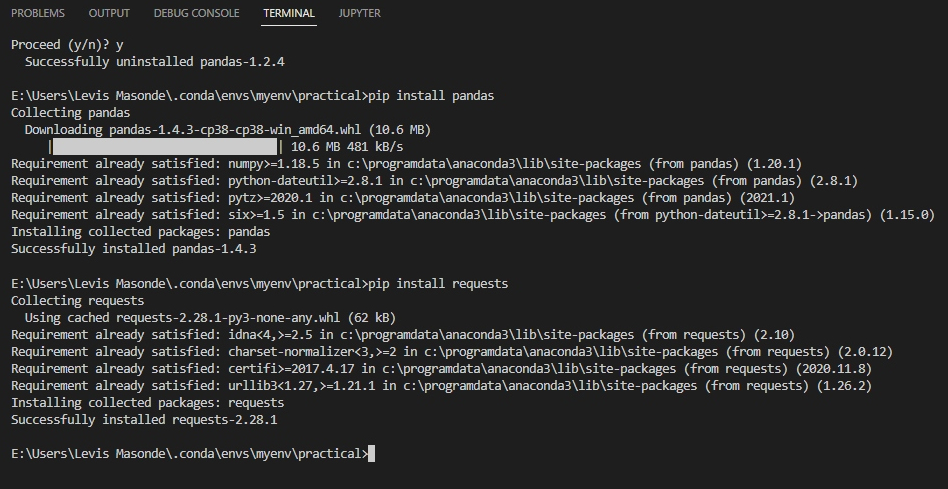
3. Open de terminal van Visual Studio (Ctrl+Shift+`), en voer de onderstaande commando’s uit om pandas en requests te installeren.
4. Maak een ander Python-bestand genaamd invoices.py (of geef het een andere naam), en voeg de onderstaande code toe aan het bestand.
Je zult codefragmenten toevoegen aan het invoices.py-bestand bij elke volgende stap, maar je kunt de volledige code bekijken op ATA’s GitHub.
Het script invoices.py wordt uitgevoerd vanuit het hoofdscript dat wordt beschreven in de volgende sectie, dat je eerste API-gegevens ophaalt.
De onderstaande code voert het volgende uit:
- Verbruikt gegevens van je API en schrijft deze naar je database.
- Vervangt de autorisatiemethode, sleutel, basis-URL en API-eindpunten door de referenties van je API-provider.
5. Voeg het onderstaande codefragment toe aan het bestand invoices.py om de headers te definiëren, bijvoorbeeld:
- Het gegevensformaat dat je verwacht te ontvangen van je API.
- De basis-URL en het eindpunt moeten vergezeld gaan van de autorisatiemethode en de respectieve sleutel.
Zorg ervoor dat je de onderstaande waarden wijzigt met je eigen waarden.
6. Voeg vervolgens de volgende async functie toe aan het bestand invoices.py.
De onderstaande code gebruikt AsyncIO om meerdere scripts te beheren vanuit één hoofdscript dat wordt behandeld in de volgende sectie. Wanneer je project groeit en meerdere API-eindpunten bevat, is het een goede praktijk om je scripts voor het consumeren van API’s in hun eigen bestanden te hebben.
7. Voeg tot slot de onderstaande code toe aan het bestand invoices.py, waar een get_pages functie de paginering van je API afhandelt.
Deze functie retourneert het totale aantal pagina’s in je API en helpt de range-functie om door alle pagina’s te itereren.
Neem contact op met de ontwikkelaars van je API over de paginatiemethode die door je API-provider wordt gebruikt.
Wenn Sie weitere API-Endpunkte zu Ihren Daten hinzufügen möchten:
- Wiederholen Sie die Schritte vier bis sechs im Abschnitt “MySQL-Datenbanken verwalten mit DBeaver”.
- Wiederholen Sie alle Schritte im Abschnitt “API-Daten abrufen und verbrauchen”.
- Ändern Sie den API-Endpunkt zu einem anderen, den Sie verbrauchen möchten.
API-Endpunkte synchronisieren
Sie haben nun eine Datenbank- und API-Verbindung und sind bereit, die API-Nutzung zu starten, indem Sie den Code in der Datei invoices.py ausführen. Dies würde Sie jedoch darauf beschränken, gleichzeitig einen API-Endpunkt zu verbrauchen.
