













Het omzetten van uw ruwe gegevens naar georganiseerde en bruikbare informatie kan complex klinken. Nou, niet als je een snelle en efficiënte oplossing hebt. Maak je geen zorgen! Deze beginner-vriendelijke AWS Glue tutorial staat voor je klaar.
In deze tutorial leert u de cruciale stappen voor het configureren en uitvoeren van gegevenstransformaties met AWS Glue.
Verken en stroomlijn de voorbereiding van gegevens voor cloudgebaseerde analyses!
Vereisten
Voordat u met AWS Glue gaat werken, zorg ervoor dat u een actief Amazon Web Services (AWS)-account heeft met ingeschakelde facturering. Een gratis account zal volstaan voor deze tutorial.
Het maken van een IAM-rol voor AWS Glue
Voordat u een transformatiejob uitvoert, moet u een Identity and Access Management (IAM)-rol maken die toestemming verleent aan de AWS Glue-service. Deze rol bepaalt welk type resources AWS Glue mag benaderen in uw AWS-account.
Volg de onderstaande stappen om de IAM-rol te maken:
1. Open uw favoriete webbrowser en log in op de AWS Management Console.
2. Zoek en selecteer IAM in de resultatenlijst om toegang te krijgen tot de IAM-console.
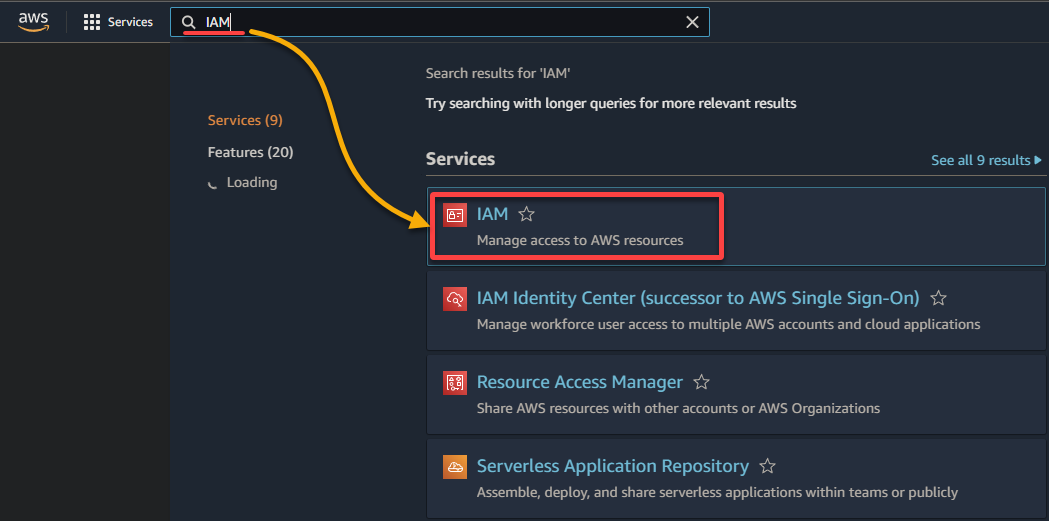
3. In de IAM-console, navigeer naar Rollen (linkerpaneel) en klik op Rol maken (rechtsboven) om uw browser door te verwijzen naar een nieuwe pagina gewijd aan het configureren van de rol.

4. Configureer nu de volgende instellingen voor de rol:
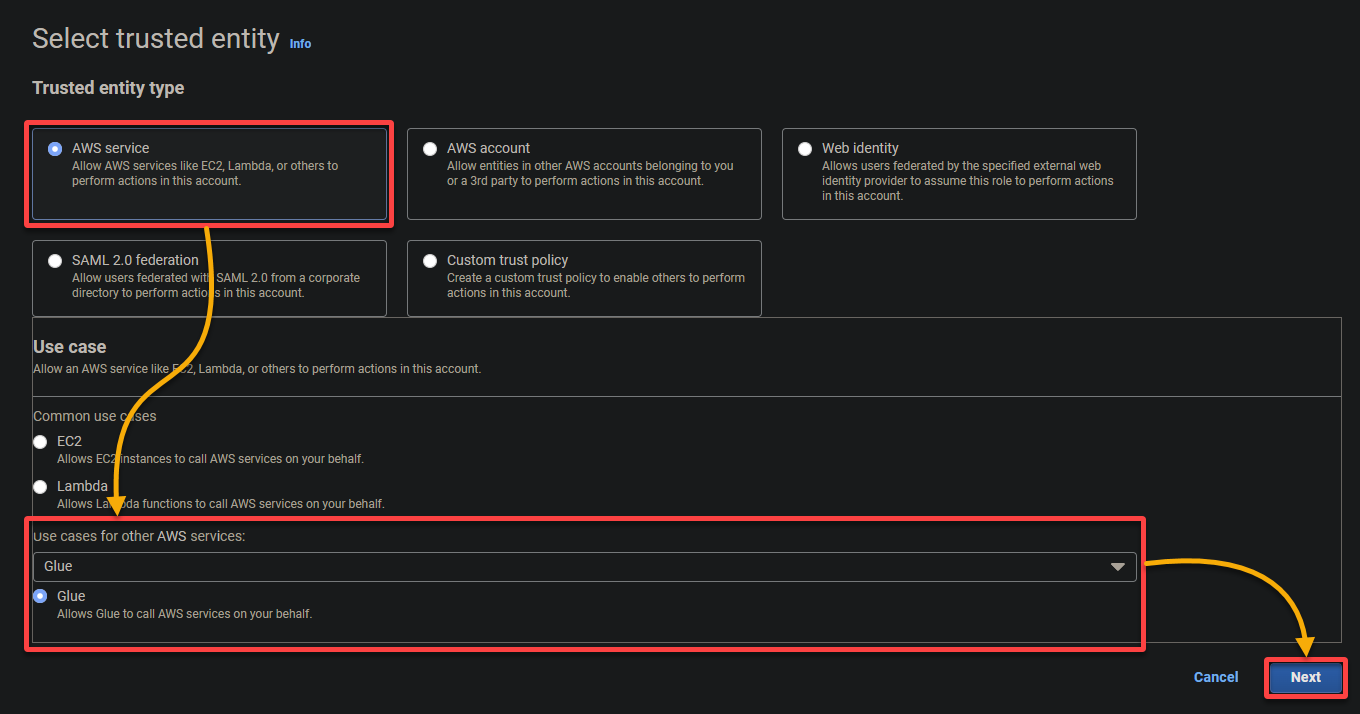
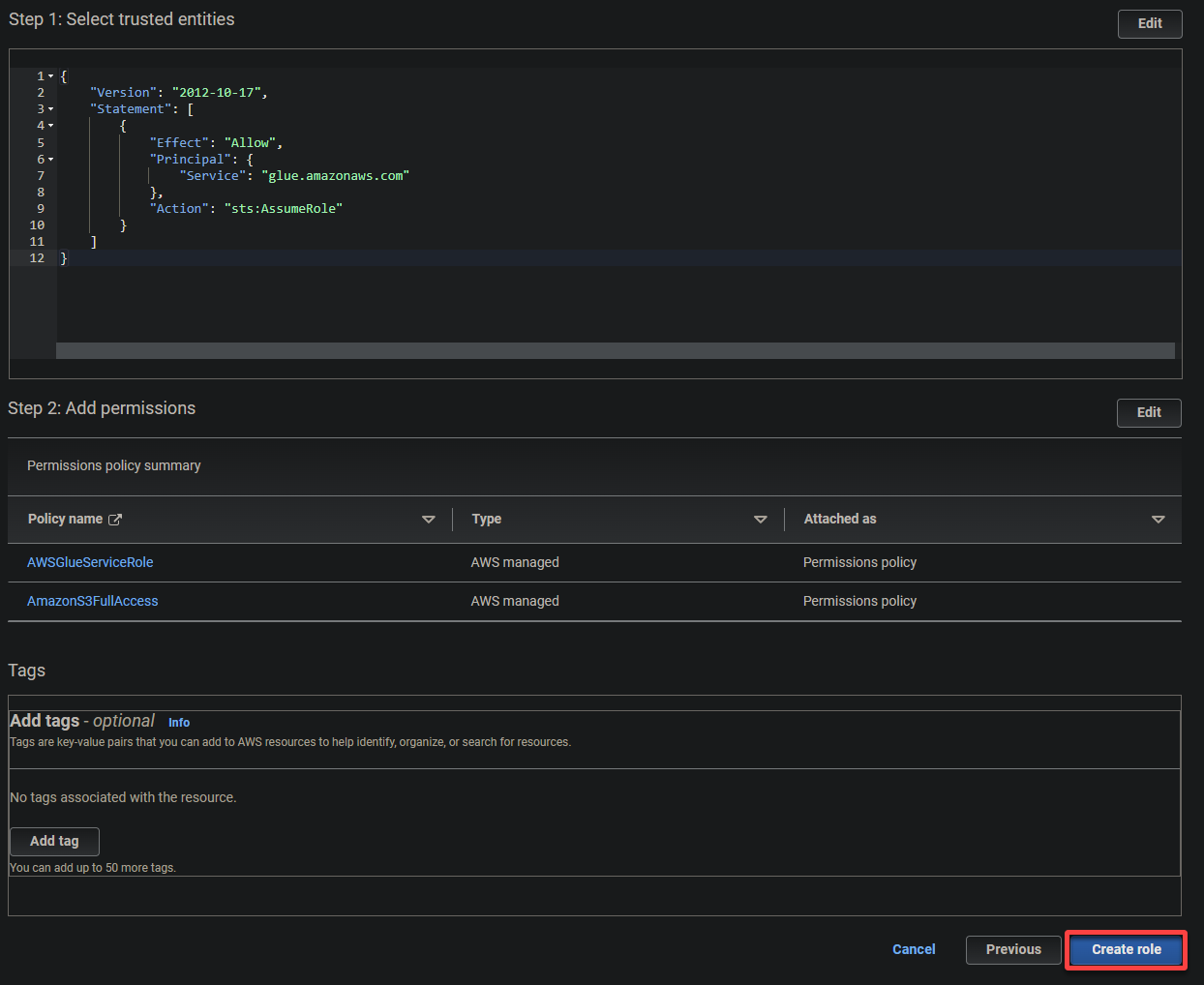
- Type vertrouwde entiteit – Selecteer AWS-service zodat een AWS-service de rol vertrouwt. Hierdoor kan die service de rol aannemen en namens u handelen.
- Gebruiksscenario – Kies Glue onder de Gebruiksscenario’s voor andere AWS-services sectie aangezien u de IAM-rol specifiek voor AWS Glue zult maken, en klik op Volgende.
5. Zoek en selecteer de volgende beleidsregels, en klik op Volgende.
- AWSGlueServiceRole – Verleent de AWS Glue-service de noodzakelijke rechten om zijn operaties uit te voeren.
- S3FullAccess – Verleent volledige toegang tot de S3-bronnen, waardoor AWS Glue kan lezen van en schrijven naar S3-buckets.
AWS Glue heeft uitgebreide rechten nodig om te lezen van en schrijven naar S3-buckets om zijn gegevensextractie, -transformatie en -laden (ETL) taken effectief uit te voeren.
? Vermijd het verlenen van onnodige buitensporige rechten, aangezien deze beveiligingsrisico’s kunnen vormen.
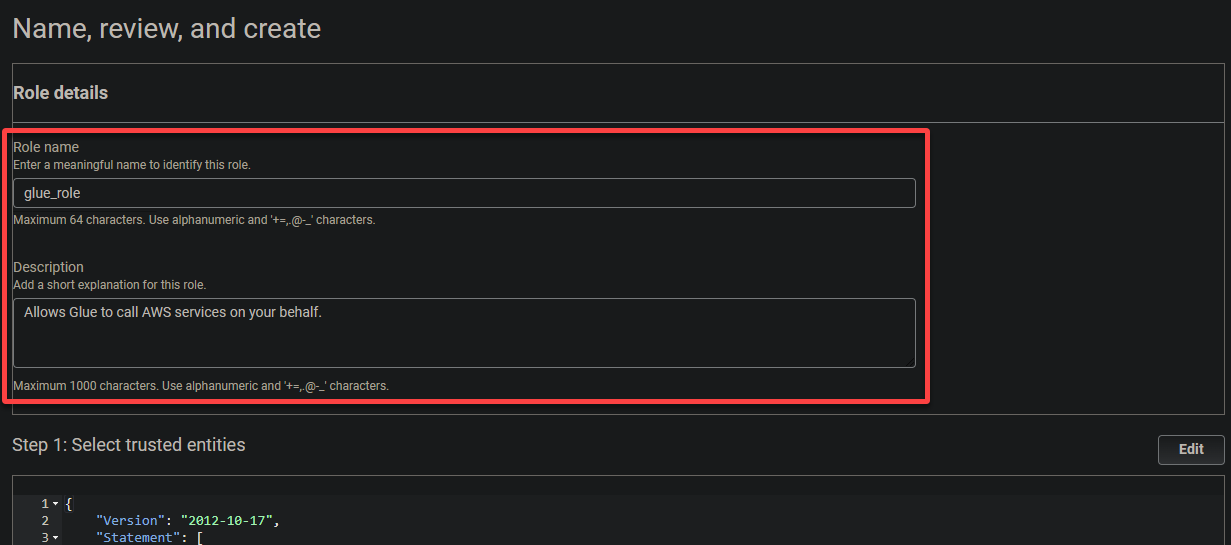
6. Geef een beschrijvende naam voor de rol (bijv. glue_role) en een beschrijving.
7. Tenslotte, scroll naar beneden, controleer je instellingen en klik op Rol maken (rechtsonder) om de rol te finaliseren.
Het maken van een S3-emmer en het uploaden van een voorbeeldbestand
Nu je een IAM-rol hebt voor AWS Glue, heb je een plek nodig om je gegevens op te slaan, specifiek, een S3-emmer. Een S3-emmer biedt een gecentraliseerde locatie voor het opslaan van de gegevens die AWS Glue zal verwerken.
In dit voorbeeld zal AWS Glue AWS S3 gebruiken als een gegevensopslag voor verschillende operaties, zoals gegevensextractie, transformatie en laden (ETL)-taken.
Volg deze stappen om een S3-emmer te maken en een voorbeeldbestand te uploaden:
1. Download een voorbeeldgegevensbestand (bijvoorbeeld Every Politician-dataset) naar je lokale machine. Dit bestand bevat een ongestructureerde verzameling records om te dienen als invoer voor de AWS Glue-transformatietaak.
2. Zoek naar en selecteer de S3-service om toegang te krijgen tot de S3-console.
3. Klik op Een emmer maken om het maken van een nieuwe S3-emmer te starten.

4. Geef nu een unieke naam op voor je emmer (bijv. sampledata54675) en selecteer de regio waar de emmer moet worden geplaatst.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
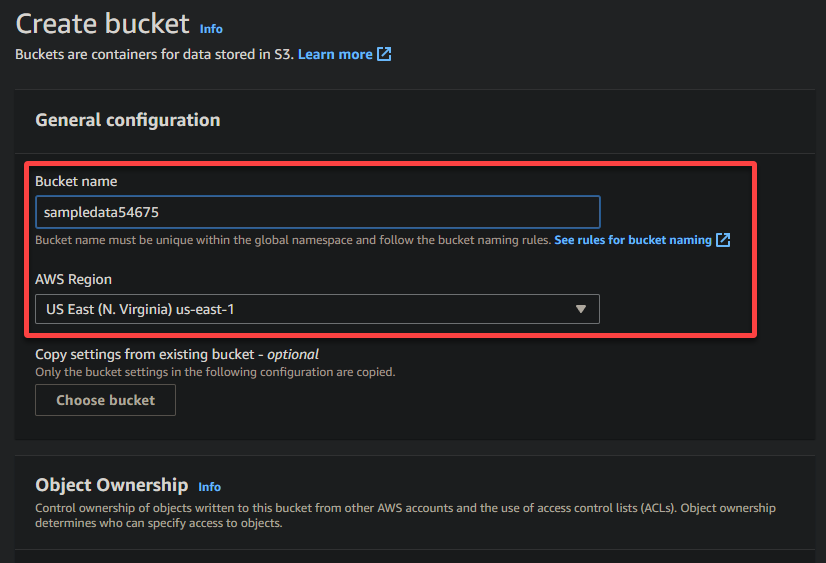
5. Scroll naar beneden, laat andere opties zoals ze zijn, en klik op Emmer maken om de emmer te maken.

6. Klik, zodra deze is gemaakt, op de hyperlink voor de nieuw gemaakte S3-emmer om naar de emmer te navigeren.

7. Klik op Uploaden en zoek het voorbeeldbestand dat je wilt uploaden.
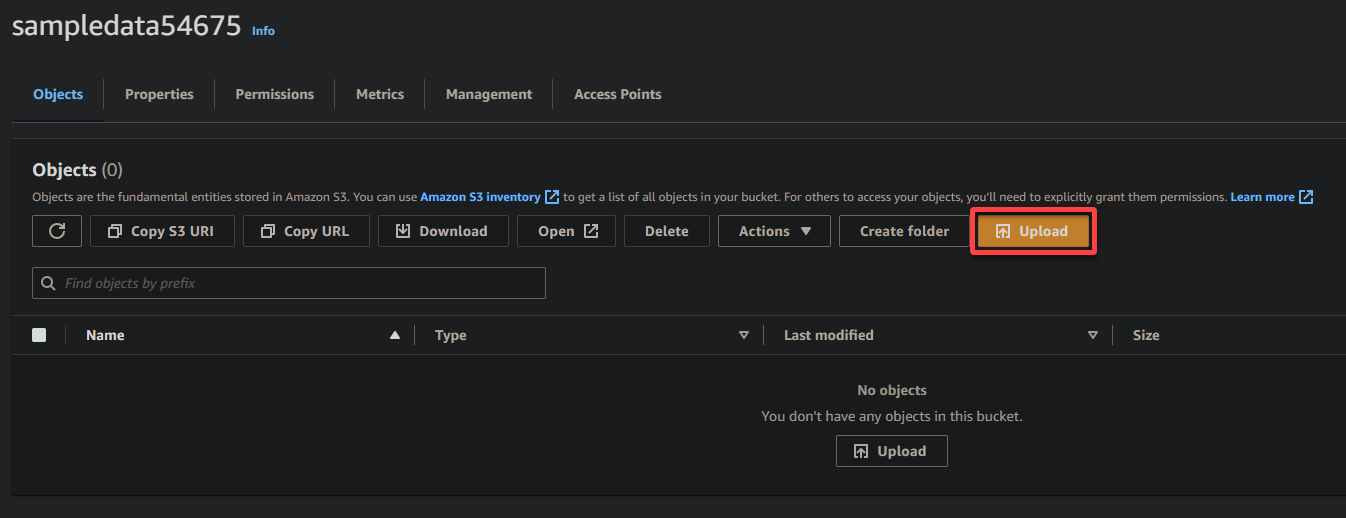
8. Tenslotte, houd andere instellingen zoals ze zijn, en klik op Uploaden om het voorbeeldbestand naar de zojuist aangemaakte bucket te uploaden.
