













RAG-systemen combineren de kracht van opzoekmechanismen en taalmodellen, waardoor ze contextueel relevante en goed onderbouwde antwoorden kunnen genereren. Echter, het evalueren van de prestaties en het identificeren van mogelijke falingsmodi van RAG-systemen kan een zeer moeilijke taak zijn.
Daarom is er de RAG Triade – een drietal metrieken die de drie belangrijkste stappen van de uitvoering van een RAG-systeem beslaan: Contextuele Relevantie, Gegrondheid en Antwoord Relevantie. In deze blogpost zal ik ingaan op de ingewikkeldheden van de RAG Triade en je door de hele procedure leiden om een RAG-systeem te evalueren, van opzetten tot uitvoeren en analyseren.
Inleiding tot de RAG Triade:
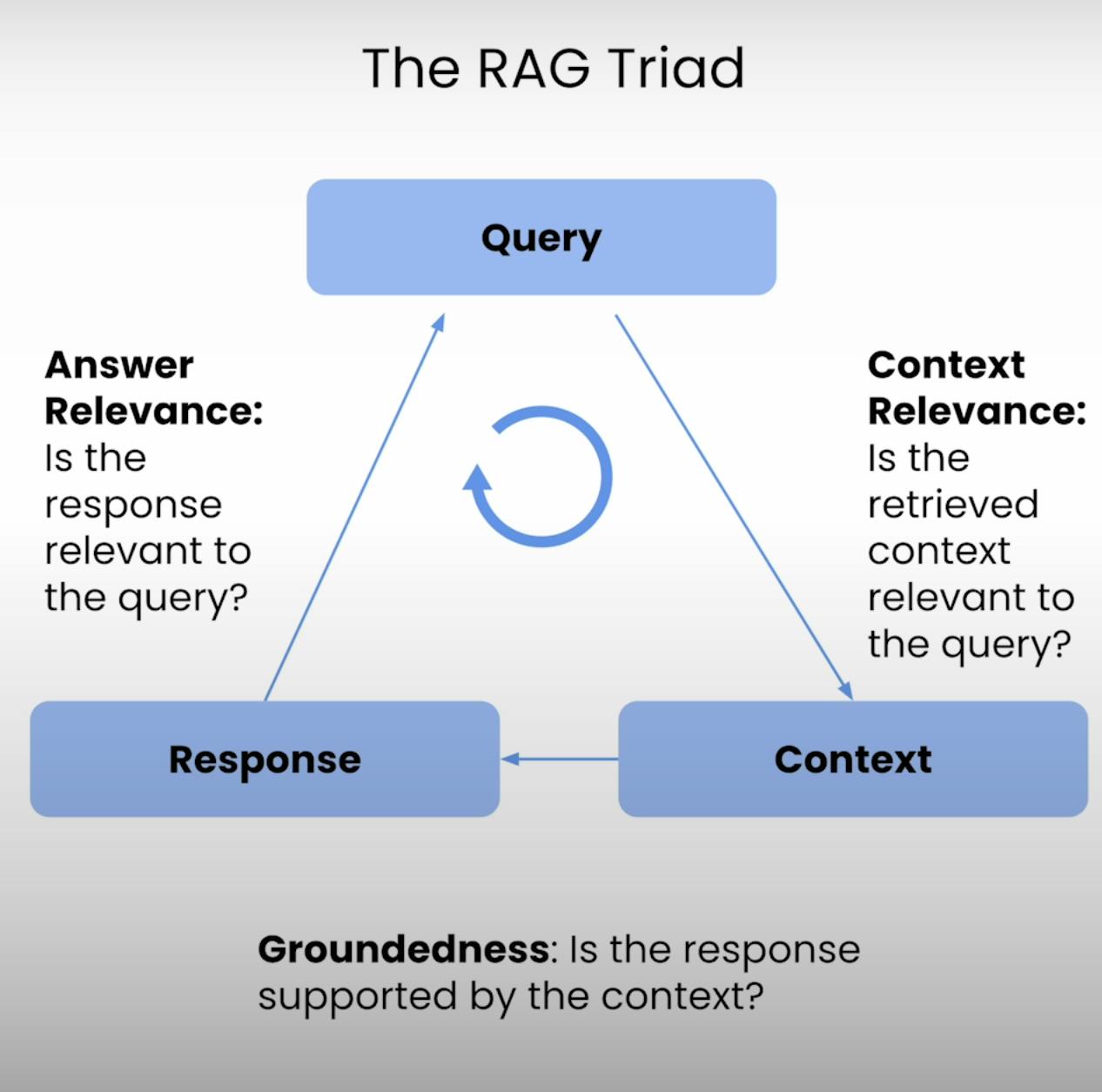
Het hart van elk RAG-systeem ligt in een fragiele balans tussen opzoeken en genereren. De RAG Triade biedt een uitgebreid kader om de kwaliteit en mogelijke falingsmodi van deze fragiele balans te evalueren. Laten we de drie componenten onder de loep nemen.
