













あなたの管理陣は、会社の財務と生産性についてすべてを知りたが、トップシェルフのIT管理ツールにはお金をかけたくないのですか?在庫、請求、およびチケットシステムのために異なるツールに頼らないでください。あなたは1つの中央システムだけが必要です。Power BI Pythonを考慮してみてはいかがでしょうか?
Power BIは、煩雑で時間のかかるタスクを自動化することができます。そして、このチュートリアルでは、データを想像できない方法でスライスして組み合わせる方法を学びます。
さあ、複雑なレポートを目で見ているストレスから解放されましょう!
前提条件
このチュートリアルは実演形式です。一緒に進める場合は、以下のものを用意してください:
- Power BIサブスクリプション – 無料トライアルで十分です。
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop – このチュートリアルではPower BI Desktop v2.105.664.0を使用しています。
- MySQL Server – このチュートリアルではMySQL Server v8.0.29を使用しています。
- 外部デバイスで使用する場合は、オンプレミスデータゲートウェイがインストールされていることが必要です。
- Visual Studio Code(VS Code)- このチュートリアルでは、VS Code v17.2 を使用します。
- Python v3.6 以降がインストールされていること – このチュートリアルでは、Python v3.10.5 を使用します。
- DBeaver がインストールされていること – このチュートリアルでは、DBeaver v22.0.2 を使用します。
MySQL データベース を構築する
Power BI はデータを美しく可視化できますが、その前にデータの取得と保存が必要です。データを保存する最良の方法の一つは、データベースに保存することです。MySQL は無料でパワフルなデータベースツールです。
1. 管理者としてコマンドプロンプトを開き、以下の mysql コマンドを実行し、プロンプトが表示されたら root ユーザー名(-u)とパスワード(-p)を入力します。
デフォルトでは、データベースの変更を行う権限を持つのは root ユーザーのみです。
2. 次に、以下のクエリを実行して、パスワード(IDENTIFIED BY)付きの新しいデータベースユーザー(CREATE USER)を作成します。ユーザーの名前は異なっても構いませんが、このチュートリアルでは ata_levi という選択肢があります。

3. ユーザーを作成した後は、以下のクエリを実行して、新しいユーザーにデータベースサーバー上でのデータベース作成などの権限(ALL PRIVILEGES)を与えます。

4. これで、MySQLからログアウトするために以下の \q コマンドを実行します。

5. 新しく作成したデータベースユーザー(ata_levi)としてログインするには、以下の mysql コマンドを実行します。
6. 最後に、以下のクエリを実行して ata_database という新しいデータベースを作成します。もちろん、データベースの名前は異なっても構いません。

DBeaver で MySQL データベースを管理する
データベースを管理する際には、通常 SQL の知識が必要です。しかし、DBeaver を使用すると、数回のクリックでデータベースを管理するための GUI を使用でき、DBeaver が SQL ステートメントを自動的に処理してくれます。
1. デスクトップまたはスタートメニューから DBeaver を開きます。
2. DBeaver を開くと、新しいデータベース接続のドロップダウンをクリックし、MySQL を選択して MySQL サーバーに接続の開始します。
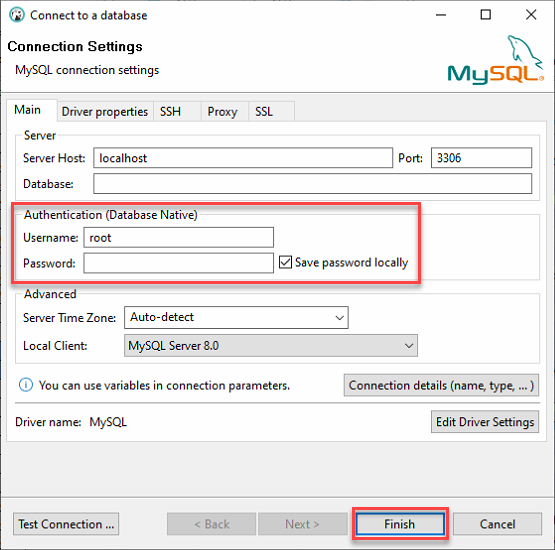
3. ローカルの MySQL サーバーに以下の情報でログインします:
- ローカルサーバーに接続しているので、サーバーホストは localhost、ポートは 3306 のままにします。
- 「MySQL データベースの構築」セクションのステップ 2 から取得した ata_levi ユーザーの資格情報(ユーザー名とパスワード)を提供し、ログインするには Finish をクリックします。
4. データベースナビゲーター(左パネル)の下のデータベース(ata_database)を展開し、テーブルを右クリックし、新しいテーブルの作成を選択します。
