













Le metriche di distanza costituiscono la base di numerosi algoritmi in data science e apprendimento automatico, permettendo la misura della similitudine o della dissimilitudine tra i punti dati. In questo guida, esploreremo i fondamenti della distanza di Minkowski, le sue proprietà matematiche e le sue implementazioni. Esaminerà come essa si relaziona ad altre misure di distanza comuni e dimostrerà il suo uso tramite esempi di codifica in Python e R.
Se si stanno sviluppando algoritmi di clustering, si sta lavorando a detection di anomalia o si sta finemente adattando modelli di classificazione, capire la distanza di Minkowski può migliorare il metodo di approcio all’analisi dati e allo sviluppo del modello. Facciamo un sguardo.
Cosa è la Distanza di Minkowski?
La distanza di Minkowski è una misura versatile utilizzata in spazi vettoriali dotati di norma, così chiamata in onore del matematico tedesco Hermann Minkowski. È una generalizzazione di diverse misure di distanza ben note, rendendola un concetto fondamentale in vari campi come la matematica, la scienza informatica e l’analisi dati.
Al suo interno, la distanza di Minkowski fornisce un metodo per misurare la distanza tra due punti in uno spazio multi-dimensionale. Ciò che la rende particolarmente utile è la sua capacità di includere altre misure di distanza come casi speciali, principalmente attraverso un parametro p. Questo parametro consente alla distanza di Minkowski di adattarsi a diversi spazi problematici e caratteristiche dei dati. La formula generale per la distanza di Minkowski è:
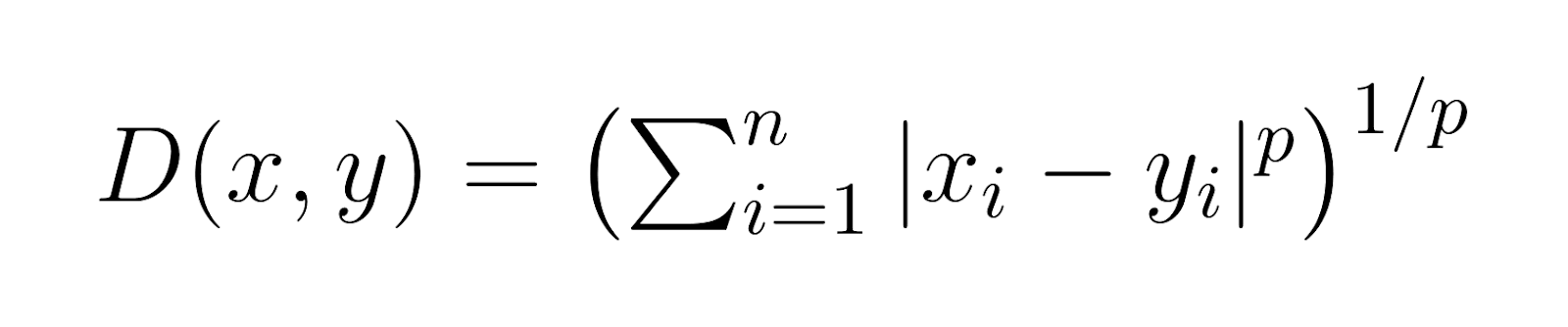
Dove:
-
xeysono due punti in uno spazio n-dimensionale -
pè un parametro che determina il tipo di distanza (p ≥ 1) -
|xi - yi|rappresenta la differenza assoluta tra le coordinate di x e y in ogni dimensione
La distanza di Minkowski è utile per due motivi principali. Per un lato, offre la flessibilità necessaria per passare da una distanza di Manhattan a una di Euclidean a seconda delle necessità. D’altro lato, riconosce che non tutti i dataset (pensate a spazi ad alta dimensione) sono adatti a una distanza di Manhattan o di Euclidean pura.
In pratica, il parametro p è tipicamente scelto integrando un workflow di validazione train/test. Testando differenti valori di p durante la validazione crociata, è possibile determinare quale valore fornisca il migliore rendimento del modello per il dataset specifico.
Come funziona la Distanza di Minkowski
Osserviamo come la distanza di Minkowski si relaziona ad altre formule di distanza e poi passiamo ad un esempio.
Generalizzazione di altri metodi di distanza
Il primo punto da considerare è come la formula di distanza di Minkowski contenga all’interno di sé le formule per la distanza di Manhattan, di Euclidean e di Chebyshev.
Distanza di Manhattan (p = 1):
Quando p è impostato a 1, la distanza di Minkowski diventa una distanza di Manhattan.
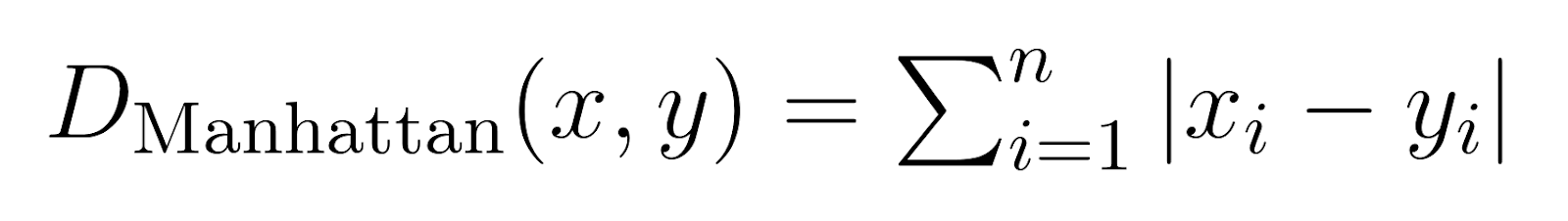
Nota anche come distanza di blocco cittadino o norma L1, la Distanza di Manhattan misura la somma delle differenze assolute.
Distanza di Euclidean (p = 2):
Quando p è impostato a 2, la distanza di Minkowski diventa una distanza di Euclidean.
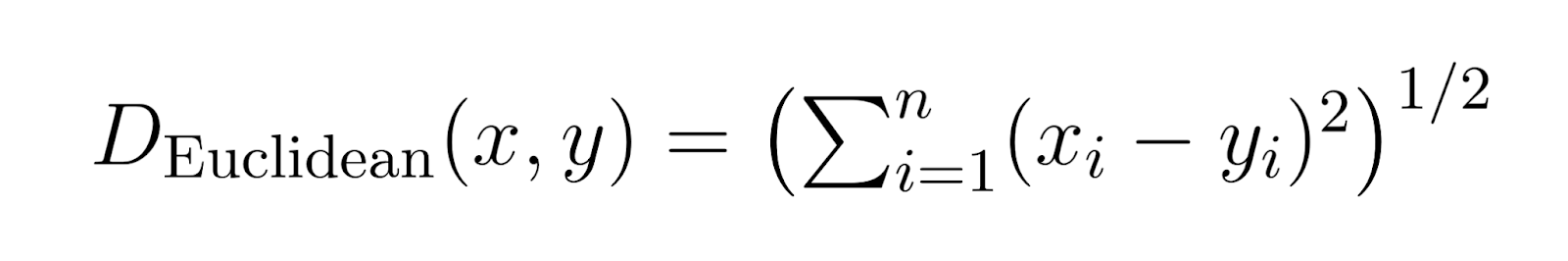
Distanza euclidea è la misura di distanza più comune, che rappresenta la distanza lineare tra due punti.
Distanza di Chebyshev (p → ∞):
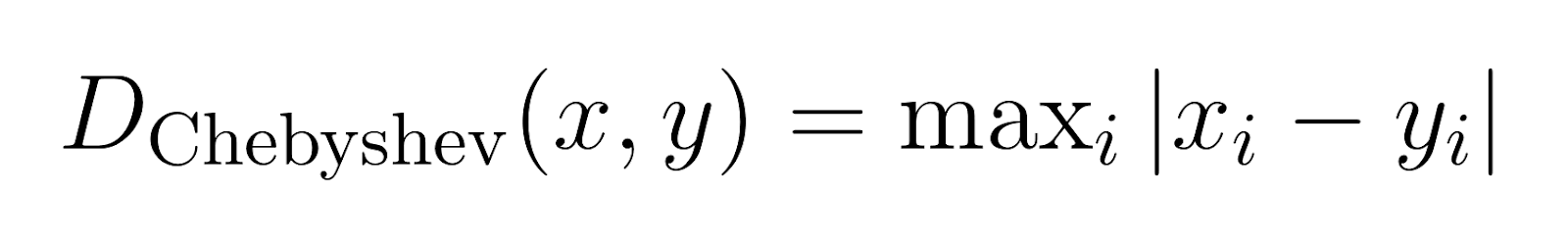
Distanza di Chebyshev, anche nota come distanza da scacchiere, misura la differenza massima lungo qualsiasi dimensione.
Esempio pratico
Per comprendere veramente la funzionalità e il potere della distanza di Minkowski, lavoriamo attraverso un esempio. Questa esplorazione ci aiuterà a capire come il parametro p influenza la calcolazione e l’interpretazione delle distanze in spazi multidimensionali.
Pensiamo a due punti in uno spazio 2D:
- Punto A: (2, 3)
- Punto B: (5, 7)
Calcoleremo la distanza di Minkowski tra questi due punti per differenti valori di p.

Il parametro p nella formula della distanza di Minkowski controlla la sensibilità alla differenza tra i singoli componenti:
- Quando p=1: Tutte le differenze contribuiscono linearmente.
- Quando p=2: Maggiori differenze hanno un impatto più significativo a causa dell’applicazione del quadrato.
- Quando p>2: viene posto ancora più focus sulla maggior differenza.
- Quando p→∞: Solo la differenza massima tra tutte le dimensioni importa.
Con l’aumentare di p, la distanza di Minkowski generalmente decresce, avvicinandosi alla distanza di Chebyshev. Questo avviene perché i valori di p più alti danno maggiore importanza alla maggior differenza e meno alle differenze minori.
Per visualizzare come i valori diversi di p influiscono sulla calcolatura della distanza tra i nostri punti A(2, 3) e B(5, 7), esaminiamo il seguente grafico:
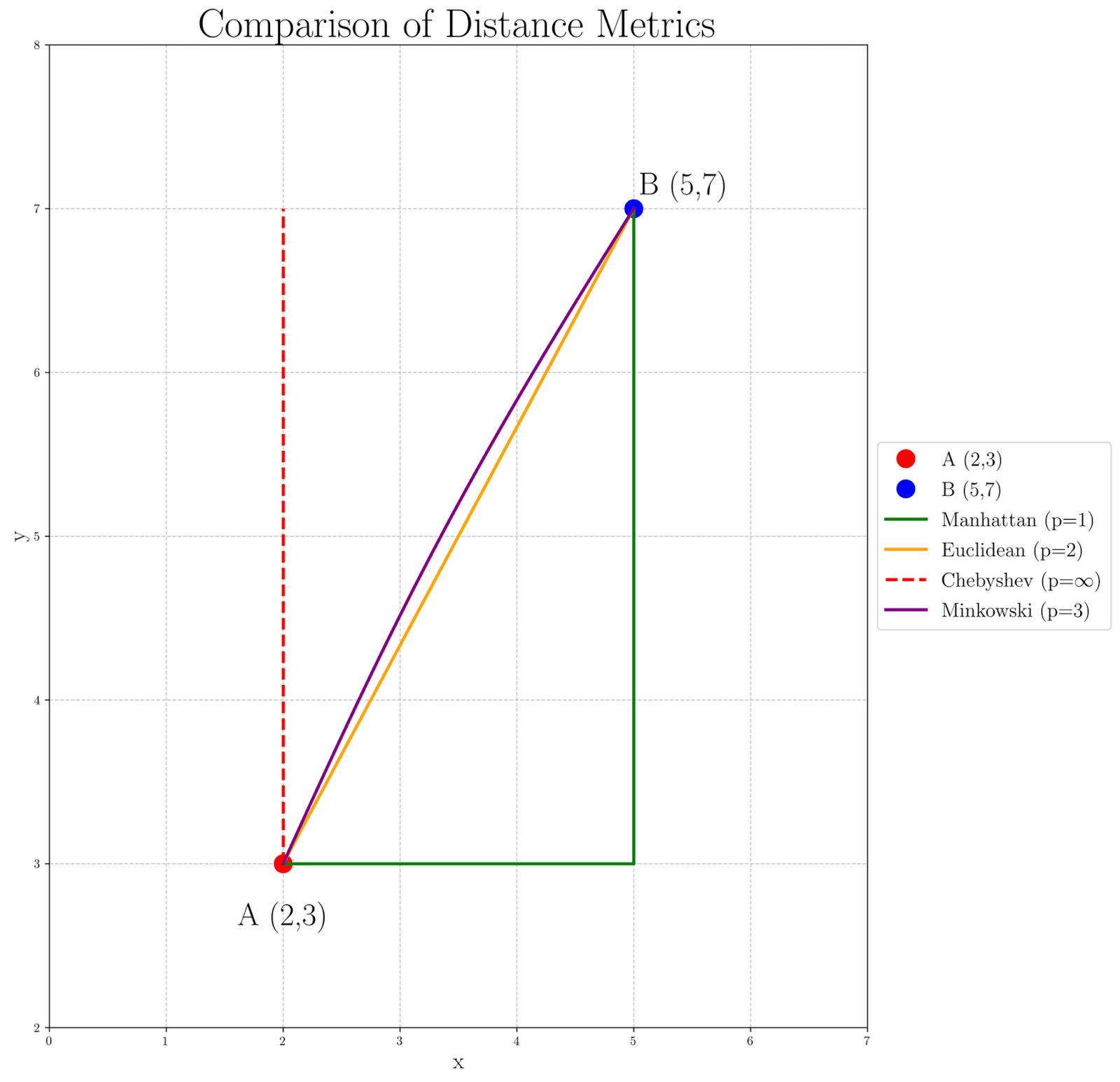
Osservando il grafico, possiamo vedere come la misura della distanza cambia man mano che p aumenta:
- La distanza Manhattan (p=1), rappresentata dalla linea verde, dà la più lunga via, poiché segue strettamente il reticolato.
- La distanza Euclidea (p=2), mostrata dalla linea arancione retta, fornisce una via diretta e retta.
- La distanza di Chebyshev (p=∞), rappresentata dalle linee rosse tratteggiate, si concentra soltanto sulla maggiore differenza delle coordinate, creando una via che si sposta massimamente in una dimensione prima di occuparsi dell’altra.
- La distanza di Minkowski con p=3 in viola mostra una leggera curva, indicando la transizione tra la distanza Euclidea e la distanza di Chebyshev.
Questa visualizzazione ci aiuta a capire perché diversi valori di p potrebbero essere scelti per varie applicazioni. Ad esempio, la distanza Manhattan potrebbe essere più appropriata nei problemi di navigazione in città, mentre la distanza Euclidea è spesso utilizzata nei calcoli dello spazio fisico. I valori di p più alti, come nel caso di Minkowski p=3, possono essere utili nei scenari in cui le differenze maggiori dovrebbero essere enfatizzate, e la distanza di Chebyshev potrebbe essere preferita quando la differenza massima in qualsiasi dimensione è il fattore più critico.
Applicazioni della distanza di Minkowski
La distanza di Minkowski, grazie al suo parametro adattabile p, è uno strumento flessibile utilizzato in diversi campi. Cambiando il valore di p, è possibile personalizzare come si misura la distanza tra i punti, rendendola adatta a varie attività. Ecco quattro applicazioni in cui la distanza di Minkowski riveste un ruolo importante.
Machine learning e data science
Nel machine learning e nella data science, la distanza di Minkowski è fondamentale per alcuni algoritmi che si basano sulla misura della similitudine o della dissimilitudine tra i punti dati. Uno degli esempi più importanti è l’algoritmo k-Nearest Neighbors (k-NN), che classifica i punti dati in base alle categorie dei loro vicini più vicini. Utilizzando la distanza di Minkowski, è possibile modificare il parametro p per cambiare il modo in cui si calcola la “proximità” tra i punti.
Riconoscimento di pattern
Il riconoscimento di pattern consiste nell’identificare schemi e regolarità nei dati, come il riconoscimento handwriting o il rilevamento dei特征 facciali. In questo contesto, la distanza di Minkowski misura la differenza tra vettori di feature che rappresentano i pattern. Per esempio, nella riconoscimento delle immagini, ogni immagine può essere rappresentata da un vettore di valori di pixel. Calcolando la distanza di Minkowski tra questi vettori è possibile quantificare come simili o differenti sono le immagini.
Regolando p, è possibile controllare la sensibilità della misura di distanza rispetto alle differenze in specifiche caratteristiche. Un p più basso potrebbe considerare le differenze globali tra tutti i pixel, mentre un p più alto potrebbe enfatizzare le differenze significative in determinate regioni dell’immagine.
Rilevamento di anomalie
Il rilevamento di anomalie ha lo scopo di identificare i punti dati che si deviano significativamente dalla maggioranza, attività fondamentale in aree come il rilevamento di frodi, la sicurezza di rete e il rilevamento di guasti nei sistemi. La distanza di Minkowski viene utilizzata per misurare quanto una datazione sia distante dagli altri punti del dataset. I punti con distanze elevate sono potenziali anomalie.Scegliendo un p appropriato, gli analisti possono migliorare la sensibilità dei sistemi di rilevamento di anomalie nei tipi di deviazioni che sono più rilevanti per il loro contesto specifico.
Geometria computazionale e analisi spaziale.
In geometria computazionale e nell’analisi spaziale, la distanza di Minkowski è utilizzata per calcolare le distanze tra punti nello spazio, che costituisce la base per molti algoritmi geometrici. Per esempio, la rilevazione di collisioni in questi domini si basa sulla distanza di Minkowski per determinare quando gli oggetti sono vicini abbastanza per interagire. Modificando p, i sviluppatori possono creare diverse Boundary collisioni, che vanno dall’angolare (più basso p) alle rotonde (più alto p).
Oltre alla rilevazione di collisioni, la distanza di Minkowski può essere utile nell’analisi spaziale e nell’approssimazione spaziale. Variando il valore di p consente ai ricercatori di enfatizzare differenti aspetti delle relazioni spaziali, dalla distanza tra blocchi cittadini alle similitudini globali della forma.
Proprietà matematiche della distanza di Minkowski
La distanza di Minkowski non solo è uno strumento versatile nelle applicazioni pratiche ma anche un importante concetto nella teoria matematica, soprattutto nell’ studio degli spazi metrici e delle norme.
Proprietà degli spazi metrici
La distanza di Minkowski soddisfa le quattro proprietà essenziali richieste per una funzione da considerarsi una metrica in uno spazio metrico:
- Non-negatività: La distanza di Minkowski tra due qualsiasi punti è sempre non negativa, d(x,y)≥0. Questo è evidente poiché è la radice p-esima di una somma di termini non negativi (valori assoluti elevati al potere p).
- Identità degli Incommensurabili: La distanza di Minkowski tra due punti è zero se e solo se i due punti sono identici. Matematicamente, d(x,y) = 0 se e solo se x=y. Questo segue perché la differenza assoluta tra componenti identici è zero.
- Simmetria: La distanza di Minkowski è simmetrica, cioè d(x,y)=d(y,x). Questa proprietà si mantiene perché l’ordine di sottrazione nei termini assoluti non influenza il risultato.
- Ingegneria del software: La distanza di Minkowski rispetta l’ineguaglianza dell’triangolo, che stabilisce che per qualunque tre punti x, y e z, la distanza da x a z è massimamente uguale alla somma della distanza da x a y e da y a z; formalmente, d(x,z)≤d(x,y)+d(y,z). Questa proprietà è meno intuitiva da dimostrare direttamente dalla formula e generalmente richiede matematiche più avanzate, ma fondamentalmente garantisce che prendere una via diretta tra due punti è il percorso più breve.
Generalizzazione della norma
La distanza di Minkowski funge da schema generale che unifica diversi modi per misurare le distanze in spazi matematici attraverso il concetto di norme. In termini semplici, una norma è una funzione che assegna una lunghezza o dimensione non negativa a un vettore in uno spazio vettoriale, misurando in sostanza quanto “lungo” sia il vettore. Modificando il parametro p nella formula della distanza di Minkowski, si può fluentemente passare da una norma all’altra, ognuna fornendo un metodo unico per calcolare la lunghezza del vettore.
Per esempio, quando p=1, la distanza di Minkowski diventa la norma Manhattan, che misura la distanza come la somma delle differenze assolute lungo ogni dimensione — immaginate di navigare una griglia di strade cittadine. Con p=2, diventa la norma euclideana, calcolando la distanza in linea retta (“come vola l’uccello”) tra i punti. Mentre p si avvicina all’infinito, converge alla norma di Chebyshev, dove la distanza è determinata dalla maggiore differenza singola tra le dimensioni. Questa flessibilità permette alla distanza di Minkowski di adattarsi a vari contesti matematici e pratici, rendendola una strumentazione versatile per misurare le distanze in diversi scenario.
Calcolare la Distanza di Minkowski in Python e R
Esploriamo implementazioni di calcolo della distanza di Minkowski in Python e R. Esaminerò pacchetti e librerie disponibili che consentono di raggiungere questo obiettivo.
Esempio Python
Per calcolare la distanza di Minkowski in Python, possiamo usare la libreria SciPy, che fornisce implementazioni efficienti di varie misure di distanza. Ecco un esempio che calcola la distanza di Minkowski per differenti valori di p:
import numpy as np from scipy.spatial import distance # Punti di esempio point_a = [2, 3] point_b = [5, 7] # Valori di p differenti p_values = [1, 2, 3, 10, np.inf] print("Minkowski distances using SciPy:") for p in p_values: if np.isinf(p): # Per p = infinito, usare la distanza di Chebyshev dist = distance.chebyshev(point_a, point_b) print(f"p = ∞, Distance = {dist:.2f}") else: dist = distance.minkowski(point_a, point_b, p) print(f"p = {p}, Distance = {dist:.2f}")
Riportando questo codice, i lettori possono osservare come la distanza cambia con differenti valori di p, reinforzando i concetti discussi precedentemente nell’articolo.
Minkowski distances using SciPy: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
Questo codice dimostra:
- Come utilizzare le funzioni di distanza di SciPy per le distanze di Minkowski e Chebyshev.
- Calcolo di distanze per diversi valori p, incluso l’infinito.
- La relazione tra la distanza di Minkowski e altre metriche (Manhattan, Euclideana, Chebyshev).
Esempio in R
Per R, utilizzeremo la funzione dist() dalla libreria stats:
# Definiamo la funzione di distanza di Minkowski usando stats::dist minkowski_distance <- function(x, y, p) { points <- rbind(x, y) if (is.infinite(p)) { # Per p = Inf, usare il metodo = "maximum" per la distanza di Chebyshev distance <- stats::dist(points, method = "maximum") } else { distance <- stats::dist(points, method = "minkowski", p = p) } return(as.numeric(distance)) } # Esempio d'uso point_a <- c(2, 3) point_b <- c(5, 7) # Valori di p diversi p_values <- c(1, 2, 3, 10, Inf) cat("Minkowski distances between points A and B using stats::dist:\n") for (p in p_values) { distance <- minkowski_distance(point_a, point_b, p) if (is.infinite(p)) { cat(sprintf("p = ∞, Distance = %.2f\n", distance)) } else { cat(sprintf("p = %g, Distance = %.2f\n", p, distance)) } }
Questo codice dimostra:
-
Come creare una funzione
minkowski_distanceutilizzando la funzionedist()dalla libreriastats. -
Gestione di differenti valori di p, incluso l’infinità per la distanza di Chebyshev.
-
Calcolo della distanza di Minkowski per diversi valori di p.
-
Formattazione dell’output per mostrare le distanze arrotondate a 2 cifre decimali.
L’output di questo codice sarà:
Minkowski distances between points A and B using stats::dist: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
Questa implementazione R fornisce un counterpart alla risorsa Python, permettendo ai lettori di vedere come la distanza di Minkowski può essere calcolata in ambienti di programmazione diversi.
Conclusione
La distanza di Minkowski fornisce un approcio flessibile e adattabile per misurare le distanze in spazi multi-dimensionali. La sua capacità di generalizzare altri metriche di distanza comuni tramite il parametro p lo rende un strumento prezioso in diversi campi della scienza dei dati e dell’apprendimento automatico. Modificando p, i praticanti possono adattare le loro calcoli di distanza alle specifiche caratteristiche dei loro dati e ai requisiti dei loro progetti, potenzialmente migliorando i risultati nelle attività che vanno dalla clustering alla rilevamento di anomalie.
Nel corso di applicare la distanza di Minkowski nel tuo lavoro, ti incoraggiamo ad esperimentare con differenti valori di p e ad osservare il loro impatto sui tuoi risultati. Per chi cerca di approfondire la sua conoscenza e le sue capacità, ti consigliamo di esplorare il corso Designing Machine Learning Workflows in Python e di considerare il programma di carriera Data Scientist Certification. Questi risorse possono aiutarti a costruire sul tuo know-how delle metriche di distanza e ad applicarle efficacemente in vari scenari.
Source:
https://www.datacamp.com/tutorial/minkowski-distance