













Nei primi giorni dell’informatica, le applicazioni gestivano i compiti in modo sequenziale. Con l’aumento della scala, con milioni di utenti, questo approccio divenne impraticabile. L’elaborazione asincrona consentì di gestire più compiti contemporaneamente, ma la gestione di thread/processi su una singola macchina portò a vincoli sulle risorse e complessità.
Qui entra in gioco l’elaborazione parallela distribuita. Distribuendo il carico di lavoro su più macchine, ciascuna dedicata a una parte del compito, offre una soluzione scalabile ed efficiente. Se hai una funzione per elaborare un grande lotto di file, puoi dividere il carico di lavoro su più macchine per elaborare i file contemporaneamente invece di gestirli sequenzialmente su una sola macchina. Inoltre, migliora le prestazioni sfruttando le risorse combinate e offre scalabilità e tolleranza ai guasti. Man mano che le richieste aumentano, puoi aggiungere altre macchine per aumentare le risorse disponibili.
È difficile costruire e gestire applicazioni distribuite su larga scala, ma ci sono diversi framework e strumenti che possono aiutarti. In questo post del blog, esamineremo uno di questi framework di calcolo distribuito open-source: Ray. Vedremo anche KubeRay, un operatore Kubernetes che consente un’integrazione fluida di Ray con i cluster Kubernetes per il calcolo distribuito in ambienti cloud-native. Ma prima, comprendiamo dove l’parallelismo distribuito è utile.
Dove Aiuta l’Elaborazione Parallela Distribuita?
Qualsiasi attività che trae vantaggio dalla suddivisione del carico di lavoro su più macchine può utilizzare l’elaborazione parallela distribuita. Questo approccio è particolarmente utile per scenari come il crawling web, l’analisi dei dati su larga scala, l’addestramento dei modelli di machine learning, l’elaborazione in tempo reale dei flussi, l’analisi dei dati genomici e il rendering video. Distribuendo i compiti su più nodi, l’elaborazione parallela distribuita migliora significativamente le prestazioni, riduce i tempi di elaborazione e ottimizza l’utilizzo delle risorse, rendendola essenziale per le applicazioni che richiedono un alto throughput e una gestione rapida dei dati.
Quando non è necessaria l’elaborazione parallela distribuita
- Applicazioni su piccola scala: Per set di dati ridotti o applicazioni con requisiti minimi di elaborazione, il costo gestionale di un sistema distribuito potrebbe non essere giustificato.
- Forti dipendenze dei dati: Se i compiti sono altamente interdipendenti e non possono essere facilmente parallelizzati, l’elaborazione distribuita potrebbe offrire pochi benefici.
- Confini temporali in tempo reale: Alcune applicazioni in tempo reale (ad esempio, siti web finanziari e di prenotazione di biglietti) richiedono latenze estremamente basse, che potrebbero non essere raggiungibili con la complessità aggiuntiva di un sistema distribuito.
- Risorse limitate: Se l’infrastruttura disponibile non può supportare il costo di un sistema distribuito (ad esempio, larghezza di banda di rete insufficiente, numero limitato di nodi), potrebbe essere meglio ottimizzare le prestazioni di una singola macchina.
Come Ray aiuta con l’elaborazione parallela distribuita
Ray è un framework di elaborazione parallela distribuita che racchiude tutti i vantaggi del calcolo distribuito e soluzioni alle sfide di cui abbiamo discusso, come tolleranza ai guasti, scalabilità, gestione del contesto, comunicazione, e così via. È un framework Pythonic, che consente l’uso di librerie e sistemi esistenti per lavorare con esso. Con l’aiuto di Ray, un programmatore non ha bisogno di gestire i pezzi del livello di elaborazione parallela. Ray si occuperà della pianificazione e dell’autoscaling in base ai requisiti di risorse specificati.
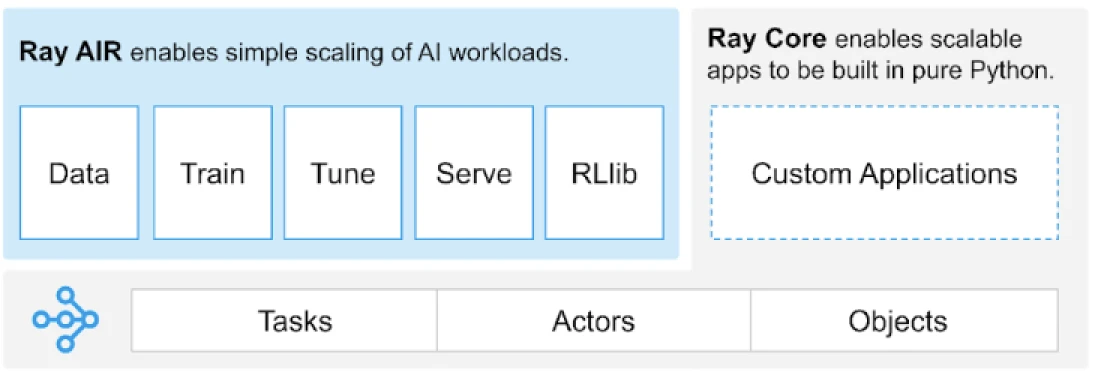
Ray fornisce un’API universale di attività, attori e oggetti per costruire applicazioni distribuite.
(Fonte Immagine)
Ray fornisce un insieme di librerie costruite sui primitivi core, cioè, Attività, Attori, Oggetti, Driver e Lavori. Questi offrono un’API versatile per aiutare a costruire applicazioni distribuite. Diamo un’occhiata ai primitivi core, alias, Ray Core.
Primitivi Core di Ray
- Compiti: I compiti Ray sono funzioni Python arbitrarie eseguite in modo asincrono su worker Python separati su un nodo di un cluster Ray. Gli utenti possono specificare i requisiti di risorse in termini di CPU, GPU e risorse personalizzate che vengono utilizzate dal programmatore del cluster per distribuire i compiti per l’esecuzione parallelizzata.
- Attori: Ciò che i compiti sono alle funzioni, gli attori sono alle classi. Un attore è un worker con stato, e i metodi di un attore vengono pianificati su quel worker specifico e possono accedere e modificare lo stato di quel worker. Come i compiti, gli attori supportano requisiti di risorse CPU, GPU e personalizzate.
- Oggetti: In Ray, i compiti e gli attori creano e calcolano oggetti. Questi oggetti remoti possono essere memorizzati ovunque in un cluster Ray. I riferimenti agli oggetti vengono utilizzati per fare riferimento ad essi, e vengono memorizzati nella memoria condivisa distribuita di Ray.
- Driver: Il programma radice, o il programma “principale”: questo è il codice che esegue
ray.init() - Jobs: La raccolta di compiti, oggetti e attori che originano (ricorsivamente) dallo stesso driver e il loro ambiente di esecuzione
Per informazioni sui primitivi, è possibile consultare la documentazione di base di Ray.
Metodi Chiave di Ray Core
Di seguito sono riportati alcuni dei metodi chiave all’interno di Ray Core comunemente utilizzati:
-
ray.init()– Avvia l’esecuzione di Ray e si connette al cluster Ray.import ray ray.init()
-
@ray.remote– Decoratore che specifica una funzione o una classe Python da eseguire come un task (funzione remota) o attore (classe remota) in un processo diverso@ray.remote def remote_function(x): return x * 2
-
.remote– Postfisso per le funzioni e classi remote; le operazioni remote sono asincroneresult_ref = remote_function.remote(10)
-
ray.put()– Mette un oggetto nello store degli oggetti in memoria; restituisce un riferimento all’oggetto utilizzato per passare l’oggetto a qualsiasi chiamata di funzione o metodo remoto.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Ottiene un oggetto(i) remoto(i) dallo store degli oggetti specificando il riferimento all’oggetto(i).result = ray.get(result_ref) original_data = ray.get(data_ref)
Ecco un esempio dell’utilizzo della maggior parte dei metodi chiave di base:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Utilizzare .remote per creare un'attività
future = calculate_square.remote(5)
# Ottieni il risultato
result = ray.get(future)
print(f"The square of 5 is: {result}")Come funziona Ray?
Il cluster Ray è come un team di computer che condividono il lavoro di esecuzione di un programma. È composto da un nodo principale e più nodi lavoratori. Il nodo principale gestisce lo stato del cluster e la pianificazione, mentre i nodi lavoratori eseguono compiti e gestiscono attori
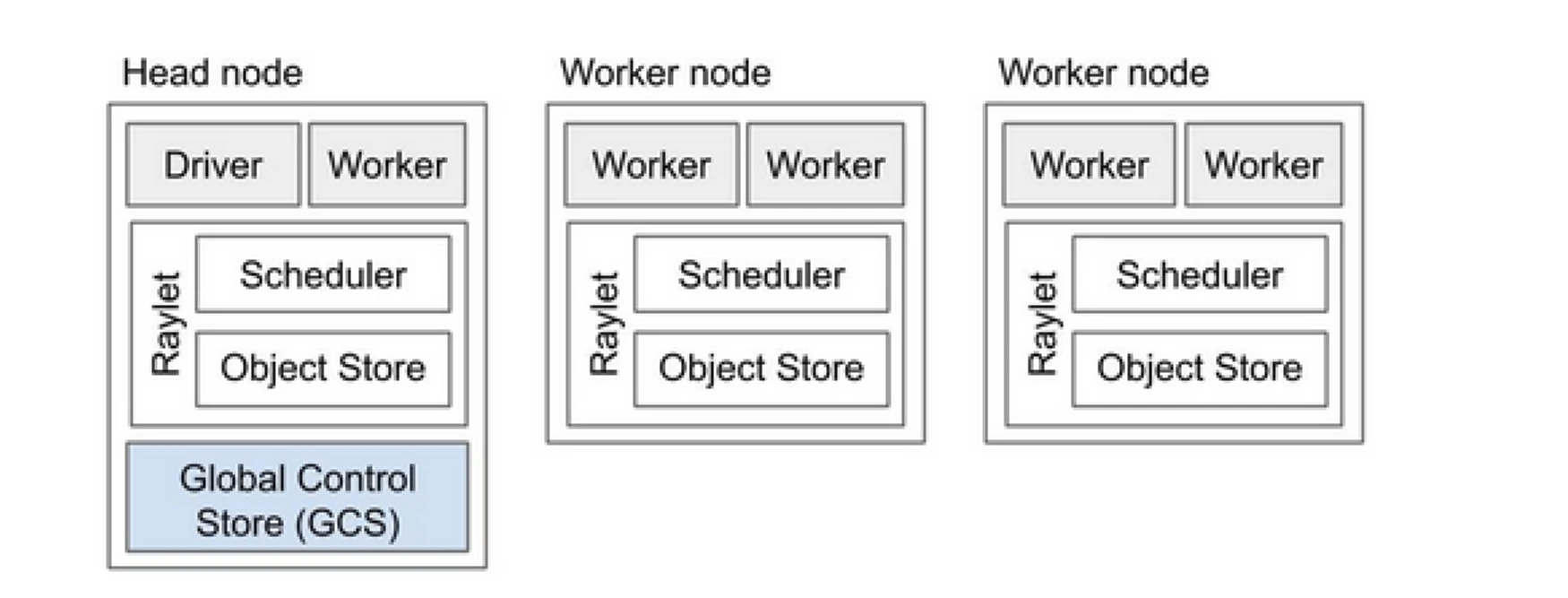
Componenti del cluster Ray
- Global Control Store (GCS): Il GCS gestisce i metadati e lo stato globale del cluster Ray. Tiene traccia di compiti, attori e disponibilità delle risorse, garantendo che tutti i nodi abbiano una visione coerente del sistema.
- Pianificatore: Il pianificatore distribuisce compiti e attori tra i nodi disponibili. Garantisce un utilizzo efficiente delle risorse e un bilanciamento del carico considerando i requisiti delle risorse e le dipendenze dei compiti.
- Nodo principale: Il nodo principale orchestra l’intero cluster Ray. Esegue il GCS, gestisce la pianificazione dei compiti e monitora la salute dei nodi lavoratori.
- Nodi lavoratori: I nodi lavoratori eseguono compiti e attori. Eseguono i calcoli effettivi e memorizzano oggetti nella loro memoria locale.
- Raylet: Gestisce le risorse condivise su ciascun nodo ed è condiviso tra tutti i lavori in esecuzione contemporaneamente.
Puoi consultare il documento sull’architettura di Ray v2 per ulteriori informazioni dettagliate.
Lavorare con applicazioni Python esistenti non richiede molte modifiche. Le modifiche necessarie riguarderebbero principalmente la funzione o la classe che deve essere distribuita naturalmente. Puoi aggiungere un decoratore e convertirlo in compiti o attori. Vediamo un esempio di questo.
Convertire una Funzione Python in un Compito Ray
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Convertire una Classe Python in un Attore Ray
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Memorizzare Informazioni in Oggetti Ray
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Per saperne di più sul suo concetto, vai alla documentazione di Ray Core Key Concept.
Ray vs Approccio Tradizionale di Elaborazione Parallela Distribuita
Sotto è un’analisi comparativa tra l’approccio tradizionale (senza Ray) e Ray su Kubernetes per abilitare l’elaborazione parallela distribuita.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Distribuzione | Impostazione e configurazione manuale | Automatizzato con KubeRay Operator |
| Scalabilità | Scalabilità manuale | Scalabilità automatica con RayAutoScaler e Kubernetes |
| Tolleranza ai Guasti | Meccanismi di tolleranza ai guasti personalizzati | Tolleranza ai guasti integrata con Kubernetes e Ray |
| Gestione delle Risorse | Assegnazione manuale delle risorse | Assegnazione e gestione automatizzate delle risorse |
| Bilanciamento del Carico | Soluzioni di bilanciamento del carico personalizzate | Bilanciamento del carico integrato con Kubernetes |
| Gestione delle dipendenze | Installazione manuale delle dipendenze | Ambiente coerente con i contenitori Docker |
| Coordinazione del cluster | Complesso e manuale | Semplificato con la scoperta e la coordinazione dei servizi di Kubernetes |
| Sovraccarico di sviluppo | Alto, con soluzioni personalizzate necessarie | Ridotto, con Ray e Kubernetes che gestiscono molti aspetti |
| Flessibilità | Adattabilità limitata a carichi di lavoro in cambiamento | Alta flessibilità con scalabilità dinamica e allocazione delle risorse |
Kubernetes fornisce una piattaforma ideale per eseguire applicazioni distribuite come Ray grazie alle sue robuste capacità di orchestrazione. Di seguito sono riportati i punti chiave che evidenziano il valore di eseguire Ray su Kubernetes:
- Gestione delle risorse
- Scalabilità
- Orchestrazione
- Integrazione con l’ecosistema
- Facile distribuzione e gestione
L’operatore KubeRay rende possibile eseguire Ray su Kubernetes.
Cosa è KubeRay?
L’Operatore KubeRay semplifica la gestione dei cluster Ray su Kubernetes automatizzando compiti come distribuzione, scalabilità e manutenzione. Utilizza le Definizioni di Risorse Personalizzate (CRD) di Kubernetes per gestire le risorse specifiche di Ray.
CRD di KubeRay
Ha tre CRD distinti:
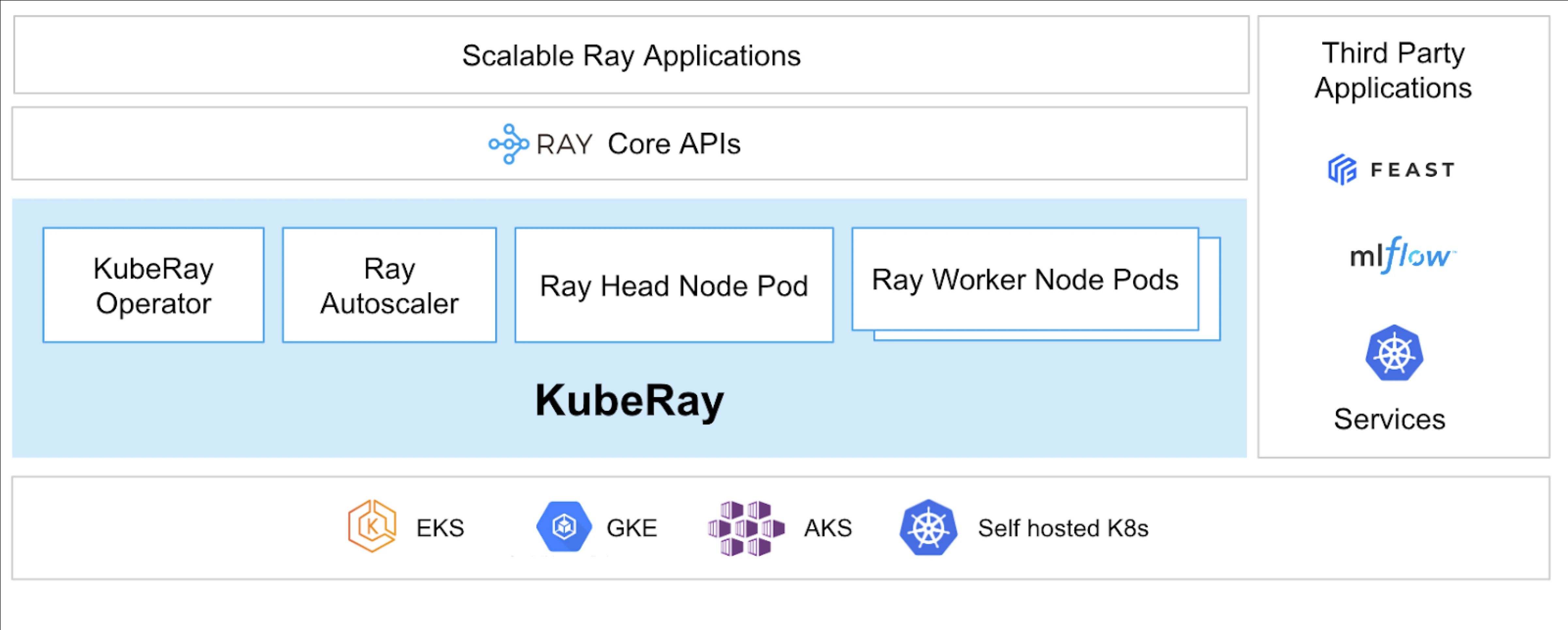
- RayCluster: Questo CRD aiuta a gestire il ciclo di vita di RayCluster e si occupa dell’AutoScaling in base alla configurazione definita.
- RayJob: È utile quando c’è un lavoro una tantum che si desidera eseguire invece di mantenere un RayCluster in standby tutto il tempo. Crea un RayCluster e invia il lavoro quando è pronto. Una volta completato il lavoro, elimina il RayCluster. Questo aiuta a riciclare automaticamente il RayCluster.
- RayService: Questo crea anche un RayCluster, ma distribuisce un’applicazione RayServe su di esso. Questo CRD rende possibile effettuare aggiornamenti in loco all’applicazione, fornendo aggiornamenti e upgrade senza tempi di inattività per garantire l’alta disponibilità dell’applicazione.
Casi d’uso di KubeRay
Distribuzione di un modello on-demand utilizzando RayService
RayService consente di distribuire modelli on-demand in un ambiente Kubernetes. Questo può essere particolarmente utile per applicazioni come la generazione di immagini o l’estrazione di testo, dove i modelli vengono distribuiti solo quando necessario.
Ecco un esempio di diffusione stabile. Una volta applicato in Kubernetes, creerà RayCluster e eseguirà anche un RayService, che servirà il modello fino a quando non eliminerai questa risorsa. Consente agli utenti di prendere il controllo delle risorse.
Addestramento di un modello su un cluster GPU utilizzando RayJob
RayService soddisfa diverse esigenze dell’utente, mantenendo il modello o l’applicazione distribuiti fino a quando non vengono eliminati manualmente. Al contrario, RayJob consente lavori una tantum per casi d’uso come l’addestramento di un modello, la preelaborazione dei dati o l’inferenza per un numero fisso di richieste fornite.
Esegui il server di inferenza su Kubernetes utilizzando RayService o RayJob
In generale, eseguiamo la nostra applicazione in Deployment, che mantiene gli aggiornamenti continui senza tempi di inattività. Allo stesso modo, in KubeRay, questo può essere ottenuto utilizzando RayService, che distribuisce il modello o l’applicazione e gestisce gli aggiornamenti continui.
Tuttavia, potrebbero esserci casi in cui si desidera semplicemente eseguire inferenze batch invece di eseguire i server di inferenza o le applicazioni per un lungo periodo di tempo. Qui è possibile sfruttare RayJob, che è simile alla risorsa Job di Kubernetes.
Inferenza batch di classificazione delle immagini con Huggingface Vision Transformer è un esempio di RayJob, che esegue inferenze batch.
Questi sono i casi d’uso di KubeRay, che ti consentono di fare di più con il cluster Kubernetes. Con l’aiuto di KubeRay, puoi eseguire carichi di lavoro misti sullo stesso cluster Kubernetes e delegare la pianificazione dei carichi di lavoro basati su GPU a Ray.
Conclusione
L’elaborazione parallela distribuita offre una soluzione scalabile per gestire attività su larga scala e ad alta intensità di risorse. Ray semplifica le complessità di costruzione di applicazioni distribuite, mentre KubeRay integra Ray con Kubernetes per un deployment e una scalabilità senza soluzione di continuità. Questa combinazione migliora le prestazioni, la scalabilità e la tolleranza ai guasti, rendendola ideale per il web crawling, l’analisi dei dati e i compiti di machine learning. Sfruttando Ray e KubeRay, puoi gestire in modo efficiente il calcolo distribuito, soddisfacendo le esigenze del mondo odierno guidato dai dati con facilità.
Non solo, ma poiché i nostri tipi di risorse di calcolo stanno cambiando da CPU a GPU, diventa importante avere un’infrastruttura cloud efficiente e scalabile per ogni tipo di applicazione, sia essa AI o elaborazione di grandi dati.
Se hai trovato questo post informativo e coinvolgente, mi piacerebbe sapere cosa ne pensi, quindi inizia una conversazione su LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray