













コンピューティングの初期では、アプリケーションはタスクを順次処理していました。ユーザー数が数百万人に増加するにつれて、このアプローチは非現実的になりました。非同期処理により複数のタスクを同時に処理できるようになりましたが、単一のマシン上でスレッド/プロセスを管理することはリソースの制約や複雑さを引き起こしました。
このような時に分散並列処理が登場しました。複数のマシンにワークロードを分散させ、それぞれがタスクの一部に専念することで、スケーラブルで効率的なソリューションが提供されます。大量のファイルを処理する関数がある場合、ワークロードを複数のマシンに分割して、1台のマシンで順次処理するのではなく、ファイルを同時に処理できます。さらに、結合されたリソースを活用することでパフォーマンスが向上し、スケーラビリティと耐障害性が提供されます。要求が増加すると、利用可能なリソースを増やすためにより多くのマシンを追加できます。
規模に合わせた分散アプリケーションを構築および実行することは難しいですが、多くのフレームワークやツールがサポートしています。このブログ投稿では、そのようなオープンソースの分散コンピューティングフレームワークであるRayを調査します。また、クラウドネイティブ環境での分散コンピューティングのためにKubernetesクラスターとのシームレスなRay統合を可能にするKubeRayについても見ていきます。しかし、まずは分散並列処理がどのように役立つかを理解しましょう。
分散並列処理が役立つのはどこですか?
複数のマシンでの作業分散に利益をもたらすタスクは、分散並列処理を利用することができます。このアプローチは、Webクローリング、大規模データ解析、機械学習モデルのトレーニング、リアルタイムストリーム処理、ゲノムデータ解析、ビデオレンダリングなどのシナリオに特に有用です。複数のノード間でタスクを分散することで、分散並列処理は性能を大幅に向上させ、処理時間を短縮し、リソースの利用を最適化し、スループットが高く迅速なデータ処理が必要なアプリケーションにとって不可欠です。
分散並列処理が不要な場合
- 小規模なアプリケーション:小規模なデータセットや処理要件が最小限のアプリケーションの場合、分散システムの管理にかかるオーバーヘッドが正当化されないかもしれません。
- 強いデータの依存関係:タスクが高度に相互依存しており、容易に並列化できない場合、分散処理はほとんど利益をもたらさないかもしれません。
- リアルタイム制約:一部のリアルタイムアプリケーション(例:金融やチケット予約ウェブサイト)では、分散システムの複雑さにより極めて低いレイテンシが必要とされるため、達成できないかもしれません。
- リソースの制約:利用可能なインフラが分散システムのオーバーヘッドをサポートできない場合(例:ネットワーク帯域幅の不足、ノード数の制限)、単一マシンの性能を最適化する方がよい場合があります。
Rayが分散並列処理をサポートする方法
Rayは、分散並列処理フレームワークであり、障害耐性、スケーラビリティ、コンテキスト管理、通信など、私たちが議論した課題への解決策を含めた分散コンピューティングのすべての利点をカプセル化しています。これはPythonicフレームワークであり、既存のライブラリやシステムを使用してそれと連携することができます。Rayの助けを借りると、プログラマーは並列処理の計算レイヤーの各部分を処理する必要がありません。Rayは、指定されたリソース要件に基づいてスケジューリングやオートスケーリングを処理します。
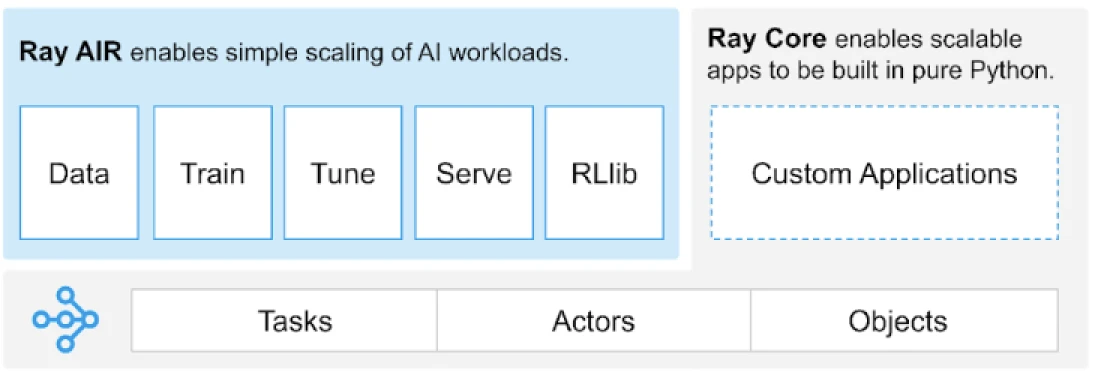
Rayは、分散アプリケーションを構築するためのタスク、アクター、オブジェクトのユニバーサルAPIを提供します。
(画像ソース)
Rayは、タスク、アクター、オブジェクト、ドライバー、ジョブなどのコアプリミティブに基づいて構築されたライブラリのセットを提供しています。これらは、分散アプリケーションを構築するのに役立つ多目的なAPIを提供します。では、コアプリミティブ、またはRay Coreを見てみましょう。
Ray Coreプリミティブ
- タスク: Ray タスクは、Ray クラスターノード上の別々の Python ワーカーで非同期に実行される任意の Python 関数です。ユーザーは、クラスタースケジューラが並列実行のためにタスクを配布するために使用する CPU、GPU、およびカスタムリソースのリソース要件を指定できます。
- アクター: タスクが関数に対応しているのに対し、アクターはクラスに対応しています。アクターは状態を持つワーカーであり、アクターのメソッドはその特定のワーカーでスケジュールされ、そのワーカーの状態にアクセスして変更できます。タスクと同様に、アクターは CPU、GPU、およびカスタムリソースの要件をサポートしています。
- オブジェクト: Ray では、タスクとアクターがオブジェクトを作成し計算します。これらのリモートオブジェクトは Ray クラスターのどこにでも格納できます。オブジェクト参照を使用してそれらを参照し、それらは Ray の分散共有メモリオブジェクトストアにキャッシュされます。
- ドライバー: プログラムのルート、または「メイン」プログラム: これは
ray.init()を実行するコードです。 - ジョブ: 同じドライバーから発信されるタスク、オブジェクト、およびアクターとそれらのランタイム環境から(再帰的に)派生するもののコレクション
プリミティブに関する情報は、Ray Core ドキュメントを参照してください。
Ray Core キーメソッド
以下は、一般的に使用される Ray Core 内の主要メソッドのいくつかです:
-
ray.init()– Rayランタイムを開始し、Rayクラスターに接続します。import ray ray.init()
-
@ray.remote– 異なるプロセスでタスク(リモート関数)またはアクター(リモートクラス)として実行されるPython関数またはクラスを指定するデコレータ@ray.remote def remote_function(x): return x * 2
-
.remote– リモート関数とクラスに後置され、リモート操作は非同期ですresult_ref = remote_function.remote(10)
-
ray.put()– オブジェクトをインメモリオブジェクトストアに配置し、そのオブジェクトを任意のリモート関数またはメソッド呼び出しに渡すために使用されるオブジェクト参照を返します。data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– オブジェクトストアからオブジェクト参照を指定してリモートオブジェクトを取得します。result = ray.get(result_ref) original_data = ray.get(data_ref)
基本的な主要メソッドのほとんどを使用する例です。
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# .remoteを使用してタスクを作成する
future = calculate_square.remote(5)
# 結果を取得する
result = ray.get(future)
print(f"The square of 5 is: {result}")Rayの動作は?
Ray Clusterは、プログラムの実行作業を共有するコンピューターチームのようなものです。ヘッドノードと複数のワーカーノードで構成されています。ヘッドノードはクラスターの状態とスケジューリングを管理し、ワーカーノードはタスクを実行しアクターを管理します
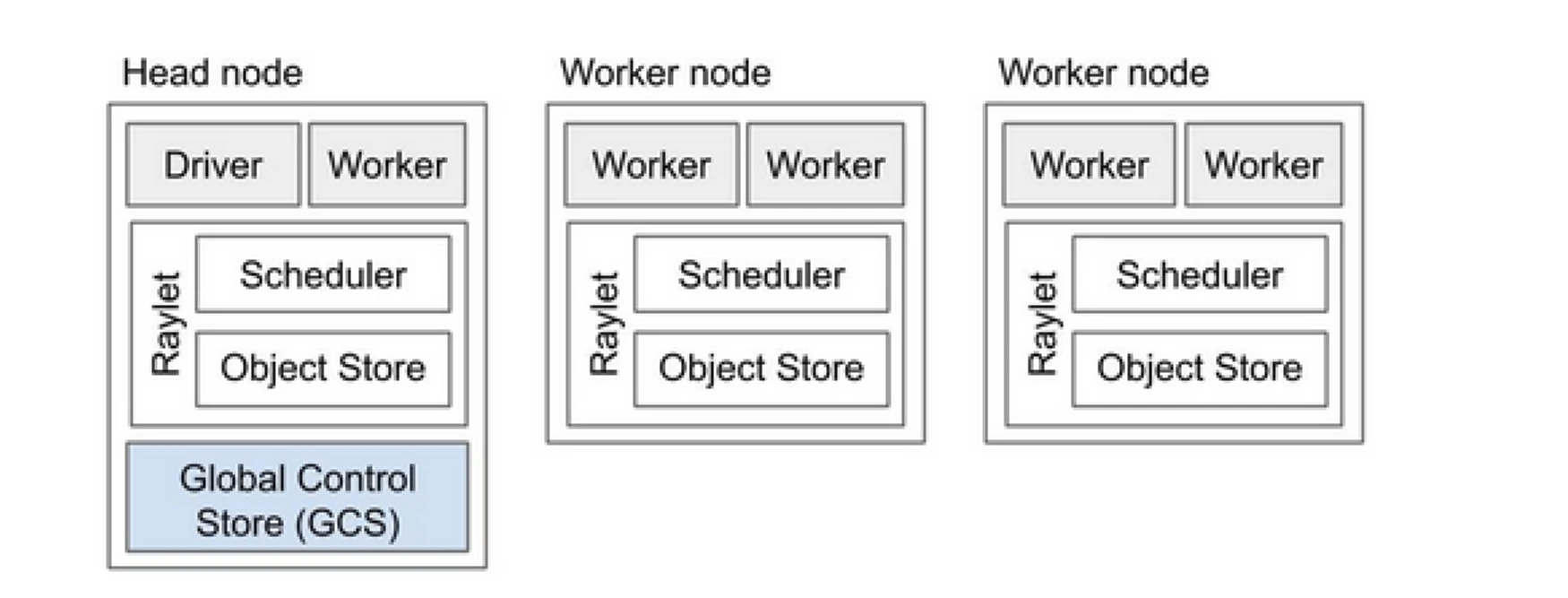
Ray Clusterのコンポーネント
- Global Control Store (GCS):GCSはRayクラスターのメタデータとグローバル状態を管理します。タスク、アクター、リソースの可用性を追跡し、すべてのノードがシステムの一貫したビューを持つようにします。
- スケジューラ:スケジューラはタスクとアクターを利用可能なノードに分散します。リソース要件とタスクの依存関係を考慮して、効率的なリソース利用と負荷分散を確保します。
- ヘッドノード:ヘッドノードはRayクラスター全体を統括します。GCSを実行し、タスクのスケジューリングを処理し、ワーカーノードの健康状態を監視します。
- ワーカーノード:ワーカーノードはタスクとアクターを実行します。実際の計算を実行し、オブジェクトをローカルメモリに保存します。
- Raylet:各ノードの共有リソースを管理し、すべての同時実行ジョブで共有されます。
詳細な情報についてはRay v2 Architectureドキュメントを参照してください。
既存のPythonアプリケーションを扱う際には、大きな変更は必要ありません。必要な変更は、主に自然に分散させる必要のある関数やクラスに関するものです。デコレーターを追加して、タスクやアクターに変換することができます。これを例を見てみましょう。
Python関数をRayタスクに変換する
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
PythonクラスをRayアクターに変換する
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Rayオブジェクトに情報を保存する
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
その概念について詳しく学ぶには、Ray Core Key Conceptのドキュメントにアクセスしてください。
Rayと従来の分散並列処理のアプローチ
以下は、従来の(Rayなしの)アプローチとKubernetes上のRayを比較した分析です。
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| デプロイメント | 手動設定と構成 | KubeRayオペレーターによる自動化 |
| スケーリング | 手動スケーリング | RayAutoScalerとKubernetesによる自動スケーリング |
| フォールトトレランス | カスタムフォールトトレランスメカニズム | KubernetesとRayによる組み込みフォールトトレランス |
| リソース管理 | 手動リソース割り当て | 自動リソース割り当てと管理 |
| 負荷分散 | カスタム負荷分散ソリューション | Kubernetes に組み込まれたロードバランシング |
| 依存関係管理 | 手動の依存関係のインストール | Docker コンテナで一貫した環境 |
| クラスター調整 | 複雑で手動的 | Kubernetes のサービス検出と調整により簡素化 |
| 開発オーバーヘッド | 高く、カスタムソリューションが必要 | Ray と Kubernetes が多くの側面を処理することで軽減 |
| 柔軟性 | 変動するワークロードに限定的な適応力 | ダイナミックスケーリングとリソースの割り当てによる高い柔軟性 |
Kubernetes は、その堅牢なオーケストレーション機能により、Ray のような分散アプリケーションを実行する理想的なプラットフォームを提供します。以下は、Kubernetes 上で Ray を実行する価値を設定する主要なポイントです:
- リソース管理
- スケーラビリティ
- オーケストレーション
- エコシステムとの統合
- 簡単な展開と管理
KubeRay Operator により、Kubernetes 上で Ray を実行することが可能になります。
KubeRay とは?
KubeRay Operator は、デプロイメント、スケーリング、およびメンテナンスなどのタスクを自動化することで、Kubernetes 上の Ray クラスターの管理を簡素化します。Ray 固有のリソースを管理するために Kubernetes のカスタムリソース定義(CRD)を使用します。
KubeRay CRD
それには3つの異なるCRDがあります:
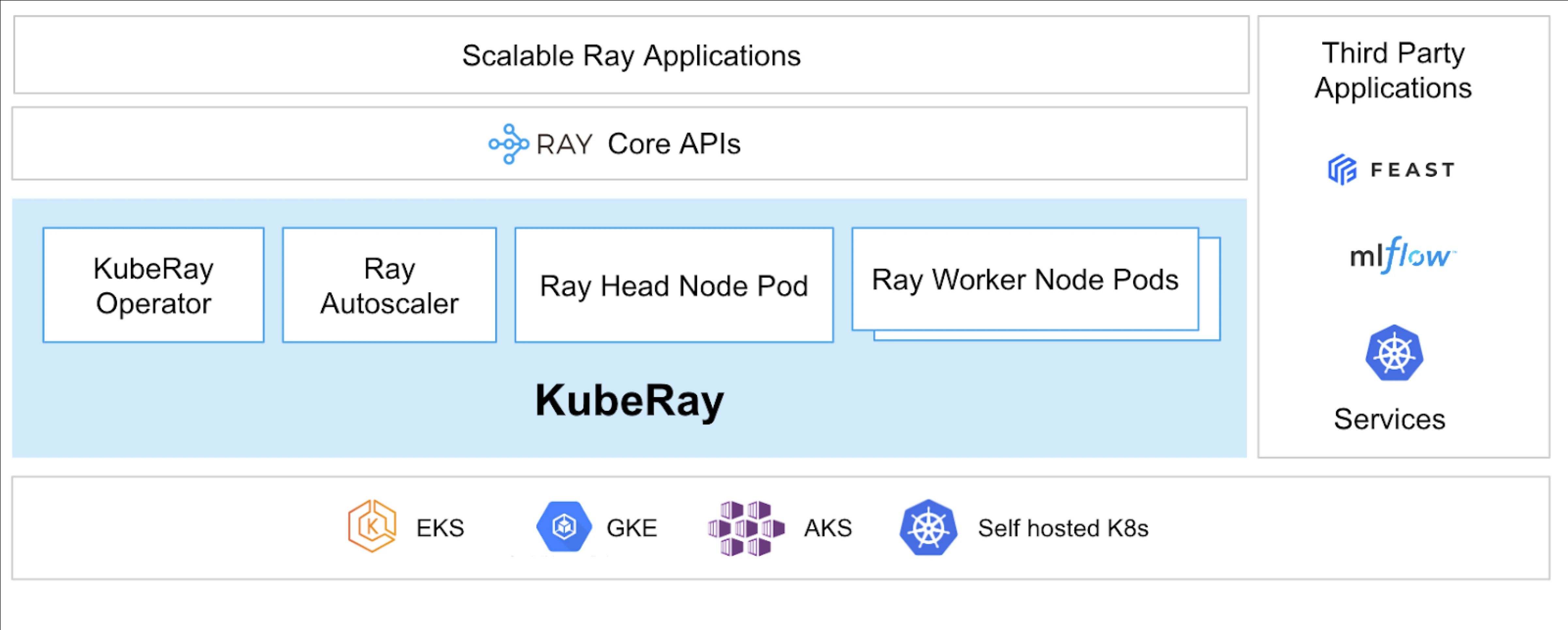
- RayCluster: このCRDはRayClusterのライフサイクルを管理し、定義された構成に基づいてAutoScalingを担当します。
- RayJob: 常時稼働しているRayClusterを維持する代わりに、1回限りのジョブを実行したい場合に便利です。 RayClusterを作成し、ジョブが準備できたら提出します。ジョブが完了すると、RayClusterを削除します。これによりRayClusterを自動的にリサイクルできます。
- RayService: これもRayClusterを作成しますが、その上にRayServeアプリケーションを展開します。このCRDにより、アプリケーションへのインプレースアップデートを実行し、ゼロダウンタイムのアップグレードとアップデートを提供してアプリケーションの高可用性を確保できます。
KubeRayのユースケース
RayServiceを使用したオンデマンドモデルの展開
RayServiceを使用すると、モデルを必要に応じてKubernetes環境に展開できます。これは、画像生成やテキスト抽出などのアプリケーションに特に有用であり、必要な時だけモデルを展開できます。
安定した拡散の例がここにあります。 Kubernetesで適用すると、RayClusterを作成し、RayServiceも実行され、このリソースを削除するまでモデルを提供します。ユーザーはリソースを管理できます。
RayJobを使用してGPUクラスターでモデルをトレーニングする
RayServiceは、ユーザーのさまざまな要件に対応し、モデルまたはアプリケーションを手動で削除するまで展開されたままに保持します。一方、RayJobは、モデルのトレーニング、データの前処理、または特定のプロンプトの固定回数に対する推論などのユースケース向けに一度だけのジョブを可能にします。
RayServiceまたはRayJobを使用してKubernetesで推論サーバーを実行する
通常、アプリケーションをデプロイメントで実行し、停止時間なしでローリングアップデートを維持します。同様に、KubeRayでは、モデルまたはアプリケーションを展開し、ローリングアップデートを処理するRayServiceを使用してこれを達成できます。
ただし、推論サーバーやアプリケーションを長時間実行するのではなく、バッチ推論を行いたい場合があります。こうした場合には、KubernetesのJobリソースに類似したRayJobを活用できます。
Huggingface Vision Transformerを使用した画像分類のバッチ推論は、RayJobの例であり、バッチ推論を行います。
これらはKubeRayのユースケースであり、Kubernetesクラスターでさらに多くのことができるようになります。KubeRayの助けを借りて、同じKubernetesクラスター上で複数のワークロードを実行し、GPUベースのワークロードスケジューリングをRayにオフロードできます。
結論
分散並列処理は、大規模でリソース集約型のタスクを処理するためのスケーラブルなソリューションを提供します。Rayは分散アプリケーションの構築の複雑さを簡素化し、KubeRayはRayをKubernetesと統合してシームレスな展開とスケーリングを実現します。この組み合わせにより、パフォーマンス、スケーラビリティ、耐障害性が向上し、Webクローリング、データ分析、機械学習タスクに最適です。RayとKubeRayを活用することで、分散コンピューティングを効率的に管理し、今日のデータ駆動型の世界の要求に簡単に対応できます。
CPUからGPUベースの計算リソースタイプに変化する中、AIや大規模データ処理などあらゆるアプリケーションに対応する効率的かつスケーラブルなクラウドインフラストラクチャが重要になってきます。
この投稿が有益で興味深いと感じた場合は、LinkedInでの会話をお楽しみください。
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray