













あなたの生データを整理して実行可能な情報に変換することは複雑に聞こえるかもしれません。しかし、迅速かつ効率的なソリューションがあればそんなことはありません。心配しないでください!この初心者向けのAWS Glueチュートリアルがあなたのバックアップになります。
このチュートリアルでは、AWS Glueを使用したデータ変換の重要なステップを学びます。
クラウドベースの分析のためのデータの準備を探索し、効率化しましょう!
前提条件
AWS Glueを使用する前に、アクティブなAmazon Web Services(AWS)アカウントと課金が有効になっていることを確認してください。このチュートリアルでは、無料のアカウントで十分です。
AWS GlueのIAMロールの作成
変換ジョブを実行する前に、AWS Glueサービスにアクセス権を付与するIdentity and Access Management(IAM)ロールを作成する必要があります。このロールは、AWS GlueがAWSアカウントでアクセスできるリソースの種類を定義します。
IAMロールを作成するには、以下の手順に従ってください:
1. 好きなウェブブラウザを開き、AWS管理コンソールにログインします。
2. 結果リストで IAM を検索して選択し、IAM コンソールにアクセスします。
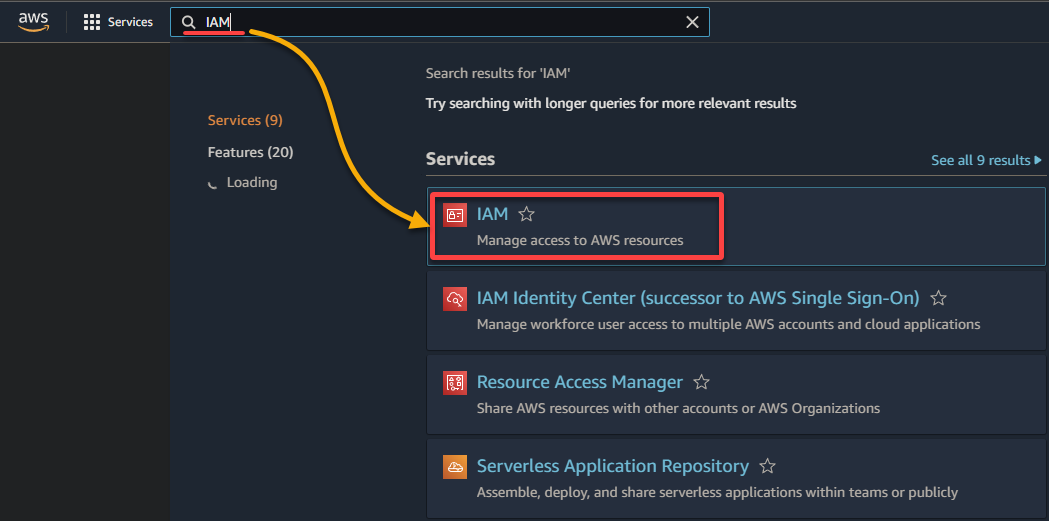
3. IAM コンソールで、ロール(左ペイン)に移動し、ロールの作成(右上)をクリックして、ブラウザを役割の構成に専用の新しいページにリダイレクトします。

4. 今、次の設定を役割に対して構成します。
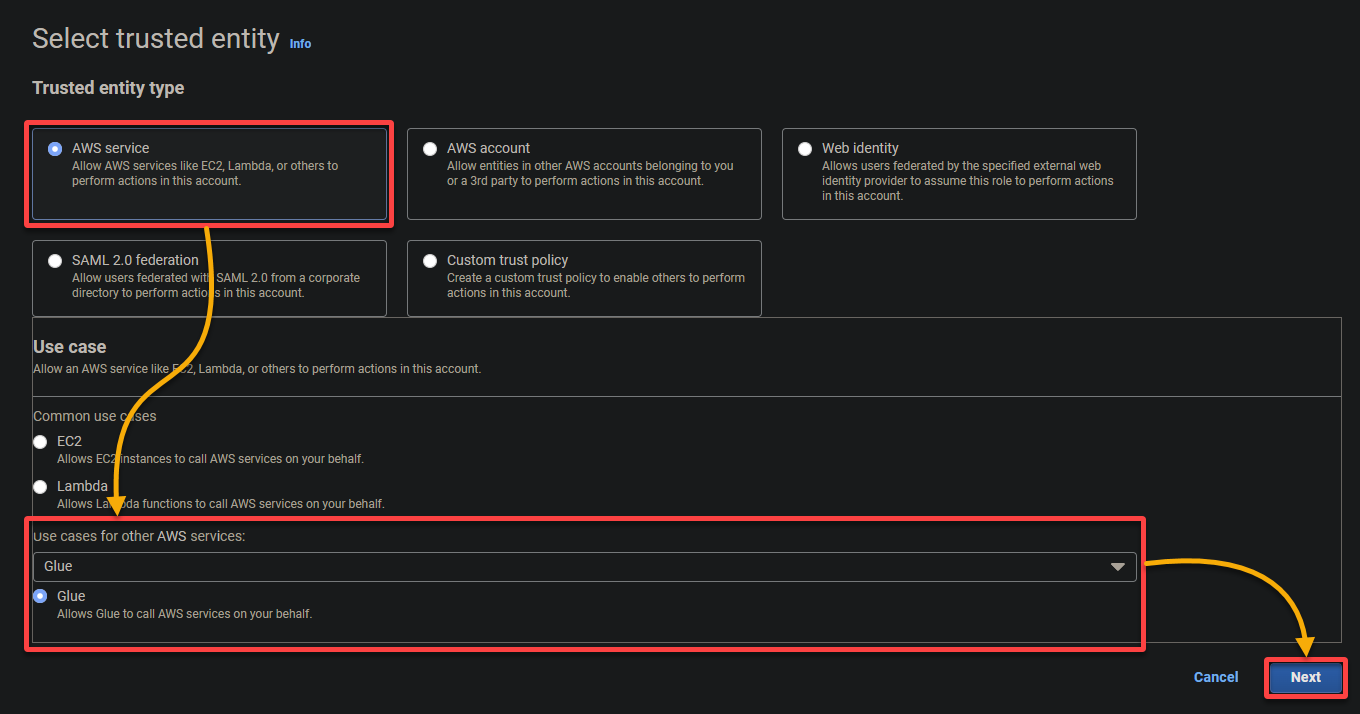
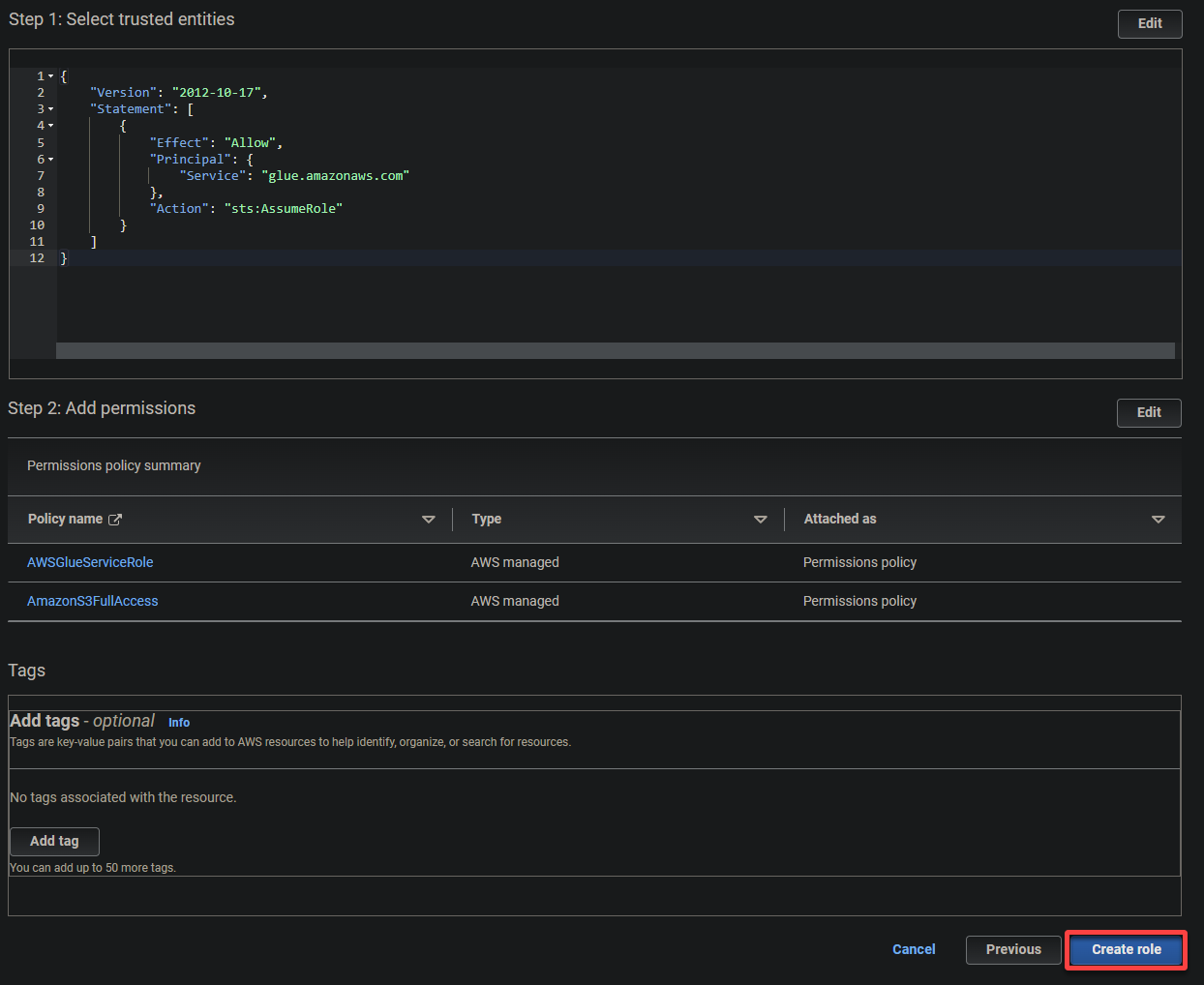
- 信頼されたエンティティタイプ – AWS サービスを選択して、AWS サービスが役割を信頼します。これにより、そのサービスが役割を引き受け、あなたの代わりに操作できるようになります。
- ユースケース – 他の AWS サービスのユースケースセクションで Glue を選択します。AWS Glue のために特に IAM ロールを作成するため、次へをクリックします。
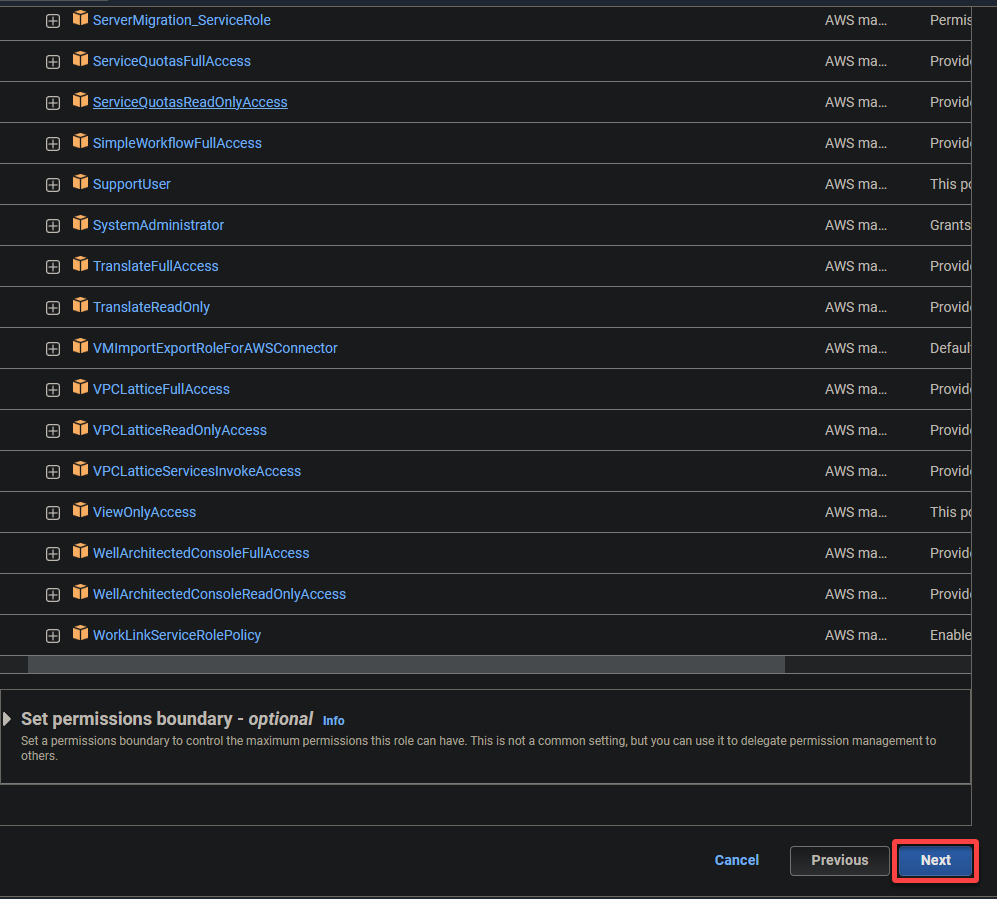
5. 次のポリシーを検索して選択し、次へ をクリックします。
- AWSGlueServiceRole – AWS Glue サービスが操作を実行するために必要なアクセス許可を付与します。
- S3FullAccess – S3 リソースへの完全なアクセスを付与し、AWS Glue が S3 バケットから読み取り、書き込みを行うことができます。
AWS Glue は、データの抽出、変換、ロード(ETL)タスクを効果的に実行するために、S3 バケットから読み取り、書き込みを行うための幅広いアクセス許可が必要です。
? 不必要な過剰なアクセス許可を付与しないように注意してください。セキュリティリスクを引き起こす可能性があります。
6. ロールの記述的な名前(つまり、glue_role)と説明を提供します。
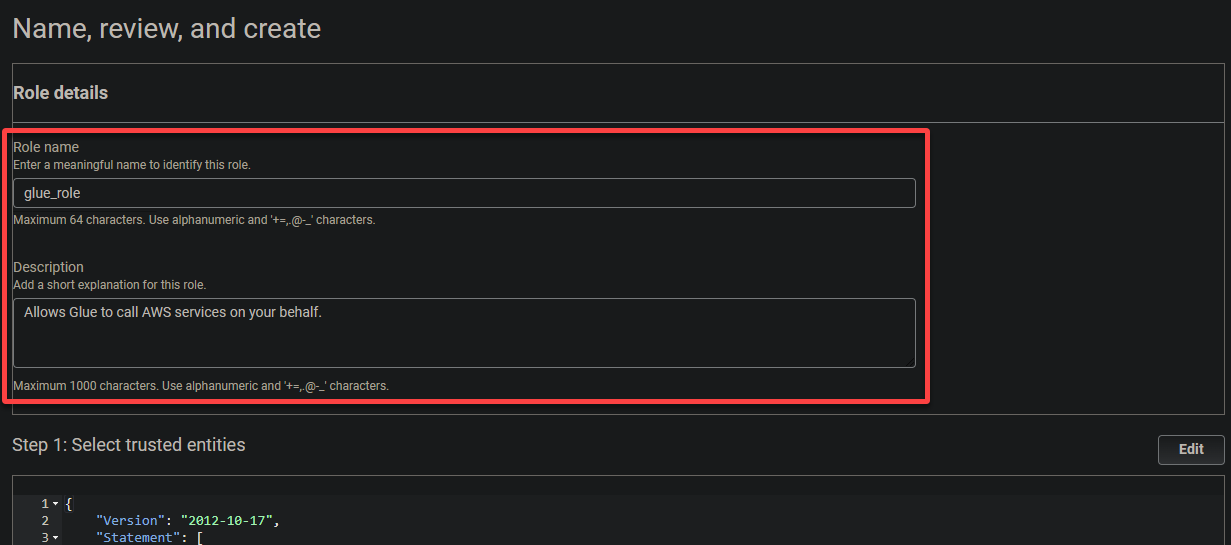
最後に、設定を確認し、ロールの作成を確定するために、下にスクロールして、ロールの作成(右下)をクリックしてください。
S3バケットの作成とサンプルファイルのアップロード
AWS Glue用のIAMロールが作成されたので、データを保存する場所が必要です。具体的には、S3バケットが必要です。S3バケットは、AWS Glueが処理するデータを保存するための中央集権型の場所を提供します。
この例では、AWS Glueは、データ抽出、変換、およびロード(ETL)タスクなどのさまざまな操作にAWS S3をデータストアとして使用します。
S3バケットを作成し、サンプルファイルをアップロードするには、次の手順に従ってください:
1. ローカルマシンにサンプルデータファイル(例:Every Politicianデータセット)をダウンロードします。このファイルには、AWS Glue変換ジョブの入力として構造化されていないレコードのコレクションが含まれています。
2. S3コンソールにアクセスするためにS3サービスを検索して選択します。
3. 新しいS3バケットを作成するためにバケットの作成をクリックします。

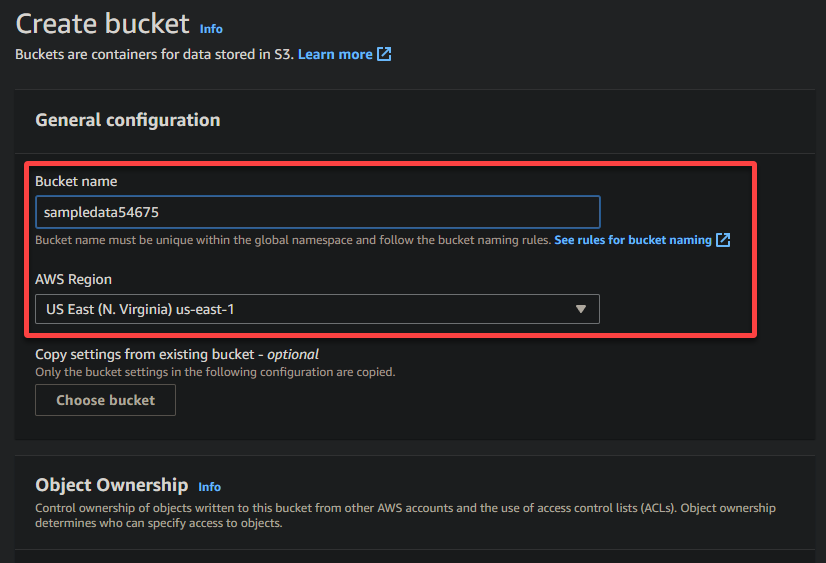
4. バケットに一意の名前(例:sampledata54675)を指定し、バケットを配置するリージョンを選択します。
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
5. スクロールして、他のオプションをそのままにして、バケットの作成をクリックしてバケットを作成します。

6. 作成されたら、新しく作成されたS3バケットのハイパーリンクをクリックしてバケットに移動します。

7. アップロードをクリックし、アップロードするサンプルファイルを見つけます。
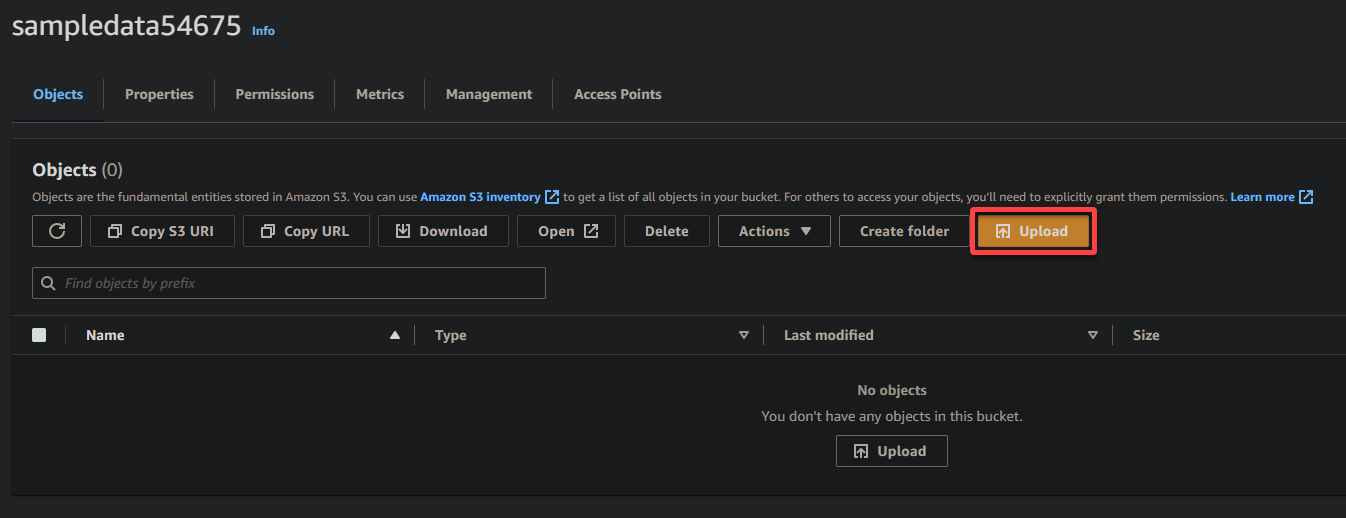
最後に、他の設定をそのままにして、サンプルファイルを新しく作成されたバケットにアップロードするためにアップロードをクリックしてください。
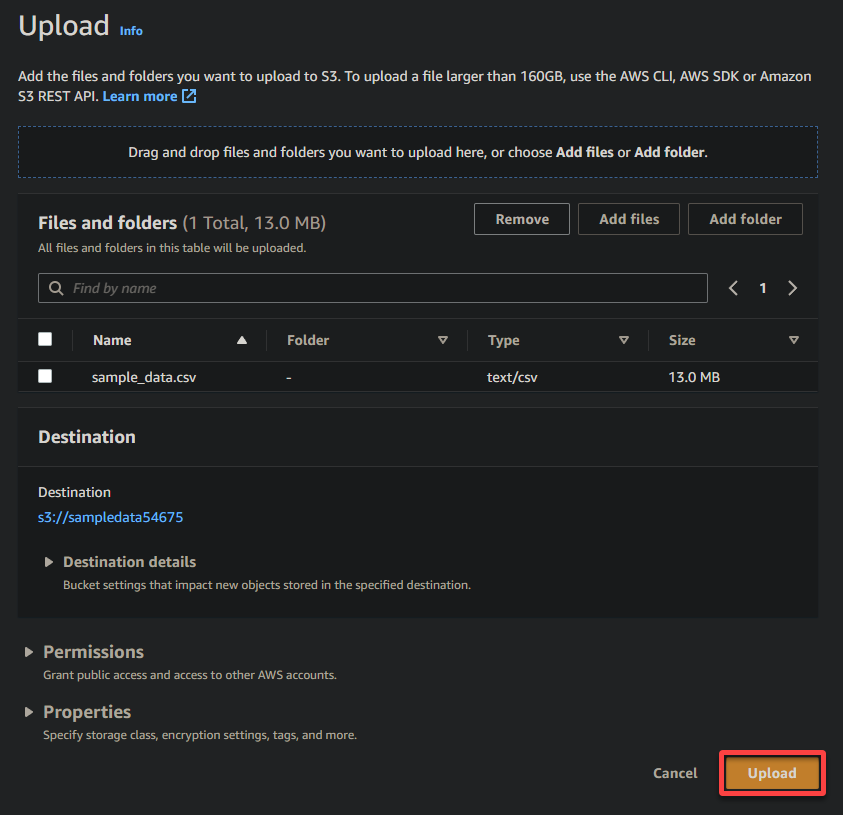
成功したら、以下に示すように、バケットに新しくアップロードされたファイルが表示されます。
データをスキャンしてカタログを作成するGlueクローラの作成
これで、サンプルデータをS3バケットにアップロードしましたが、現在は非構造化されているため、データを読み取り、メタデータカタログを構築する方法が必要です。どうやって? Glueクローラを作成して、データを自動的にスキャンしてカタログ化します。
Glueクローラを作成するには、以下の手順に従ってください:
1. AWS管理コンソール経由でAWS Glueコンソールに移動し、以下に示すようにします。
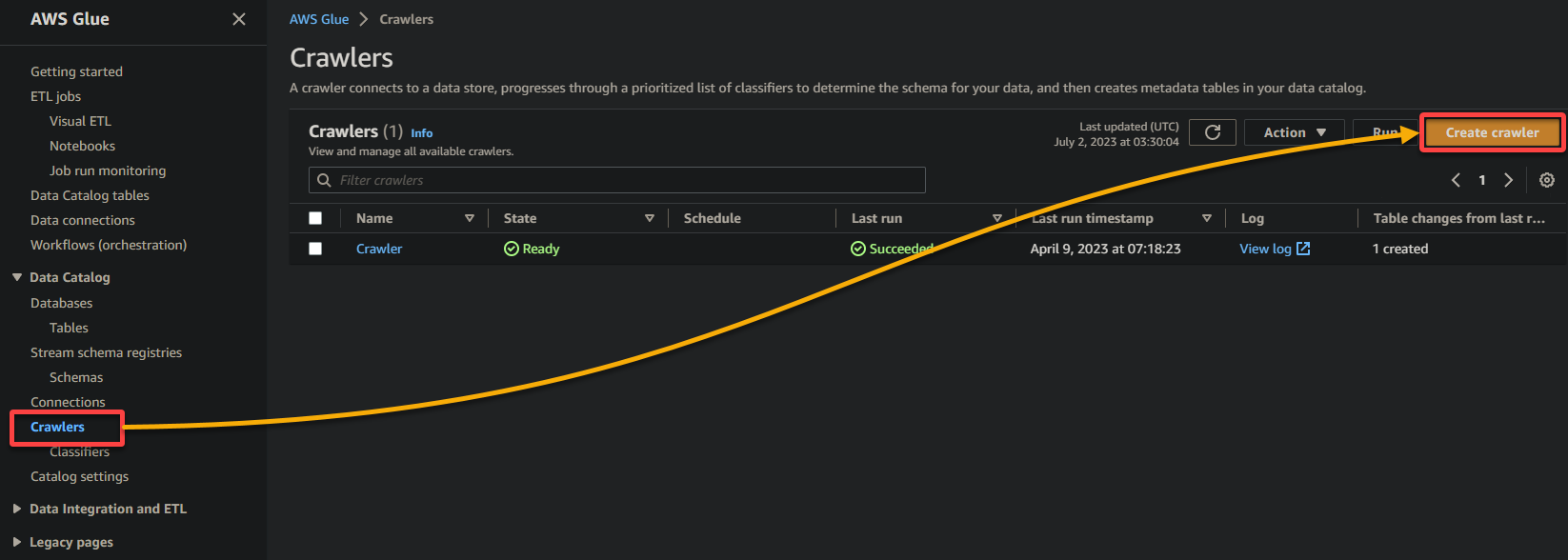
2.次に、Crawler(左側のペイン)に移動し、クローラの追加(右上)をクリックして、新しいGlueクローラの作成を開始します。
3.クローラの名前(例:glue_crawler)と説明を入力し、他の設定をそのままにして、次へをクリックしてください。
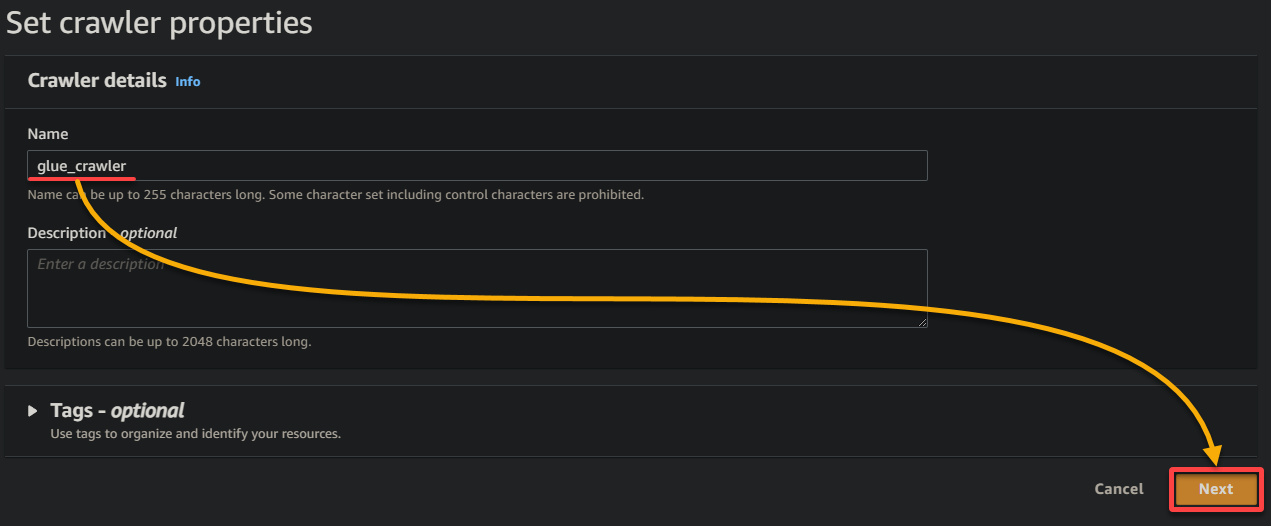
4.次に、データソースの下にあるデータソースの追加をクリックして、クローラに新しいデータソースを追加します。
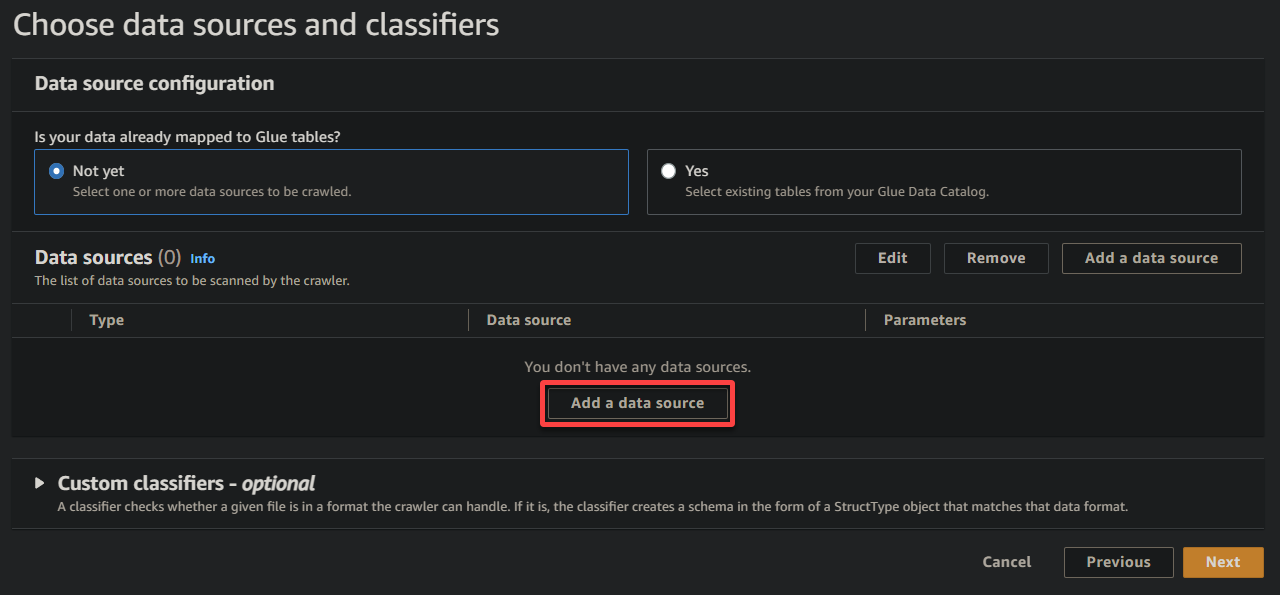
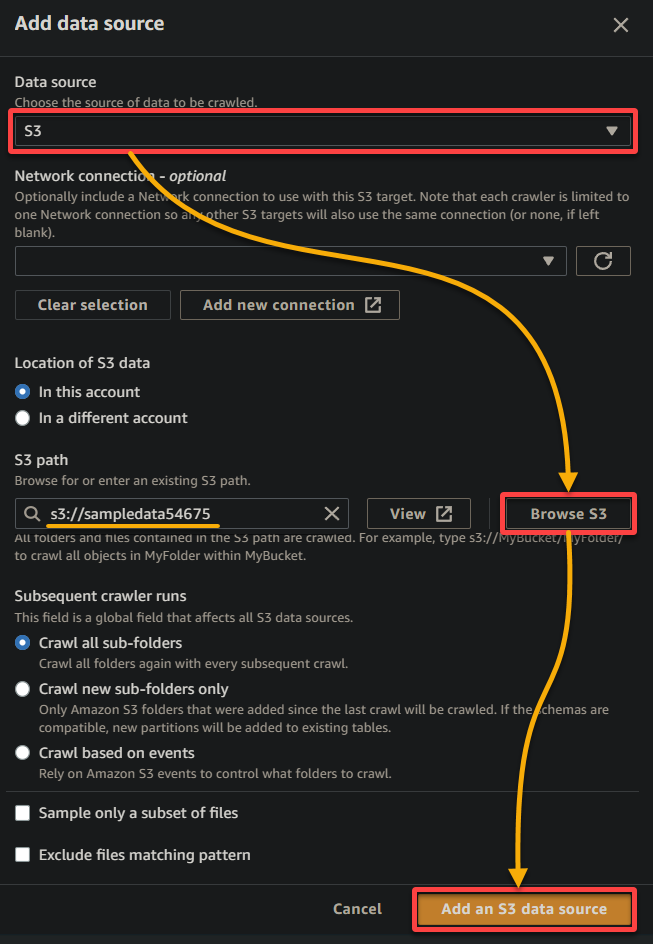
5.ポップアップウィンドウで、データソースを以下のように設定します:
- データソース– データがS3バケットにあるため、S3を選択します。
- S3パス – S3を参照をクリックし、アップロードされたサンプルデータ(sampledata54675)を含むバケットを選択してください。
- その他の設定はそのままにし、S3データソースを追加をクリックしてサンプルデータをクローラに追加してください。
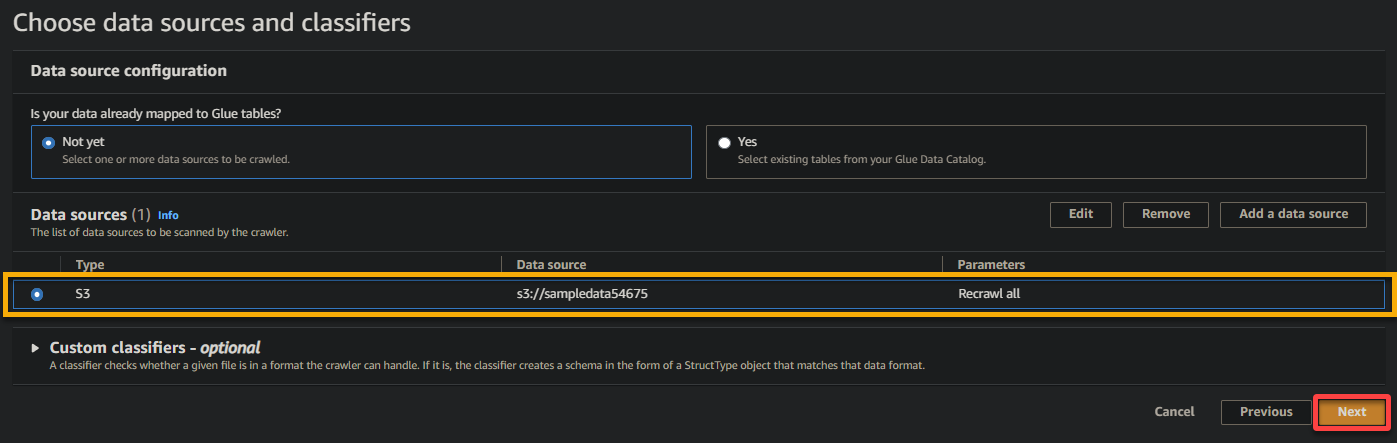
6. 設定が完了したら、以下のようにデータソースを確認し、次へをクリックして続行してください。
7. 次の画面で、以前に作成したIAMロール(glue_role)を選択し、その他の設定はそのままにして次へをクリックしてください。
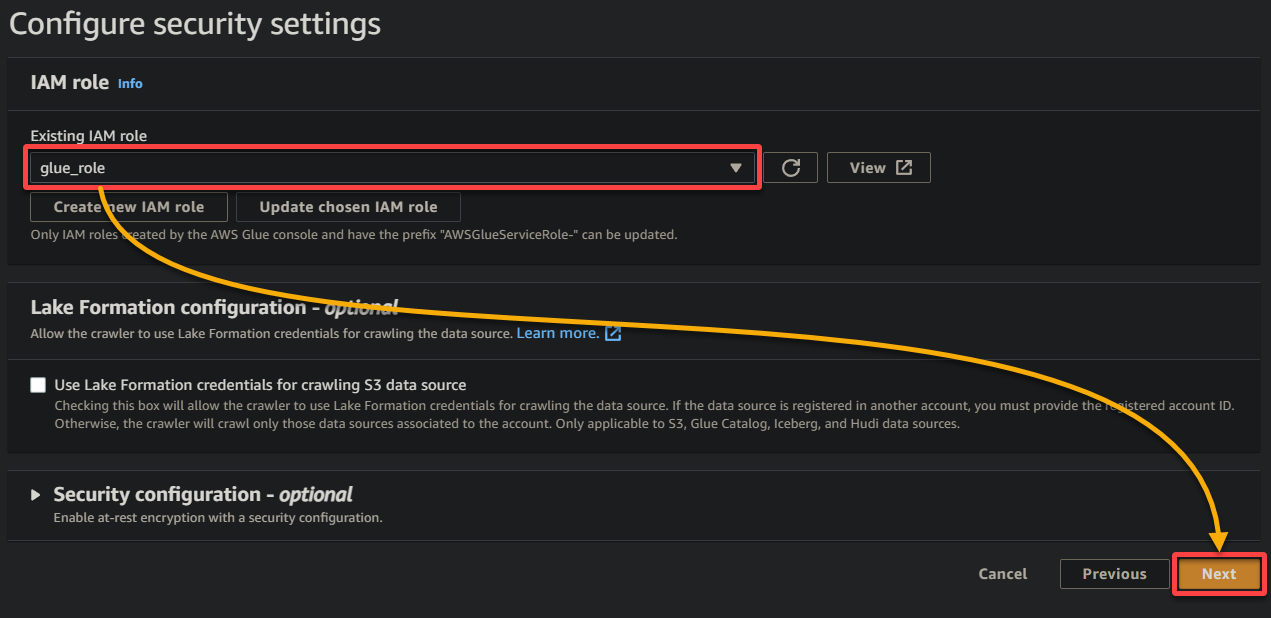
8. 出力とスケジューリングの下で、データベースを追加をクリックして、Glueクローラによって生成された処理済みデータおよびメタデータを格納する新しいデータベースの追加を開始してください。この操作により、新しいブラウザのタブが開き、データベースの詳細を設定します(ステップ8)。
このデータベースは、クエリと分析のためのデータの構造化された表現を提供します。
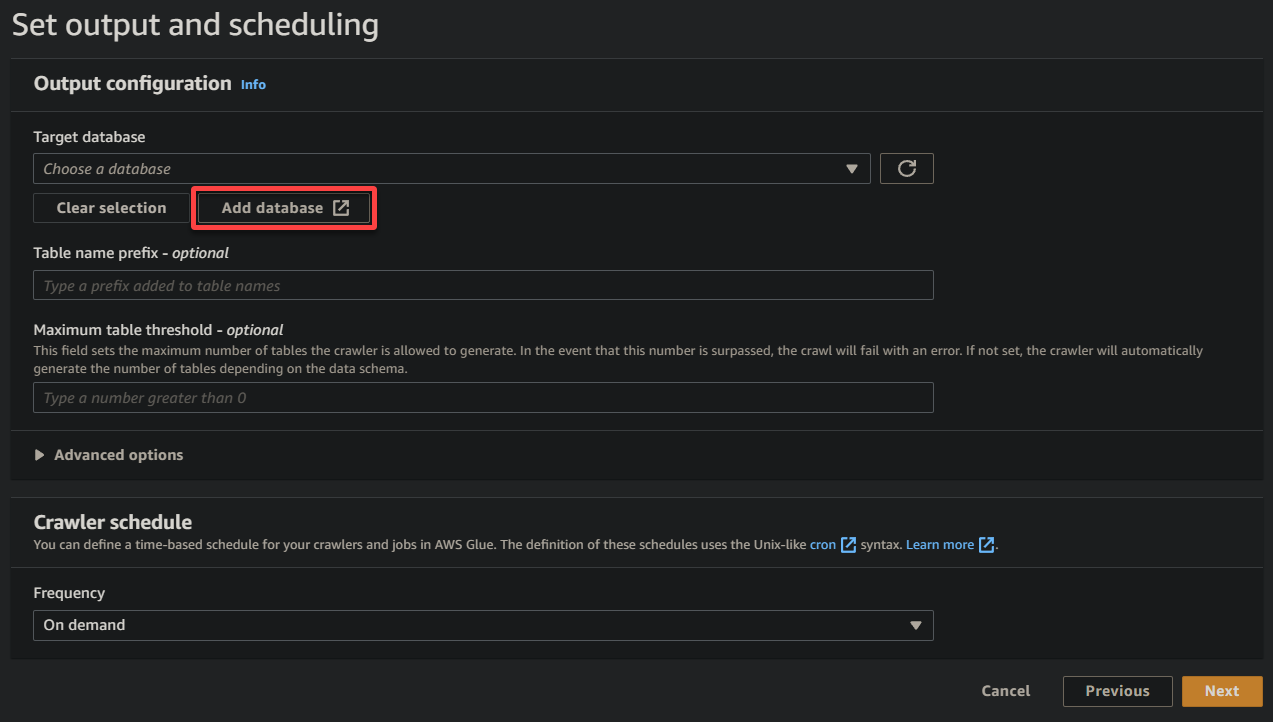
9. 新しいブラウザのタブで、説明的なデータベース名(例:glue_database)を入力し、データベースを作成をクリックしてデータベースを作成してください。
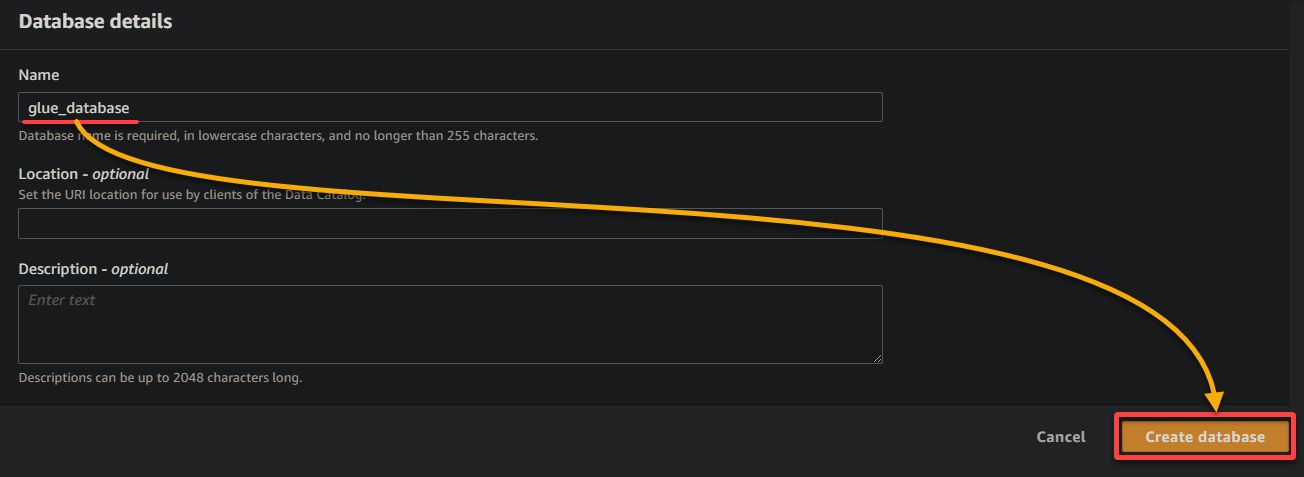
10. 前のブラウザのタブに切り替え、ドロップダウンから新しく作成されたデータベース(glue_database)を選択し、その他の設定はそのままにして次へをクリックしてください。
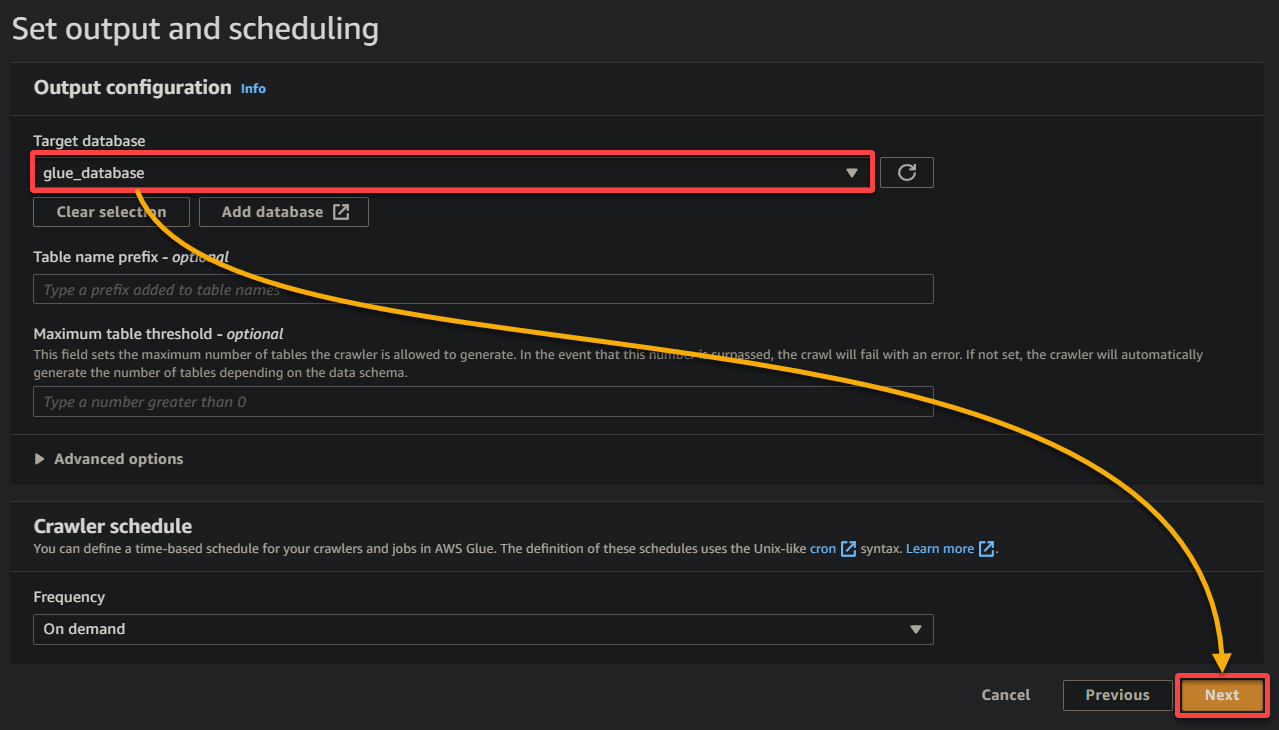
11. 最終画面で設定を確認し、正確であることを確認したら、新しいクローラを作成するために右下のクローラを作成をクリックしてください。
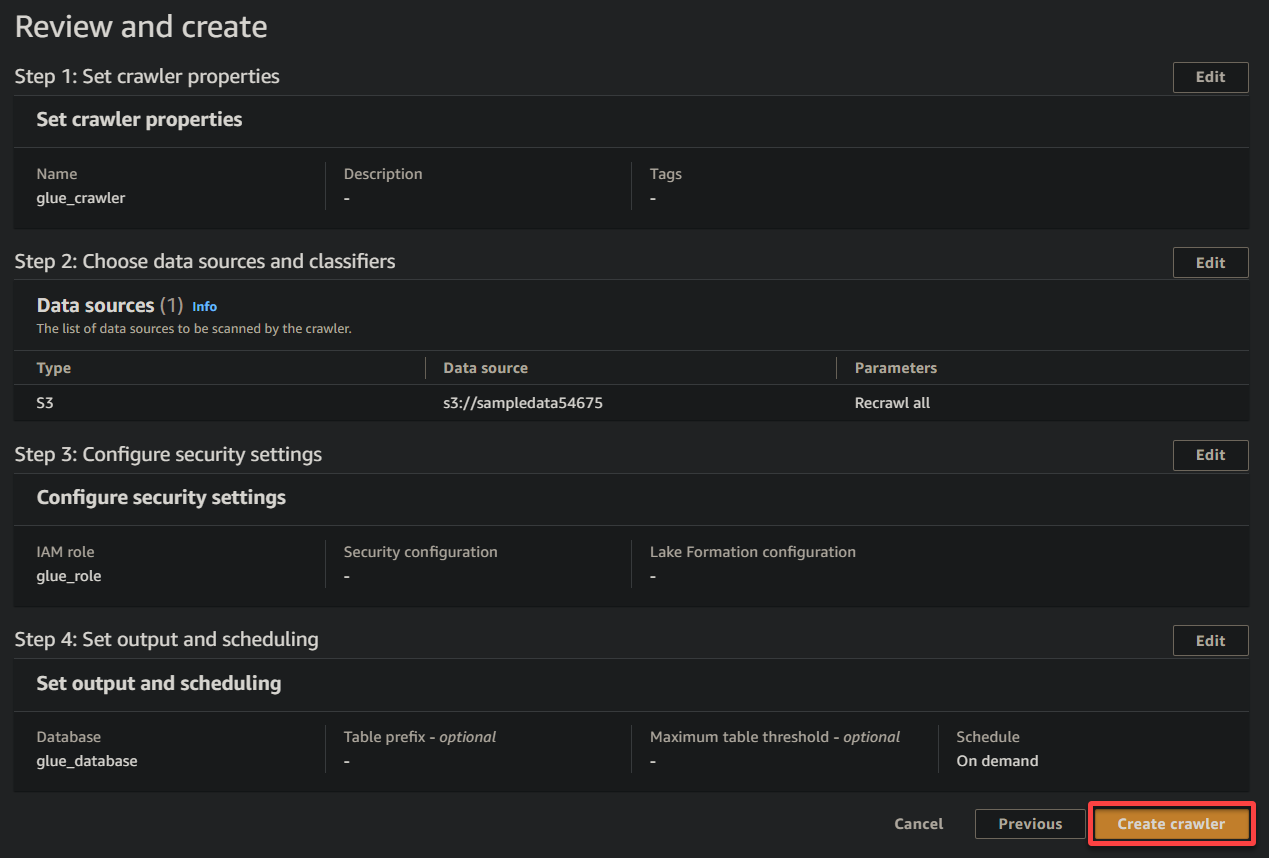
すべてがうまくいけば、クローラの作成が成功したことを確認する画面が表示されます。まだこの画面を閉じないでください。次のセクションでこのクローラを実行します。
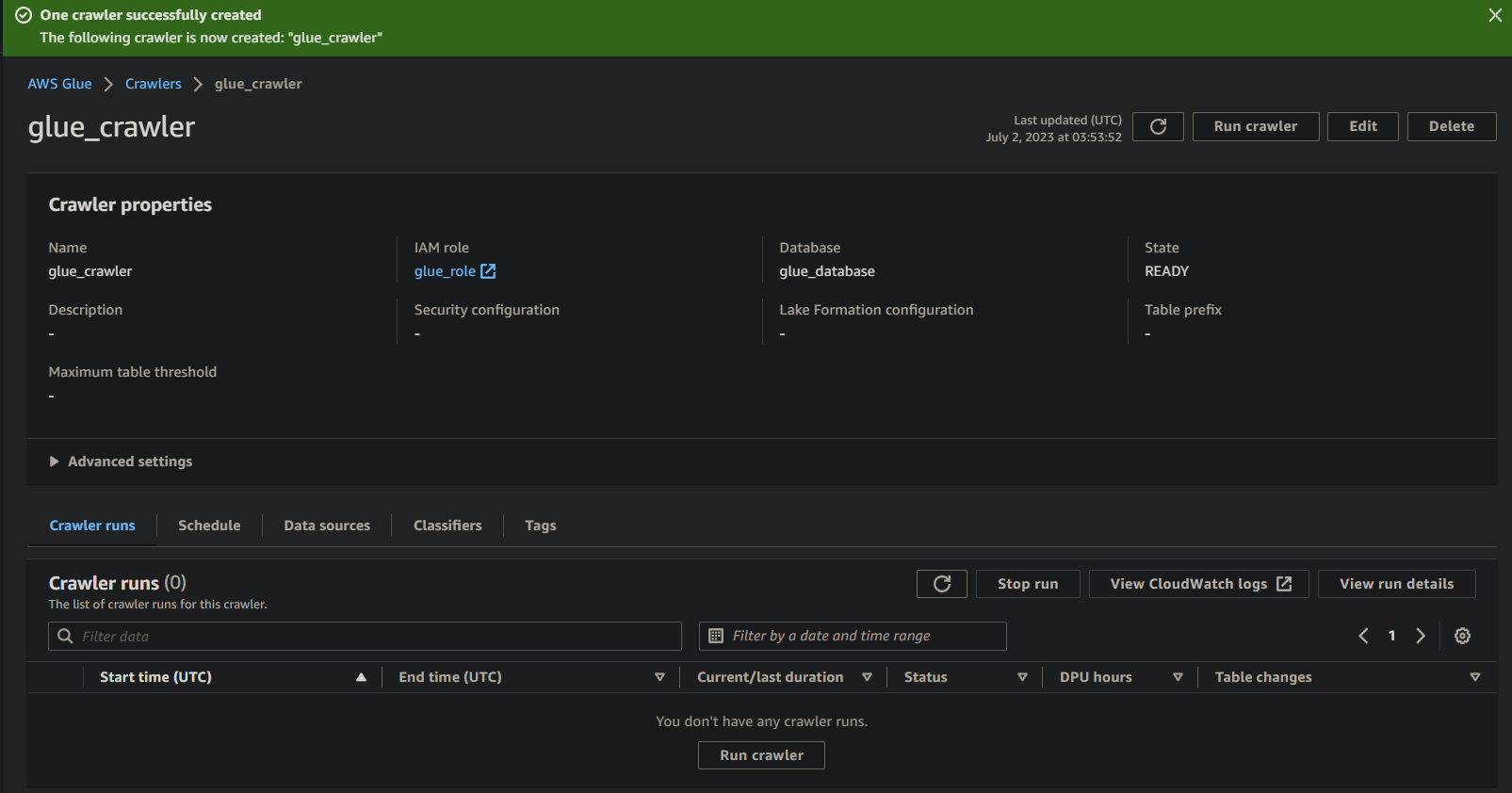
グルークローラーを実行してメタデータカタログを構築する
新しいクローラーを手に入れたら、クローラーを実行することがスキャンとカタログ化のプロセスを開始するために重要です。 グルークローラーは、データの構造化された表現を提供し、クエリと分析の目的で使用できるメタデータカタログを構築します。
新しく作成したグルークローラーを実行するには:
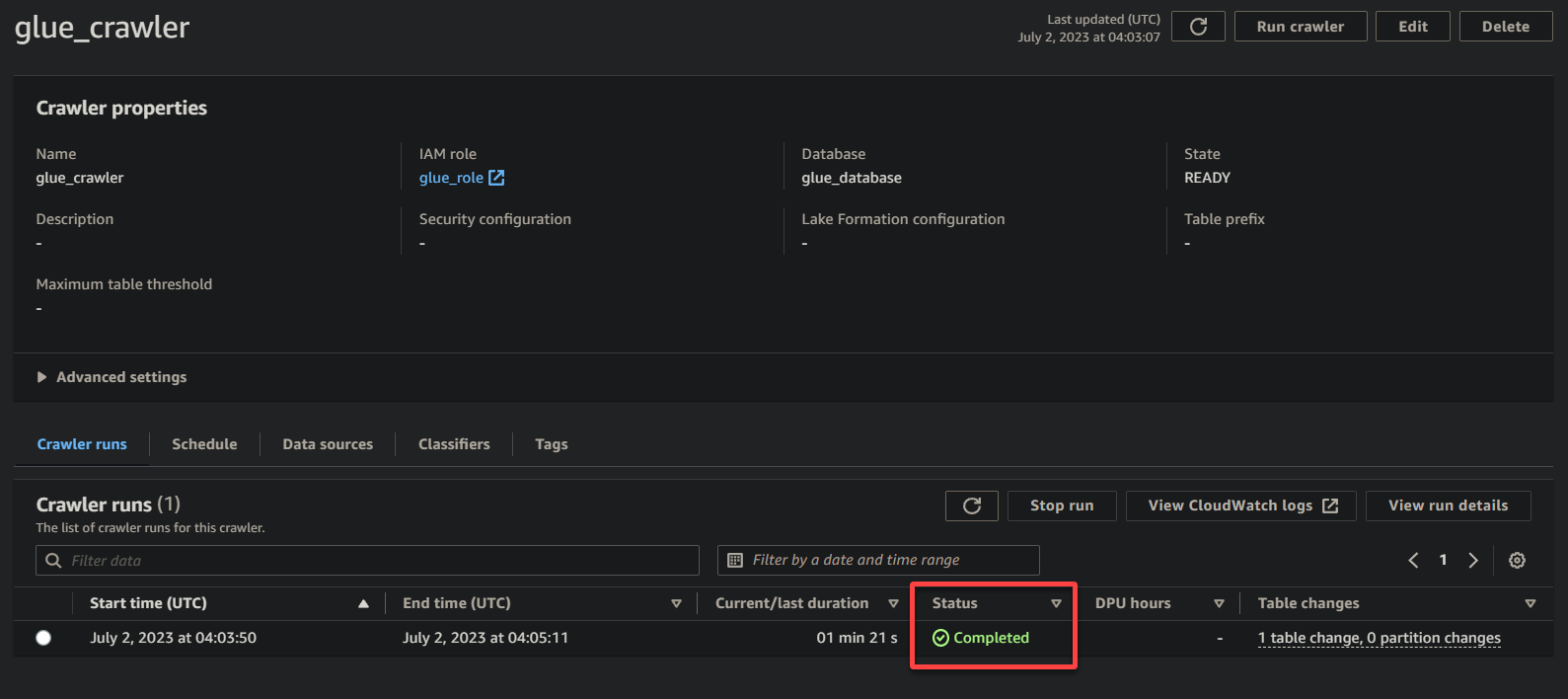
1. クローラーの詳細ページで、クローラーの実行 をクリックして、クローラーの実行を開始します。 クローラーの実行 タブがあります。
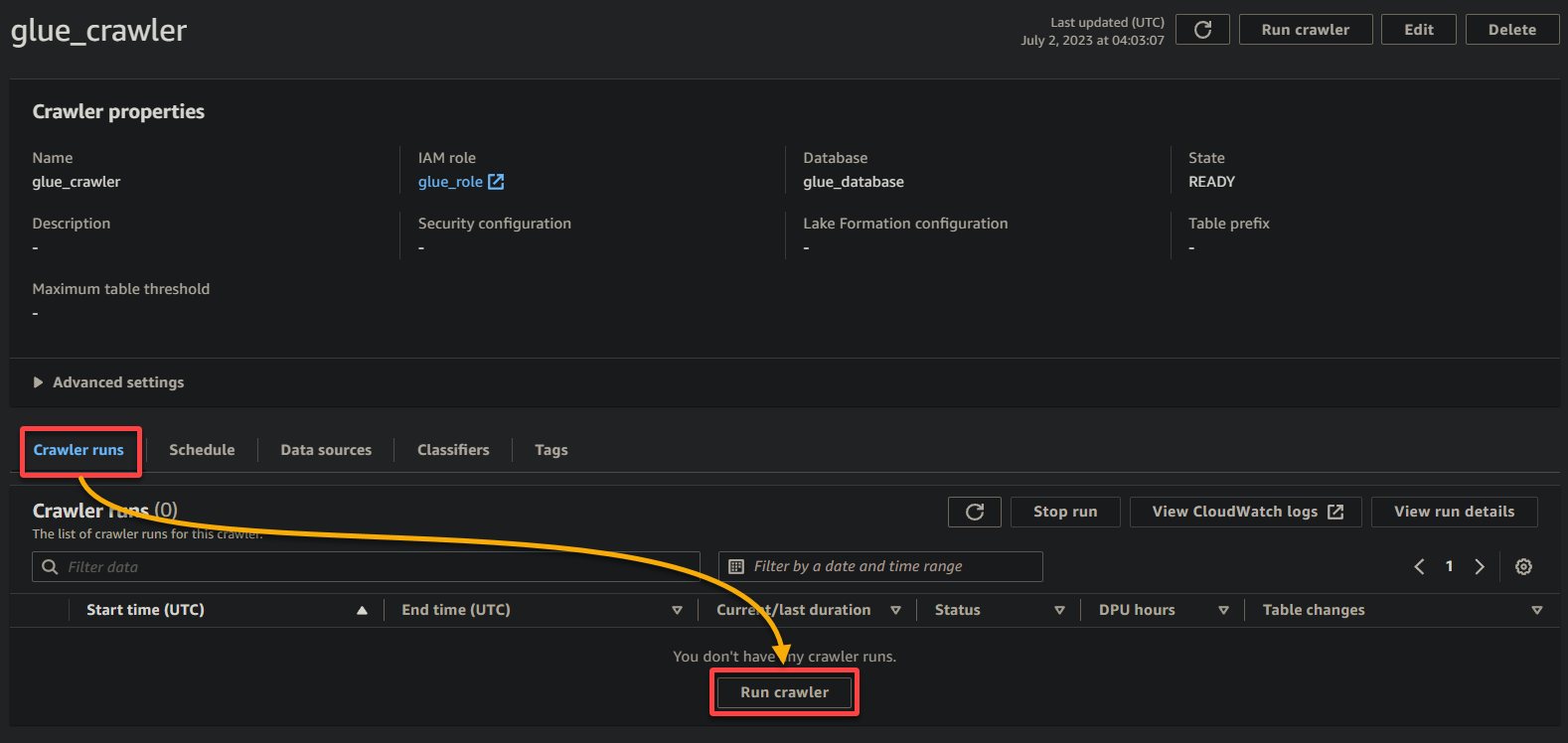
クローラーの実行が開始されると、クローラーの詳細ページでその状態と進捗状況が表示されます。
データのサイズや複雑さに応じて、クローラーの実行には時間がかかる場合があります。 クローラーの更新されたステータスを確認するために、定期的にページを更新できます。
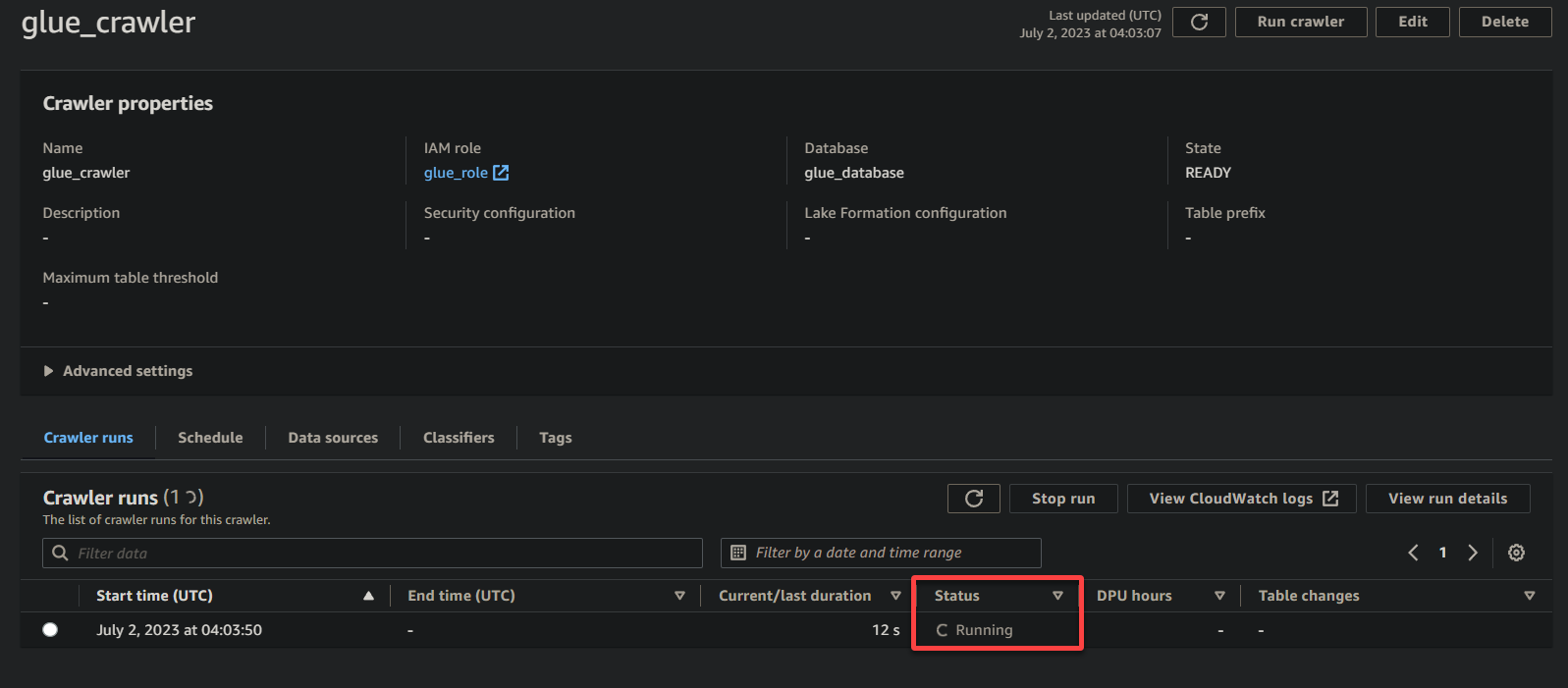
クローラーの実行が完了すると、ステータスが完了に変わります。 この時点で、データのクエリを実行できます。
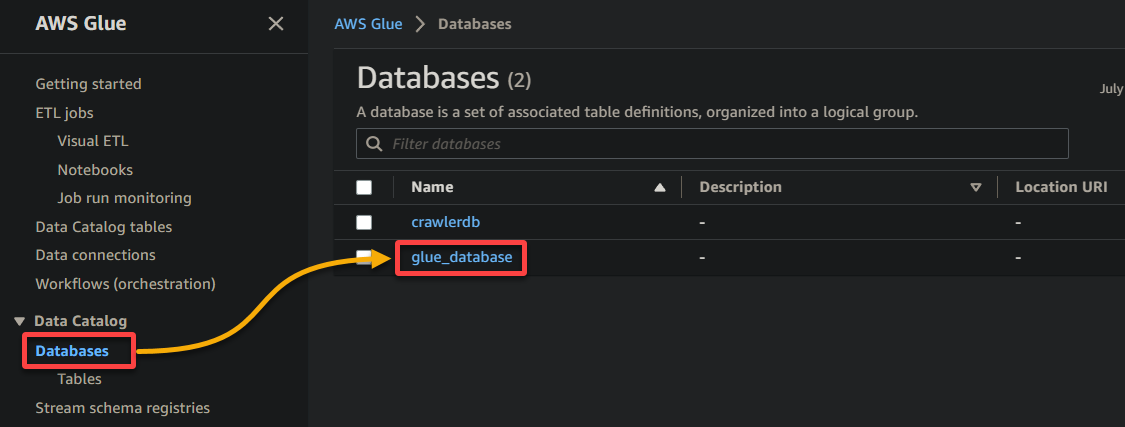
2. 次に、データベース(左側のペイン)に移動し、データベースをクリックしてそのプロパティとテーブルにアクセスします。
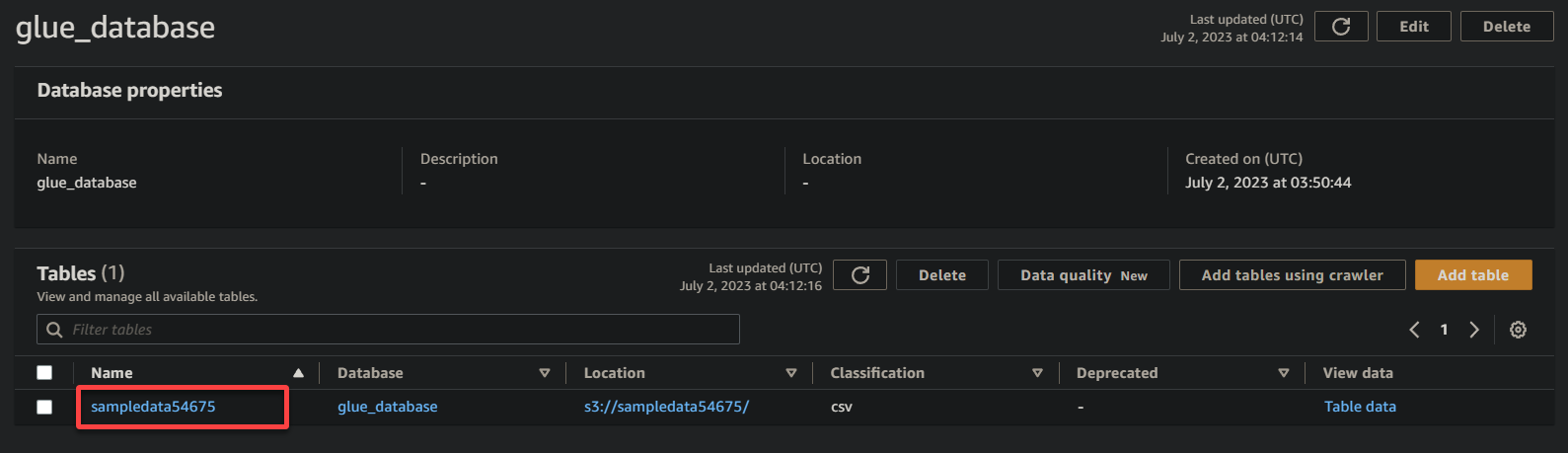
3. 最後に、バケットの名前(sampledata54675)をクリックして、保存されたデータを表示します。
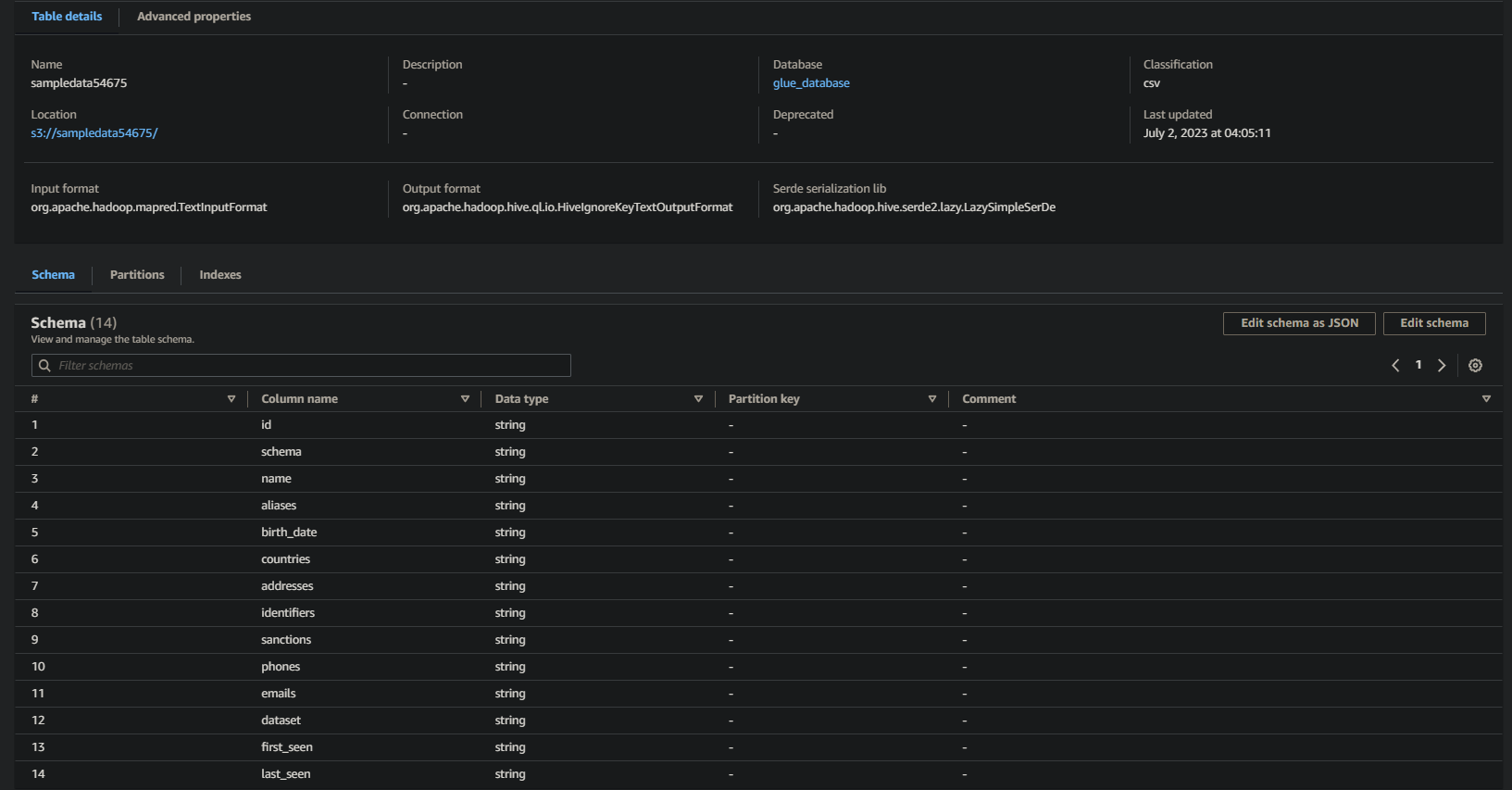
成功すると、以下のような情報が表示されます。 この情報により、データがデータベーステーブルに正常に変換され、貴重な詳細が提供されます。
AWS Athenaを使用してカタログ化されたデータのクエリを実行
AWS Glue Data Catalogでデータが利用可能になったので、さまざまなツールを使用してデータをクエリおよび分析することができます。そのようなツールの1つがAWS Athenaです。AWS Athenaは、標準のSQLを使用してクラウド上のデータを分析できるインタラクティブなクエリサービスです。
AWS Athenaを使用してデータをクエリするには、以下の手順に従ってください:
1. Athenaコンソールを検索してアクセスします。
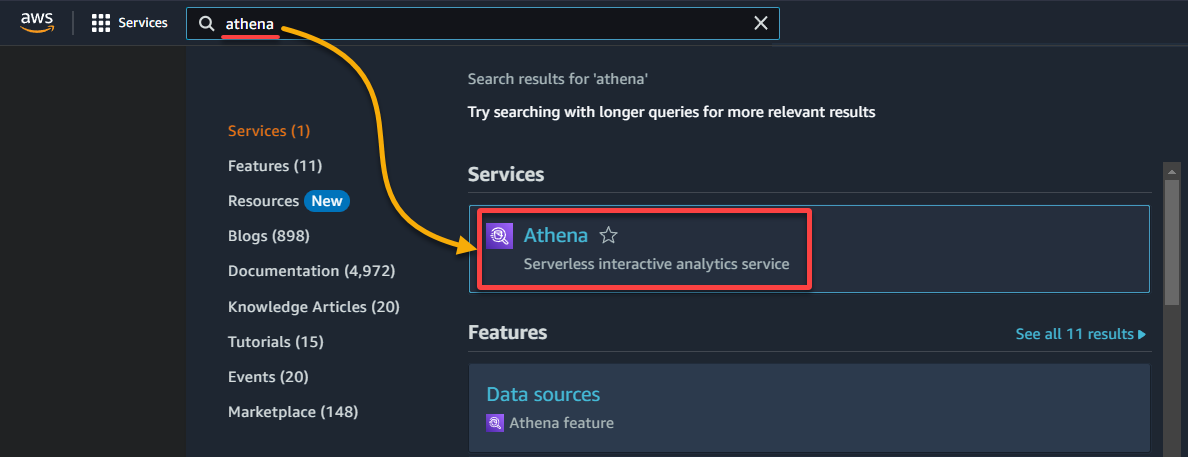
2. Dataセクションの下に、データがカタログ化されているデータベースを選択します。以下のように選択します:
- データソース – AWS Glueでカタログ化されたデータをクエリすることを示すために、AwsDataCatalogを選択します。
- データベース – ドロップダウンフィールドから適切なデータベースを選択します(例:glue_database)。
? ドロップダウンで目的のデータベースが表示されない場合は、クローラーが実行を完了し、データをカタログ化したことを確認してください。
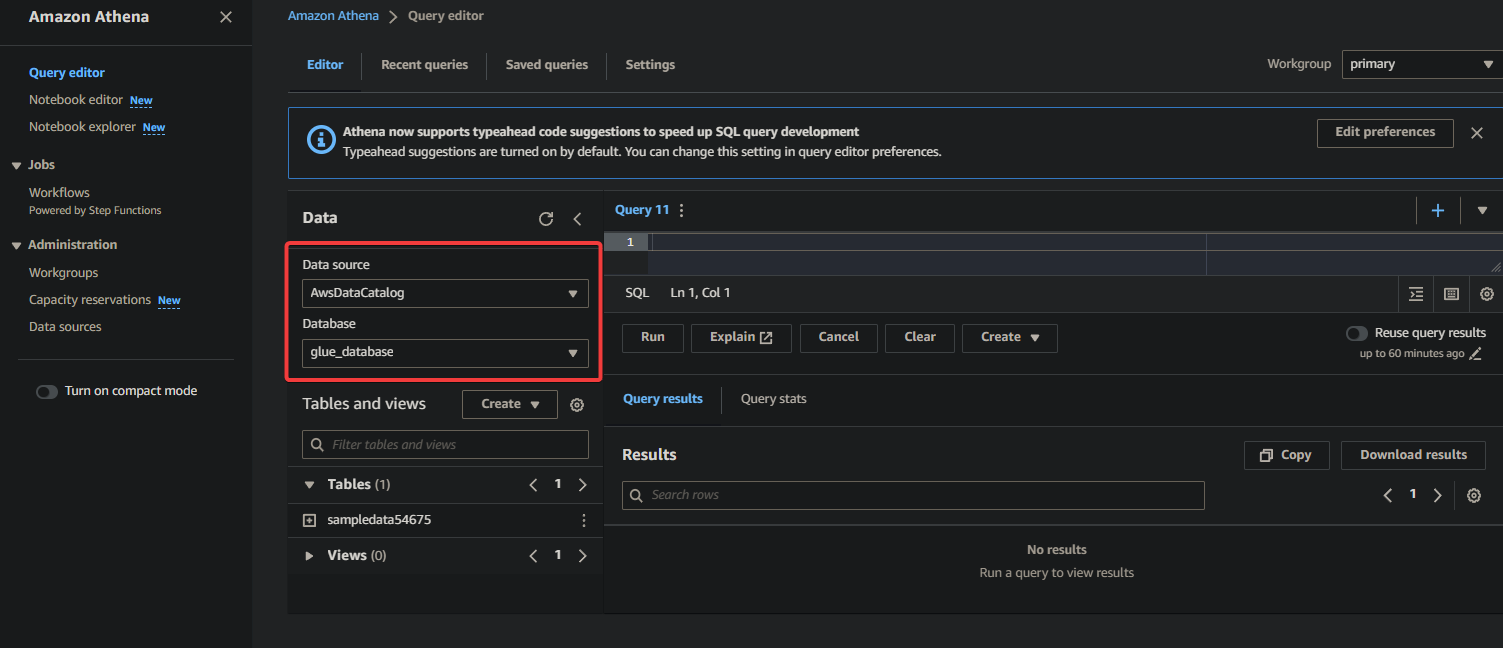
3. 最後に、右側のクエリエディタに以下のクエリを入力して実行します。
このクエリは、glue_databaseデータベースのsampledata54675テーブルから最初の10行を返します。必要に応じてクエリを変更して特定の要件に合わせてください。
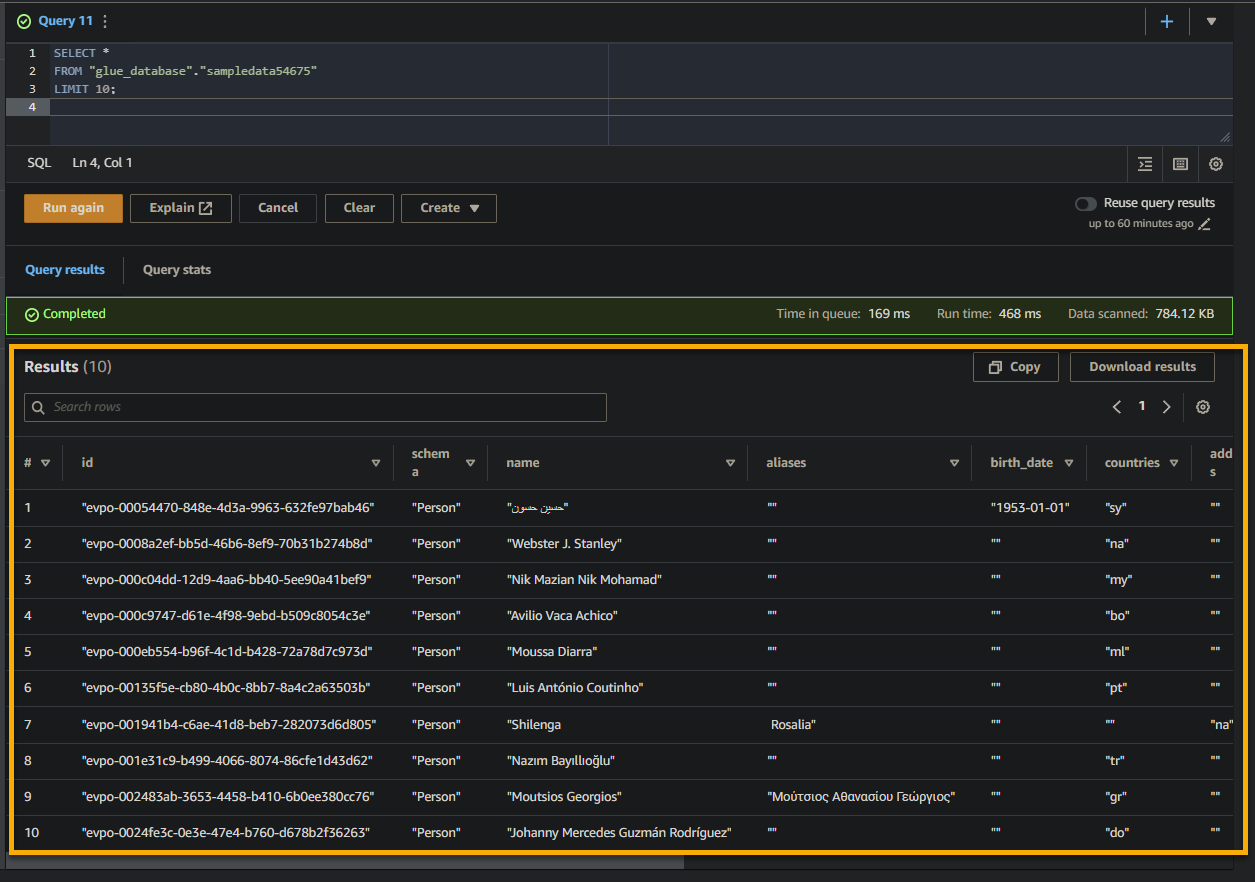
クエリが成功すると、以下のように結果ペインに結果が表示されます。結果には、SQLクエリに基づいてテーブルに格納されているレコードに関する情報が含まれています。
結果セットに含まれる列名、データ型、および値に注意してください。この情報は、クエリされたデータの構造と内容を理解するのに役立ちます。
結論
このチュートリアルでは、AWS Glueを使用してGlue Crawlerを作成し、データをカタログ化し、AWS Athenaを使用してデータをクエリする基本を学びました。データの準備と分析は、データに基づくアプリケーションにとって重要です。そして、AWS Glueのようなツールは、さまざまなソースからデータを抽出、変換、ロード(ETL)するための迅速な方法を提供します。
AWS Glueを使用すると、データを迅速に管理および整理できるため、データからの洞察を得ることにより、より注力できます。ただし、これまで見てきたのは氷山の一角に過ぎません。AWS Glueが提供できる広範な機能と機能を探索してみてください!
なぜAWS Glueの接続を活用しないでしょうか?これにより、Amazon RDSやAmazon Redshiftなどの他のAWSサービスとシームレスに統合できます。この統合により、複雑なETLパイプラインを構築し、さらに高度なデータ分析機能を実現できます。