













はじめに
このチュートリアルでは、入力ビデオから音声を抽出し、抽出した音声を転写し、転写に基づいて字幕ファイルを生成し、そして入力ビデオのコピーに字幕を追加することができるPythonアプリケーションを作成します。
このアプリケーションを作成するために、FFmpegを使用して入力ビデオから音声を抽出します。抽出した音声の転写にはOpenAIのWhisperを使用し、この転写を元に字幕ファイルを生成します。さらに、生成された字幕ファイルを入力ビデオのコピーに追加するためにFFmpegを使用します。
FFmpegは、オーディオやビデオの処理など、マルチメディアデータを扱うための強力でオープンソースのソフトウェアスイートです。さまざまなフォーマットとコーデックに対応した、変換、編集、操作が可能なコマンドラインツールを提供しています。
OpenAIのWhisperは、口頭での言語を書き込まれたテキストに変換するための自動音声認識(ASR)システムです。多言語およびマルチタスキングの教師付きデータを大量に学習し、高い精度でさまざまなオーディオコンテンツを転写することが得意です。
このチュートリアルの最後までに、ビデオに字幕を追加することができるアプリケーションが完成します。
前提条件
このチュートリアルに従うためには、以下のツールが必要です:
-
FFmpegのインストール。
-
Pythonの基本的な理解。Pythonでコーディングする方法については、このチュートリアルシリーズを参考にすることができます。
ステップ1 — プロジェクトのルートディレクトリの作成
このセクションでは、プロジェクトディレクトリを作成し、入力ビデオをダウンロードし、仮想環境を作成してアクティブにし、必要なPythonパッケージをインストールします。
ターミナルウィンドウを開き、プロジェクトに適した場所に移動します。次のコマンドを実行してプロジェクトディレクトリを作成します:
プロジェクトディレクトリに移動します:
この編集済みのビデオをダウンロードし、プロジェクトのルートディレクトリにinput.mp4という名前で保存してください。このビデオは、Rushawnという子供がJermaine Edwardの「Beautiful Day」を歌っている様子を紹介しています。このチュートリアルで使用する編集済みのビデオは、次のYouTubeのビデオから取得されました:
新しい仮想環境を作成し、envという名前を付けてください:
仮想環境をアクティブにします:
次のコマンドを使用して、このアプリケーションをビルドするために必要なパッケージをインストールしてください:
上記のコマンドで、次のライブラリがインストールされました:
-
faster-whisper:OpenAIのWhisperモデルの再設計版で、Transformerモデルの高性能推論エンジンであるCTranslate2を活用しています。この実装では、同等の精度を持ちながら、最大4倍の高速化を実現し、より少ないメモリを消費します。 -
ffmpeg-pythonは、FFmpegツールのラッパーを提供するPythonライブラリであり、PythonスクリプトでFFmpegの機能と簡単にやり取りすることができます。Pythonicなインターフェースを通じて、編集、変換、操作などのビデオやオーディオの処理タスクを実行することができます。
次のコマンドを実行して、仮想環境でインストールされたパッケージをrequirements.txtという名前のファイルに保存します:
requirements.txtファイルは次のようになります:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
このセクションでは、プロジェクトディレクトリを作成し、このチュートリアルで使用する入力ビデオをダウンロードし、仮想環境をセットアップし、アクティブにし、必要なPythonパッケージをインストールしました。次のセクションでは、入力ビデオのトランスクリプトを生成します。
ステップ2 — ビデオトランスクリプトの生成
このセクションでは、アプリケーションが存在するPythonスクリプトを作成します。このスクリプト内で、前のセクションでダウンロードした入力ビデオからオーディオトラックを抽出し、WAVファイルとして保存するためにffmpeg-pythonライブラリを使用します。次に、抽出したオーディオに対してトランスクリプトを生成するためにfaster-whisperライブラリを使用します。
プロジェクトのルートディレクトリにmain.pyという名前のファイルを作成し、次のコードを追加します:
ここでは、コードはさまざまなライブラリとモジュール(time、math、ffmpeg from ffmpeg-python、およびfaster_whisperからのWhisperModelという名前のカスタムモジュール)をインポートしています。これらのライブラリは、ビデオとオーディオの処理、トランスクリプトの生成、字幕の生成に使用されます。
次に、コードは入力ビデオファイル名を設定し、それをinput_videoという定数に格納し、.mp4拡張子を除いたビデオファイル名をinput_video_nameという定数に格納します。ここで入力ファイル名を設定することで、複数の入力ビデオで作業し、それらに対して生成された字幕と出力ビデオファイルを上書きせずに済みます。
main.pyの最後に次のコードを追加します:
上記のコードは、extract_audio()という名前の関数を定義しています。この関数は、入力ビデオからオーディオを抽出する責任を持ちます。
まず、入力ビデオの基本名にaudio-を付け加え、.wav拡張子を追加して抽出されるオーディオの名前を設定し、この名前をextracted_audioという定数に保存します。
次に、コードはffmpegライブラリのffmpeg.input()メソッドを呼び出し、入力ビデオを開き、streamという入力ストリームオブジェクトを作成します。
その後、コードはffmpeg.output()メソッドを呼び出して、入力ストリームと定義された抽出されたオーディオファイル名を使用して出力ストリームオブジェクトを作成します。
出力ストリームを設定した後、コードはffmpeg.run()メソッドを呼び出し、出力ストリームをパラメータとして渡してオーディオ抽出プロセスを開始し、抽出されたオーディオファイルをプロジェクトのルートディレクトリに保存します。さらに、overwrite_output=Trueというブール型のパラメータが含まれており、既にそのようなファイルが存在する場合には新しく生成されたファイルで既存の出力ファイルを置き換えます。
最後に、コードは抽出されたオーディオファイルの名前を返します。
extract_audio()関数の下に以下のコードを追加してください。
ここでは、run()という名前の関数を定義し、それを呼び出します。この関数は、ビデオに字幕を生成して追加するために必要なすべての関数を呼び出します。
関数の内部では、コードはextract_audio()関数を呼び出してビデオからオーディオを抽出し、返されたオーディオファイル名をextracted_audioという変数に保存します。
ターミナルに戻り、以下のコマンドを実行してmain.pyスクリプトを実行します。
上記のコマンドを実行すると、FFmpegの出力がターミナルに表示され、入力ビデオから抽出されたオーディオが含まれるaudio-input.wavという名前のファイルがプロジェクトのルートディレクトリに保存されます。
main.pyファイルに戻り、extract_audio()関数とrun()関数の間に以下のコードを追加してください:
上記のコードは、入力ビデオから抽出したオーディオファイルを転写する責任を持つtranscribeという名前の関数を定義しています。
まず、コードはWhisperModelオブジェクトのインスタンスを作成し、モデルタイプをsmallに設定します。OpenAIのWhisperには次のモデルタイプがあります:tiny、base、small、medium、large。tinyモデルは最も小さくて高速であり、largeモデルは最も大きくて遅いですが、最も正確です。
次に、コードはmodel.transcribe()メソッドを呼び出し、抽出したオーディオを引数として渡して、セグメント関数とオーディオ情報を取得し、それぞれinfoとsegmentsという変数に格納します。セグメント関数はPythonのジェネレータなので、コードがそれを反復処理すると転写が開始されます。セグメントをlistやforループで集めることで、転写を完了させることができます。
次に、コードはオーディオで検出された言語を定数infoに格納し、それをコンソールに出力します。
言語を検出した後、コードはlistに転写セグメントを収集して転写を実行し、収集されたセグメントをsegmentsという変数に保存します。次に、コードは転写セグメントのリストをループして、各セグメントの開始時間、終了時間、およびテキストをコンソールに表示します。
最後に、コードはオーディオで検出された言語と転写セグメントを返します。
run()関数の内部に以下のコードを追加してください。
追加したコードは、抽出されたオーディオを引数としてtranscribe関数を呼び出し、返された値をlanguageとsegmentsという定数に保存します。
ターミナルに戻り、以下のコマンドを実行してmain.pyスクリプトを実行してください。
このスクリプトを初めて実行すると、コードは最初にWhisper Smallモデルをダウンロードしてキャッシュします。その後の実行ははるかに高速になります。
上記のコンソールには、オーディオで検出された言語が英語(en)であることが表示されます。さらに、各転写セグメントの開始時間と終了時間(秒単位)とテキストが表示されます。
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
警告:OpenAIのWhisper音声認識は非常に正確ですが、100%正確ではありません。特に言語やオーディオの状況が複雑な場合には、制限や時折のエラーが発生する可能性があります。必ず手動で転写を確認してください。
このセクションでは、アプリケーションのためのPythonスクリプトを作成しました。スクリプトの中で、ffmpeg-pythonを使用してダウンロードしたビデオからオーディオを抽出し、WAVファイルとして保存しました。その後、faster-whisperライブラリを使用して抽出したオーディオのトランスクリプトを生成しました。次のセクションでは、トランスクリプトに基づいて字幕ファイルを生成し、その後、ビデオに字幕を追加します。
ステップ3 – 字幕の生成とビデオへの追加
このセクションでは、まず、字幕ファイルとその構造について理解します。次に、前のセクションで生成されたトランスクリプトのセグメントを使用して字幕ファイルを作成します。字幕ファイルを作成した後、入力ビデオのコピーに字幕ファイルを追加するために、ffmpeg-pythonライブラリを使用します。
字幕の理解:構造とタイプ
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
字幕インデックス:ファイル内の字幕の順序を示す連番。
-
タイムコード:字幕テキストが表示されるべき時間を指定する開始時刻と終了時刻のマーカーです。タイムコードは通常、
HH:MM:SS,sss(時間、分、秒、ミリ秒)の形式でフォーマットされます。 -
字幕テキスト:口述または書かれたコンテンツを表す実際の字幕エントリのテキストです。このテキストは指定された時間間隔で画面に表示されます。
例えば、SRTファイルの字幕エントリは以下のようになります:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
この例では、インデックスは1で、タイムコードは字幕が10.5秒から15秒まで表示されることを示しており、字幕テキストはThis is an example subtitle.です。
字幕は主に2つのタイプに分けられます:
-
ソフト字幕:クローズドキャプションとも呼ばれ、別々のファイル(例:SRT)として外部に保存され、ビデオとは独立して追加または削除することができます。視聴者の柔軟性を提供し、切り替えや言語の切り替え、設定のカスタマイズが可能です。ただし、効果はビデオプレイヤーのサポートに依存し、すべてのプレイヤーがソフト字幕をサポートしているわけではありません。
-
ハードサブタイトル:編集やエンコード中にビデオフレームに永久に埋め込まれ、ビデオの一部として固定されます。外部の字幕ファイルに対するサポートがないプレーヤーでも一貫した表示が可能ですが、修正やオフにするにはビデオ全体の再エンコードが必要であり、ユーザーの制御が制限されます。
字幕ファイルの作成
main.pyファイルに戻り、transcribe()関数とrun()関数の間に次のコードを追加してください。
ここでは、format_time()という関数が定義されています。この関数は、与えられた転写セグメントの開始時間と終了時間(秒単位)を、時間、分、秒、ミリ秒(HH:MM:SS,sss)で表示する字幕互換の時間形式に変換する責任を持ちます。
コードはまず、与えられた時間(秒単位)から時間、分、秒、ミリ秒を計算し、適切な形式でフォーマットしてから、フォーマットされた時間を返します。
format_time()関数とrun()関数の間に以下のコードを追加してください:
追加したコードは、generate_subtitle_file()という関数を定義しています。この関数は、抽出された音声の検出言語と転写セグメントをパラメータとして受け取り、言語と転写セグメントに基づいたSRT形式の字幕ファイルを生成する責任を持ちます。
まず、コードは字幕ファイルの名前を入力ビデオの基本名にsub-と検出言語を追加し、拡張子を「.srt」として形成し、この名前をsubtitle_fileという定数に保存します。さらに、コードはtextという変数を定義し、そこに字幕のエントリを保存します。
次に、コードは転写セグメントを反復処理し、format_time()関数を使用して開始時間と終了時間をフォーマットし、これらのフォーマットされた値をセグメントのインデックスとテキストとともに字幕エントリを作成し、各字幕エントリを区切るために空行を追加します。
最後に、コードはプロジェクトのルートディレクトリに先に設定した名前で字幕ファイルを作成し、ファイルに字幕エントリを追加し、字幕ファイル名を返します。
以下のコードをrun()関数の最後に追加してください:
追加されたコードは、検出された言語と転写セグメントを引数としてgenerate_subtitle_file()関数を呼び出し、返された字幕ファイル名をsubtitle_fileという定数に格納します。
ターミナルに戻り、以下のコマンドを実行してmain.pyスクリプトを実行してください:
上記のコマンドを実行すると、sub-input.en.srtという名前の字幕ファイルがプロジェクトのルートディレクトリに保存されます。
sub-input.en.srt字幕ファイルを開くと、次のような内容が表示されるはずです:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
動画に字幕を追加する
generate_subtitle_file()関数とrun()関数の間に以下のコードを追加してください:
ここでは、コードはadd_subtitle_to_video()という関数を定義し、ソフト字幕またはハード字幕を追加するかを判断するためのブール値、字幕ファイル名、および転写で検出された言語をパラメータとして受け取ります。この関数は、入力ビデオのコピーにソフト字幕またはハード字幕を追加する責任を持ちます。
最初に、コードはffmpeg.input()メソッドを使用して、入力ビデオと字幕ファイルを使用して入力ストリームオブジェクトを作成し、それぞれvideo_input_streamおよびsubtitle_input_streamという名前の定数に保存します。
入力ストリームを作成した後、コードは出力ビデオファイルの名前を、入力ビデオのベース名にoutput-を追加し、拡張子を「.mp4」としたものに設定し、この名前をoutput_videoという定数に保存します。さらに、字幕トラックの名前を.srt拡張子を除いた字幕ファイルの名前に設定し、この名前をsubtitle_track_titleという定数に保存します。
次に、コードはブール型のsoft_subtitleがTrueに設定されているかどうかをチェックし、ソフト字幕を追加する必要があることを示します。
その場合、コードはffmpeg.output()メソッドを呼び出して、入力ストリーム、出力ビデオファイル名、および以下のオプションを使用して出力ストリームオブジェクトを作成します:
-
"c": "copy":入力から出力へビデオコーデックおよびその他のビデオパラメータを再エンコードせずに直接コピーすることを指定します。 -
"c:s": "mov_text":入力から出力への字幕コーデックとパラメーターの再エンコードなしでのコピーを指定します。mov_textは、MP4/MOV ファイルで使用される一般的な字幕コーデックです。 -
”metadata:s:s:0”: f"language={subtitle_language}":字幕ストリームの言語メタデータを設定します。言語はsubtitle_languageで指定された値に設定されます。 -
"metadata:s:s:0": f"title={subtitle_track_title}":字幕ストリームのタイトルメタデータを設定します。タイトルはsubtitle_track_titleで指定された値に設定されます。
最後に、コードは ffmpeg.run() メソッドを呼び出し、出力ストリームをパラメーターとして渡してソフト字幕をビデオに追加し、出力ビデオファイルをプロジェクトのルートディレクトリに保存します。
add_subtitle_to_video() 関数の最後に次のコードを追加してください。
ブール型のsoft_subtitleがFalseに設定されている場合、ハードサブタイトルを追加することを示すhighlightedコードが実行されます。
それが、最初に、コードはffmpeg.output()メソッドを呼び出して、入力ビデオストリーム、出力ビデオファイル名、およびvf=f"subtitles={subtitle_file}"パラメータを使用して出力ストリームオブジェクトを作成します。vfは「ビデオフィルタ」を表し、ビデオストリームにフィルタを適用するために使用されます。この場合、適用されるフィルタはサブタイトルの追加です。
最後に、コードはffmpeg.run()メソッドを呼び出し、出力ストリームをパラメータとして渡してビデオにハードサブタイトルを追加し、出力ビデオファイルをプロジェクトのルートディレクトリに保存します。
run()関数に以下のhighlightedコードを追加してください。
このhighlightedコードは、soft_subtitleパラメータをTrueに設定し、サブタイトルファイル名とサブタイトルの言語を指定して、入力ビデオのコピーにソフトサブタイトルを追加するadd_subtitle_to_video()を呼び出します。
ターミナルに戻り、以下のコマンドを実行してmain.pyスクリプトを実行してください。
上記のコマンドを実行すると、output-input.mp4という名前の出力ビデオファイルがプロジェクトのルートディレクトリに保存されます。
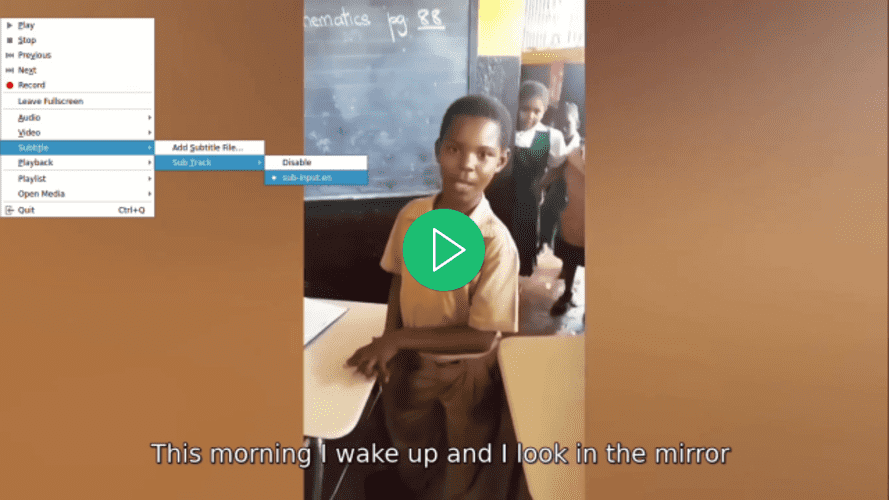
お好みのビデオプレーヤーでビデオを開き、ビデオにサブタイトルを選択して、サブタイトルが選択されるまで表示されないことに注意してください。
main.pyファイルに戻り、run()関数に移動し、add_subtitle_to_video()関数の呼び出しでsoft_subtitleパラメータをFalseに設定してください。
ここでは、soft_subtitleパラメータをFalseに設定して、ビデオにハードサブタイトルを追加します。
ターミナルに戻り、以下のコマンドを実行してmain.pyスクリプトを実行してください。
上記のコマンドを実行すると、プロジェクトのルートディレクトリにあるoutput-input.mp4ビデオファイルが上書きされます。
お好みのビデオプレーヤーを使用してビデオを開き、ビデオの字幕を選択しようとすると、まだ字幕が用意されていないにもかかわらず字幕が表示されていることに注意してください。

このセクションでは、SRT字幕ファイルの構造を理解し、前のセクションの転写セグメントを利用して字幕ファイルを作成しました。その後、ffmpeg-pythonライブラリを使用して生成された字幕ファイルをビデオに追加しました。
結論
このチュートリアルでは、ffmpeg-pythonおよびfaster-whisperのPythonライブラリを使用して、入力ビデオからオーディオを抽出し、抽出したオーディオを転写し、転写に基づいて字幕ファイルを生成し、入力ビデオのコピーに字幕を追加するアプリケーションを作成しました。