













RAGシステムは検索メカニズムと言語モデルの力を組み合わせ、文脈的に関連性の高く、根拠のある応答を生成することを可能にします。しかし、RAGシステムの性能を評価し、潜在的な障害モードを特定することは非常に困難です。
そこで、RAGトライアド――RAGシステムの実行の3つの主要ステップを提供する3つの指標のトリアド:コンテキスト関連性、根拠性、そして回答関連性。このブログ記事では、RAGトライアドの複雑さを解き明かし、RAGシステムの評価を設定、実行、分析するプロセスをご案内します。
RAGトライアドの紹介:
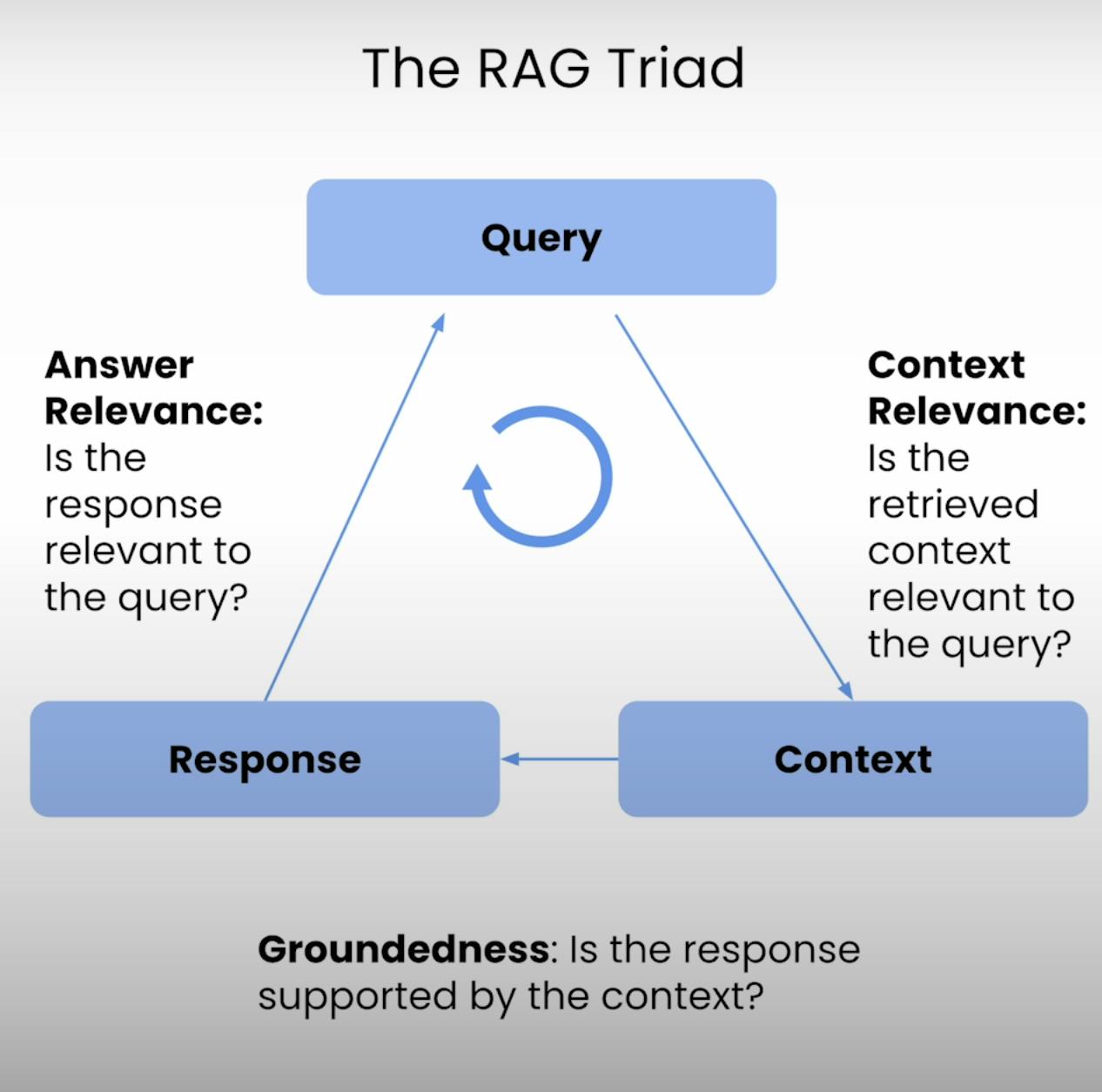
すべてのRAGシステムの中心には、検索と生成の微妙なバランスがあります。RAGトライアドは、この微妙なバランスの品質と潜在的な障害モードを評価する包括的なフレームワークを提供します。3つの要素を分解してみましょう。
A. Context Relevance:
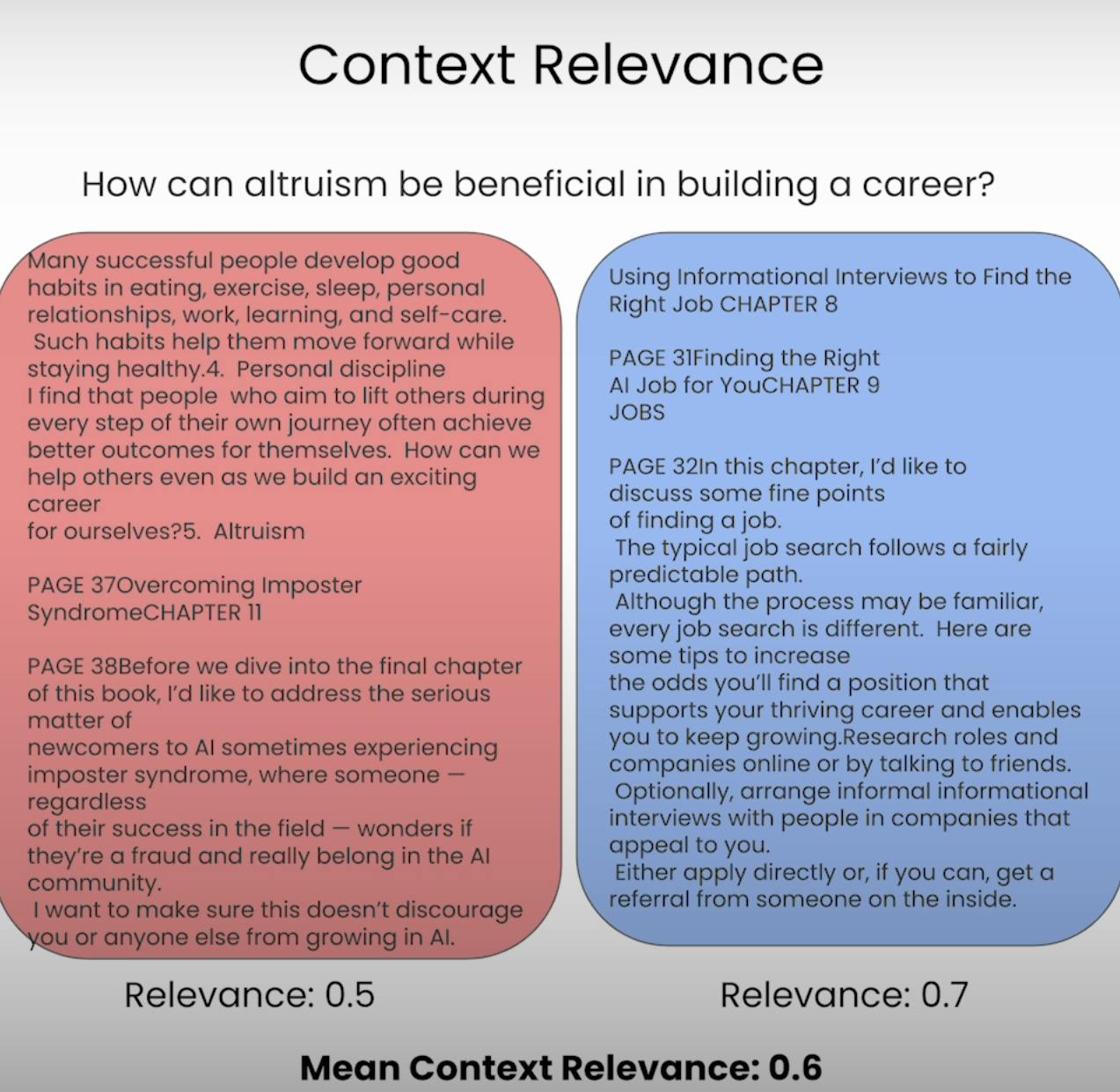
質問に答えることを期待されていると想像してくださいが、提供された情報が完全に無関係であるとします。それがまさにRAGシステムが避けようとしていることです。コンテキスト関連性は、検索された文脈の各部分が元のクエリにどれだけ関連しているかを評価することで、検索プロセスの品質を評価します。検索された文脈の関連性をスコアリングすることで、検索メカニズムにおける潜在的な問題を特定し、必要な調整を行うことができます。

B. Groundedness:
あなたは、誰かが事実を捏造したり、確固たる根拠のない情報を提供しているような会話を経験したことがありますか?それは、RAGシステムが根拠のなさに欠けているのと同じです。根拠のある評価は、システムが生成する最終的な応答が検索されたコンテキストにどれだけしっかりと根ざしているかを評価します。もし応答に検索された情報によって支持されていない声明や主張が含まれている場合、システムは幻覚を起こしているか、事前学習データに過度に依存している可能性があり、潜在的な不正確さやバイアスを引き起こす可能性があります。
C. Answer Relevance:
最寄りのコーヒーショップへの道順を尋ねて、ケーキ焼きの詳細なレシピを受け取るような状況を想像してください。それは、回答の関連性が防ぎたい状況の一例です。RAGトライアドのこの要素は、システムによって生成された最終的な応答が、元の問いに本当に関連しているかどうかを評価します。答えの関連性を評価することで、システムが質問を誤解したり、意図されたトピックから逸れたりしている事例を特定できます。

RAGトライアド評価の設定
評価プロセスに取り掛かる前に、土台を築く必要があります。RAGトライアド評価を設定するための必要なステップを一緒に見ていきましょう。
A. Importing Libraries and Establishing API Keys:
まずはじめに、必要なライブラリやモジュール、そしてOpenAIのAPIキーとLLMプロバイダーをインポートする必要があります。
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
次に、RAGシステムが扱う文書コーパスを読み込んでインデックス化します。この場合、「AIでのキャリア構築の方法」に関するAndrew NGのPDF文書を使用します。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

RAG トライアド評価の核心にあるのはフィードバック機能であり、これはトライアドの各コンポーネントを評価するための特殊な機能です。TrueLensライブラリを使用してこれらの機能を定義しましょう。


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
RAGアプリケーションと評価の実行
設定が完了したので、RAGシステムと評価フレームワークを実際に動作させる時が来ました。アプリケーションの実行と評価結果の記録に関係するステップを見ていきましょう。
A. Preparing the Evaluation Questions:
まず、RAGシステムが答えることを希望する評価用の質問セットを読み込みます。これらの質問は、評価プロセスの基盤となります。
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
次に、TruLensレコーダーを設置します。これは、プロンプト、応答、評価結果をローカルデータベースに記録するのに役立ちます。
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
RAGアプリケーションが各評価質問で実行されると、TruLensレコーダーはプロンプト、応答、中間結果、評価スコアを勤勉にキャプチャし、ローカルデータベースに保存してさらに分析するために使用します。
評価結果の分析
評価データが手元にあるので、分析に取り掛かり、洞察を得る時が来ました。結果を分析し、改善の可能性がある分野を特定するためのさまざまな方法を見てみましょう。
A. Examining Individual Record-Level Results:
時には、悪魔は細部に宿る。個々のレコードレベルの結果を検討することで、RAGシステムの強みと弱みをより深く理解することができます。
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
このコードスニペットは、個々のレコードのプロンプト、応答、評価スコアにアクセスできるようにし、システムがどこで苦戦したか、または優れた結果を出したかを特定することができます。
B. Viewing Aggregate Performance Metrics:
まず、全体像を見直してみましょう。TrueLensライブラリは、すべてのレコードにまたがるパフォーマンスメトリクスを集計し、RAGシステムの全体的なパフォーマンスを高レベルで把握できるランキングを提供しています。
tru.get_leaderboard(app_ids=[])
このランキングには、RAGトライアドの各コンポーネントの平均スコアだけでなく、待ち時間やコストなどのメトリクスも表示されます。これらの集計メトリクスを分析することで、レコードレベルでは明らかでないトレンドやパターンを特定できます。
C. Exploring the TrueLens Streamlit Dashboard:
CLIに加えて、TrueLensは評価結果を探索し分析するGUIを提供するStreamlitダッシュボードも提供しています。簡単なコマンドでダッシュボードを起動できます。
tru.run_dashboard()
ダッシュボードが立ち上がると、RAGシステムのパフォーマンスの包括的な概要が見られます。一目でRAGトライアドの各コンポーネントの集計メトリクスや、待ち時間とコスト情報を確認できます。
ドロップダウンメニューからアプリケーションを選択することで、評価結果の詳細なレコードレベルのビューにアクセスできます。各レコードはユーザーの入力プロンプト、RAGシステムの応答、そして回答の関連性、文脈の関連性、実体性に対応するスコアとともにきちんと表示されます。
個々のレコードをクリックすると、より深い洞察が得られます。各評価スコアの背後にある思考プロセスを探ることができ、評価を行う言語モデルの思考過程を説明します。この透明性は、潜在的な失敗モードや改善の余地を特定するのに役立ちます。
仮に、Groundednessスコアが低いレコードに出くわしたとしましょう。詳細を見ることで、RAGシステムの応答には、検索されたコンテキストに十分に根ざしていない声明が含まれていることに気づくかもしれません。ダッシュボードは、どの声明が根拠を欠いているかを正確に示してくれるため、問題の根本原因を突き止めることができます。
TrueLens Streamlitダッシュボードは、単なる可視化ツール以上のものです。そのインタラクティブな機能とデータ主導の洞察を活用することで、知識豊富な意思決定を行い、アプリケーションのパフォーマンスを強化するためのターゲット指向の行動を取ることができます。
高度なRAGテクニックと繰り返し改善
A. Introducing the Sentence Window RAG Technique:
1つの高度なテクニックは、Sentence Window RAGで、RAGシステムの一般的な失敗モードを解決します:コンテキストサイズが限定されている。コンテキストウィンドウサイズを拡大することで、Sentence Window RAGは言語モデルにより関連性の高く包括的な情報を提供し、システムのコンテキスト関連性とGroundednessを改善する可能性を目指しています。
B. Re-evaluating with the RAG Triad:
Sentence Window RAGテクニックを実装した後、同じRAGトライアドフレームワークを使用してそれを再評価するテストを行います。今回は、コンテキストサイズの増加による影響を探るため、コンテキスト関連性とGroundednessスコアに焦点を当てます。
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Sentence Window RAGテクニックはパフォーマンスを改善する可能性がありますが、最適なウィンドウサイズは特定のユースケースやデータセットによって異なる場合があります。ウィンドウサイズが小さすぎると、十分な関連性のあるコンテキストが提供されず、逆に大きすぎると無関係な情報が導入され、システムのGroundednessと回答関連性に影響を与える可能性があります。
異なるウィンドウサイズで実験し、RAGトリアドを用いて再評価することで、文脈の関連性と根拠性、そして回答の関連性のバランスの取れた最適点を見つけることができ、結果としてより堅牢で信頼性の高いRAGシステムを生み出すことができます。
結論:
文脈の関連性、根拠性、回答の関連性を含むRAGトリアドは、検索拡張生成システムの性能評価や潜在的な失敗モードの特定に役立つ有用なフレームワークであることが証明されました。
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems