













著者は、フリーおよびオープンソース基金を、寄付のためのライティングプログラムの一環として寄付先に選択しました。
紹介
Flaskは、Python言語でウェブアプリケーションを作成するための便利なツールや機能を提供する軽量なPythonウェブフレームワークです。 SQLAlchemyは、リレーショナルデータベース向けの効率的で高性能なデータベースアクセスを提供するSQLツールキットです。 SQLite、MySQL、およびPostgreSQLなど、いくつかのデータベースエンジンとやり取りする方法を提供します。 データベースのSQL機能にアクセスできます。 また、オブジェクト関係マッパー(ORM)も提供されており、簡単なPythonオブジェクトとメソッドを使用してクエリを実行し、データを処理できます。 Flask-SQLAlchemyは、Flask拡張機能であり、FlaskとSQLAlchemyを使用することを容易にし、Flaskアプリケーション内でSQLAlchemyを使用してデータベースとやり取りするためのツールやメソッドを提供します。
このチュートリアルでは、FlaskとFlask-SQLAlchemyを使用して、従業員管理システムを作成し、従業員用のテーブルを持つデータベースを作成します。各従業員には、固有のID、名、姓、固有のメールアドレス、年齢の整数値、会社に入社した日付、従業員が現在アクティブかどうかを判定するブール値があります。
Flaskシェルを使用してテーブルをクエリし、列の値(たとえば、メール)に基づいてテーブルレコードを取得します。特定の条件で従業員のレコードを取得し、例えばアクティブな従業員のみを取得したり、休暇中の従業員のリストを取得します。結果を列の値で並べ替え、クエリ結果をカウントして制限します。最後に、Webアプリケーションでページごとに一定数の従業員を表示するためにページネーションを使用します。
前提条件
-
ローカルPython 3プログラミング環境。 Python 3用のローカルプログラミング環境のインストールと設定に関するチュートリアルを参照してください。 このチュートリアルでは、プロジェクトディレクトリを
flask_appと呼びます。 -
ルート、ビュー関数、テンプレートなどの基本的なFlaskの概念の理解。Flaskに慣れていない場合は、FlaskとPythonを使用して最初のWebアプリケーションを作成する方法とFlaskアプリケーションでテンプレートを使用する方法をチェックしてください。
-
基本的なHTMLの概念の理解。背景知識として、HTMLでウェブサイトを構築する方法チュートリアルシリーズを確認できます。
-
データベースの設定、データベースモデルの作成、およびデータのデータベースへの挿入など、基本的なFlask-SQLAlchemyの概念の理解。背景知識については、Flaskアプリケーションでデータベースとのやり取りにFlask-SQLAlchemyを使用する方法を参照してください。
ステップ1 — データベースとモデルの設定
このステップでは、必要なパッケージをインストールし、Flaskアプリケーション、Flask-SQLAlchemyデータベース、および従業員データを格納するemployeeテーブルを表す従業員モデルを設定します。いくつかの従業員をemployeeテーブルに挿入し、アプリケーションのインデックスページで全ての従業員が表示されるルートとページを追加します。
まず、仮想環境をアクティブにした状態で、FlaskとFlask-SQLAlchemyをインストールします:
インストールが完了すると、最後に次の行が表示されます:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
必要なパッケージがインストールされている場合、flask_appディレクトリにapp.pyという新しいファイルを開きます。このファイルには、データベースの設定とFlaskのルートのコードが含まれます:
app.pyに以下のコードを追加します。このコードは、SQLiteデータベースとemployeeテーブルを表す従業員データベースモデルを設定します。これは、従業員データを保存するために使用します:
ファイルを保存して閉じます。
ここでは、osモジュールをインポートしています。これにより、様々なオペレーティングシステムインターフェースにアクセスできます。これを使用して、database.dbデータベースファイルのファイルパスを構築します。
flaskパッケージから、アプリケーションで必要なヘルパーをインポートしています: Flaskアプリケーションインスタンスを作成するためのFlaskクラス、テンプレートをレンダリングするrender_template()、リクエストを処理するrequestオブジェクト、URLを構築するurl_for()、ユーザーをリダイレクトするためのredirect()関数です。ルートとテンプレートの詳細については、Flaskアプリケーションでテンプレートを使用する方法を参照してください。
その後、Flask-SQLAlchemy拡張機能からSQLAlchemyクラスをインポートしています。これにより、FlaskとSQLAlchemyを統合し、すべての関数やクラスにアクセスできます。これを使用して、Flaskアプリケーションに接続するデータベースオブジェクトを作成します。
データベースファイルのパスを構築するには、ベースディレクトリを現在のディレクトリとして定義します。os.path.abspath()関数を使用して、現在のファイルのディレクトリの絶対パスを取得します。特別な__file__変数は現在のapp.pyファイルのパス名を保持します。ベースディレクトリの絶対パスをbasedirという変数に格納します。
次に、appという名前のFlaskアプリケーションインスタンスを作成し、Flask-SQLAlchemyの設定キーを2つ構成します。
-
SQLALCHEMY_DATABASE_URI:接続を確立するデータベースを指定するデータベースURI。この場合、URIはsqlite:///path/to/database.dbの形式に従います。basedir変数に構築して保存したベースディレクトリとdatabase.dbファイル名をos.path.join()関数を使用してインテリジェントに結合します。これにより、flask_appディレクトリ内のdatabase.dbデータベースファイルに接続します。データベースを初期化するとファイルが作成されます。 -
SQLALCHEMY_TRACK_MODIFICATIONS:オブジェクトの変更を追跡するかどうかを設定する構成です。追跡を無効にするにはFalseに設定します。これによりメモリ使用量が少なくなります。詳細については、Flask-SQLAlchemyドキュメントの構成ページを参照してください。
SQLAlchemyを設定してデータベースURIを設定し、追跡を無効にした後、SQLAlchemyクラスを使用してデータベースオブジェクトを作成します。 FlaskアプリケーションをSQLAlchemyに接続するために、アプリケーションインスタンスを渡します。データベースオブジェクトはdbという変数に格納され、データベースとやり取りする際に使用します。
アプリケーションインスタンスとデータベースオブジェクトを設定した後、db.Modelクラスから継承して、Employeeというデータベースモデルを作成します。このモデルはemployeeテーブルを表し、次の列があります:
id: 従業員ID、整数の主キー。firstname: 従業員の名、最大長100文字の文字列です。nullable=Falseは、この列が空であってはならないことを示します。lastname: 従業員の姓、最大長100文字の文字列です。nullable=Falseは、この列が空であってはならないことを示します。email: 従業員のメールアドレス、最大長100文字の文字列です。unique=Trueは、各メールアドレスが一意であることを示します。nullable=Falseは、その値が空であってはならないことを示します。age: 従業員の年齢、整数値です。hire_date: 従業員の雇用日。これを日付を保持する列として宣言するためにdb.Dateを列の型として設定します。active: 従業員が現在勤務中かどうかを示すブール値を保持する列です。
特別な__repr__関数を使用して、各オブジェクトに識別用の文字列表現を与えることができます。この場合、従業員オブジェクトを表すために従業員の名字と名前を使用します。
データベース接続と従業員モデルを設定したので、データベースを作成し、employeeテーブルを作成し、いくつかの従業員データをテーブルに挿入するPythonプログラムを書きます。
flask_appディレクトリにinit_db.pyという新しいファイルを開きます。
次のコードを追加して、既存のデータベーステーブルを削除し、クリーンなデータベースから開始し、employeeテーブルを作成し、その中に9人の従業員を挿入します。
ここでは、datetimeモジュールからdate()クラスをインポートして、従業員の採用日を設定するために使用します。
データベースオブジェクトとEmployeeモデルをインポートします。db.drop_all()関数を呼び出して、すべての既存のテーブルを削除し、データベース内に既にデータの入ったemployeeテーブルが存在する可能性を避けます。これにより、init_db.pyプログラムを実行するたびにすべてのデータベースデータが削除されます。データベーステーブルの作成、変更、削除の詳細については、Flaskアプリケーションでデータベースとやり取りするためのFlask-SQLAlchemyの使用方法を参照してください。
その後、このチュートリアルでクエリする従業員を表すEmployeeモデルの複数のインスタンスを作成し、db.session.add_all()関数を使用してそれらをデータベースセッションに追加します。最後に、トランザクションをコミットし、db.session.commit()を使用してデータベースに変更を適用します。
ファイルを保存して閉じます。
init_db.pyプログラムを実行します。
追加したデータをデータベースに表示するには、仮想環境がアクティブになっていることを確認し、Flaskシェルを開いてすべての従業員のクエリを実行し、データを表示します。
以下のコードを実行してすべての従業員のクエリを実行し、データを表示します。
query属性のall()メソッドを使用してすべての従業員を取得します。結果をループ処理し、従業員情報を表示します。active列に関しては、条件文を使用して従業員の現在のステータス、「’Active’」または「’Out of Office’」を表示します。
以下の出力が表示されます。
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
追加したデータベースのすべての従業員が適切に表示されていることがわかります。
Flaskシェルを終了します。
次に、従業員を表示するためのFlaskルートを作成します。編集用にapp.pyを開きます。
ファイルの末尾に次のルートを追加します。
ファイルを保存して閉じます。
これにより、すべての従業員をクエリし、index.htmlテンプレートをレンダリングし、取得した従業員を渡すことができます。
テンプレートディレクトリとベーステンプレートを作成します:
次のコードをbase.htmlに追加します:
ファイルを保存して閉じます。
ここでは、タイトルブロックを使用していくつかのCSSスタイリングを追加します。2つのアイテムを持つナビゲーションバーを追加します。1つはインデックスページ用であり、もう1つは非アクティブな「About」ページ用です。このナビゲーションバーは、このベーステンプレートから継承されるテンプレート内でアプリケーション全体で再利用されます。コンテンツブロックは各ページのコンテンツで置き換えられます。テンプレートについての詳細は、Flaskアプリケーションでテンプレートを使用する方法を参照してください。
次に、app.pyでレンダリングされた新しいindex.htmlテンプレートを開きます:
次のコードをファイルに追加します:
ここでは、従業員をループして、各従業員の情報を表示します。従業員がアクティブである場合は(アクティブ)ラベルを追加し、そうでない場合は(オフィス外)ラベルを表示します。
ファイルを保存して閉じます。
flask_appディレクトリ内で仮想環境をアクティブ化した状態で、アプリケーション(この場合はapp.py)に対してFlaskに通知し、FLASK_APP環境変数を使用してアプリケーションを設定します。次に、アプリケーションを開発モードで実行し、デバッガにアクセスします。Flaskデバッガの詳細については、Flaskアプリケーションでエラーを処理する方法を参照してください。次のコマンドを使用して、これを行います:
次に、アプリケーションを実行します:
開発サーバーが実行されている状態で、ブラウザを使用して次のURLにアクセスします:
http://127.0.0.1:5000/
以下のようなページに、データベースに追加した従業員が表示されます:
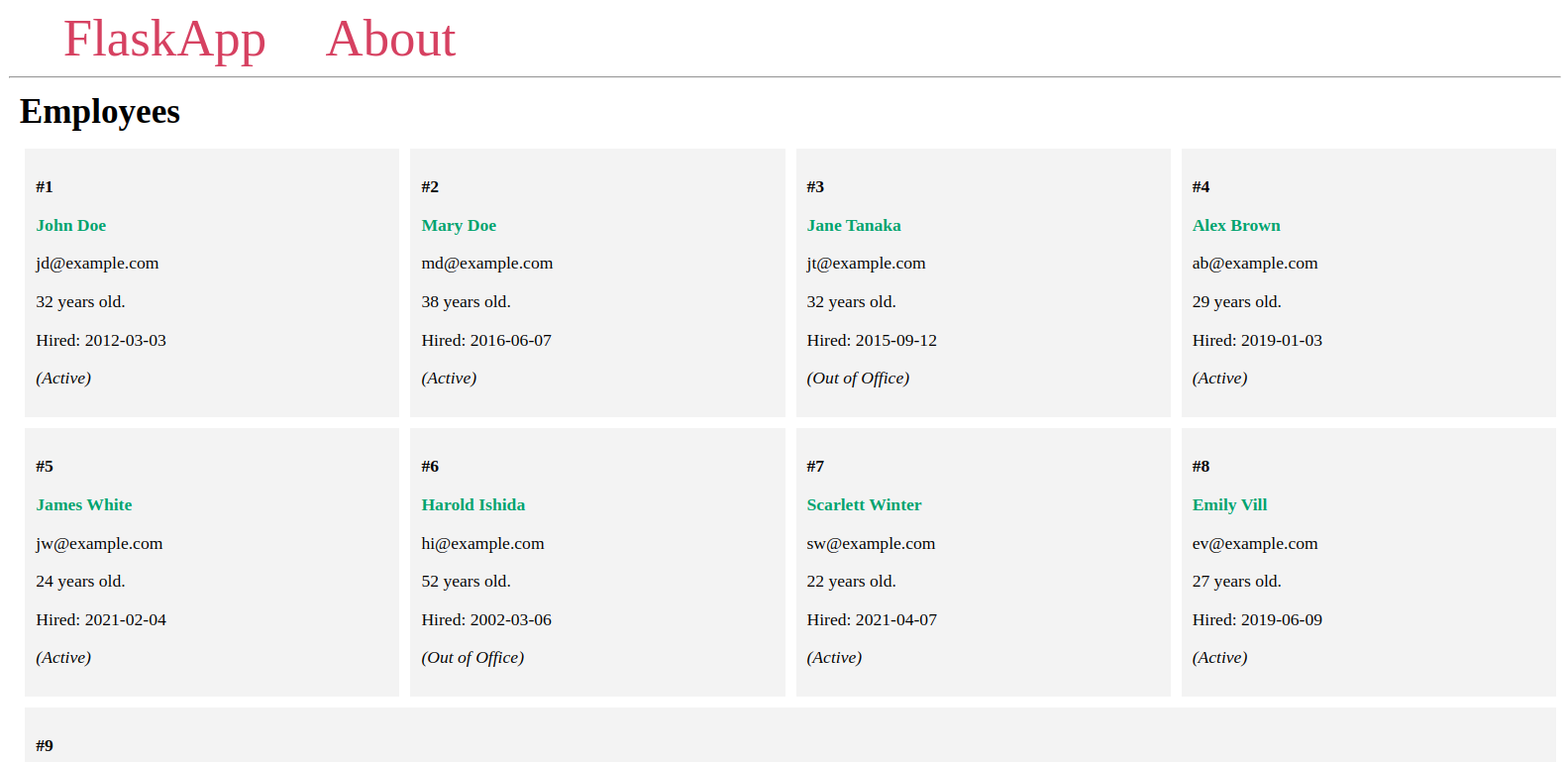
サーバーを実行したままにし、別のターミナルを開いて次の手順に進んでください。
データベースに登録されている従業員がインデックスページに表示されました。次に、Flaskシェルを使用して異なる方法で従業員をクエリします。
ステップ2 — レコードのクエリ
このステップでは、Flaskシェルを使用してレコードをクエリし、複数の方法と条件を使用して結果をフィルタリングおよび取得します。
プログラミング環境がアクティブ化されている状態で、FLASK_APPおよびFLASK_ENV変数を設定し、Flaskシェルを開きます:
dbオブジェクトとEmployeeモデルをインポートしてください:
すべてのレコードを取得する
前の手順で見たように、query属性のall()メソッドを使用してテーブル内のすべてのレコードを取得できます:
出力は、すべての従業員を表すオブジェクトのリストになります:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
最初のレコードを取得する
同様に、first()メソッドを使用して最初のレコードを取得できます:
出力は、最初の従業員のデータを保持するオブジェクトになります:
Output<Employee John Doe>
IDによるレコードの取得
ほとんどのデータベーステーブルでは、レコードは一意のIDで識別されます。 Flask-SQLAlchemyを使用すると、get()メソッドを使用してIDを指定してレコードを取得できます:
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
列の値によってレコードまたは複数のレコードを取得する
その列の値を使用してレコードを取得するには、filter_by()メソッドを使用します。たとえば、ID値を使用してレコードを取得するには、get()メソッドと同様に次のようにします:
Output<Employee John Doe>
filter_by()は複数の結果を返す可能性があるため、first()を使用します。
注意:IDによってレコードを取得する場合は、get()メソッドを使用する方が良いアプローチです。
別の例として、年齢を使用して従業員を取得できます:
Output<Employee Harold Ishida>
クエリ結果が複数の一致するレコードを保持している場合の例として、firstname列と名前がMaryである最初の名前(2人の従業員が共有している名前)を使用します:
Output[<Employee Mary Doe>, <Employee Mary Park>]
ここでは、完全なリストを取得するためにall()を使用します。最初の結果のみを取得するにはfirst()を使用することもできます:
Output<Employee Mary Doe>
列の値を使用してレコードを取得しました。次に、論理条件を使用してテーブルをクエリします。
ステップ3 — 論理条件を使用したレコードのフィルタリング
複雑で充実したウェブアプリケーションでは、場所、可用性、役割、責任などを考慮した条件の組み合わせに基づいて従業員を取得する必要があります。このステップでは、条件演算子の使用方法を練習します。異なる演算子を使用して論理条件を使用してクエリ結果をフィルタリングするために、query属性上のfilter()メソッドを使用します。たとえば、現在休暇中の従業員のリストを取得したり、昇進予定の従業員を取得したり、従業員の休暇時間のカレンダーを提供したりできます。
等しい
使用できる最も単純な論理演算子は等価演算子==であり、これはfilter_by()と似た方法で動作します。たとえば、firstname列の値がMaryであるレコードをすべて取得するには、次のようにfilter()メソッドを使用できます:
ここでは、filter()メソッドへの引数としてModel.column == valueの構文を使用します。filter_by()メソッドはこの構文のショートカットです。
結果は、同じ条件でfilter_by()メソッドの結果と同じです:
Output[<Employee Mary Doe>, <Employee Mary Park>]
filter_by()と同様に、first()メソッドを使用して最初の結果を取得することもできます。
Output<Employee Mary Doe>
等しくない
filter()メソッドを使用すると、!= Python演算子を使用してレコードを取得できます。たとえば、外出している従業員のリストを取得するには、次の方法を使用できます。
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
ここでは、結果をフィルタリングするためにEmployee.active != True条件を使用しています。
未満
<演算子を使用して、指定された列の値が指定された値よりも小さいレコードを取得できます。たとえば、32歳未満の従業員のリストを取得するには:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
指定された値以下のレコードには<=演算子を使用します。たとえば、前のクエリに32歳の従業員を含めるには:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
より大きい
同様に、>演算子は、指定された値よりも大きいレコードを取得します。たとえば、32歳を超える従業員を取得するには:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
そして>=演算子は、指定された値以上のレコードです。たとえば、前のクエリに32歳の従業員を再度含めることができます。
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
SQLAlchemy
は、in_()メソッドを使用して、列の値が指定された値のリストの値と一致するレコードを取得する方法も提供しています。以下のように、列にin_()メソッドを使用します:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
ここでは、Model.column.in_(iterable)という構文の条件を使用します。ここで、iterableは任意の種類の反復可能なオブジェクトです。別の例として、range() Python関数を使用して特定の年齢範囲の従業員を取得できます。次のクエリは、30代の従業員をすべて取得します。
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Not In
in_()メソッドと同様に、not_in()メソッドを使用して、指定された反復可能オブジェクトに列の値が含まれていないレコードを取得できます:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
ここでは、namesリストに名前がある場合を除くすべての従業員を取得します。
And
db.and_()関数を使用して複数の条件を結合することができます。これはPythonのand演算子と同様に機能します。
例えば、32歳で現在活動中の従業員をすべて取得したいとします。まず、filter_by()メソッド(必要に応じてfilter()も使用できます)を使用して、誰が32歳かを確認できます:
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
ここでは、JohnとJaneが32歳の従業員であることがわかります。Johnは活動中であり、Janeは外出中です。
32歳かつ活動中の従業員を取得するには、filter()メソッドで2つの条件を使用します:
Employee.age == 32Employee.active == True
これらの2つの条件を結合するには、db.and_()関数を使用します:
Output[<Employee John Doe>]
ここでは、filter(db.and_(condition1, condition2))の構文を使用しています。
クエリにall()を使用すると、2つの条件に一致するすべてのレコードのリストが返されます。最初の結果を取得するには、first()メソッドを使用できます:
Output<Employee John Doe>
より複雑な例では、db.and_()をdate()関数と組み合わせて特定の時間枠で採用された従業員を取得できます。この例では、2019年に採用されたすべての従業員を取得します:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
ここでは、date()関数をインポートし、次の2つの条件を組み合わせるためにdb.and_()関数を使用して結果をフィルタリングしています:
Employee.hire_date >= date(year=2019, month=1, day=1): これは、2019年1月1日以降に雇用された従業員に対してTrueです。Employee.hire_date < date(year=2020, month=1, day=1): これは2020年1月1日より前に雇われた従業員に対してTrueです。
両方の条件を組み合わせると、2019年の最初の日から2020年の最初の日までに雇われた従業員が取得されます。
または
db.or_()は、db.and_()と同様に、2つの条件を組み合わせ、Pythonのor演算子のように振る舞います。2つの条件のいずれかを満たすレコードを取得します。たとえば、年齢が32歳または52歳の従業員を取得するには、次のようにdb.or_()関数で2つの条件を組み合わせます。
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
startswith()およびendswith()メソッドを使用して、filter()メソッドに渡す条件の文字列値を使用することもできます。たとえば、名前が文字列'M'で始まる従業員と、姓が文字列'e'で終わる従業員を取得するには:
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
次の2つの条件を組み合わせます。
Employee.firstname.startswith('M'):名前が'M'で始まる従業員に一致します。Employee.lastname.endswith('e'):姓が'e'で終わる従業員に一致します。
これで、Flask-SQLAlchemyアプリケーションで論理条件を使用してクエリ結果をフィルタリングできるようになりました。次に、データベースから取得した結果を並べ替え、制限し、数えます。
フィードバックはありますか?
ステップ4 — 結果の並べ替え、制限、および数え上げ
ウェブアプリケーションでは、表示するときにレコードを並べ替える必要があります。たとえば、各部門の最新の採用を表示するページがあるとします。これにより、チームの残りのメンバーに新入社員について知らせることができます。また、最も古い採用を最初に表示することで、長期在籍の従業員を認識することができます。また、特定の場合には結果を制限する必要があります。たとえば、小さなサイドバーに最新の3人の採用のみを表示するなどです。さらに、クエリの結果を数える必要があります。たとえば、現在アクティブな従業員の数を表示するためです。このステップでは、結果の並べ替え、制限、および数え上げの方法を学びます。
結果の並べ替え
特定の列の値を使用して結果を並べ替えるには、order_by() メソッドを使用します。たとえば、従業員の名前で結果を並べ替えるには次のようにします:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
出力に示されているように、結果は従業員の名前のアルファベット順に並べ替えられます。
他の列でも並べ替えることができます。たとえば、姓で従業員を並べ替えることができます:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
また、採用日によって従業員を並べ替えることもできます。
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
出力に示されているように、これは最も早く雇われた従業員から最も最近に雇われた従業員への結果を順に並べ替えます。順序を逆にして、最も最近の雇用から最も古い雇用に降順にするには、desc()メソッドを使用します。次のようにして:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
order_by()メソッドをfilter()メソッドと組み合わせて、フィルタリングされた結果を順序付けることもできます。次の例では、2021年に採用されたすべての従業員を取得し、その年齢で並べ替えます:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
ここでは、db.and_()関数を2つの条件と共に使用します:Employee.hire_date >= date(year=2021, month=1, day=1)(2021年1月1日以降に採用された従業員)およびEmployee.hire_date < date(year=2022, month=1, day=1)(2022年1月1日より前に採用された従業員)。その後、order_by()メソッドを使用して、その結果として得られる従業員を年齢順に並べ替えます。
結果の制限
ほとんどの実世界のケースでは、データベーステーブルをクエリする際に、何百万もの一致する結果が得られることがあり、結果を特定の数に制限する必要がある場合があります。Flask-SQLAlchemyで結果を制限するには、limit()メソッドを使用できます。次の例はemployeeテーブルをクエリし、最初の3つの一致する結果のみを返します:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
limit()をfilterやorder_byなどの他のメソッドと組み合わせることもできます。たとえば、次のようにして、2021年に採用された最後の2人の従業員を取得するには、limit()メソッドを使用できます:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
前のセクションと同じクエリを使用して、追加のlimit(2)メソッド呼び出しを行います。
結果のカウント
クエリの結果の数をカウントするには、count()メソッドを使用できます。たとえば、データベースに現在存在する従業員の数を取得するには:
Output9
count()メソッドをlimit()などの他のクエリメソッドと組み合わせることができます。たとえば、2021年に雇われた従業員の数を取得するには:
Output3
ここでは、以前に2021年に雇われたすべての従業員を取得するために使用したクエリを使用しています。そして、count()を使用してエントリの数(3つ)を取得します。
Flask-SQLAlchemyでクエリ結果を並べ替え、制限し、カウントしました。次に、Flaskアプリケーションでクエリ結果を複数のページに分割し、ページネーションシステムを作成する方法を学びます。
ステップ5 — 複数のページに長いレコードリストを表示する
このステップでは、メインルートを変更してインデックスページで従業員を複数のページに表示し、従業員リストのナビゲーションを容易にします。
最初に、Flaskシェルを使用して、Flask-SQLAlchemyのページネーション機能の使用方法をデモンストレーションします。すでにFlaskシェルを開いていない場合は、開いてください:
テーブルの従業員レコードを複数のページに分割し、ページごとに2つのアイテムに分割したいとします。次のようにpaginate()クエリメソッドを使用してこれを行うことができます:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
この場合、paginate()クエリメソッドのpageパラメータを使用してアクセスするページを指定します。そして、per_pageパラメータは各ページが持つアイテムの数を指定します。この場合、各ページに2つのアイテムを持つように設定します。
ここでのpage1変数はページネーションオブジェクトであり、ページネーションを管理するために使用する属性やメソッドにアクセスできます。
ページのアイテムにはitems属性を使用してアクセスします。
次のページにアクセスするには、ページネーションオブジェクトのnext()メソッドを使用します。返された結果もページネーションオブジェクトです:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
前のページのページネーションオブジェクトはprev()メソッドを使用して取得できます。次の例では、4番目のページのページネーションオブジェクトにアクセスし、その前のページであるページ3のページネーションオブジェクトにアクセスします:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
現在のページ番号にはpage属性を使用してアクセスできます。
Output1
2
ページの総数を取得するには、ページネーションオブジェクトのpages属性を使用します。次の例では、page1.pagesとpage2.pagesの両方が同じ値を返します。これは、総ページ数が一定であるためです:
Output5
5
アイテムの総数を取得するには、ページネーションオブジェクトのtotal属性を使用します:
Output9
9
ここでは、全従業員をクエリしているため、ページネーションの総アイテム数は9です。なぜなら、データベースには9人の従業員がいるからです。
以下は、ページネーションオブジェクトが持っている他の属性のいくつかです:
prev_num: 前のページ番号。next_num: 次のページ番号。has_next: 次のページがある場合はTrue。has_prev: 前のページがある場合はTrue。per_page: ページごとのアイテム数。
また、ページネーションオブジェクトには、ページ番号にアクセスするためのiter_pages()メソッドもあります。たとえば、次のようにしてすべてのページ番号を印刷できます:
Output1
2
3
4
5
次は、ページネーションオブジェクトとiter_pages()メソッドを使用してすべてのページとそのアイテムにアクセスする方法のデモンストレーションです:
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
ここでは、最初のページから始まるページネーションオブジェクトを作成します。iter_pages()ページネーションメソッドを使用してforループを介してページをループします。ページ番号とページアイテムを印刷し、next()メソッドを使用してpaginationオブジェクトをその次のページのページネーションオブジェクトに設定します。
filter() メソッドと order_by() メソッドを paginate() メソッドと組み合わせて、フィルタリングされた順序付けされたクエリ結果をページ分割できます。たとえば、次のようにして、30歳以上の従業員を取得し、結果を年齢順に並べ替えてページ分割できます:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
Flask-SQLAlchemy でのページ分割の仕組みがどのように機能するかをしっかりと理解したので、アプリケーションのインデックスページを編集して、複数ページにまたがる従業員を表示し、ナビゲーションを容易にします。
Flask シェルを終了します:
異なるページにアクセスするには、URL パラメータ、別名 URL クエリ文字列 を使用します。これは、URL を介してアプリケーションに情報を渡す方法です。パラメータは、? 記号の後の URL に渡されます。たとえば、異なる値を持つ page パラメータを渡すには、次のような URL を使用できます:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
ここでは、最初の URL は page パラメータに値 1 を渡しています。2 番目の URL は同じパラメータに値 3 を渡しています。
app.py ファイルを開きます:
インデックスルートを以下のように編集します:
ここでは、request.args オブジェクトとその get() メソッドを使用して、page URL パラメータの値を取得します。たとえば、/?page=1 は page URL パラメータから値 1 を取得します。デフォルト値として 1 を渡し、type パラメータに int Python 型を引数として渡して、値が整数であることを確認します。
次に、paginationオブジェクトを作成し、最初の名前でクエリ結果を並べ替えます。paginate()メソッドにpage URLパラメータの値を渡し、per_pageパラメータに値2を渡して1ページあたりのアイテムを2つに分割します。
最後に、構築したpaginationオブジェクトをレンダリングされたindex.htmlテンプレートに渡します。
ファイルを保存して閉じます。
次に、index.htmlテンプレートを編集してページネーションアイテムを表示します:
現在のページを示すh2見出しを追加し、forループをemployeesオブジェクトではなくpagination.itemsオブジェクトをループするように変更します。これはもはや利用できないオブジェクトです:
ファイルを保存して閉じます。
まだ行っていない場合は、FLASK_APPおよびFLASK_ENV環境変数を設定し、開発サーバーを実行します:
次に、page URLパラメータの異なる値でインデックスページに移動します:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
以前にFlaskシェルで見たように、それぞれに2つのアイテムが含まれ、異なるアイテムが含まれる異なるページが表示されます。
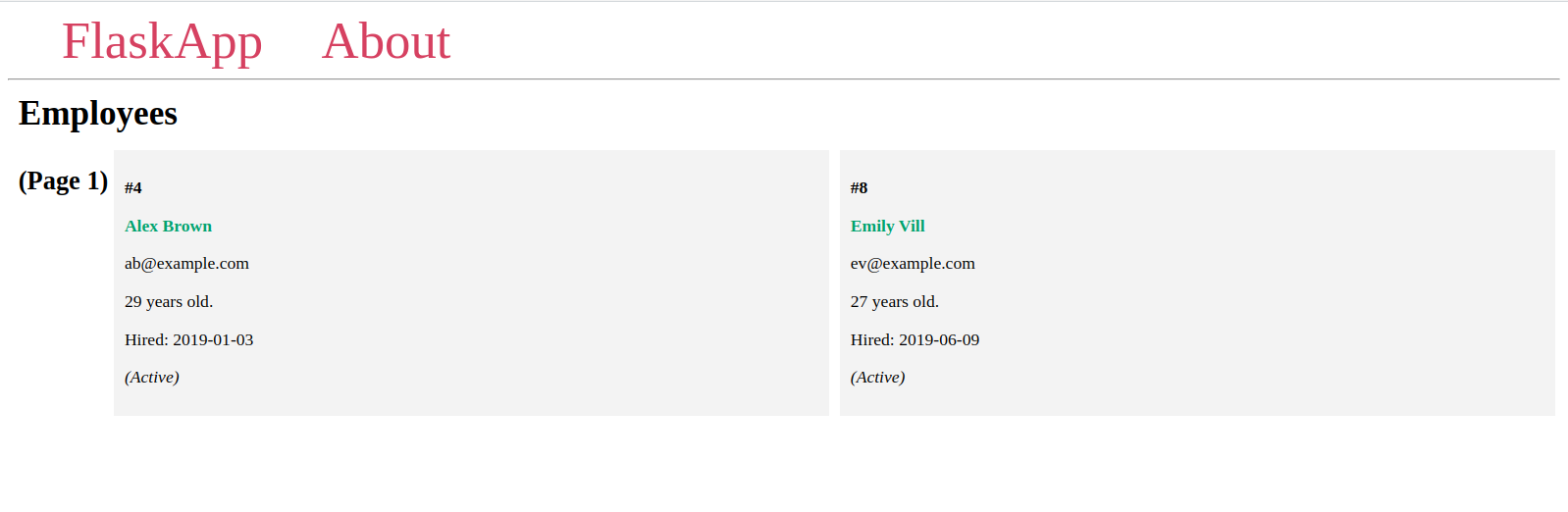
指定されたページ番号が存在しない場合、404 Not FoundのHTTPエラーが発生します。これは、前述のURLリストの最後のURLでのケースです。
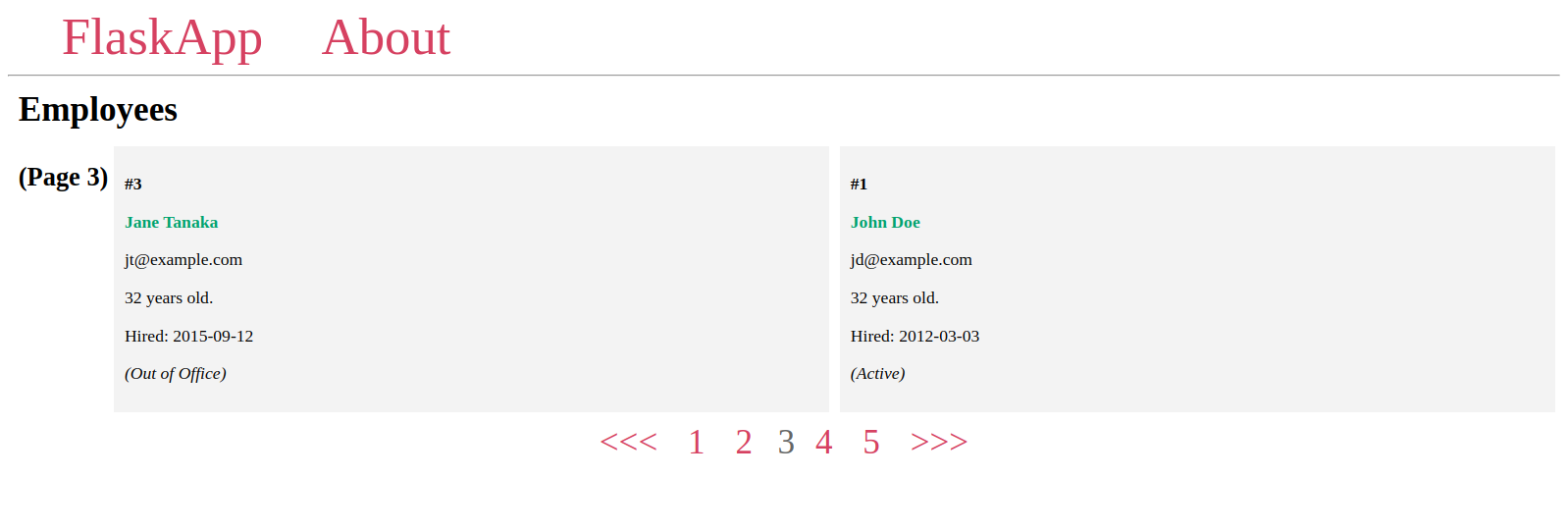
次に、ページネーションウィジェットを作成して、ページ間を移動します。ページネーションオブジェクトのいくつかの属性とメソッドを使用して、すべてのページ番号を表示し、各番号にはその専用ページへのリンクがあり、現在のページに前のページがある場合は <<< ボタンが表示され、次のページに移動する >>> ボタンが表示されます。
ページネーションウィジェットは次のようになります:

それを追加するには、index.html を開きます:
以下のハイライトされた div タグをコンテンツ div タグの下に追加してファイルを編集します:
ファイルを保存して閉じます。
ここでは、条件 if pagination.has_prev を使用して、現在のページが最初のページでない場合は前のページへの <<< リンクを追加します。前のページへのリンクは、url_for('index', page=pagination.prev_num) 関数呼び出しを使用して行われます。ここで、index ビュー関数にリンクし、pagination.prev_num の値を page URL パラメータに渡します。
利用可能なすべてのページ番号へのリンクを表示するには、pagination.iter_pages() メソッドのアイテムをループ処理します。これにより、各ループでページ番号が取得されます。
現在のページ番号が現在のループ番号と異なるかどうかを確認するために、if pagination.page != number 条件を使用します。 条件が true の場合、ユーザーが現在のページを別のページに変更できるように、ページへのリンクが表示されます。 それ以外の場合、現在のページがループ番号と同じ場合、リンクなしで番号が表示されます。 これにより、ユーザーはページネーションウィジェット内の現在のページ番号を知ることができます。
最後に、pagination.has_next 条件を使用して、現在のページに次のページがあるかどうかを確認し、次のページにリンクします。 この場合、url_for('index', page=pagination.next_num) コールと >>> リンクが使用されます。
ブラウザでインデックスページに移動してください:http://127.0.0.1:5000/
ページネーションウィジェットが完全に機能していることがわかります:
ここでは、次のページに移動するために >>>、前のページに移動するために <<< を使用していますが、他の任意の文字、例えば > と <、または <img> タグ内の画像を使用することもできます。
複数のページで従業員を表示し、Flask-SQLAlchemy でのページネーションの処理方法を学びました。 そして、今後は他の Flask アプリケーションでこのページネーションウィジェットを使用できます。
結論
Flask-SQLAlchemyを使用して従業員管理システムを作成しました。テーブルをクエリし、列の値と単純および複雑な論理条件に基づいて結果をフィルタリングしました。クエリの結果を並べ替え、カウントし、制限しました。そして、Webアプリケーション内で特定のレコード数を各ページに表示し、ページ間を移動するためのページネーションシステムを作成しました。
このチュートリアルで学んだことを、他のいくつかのFlask-SQLAlchemyチュートリアルで説明されている概念と組み合わせて、従業員管理システムにさらなる機能を追加するために使用できます:
- Flaskアプリケーションでデータベースとのやり取りにFlask-SQLAlchemyを使用する方法従業員の追加、編集、または削除方法を学ぶために。
- Flask-SQLAlchemyを使用した1対多のデータベース関係の使用方法各従業員を所属する部門にリンクするための1対多の関係を使用する方法を学ぶために。
- Flask-SQLAlchemyを使用した多対多のデータベース関係の使い方は、多対多の関係を使用して
tasksテーブルを作成し、それをemployeeテーブルにリンクする方法を学ぶためのものです。ここでは、各従業員が多くのタスクを持ち、各タスクが複数の従業員に割り当てられるようにします。
Flaskについて詳しく読みたい場合は、FlaskでWebアプリケーションを構築する方法シリーズの他のチュートリアルをチェックしてください。