Hoe de limiet te overschrijden? U maakt een ander Python-bestand als een centraal bestand dat API-functies van verschillende Python-bestanden aanroept en de functies asynchroon uitvoert met behulp van AsyncIO. Op deze manier houdt u uw programmering schoon en kunt u meerdere functies bundelen.
1. Maak een nieuw Python-bestand genaamd central.py en voeg de onderstaande code toe.
Vergelijkbaar met het bestand invoices.py voegt u op elke stap codefragmenten toe aan het bestand central.py, maar u kunt de volledige code bekijken op ATA’s GitHub.
De onderstaande code importeert essentiële modules en scripts uit andere bestanden met behulp van de syntaxis from <filename> import <function name>.
2. Voeg vervolgens de volgende code toe om de scripts van invoices.py te beheren in het bestand central.py.
U moet verwijzen/oproepen naar de functie call_invoices van invoices.py naar een AsyncIO-taak (invoice_task) in central.py.
3. Na het maken van de AsyncIO-taak, wacht op de taak om de call_invoices-functie uit te voeren en uit te voeren vanuit invoice.py zodra de ketenfunctie (in stap twee) begint met uitvoeren.
4. Maak een AsyncIOScheduler om een taak voor het script in te plannen. De taak toegevoegd in deze code voert de ketenfunctie uit in intervallen van één seconde.
Deze taak is belangrijk om ervoor te zorgen dat uw programma uw scripts blijft uitvoeren om uw gegevens up-to-date te houden.
5. Als laatste, voer het script central.py uit in VS Code, zoals hieronder weergegeven.
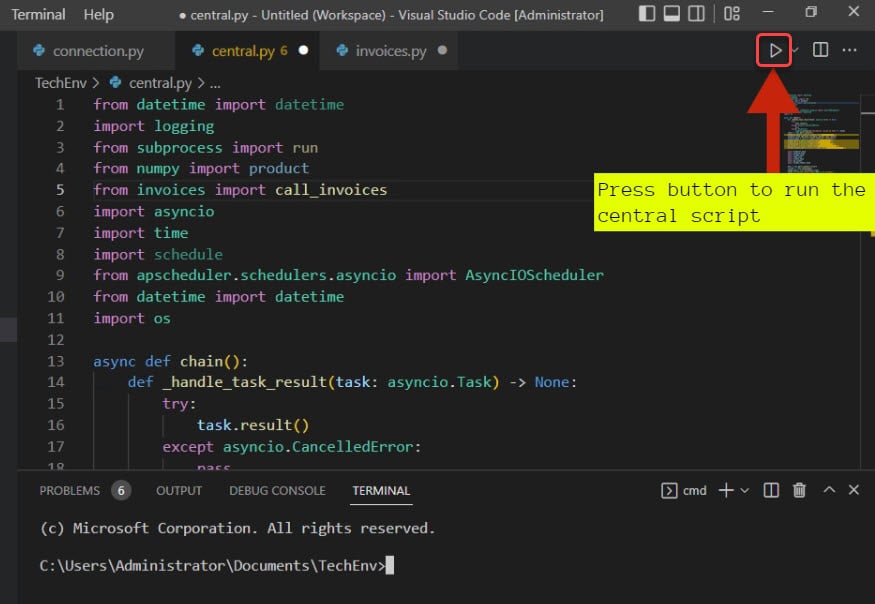
Na het uitvoeren van het script, ziet u de uitvoer op de terminal zoals hieronder weergegeven.
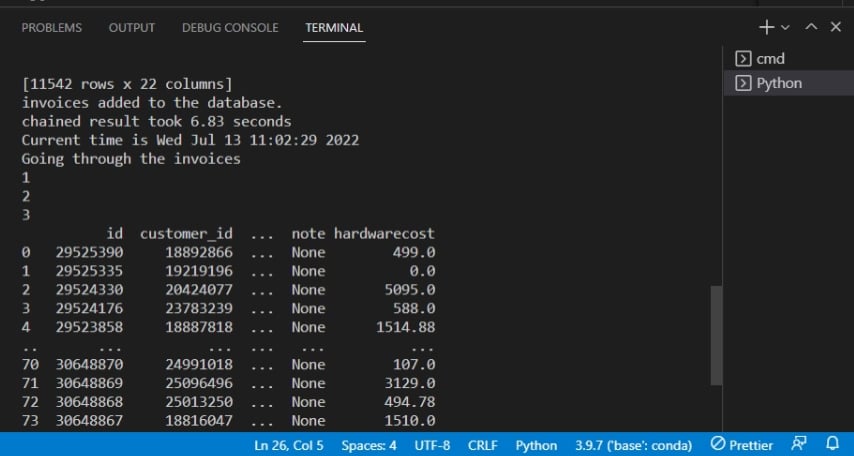
Hieronder bevestigt de uitvoer dat facturen aan de database zijn toegevoegd.
Het ontwikkelen van Power BI Visuals
Na het coderen van een programma dat verbinding maakt met en API-gegevens verbruikt en deze gegevens naar een database pusht, ben je bijna klaar om je gegevens te oogsten. Maar eerst duw je de gegevens in de database naar Power BI voor visualisatie, het eindspel.
Veel gegevens zijn nutteloos als je ze niet kunt visualiseren en diepe verbindingen kunt maken. Gelukkig zijn Power BI-visuals zoals grafieken die complexe wiskundige vergelijkingen eenvoudig en voorspelbaar kunnen maken.
1. Open Power BI vanuit je bureaublad of Startmenu.
2. Klik op het gegevensbronpictogram boven de vervolgkeuzelijst Get data in het hoofdvenster van Power BI. Er verschijnt een pop-upvenster waarin je de gegevensbron kunt selecteren die je wilt gebruiken (stap drie).
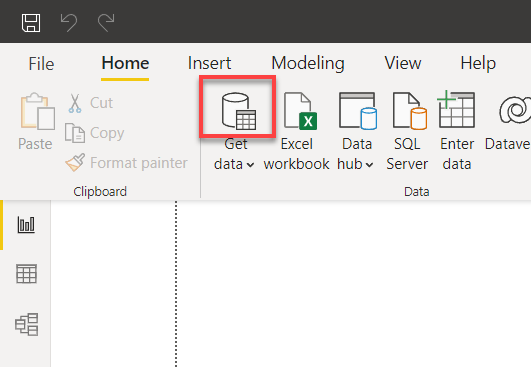
3. Zoek naar mysql, selecteer de MySQL-database en klik op Verbinden om verbinding te maken met je MySQL-database (stap vier).
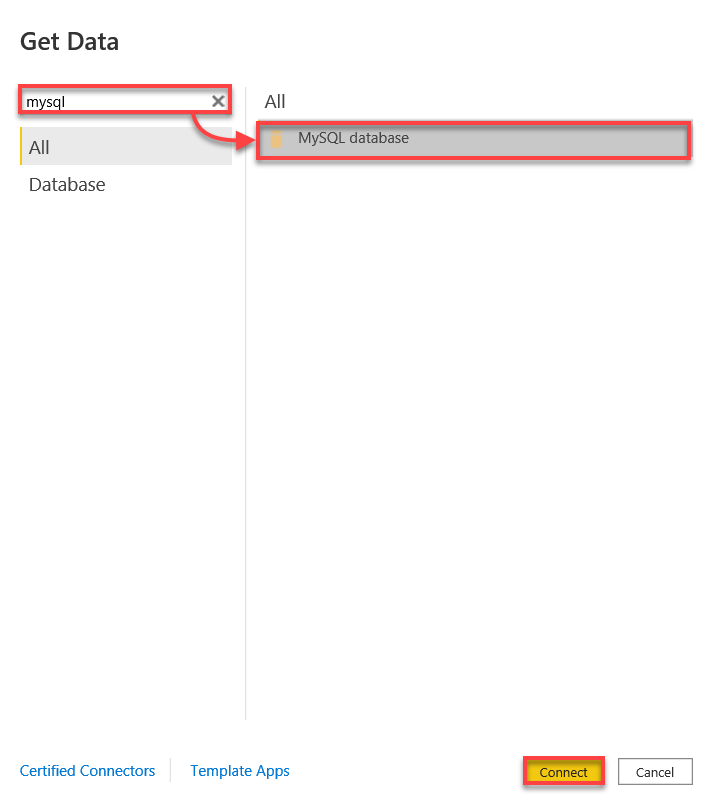
4. Maak nu verbinding met je MySQL-database met het volgende:
- Voer localhost:3306 in, aangezien je verbinding maakt met je lokale MySQL-server op poort 3306.
- Geef de naam van je database op, in dit geval ata_db.
- Klik op OK om verbinding te maken met je MySQL-database.

5. Klik nu op Gegevens transformeren (rechtsonder) om het overzicht van de gegevens te zien in de Query-editor van Power BI (stap vijf).

6. Nadat je de gegevensbron hebt bekeken, klik je op Sluiten en toepassen om terug te keren naar de hoofdtoepassing en te bevestigen of er wijzigingen zijn toegepast.
De query-editor toont tabellen van je gegevensbron links. Tegelijkertijd kun je het formaat van de gegevens controleren voordat je verder gaat naar de hoofdtoepassing.
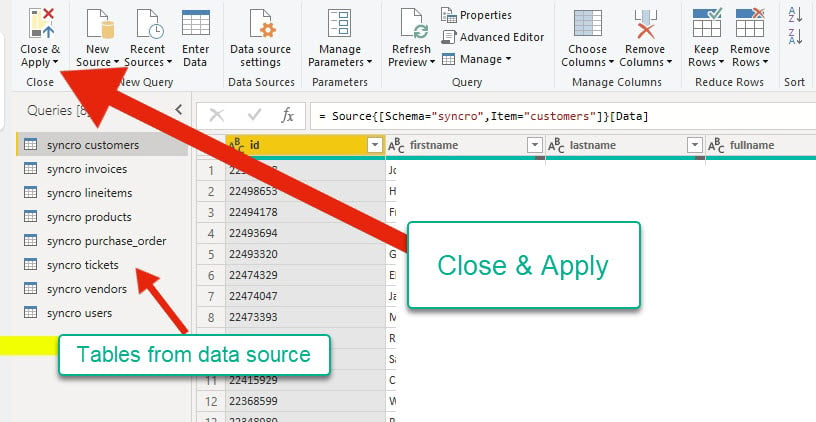
7. Klik op het lint Tabellengereedschappen, selecteer een willekeurige tabel in het venster Velden en klik op Beheer relaties om de relatiemanager te openen.
Voordat je visuals maakt, moet je ervoor zorgen dat je tabellen gerelateerd zijn, dus specificeer expliciet eventuele relaties tussen je tabellen. Waarom? Power BI detecteert nog niet automatisch complexe tabelcorrelatie.

8. Schakel de vakjes in van bestaande relaties die je wilt bewerken en klik op Bewerken. Er verschijnt een pop-upvenster waarin je de geselecteerde relaties kunt bewerken (stap negen).
Maar als je de voorkeur geeft aan het toevoegen van een nieuwe relatie, klik dan op Nieuw.
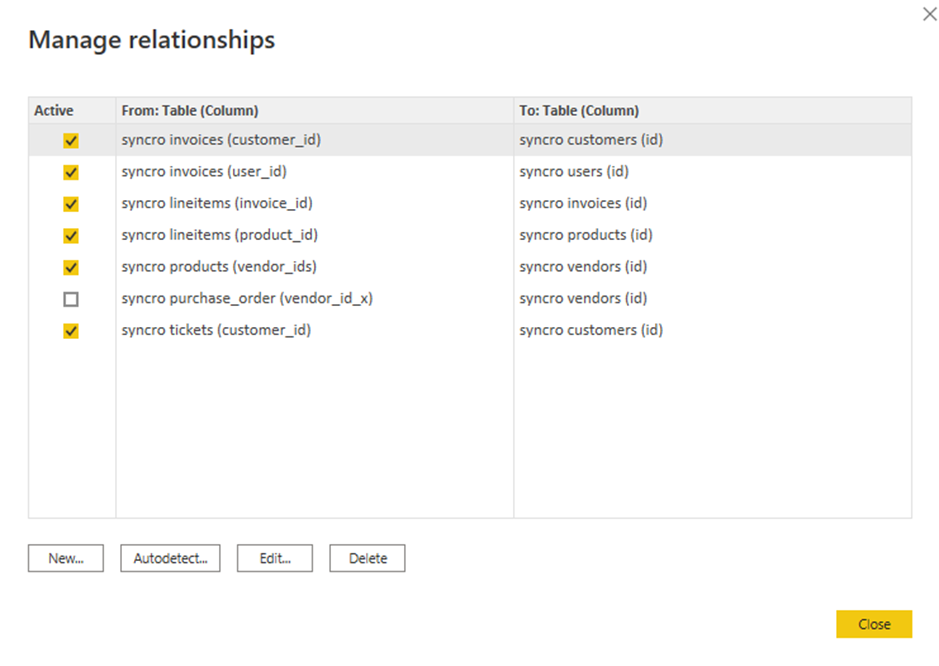
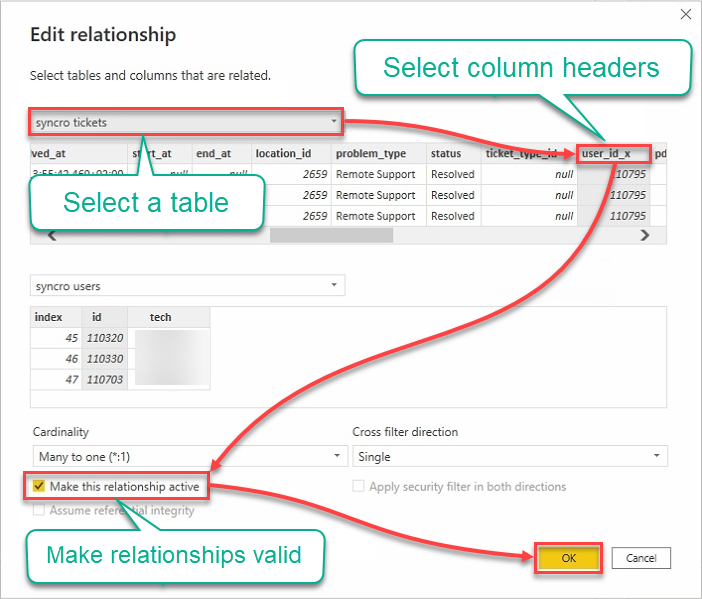
9. Bewerk relaties met het volgende:
- Klik op het vervolgkeuzemenu van de tabellen en selecteer een tabel.
- Klik op koppen om kolommen te selecteren die moeten worden gebruikt.
- Vink het vakje Maak deze relatie actief aan om ervoor te zorgen dat de relaties geldig zijn.
- Klik op OK om de relatie tot stand te brengen en het venster Relatie bewerken te sluiten.
10. Klik nu op het type Table visual onder het venster Visualisaties (uiterst rechts) om je eerste visuele weergave te maken, en er verschijnt een lege tabelweergave (stap 11).
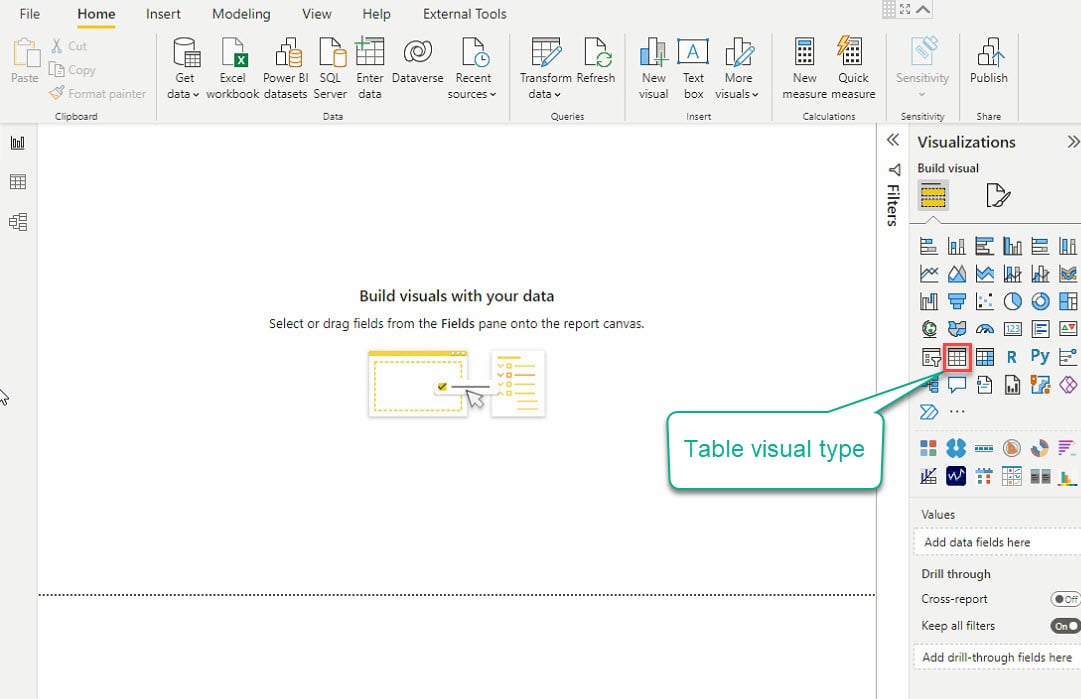
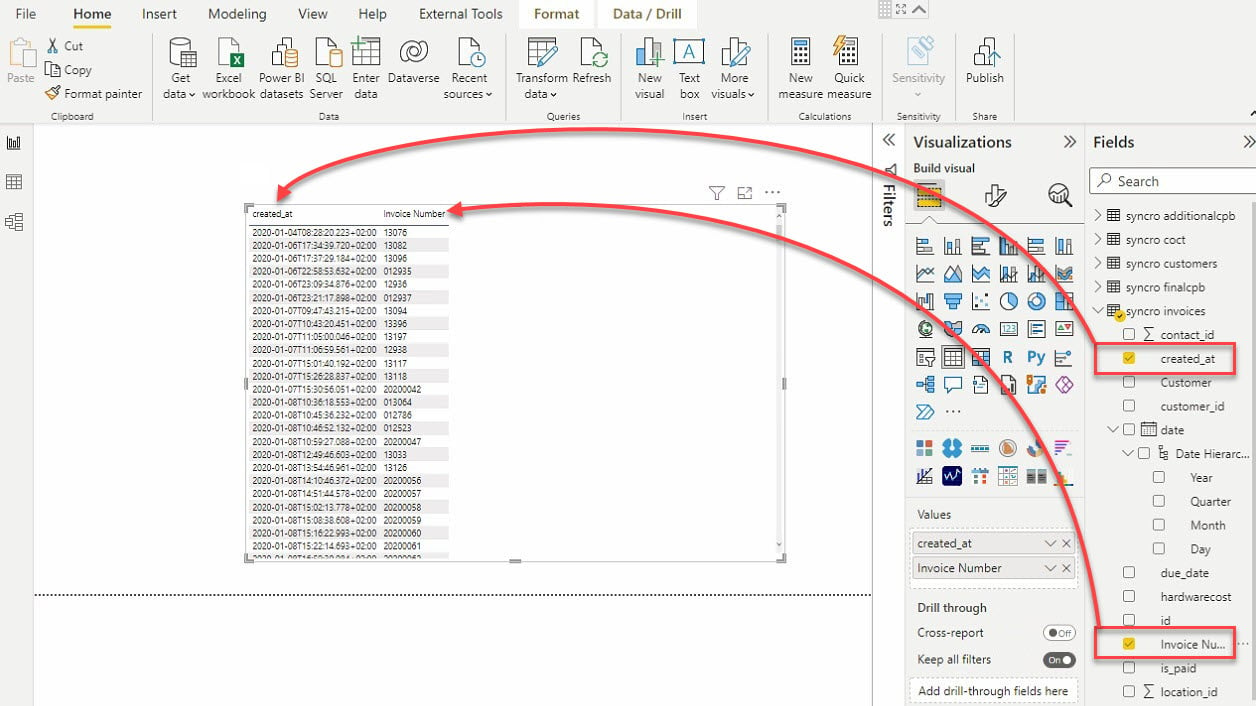
11. Selecteer de tabelvisual en de gegevensvelden (in het veldenvenster) om toe te voegen aan je tabelvisual, zoals hieronder getoond.
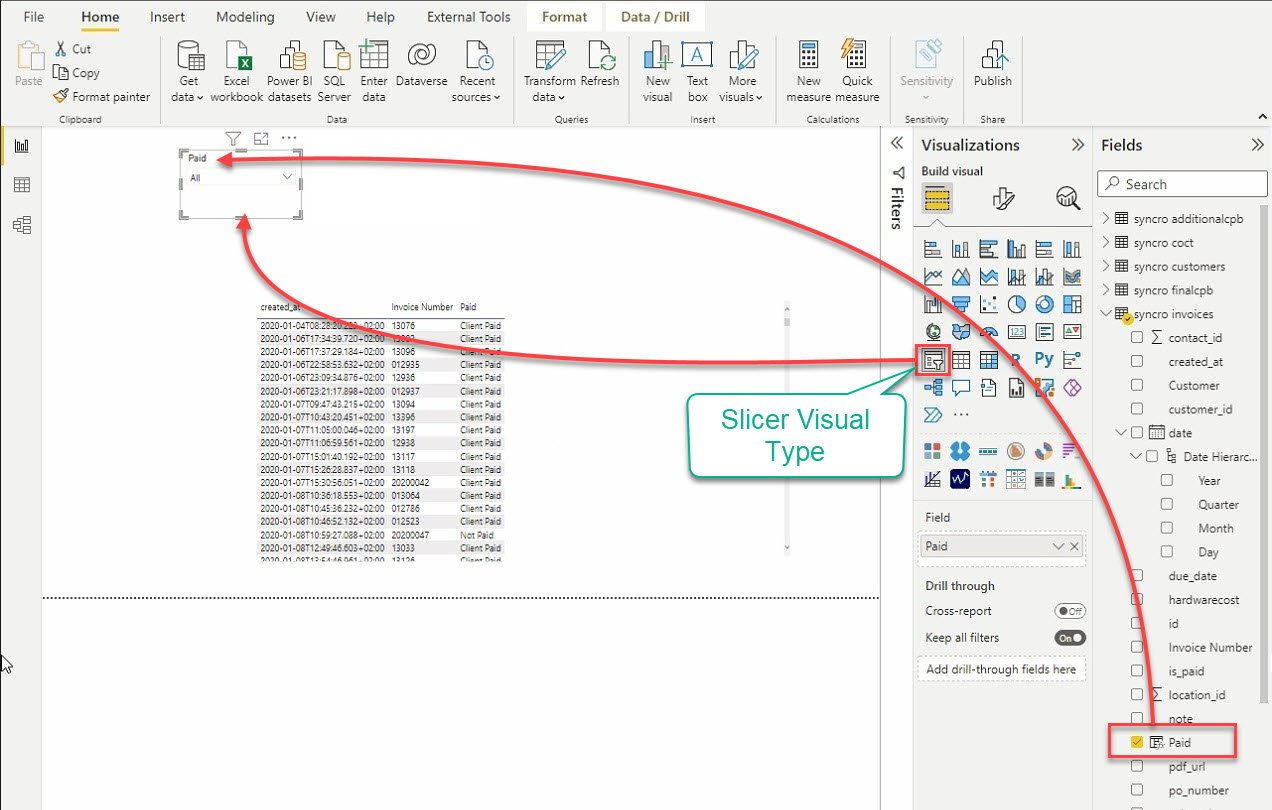
12. Klik ten slotte op het type Slicer visual om een andere visuele weergave toe te voegen. Zoals de naam al doet vermoeden, snijdt de slicer visual gegevens door andere visuals te filteren.
Na het toevoegen van de slicer, selecteer gegevens uit het veldenvenster om toe te voegen aan de slicer visual.
Visualisaties wijzigen
De standaardweergave van de visuals is behoorlijk fatsoenlijk. Maar zou het niet geweldig zijn als je de uitstraling van de visuals kon veranderen naar iets minder saais? Laat Power BI het werk doen.
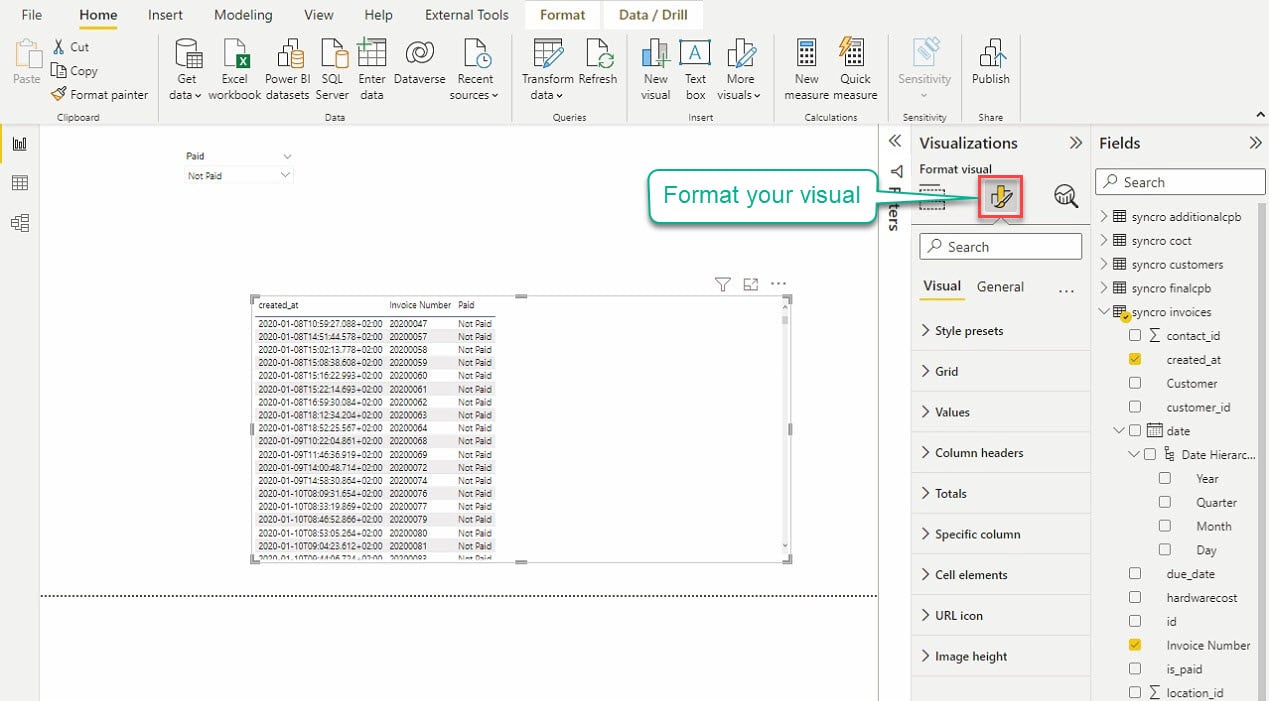
Klik op het icoon Formateer je visual onder visualisatie om toegang te krijgen tot de visualisatie-editor, zoals hieronder getoond.
Neem de tijd om te spelen met de instellingen van de visualisatie om de gewenste uitstraling van je visuals te krijgen. Je visuals zullen correleren zolang je een relatie tussen de tabellen tot stand brengt die je in je visuals betrekt.
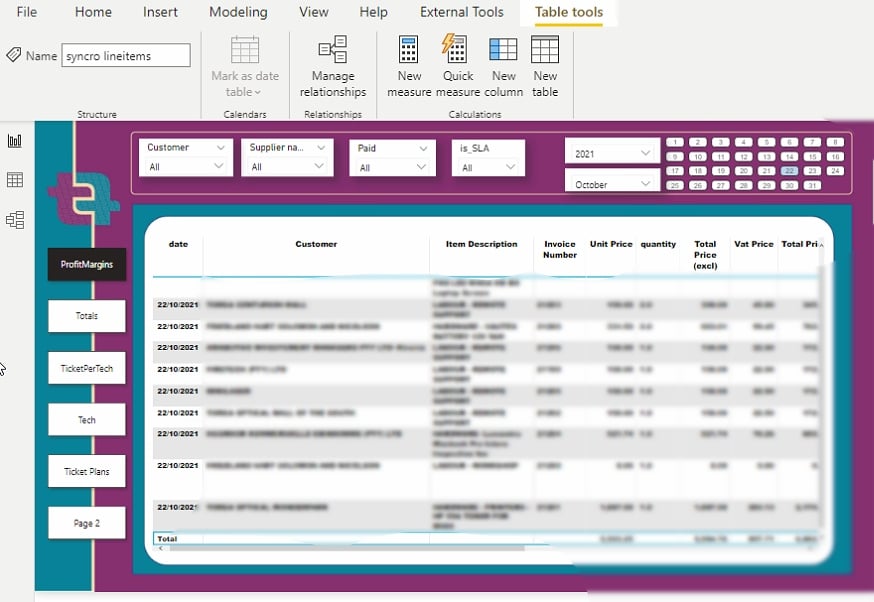
Na het wijzigen van de visualisatie-instellingen kun je rapporten genereren zoals hieronder.
Nu kun je je gegevens visualiseren en analyseren zonder complexiteit of vermoeide ogen.
In de volgende visualisatie, bij het bekijken van de trendgrafiek, zul je zien dat er iets misging in april 2020. Dat was toen de Covid-19-lockdowns voor het eerst Zuid-Afrika troffen.
Deze output bevestigt alleen de kracht van Power BI in het leveren van nauwkeurige gegevensvisualisaties.

Conclusie
Deze handleiding heeft als doel je te laten zien hoe je een live dynamische gegevenspijplijn kunt opzetten door gegevens op te halen uit API-eindpunten. Daarnaast het verwerken en pushen van gegevens naar je database en Power BI met behulp van Python. Met deze nieuw verworven kennis kun je nu API-gegevens consumeren en je eigen gegevensvisualisaties maken.
Steeds meer bedrijven creëren Restful API-webtoepassingen. En op dit punt ben je nu zelfverzekerd in het consumeren van API’s met behulp van Python en het maken van gegevensvisualisaties met Power BI, wat kan helpen bij het beïnvloeden van zakelijke beslissingen.