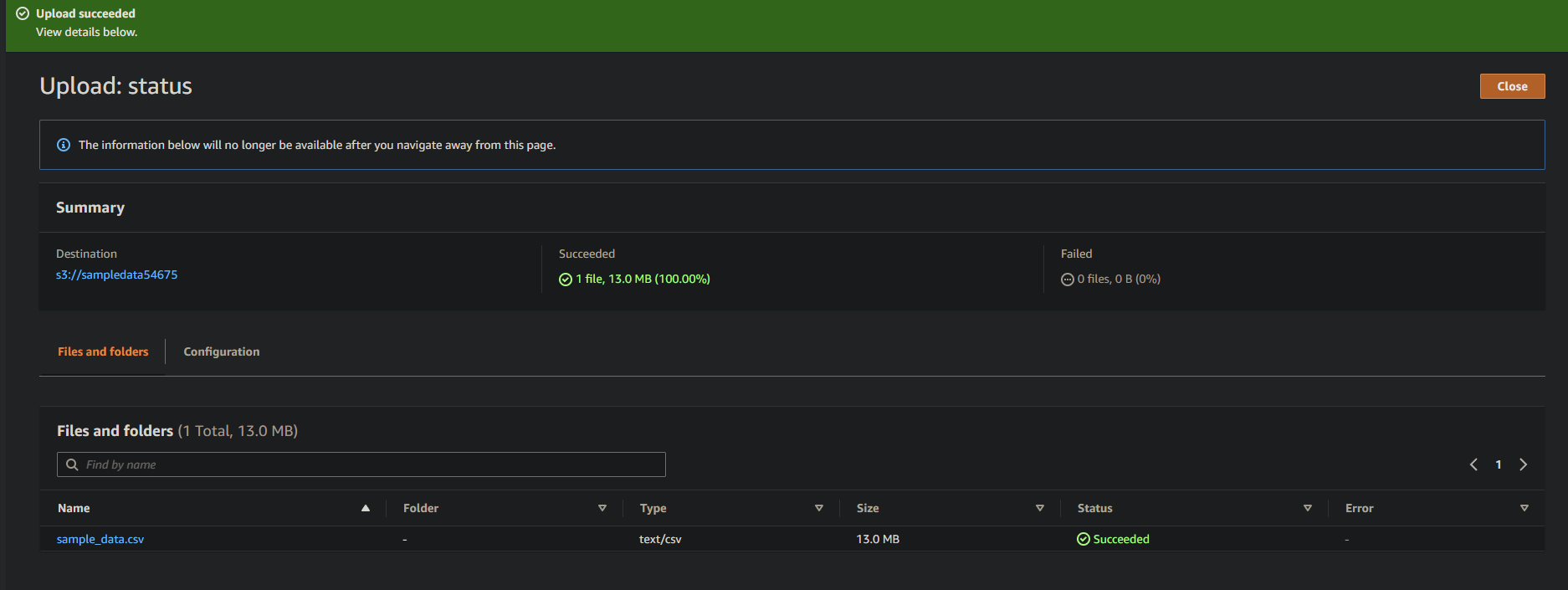
Als het gelukt is, zie je je zojuist geüploade bestand in je bucket, zoals hieronder weergegeven.
Het maken van een Glue Crawler om gegevens te scannen en te catalogiseren
Je hebt zojuist voorbeeldgegevens geüpload naar je S3-bucket, maar omdat het momenteel ongestructureerd is, heb je een manier nodig om de gegevens te lezen en een metadatalogus op te bouwen. Hoe? Door een glue crawler te maken die automatisch de gegevens scant en catalogiseert.
Volg de onderstaande stappen om een glue crawler te maken:
1. Ga naar de AWS Glue-console via de AWS Management Console, zoals hieronder weergegeven.
2. Ga vervolgens naar Crawler (linkerpaneel) en klik op Crawler toevoegen (rechtsboven) om het maken van een nieuwe glue crawler te starten.
3. Geef een beschrijvende naam op (bijv. glue_crawler) en een beschrijving voor de crawler, houd andere instellingen zoals ze zijn, en klik op Volgende.
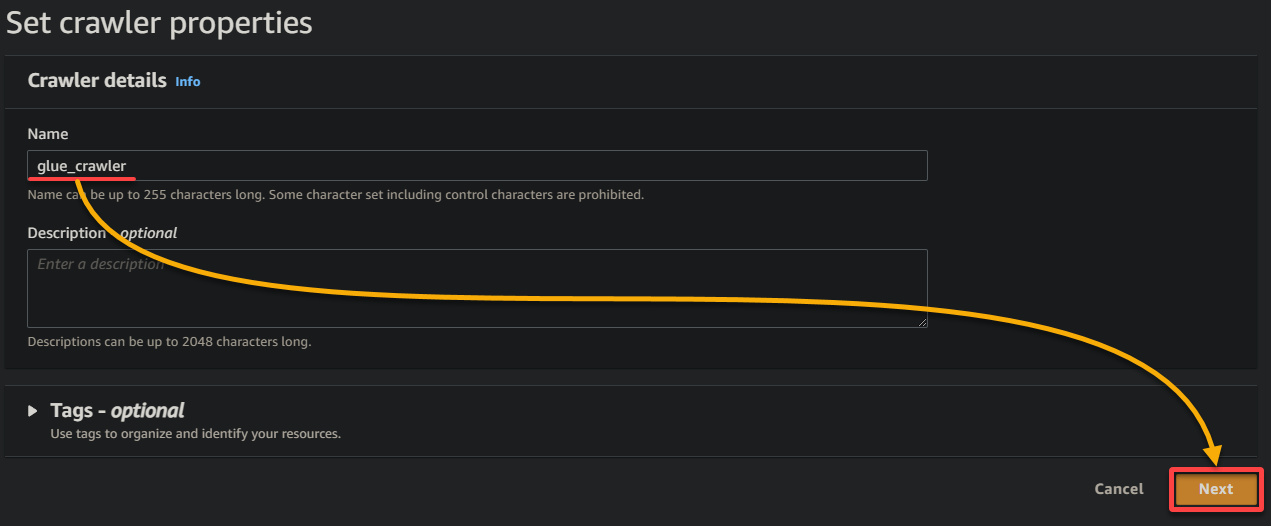
4. Klik nu op Een gegevensbron toevoegen onder Gegevensbronnen om het toevoegen van een nieuwe gegevensbron aan de crawler te starten.
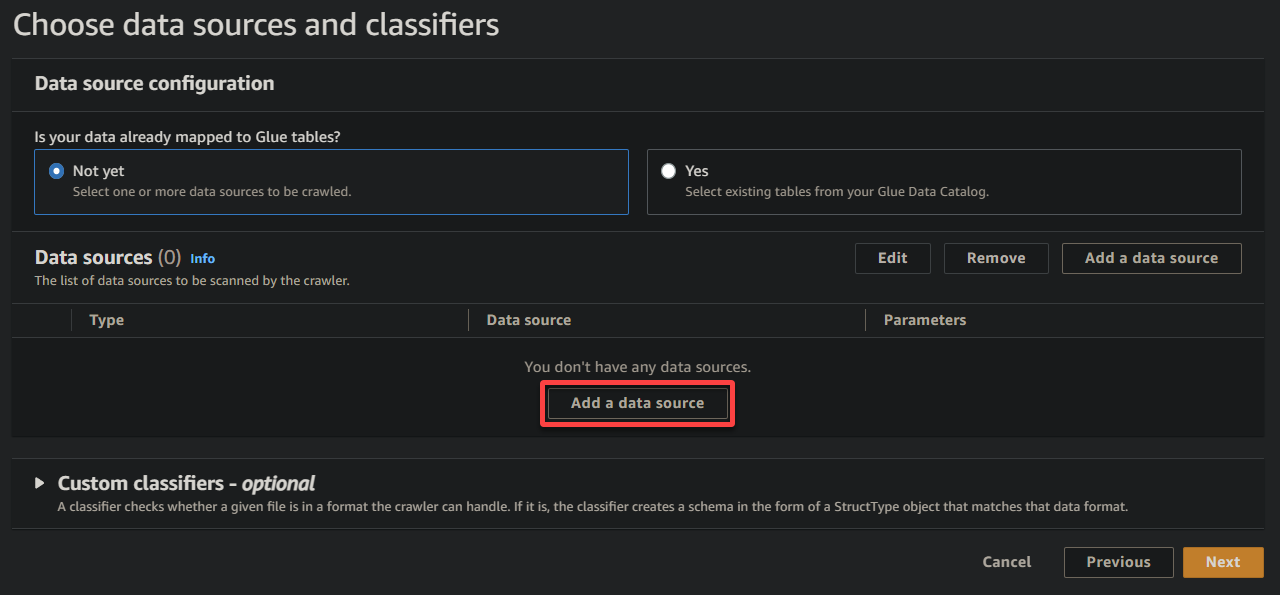
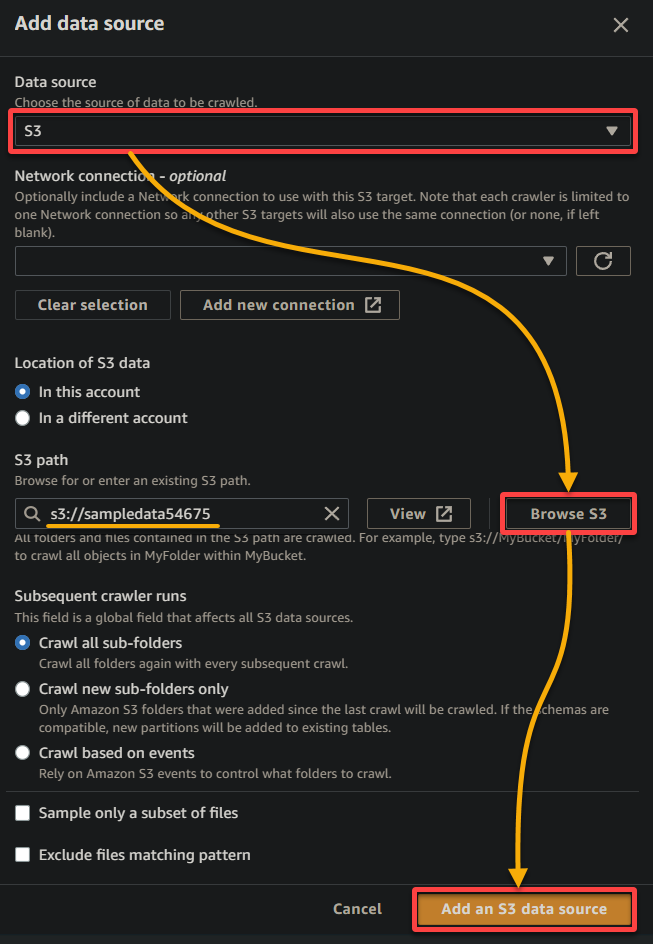
5. Configureer de gegevensbron op het pop-upvenster als volgt:
- Gegevensbron – Selecteer S3 omdat je gegevens zich in je S3-bucket bevinden.
- S3-pad – Klik op Bladeren in S3 en kies de emmer die uw geüploade voorbeeldgegevens bevat (sampledata54675).
- Houd andere instellingen zoals ze zijn en klik op Een S3-gegevensbron toevoegen om de voorbeeldgegevens aan de crawler toe te voegen.
