













המחבר בחר ב־קרן הקוד הפתוח והחופשי לקבל תרומה כחלק מתוכנית כתיבה למען תרומות.
הקדמה
Flask הוא מסגרת פייתון קלה המספקת כלים ותכונות שימושיים ליצירת אפליקציות אינטרנט בשפת פייתון. SQLAlchemy הוא ערכת כלים SQL המספקת גישה יעילה וביצועית גבוהה למסדי נתונים רלציוניים. היא מספקת דרכים לפעול עם מסדי נתונים שונים כמו SQLite, MySQL ו־PostgreSQL. היא נותנת לך גישה לפונקציות ה־SQL של מסד הנתונים. והיא גם מספקת לך Mapper אובייקטים רלציוני (ORM), שמאפשר לך לבצע שאילתות ולטפל בנתונים באמצעות אובייקטים פייתוניים פשוטים ושיטות. Flask-SQLAlchemy היא הרחבה של Flask שהופכת את השימוש ב־SQLAlchemy עם Flask לקל יותר, ומספקת לך כלים ושיטות לפעול עם מסד הנתונים שלך ביישומי Flask שלך דרך SQLAlchemy.
במדריך זה, תשתמש ב־Flask ו־Flask-SQLAlchemy כדי ליצור מערכת ניהול עובדים עם מסד נתונים שיש בו טבלה עבור עובדים. כל עובד יכול להיות עם מזהה ייחודי, שם פרטי, שם משפחה, דוא"ל ייחודי, ערך שלם עבור גילם, תאריך ליום בו הם הצטרפו לחברה, וערך בוליאני כדי לקבוע האם עובד פעיל כרגע או מחוץ למשרה.
תשתמש ב־shell של Flask כדי לשאול את הטבלה, ולקבל רשומות טבלה בהתבסס על ערך בעמודה (לדוגמה, דוא"ל). תאחזר רשומות של עובדים על תנאים מסוימים, כמו לקבל רק עובדים פעילים או לקבל רשימה של עובדים שמחוץ למשרה. תסדר את התוצאות לפי ערך בעמודה, ותספור ותגביל את תוצאות השאילתה. לבסוף, תשתמש בפירוק לעמודים כדי להציג מספר מסוים של עובדים לכל עמוד ביישום אינטרנט.
דרישות מראש
-
סביבת פיתוח Python 3 מקומית. עקוב אחר המדריך של ההפצה שלך בסדרת איך להתקין ולהגדיר סביבת פיתוח מקומית עבור Python 3. במדריך זה נקרא לתיקיית הפרויקט שלנו
flask_app. -
הבנת מושגים בסיסיים של Flask, כמו נתיבים, פונקציות תצוגה ותבניות. אם אינך מוכר עם Flask, ניתן לבדוק את כיצד ליצור אפליקציית אינטרנט ראשונה שלך באמצעות Flask ו-Python וכיצד להשתמש בתבניות באפליקציית Flask.
-
הבנת מושגים בסיסיים של HTML. ניתן לעיין בסדרת התרגולים שלנו כיצד לבנות אתר אינטרנט עם HTML לידע מקדים.
-
הבנת מושגים בסיסיים של Flask-SQLAlchemy, כמו התקנת מסד נתונים, יצירת מודלי מסד נתונים, והכנסת נתונים למסד הנתונים. ראה איך להשתמש ב-Flask-SQLAlchemy לפעולות עם מסדי נתונים ביישום Flask לידע מקדים.
שלב 1 — הגדרת המסד נתונים והמודל
בשלב זה, תתקין את החבילות הנדרשות, ותגדיר את יישום ה-Flask שלך, את מסד הנתונים Flask-SQLAlchemy, ואת המודל של העובדים שמייצג את טבלת ה-employee שבה תאחסן את נתוני העובדים שלך. תכניס מספר עובדים לטבלת ה-employee, ותוסיף נתיב ודף בו יוצגו כל העובדים בעמוד הבית של היישום שלך.
ראשית, עם הסביבה הווירטואלית שלך פעילה, התקן את Flask ואת Flask-SQLAlchemy:
לאחר ההתקנה הושלמה, תקבל פלט עם השורה הבאה בסופו:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
עם החבילות הנדרשות מותקנות, פתח קובץ חדש בשם app.py בתיקיית ה-flask_app שלך. בקובץ זה תהיה קוד להגדרת מסד הנתונים והנתיבים של Flask שלך:
הוסף את הקוד הבא ל-app.py. קוד זה יקים מסד נתונים SQLite ומודל מסד נתונים של עובדים המייצג את טבלת employee שתשתמש לאחסון נתוני העובדים שלך:
שמור וסגור את הקובץ.
כאן, אתה מייבא את מודול os, שמעניק לך גישה לממשקי מערכת ההפעלה השונים. תשתמש בו כדי לבנות נתיב קובץ עבור קובץ מסד הנתונים שלך, database.db.
מחבילת flask, אתה מייבא עזרים שאתה צריך ליישום שלך: מחלקת Flask ליצירת מופע של Flask, render_template() לעיבוד תבניות, אובייקט request לטיפול בבקשות, url_for() לבניית כתובות URL, ופונקצית redirect() להפניית משתמשים. למידע נוסף על נתיבים ותבניות, ראה איך להשתמש בתבניות ביישום Flask.
לאחר מכן, אתה מייבא את המחלקה SQLAlchemy מהתוסף Flask-SQLAlchemy, שמעניקה לך גישה לכל הפונקציות והמחלקות מ-SQLAlchemy, בנוסף לעזרים ופונקציות שמשלבים את Flask עם SQLAlchemy. תשתמש בזה כדי ליצור אובייקט מסד נתונים שמתחבר ליישום Flask שלך.
כדי לבנות נתיב עבור קובץ מסד הנתונים שלך, אתה מגדיר ספריית בסיס כספריית הנוכחית. אתה משתמש בפונקציה os.path.abspath() כדי לקבל את הנתיב המוחלט של ספריית הקובץ הנוכחית. המשתנה המיוחד __file__ מחזיק את שם הנתיב של הקובץ הנוכחי app.py. אתה שומר את הנתיב המוחלט של ספריית הבסיס במשתנה בשם basedir.
אז אתה יוצר מופע של אפליקציית Flask בשם app, שאתה משתמש בו כדי להגדיר שני מפתחות תצורה של Flask-SQLAlchemy :
-
SQLALCHEMY_DATABASE_URI: URI של מסד הנתונים כדי לציין את מסד הנתונים שברצונך להתחבר אליו. במקרה זה, ה-URI עוקב אחר תבנית המקראיתsqlite:///נתיב/אל/מסד/הנתונים.db. אתה משתמש בפונקציהos.path.join()כדי לשרשר באופן חכם את ספריית הבסיס שבנית ושמרת במשתנהbasedirעם שם הקובץdatabase.db. זה יתחבר לקובץ מסד הנתוניםdatabase.dbבתיקיית ה-flask_appשלך. הקובץ ייווצר בעת שאתה מתחיל את מסד הנתונים. -
SQLALCHEMY_TRACK_MODIFICATIONS: הגדרה לאפשר או להשבית מעקב אחר שינויים של אובייקטים. אתה מגדיר אותה ל-Falseכדי להשבית את המעקב, שמשתמש בפחות זיכרון. למידע נוסף, ראה דף ההגדרות בתיעוד של Flask-SQLAlchemy.
לאחר הגדרת SQLAlchemy על ידי הגדרת URI למסד נתונים והשבתת המעקב, אתה יוצר אובייקט מסד נתונים באמצעות המחלקה SQLAlchemy, על ידי העברת אינסטנס היישום לחיבור יישומך Flask עם SQLAlchemy. אתה שומר את אובייקט מסד הנתונים שלך במשתנה בשם db, אשר תשתמש בו כדי להתקשר עם מסד הנתונים שלך.
אחרי התקנת המופע של היישום ואובייקט מסד הנתונים, אתה מוריש מהמחלקה db.Model כדי ליצור מודל מסד נתונים בשם Employee. מודל זה מייצג את טבלת העובדים, והוא מכיל את העמודות הבאות:
id: מזהה העובד, מספר שלם מפתח ראשי.firstname: שם הפרטי של העובד, מחרוזת בעלת אורך מרבי של 100 תווים.nullable=Falseמציין כי עמוד זה לא יכול להיות ריק.lastname: שם המשפחה של העובד, מחרוזת בעלת אורך מרבי של 100 תווים.nullable=Falseמציין כי עמוד זה לא יכול להיות ריק.email: האימייל של העובד, מחרוזת בעלת אורך מרבי של 100 תווים.unique=Trueמציין כי כל אימייל צריך להיות ייחודי.nullable=Falseמציין כי ערך זה לא יכול להיות ריק.age: גיל העובד, ערך שלם.hire_date: תאריך הגיוס של העובד. אתה מגדיר אתdb.Dateכסוג העמודה כדי להצהיר עליה כעמודה שמחזיקה תאריכים.active: עמודה שתחזיק ערך בוליאני כדי לציין האם העובד פעיל כרגע או שהוא מחוץ למשרה.
הפונקציה __repr__ המיוחדת מאפשרת לך להעניק לכל אובייקט מיוצג מחרוזת כדי לזהות אותו לצורכי איתור שגיאות. במקרה זה, אתה משתמש בשם הפרטי ושם המשפחה של העובד כדי לייצג כל אובייקט של עובד.
עכשיו שהגדרת את חיבור מסד הנתונים ואת מודל העובד, תכתוב תוכנית Python כדי ליצור את מסד הנתונים שלך ואת טבלת employee ולמלא את הטבלה עם נתוני עובדים.
פתח קובץ חדש בשם init_db.py בתיקיית flask_app שלך:
הוסף את הקוד הבא כדי למחוק טבלאות מסד נתונים קיימות כדי להתחיל מבסיס נתונים נקי, ליצור את טבלת employee ולהכניס תשעה עובדים אליה:
כאן, אתה מייבא את מחלקת date() ממודול datetime כדי להשתמש בה להגדרת תאריך התחילה של עובד.
אתה מייבא את אובייקט מסד הנתונים ואת מודל ה- Employee. אתה קורא לפונקציה db.drop_all() כדי למחוק את כל הטבלאות הקיימות כדי למנוע את הזדמנות של טבלת employee מוכנה קיימת במסד הנתונים, שעשויה לגרום לבעיות. פעולה זו מוחקת את כל נתוני מסד הנתונים בכל פעם שאתה מפעיל את התוכנית init_db.py. למידע נוסף על יצירת, שינוי ומחיקת טבלאות מסד נתונים, ראה איך להשתמש ב-Flask-SQLAlchemy לפעול עם מסדי נתונים באפליקציה Flask.
אז אתה יוצר מספר מופעים של המודל Employee, המייצגים את העובדים שתשאיר שאילתה עליהם במדריך זה, ומוסיף אותם לסשן מסד הנתונים באמצעות הפונקציה db.session.add_all(). לבסוף, אתה מאשר את העסקה ומחבר את השינויים למסד הנתונים באמצעות הפונקציה db.session.commit().
שמור וסגור את הקובץ.
בצע את התוכנית init_db.py:
כדי לצפות בנתונים שהוספת למסד הנתונים שלך, וודא שהסביבה הווירטואלית שלך מופעלת ופתח את פקודת ה-Flask כדי לשאול את כל העובדים ולהציג את הנתונים שלהם:
הרץ את הקוד הבא כדי לשאול את כל העובדים ולהציג את הנתונים שלהם:
אתה משתמש בשיטת all() של התכונה query כדי לקבל את כל העובדים. אתה עובר דרך התוצאות ומציג מידע על העובדים. לעמודה active, אתה משתמש בהצהרת תנאי כדי להציג את המצב הנוכחי של העובד, או 'פעיל' או 'מחוץ למשרה'.
תקבל את הפלט הבא:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
ניתן לראות שכל העובדים שהוספנו למסד הנתונים מוצגים כהלכה.
צא מפקודת ה-Flask:
לאחר מכן, תיצור נתיב Flask כדי להציג עובדים. פתח את app.py לעריכה:
הוסף את הנתיב הבא בסוף הקובץ:
שמור וסגור את הקובץ.
הוא משאיל את כל העובדים, מרנדר תבנית index.html, ומעביר אליה את העובדים שאתה מביא.
צור ספריית תבניות ו־תבנית בסיס:
הוסף את הקוד הבא ל־base.html:
שמור וסגור את הקובץ.
כאן, אתה משתמש בבלוק כותרת ומוסיף עיצוב CSS. אתה מוסיף נווט עם שני פריטים, אחד עבור דף הבית ואחד עבור דף אודות לא פעיל. נווט זה יוכל להיות בשימוש מחדש בכל היישומון בתבניות המורישות מהתבנית הבסיסית זו. הבלוק תוכן יוחלף עם תוכן כל דף. למידע נוסף על תבניות, ראה איך להשתמש בתבניות ביישומון Flask.
לאחר מכן, פתח תבנית חדשה בשם index.html שהפעלת ב־app.py:
הוסף את הקוד הבא לקובץ:
כאן, אתה מעביר על כל העובדים ומציג את מידע כל עובד. אם העובד פעיל אתה מוסיף תווית (פעיל), אחרת אתה מציג תווית (מחוץ למשרה).
שמור וסגור את הקובץ.
כאשר אתה נמצא בתיקיית ה-flask_app עם הסביבה הווירטואלית שלך פעילה, יש ליידע את Flask על היישום (app.py במקרה זה) באמצעות משתנה הסביבה FLASK_APP. לאחר מכן, יש להגדיר את משתנה הסביבה FLASK_ENV לערך development כדי להפעיל את היישום במצב פיתוח ולקבל גישה למפתח התקלות. למידע נוסף על מנפח השגיאות של Flask, ראה כיצד לטפל בשגיאות ביישום Flask. השתמש בפקודות הבאות כדי לבצע זאת:
לאחר מכן, הפעל את היישום:
כאשר השרת לפיתוח רץ, בקר בכתובת ה-URL הבאה בעזרת הדפדפן שלך:
http://127.0.0.1:5000/
תראה את העובדים שהוספת למסד הנתונים בדף דומה לדוגמא הבאה:
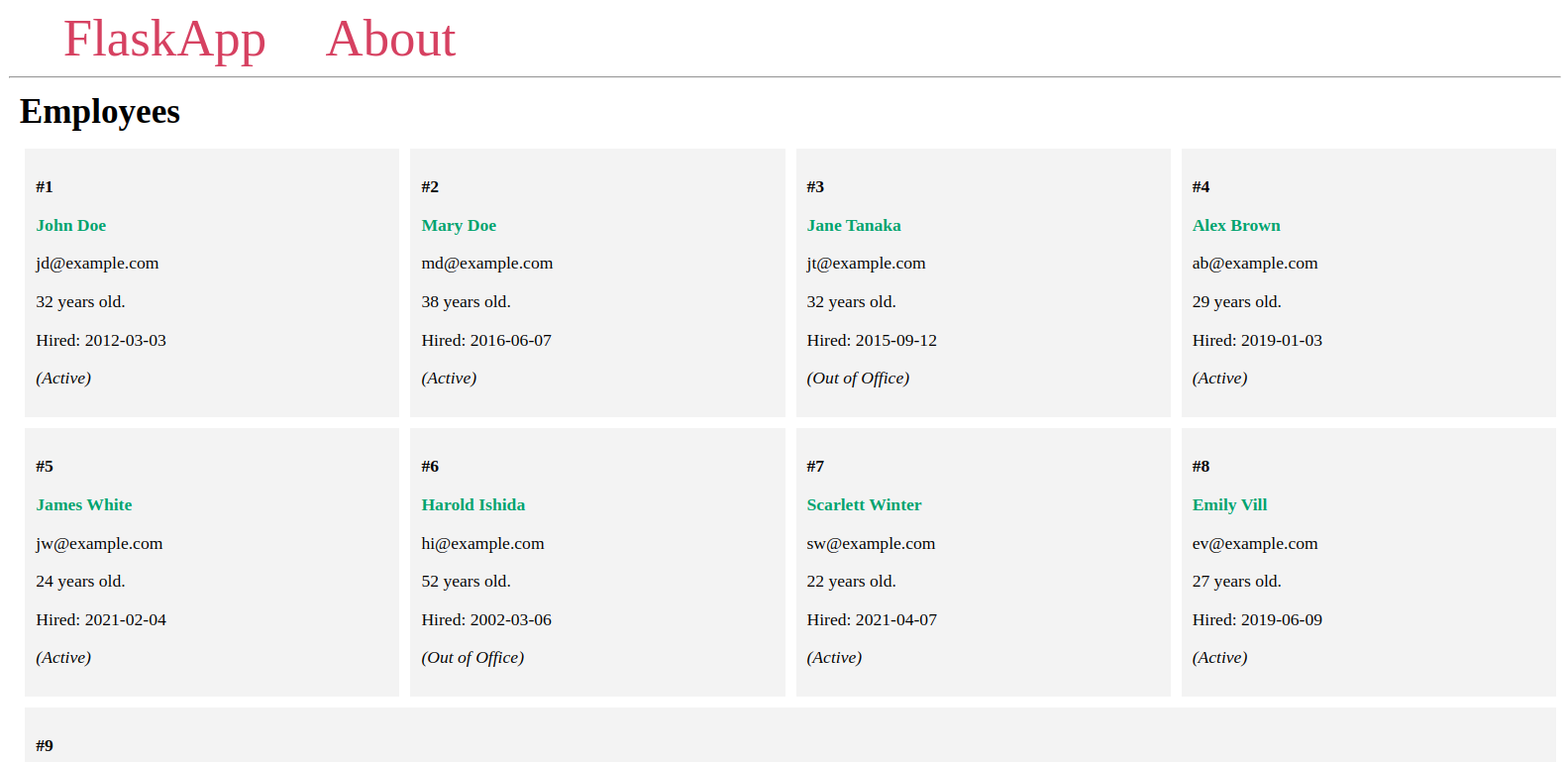
השאר את השרת פועל, פתח טרמינל נוסף, והמשך לשלב הבא.
הצגת את העובדים שיש לך במסד הנתונים בעמוד הראשי. לאחר מכן, תשתמש ב-Flask shell כדי לשאול עובדים באמצעות שיטות שונות.