A. Context Relevance:
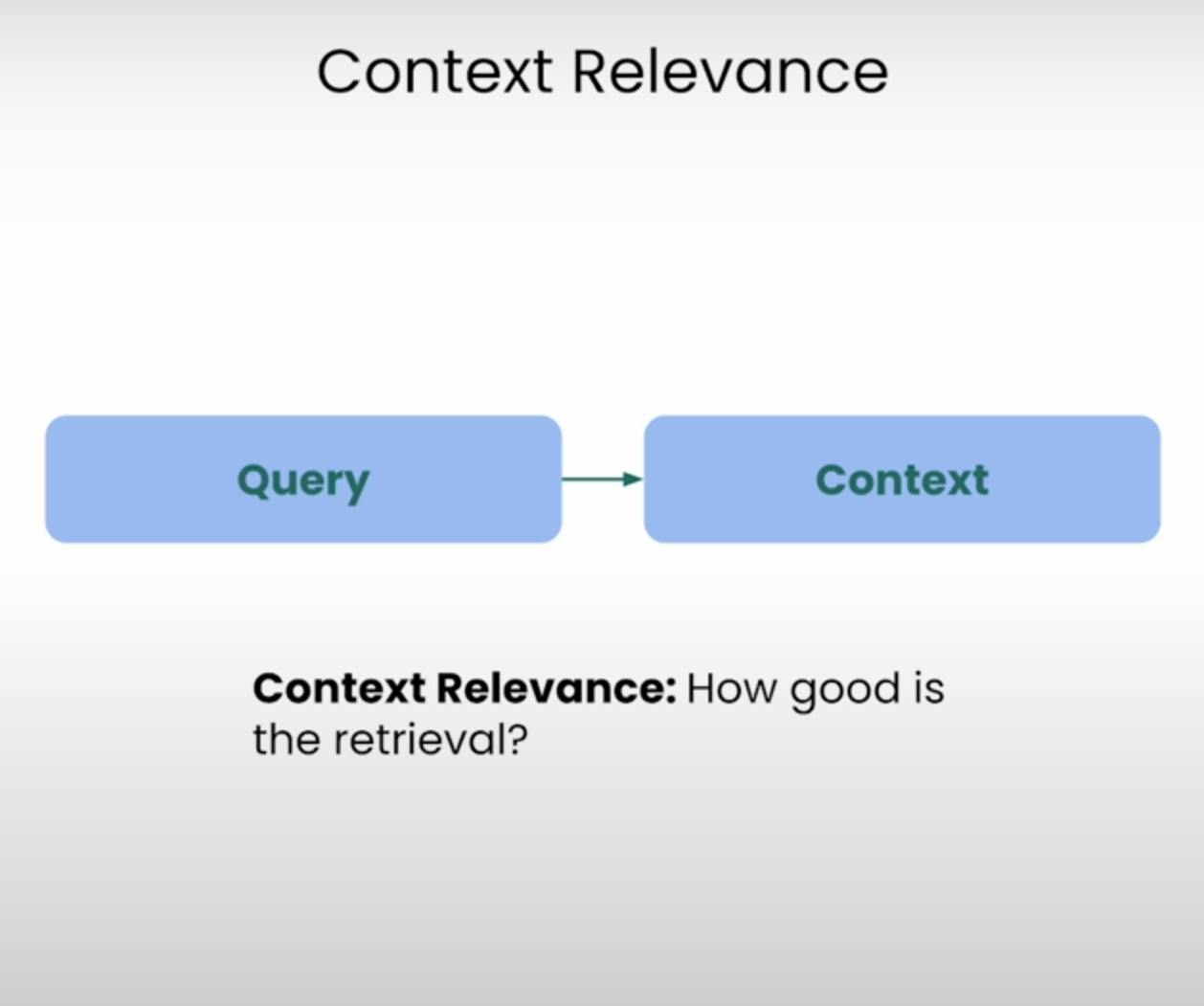
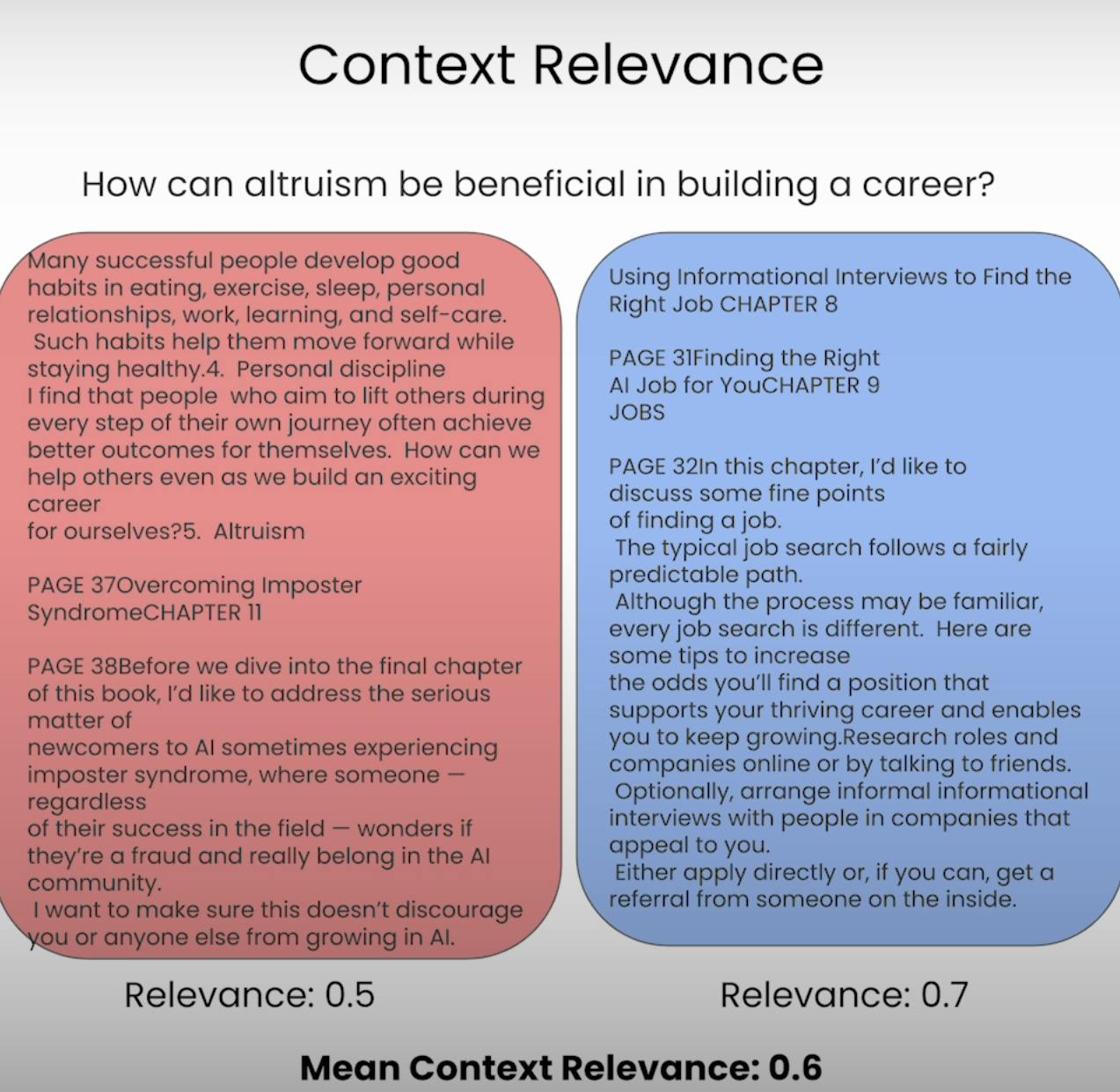
Stel je voor dat je een vraag moet beantwoorden, maar de informatie die je hebt gekregen is volkomen ongerelateerd. Dat is precies wat een RAG-systeem probeert te voorkomen. Contextuele Relevantie beoordeelt de kwaliteit van het opzoekproces door te evalueren hoe relevant elk stukje opgehaalde context is voor de oorspronkelijke vraag. Door de relevantie van de opgehaalde context te scoren, kunnen we eventuele problemen in het opzoekmechanisme identificeren en de nodige aanpassingen maken.

B. Groundedness:
Heb je ooit een gesprek gehad waarin iemand feiten leek te verzinnen of informatie gaf zonder solide onderbouwing? Dat is hetzelfde als een RAG-systeem dat gebrek aan gefundeerdheid heeft. Gefundeerdheid evalueert of de uiteindelijke respons van het systeem goed is gefundeerd in de opgehaalde context. Als de respons uitspraken of beweringen bevat die niet ondersteund worden door de opgehaalde informatie, kan het systeem aan het fantaseren zijn of te veel vertrouwen op zijn pre-trainingsgegevens, wat kan leiden tot potentiële onnauwkeurigheden of vooroordelen.
C. Answer Relevance:
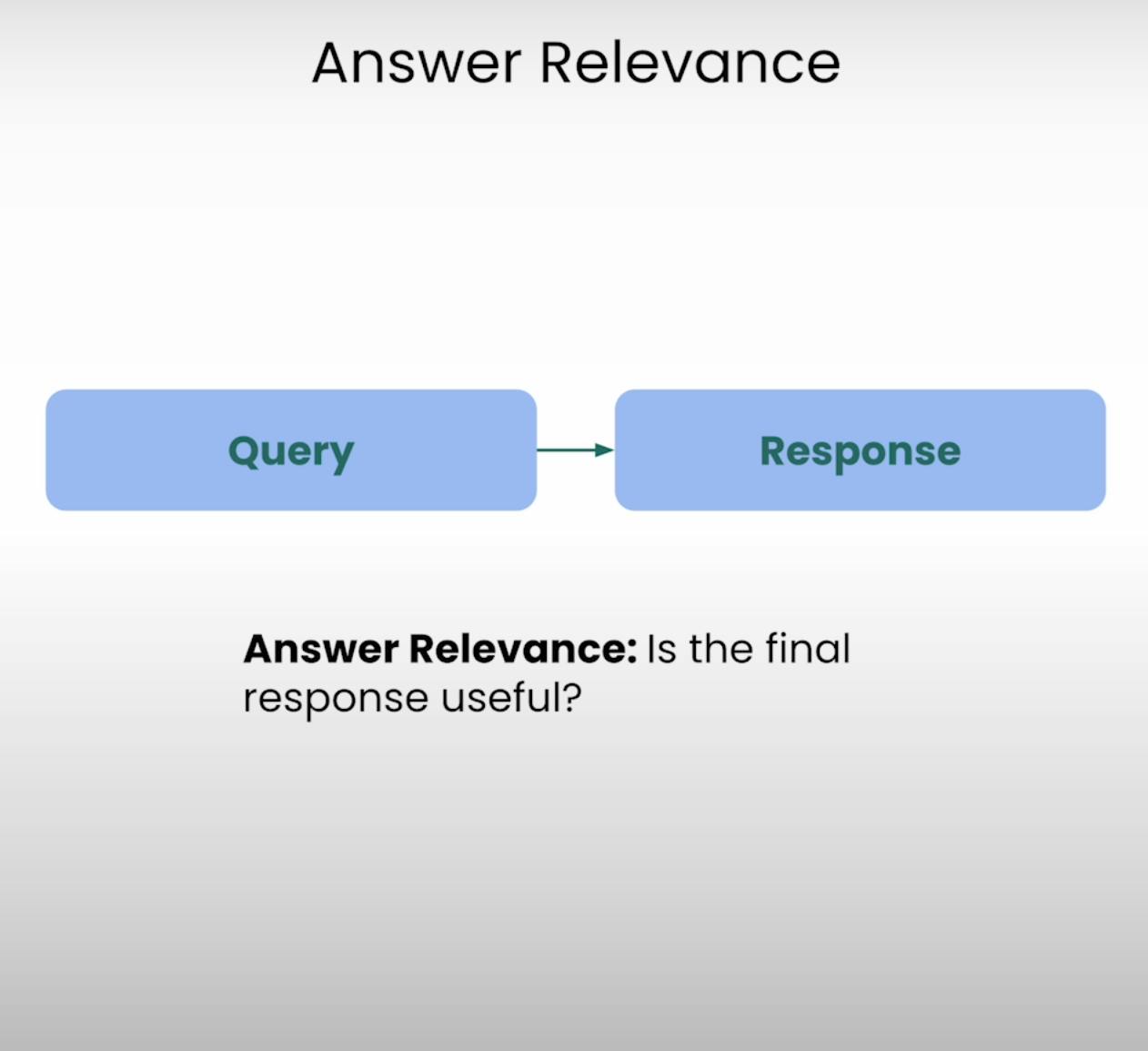
Stel je voor dat je om instructies vraagt voor de dichtstbijzijnde koffiewinkel en een gedetailleerde cakereceptuur krijgt. Dat is het soort situatie waar Answer Relevance voor wil voorkomen. Deze component van het RAG-drieluik evalueert of de uiteindelijke respons van het systeem echt relevant is voor de oorspronkelijke vraag. Door de relevantie van het antwoord te beoordelen, kunnen we situaties identificeren waarin het systeem de vraag misschien verkeerd heeft begrepen of van het bedoelde onderwerp is afgeweken.

Het opzetten van de RAG-drieluikevaluatie
Voordat we in de evaluatieproces kunnen duiken, moeten we de basis leggen. Laten we stap voor stap door de noodzakelijke stappen lopen om de RAG-drieluikevaluatie op te zetten.
A. Importing Libraries and Establishing API Keys:
Allereerst moeten we de vereiste bibliotheken en modules importeren, inclusief de API-sleutel van OpenAI en LLM-provider.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
Vervolgens laden en indexeren we de documentenkorpus waarmee on咱 RAG-systeem zal werken. In ons geval gebruiken we een PDF-document over “Hoe een Carrière in AI op te bouwen” door Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

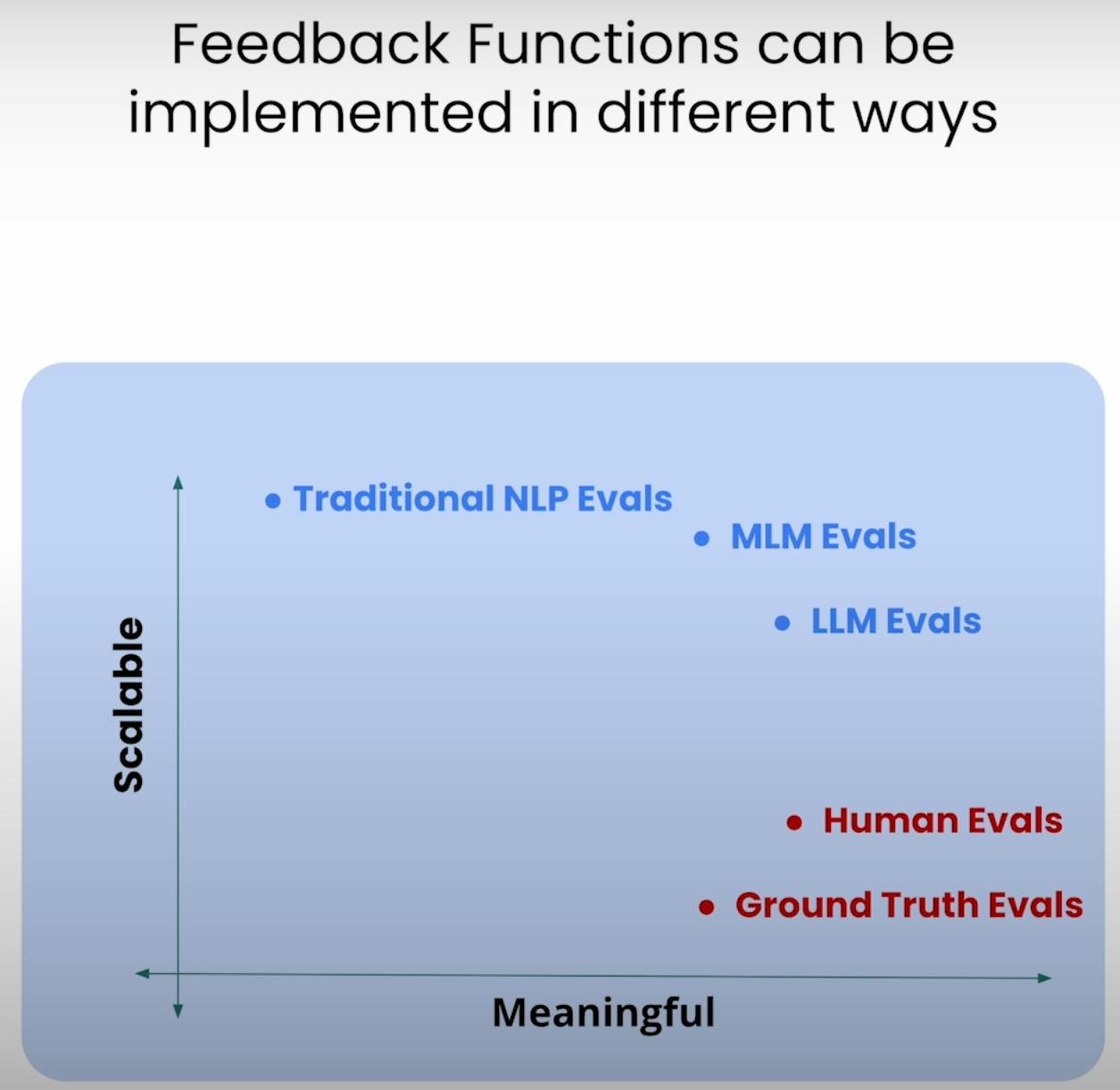
In het hart van de RAG Triade evaluatie liggen de feedbackfuncties – gespecialiseerde functies die elk onderdeel van de triade beoordelen. Laten we deze functies definiëren met behulp van de TrueLens bibliotheek.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Uitvoeren van de RAG-toepassing en evaluatie
Nu de setup compleet is, is het tijd om ons RAG-systeem en het evaluatiekader in actie te zetten. Laten we de stappen doorlopen die betrokken zijn bij het uitvoeren van de toepassing en het vastleggen van de evaluatieresultaten.
A. Preparing the Evaluation Questions:
Eerst laden we een set evaluatievragen die we willen laten beantwoorden door ons RAG-systeem. Deze vragen zullen als basis dienen voor ons evaluatieproces.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Vervolgens zullen we de TruLens recorder instellen, die ons helpt om de aanvragen, antwoorden en evaluatieresultaten op te slaan in een lokale database.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
Terwijl de RAG-toepassing draait voor elke evaluatievraag, zal de TruLens recorder ijverig de aanvragen, antwoorden, tussenresultaten en evaluatiescores vastleggen, ze opslaan in een lokale database voor verdere analyse.
Analyse van de evaluatieresultaten
Met de evaluatiedata in handen, is het tijd om in de analyse te duiken en inzichten te krijgen. Laten we kijken naar verschillende manieren waarop we de resultaten kunnen analyseren en potentieel verbeterpunten kunnen identificeren.
A. Examining Individual Record-Level Results:
Soms zit de duivel in de details. Door individuele recordresultaten te onderzoeken, kunnen we een dieper inzicht krijgen in de sterke en zwakke punten van ons RAG-systeem.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Deze codefragment geeft ons toegang tot de aanvragen, antwoorden en evaluatiescores voor elk individueel record, waardoor we specifieke gevallen kunnen identificeren waar het systeem misschien moeite had of uitblonk.
B. Viewing Aggregate Performance Metrics:
Laten we een stap terug doen en het grotere plaatje bekijken. De TrueLens-bibliotheek biedt ons een ranglijst die de prestatiemetingen over alle records samenvat, waardoor we een overzichtelijk beeld krijgen van de algehele prestaties van ons RAG-systeem.
tru.get_leaderboard(app_ids=[])
Deze ranglijst toont de gemiddelde scores voor elk onderdeel van het RAG Triade, samen met metingen zoals latentie en kosten. Door deze geaggregeerde metingen te analyseren, kunnen we trends en patronen identificeren die misschien niet duidelijk zijn op recordniveau.