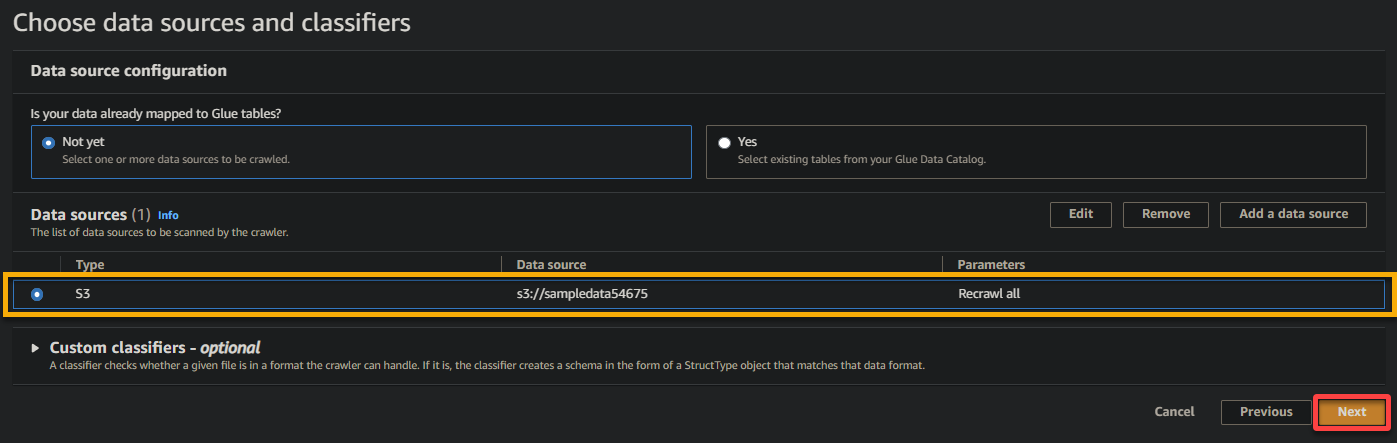
6. Zodra geconfigureerd, controleer de gegevensbron, zoals hieronder weergegeven, en klik op Volgende om door te gaan.
7. Op het volgende scherm, selecteer de IAM-rol die u eerder heeft aangemaakt (glue_role), houd andere instellingen zoals ze zijn, en klik op Volgende.
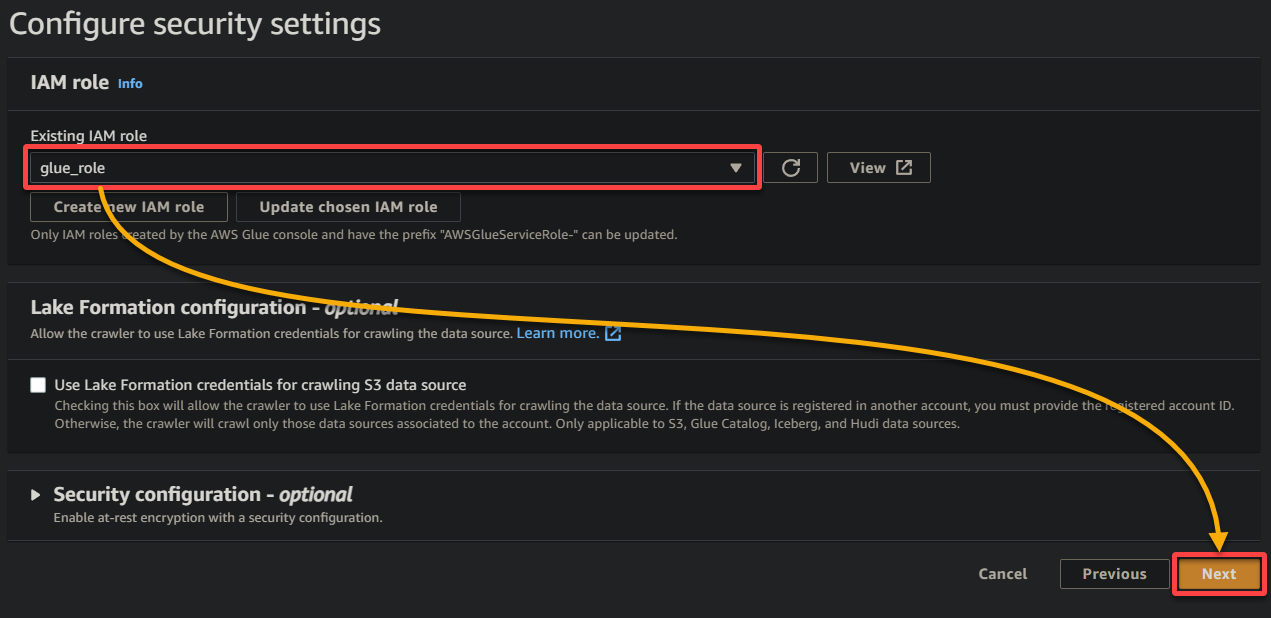
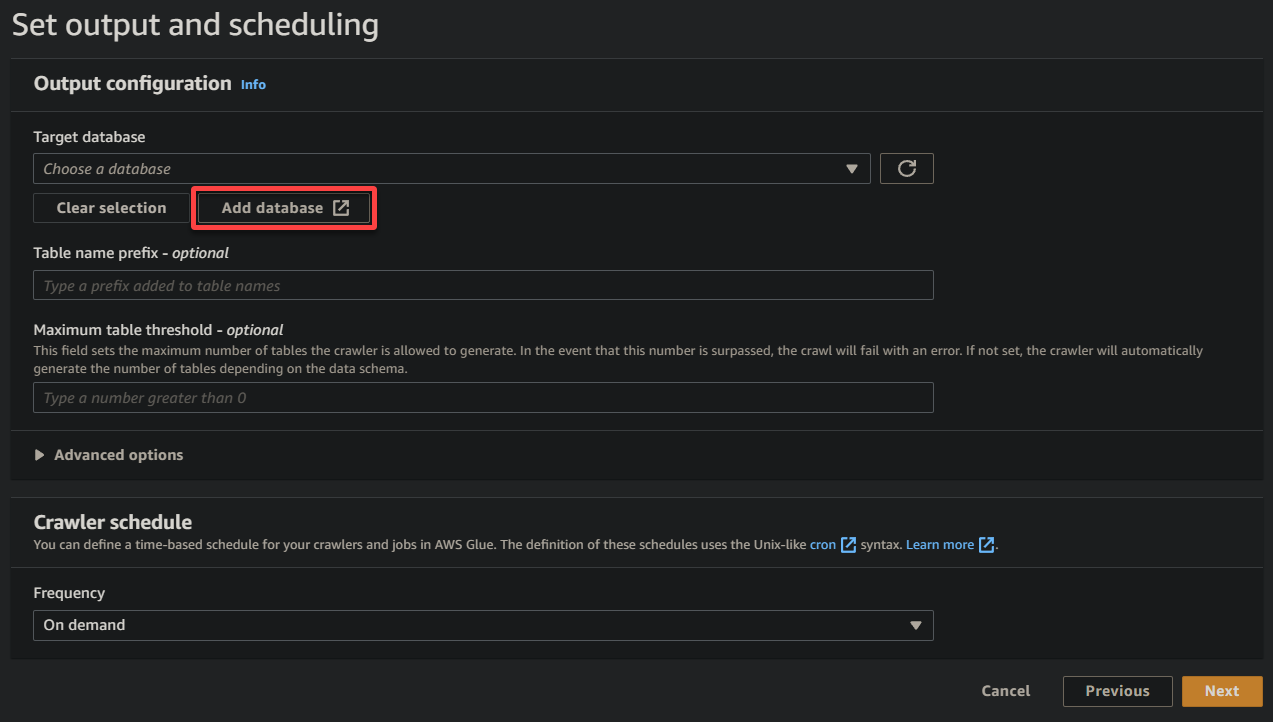
8. Onder uitvoer en planning, klik op Database toevoegen om het toevoegen van een nieuwe database te starten om de verwerkte gegevens en metadata op te slaan die door uw Glue-crawler worden gegenereerd. Deze actie opent een nieuw browsertabblad, waar u uw databasedetails zult configureren (stap acht).
Deze database biedt een gestructureerde representatie van de gegevens voor het opvragen en analyseren.
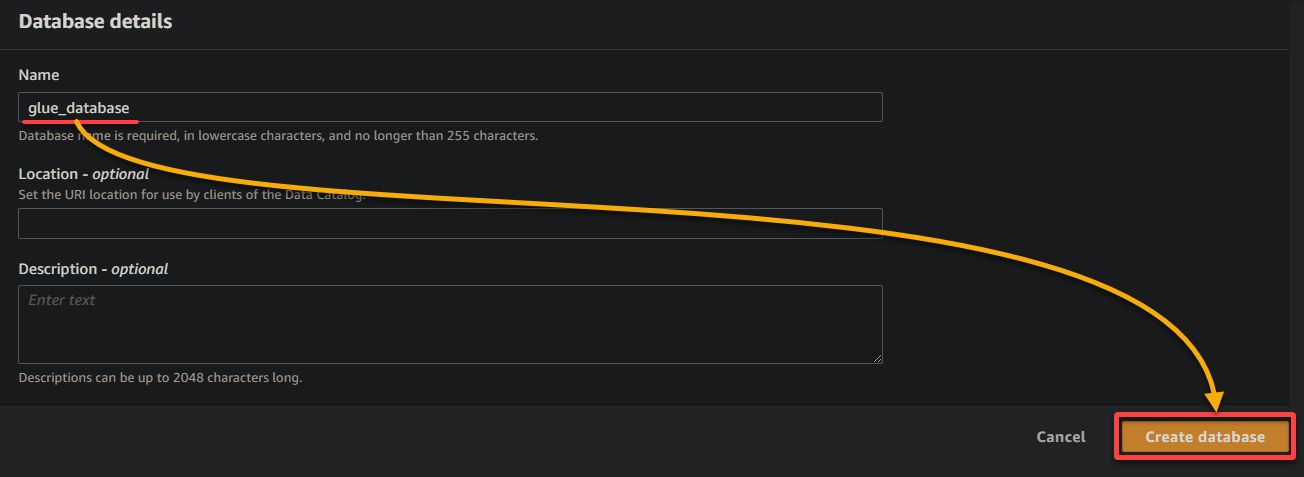
9. Op het nieuwe browsertabblad, geef een beschrijvende databasenaam op (bijv. glue_database) en klik op Database maken om de database te maken.
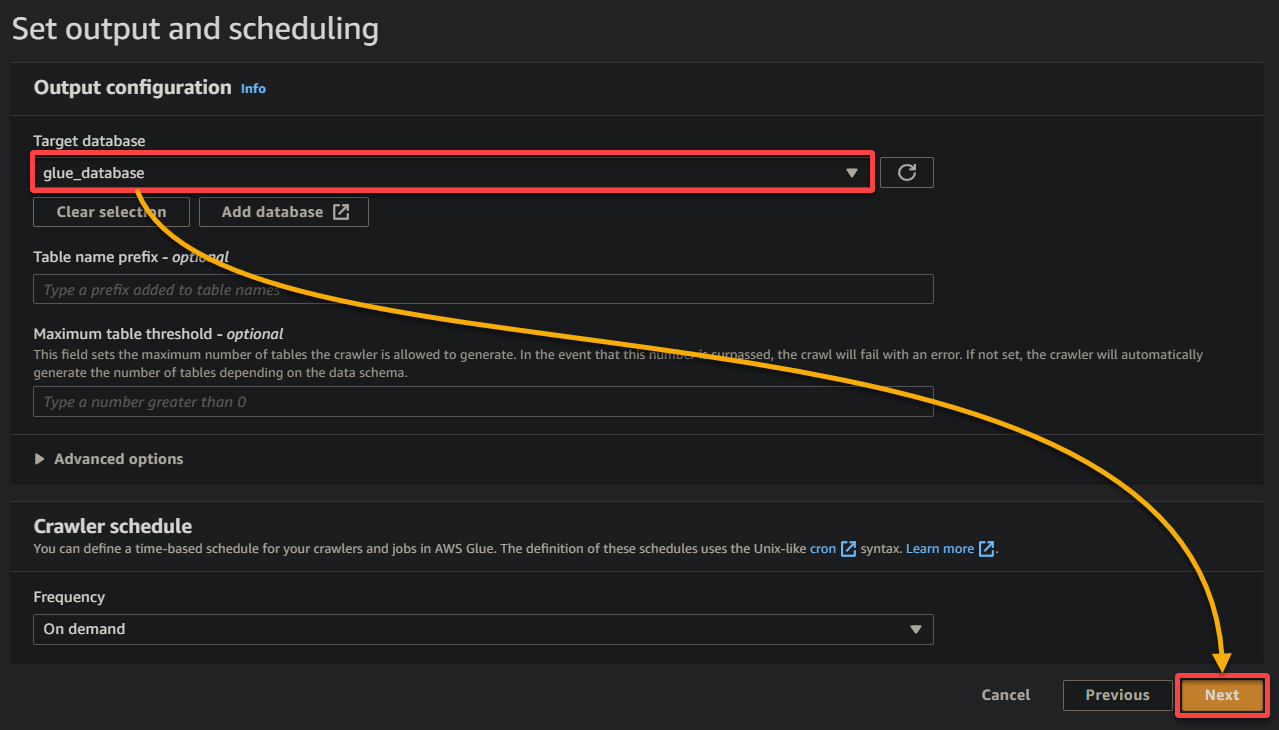
10. Schakel over naar het vorige browsertabblad, selecteer de nieuw gemaakte database (glue_database) uit het dropdownmenu, houd andere instellingen zoals ze zijn, en klik op Volgende.
11. Bekijk uiteindelijk uw instellingen op het laatste scherm om ervoor te zorgen dat ze correct zijn, en klik op Crawler maken (rechtsonder) om de nieuwe crawler te maken.
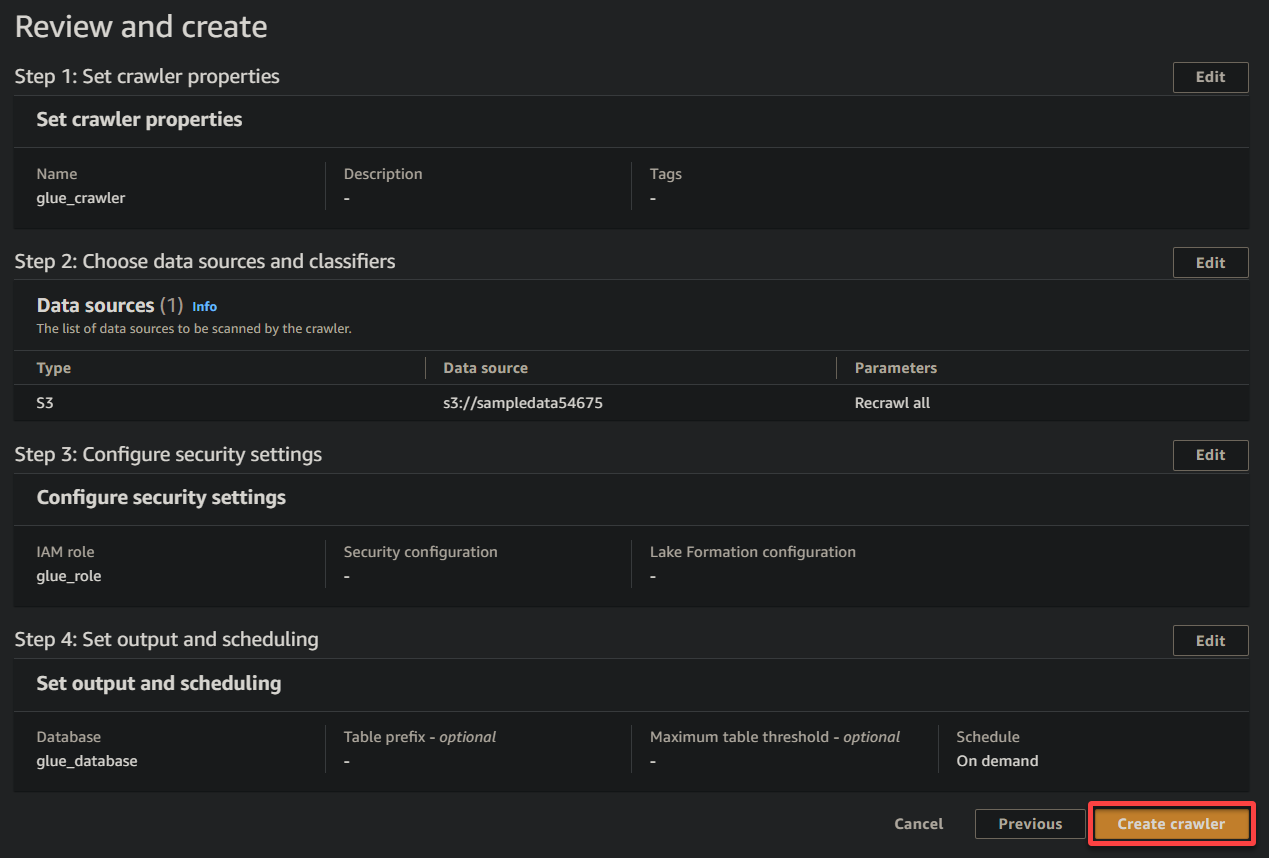
Als alles goed gaat, ziet u een scherm waarin de succesvolle creatie van de crawler wordt bevestigd. Sluit dit scherm nog niet; u zult deze crawler uitvoeren in de volgende sectie.
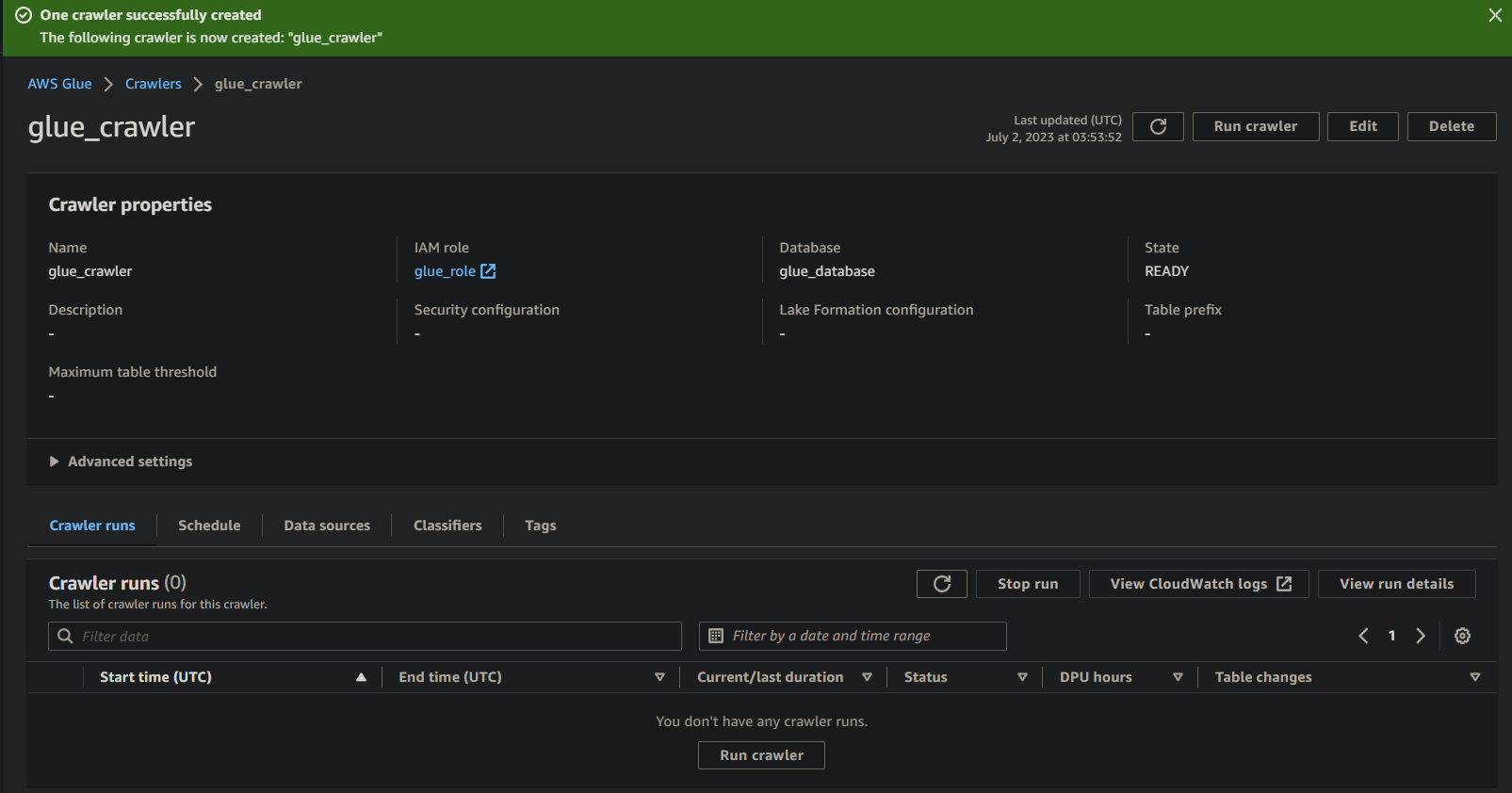
Het uitvoeren van de Glue Crawler om een Metadatabibliotheek op te bouwen
Met een nieuwe crawler tot uw beschikking is het essentieel om de crawler uit te voeren om het scan- en catalogusproces te starten. Uw glue-crawler zal een metadatabibliotheek opbouwen die een gestructureerde representatie van uw gegevens biedt voor vraag- en analyzedoeleinden.
Om uw nieuw gecreëerde glue-crawler uit te voeren, volgt u deze stappen:
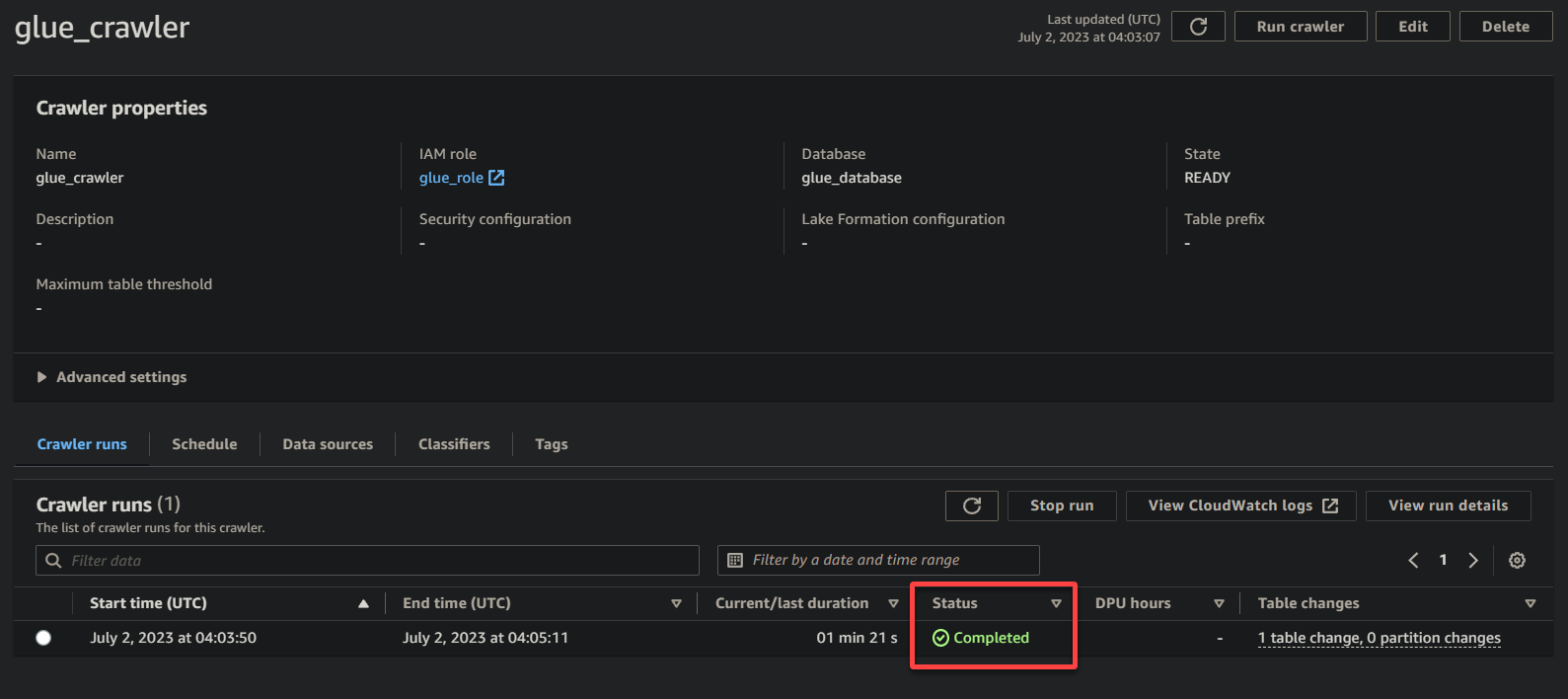
1. Op de pagina met crawlerdetails klikt u op Crawler uitvoeren onder het tabblad Crawl-runs om de uitvoering van de crawler te starten.
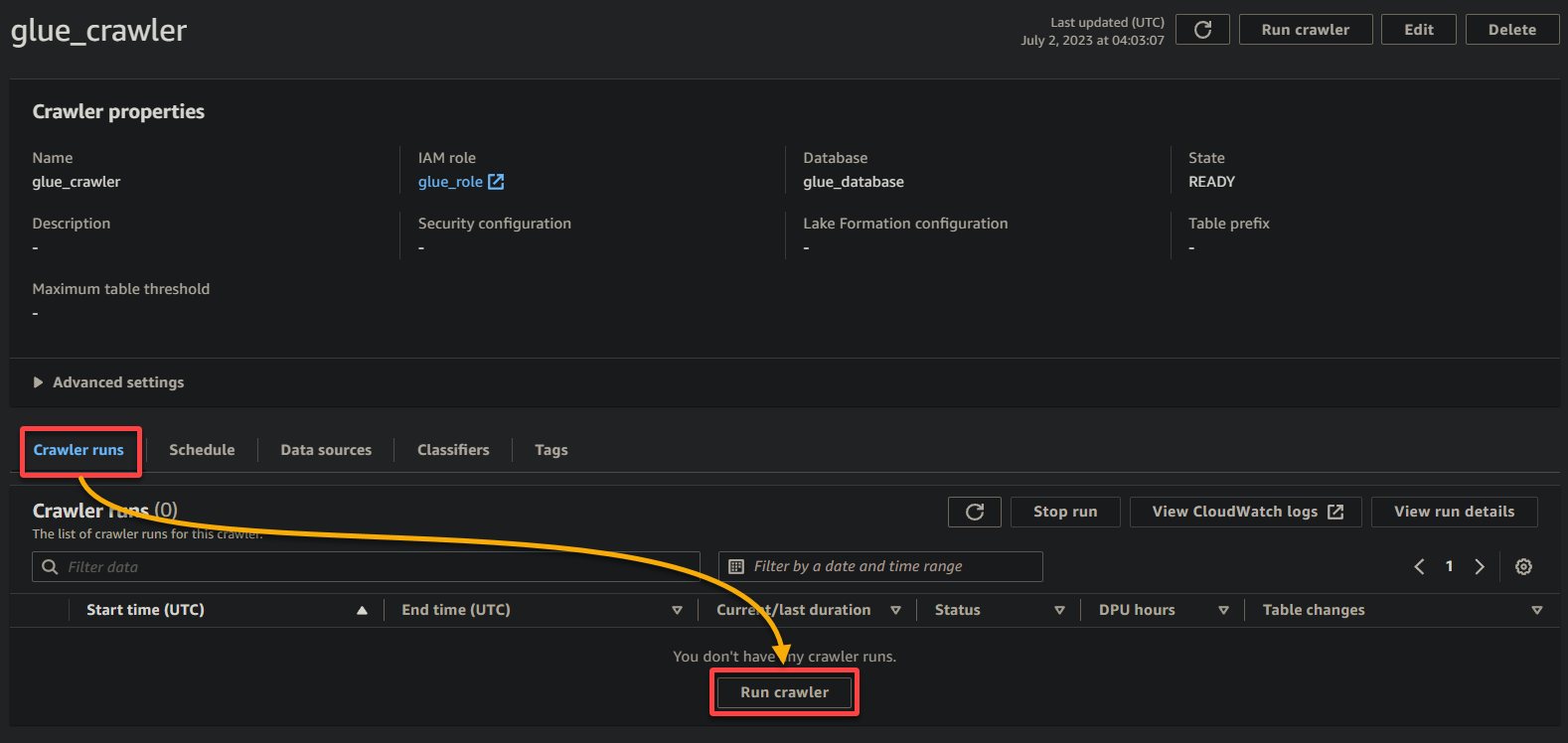
Zodra de crawler begint met uitvoeren, ziet u de status en voortgang op de pagina met crawlerdetails.
Afhankelijk van de omvang en complexiteit van uw gegevens kan het even duren voordat de crawler de uitvoering heeft voltooid. U kunt de pagina periodiek vernieuwen om de bijgewerkte status van de crawler te zien.
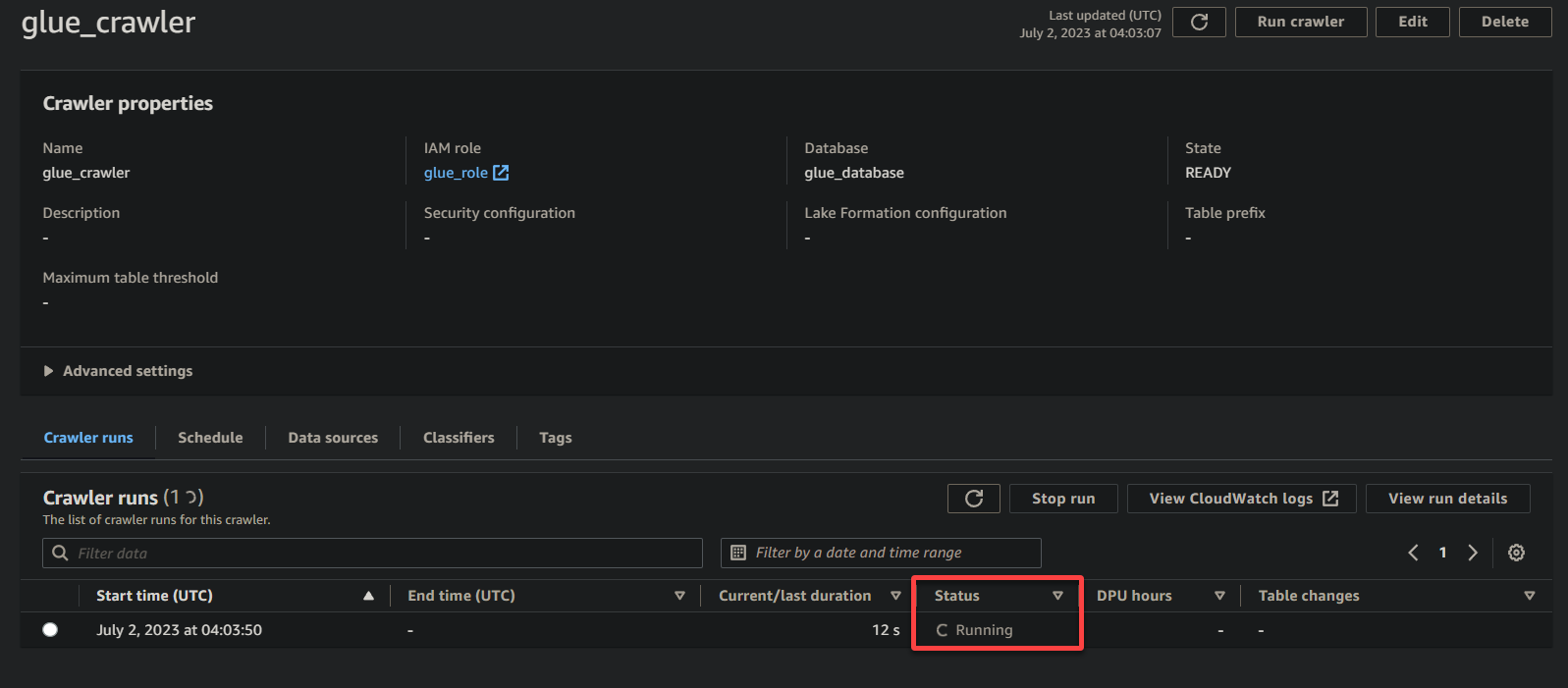
Zodra de crawler de uitvoering heeft voltooid, verandert de status in Voltooid, zoals hieronder weergegeven. Op dit punt kunt u doorgaan met het bevragen van uw gegevens.
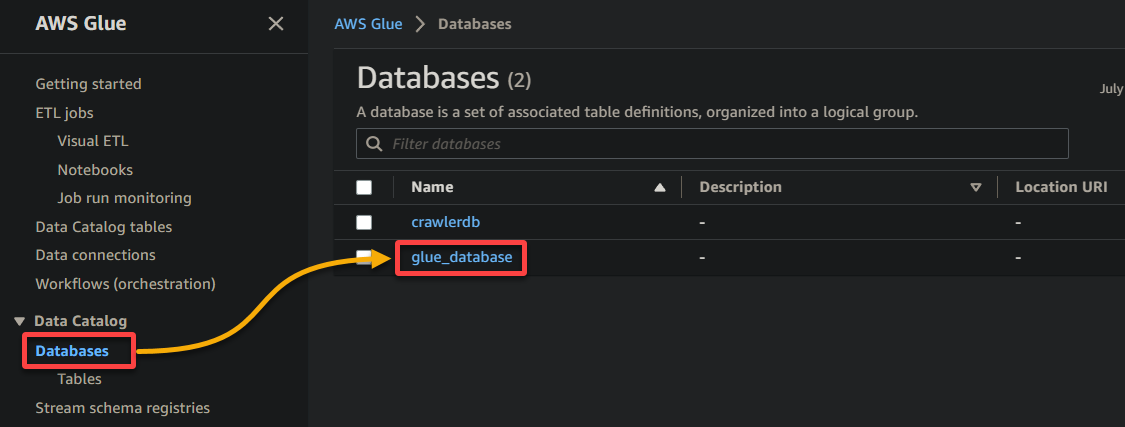
2. Ga vervolgens naar Database (linkerpaneel) en klik op uw database om toegang te krijgen tot de eigenschappen en tabellen.
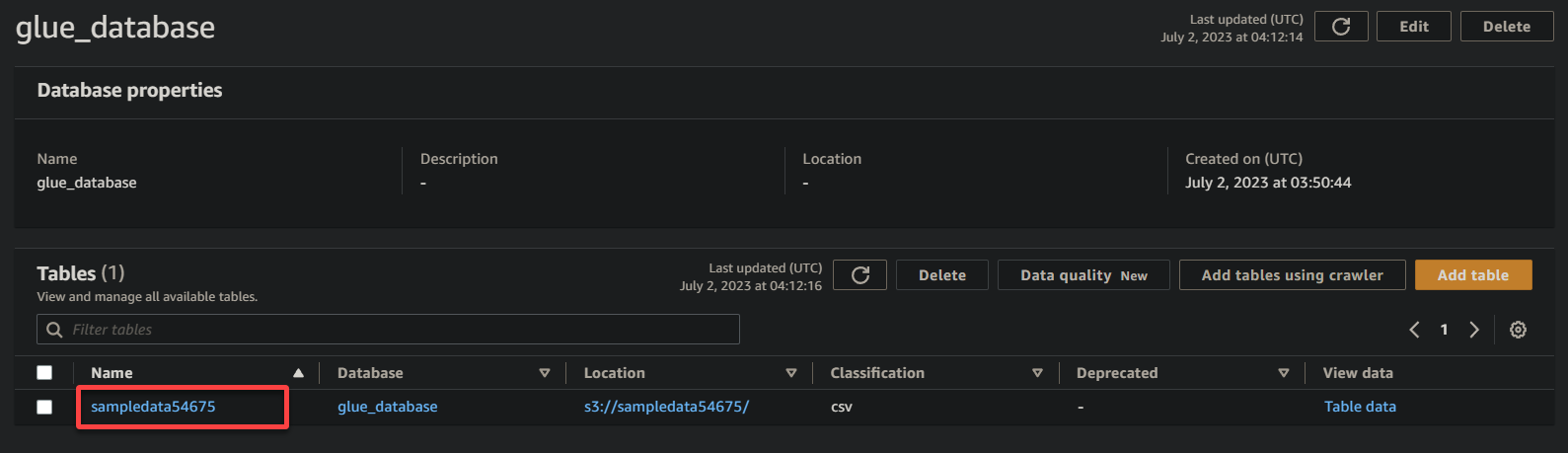
3. Klik ten slotte op de naam van uw bucket (sampledata54675), nu een tabel, om de opgeslagen gegevens te bekijken.
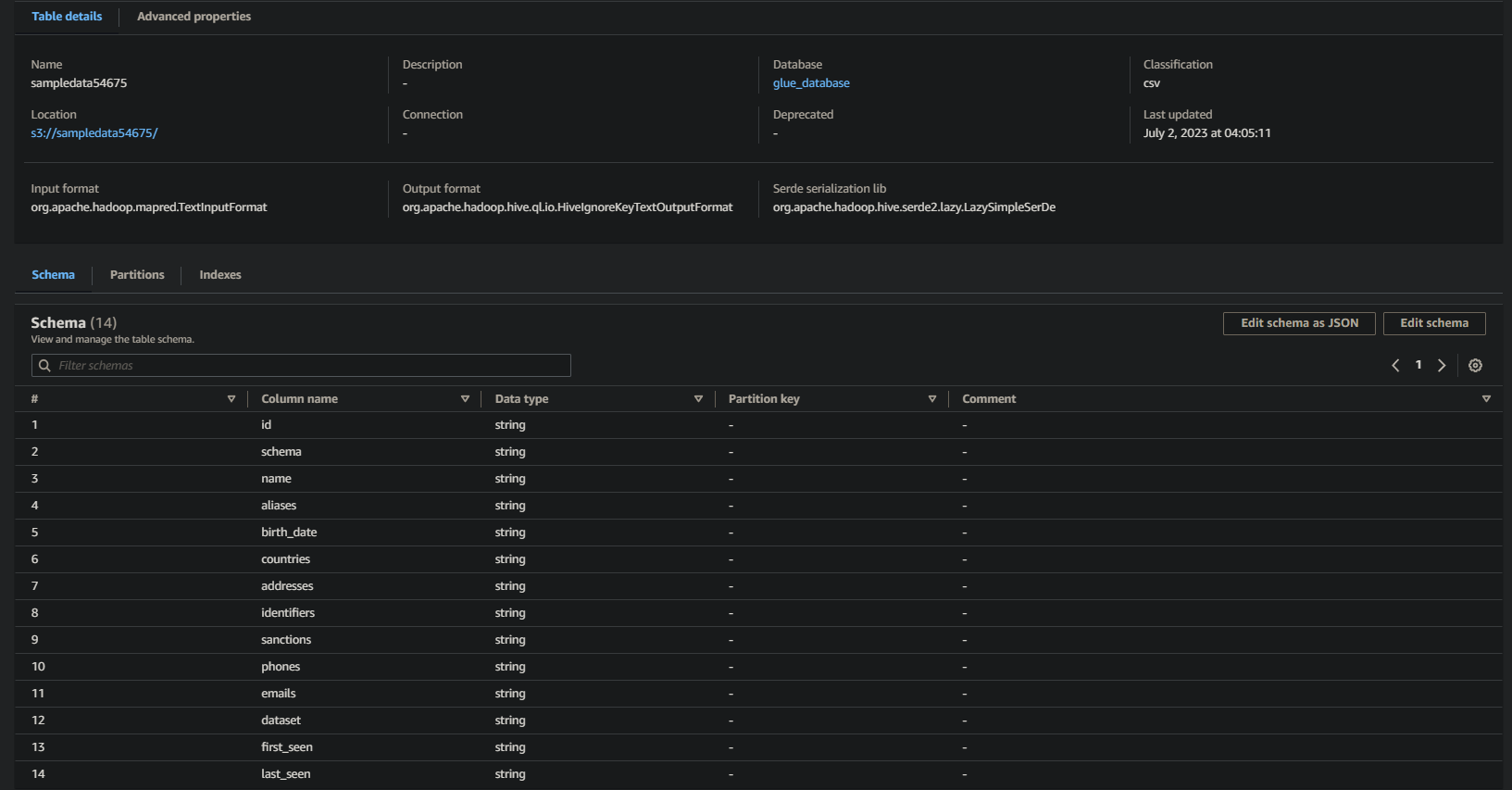
Als het succesvol is, ziet u informatie vergelijkbaar met hieronder. Deze informatie bevestigt dat de gegevens succesvol zijn omgezet in de databasetabel, met waardevolle details.
Gegevens bevragen via AWS Athena
Nu uw gegevens beschikbaar zijn in de AWS Glue Data Catalogus, kunt u verschillende tools gebruiken om uw gegevens te bevragen en te analyseren. Een van die tools is AWS Athena, een interactieve queryservice waarmee u gegevens in de cloud kunt analyseren met standaard SQL.
Om de gegevens te bevragen met behulp van AWS Athena, volgt u de onderstaande stappen:
1. Zoek naar en open de Athena-console.
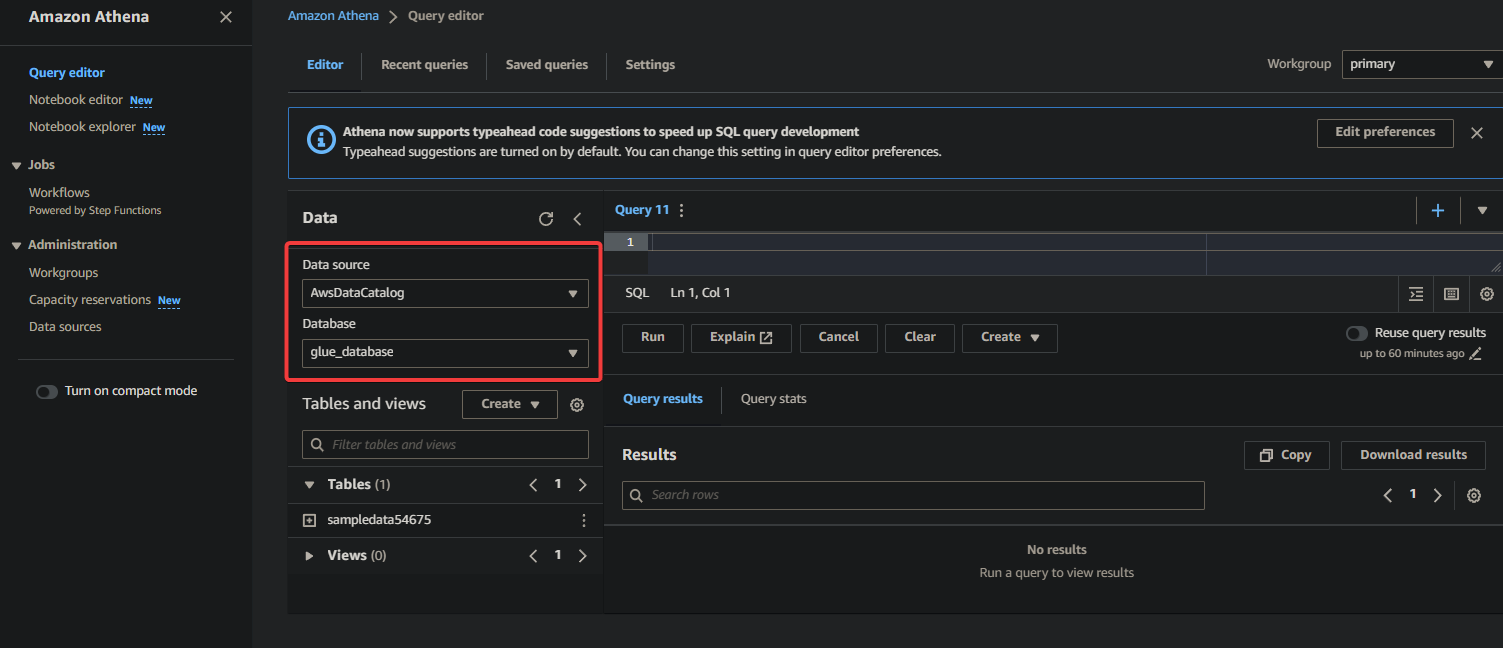
2. Selecteer de database waar uw gegevens zijn gecatalogiseerd onder de Data-sectie als volgt:
- Data bron – Selecteer AwsDataCatalogus om aan te geven dat u de gegevens wilt bevragen die zijn gecatalogiseerd in AWS Glue.
- Database – Selecteer de juiste database uit het vervolgkeuzemenu (bijv. glue_database).
? Als u uw gewenste database niet ziet in het vervolgkeuzemenu, zorg er dan voor dat de crawler zijn uitvoering heeft voltooid en de gegevens heeft gecatalogiseerd.
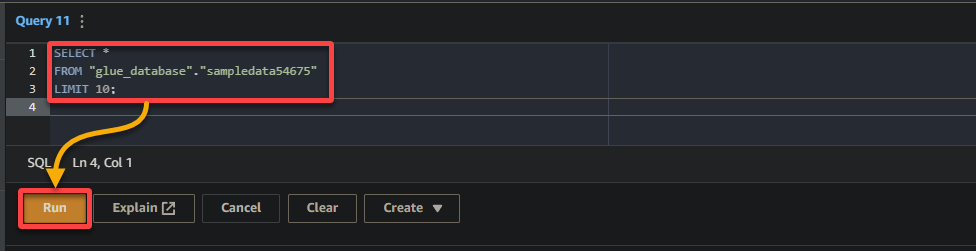
3. Vul tot slot de volgende query in en voer deze uit in de query-editor aan de rechterkant.
Deze query retourneert de eerste 10 rijen uit de tabel sampledata54675 in de database glue_database. Pas de query gerust aan om aan uw specifieke eisen te voldoen.
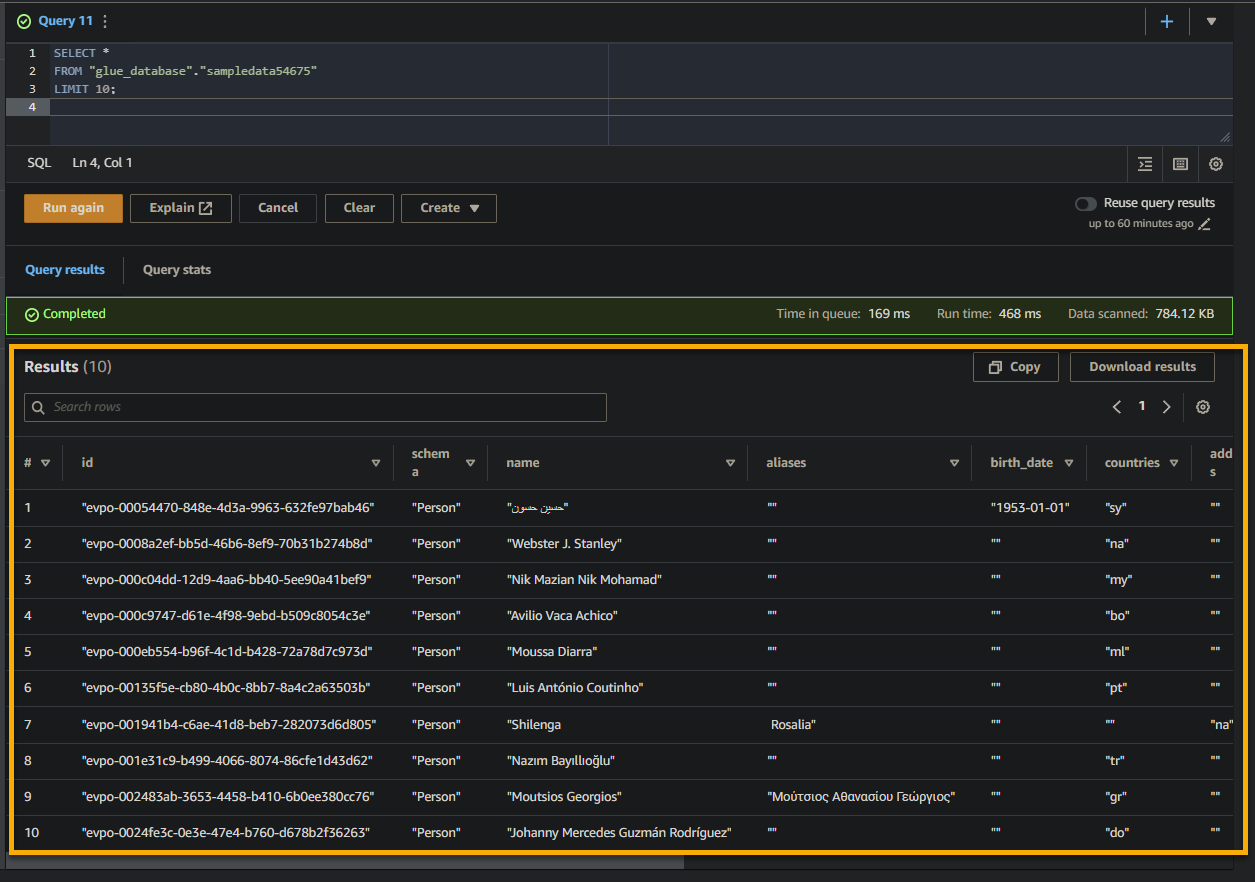
Als de query succesvol is, ziet u de resultaten in het Resultaat-paneel, zoals hieronder weergegeven. De resultaten bevatten informatie over de records die in de tabel zijn opgeslagen op basis van uw SQL-query.
Neem nota van de kolomnamen, gegevenstypen en waarden die worden teruggegeven in de resultaatset. Deze informatie helpt u de structuur en inhoud van de opgevraagde gegevens te begrijpen.
Conclusie
In deze tutorial heb je de basisprincipes geleerd van het gebruik van AWS Glue om een Glue Crawler te maken, je gegevens te catalogiseren en gegevens te bevragen met behulp van AWS Athena. Gegevensvoorbereiding en -analyse zijn essentieel voor elke op gegevens gebaseerde toepassing. En tools zoals AWS Glue bieden een snelle manier om gegevens uit verschillende bronnen te extraheren, transformeren en laden (ETL) in een databasetabel.
Met AWS Glue kun je nu snel gegevens beheren en organiseren, zodat je je meer kunt concentreren op het analyseren en afleiden van inzichten uit je gegevens. Maar wat je hebt gezien, is slechts het topje van de ijsberg. Ontdek het brede scala aan mogelijkheden en functionaliteiten die AWS Glue te bieden heeft!
Waarom niet profiteren van AWS Glue-verbindingen om naadloos te integreren met andere AWS-services, zoals Amazon RDS of Amazon Redshift? Deze integratie stelt je in staat om complexe ETL-pijplijnen te bouwen en nog grotere data-analysemogelijkheden te bereiken.