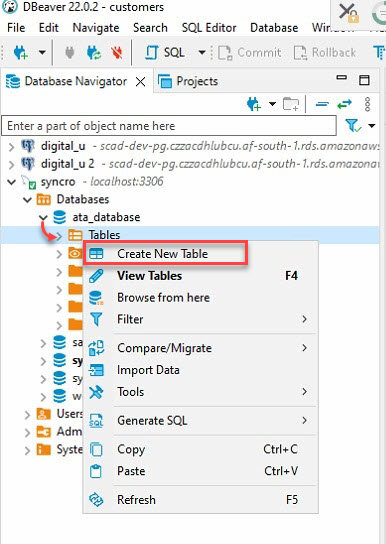
5. 新しいテーブルの名前を付けますが、このチュートリアルでは ata_Table を選択します。
テーブル名が、「APIデータの取得と消費」セクションの7番目の「to_sql(”テーブル名”)」メソッドで指定するテーブル名と一致していることを確認してください。
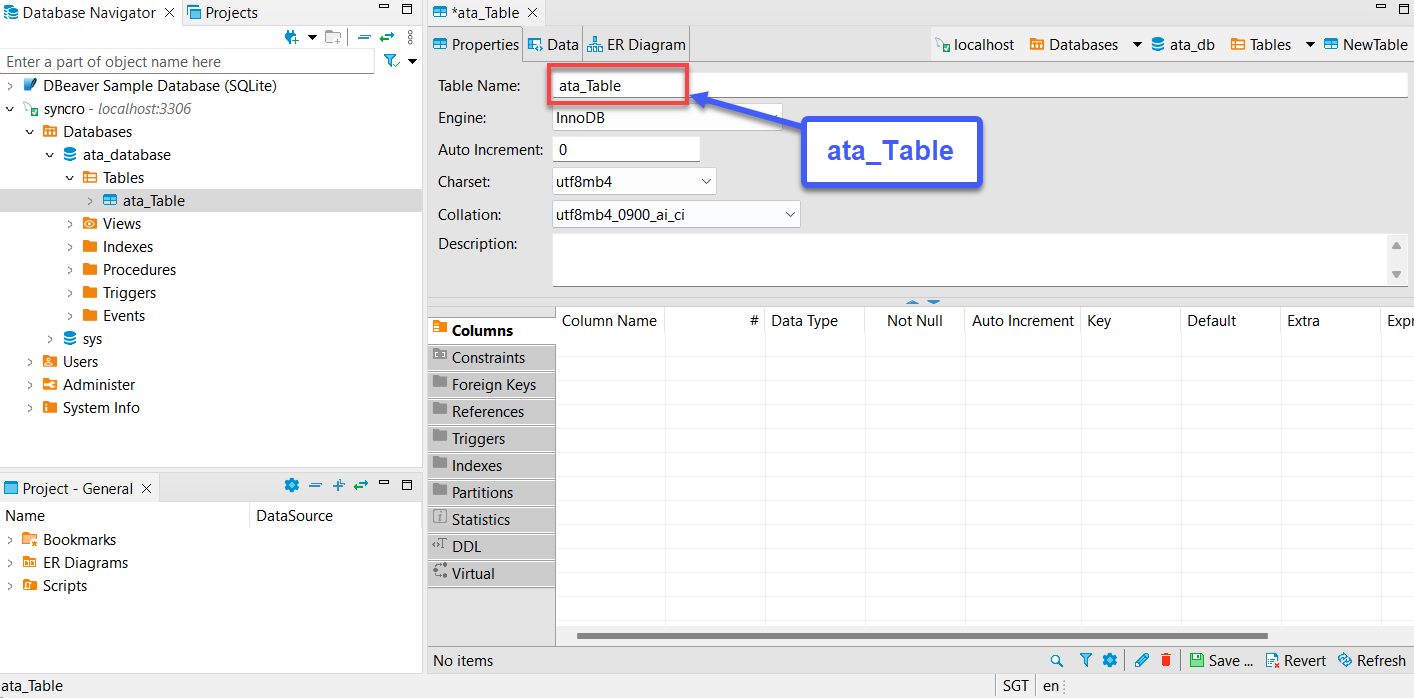
6. 次に、新しいテーブル(ata_table)を展開し、列を右クリックし、新しい列の作成を選択します。
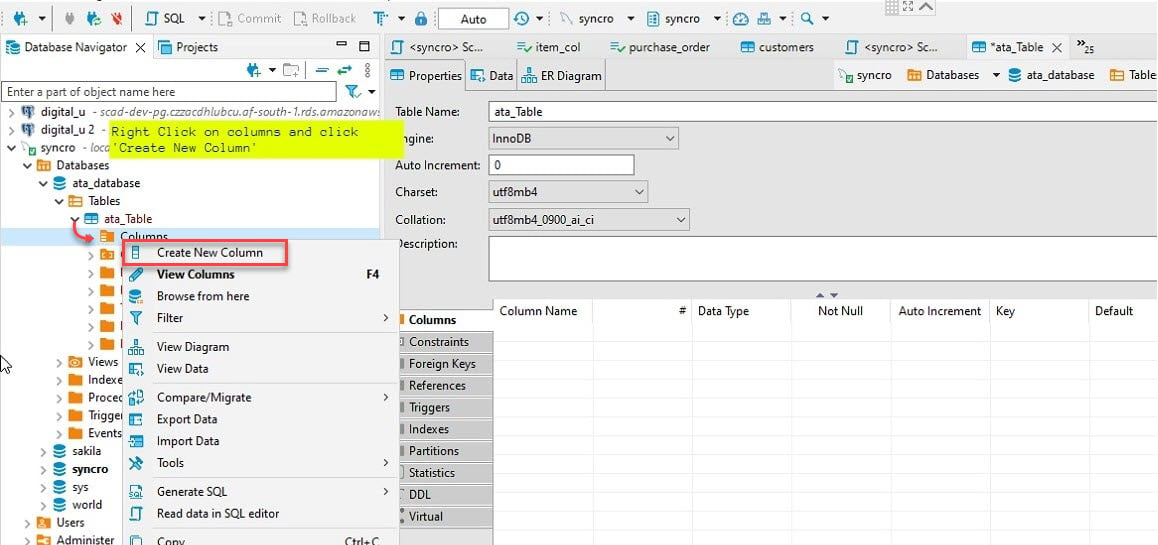
7. 列の名前を指定し、Not Null のチェックボックスをオンにし、新しい列を作成するために OK をクリックします。
理想的には、”id” という名前の列を追加することが望ましいです。なぜなら、ほとんどのAPIにはidがあり、Pythonのpandasデータフレームが他の列を自動的に埋めるからです。
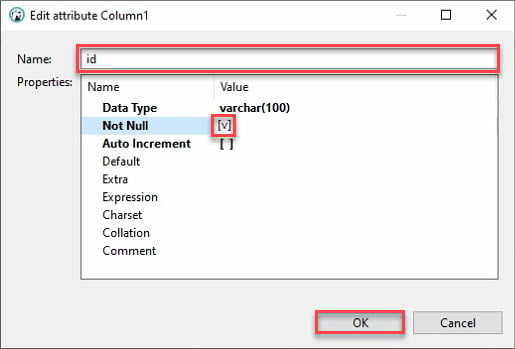
8. 変更内容を保存するために、保存(右下)をクリックするか、Ctrl+S を押します。新しく作成した列(id)が正しく表示されることを確認してください。
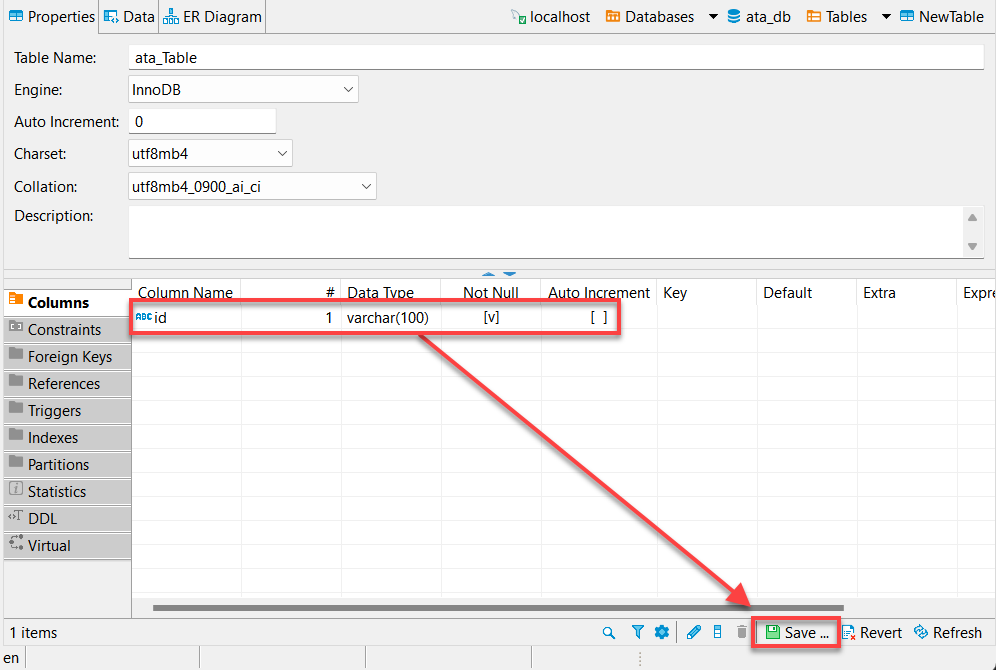
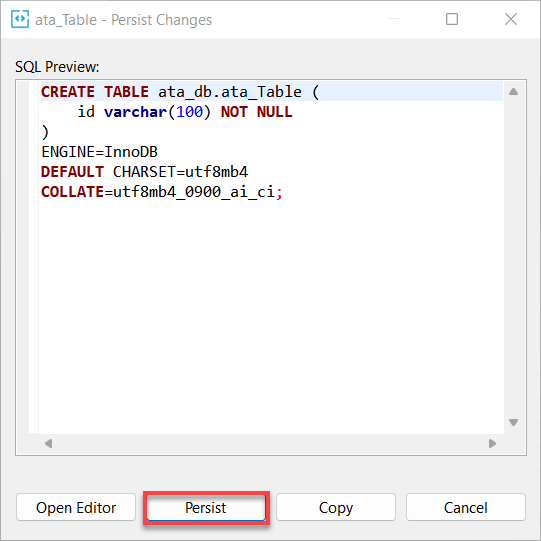
9. 最後に、変更内容を永続化するために、永続化をクリックします。
APIデータの取得と消費
データを保存するためのデータベースを作成したので、Pythonを使用してAPIプロバイダーからデータを取得し、データベースにプッシュする必要があります。このデータをPower BIで視覚化するために使用します。
APIプロバイダーに接続するためには、3つの重要な情報が必要です。認証方法、APIベースURL、およびAPIエンドポイントです。これらの情報について疑問がある場合や、これらの情報を取得する方法については、APIプロバイダーのドキュメントサイトを参照してください。
以下は、Syncroからのドキュメントページです。
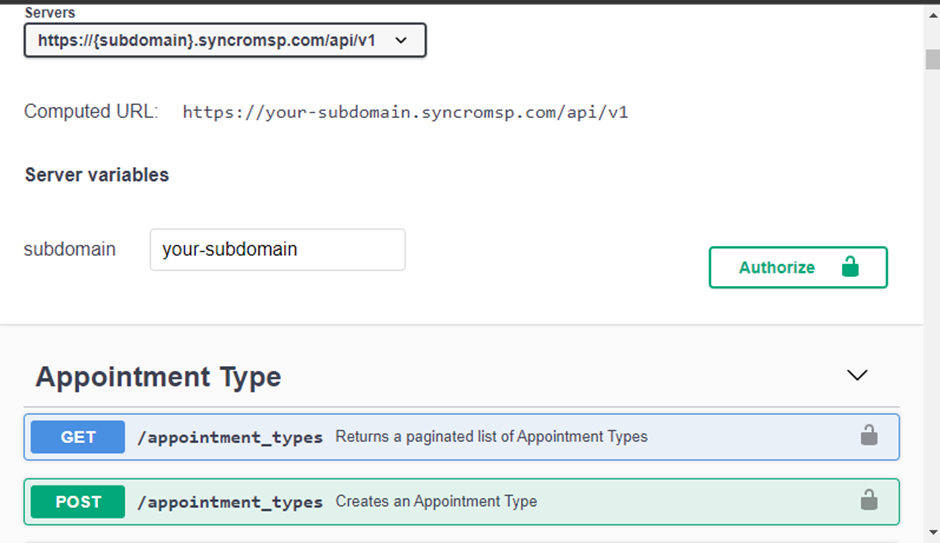
1. VS Codeを開き、Pythonファイルを作成し、ファイル名をファイルから期待されるAPIデータに応じて付けます。このファイルは、APIデータを取得してデータベースにプッシュする責任があります(データベース接続)。
データベース接続には複数のPythonライブラリがありますが、このチュートリアルではSQLAalchemyを使用します。
以下のpipコマンドをVS Codeのターミナルで実行して、環境にSQLAalchemyをインストールします。

2. 次に、connection.pyというファイルを作成し、以下のコードを埋め、値を適切に置き換えてファイルを保存します。
データベースと通信するスクリプトを作成し始めると、データベースにコマンドを受け入れる前にデータベースへの接続を確立する必要があります。
ただし、書き込むスクリプトごとにデータベース接続文字列を書き直す代わりに、以下のコードはこの接続を作成するために他のスクリプトから呼び出し/参照されるように専用されています。
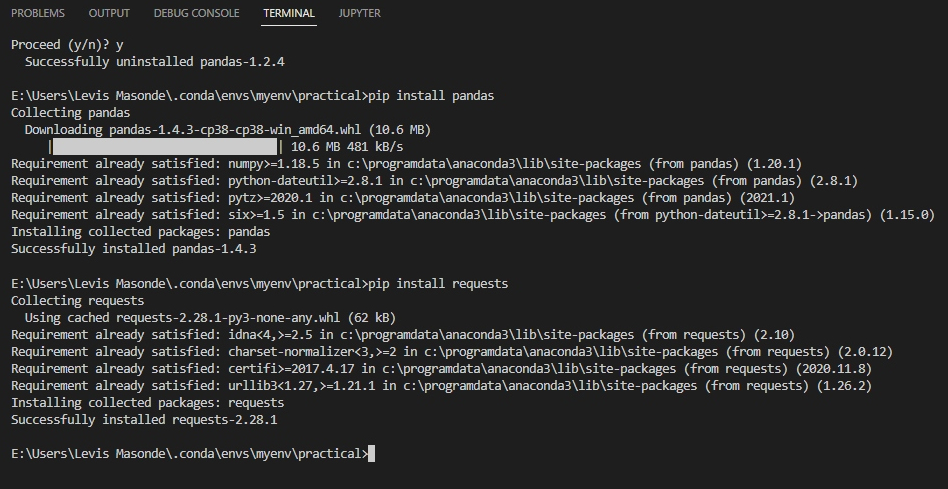
3. Visual Studioのターミナルを開き(Ctrl+Shift+`)、以下のコマンドを実行してpandasとrequestsをインストールしてください。
4. 別のPythonファイルを作成してinvoices.pyという名前を付けます(または異なる名前を付けます)、そして以下のコードをファイルに追加してください。
以降のステップでinvoices.pyファイルにコードスニペットを追加しますが、完全なコードはATAのGitHubで確認できます。
次のセクションで説明されているメインスクリプトからinvoices.pyスクリプトを実行し、最初のAPIデータを取得します。
以下のコードは次のことを実行します:
- APIからデータを取得し、それをデータベースに書き込みます。
- 認証方法、キー、ベースURL、およびAPIエンドポイントをAPIプロバイダーの認証情報に置き換えます。
5. invoices.pyファイルに以下のコードスニペットを追加して、例えばヘッダーを定義します:
- APIから受け取る予定のデータ形式です。
- ベースURLとエンドポイントは、認証方法とそれに対応するキーとともに提供される必要があります。
以下の値を自分のものに変更してください。
6. 次に、以下の非同期関数をinvoices.pyファイルに追加してください。
以下のコードは、AsyncIOを使用して、1つのメインスクリプトから複数のスクリプトを管理します。プロジェクトが複数のAPIエンドポイントを含むようになると、APIの消費スクリプトをそれぞれのファイルに分けておくのが良い習慣です。
7. 最後に、以下のコードをinvoices.pyファイルに追加してください。get_pages関数がAPIのページネーションを処理します。
この関数はAPIの総ページ数を返し、range関数がすべてのページを反復処理するのに役立ちます。
APIプロバイダーが使用しているページネーションメソッドに関して、APIの開発者に連絡してください。
データにさらにAPIエンドポイントを追加する場合:
- 「DBeaverでMySQLデータベースを管理する」セクションの手順4から6を繰り返します。
- 「APIデータの取得と消費」セクションのすべての手順を繰り返します。
- 別のAPIエンドポイントにAPIエンドポイントを変更します。
APIエンドポイントの同期
今やデータベースとAPI接続があり、invoices.pyファイルのコードを実行してAPIの消費を開始する準備が整いました。しかし、これを行うと、同時に1つのAPIエンドポイントしか消費できません。
どのように限界を超えるか?別のPythonファイルを中央ファイルとして作成し、さまざまなPythonファイルからAPI関数を呼び出して関数を非同期で実行します。AsyncIO。これにより、プログラムが整理され、複数の関数をまとめてバンドルできます。
1. central.pyという新しいPythonファイルを作成し、以下のコードを追加します。
請求書.pyファイルと同様に、各ステップでcentral.pyファイルにコードスニペットを追加しますが、完全なコードはATAのGitHubで確認できます。
以下のコードは、必要なモジュールと他のファイルからのスクリプトを、from <filename> import <function name> 構文を使用してインポートします。
2. 次に、central.pyファイルで請求書.pyのスクリプトを制御するために、次のコードを追加します。
3. AsyncIOタスクを作成した後、チェーン関数(ステップ2で)が実行されると、invoice.pyからcall_invoices関数を取得して実行するために、タスクを待機します。
4. AsyncIOSchedulerを作成してスクリプトのジョブをスケジュールします。このコードで追加されたジョブは、1秒間隔でチェーン関数を実行します。
このジョブは、プログラムがスクリプトを継続して実行し、データを最新の状態に保つことを確認するために重要です。
5. 最後に、VS Codeでcentral.pyスクリプトを実行します。以下のように表示されます。
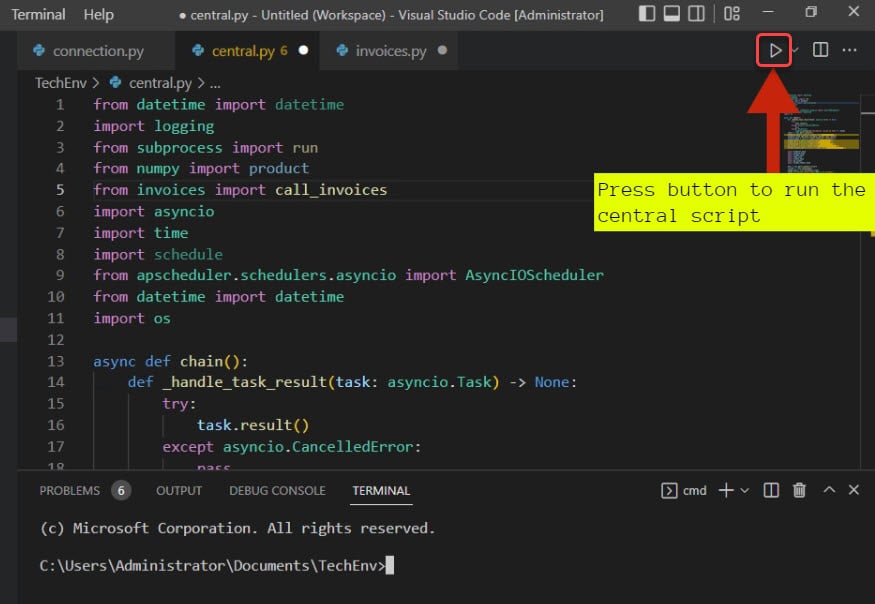
スクリプトを実行した後、ターミナルで以下のような出力が表示されます。
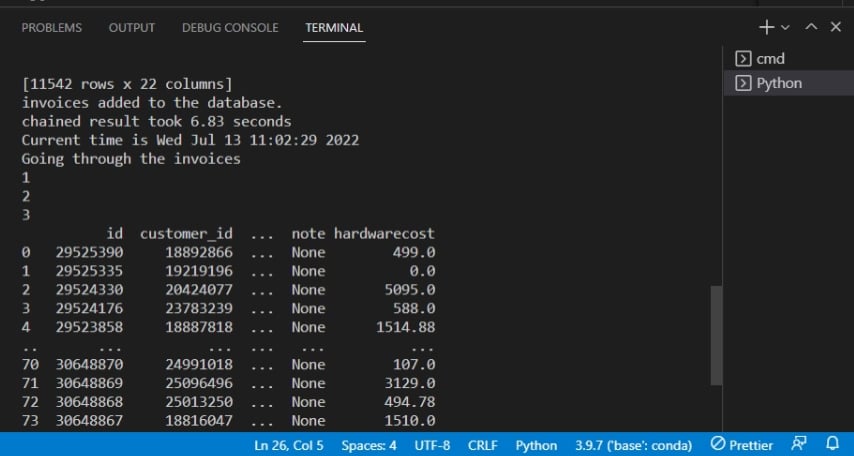
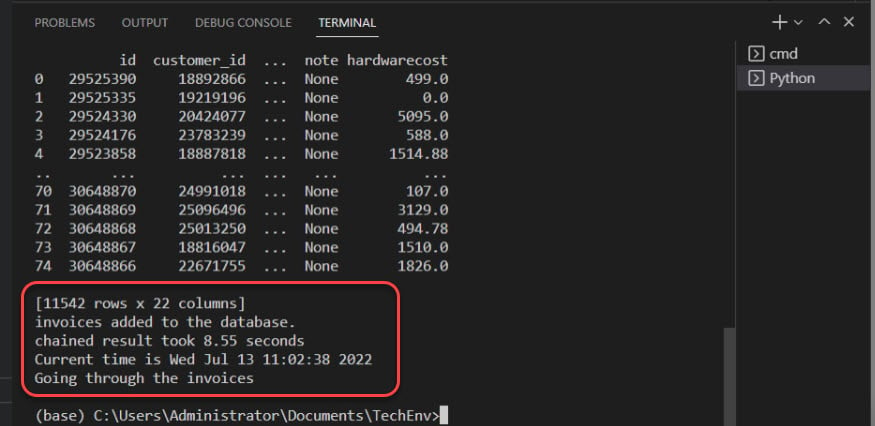
以下の出力は、データベースに請求書が追加されたことを確認しています。
Power BIビジュアルの開発
APIデータに接続し、これらのデータをデータベースにプッシュするプログラムをコーディングした後、データを収穫する準備がほぼ整いました。しかし、まずはデータベース内のデータをPower BIに可視化するためにプッシュします。
データは視覚化されず、深い関連性を見出すことができない場合、多くのデータは役に立ちません。幸いなことに、Power BIのビジュアルは、グラフが複雑な数学方程式を簡単で予測可能にする方法のようです。
1. デスクトップまたはスタートメニューからPower BIを開きます。
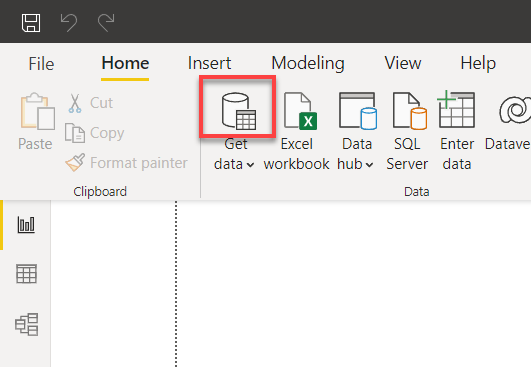
2. パワーBIのメインウィンドウ上の「データの取得」ドロップダウンメニューの上にあるデータソースアイコンをクリックします。
3. mysqlを検索し、MySQLデータベースを選択し、接続を開始するために「接続」をクリックします。
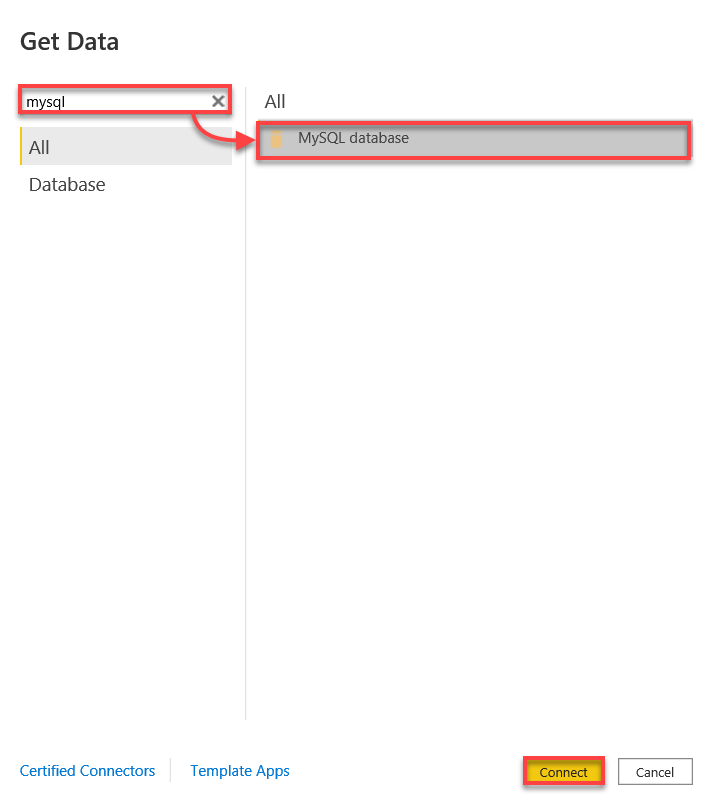
4. 以下の手順でMySQLデータベースに接続します:
- ローカルのMySQLサーバーにポート3306で接続しているため、localhost:3306と入力します。
- データベースの名前(この場合はata_db)を指定します。
- MySQLデータベースに接続するためにOKをクリックします。

5. 今、データの概要を表示するために「データの変換」(右下)をクリックします(手順5)。

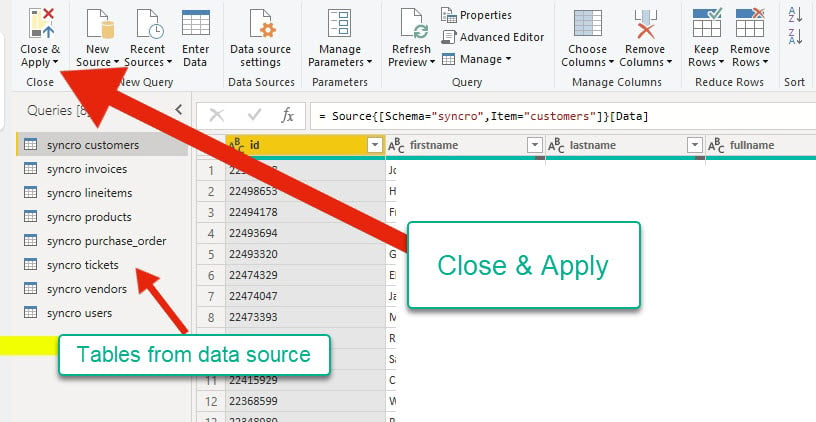
6. データソースのプレビュー後、変更が適用されたかどうかを確認するために「閉じて適用」をクリックしてメインアプリケーションに戻ります。
クエリエディタは、データソースから取得したテーブルを左側に表示します。同時に、メインアプリケーションに進む前にデータの形式を確認することができます。
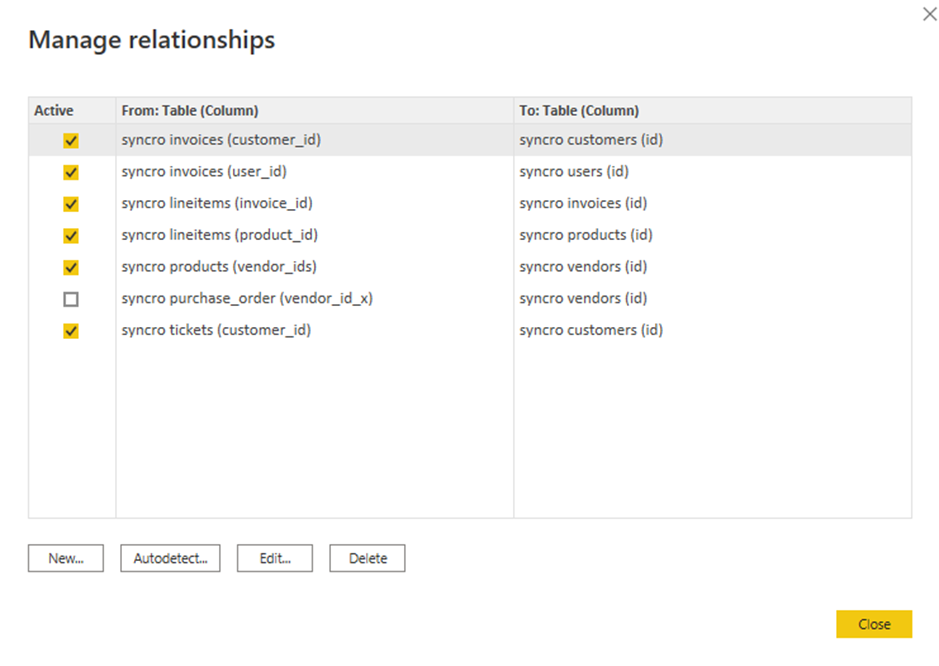
7. テーブルツールのリボンタブをクリックし、フィールドペインの任意のテーブルを選択して「関係の管理」をクリックして関係のウィザードを開きます。
視覚化を作成する前に、テーブル間に関係があることを確認する必要があります。なぜなら、パワーBIは複雑なテーブルの関連を自動的に検出しないからです。

8. 編集する既存の関係のチェックボックスにチェックを入れ、編集をクリックします。ポップアップウィンドウが表示され、選択した関係を編集することができます(手順9)。
ただし、新しい関係を追加する場合は、代わりに[新規]をクリックしてください。
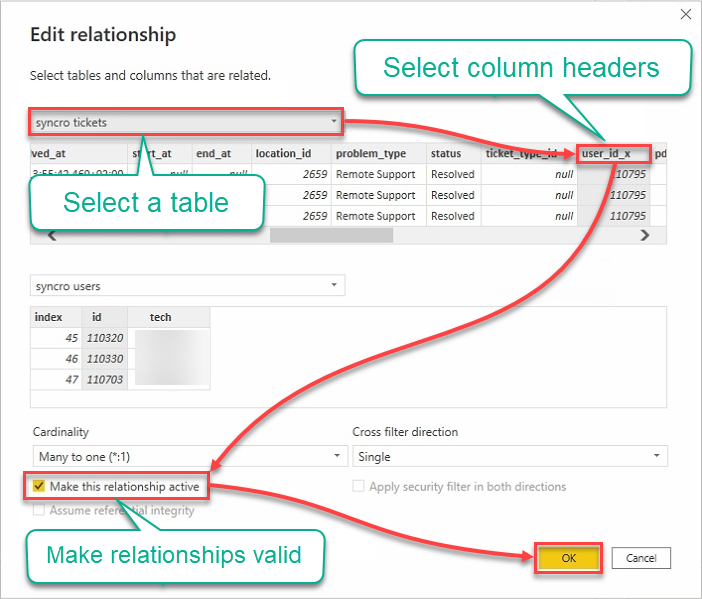
9. 以下の関係を編集する:
- テーブルのドロップダウンフィールドをクリックし、テーブルを選択します。
- 使用する列を選択するためにヘッダーをクリックします。
- 関係を有効にするためにこの関係をアクティブにする チェックボックスをオンにします。
- 関係を確立し、編集関係ウィンドウを閉じるためにOKをクリックします。
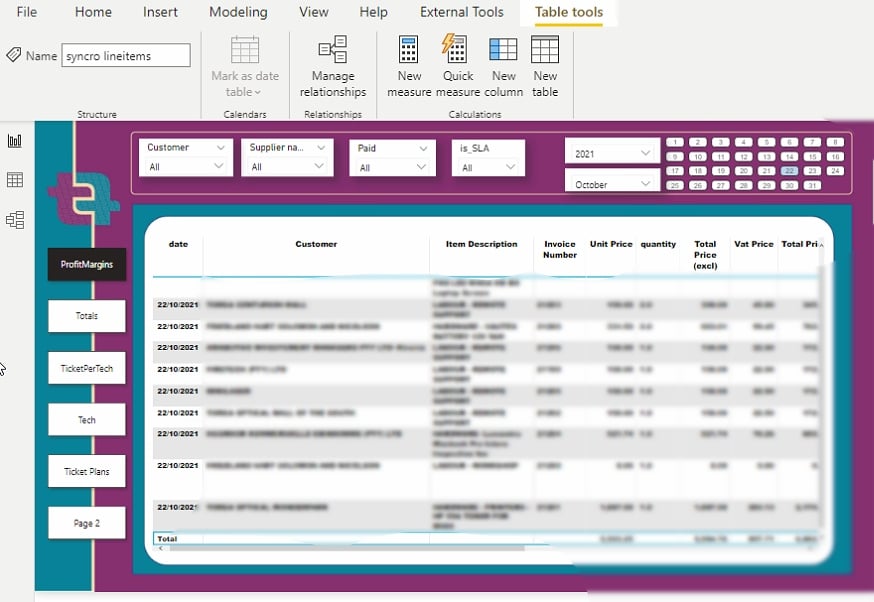
10. 次に、(最右側の)視覚化ペインの[テーブルビジュアルタイプ]をクリックして、最初のビジュアルを作成します。空のテーブルビジュアルが表示されます(ステップ11)。
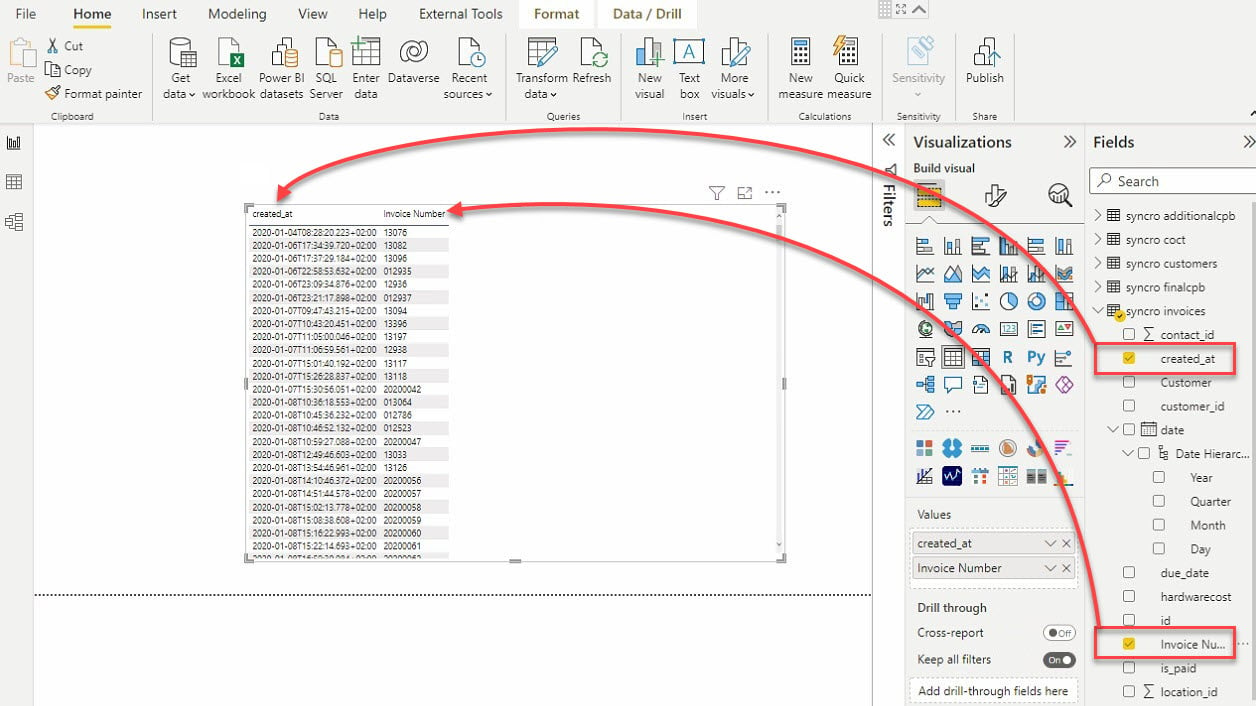
11. テーブルビジュアルとデータフィールド(フィールドペインに表示される)を選択して、テーブルビジュアルに追加します。以下のように表示されます。
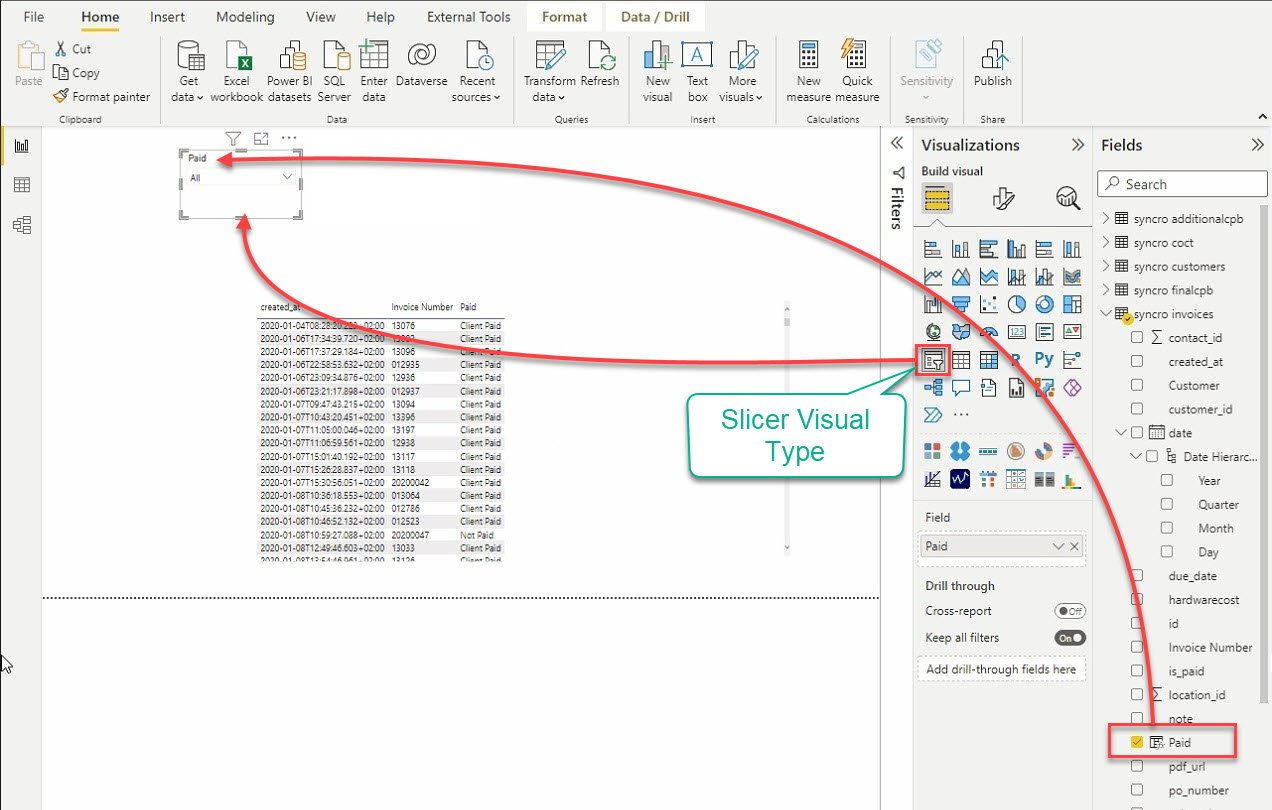
12. 最後に、別のビジュアルを追加するためにスライサービジュアルタイプをクリックします。その名の通り、スライサービジュアルは他のビジュアルをフィルタリングしてデータをスライスします。
スライサーを追加した後、スライサービジュアルに追加するためにフィールドペインからデータを選択します。
視覚化の変更
視覚化のデフォルトルックスはかなりまともです。しかし、もっと地味ではない何かに視覚化の外観を変更できれば素晴らしいですよね?Power BIにトリックをやらせましょう。
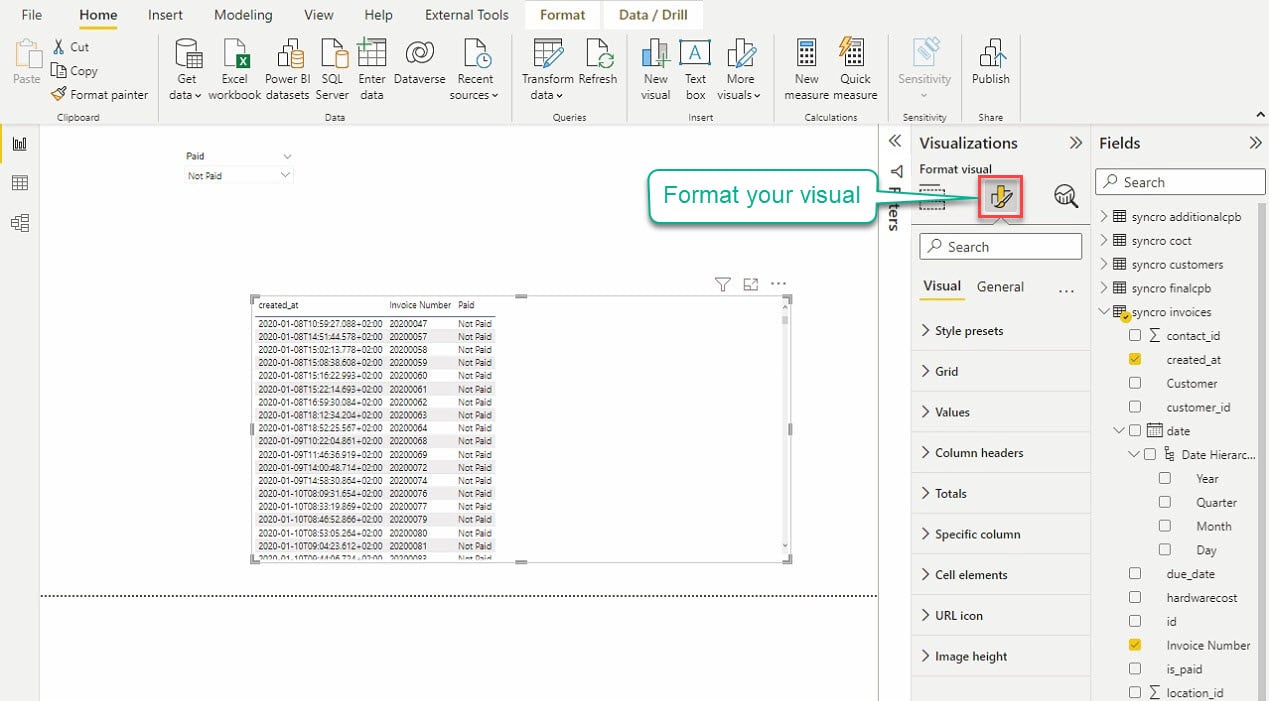
視覚化をフォーマットアイコンをクリックして、視覚化エディタにアクセスします。以下のように表示されます。
視覚化の設定を調整して、視覚化の外観を取得するために時間を費やしてください。テーブルに関わるテーブル間の関係が確立されている限り、視覚化は相関します。
変更した可視化設定の後、以下のようなレポートを取得できます。
今、複雑さなく、目を痛めることなくデータを視覚化し、分析できます。
次の視覚化では、トレンドグラフを見ると、2020年4月に何かがうまくいかなかったことがわかります。その時が、新型コロナウイルスのロックダウンが初めて南アフリカに影響を与えた時期でした。
この出力は、Power BIが的確なデータの視覚化を提供する能力を証明しています。

結論
このチュートリアルの目的は、APIエンドポイントからデータを取得して、ライブのダイナミックなデータパイプラインを確立する方法を示すことです。さらに、Pythonを使用してデータを処理し、データベースとPower BIにデータをプッシュします。この新しい知識を活用することで、APIデータを消費し、独自のデータ視覚化を作成できるようになります。
ますます多くの企業がRestful API Webアプリを作成しています。そしてこの時点で、Pythonを使用してAPIを消費し、Power BIでデータ視覚化を行うことに自信を持っているため、ビジネスの意思決定に影響を与えるのに役立ちます。