C. Exploring the TrueLens Streamlit Dashboard:
Naast de CLI biedt TrueLens ook een Streamlit-dashbord dat een GUI biedt om de evaluatieresultaten te verkennen en te analyseren. Met enkele eenvoudige commando’s kunnen we het dashboard starten.
tru.run_dashboard()
Zodra het dashboard actief is, zien we een uitgebreid overzicht van de prestaties van ons RAG-systeem. In één oogopslag kunnen we de geaggregeerde metingen voor elk onderdeel van het RAG Triade zien, evenals informatie over latentie en kosten.
Door onze applicatie uit het dropdown-menu te selecteren, kunnen we toegang krijgen tot een gedetailleerd recordniveau-overzicht van de evaluatieresultaten. Elk record wordt netjes weergegeven, compleet met de invoerprompt van de gebruiker, de respons van het RAG-systeem en de bijbehorende scores voor Antwoord Relevantie, Context Relevantie en Gegrondheid.
Door op een individueel record te klikken, krijgen we meer inzichten te zien. We kunnen de redeneringsketen achter elke evaluatiescore verkennen, waardoor de denkprocessen van de taalmodel die de evaluatie uitvoert worden uitgelegd. Deze mate van transparantie is handig voor het identificeren van mogelijke falingsmodi en verbeterpunten.
Laten we aannemen dat we een record tegenkomen waarbij de Groundedness score laag is. Door de details te bekijken, kunnen we ontdekken dat de respons van het RAG-systeem uit uitspraken bestaat die niet goed gefundeerd zijn in de opgehaalde context. De dashboard zal ons precies tonen welke uitspraken gebrekkig bewijs ondersteunen, waardoor we de kernoorzaak van het probleem kunnen identificeren.
De TrueLens Streamlit dashboard is meer dan alleen een visualisatiegereedschap. Door gebruik te maken van zijn interactieve mogelijkheden en gegevensgestuurde inzichten, kunnen we geïnformeerde beslissingen nemen en gerichte acties ondernemen om de prestaties van onze applicaties te verbeteren.
Geavanceerde RAG-technieken en iteratieve verbetering
A. Introducing the Sentence Window RAG Technique:
Een geavanceerde techniek is de Sentence Window RAG, die een veelvoorkomende falingsmodus van RAG-systemen aanpakt: beperkte contextgrootte. Door de contextvenstergrootte te vergroten, probeert de Sentence Window RAG het taalmodel meer relevant en uitgebreid informatie te bieden, wat potentieel verbeteringen in de Context Relevance en Groundedness van het systeem kan opleveren.
B. Re-evaluating with the RAG Triad:
Na de implementatie van de Sentence Window RAG-techniek kunnen we deze testen door het opnieuw te evalueren met behulp van hetzelfde RAG Triad-raamwerk. Deze keer zullen we ons focussen op de Context Relevance en Groundedness scores, op zoek naar verbeteringen in deze gebieden als gevolg van de vergrote contextgrootte.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Hoewel de Sentence Window RAG-techniek potentieel prestatieverbeteringen kan opleveren, kan de optimale venstergrootte variëren afhankelijk van de specifieke gebruikscase en dataset. Een te kleine venstergrootte kan niet genoeg relevante context bieden, terwijl een te grote venstergrootte irrelevante informatie kan introduceren, wat de Groundedness en Answer Relevance van het systeem kan beïnvloeden.
Door te experimenteren met verschillende venstergroottes en opnieuw te evalueren met behulp van de RAG Triade, kunnen we de ideale afstemming vinden tussen contextrelevantie, verankering en antwoordrelevantie, wat uiteindelijk leidt tot een robuuster en betrouwbaarder RAG-systeem.
Conclusie:
De RAG Triade, bestaande uit Context Relevantie, Verankering en Antwoord Relevantie, heeft bewezen een nuttig kader te zijn voor het evalueren van de prestaties en het identificeren van mogelijke falingsmodi van Retrieval-Augmented Generation-systemen.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems