













L’auteur a sélectionné le Fonds pour le Logiciel Libre et Open Source pour recevoir un don dans le cadre du programme Écrire pour les Dons.
Introduction
Flask est un framework web léger en Python qui fournit des outils et des fonctionnalités utiles pour créer des applications web en langage Python. SQLAlchemy est une trousse à outils SQL qui offre un accès efficace et performant aux bases de données relationnelles. Il propose des moyens d’interagir avec plusieurs moteurs de base de données tels que SQLite, MySQL et PostgreSQL. Il vous donne accès aux fonctionnalités SQL de la base de données. Et il vous fournit également un Mappage Objet Relationnel (ORM), qui vous permet d’effectuer des requêtes et de manipuler des données à l’aide d’objets et de méthodes Python simples. Flask-SQLAlchemy est une extension Flask qui facilite l’utilisation de SQLAlchemy avec Flask, en vous fournissant des outils et des méthodes pour interagir avec votre base de données dans vos applications Flask via SQLAlchemy.
Dans ce tutoriel, vous utiliserez Flask et Flask-SQLAlchemy pour créer un système de gestion des employés avec une base de données comprenant une table pour les employés. Chaque employé aura un identifiant unique, un prénom, un nom, un e-mail unique, une valeur entière pour leur âge, une date pour le jour où ils ont rejoint l’entreprise, et une valeur booléenne pour déterminer si un employé est actuellement actif ou absent du bureau.
Vous utiliserez la coquille Flask pour interroger une table et obtenir des enregistrements de table en fonction d’une valeur de colonne (par exemple, un e-mail). Vous récupérerez les enregistrements des employés selon certaines conditions, telles que l’obtention uniquement des employés actifs ou l’obtention d’une liste d’employés hors bureau. Vous ordonnerez les résultats par une valeur de colonne, compterez et limiterez les résultats de la requête. Enfin, vous utiliserez la pagination pour afficher un certain nombre d’employés par page dans une application web.
Prérequis
-
Un environnement de programmation Python 3 local. Suivez le tutoriel pour votre distribution dans la série Comment installer et configurer un environnement de programmation local pour Python 3. Dans ce tutoriel, nous appellerons notre répertoire de projet
flask_app. -
Une compréhension des concepts de base de Flask, tels que les routes, les fonctions de vue et les modèles. Si vous n’êtes pas familier avec Flask, consultez Comment créer votre première application Web à l’aide de Flask et Python et Comment utiliser les modèles dans une application Flask.
-
Une compréhension des concepts de base de HTML. Vous pouvez consulter notre série de tutoriels Comment construire un site Web avec HTML pour des connaissances préalables.
-
Une compréhension des concepts de base de Flask-SQLAlchemy, tels que la configuration d’une base de données, la création de modèles de base de données et l’insertion de données dans la base de données. Voir Comment utiliser Flask-SQLAlchemy pour interagir avec les bases de données dans une application Flask pour des connaissances préalables.
Étape 1 — Configuration de la base de données et du modèle
Dans cette étape, vous installerez les packages nécessaires et configurerez votre application Flask, la base de données Flask-SQLAlchemy et le modèle d’employé qui représente la table employee où vous stockerez vos données d’employé. Vous insérerez quelques employés dans la table employee, et ajouterez une route et une page où tous les employés sont affichés sur la page d’accueil de votre application.
Tout d’abord, avec votre environnement virtuel activé, installez Flask et Flask-SQLAlchemy:
Une fois l’installation terminée, vous recevrez une sortie avec la ligne suivante à la fin:
Output
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
Avec les packages requis installés, ouvrez un nouveau fichier appelé app.py dans votre répertoire flask_app. Ce fichier aura du code pour configurer la base de données et vos routes Flask:
Ajoutez le code suivant à app.py. Ce code configurera une base de données SQLite et un modèle de base de données d’employés représentant la table employee que vous utiliserez pour stocker vos données d’employés:
Enregistrez et fermez le fichier.
Ici, vous importez le module os, qui vous donne accès aux interfaces du système d’exploitation. Vous l’utiliserez pour construire un chemin de fichier pour votre base de données database.db.
À partir du package flask, vous importez les assistants dont vous avez besoin pour votre application : la classe Flask pour créer une instance d’application Flask, render_template() pour rendre les modèles, l’objet request pour gérer les requêtes, url_for() pour construire des URL et la fonction redirect() pour rediriger les utilisateurs. Pour plus d’informations sur les routes et les modèles, consultez Comment Utiliser les Modèles dans une Application Flask.
Ensuite, vous importez la classe SQLAlchemy de l’extension Flask-SQLAlchemy, qui vous donne accès à toutes les fonctions et classes de SQLAlchemy, en plus des assistants et fonctionnalités qui intègrent Flask avec SQLAlchemy. Vous l’utiliserez pour créer un objet de base de données qui se connecte à votre application Flask.
Pour construire un chemin vers votre fichier de base de données, vous définissez un répertoire de base comme étant le répertoire courant. Vous utilisez la fonction os.path.abspath() pour obtenir le chemin absolu du répertoire du fichier actuel. La variable spéciale __file__ contient le chemin d’accès du fichier app.py actuel. Vous stockez le chemin absolu du répertoire de base dans une variable appelée basedir.
Ensuite, vous créez une instance d’application Flask appelée app, que vous utilisez pour configurer deux clés de configuration Flask-SQLAlchemy :
-
SQLALCHEMY_DATABASE_URI: L’URI de la base de données pour spécifier la base de données avec laquelle vous souhaitez établir une connexion. Dans ce cas, l’URI suit le formatsqlite:///chemin/vers/database.db. Vous utilisez la fonctionos.path.join()pour joindre intelligemment le répertoire de base que vous avez construit et stocké dans la variablebasediravec le nom de fichierdatabase.db. Cela se connectera à un fichier de base de donnéesdatabase.dbdans votre répertoireflask_app. Le fichier sera créé une fois que vous aurez initié la base de données. -
SQLALCHEMY_TRACK_MODIFICATIONS: Une configuration pour activer ou désactiver le suivi des modifications d’objets. Vous le définissez surFalsepour désactiver le suivi, ce qui utilise moins de mémoire. Pour en savoir plus, consultez la page de configuration dans la documentation de Flask-SQLAlchemy.
Après avoir configuré SQLAlchemy en définissant une URI de base de données et en désactivant le suivi, vous créez un objet de base de données en utilisant la classe SQLAlchemy, en passant l’instance de l’application pour connecter votre application Flask avec SQLAlchemy. Vous stockez votre objet de base de données dans une variable appelée db, que vous utiliserez pour interagir avec votre base de données.
Après avoir configuré l’instance de l’application et l’objet de la base de données, vous héritez de la classe db.Model pour créer un modèle de base de données appelé Employee. Ce modèle représente la table employee, et il a les colonnes suivantes :
id: L’identifiant de l’employé, une clé primaire entière.firstname: Le prénom de l’employé, une chaîne de caractères d’une longueur maximale de 100 caractères.nullable=Falsesignifie que cette colonne ne doit pas être vide.lastname: Le nom de famille de l’employé, une chaîne de caractères d’une longueur maximale de 100 caractères.nullable=Falsesignifie que cette colonne ne doit pas être vide.email: L’e-mail de l’employé, une chaîne de caractères d’une longueur maximale de 100 caractères.unique=Truesignifie que chaque e-mail doit être unique.nullable=Falsesignifie que sa valeur ne doit pas être vide.age: L’âge de l’employé, une valeur entière.hire_date: La date à laquelle l’employé a été embauché. Vous définissezdb.Datecomme type de colonne pour la déclarer comme une colonne qui contient des dates.active: Une colonne qui contiendra une valeur booléenne pour indiquer si l’employé est actuellement actif ou hors du bureau.
La fonction spéciale __repr__ vous permet de donner à chaque objet une représentation sous forme de chaîne pour le reconnaître à des fins de débogage. Dans ce cas, vous utilisez le prénom et le nom de famille de l’employé pour représenter chaque objet employé.
Maintenant que vous avez établi la connexion à la base de données et le modèle d’employé, vous allez écrire un programme Python pour créer votre base de données et la table employee et peupler la table avec des données d’employés.
Ouvrez un nouveau fichier appelé init_db.py dans votre répertoire flask_app:
Ajoutez le code suivant pour supprimer les tables de base de données existantes afin de démarrer avec une base de données propre, créer la table employee et y insérer neuf employés :
Ici, vous importez la classe date() du module datetime pour l’utiliser afin de définir les dates d’embauche des employés.
Vous importez l’objet de la base de données et le modèle Employee. Vous appelez la fonction db.drop_all() pour supprimer toutes les tables existantes afin d’éviter que la table employee déjà peuplée n’existe dans la base de données, ce qui pourrait causer des problèmes. Cela supprime toutes les données de la base de données chaque fois que vous exécutez le programme init_db.py. Pour plus d’informations sur la création, la modification et la suppression des tables de base de données, consultez Comment utiliser Flask-SQLAlchemy pour interagir avec les bases de données dans une application Flask.
Ensuite, vous créez plusieurs instances du modèle Employee, qui représentent les employés que vous interrogerez dans ce tutoriel, et les ajoutez à la session de la base de données en utilisant la fonction db.session.add_all(). Enfin, vous validez la transaction et appliquez les modifications à la base de données en utilisant la fonction db.session.commit().
Enregistrez et fermez le fichier.
Exécutez le programme init_db.py:
Pour consulter les données que vous avez ajoutées à votre base de données, assurez-vous que votre environnement virtuel est activé et ouvrez l’interpréteur Flask pour interroger tous les employés et afficher leurs données:
Exécutez le code suivant pour interroger tous les employés et afficher leurs données:
Vous utilisez la méthode all() de l’attribut query pour obtenir tous les employés. Vous parcourez les résultats et affichez les informations sur les employés. Pour la colonne active, vous utilisez une instruction conditionnelle pour afficher le statut actuel de l’employé, soit 'Actif' soit 'Hors bureau'.
Vous recevrez la sortie suivante:
OutputJohn Doe
Email: [email protected]
Age: 32
Hired: 2012-03-03
Active
----
Mary Doe
Email: [email protected]
Age: 38
Hired: 2016-06-07
Active
----
Jane Tanaka
Email: [email protected]
Age: 32
Hired: 2015-09-12
Out of Office
----
Alex Brown
Email: [email protected]
Age: 29
Hired: 2019-01-03
Active
----
James White
Email: [email protected]
Age: 24
Hired: 2021-02-04
Active
----
Harold Ishida
Email: [email protected]
Age: 52
Hired: 2002-03-06
Out of Office
----
Scarlett Winter
Email: [email protected]
Age: 22
Hired: 2021-04-07
Active
----
Emily Vill
Email: [email protected]
Age: 27
Hired: 2019-06-09
Active
----
Mary Park
Email: [email protected]
Age: 30
Hired: 2021-08-11
Active
----
Vous pouvez voir que tous les employés que nous avons ajoutés à la base de données sont correctement affichés.
Quittez l’interpréteur Flask:
Ensuite, vous créerez une route Flask pour afficher les employés. Ouvrez app.py pour l’éditer:
Ajoutez la route suivante à la fin du fichier:
Enregistrez et fermez le fichier.
Cela interroge tous les employés, rend un modèle index.html et lui passe les employés que vous avez récupérés.
Créez un répertoire de modèles et un modèle de base :
Ajoutez ce qui suit à base.html :
Enregistrez et fermez le fichier.
Ici, vous utilisez un bloc de titre et ajoutez un peu de style CSS. Vous ajoutez une barre de navigation avec deux éléments, un pour la page d’index et un pour une page À propos inactive. Cette barre de navigation sera réutilisée dans l’ensemble de l’application dans les modèles qui héritent de ce modèle de base. Le bloc de contenu sera remplacé par le contenu de chaque page. Pour en savoir plus sur les modèles, consultez Comment Utiliser les Modèles dans une Application Flask.
Ensuite, ouvrez un nouveau modèle index.html que vous avez rendu dans app.py :
Ajoutez le code suivant au fichier :
Ici, vous parcourez les employés et affichez les informations de chaque employé. Si l’employé est actif, vous ajoutez une étiquette (Actif), sinon vous affichez une étiquette (Hors Bureau).
Enregistrez et fermez le fichier.
Une fois dans votre répertoire flask_app avec votre environnement virtuel activé, indiquez à Flask l’application (app.py dans ce cas) en utilisant la variable d’environnement FLASK_APP. Ensuite, définissez la variable d’environnement FLASK_ENV sur development pour exécuter l’application en mode développement et accéder au débogueur. Pour plus d’informations sur le débogueur Flask, consultez Comment gérer les erreurs dans une application Flask. Utilisez les commandes suivantes pour cela :
Ensuite, exécutez l’application :
Avec le serveur de développement en cours d’exécution, visitez l’URL suivante à l’aide de votre navigateur :
http://127.0.0.1:5000/
Vous verrez les employés que vous avez ajoutés à la base de données sur une page similaire à celle-ci :
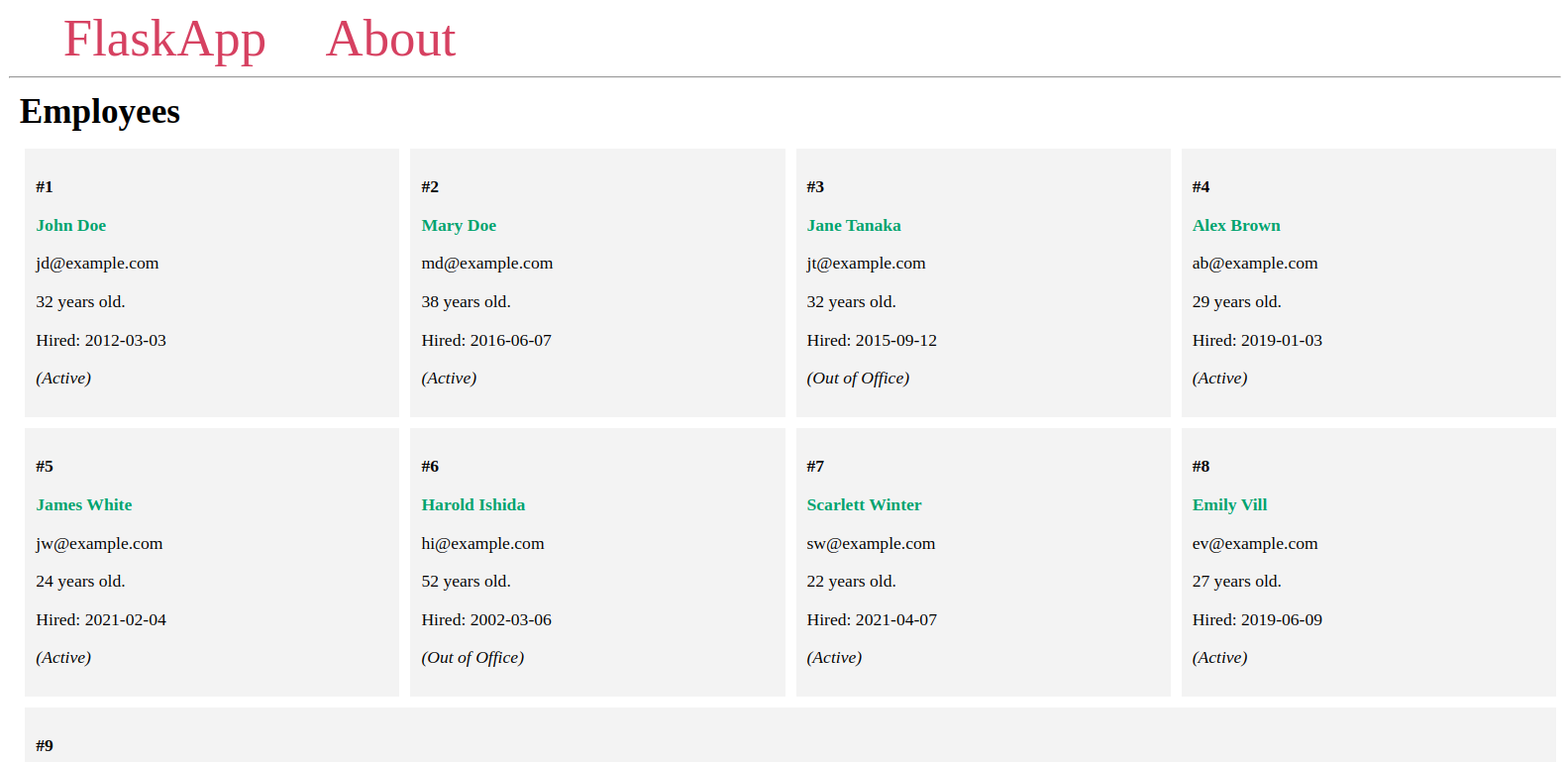
Laissez le serveur en cours d’exécution, ouvrez un autre terminal et passez à l’étape suivante.
Vous avez affiché les employés que vous avez dans votre base de données sur la page d’index. Ensuite, vous utiliserez l’interpréteur de commandes Flask pour interroger les employés en utilisant différentes méthodes.
Étape 2 — Interrogation des enregistrements
Dans cette étape, vous utiliserez l’interpréteur de commandes Flask pour interroger les enregistrements, filtrer et récupérer des résultats en utilisant plusieurs méthodes et conditions.
Avec votre environnement de programmation activé, définissez les variables FLASK_APP et FLASK_ENV, et ouvrez l’interpréteur de commandes Flask :
Importer l’objet db et le modèle Employee :
Récupération de tous les enregistrements
Comme vous l’avez vu dans l’étape précédente, vous pouvez utiliser la méthode all() sur l’attribut query pour obtenir tous les enregistrements dans une table :
La sortie sera une liste d’objets représentant tous les employés :
Output
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
Récupération du premier enregistrement
De même, vous pouvez utiliser la méthode first() pour obtenir le premier enregistrement :
La sortie sera un objet contenant les données du premier employé :
Output<Employee John Doe>
Récupération d’un enregistrement par ID
Dans la plupart des tables de bases de données, les enregistrements sont identifiés par un ID unique. Flask-SQLAlchemy vous permet de récupérer un enregistrement en utilisant son ID avec la méthode get() :
Output<Employee James White> | ID: 5
<Employee Jane Tanaka> | ID: 3
Récupération d’un enregistrement ou de plusieurs enregistrements par une valeur de colonne
Pour obtenir un enregistrement en utilisant la valeur d’une de ses colonnes, utilisez la méthode filter_by(). Par exemple, pour obtenir un enregistrement en utilisant sa valeur d’ID, similaire à la méthode get():
Output<Employee John Doe>
Vous utilisez first() parce que filter_by() peut renvoyer plusieurs résultats.
Remarque : Pour obtenir un enregistrement par ID, utiliser la méthode get() est une meilleure approche.
Pour un autre exemple, vous pouvez obtenir un employé en utilisant son âge :
Output<Employee Harold Ishida>
Pour un exemple où le résultat de la requête contient plus d’un enregistrement correspondant, utilisez la colonne firstname et le prénom Mary, qui est un nom partagé par deux employés :
Output[<Employee Mary Doe>, <Employee Mary Park>]
Ici, vous utilisez all() pour obtenir la liste complète. Vous pouvez également utiliser first() pour obtenir uniquement le premier résultat :
Output<Employee Mary Doe>
Vous avez récupéré des enregistrements via des valeurs de colonnes. Ensuite, vous interrogerez votre table en utilisant des conditions logiques.
Étape 3 — Filtrer les enregistrements en utilisant des conditions logiques
Dans les applications web complexes et complètes, vous avez souvent besoin d’interroger les enregistrements de la base de données en utilisant des conditionnels compliqués, tels que la récupération des employés en fonction d’une combinaison de conditions qui tiennent compte de leur emplacement, de leur disponibilité, de leur rôle et de leurs responsabilités. Dans cette étape, vous allez vous exercer à utiliser des opérateurs conditionnels. Vous utiliserez la méthode filter() sur l’attribut query pour filtrer les résultats de la requête en utilisant des conditions logiques avec différents opérateurs. Par exemple, vous pouvez utiliser des opérateurs logiques pour récupérer une liste des employés actuellement absents, ou des employés en attente de promotion, et peut-être fournir un calendrier des congés des employés, etc.
Égalité
L’opérateur logique le plus simple que vous pouvez utiliser est l’opérateur d’égalité ==, qui se comporte de manière similaire à filter_by(). Par exemple, pour obtenir tous les enregistrements où la valeur de la colonne firstname est Mary, vous pouvez utiliser la méthode filter() comme ceci :
Ici, vous utilisez la syntaxe Modèle.colonne == valeur comme argument de la méthode filter(). La méthode filter_by() est un raccourci pour cette syntaxe.
Le résultat est le même que celui de la méthode filter_by() avec la même condition :
Output[<Employee Mary Doe>, <Employee Mary Park>]
Tout comme filter_by(), vous pouvez également utiliser la méthode first() pour obtenir le premier résultat :
Output<Employee Mary Doe>
Différent de
La méthode filter() vous permet d’utiliser l’opérateur Python != pour obtenir des enregistrements. Par exemple, pour obtenir une liste d’employés hors du bureau, vous pouvez utiliser l’approche suivante :
Output[<Employee Jane Tanaka>, <Employee Harold Ishida>]
Ici, vous utilisez la condition Employee.actif != True pour filtrer les résultats.
Inférieur à
Vous pouvez utiliser l’opérateur < pour obtenir un enregistrement où la valeur d’une colonne donnée est inférieure à la valeur donnée. Par exemple, pour obtenir une liste d’employés de moins de 32 ans :
Output
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Utilisez l’opérateur <= pour les enregistrements qui sont inférieurs ou égaux à la valeur donnée. Par exemple, pour inclure les employés âgés de 32 ans dans la requête précédente :
Output
John Doe
Age: 32
----
Jane Tanaka
Age: 32
----
Alex Brown
Age: 29
----
James White
Age: 24
----
Scarlett Winter
Age: 22
----
Emily Vill
Age: 27
----
Mary Park
Age: 30
----
Supérieur à
De même, l’opérateur > obtient un enregistrement où la valeur d’une colonne donnée est supérieure à la valeur donnée. Par exemple, pour obtenir des employés de plus de 32 ans :
OutputMary Doe
Age: 38
----
Harold Ishida
Age: 52
----
Et l’opérateur >= est pour les enregistrements qui sont supérieurs ou égaux à la valeur donnée. Par exemple, vous pouvez à nouveau inclure les employés de 32 ans dans la requête précédente :
Output
John Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Harold Ishida
Age: 52
----
Dans
SQLAlchemy fournit également un moyen d’obtenir des enregistrements où la valeur d’une colonne correspond à une valeur d’une liste donnée de valeurs en utilisant la méthode in_() sur la colonne comme ceci:
Output[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
Ici, vous utilisez une condition avec la syntaxe Modèle.colonne.in_(itérable), où itérable est n’importe quel type d’objet que vous pouvez parcourir. Par exemple, vous pouvez utiliser la fonction Python range() pour obtenir des employés dans une certaine tranche d’âge. La requête suivante récupère tous les employés qui sont dans la trentaine.
OutputJohn Doe
Age: 32
----
Mary Doe
Age: 38
----
Jane Tanaka
Age: 32
----
Mary Park
Age: 30
----
Pas dans
Similaire à la méthode in_(), vous pouvez utiliser la méthode not_in() pour obtenir des enregistrements où une valeur de colonne n’est pas dans un itérable donné:
Output
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
Ici, vous obtenez tous les employés sauf ceux dont le prénom est dans la liste noms.
Et
Vous pouvez joindre plusieurs conditions ensemble en utilisant la fonction db.and_(), qui fonctionne comme l’opérateur and de Python.
Par exemple, supposons que vous vouliez obtenir tous les employés qui ont 32 ans et sont actuellement actifs. Tout d’abord, vous pouvez vérifier qui a 32 ans en utilisant la méthode filter_by() (vous pouvez également utiliser filter() si vous le souhaitez) :
Output<Employee John Doe>
Age: 32
Active: True
-----
<Employee Jane Tanaka>
Age: 32
Active: False
-----
Ici, vous voyez que John et Jane sont les employés qui ont 32 ans. John est actif et Jane est hors du bureau.
Pour obtenir les employés qui ont 32 ans et sont actifs, vous utiliserez deux conditions avec la méthode filter() :
Employee.age == 32Employee.active == True
Pour joindre ces deux conditions ensemble, utilisez la fonction db.and_() comme ceci :
Output[<Employee John Doe>]
Ici, vous utilisez la syntaxe filter(db.and_(condition1, condition2)).
En utilisant all() sur la requête, vous obtenez une liste de tous les enregistrements qui correspondent aux deux conditions. Vous pouvez utiliser la méthode first() pour obtenir le premier résultat :
Output<Employee John Doe>
Pour un exemple plus complexe, vous pouvez utiliser db.and_() avec la fonction date() pour obtenir les employés qui ont été embauchés dans une période de temps spécifique. Dans cet exemple, vous obtenez tous les employés embauchés en 2019 :
Output<Employee Alex Brown> | Hired: 2019-01-03
<Employee Emily Vill> | Hired: 2019-06-09
Ici, vous importez la fonction date(), et vous filtrez les résultats en utilisant la fonction db.and_() pour combiner les deux conditions suivantes :
Employee.hire_date >= date(year=2019, month=1, day=1): C’estTruepour les employés embauchés le premier janvier 2019 ou plus tard.Employee.hire_date < date(year=2020, month=1, day=1): Ceci estVraipour les employés embauchés avant le premier janvier 2020.
En combinant les deux conditions, on récupère les employés embauchés à partir du premier jour de 2019 et avant le premier jour de 2020.
Ou
Similaire à db.and_(), la fonction db.or_() combine deux conditions, et elle se comporte comme l’opérateur or en Python. Elle récupère tous les enregistrements qui répondent à l’une des deux conditions. Par exemple, pour obtenir des employés âgés de 32 ou 52 ans, vous pouvez combiner deux conditions avec la fonction db.or_() comme suit :
Output<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
<Employee Harold Ishida> | Age: 52
Vous pouvez également utiliser les méthodes startswith() et endswith() sur les valeurs de chaîne de caractères dans les conditions que vous passez à la méthode filter(). Par exemple, pour obtenir tous les employés dont le prénom commence par la chaîne de caractères 'M' et ceux dont le nom de famille se termine par la chaîne de caractères 'e' :
Output<Employee John Doe>
<Employee Mary Doe>
<Employee James White>
<Employee Mary Park>
Ici, vous combinez les deux conditions suivantes :
Employee.firstname.startswith('M'): Correspond aux employés dont le prénom commence par'M'.Employee.lastname.endswith('e'): Correspond aux employés dont le nom de famille se termine par'e'.
Vous pouvez désormais filtrer les résultats de la requête en utilisant des conditions logiques dans vos applications Flask-SQLAlchemy. Ensuite, vous trierez, limiterez et compterez les résultats que vous obtiendrez de la base de données.
Étape 4 — Commande, Limitation et Comptage des Résultats
Dans les applications web, vous devez souvent ordonner vos enregistrements lors de leur affichage. Par exemple, vous pourriez avoir une page pour afficher les dernières embauches dans chaque département afin d’informer le reste de l’équipe des nouvelles embauches, ou vous pouvez ordonner les employés en affichant d’abord les embauches les plus anciennes pour reconnaître les employés ayant une longue ancienneté. Vous devrez également limiter vos résultats dans certains cas, comme afficher uniquement les trois dernières embauches sur une petite barre latérale. Et vous avez souvent besoin de compter les résultats d’une requête, par exemple, pour afficher le nombre d’employés actuellement actifs. Dans cette étape, vous apprendrez comment ordonner, limiter et compter les résultats.
Commande des Résultats
Pour ordonner les résultats en utilisant les valeurs d’une colonne spécifique, utilisez la méthode order_by(). Par exemple, pour ordonner les résultats par le prénom des employés :
Output[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
Comme le montre la sortie, les résultats sont ordonnés alphabétiquement par le prénom de l’employé.
Vous pouvez aussi ordonner par d’autres colonnes. Par exemple, vous pouvez utiliser le nom de famille pour ordonner les employés :
Output[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
Vous pouvez également ordonner les employés par leur date d’embauche :
Output
Harold Ishida 2002-03-06
John Doe 2012-03-03
Jane Tanaka 2015-09-12
Mary Doe 2016-06-07
Alex Brown 2019-01-03
Emily Vill 2019-06-09
James White 2021-02-04
Scarlett Winter 2021-04-07
Mary Park 2021-08-11
Comme le montre la sortie, cela classe les résultats de l’embauche la plus ancienne à la plus récente. Pour inverser l’ordre et le rendre descendant de la plus récente à la plus ancienne, utilisez la méthode desc() comme ceci:
OutputMary Park 2021-08-11
Scarlett Winter 2021-04-07
James White 2021-02-04
Emily Vill 2019-06-09
Alex Brown 2019-01-03
Mary Doe 2016-06-07
Jane Tanaka 2015-09-12
John Doe 2012-03-03
Harold Ishida 2002-03-06
Vous pouvez également combiner la méthode order_by() avec la méthode filter() pour ordonner les résultats filtrés. L’exemple suivant récupère tous les employés embauchés en 2021 et les ordonne par âge:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Mary Park 2021-08-11 | Age 30
Ici, vous utilisez la fonction db.and_() avec deux conditions: Employee.hire_date >= date(year=2021, month=1, day=1) pour les employés embauchés le premier jour de 2021 ou après, et Employee.hire_date < date(year=2022, month=1, day=1) pour les employés embauchés avant le premier jour de 2022. Ensuite, vous utilisez la méthode order_by() pour ordonner les employés résultants par leur âge.
Limitation des résultats
Dans la plupart des cas réels, lors de la requête d’une table de base de données, vous pouvez obtenir jusqu’à des millions de résultats correspondants, et il est parfois nécessaire de limiter les résultats à un certain nombre. Pour limiter les résultats dans Flask-SQLAlchemy, vous pouvez utiliser la méthode limit(). L’exemple suivant interroge la table employee et ne renvoie que les trois premiers résultats correspondants:
Output[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
Vous pouvez utiliser limit() avec d’autres méthodes, telles que filter et order_by. Par exemple, vous pouvez obtenir les deux derniers employés embauchés en 2021 en utilisant la méthode limit() comme ceci:
OutputScarlett Winter 2021-04-07 | Age 22
James White 2021-02-04 | Age 24
Voici, vous utilisez la même requête que dans la section précédente avec un appel de méthode supplémentaire limit(2).
Comptage des Résultats
Pour compter le nombre de résultats d’une requête, vous pouvez utiliser la méthode count(). Par exemple, pour obtenir le nombre d’employés actuellement dans la base de données :
Output9
Vous pouvez combiner la méthode count() avec d’autres méthodes de requête similaires à limit(). Par exemple, pour obtenir le nombre d’employés embauchés en 2021 :
Output3
Ici, vous utilisez la même requête que précédemment pour obtenir tous les employés embauchés en 2021. Et vous utilisez la méthode count() pour récupérer le nombre d’entrées, qui est de 3.
Vous avez ordonné, limité et compté les résultats de requête dans Flask-SQLAlchemy. Ensuite, vous apprendrez à diviser les résultats de requête en plusieurs pages et à créer un système de pagination dans vos applications Flask.
Étape 5 — Affichage de Listes de Résultats Longs sur Plusieurs Pages
Dans cette étape, vous modifierez la route principale pour que la page d’index affiche les employés sur plusieurs pages afin de faciliter la navigation dans la liste des employés.
Tout d’abord, vous utiliserez la coquille Flask pour voir une démonstration de comment utiliser la fonction de pagination dans Flask-SQLAlchemy. Ouvrez la coquille Flask si ce n’est pas déjà fait :
Supposons que vous vouliez diviser les enregistrements des employés dans votre table en plusieurs pages, avec deux éléments par page. Vous pouvez le faire en utilisant la méthode de requête paginate() comme ceci :
Output<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
[<Employee John Doe>, <Employee Mary Doe>]
Vous utilisez le paramètre page de la méthode de requête paginate() pour spécifier la page que vous voulez accéder, qui est la première page dans ce cas. Le paramètre per_page spécifie le nombre d’éléments que chaque page doit avoir. Dans ce cas, vous le définissez sur 2 pour que chaque page ait deux éléments.
La variable page1 ici est un objet de pagination, qui vous donne accès aux attributs et méthodes que vous utiliserez pour gérer votre pagination.
Vous accédez aux éléments de la page en utilisant l’attribut items.
Pour accéder à la page suivante, vous pouvez utiliser la méthode next() de l’objet de pagination comme ceci, le résultat retourné est également un objet de pagination :
Output[<Employee Jane Tanaka>, <Employee Alex Brown>]
<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
Vous pouvez obtenir un objet de pagination pour la page précédente en utilisant la méthode prev(). Dans l’exemple suivant, vous accédez à l’objet de pagination pour la quatrième page, puis vous accédez à l’objet de pagination de sa page précédente, qui est la page 3 :
Output[<Employee Scarlett Winter>, <Employee Emily Vill>]
[<Employee James White>, <Employee Harold Ishida>]
Vous pouvez accéder au numéro de page actuelle en utilisant l’attribut page comme ceci :
Output1
2
Pour obtenir le nombre total de pages, utilisez l’attribut pages de l’objet pagination. Dans l’exemple suivant, à la fois page1.pages et page2.pages retournent la même valeur car le nombre total de pages est constant :
Output5
5
Pour le nombre total d’éléments, utilisez l’attribut total de l’objet pagination :
Output9
9
Ici, puisque vous interrogez tous les employés, le nombre total d’éléments dans la pagination est de 9, car il y a neuf employés dans la base de données.
Voici quelques-uns des autres attributs des objets pagination :
prev_num: Le numéro de page précédent.next_num: Le numéro de page suivant.has_next:Vrais’il y a une page suivante.has_prev:Vrais’il y a une page précédente.per_page: Le nombre d’éléments par page.
L’objet pagination a également une méthode iter_pages() que vous pouvez parcourir pour accéder aux numéros de page. Par exemple, vous pouvez imprimer tous les numéros de page de la manière suivante :
Output1
2
3
4
5
Ce qui suit est une démonstration de comment accéder à toutes les pages et à leurs éléments en utilisant un objet pagination et la méthode iter_pages() :
Output
PAGE 1
-
[<Employee John Doe>, <Employee Mary Doe>]
--------------------
PAGE 2
-
[<Employee Jane Tanaka>, <Employee Alex Brown>]
--------------------
PAGE 3
-
[<Employee James White>, <Employee Harold Ishida>]
--------------------
PAGE 4
-
[<Employee Scarlett Winter>, <Employee Emily Vill>]
--------------------
PAGE 5
-
[<Employee Mary Park>]
--------------------
Ici, vous créez un objet pagination qui commence à partir de la première page. Vous parcourez les pages en utilisant une boucle for avec la méthode de pagination iter_pages(). Vous imprimez le numéro de page et les éléments de la page, et vous définissez l’objet pagination sur l’objet pagination de sa page suivante en utilisant la méthode next().
Vous pouvez également utiliser les méthodes filter() et order_by() avec la méthode paginate() pour paginer les résultats de requête filtrés et ordonnés. Par exemple, vous pouvez obtenir les employés de plus de trente ans, ordonner les résultats par âge et paginer les résultats comme ceci :
OutputPAGE 1
-
<Employee John Doe> | Age: 32
<Employee Jane Tanaka> | Age: 32
--------------------
PAGE 2
-
<Employee Mary Doe> | Age: 38
<Employee Harold Ishida> | Age: 52
--------------------
Maintenant que vous avez une bonne compréhension de comment la pagination fonctionne dans Flask-SQLAlchemy, vous allez éditer la page d’index de votre application pour afficher les employés sur plusieurs pages pour une navigation plus facile.
Quitter le shell Flask :
Pour accéder à différentes pages, vous utiliserez des paramètres d’URL, également connus sous le nom de chaînes de requête d’URL, qui sont une manière de transmettre des informations à l’application à travers l’URL. Les paramètres sont transmis à l’application dans l’URL après un symbole ?. Par exemple, pour transmettre un paramètre page avec différentes valeurs, vous pouvez utiliser les URLs suivantes :
http://127.0.0.1:5000/?page=1
http://127.0.0.1:5000/?page=3
Ici, le premier URL transmet une valeur 1 au paramètre d’URL page. Le deuxième URL transmet une valeur 3 au même paramètre.
Ouvrez le fichier app.py :
Modifiez la route de l’index comme suit :
Ici, vous obtenez la valeur du paramètre d’URL page en utilisant l’objet request.args et sa méthode get(). Par exemple /?page=1 obtiendra la valeur 1 du paramètre d’URL page. Vous passez 1 comme valeur par défaut, et vous passez le type Python int comme argument au paramètre type pour vous assurer que la valeur est un entier.
Ensuite, vous créez un objet pagination, en ordonnant les résultats de la requête par le prénom. Vous passez la valeur du paramètre d’URL page à la méthode paginate(), et vous divisez les résultats en deux éléments par page en passant la valeur 2 au paramètre per_page.
Enfin, vous passez l’objet pagination que vous avez construit au modèle index.html rendu.
Enregistrez et fermez le fichier.
Ensuite, modifiez le modèle index.html pour afficher les éléments de pagination :
Modifiez la balise div de contenu en ajoutant un titre h2 qui indique la page actuelle, et modifiez la boucle for pour parcourir l’objet pagination.items au lieu de l’objet employees, qui n’est plus disponible:
Enregistrez et fermez le fichier.
Si ce n’est pas déjà fait, définissez les variables d’environnement FLASK_APP et FLASK_ENV et lancez le serveur de développement :
Maintenant, accédez à la page d’index avec différentes valeurs pour le paramètre d’URL page:
http://127.0.0.1:5000/
http://127.0.0.1:5000/?page=2
http://127.0.0.1:5000/?page=4
http://127.0.0.1:5000/?page=19
Vous verrez différentes pages avec deux éléments chacune, et différents éléments sur chaque page, comme vous l’avez déjà vu dans l’interpréteur Flask.
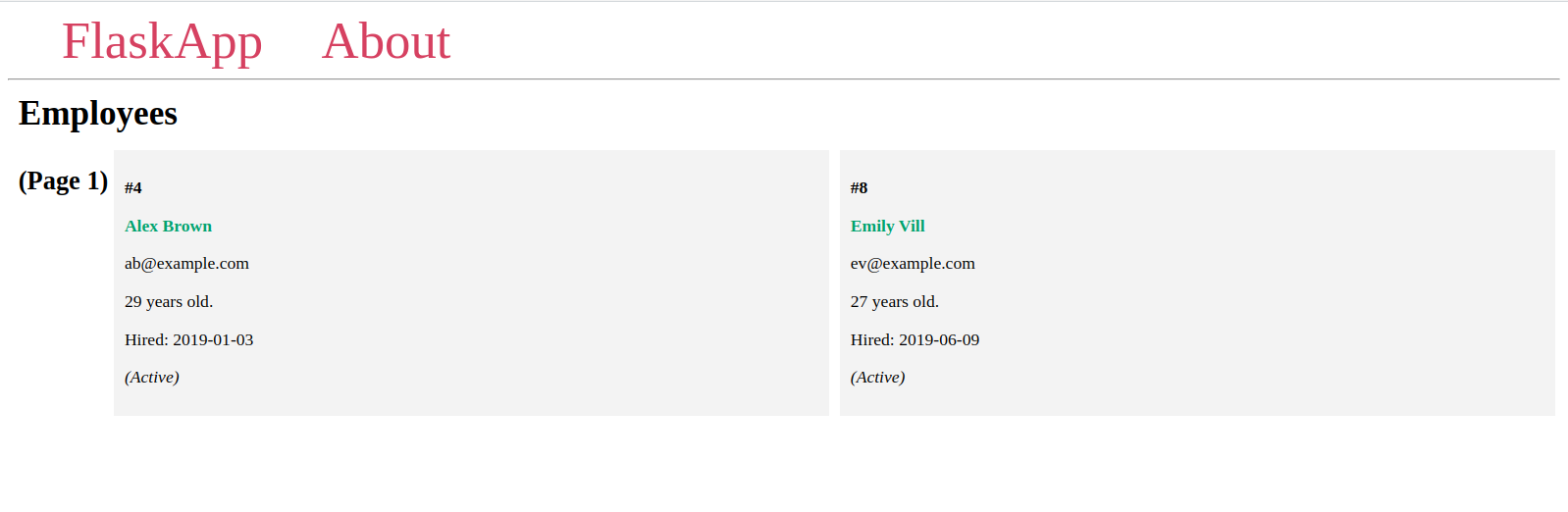
Si le numéro de page donné n’existe pas, vous obtiendrez une erreur HTTP 404 Not Found, ce qui est le cas avec la dernière URL dans la liste d’URL précédente.
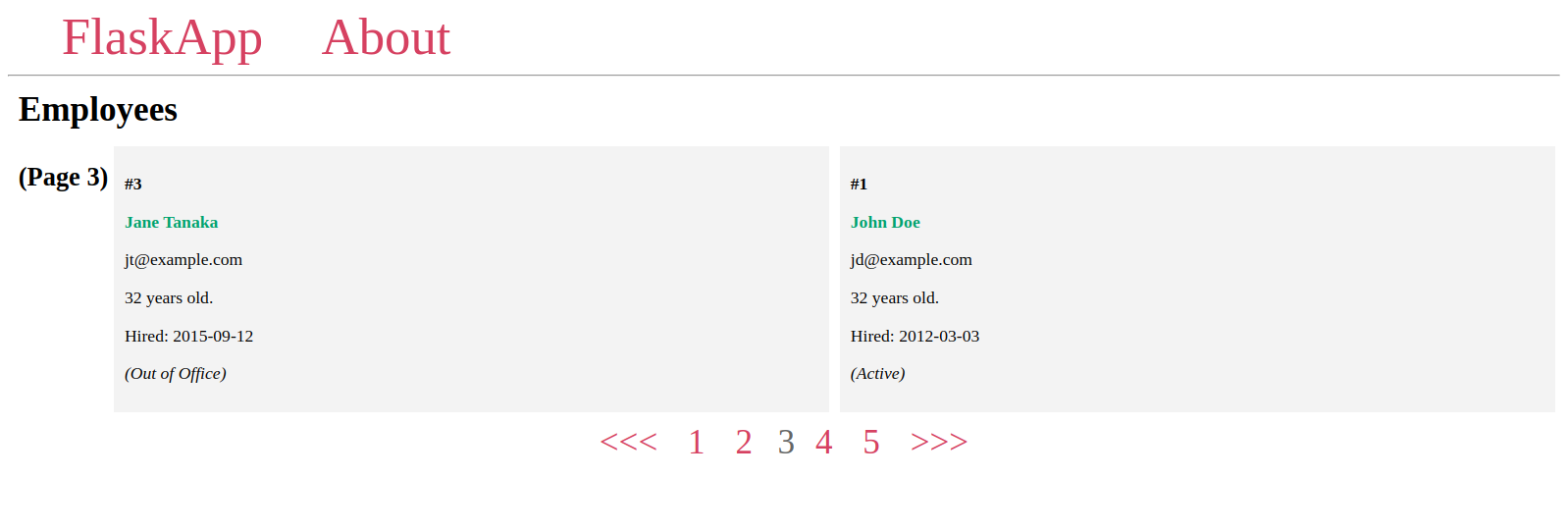
Ensuite, vous allez créer un widget de pagination pour naviguer entre les pages, vous utiliserez quelques attributs et méthodes de l’objet de pagination pour afficher tous les numéros de page, chaque numéro étant lié à sa page dédiée, et un bouton <<< pour revenir en arrière si la page actuelle a une page précédente, et un bouton >>> pour aller à la page suivante si elle existe.
Le widget de pagination aura l’aspect suivant :

Pour l’ajouter, ouvrez index.html :
Modifiez le fichier en ajoutant la balise div suivante mise en évidence ci-dessous sous la balise div de contenu :
Enregistrez et fermez le fichier.
Ici, vous utilisez la condition if pagination.has_prev pour ajouter un lien <<< vers la page précédente si la page actuelle n’est pas la première page. Vous liez à la page précédente en utilisant l’appel de fonction url_for('index', page=pagination.prev_num), dans lequel vous liez à la fonction de vue index, passant la valeur pagination.prev_num au paramètre d’URL page.
Pour afficher des liens vers tous les numéros de page disponibles, vous bouclez à travers les éléments de la méthode pagination.iter_pages() qui vous donne un numéro de page à chaque boucle.
Vous utilisez la condition if pagination.page != number pour vérifier si le numéro de page actuel n’est pas le même que celui dans la boucle actuelle. Si la condition est vraie, vous liez la page pour permettre à l’utilisateur de changer la page actuelle vers une autre page. Sinon, si la page actuelle est la même que le numéro de la boucle, vous affichez le numéro sans lien. Cela permet aux utilisateurs de connaître le numéro de page actuel dans le widget de pagination.
Enfin, vous utilisez la condition pagination.has_next pour voir si la page actuelle a une page suivante, auquel cas vous liez à celle-ci en utilisant l’appel url_for('index', page=pagination.next_num) et un lien >>>.
Naviguez vers la page d’index dans votre navigateur : http://127.0.0.1:5000/
Vous verrez que le widget de pagination est entièrement fonctionnel :
Ici, vous utilisez >>> pour passer à la page suivante et <<< pour la page précédente, mais vous pouvez également utiliser d’autres caractères que vous souhaitez, tels que > et < ou des images dans des balises <img>.
Vous avez affiché des employés sur plusieurs pages et appris à gérer la pagination dans Flask-SQLAlchemy. Et vous pouvez maintenant utiliser votre widget de pagination sur d’autres applications Flask que vous construisez.
Conclusion
Vous avez utilisé Flask-SQLAlchemy pour créer un système de gestion des employés. Vous avez interrogé une table et filtré les résultats en fonction des valeurs des colonnes et des conditions logiques simples et complexes. Vous avez ordonné, compté et limité les résultats de la requête. Et vous avez créé un système de pagination pour afficher un certain nombre d’enregistrements sur chaque page de votre application web, et naviguer entre les pages.
Vous pouvez utiliser ce que vous avez appris dans ce tutoriel en combinaison avec les concepts expliqués dans certains de nos autres tutoriels Flask-SQLAlchemy pour ajouter plus de fonctionnalités à votre système de gestion des employés:
- Comment utiliser Flask-SQLAlchemy pour interagir avec les bases de données dans une application Flask pour apprendre comment ajouter, éditer ou supprimer des employés.
- Comment utiliser les relations de base de données un-à-plusieurs avec Flask-SQLAlchemy pour apprendre comment utiliser les relations un-à-plusieurs pour créer une table de département afin de lier chaque employé au département auquel il appartient.
- Comment utiliser les relations de base de données many-to-many avec Flask-SQLAlchemy pour apprendre à utiliser les relations many-to-many afin de créer une table
taskset de la lier à la tableemployee, où chaque employé a plusieurs tâches et chaque tâche est attribuée à plusieurs employés.
Si vous souhaitez en savoir plus sur Flask, consultez les autres tutoriels de la série Comment construire des applications Web avec Flask.