שלב 2 — שאילתת רשומות
בשלב זה, תשתמש ב-Flask shell כדי לשאול רשומות, ותפלט ותאחזר תוצאות באמצעות שיטות ותנאים מרובים.
עם הסביבת התכנות שלך פעילה, הגדר את המשתנים FLASK_APP ו-FLASK_ENV, ופתח את ה-Flask shell:
ייבא את אובייקט ה-db ואת מודל ה-Employee:
איחזור רשומות כלליות
כפי שראית בשלב הקודם, ניתן להשתמש בשיטת all() על המאפיין query כדי לקבל את כל הרשומות בטבלה:
הפלט יהיה רשימת אובייקטים המייצגים את כל העובדים:
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
איחזור הרשומה הראשונה
באופן דומה, ניתן להשתמש בשיטת first() כדי לקבל את הרשומה הראשונה:
הפלט יהיה אובייקט שמחזיק את נתוני העובד הראשון:
Output<Employee John Doe>
איחזור רשומה על פי זיהוי
ברוב הטבלאות בבסיס הנתונים, רשומות מזוהות עם זיהוי ייחודי. Flask-SQLAlchemy מאפשרת לך לאחזר רשומה באמצעות הזיהוי שלה באמצעות שיטת get():
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
לאחזור רשומה או מספר רשומות על ידי ערך בעמודה
כדי לקבל רשומה באמצעות ערך אחד מהעמודות שלה, ניתן להשתמש בשיטת filter_by(). לדוגמה, כדי לקבל רשומה באמצעות ערך המזהה שלה, דומה לשיטת get():
Output<Employee John Doe>
אתה משתמש ב- first() מאחר ו- filter_by() עשוי להחזיר תוצאות מרובות.
הערה: לקבלת רשומה על פי מזהה, שימוש בשיטת get() הוא גישה יותר טובה.
לדוגמה נוספת, ניתן לקבל עובד על פי גילם:
Output<Employee Harold Ishida>
לדוגמה שבה תוצאת השאילתה מכילה יותר מרשומה אחת תואמת, ניתן להשתמש בעמודת firstname ובשם הפרטי Mary, שהוא שם משותף של שני עובדים:
Output[<Employee Mary Doe>, <Employee Mary Park>]
כאן, אתה משתמש ב- all() כדי לקבל את רשימת התוצאות המלאה. ניתן גם להשתמש ב- first() כדי לקבל רק את התוצאה הראשונה:
Output<Employee Mary Doe>
אתה קיבלת רשומות על ידי ערכי עמודות. הבאה היא לשאול את הטבלה שלך באמצעות תנאי לוגי.
שלב 3 — סינון רשומות באמצעות תנאים לוגיים
ביישומים מורכבים ומלאי תכונות ברשת, לעתים תצטרך לשאול רשומות ממסד הנתונים באמצעות תנאים מורכבים, כמו למשל לאחזר עובדים בהתבסס על שילוב של תנאים המתחשבים במיקומם, בזמינותם, בתפקידם ובאחריותם. בשלב זה, תקבל תרגול בשימוש באופרטורים תנאיים. תשתמש בשיטת filter() על המאפיין query כדי לסנן תוצאות שאילתה באמצעות תנאים לוגיים עם אופרטורים שונים. לדוגמה, תוכל להשתמש באופרטורים לוגיים כדי לאחזר רשימה של העובדים הנוכחיים החוץ מהמשרה, או עובדים הראויים לקידום, ואולי לספק לוח שנה של זמן חופשת העובדים, וכו'.
שווה
האופרטור הלוגי הפשוט ביותר שניתן להשתמש בו הוא אופרטור השוויון ==, אשר מתנהג בדרך דומה ל־filter_by(). לדוגמה, כדי לקבל את כל הרשומות שבהן ערך העמודה firstname הוא Mary, תוכל להשתמש בשיטת filter() כך:
כאן אתה משתמש בתחביר Model.column == value כארגומנט לשיטת filter(). שיטת filter_by() היא קיצור דרך לתחביר זה.
התוצאה תהיה זהה לתוצאת שיטת filter_by() עם אותו תנאי:
Output[<Employee Mary Doe>, <Employee Mary Park>]
כמו filter_by(), אתה יכול גם להשתמש בשיטת first() כדי לקבל את התוצאה הראשונה:
Output<Employee Mary Doe>
לא שווה
שיטת filter() מאפשרת לך להשתמש באופרטור Python של != כדי לקבל רשומות. לדוגמה, כדי לקבל רשימה של עובדים שאינם במשרה, ניתן להשתמש בשיטה הבאה:
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
כאן אתה משתמש בתנאי Employee.active != True כדי לסנן תוצאות.
פחות מ
ניתן להשתמש באופרטור < כדי לקבל רשומה בה ערך של עמודה נתונה קטן מהערך הנתון. לדוגמה, כדי לקבל רשימה של עובדים מתחת לגיל 32:
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
ניתן להשתמש באופרטור <= עבור רשומות שהן קטנות מאוו זה או שוות לערך הנתון. לדוגמה, כדי לכלול עובדים בגיל 32 בשאילתה הקודמת:
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
גדול מ
באופן דומה, אופרטור > מקבל רשומה בה ערך של עמודה נתונה גדול מהערך הנתון. לדוגמה, כדי לקבל עובדים מעל גיל 32:
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
והאופרטור >= הוא עבור רשומות שהן גדולות מהערך הנתון או שוות לו. לדוגמה, ניתן שוב לכלול עובדים בגיל 32 בשאילתה הקודמת:
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
ב
SQLAlchemy מספקת גם אפשרות לקבל רשומות שערכו של עמודה מתאים לערך מרשימת ערכים נתונה באמצעות השיטה in_() על העמודה בדיוק כמו בדוגמה הבאה:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
כאן, אתה משתמש בתנאי עם התחביר Model.column.in_(iterable), כאשר iterable הוא כל סוג של אובייקט שניתן לעבור עליו באמצעות לולאה. לדוגמה נוספת, ניתן להשתמש בפונקציית ה-Python range() כדי לקבל עובדים מטווח גילאים מסוים. השאילתה הבאה מביאה את כל העובדים שנמצאים בשלושים שלהם.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
לא ב
בדומה לשיטת in_(), ניתן להשתמש בשיטת not_in() כדי לקבל רשומות שערכו של עמודה אינו באובייקט הנתון:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
כאן, אתה מקבל את כל העובדים פרט לאלה ששם פרטי שלהם נמצא ברשימת names.
וגם
ניתן לחבר מספר תנאים ביחד באמצעות פונקציית db.and_(), שעובדת בדיוק כמו אופרטור ה-and ב-Python.
לדוגמה, נניח שתרצה לקבל את כל העובדים שבני 32 שנה ומ-פעילים כרגע. תחילה, תוכל לבדוק מי מבוגר/ת 32 באמצעות שיטת filter_by() (ניתן גם להשתמש ב- filter() אם תרצה):
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
כאן, אתה רואה שג'ון וג'יין הם העובדים שבני 32 שנה. ג'ון פעיל, וג'יין לא במשרה כרגע.
כדי לקבל את העובדים שבני 32 ופעילים, עליך להשתמש בשתי תנאים עם שיטת filter():
Employee.age == 32Employee.active == True
כדי לשלב את שני התנאים הללו, השתמש בפונקציה db.and_() כך:
Output[<Employee John Doe>]
כאן, אתה משתמש בתחביר filter(db.and_(תנאי1, תנאי2)).
בשימוש all() על השאילתה מחזיר רשימה של כל הרשומות שמתאימות לשני התנאים. תוכל להשתמש בשיטת first() כדי לקבל את התוצאה הראשונה:
Output<Employee John Doe>
לדוגמה מורכבת יותר, תוכל להשתמש ב- db.and_() עם הפונקציה date() כדי לקבל עובדים שהועסקו בטווח זמן ספציפי. בדוגמה זו, אתה מקבל את כל העובדים שהועסקו בשנת 2019:
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
כאן אתה מייבא את הפונקציה date(), ואתה מסנן תוצאות באמצעות הפונקציה db.and_() כדי לשלב את שני התנאים הבאים:
Employee.hire_date >= date(year=2019, month=1, day=1): זהוTrueעבור עובדים שהתקבלו בראשון לינואר 2019 או מאוחר יותר.Employee.hire_date < date(year=2020, month=1, day=1): זהוTrueעבור עובדים שנתקבלו לעבודה לפני ראשון בינואר 2020.
בשילוב שני התנאים מביא עובדים שנתקבלו מהראשון לינואר 2019 ועד לפני ראשון בינואר 2020.
או
דומה ל־db.and_(), פונקציית ה־db.or_() משלבת שני תנאים, והיא נהגת כמו האופרטור or בפייתון. היא מביאה את כל הרשומות שעונות על אחד משני התנאים. לדוגמה, כדי לקבל עובדים בגיל 32 או 52, ניתן לשלב שני תנאים בעזרת פונקציית db.or_() כך:
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
ניתן גם להשתמש בפעולות startswith() ו־endswith() על ערכי מחרוזת בתנאים שאנו מעבירים לשיטת filter(). לדוגמה, כדי לקבל את כל העובדים ששמם הפרטי מתחיל במחרוזת 'M' ואלו ששם המשפחה שלהם מסתיים במחרוזת 'e':
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
כאן אנו משלבים את שני התנאים הבאים:
Employee.firstname.startswith('M'): תואם עובדים ששמם הפרטי מתחיל ב־'M'.Employee.lastname.endswith('e'): תואם עובדים ששם המשפחה שלהם מסתיים ב־'e'.
עכשיו ניתן לסנן את תוצאות השאילתה בעזרת תנאים לוגיים ביישומי Flask-SQLAlchemy שלך. למשך, נסדר, נגביל ונספור את התוצאות שמתקבלות ממסד הנתונים.
שלב 4 — הזמנה, הגבלה וספירת תוצאות
ביישומי רשת, לעתים תצטרך להזמין את הרשומות שלך בעת הצגתן. לדוגמה, ייתכן ויהיה לך עמוד להצגת השכרות האחרונות בכל מחלקה כדי להודיע לשאר הצוות על השכרות חדשות, או שתסדר עובדים על ידי הצגת השכרות העתיקות ביותר תחילה כדי להכיר בעובדים המשמשים זמן רב. תצטרך גם להגביל את התוצאות שלך במקרים מסוימים, כגון הצגת השכרות השלוש האחרונות בסרגל צד. ותצטרך לפעמים לספור את תוצאות השאילתה, לדוגמה, כדי להציג את מספר העובדים הפעילים כעת. בשלב זה, תלמד איך לסדר, להגביל ולספור תוצאות.
סידור התוצאות
כדי לסדר תוצאות בהתאם לערכי עמודה ספציפית, יש להשתמש בשיטת order_by(). לדוגמה, כדי לסדר תוצאות לפי שם הפרטי של העובדים:
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
כפי שהפלט מראה, התוצאות מסודרות לפי אלפבית שם הפרטי של העובד.
אפשר לסדר גם לפי עמודות אחרות. לדוגמה, ניתן להשתמש בשם המשפחה כדי לסדר את העובדים:
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
ניתן גם לסדר את העובדים לפי תאריך ההשכרה שלהם:
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
כפי שהפלט מציג, תוצאות ההזמנה מסדרות מההשכרה המוקדמת ביותר להשכרה האחרונה. כדי להפוך את הסדר ולהפוך אותו לסדר יורד מהשכרה האחרונה להשכרה המוקדמת, יש להשתמש בשיטת desc() כך:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
ניתן גם לשלב את השיטה order_by() עם השיטה filter() כדי למיין תוצאות מסוננות. הדוגמה הבאה מקבלת את כל העובדים שהועסקו בשנת 2021 וממיינת אותם לפי גיל:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
כאן, נשתמש בפונקציית db.and_() עם שני תנאים: Employee.hire_date >= date(year=2021, month=1, day=1) עבור עובדים שהועסקו ביום הראשון של שנת 2021 או מאוחר יותר, ו-Employee.hire_date < date(year=2022, month=1, day=1) עבור עובדים שהועסקו לפני היום הראשון של שנת 2022. לאחר מכן משתמשים בשיטת order_by() כדי למיין את העובדים התוצאה לפי גילם.
מגביל תוצאות
ברוב המקרים בעולם האמיתי, כאשר עושים שאילתה לטבלת מסד נתונים, יתכן שנקבל עד מיליוני תוצאות תואמות, ולפעמים נדרש להגביל את התוצאות למספר מסוים. כדי להגביל תוצאות ב-Flask-SQLAlchemy, ניתן להשתמש בשיטת limit(). הדוגמה הבאה משאירה שאילתה את טבלת employee ומחזירה רק את שלושת התוצאות התואמות הראשונות:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
ניתן להשתמש ב-limit() עם שיטות אחרות, כגון filter ו-order_by. לדוגמה, ניתן לקבל את שני העובדים האחרונים שהועסקו בשנת 2021 באמצעות שימוש בשיטת limit() כך:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
כאן, אתה משתמש באותה שאילתה שבקטע הקודם עם קריאה לשיטת limit(2) נוספת.
ספירת תוצאות
כדי לספור את מספר התוצאות של שאילתה, ניתן להשתמש בשיטת count(). לדוגמה, כדי לקבל את מספר העובדים הנוכחיים במסד הנתונים:
Output9
ניתן לשלב את שיטת count() עם שיטות שאילתה אחרות דומות ל-limit(). לדוגמה, כדי לקבל את מספר העובדים שהועסקו בשנת 2021:
Output3
כאן אתה משתמש באותה שאילתה שהשתמשת בה קודם כדי לקבל את כל העובדים שהועסקו בשנת 2021. ואתה משתמש ב-count() כדי לקבל את מספר הערכים, שהוא 3.
סידרת, הגבלת וספרת תוצאות שאילתה ב-Flask-SQLAlchemy. למעשה, השלב הבא הוא ללמוד איך לפצל את תוצאות השאילתה לעמודים מרובים ואיך ליצור מערכת פיגומים ביישומי Flask שלך.
שלב 5 — הצגת רשימות רשומות ארוכות בעמודים מרובים
בשלב זה, תיערך את המסלול הראשי כך שהעמוד הראשי יציג עובדים על מספר עמודים כדי להקל על הניווט ברשימת העובדים.
ראשית, תשתמשו ב-Flask shell כדי לראות הדגמה של כיצד להשתמש בתכונת הפגינציה ב-Flask-SQLAlchemy. פתחו את Flask shell אם עדיין לא עשיתם זאת:
נניח שתרצו לחלק את רשומות העובדים בטבלה שלכם לעמודים מרובים, עם שני פריטים בכל עמוד. תוכלו לעשות זאת באמצעות שימוש בשיטת שאילתה paginate() כך:
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
תשתמשו בפרמטר page של שיטת השאילתה paginate() כדי לציין את העמוד שברצונכם לגשת אליו, שהוא העמוד הראשון במקרה זה. הפרמטר per_page מציין את מספר הפריטים שכל עמוד חייב להכיל. במקרה זה אתם מגדירים אותו ל-2 כדי להפוך כל עמוד לכלול שני פריטים.
המשתנה page1 כאן הוא אובייקט פגינציה, אשר מעניק לכם גישה למאפיינים ולשיטות שתשתמשו בהם כדי לנהל את הפגינציה שלכם.
אתם יכולים לגשת לפריטים של העמוד באמצעות המאפיין items.
כדי לגשת לעמוד הבא, תוכלו להשתמש בשיטת next() של אובייקט הפגינציה כך, התוצאה שתחזור היא גם אובייקט פגינציה:
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
אתם יכולים לקבל אובייקט פגינציה עבור העמוד הקודם באמצעות שימוש בשיטת prev(). בדוגמה הבאה אתם גוששים את אובייקט הפגינציה עבור העמוד הרביעי, ואז אתם נגשים לאובייקט הפגינציה של העמוד הקודם שלו, שהוא עמוד 3:
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
תוכלו לגשת למספר העמוד הנוכחי באמצעות המאפיין page כך:
Output1
2
כדי לקבל את מספר העמודים הכולל, יש להשתמש במאפיין pages של אובייקט הפגינציה. בדוגמה הבאה, כן page1.pages וכן page2.pages מחזירים את אותה הערך מאחר ומספר העמודים הכולל הוא קבוע:
Output5
5
לקבלת מספר הפריטים הכולל, יש להשתמש במאפיין total של אובייקט הפגינציה:
Output9
9
כאן, מאחר ואתה פונה לכל העובדים, מספר הפריטים הכולל בפגינציה הוא 9, מכיוון שיש תשעה עובדים במסד הנתונים.
הנה כמה מהמאפיינים האחרים של אובייקטי הפגינציה:
prev_num: מספר העמוד הקודם.next_num: מספר העמוד הבא.has_next:Trueאם יש עמוד הבא.has_prev:Trueאם יש עמוד קודם.per_page: מספר הפריטים לכל עמוד.
לאובייקט הפגינציה יש גם את השיטה iter_pages() שבאפשרותך לעבור דרך כדי לגשת למספרי עמודים. לדוגמה, באפשרותך להדפיס את כל מספרי העמודים כך:
Output1
2
3
4
5
הנה הדגמה כיצד לגשת לכל העמודים ולפריטים שלהם באמצעות אובייקט פגינציה ושיטת iter_pages():
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
כאן, אתה יוצר אובייקט פגינציה שמתחיל מהעמוד הראשון. אתה עובר דרך העמודים באמצעות לולאת for עם שיטת הפגינציה iter_pages(). אתה מדפיס את מספר העמוד ואת הפריטים שבו, ואתה מגדיר את אובייקט הפגינציה שלו לאובייקט הבא שלו באמצעות השיטה next().
אתה יכול גם להשתמש ב־filter() וב־order_by() יחד עם השיטה paginate() כדי לחלק לעמודים תוצאות שאורכו מסוננות וממוינות. לדוגמה, תוכל לקבל עובדים מעל גיל שלושים ולמיין את התוצאות לפי גיל ולחלק את התוצאות לעמודים באופן הבא:
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
עכשיו שיש לך הבנה טובה של איך פילוספיית העמודים עובדת ב־Flask-SQLAlchemy, תערוך את דף האינדקס של האפליקציה שלך כך שיציג עובדים על מספר עמודים כדי להקל על ניווט.
צא מה־Flask shell:
כדי לגשת לעמודים שונים, תשתמש ב־פרמטרי URL, שגם מכונים מחרוזות שאילתה ב־URL, שהם דרך להעביר מידע לאפליקציה דרך ה־URL. הפרמטרים מועברים לאפליקציה ב־URL לאחר סמל ?. לדוגמה, כדי להעביר פרמטר page עם ערכים שונים, ניתן להשתמש ב־URLים הבאים:
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
כאן, ה־URL הראשון מעביר ערך 1 לפרמטר ה־URL page. ה־URL השני מעביר ערך 3 לאותו פרמטר.
פתח את קובץ ה־app.py:
ערוך את הנתיב של האינדקס להיראות כך:
כאן, אתה מקבל את ערך פרמטר ה־URL page באמצעות אובייקט ה־request.args ואת השיטה שלו get(). לדוגמה, /?page=1 תקבל את הערך 1 מפרמטר ה־URL page. אתה מעביר 1 כערך ברירת המחדל, ואתה מעביר את סוג ה־Python int כארגומנט לפרמטר ה־type כדי לוודא שהערך הוא מספר שלם.
אחרי כן, תיצור אובייקט pagination, ממיין את תוצאות השאילתה לפי שם הפרטי. אתה מעביר את ערך פרמטר ה-URL page לשיטת paginate(), ואתה פוצל את התוצאות לשני פריטים לעמוד על ידי מעבר ערך 2 לפרמטר per_page.
לבסוף, אתה מעביר את אובייקט ה-pagination שבנית לתבנית ה-index.html שהוצגה.
שמור וסגור את הקובץ.
באשף הקובץ index.html על מנת להציג פריטי פגינציה:
שנה את התכנית של התגית div על ידי הוספת כותרת h2 שמציינת את הדף הנוכחי, ושינוי הלולאה for כך שתעבור על אובייקט הפריטים pagination.items במקום על האובייקט employees, שאינו זמין יותר:
שמור וסגור את הקובץ.
אם עדיין לא עשית זאת, הגדר את משתני הסביבה FLASK_APP וְ-FLASK_ENV והרץ את שרת הפיתוח:
כעת, נווט לדף האינדקס עם ערכים שונים עבור פרמטר ה-URL page:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
תראה דפים שונים עם שני פריטים בכל אחד, ופריטים שונים בכל דף, כמו שראית קודם באשף ה-Flask.
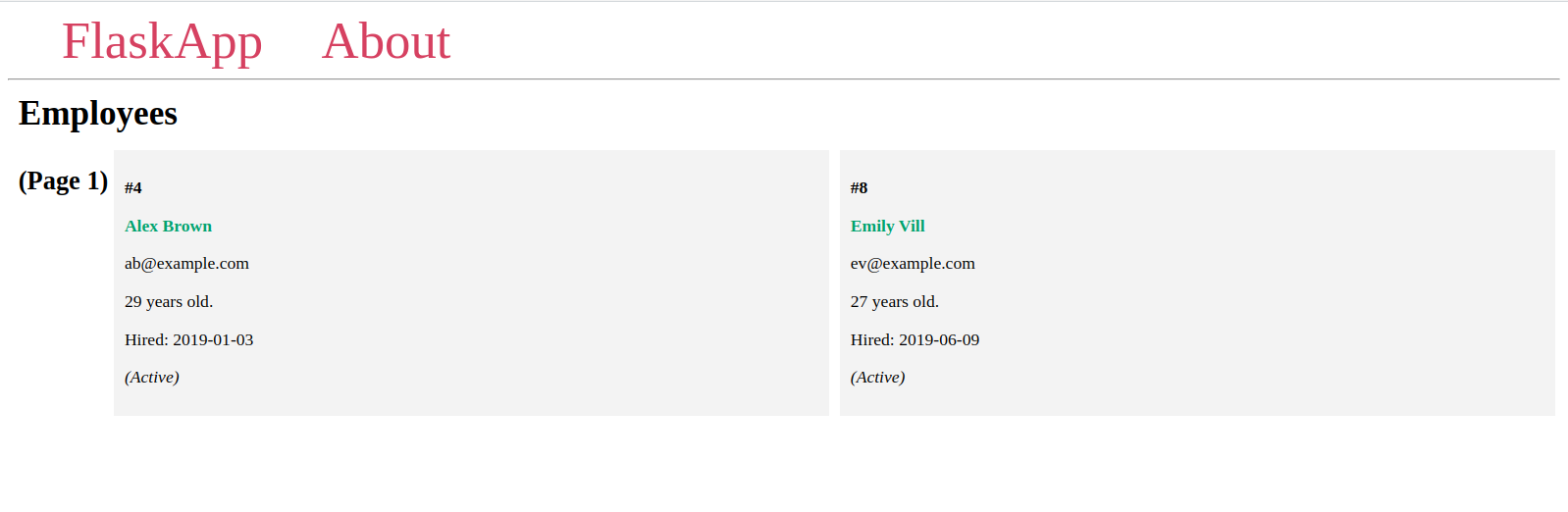
אם מספר הדף הנתון אינו קיים, תקבל שגיאת HTTP 404 Not Found, כפי שקרה עם ה-URL האחרון ברשימת ה-URL הקודמת.
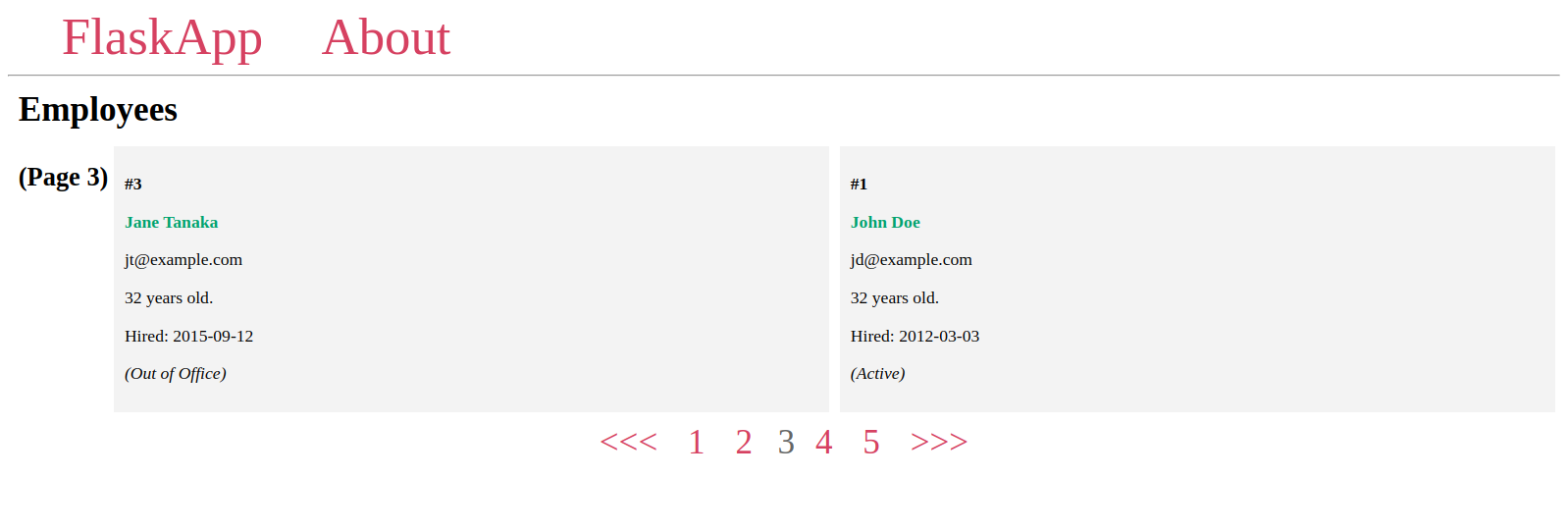
הבא, תיצור וידג'ט פיגונציה כדי לנווט בין העמודים, תשתמש במספר מאפיינים ושיטות של אובייקט הפיגונציה כדי להציג את כל מספרי העמודים, כאשר כל מספר מחבר לדף המיועד שלו, ולחצן <<< כדי לחזור אם העמוד הנוכחי יש לו עמוד קודם, ולחצן >>> כדי לעבור לעמוד הבא אם קיים.
הווידג'ט פיגונציה יראה כך:

כדי להוסיף אותו, פתח את index.html:
ערוך את הקובץ והוסף את התגית div המודגשת הבאה מתחת לתגית התוכן div:
שמור וסגור את הקובץ.
כאן, אתה משתמש בתנאי if pagination.has_prev כדי להוסיף קישור <<< לעמוד הקודם אם העמוד הנוכחי אינו העמוד הראשון. אתה מקשר לעמוד הקודם באמצעות קריאת הפונקציה url_for('index', page=pagination.prev_num), שבה אתה מקשר לפונקציית התצוגה של האינדקס, עובר את הערך pagination.prev_num לפרמטר URL page.
כדי להציג קישורים לכל מספרי העמודים הזמינים, אתה מעבור דרך פריטי pagination.iter_pages() שמחזיר לך מספר עמוד בכל לולאה.
אתה משתמש בתנאי if pagination.page != number כדי לראות אם מספר הדף הנוכחי אינו זהה עם המספר בלולאה הנוכחית. אם התנאי נכון, אתה מקשר אל הדף כדי לאפשר למשתמש לשנות את הדף הנוכחי לדף אחר. במקרה שבו הדף הנוכחי זהה למספר הלולאה, אתה מציג את המספר ללא קישור. זה מאפשר למשתמשים לדעת את מספר הדף הנוכחי בווידג'ט התיקול.
לבסוף, אתה משתמש בתנאי pagination.has_next כדי לראות האם יש לדף הנוכחי דף הבא, במקרה כזה אתה מקשר אליו באמצעות הקריאה url_for('index', page=pagination.next_num) וקישור >>>.
נווט לדף האינדקס בדפדפן שלך: http://127.0.0.1:5000/
תראה שהווידג'ט של התיקול פועל באופן מלא:
כאן, אתה משתמש ב־>>> כדי לעבור לדף הבא ו־<<< עבור הדף הקודם, אך אתה יכול גם להשתמש בתווים אחרים לדוגמה > ו־< או תמונות בתגי <img>.
הצגת אישיות בדפים מרובים ולמידה איך להתמודד עם תיקול ב־Flask-SQLAlchemy. וכעת אתה יכול להשתמש בווידג'ט התיקול שלך ביישומי Flask אחרים שאתה בונה.
סיכום
השתמשת ב-Flask-SQLAlchemy כדי ליצור מערכת לניהול עובדים. עשית שאילתות לטבלה וסיננת תוצאות בהתבסס על ערכי עמודות ותנאים לוגיים פשוטים ומורכבים. סידרת, ספרת, והגבלת את תוצאות השאילתה. ויצרת מערכת פגינציה כדי להציג מספר מסוים של רשומות בכל עמוד באפליקציית האינטרנט שלך, ולנווט בין העמודים.
באפשרותך להשתמש במה שלמדת במדריך זה בשילוב עם המושגים המסופקים בכמה מהמדריכים האחרים שלנו על Flask-SQLAlchemy כדי להוסיף יותר פונקציונליות למערכת ניהול העובדים שלך:
- כיצד להשתמש ב-Flask-SQLAlchemy כדי להתמודד עם מסדי נתונים ביישום Flask כדי ללמוד כיצד להוסיף, לערוך, או למחוק עובדים.
- כיצד להשתמש ביחסי מסד נתונים חד-לרבים עם Flask-SQLAlchemy כדי ללמוד כיצד להשתמש ביחסי אחד-לרבים כדי ליצור טבלת מחלקה כדי לקשר כל עובד למחלקה שהוא שייך אליה.
- איך להשתמש ביחסי מסד נתונים רבים לרבים עם Flask-SQLAlchemy כדי ללמוד איך להשתמש ביחסי רבים לרבים כדי ליצור טבלת
tasksולקשר אותה לטבלתemployee, כאשר לכל עובד יש הרבה משימות וכל משימה משויכת למספר עובדים.
אם ברצונך לקרוא עוד על Flask, בדוק את המדריכים האחרים בסדרת איך לבנות אפליקציות אינטרנט עם Flask.