













Convertire i tuoi dati grezzi in informazioni organizzate e utilizzabili può sembrare complesso. Beh, non quando hai una soluzione veloce ed efficiente. Non preoccuparti! Questo tutorial di AWS Glue per principianti ti aiuterà.
In questo tutorial, imparerai i passaggi cruciali per configurare ed eseguire trasformazioni dei dati con AWS Glue.
Esplora e semplifica la preparazione dei dati per l’analisi basata su cloud!
Prerequisiti
Prima di lavorare con AWS Glue, assicurati di avere un account attivo di Amazon Web Services (AWS) con la fatturazione abilitata. Un account gratuito sarà sufficiente per questo tutorial.
Creazione di un ruolo IAM per AWS Glue
Prima di eseguire un lavoro di trasformazione, è necessario creare un ruolo di Identity and Access Management (IAM) che conceda l’autorizzazione al servizio AWS Glue. Questo ruolo definisce il tipo di risorse a cui AWS Glue può accedere nel tuo account AWS.
Per creare il ruolo IAM, segui i passaggi seguenti:
1. Apri il tuo browser preferito e accedi alla Console di Gestione AWS.
2. Cerca e seleziona IAM nell’elenco dei risultati per accedere alla console IAM.
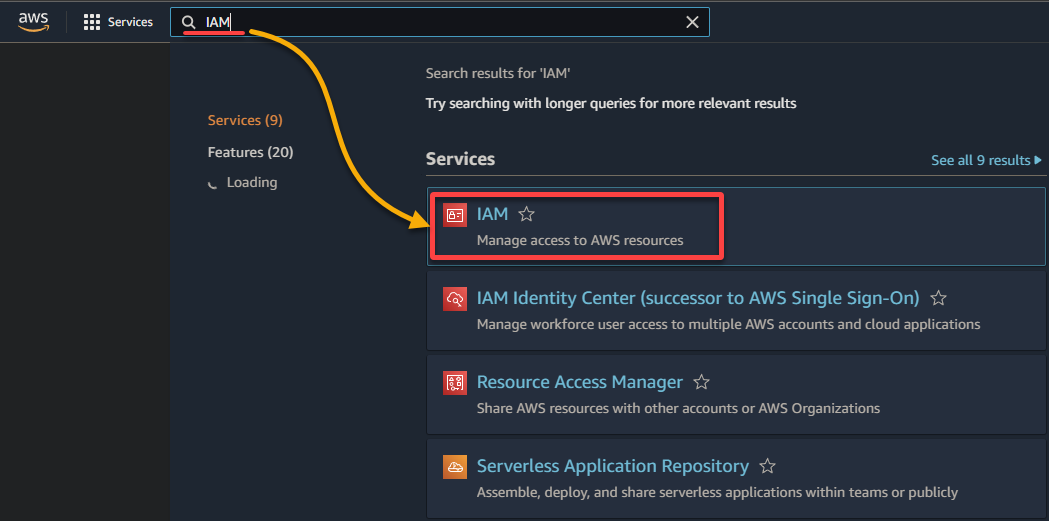
3. Nella console IAM, vai a Ruoli (pannello sinistro) e clicca su Crea ruolo (in alto a destra), reindirizzando il tuo browser a una nuova pagina dedicata alla configurazione del ruolo.

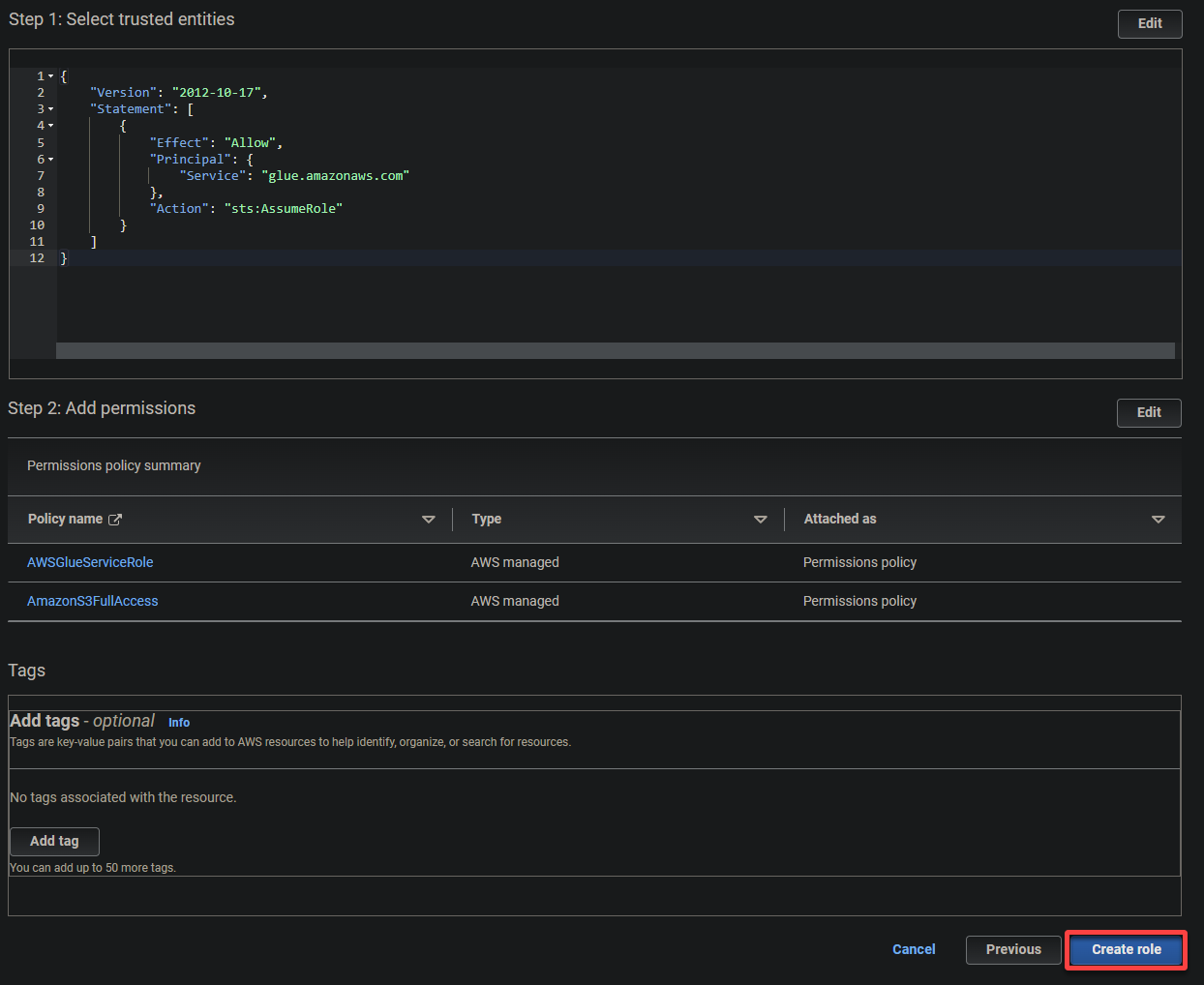
4. Ora, configura le seguenti impostazioni per il ruolo:
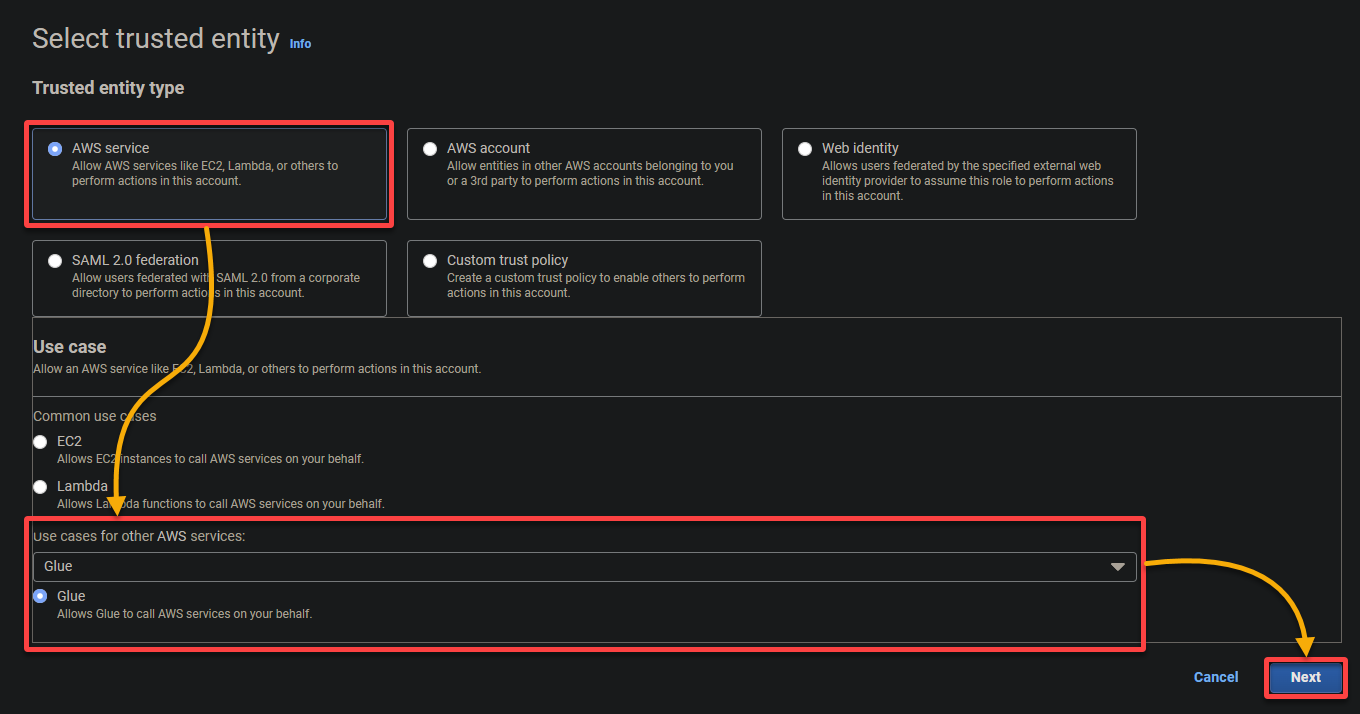
- Tipo di entità affidabile – Seleziona il servizio AWS in modo che un servizio AWS possa fidarsi del ruolo. Ciò consente a quel servizio di assumere il ruolo e agire per tuo conto.
- Caso d’uso – Scegli Glue nella sezione Casi d’uso per altri servizi AWS poiché creerai il ruolo IAM specificamente per AWS Glue, e fai clic su Avanti.
5. Cerca e seleziona le seguenti policy, e fai clic su Avanti.
- AWSGlueServiceRole – Concede al servizio AWS Glue le autorizzazioni necessarie per eseguire le sue operazioni.
- S3FullAccess – Concede accesso completo alle risorse S3, consentendo ad AWS Glue di leggere e scrivere nei bucket S3.
AWS Glue ha bisogno di autorizzazioni estese per leggere e scrivere nei bucket S3 per eseguire efficacemente le sue attività di estrazione, trasformazione e caricamento (ETL).
? A evita di concedere autorizzazioni eccessive non necessarie, poiché possono rappresentare rischi per la sicurezza.
6. Fornisci un nome descrittivo per il ruolo (ad es., glue_role) e una descrizione.
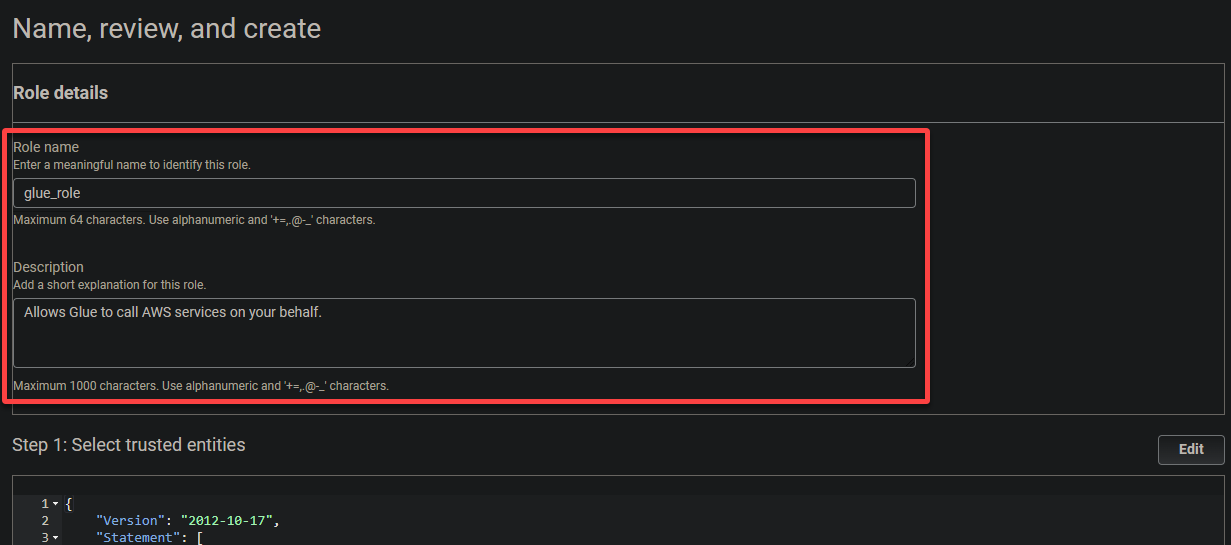
Infine, scorri verso il basso, rivedi le tue impostazioni e clicca su Crea ruolo (in basso a destra) per finalizzare la creazione del ruolo.
Creazione di un Bucket S3 e Caricamento di un File di Esempio
Ora che hai un ruolo IAM per AWS Glue, hai bisogno di un luogo in cui memorizzare i tuoi dati, nello specifico, un bucket S3. Un bucket S3 fornisce una posizione centralizzata per memorizzare i dati che AWS Glue elaborerà.
In questo esempio, AWS Glue utilizzerà AWS S3 come archivio dati per varie operazioni, come l’estrazione, la trasformazione e il caricamento (ETL) dei dati.
Per creare un bucket S3 e caricare un file di esempio, segui questi passaggi:
1. Scarica un file dati di esempio (ad esempio il set di dati Every Politician) sul tuo computer locale. Questo file contiene una raccolta non strutturata di record da utilizzare come input per il lavoro di trasformazione di AWS Glue.
2. Cerca e seleziona il servizio S3 per accedere alla console S3.
3. Clicca su Crea un bucket per avviare la creazione di un nuovo bucket S3.

4. Ora, fornisci un nome univoco per il tuo bucket (ad esempio, sampledata54675) e seleziona la regione in cui dovrebbe trovarsi il bucket.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
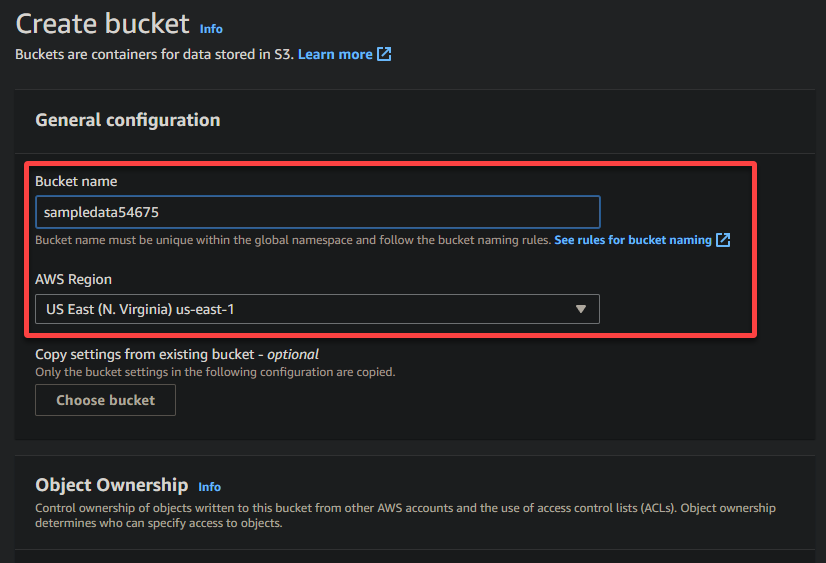
5. Scorri verso il basso, lascia le altre opzioni come sono, e clicca su Crea bucket per creare il bucket.

6. Una volta creato, clicca sull’iperlink per il bucket S3 appena creato per navigare nel bucket.

7. Clicca su Carica e individua il file di esempio che desideri caricare.
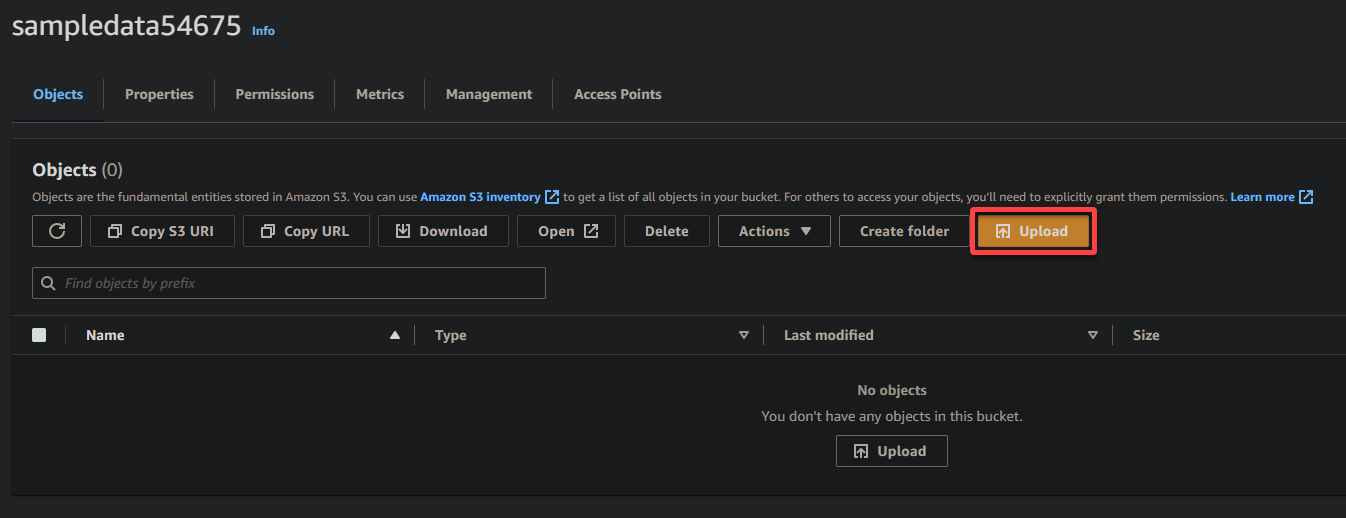
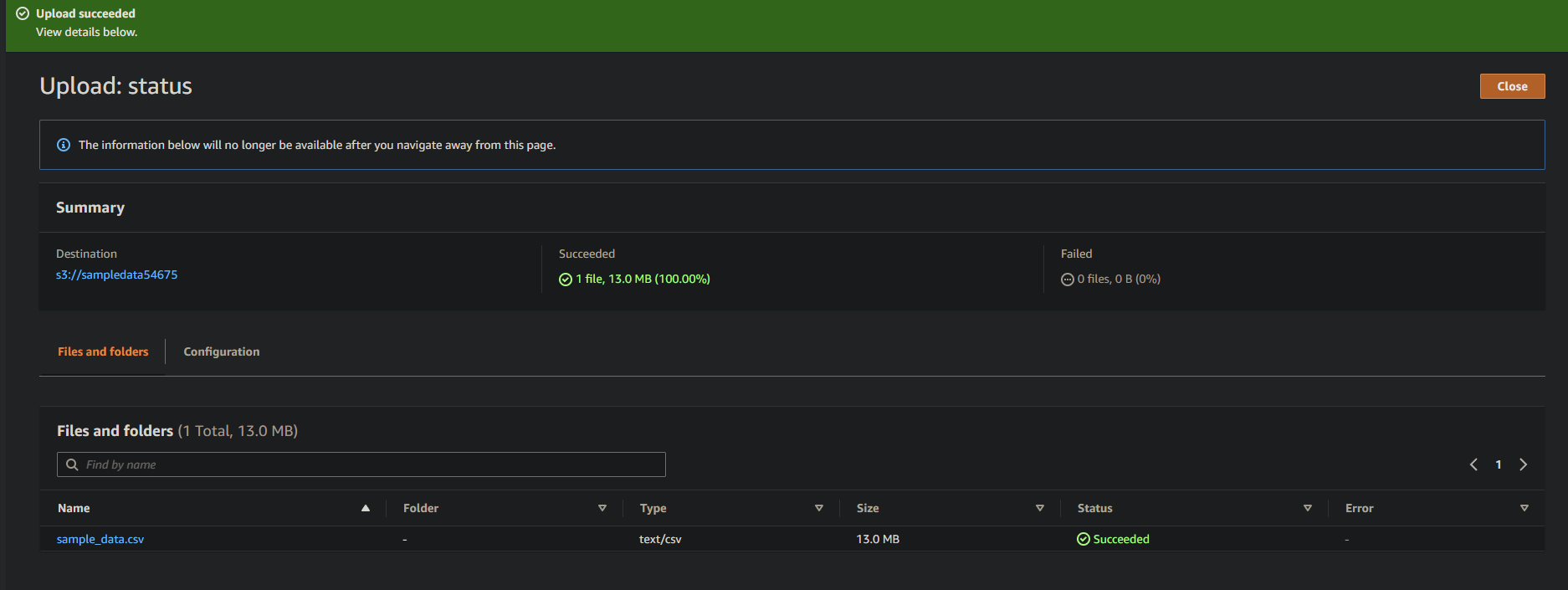
8. Infine, mantieni le altre impostazioni come sono e clicca su Carica per caricare il file di esempio nel bucket appena creato.
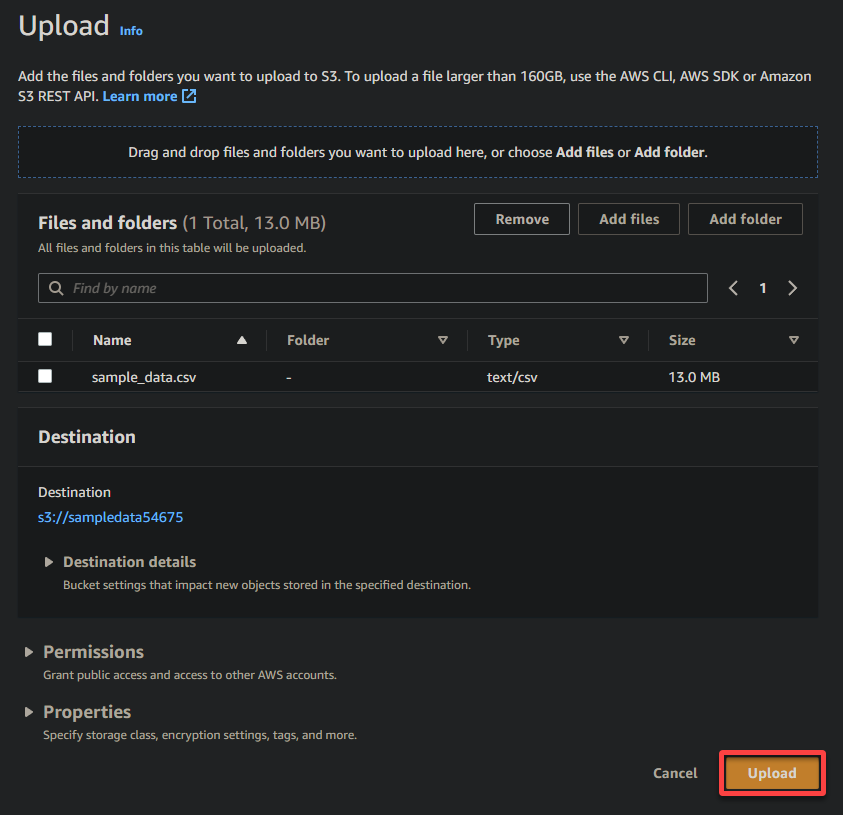
Se avrai successo, vedrai il tuo file appena caricato nel tuo bucket, come mostrato di seguito.
Creazione di un Glue Crawler per Scansionare e Catalogare i Dati
Hai appena caricato dei dati di esempio nel tuo bucket S3, ma poiché attualmente sono non strutturati, hai bisogno di un modo per leggere i dati e creare un catalogo di metadati. Come? Creando un crawler di colla che scansione e cataloga automaticamente i dati.
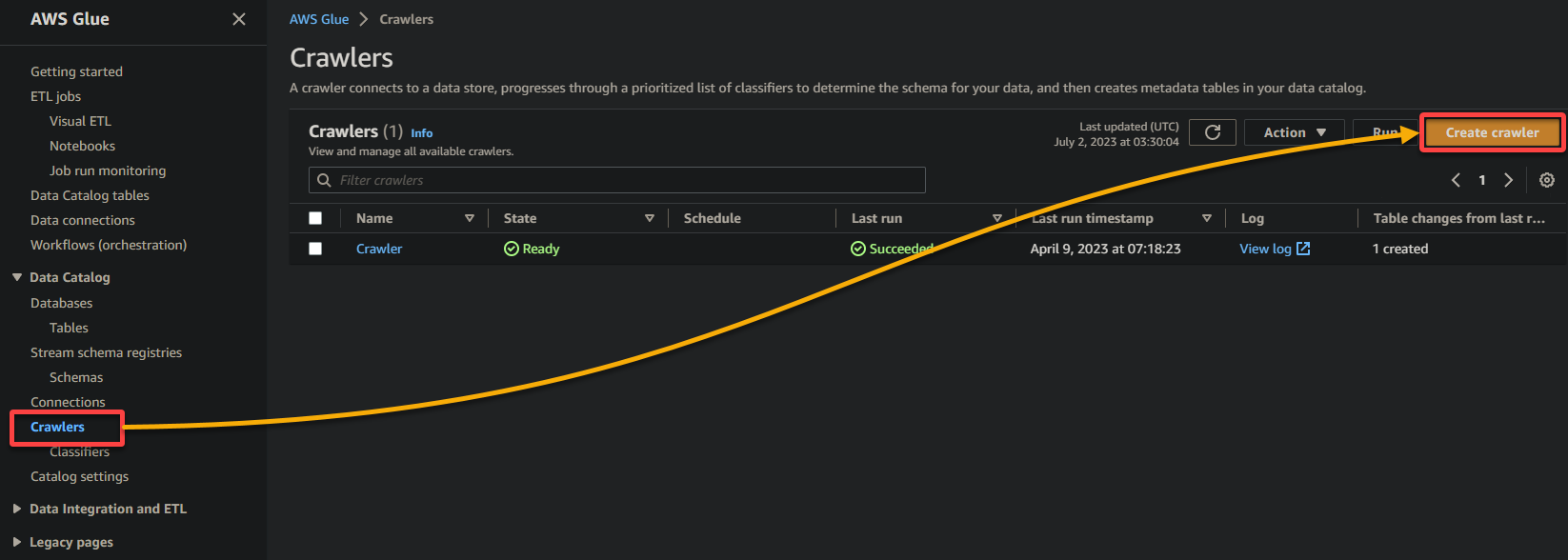
Per creare un crawler di colla, segui i passaggi di seguito:
1. Naviga nella console AWS Glue tramite la Console di Gestione AWS, come mostrato di seguito.
2. Successivamente, vai a Crawler (pannello di sinistra) e clicca su Aggiungi crawler (in alto a destra) per avviare la creazione di un nuovo crawler di colla.
3. Fornisci un nome descrittivo (ad esempio, glue_crawler) e una descrizione per il crawler, mantieni le altre impostazioni come sono, e clicca su Avanti.
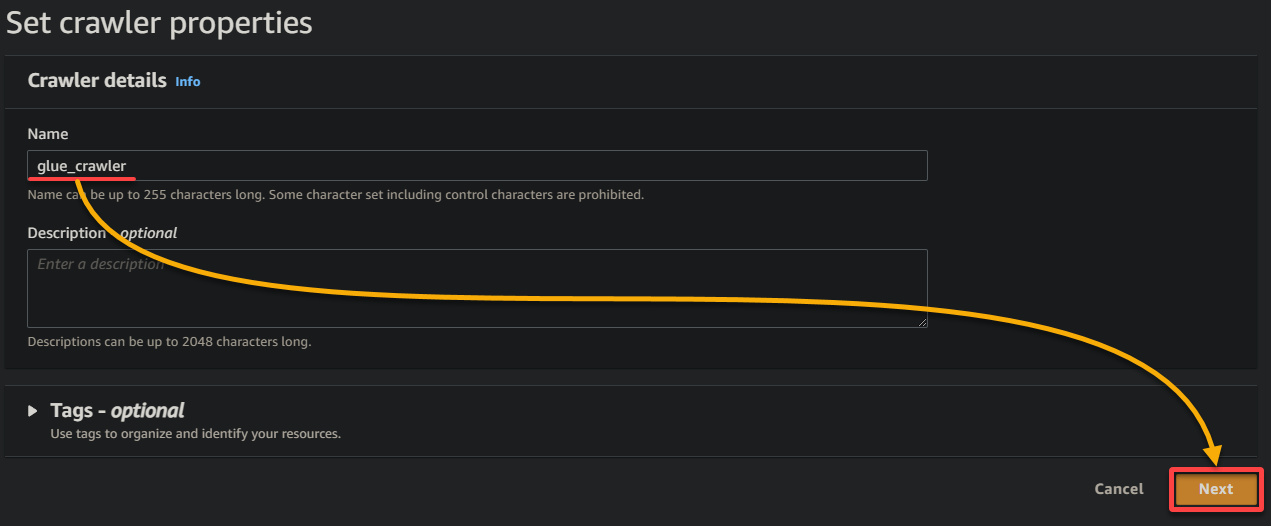
4. Ora, clicca su Aggiungi una fonte dati sotto Fonti dati per avviare l’aggiunta di una nuova fonte dati al crawler.
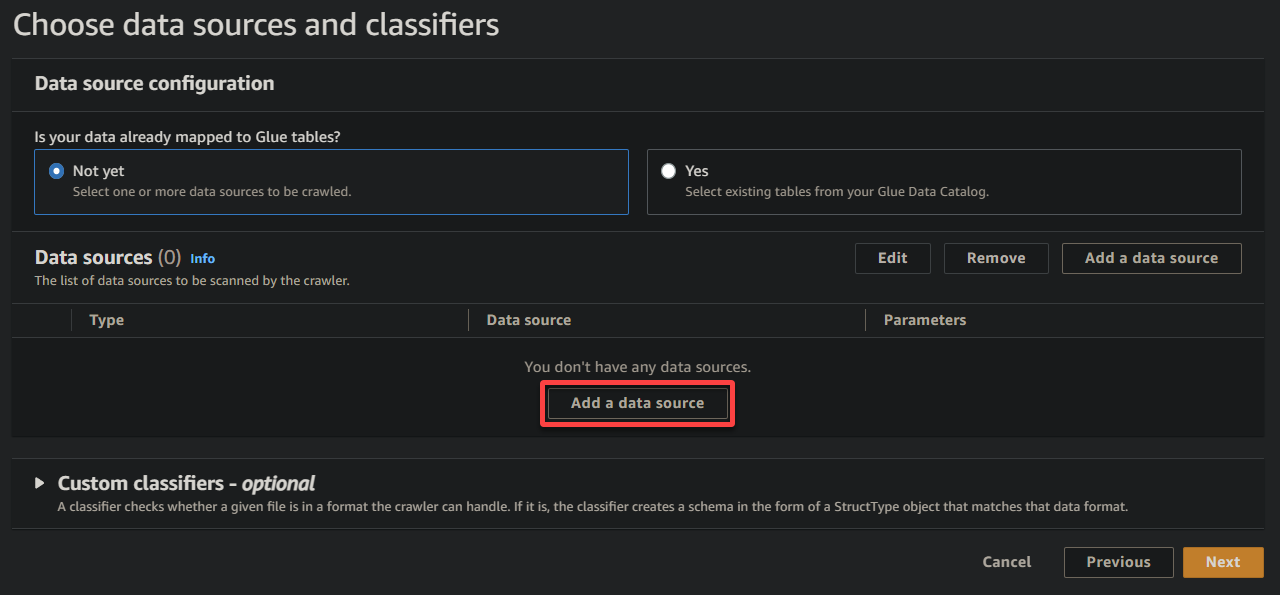
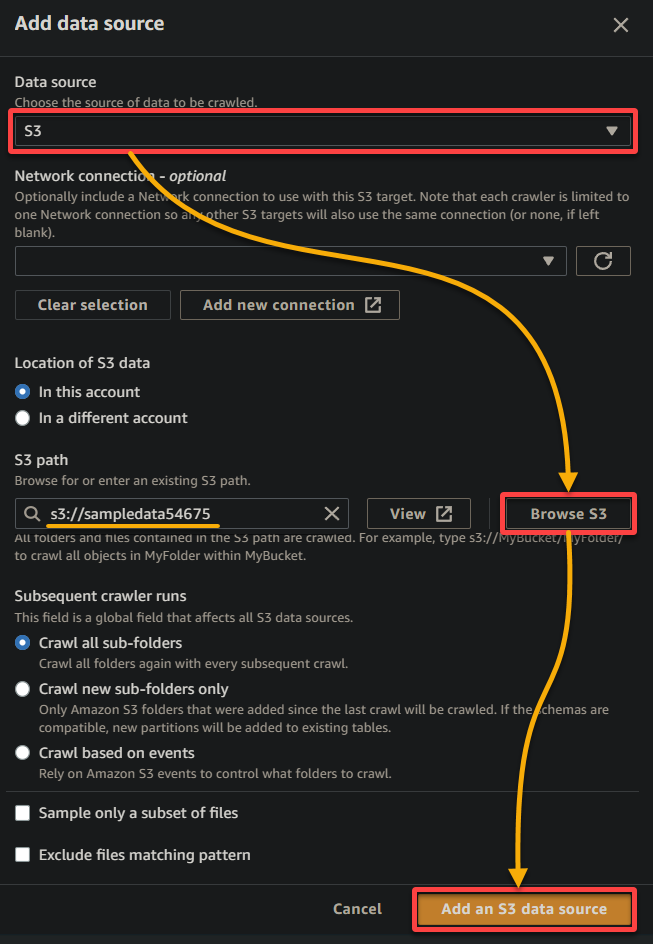
5. Nella finestra popup, configura la fonte dati come segue:
- Fonte dati – Seleziona S3 poiché i tuoi dati sono nel tuo bucket S3.
- Percorso S3 – Fai clic su Sfoglia S3 e scegli il bucket che contiene i tuoi dati di esempio caricati (sampledata54675).
- Mantieni le altre impostazioni come sono e fai clic su Aggiungi una fonte dati S3 per aggiungere i dati di esempio al crawler.
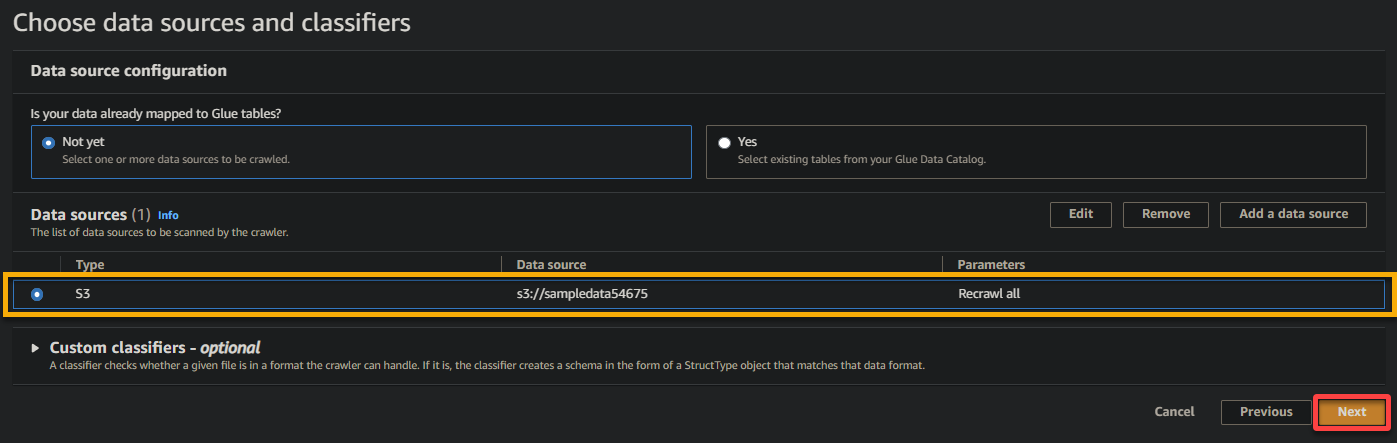
6. Una volta configurato, verifica la fonte dati, come mostrato di seguito, e fai clic su Avanti per continuare.
7. Nella schermata successiva, seleziona il ruolo IAM creato in precedenza (glue_role), mantieni le altre impostazioni come sono e fai clic su Avanti.
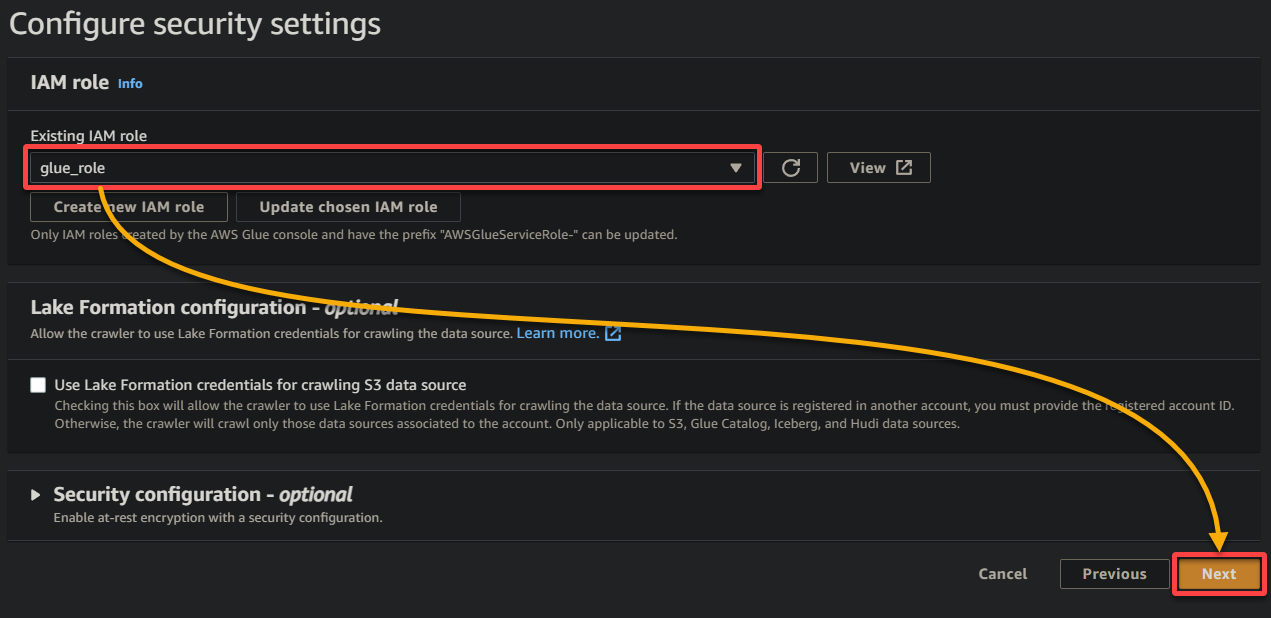
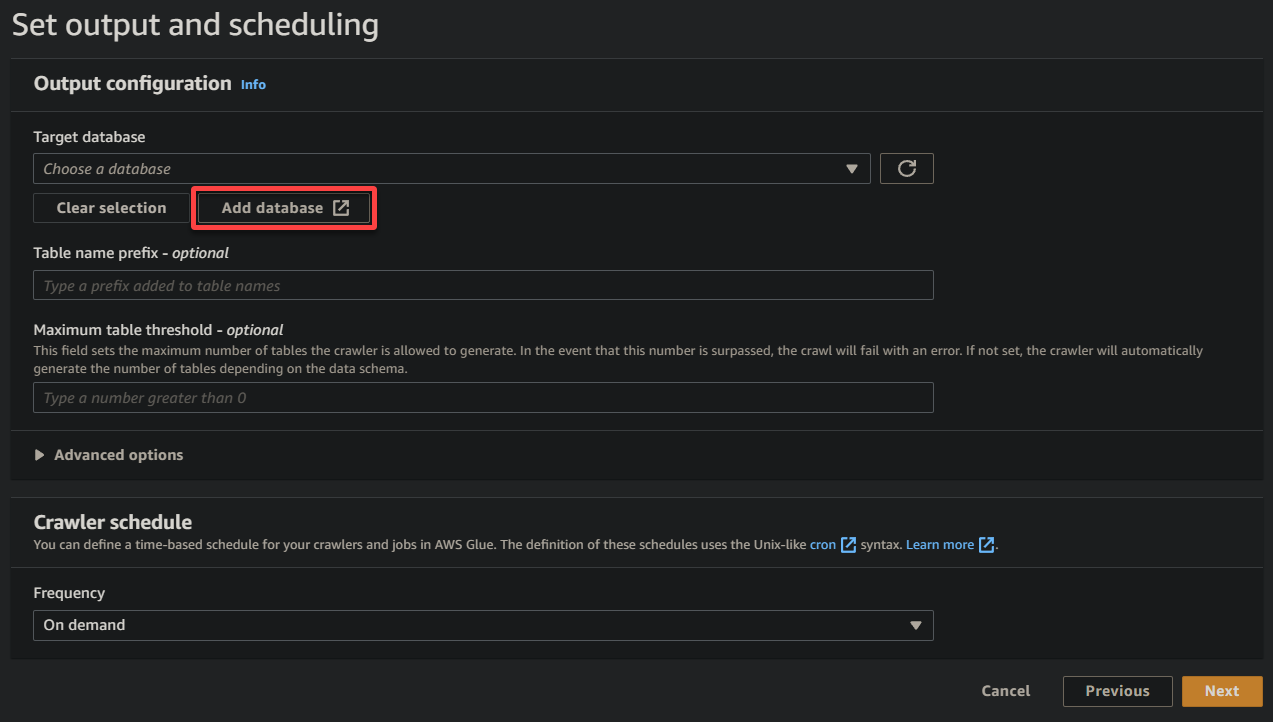
8. Sotto output e pianificazione, fai clic su Aggiungi database per avviare l’aggiunta di un nuovo database per memorizzare i dati elaborati e i metadati generati dal tuo crawler Glue. Questa azione apre una nuova scheda del browser, dove configurerai i dettagli del tuo database (passaggio otto).
Questo database fornisce una rappresentazione strutturata dei dati per interrogazioni e analisi.
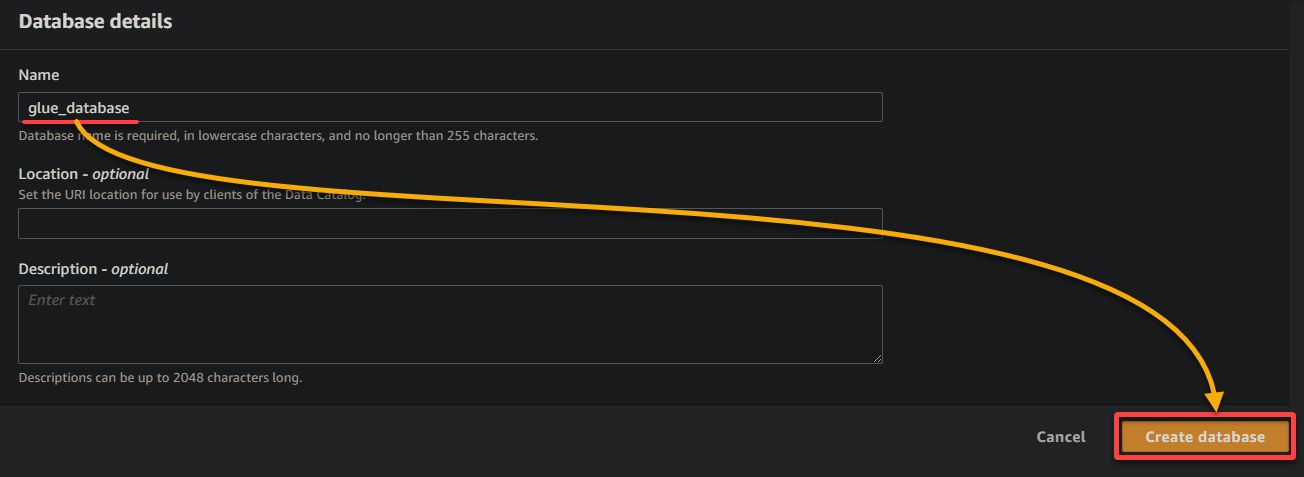
9. Nella nuova scheda del browser, fornisci un nome descrittivo per il database (ad esempio, glue_database) e fai clic su Crea database per creare il database.
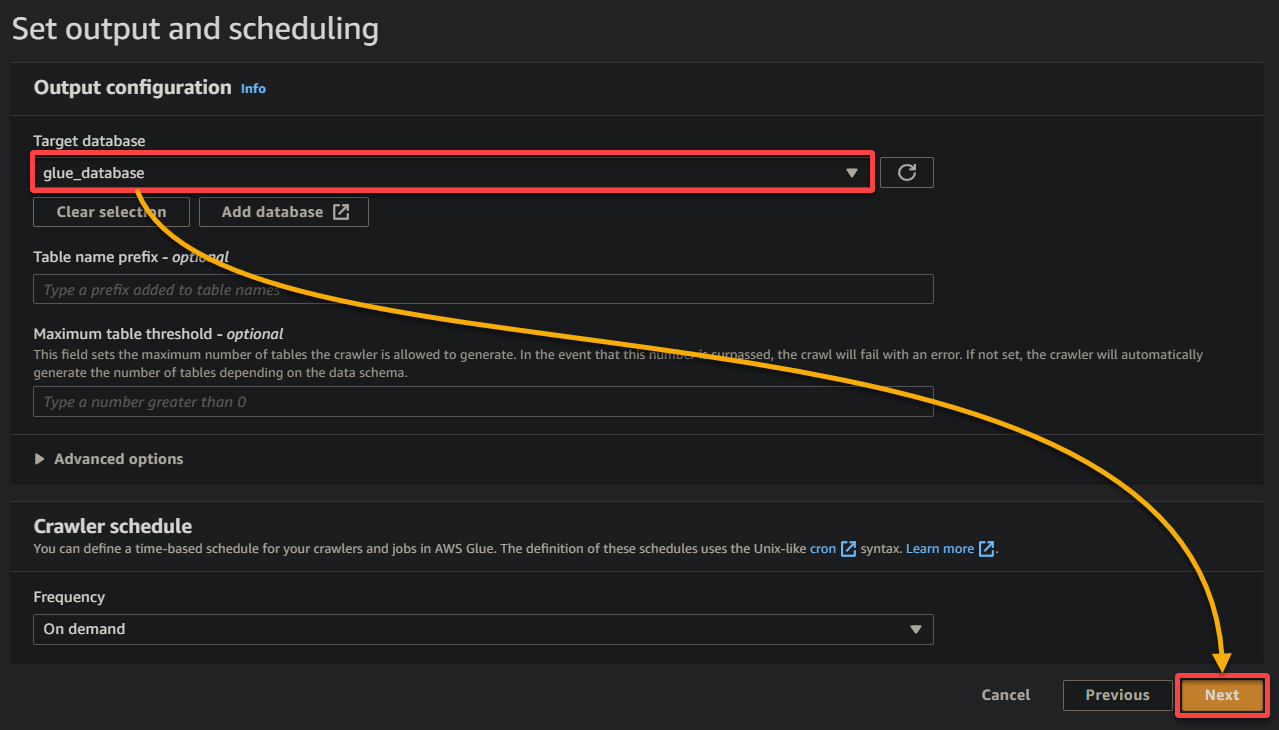
10. Torna alla scheda del browser precedente, seleziona il database appena creato (glue_database) dal menu a discesa, mantieni le altre impostazioni come sono e fai clic su Avanti.
11. Infine, rivedi le tue impostazioni nella schermata finale per assicurarti che siano corrette e fai clic su Crea crawler (in basso a destra) per creare il nuovo crawler.
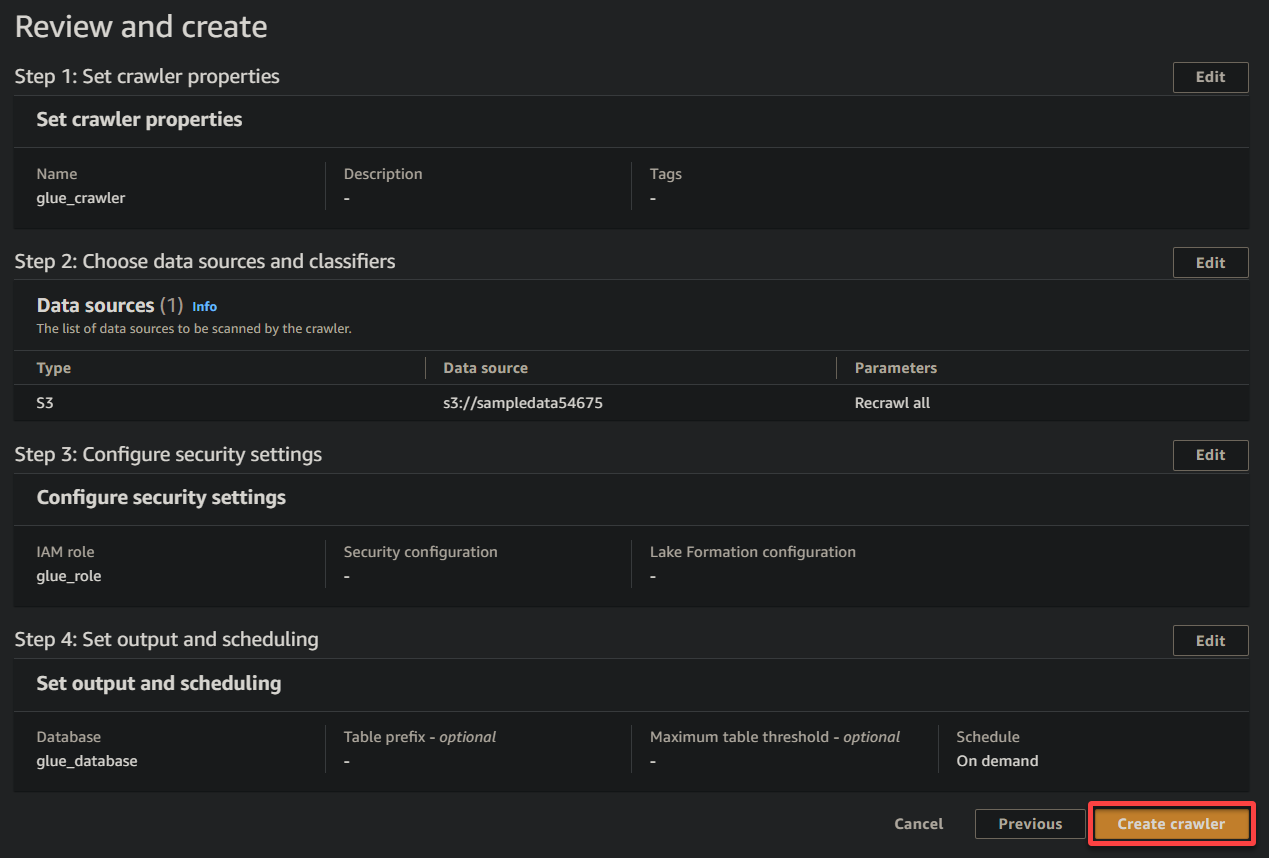
Se tutto va bene, vedrai una schermata che conferma la creazione riuscita del crawler. Non chiudere ancora questa schermata; eseguirai questo crawler nella sezione seguente.
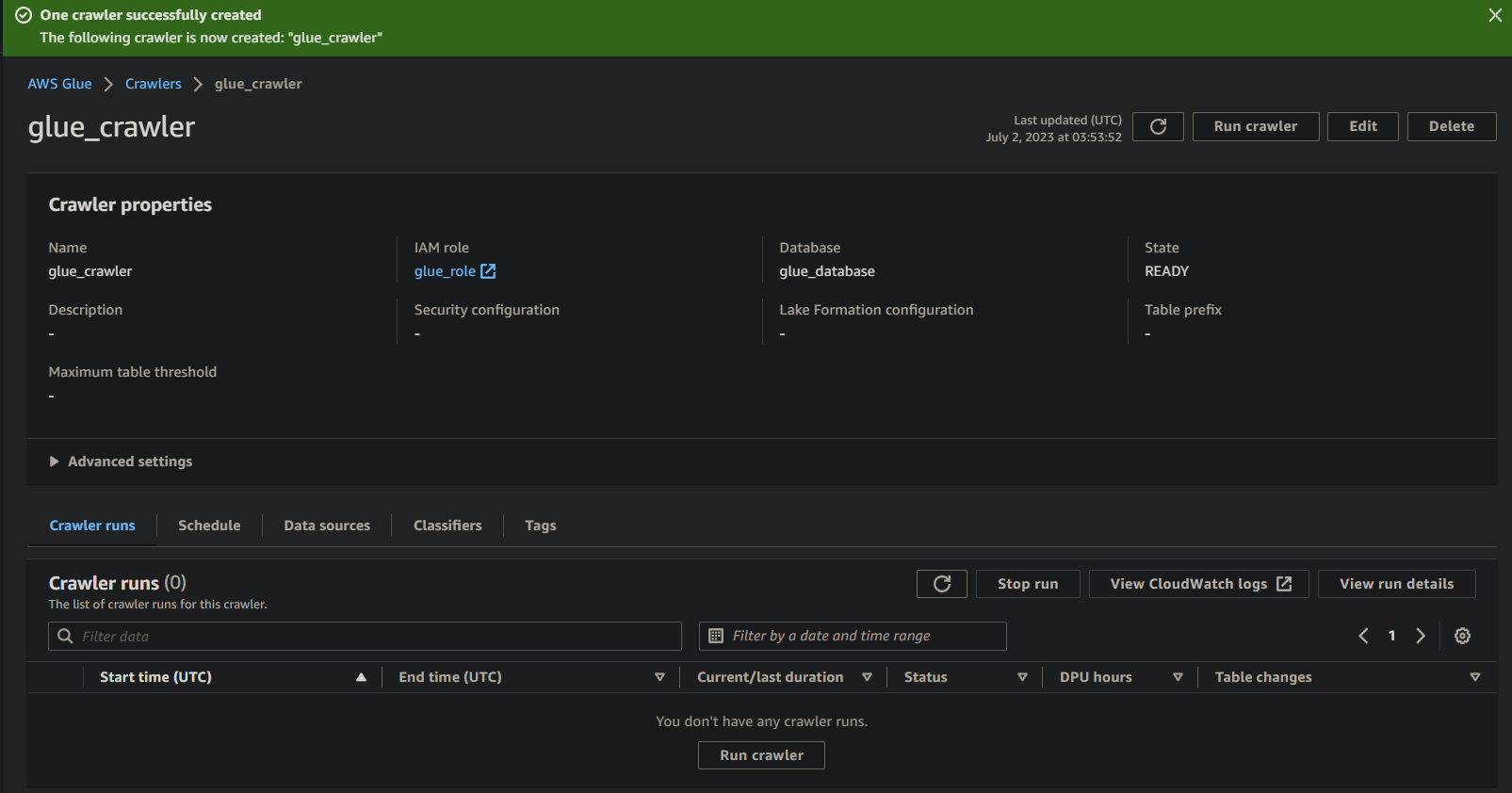
Eseguire il Glue Crawler per Creare un Catalogo Metadata
Con un nuovo crawler a tua disposizione, eseguire il crawler è essenziale per avviare il processo di scansione e catalogazione. Il tuo glue crawler creerà un catalogo metadata che fornisce una rappresentazione strutturata dei tuoi dati per scopi di interrogazione e analisi.
Per eseguire il tuo glue crawler appena creato:
1. Nella pagina dei dettagli del crawler, fare clic su Esegui crawler nella scheda Esecuzioni del crawler per avviare l’esecuzione del crawler.
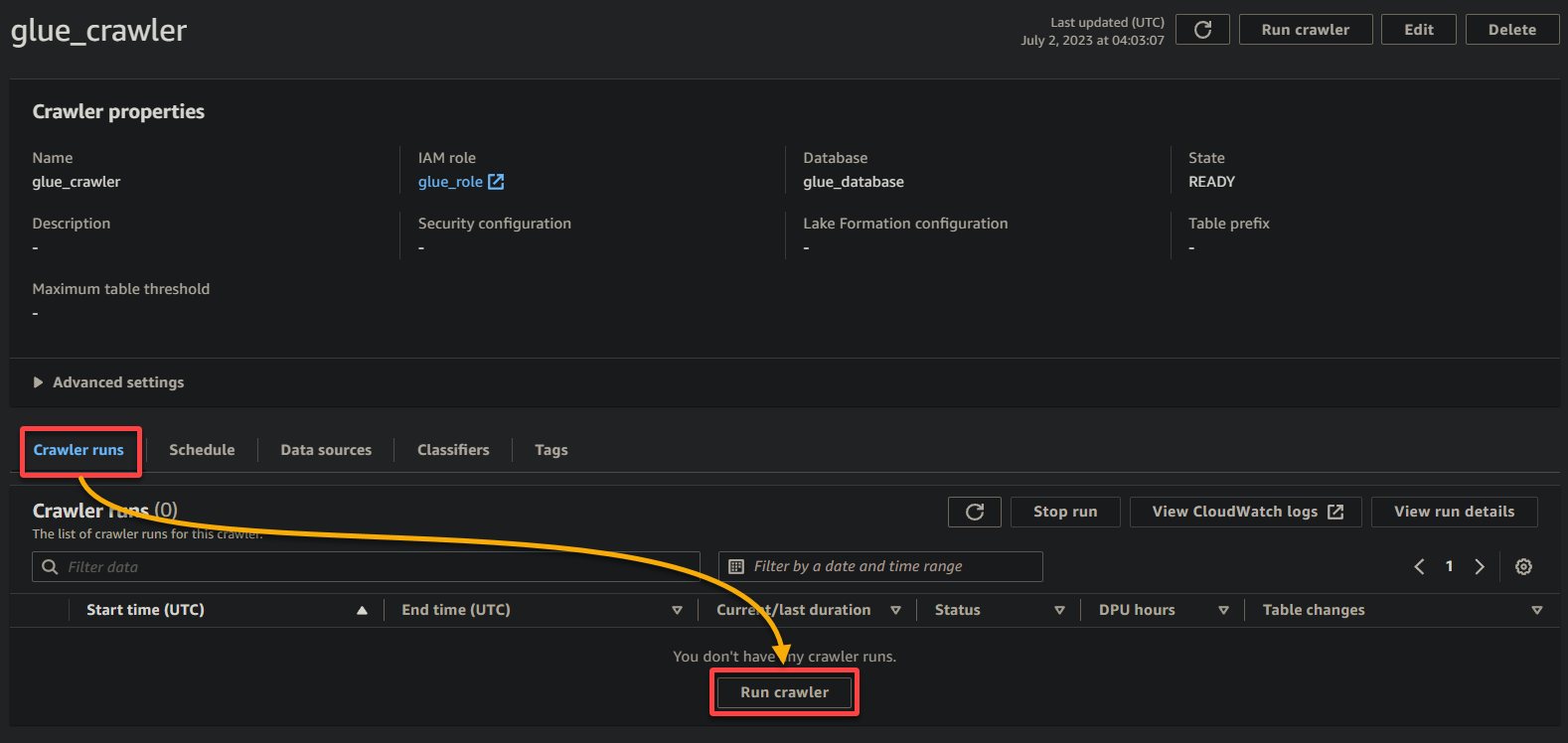
Una volta avviato il crawler, vedrai lo stato e il progresso sulla pagina dei dettagli del crawler.
A seconda delle dimensioni e della complessità dei tuoi dati, il crawler potrebbe impiegare del tempo per completare l’esecuzione. Puoi aggiornare periodicamente la pagina per vedere lo stato aggiornato del crawler.
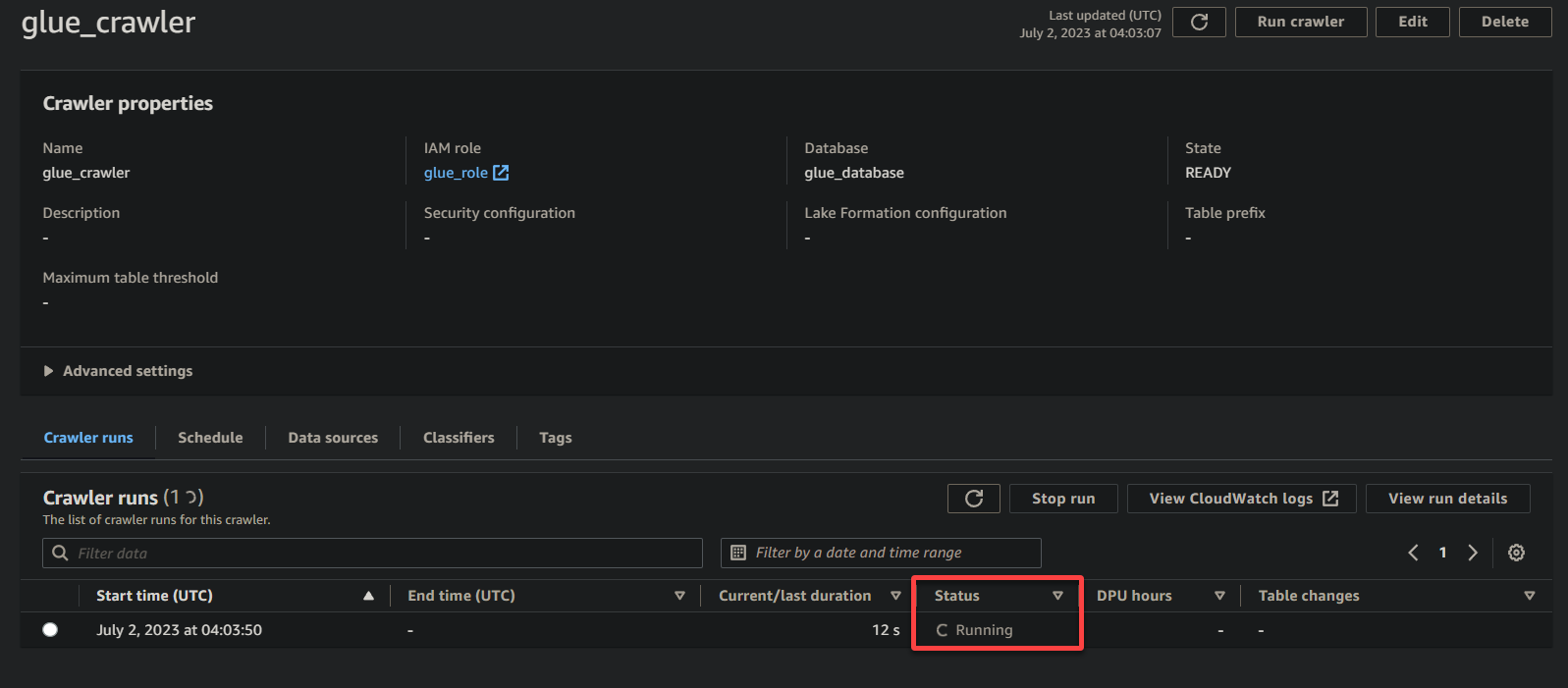
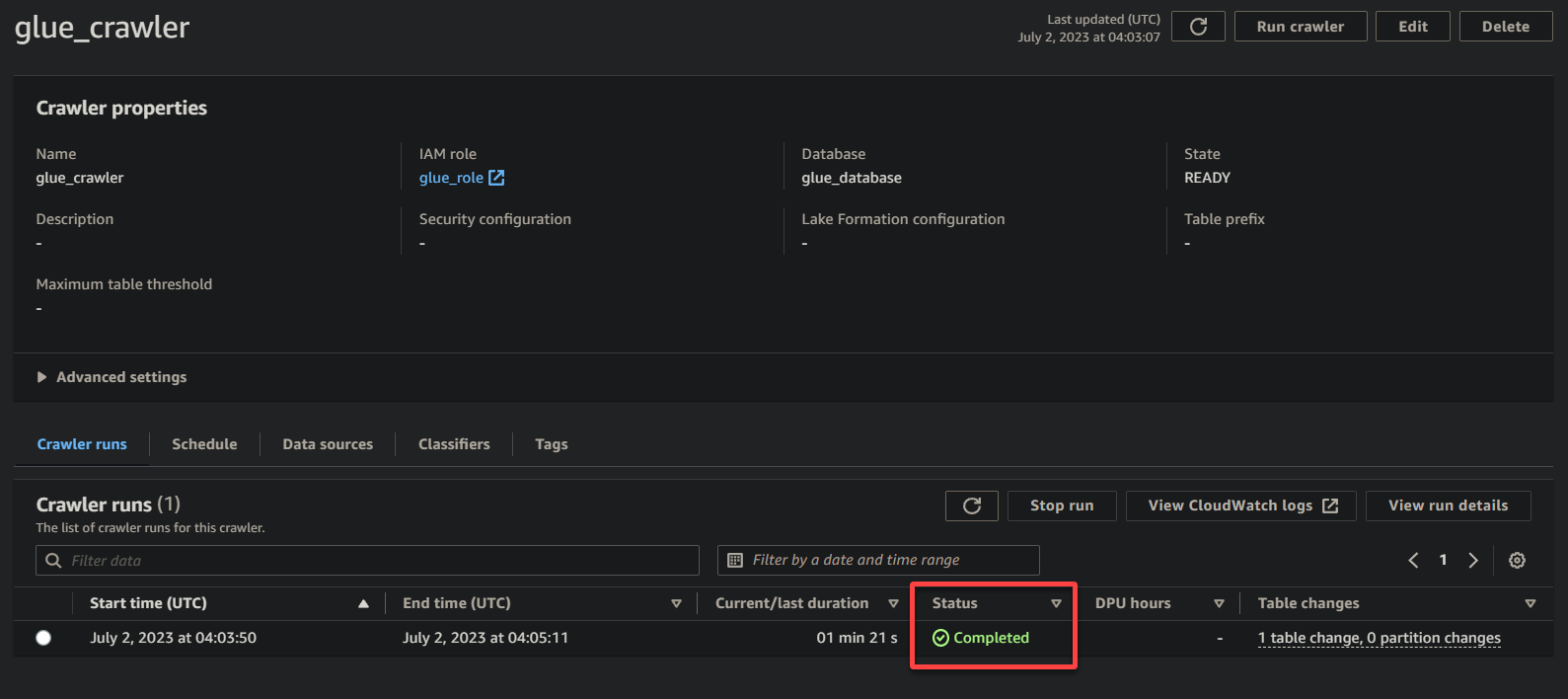
Una volta completata l’esecuzione del crawler, lo stato cambierà in Completato, come mostrato di seguito. A questo punto, puoi procedere con l’interrogazione dei tuoi dati.
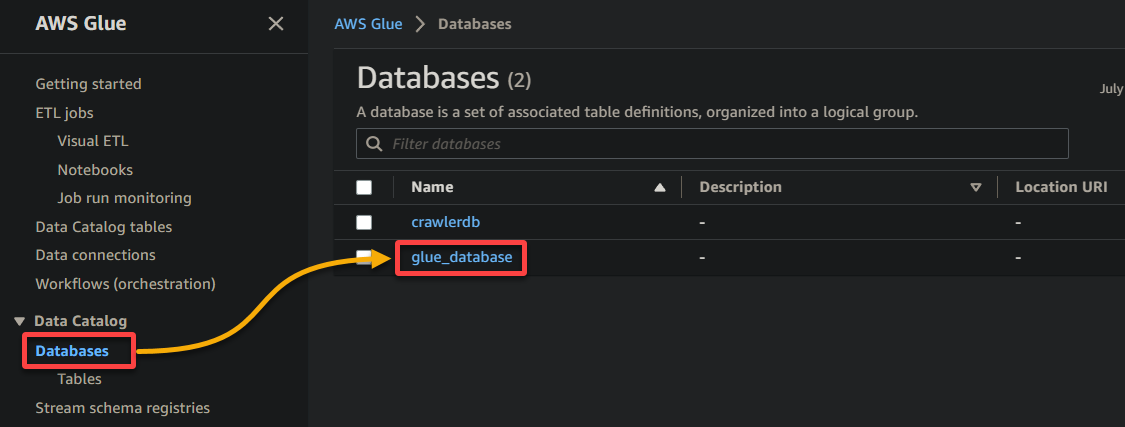
2. Successivamente, vai a Database (pannello sinistro) e fai clic sul tuo database per accedere alle sue proprietà e tabelle.
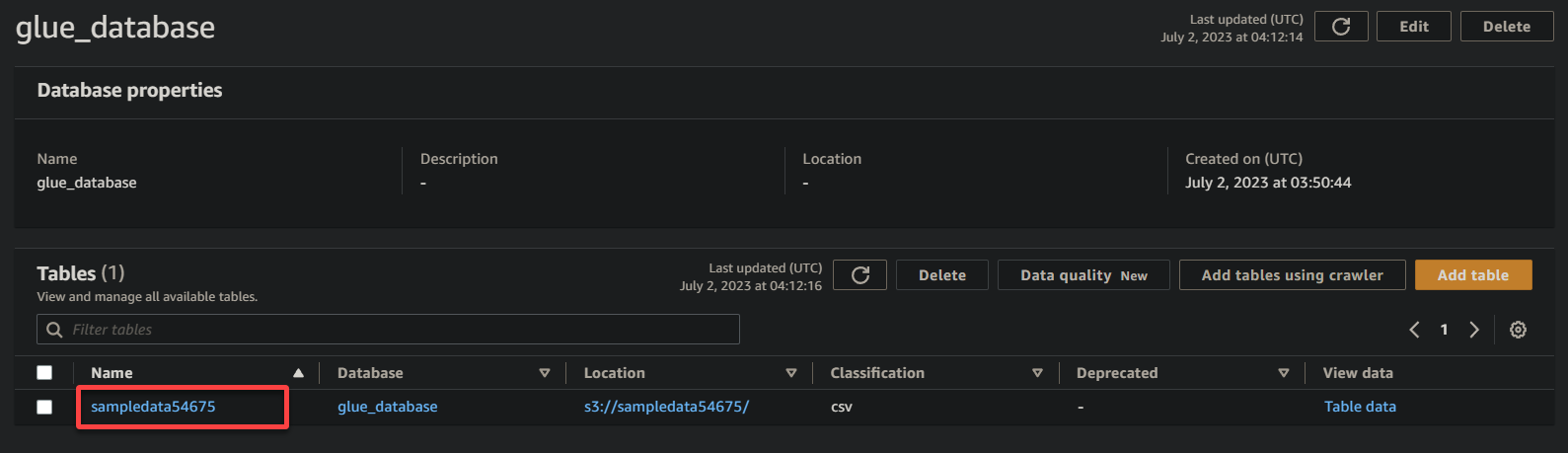
3. Infine, fai clic sul nome del tuo bucket (sampledata54675), ora una tabella, per visualizzare i dati memorizzati.
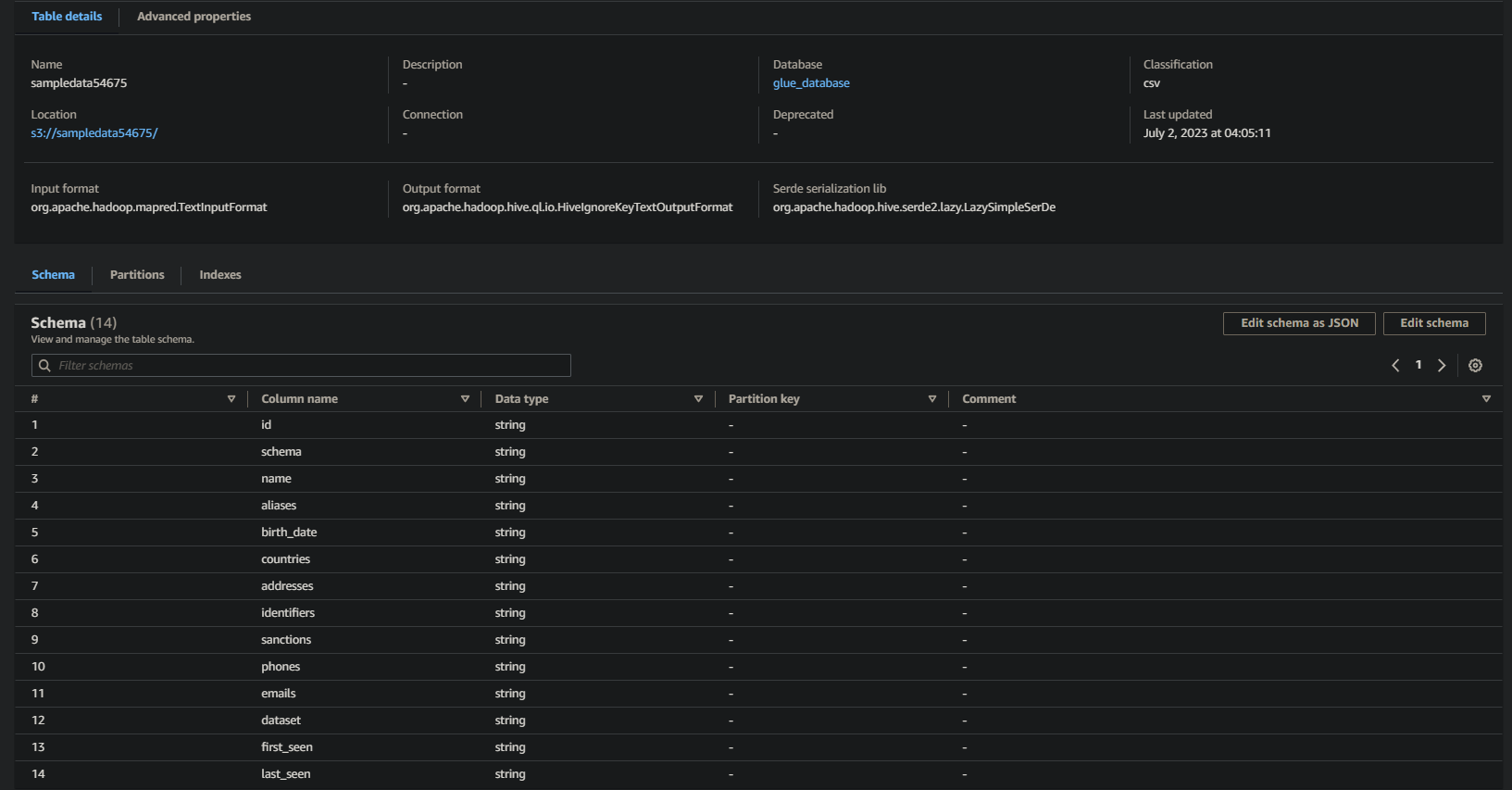
Se avrai successo, vedrai informazioni simili a quelle riportate di seguito. Queste informazioni confermano che i dati sono stati trasformati con successo nella tabella del database, fornendo dettagli preziosi.
Interrogare i Dati Catalogati tramite AWS Athena
Ora che i tuoi dati sono disponibili nel Catalogo dei dati di AWS Glue, puoi utilizzare vari strumenti per interrogare e analizzare i tuoi dati. Uno di questi strumenti è AWS Athena, un servizio di interrogazione interattivo che ti consente di analizzare i dati nel cloud utilizzando SQL standard.
Per interrogare i dati utilizzando AWS Athena, segui i passaggi seguenti:
1. Cerca e accedi alla console di Athena.
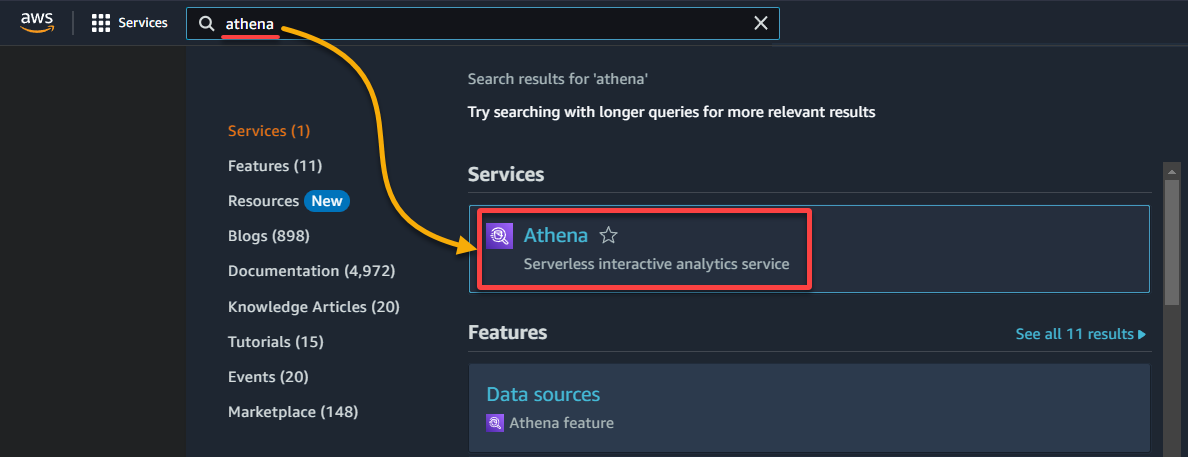
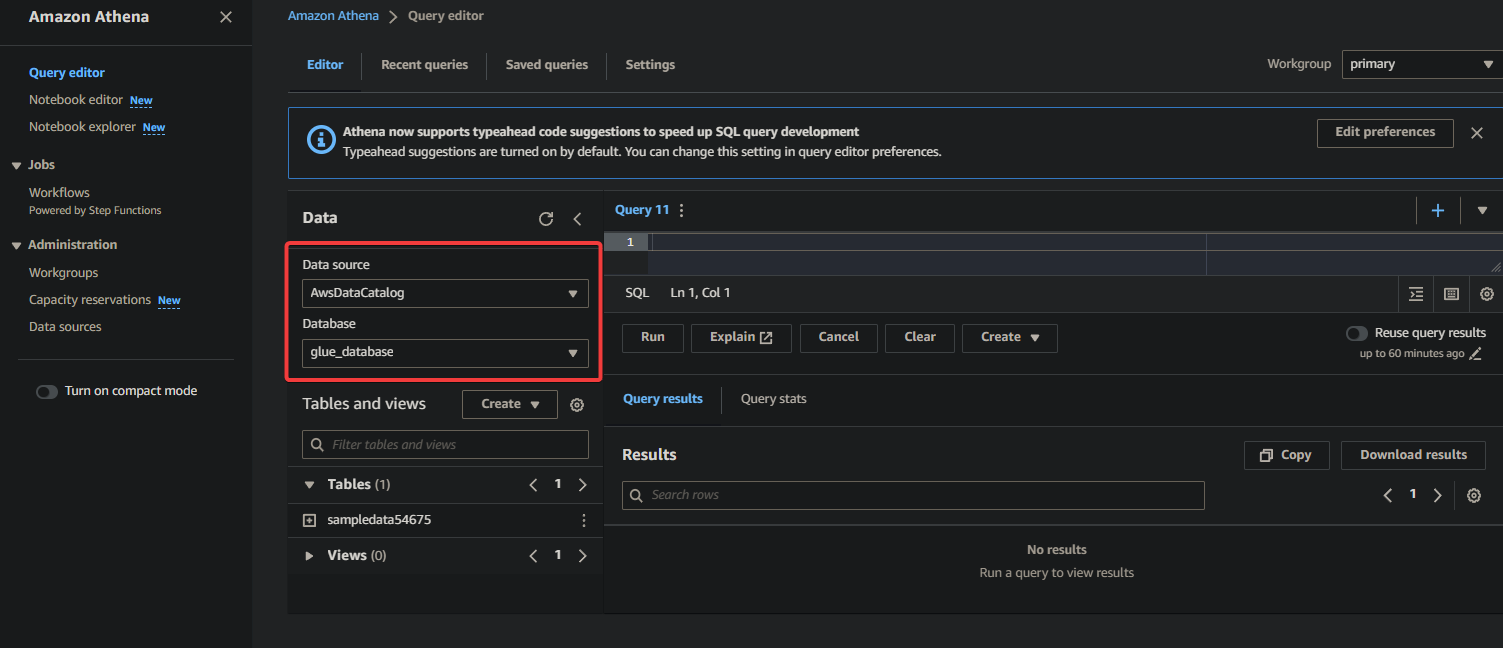
2. Seleziona il database in cui sono catalogati i tuoi dati nella sezione Dati come segue:
- Origine dati – Seleziona AwsDataCatalog per indicare che desideri interrogare i dati catalogati in AWS Glue.
- Database – Seleziona il database appropriato dal menu a discesa (ad esempio, glue_database).
? Se non vedi il database desiderato nel menu a discesa, assicurati che il crawler abbia completato la sua esecuzione e catalogato i dati.
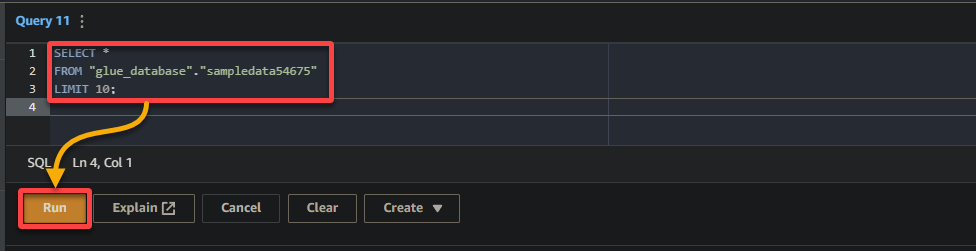
3. Infine, popola ed esegui la seguente query nell’editor di query a destra.
Questa query restituisce le prime 10 righe dalla tabella sampledata54675 nel database glue_database. Sentiti libero di modificare la query per soddisfare i tuoi requisiti specifici.
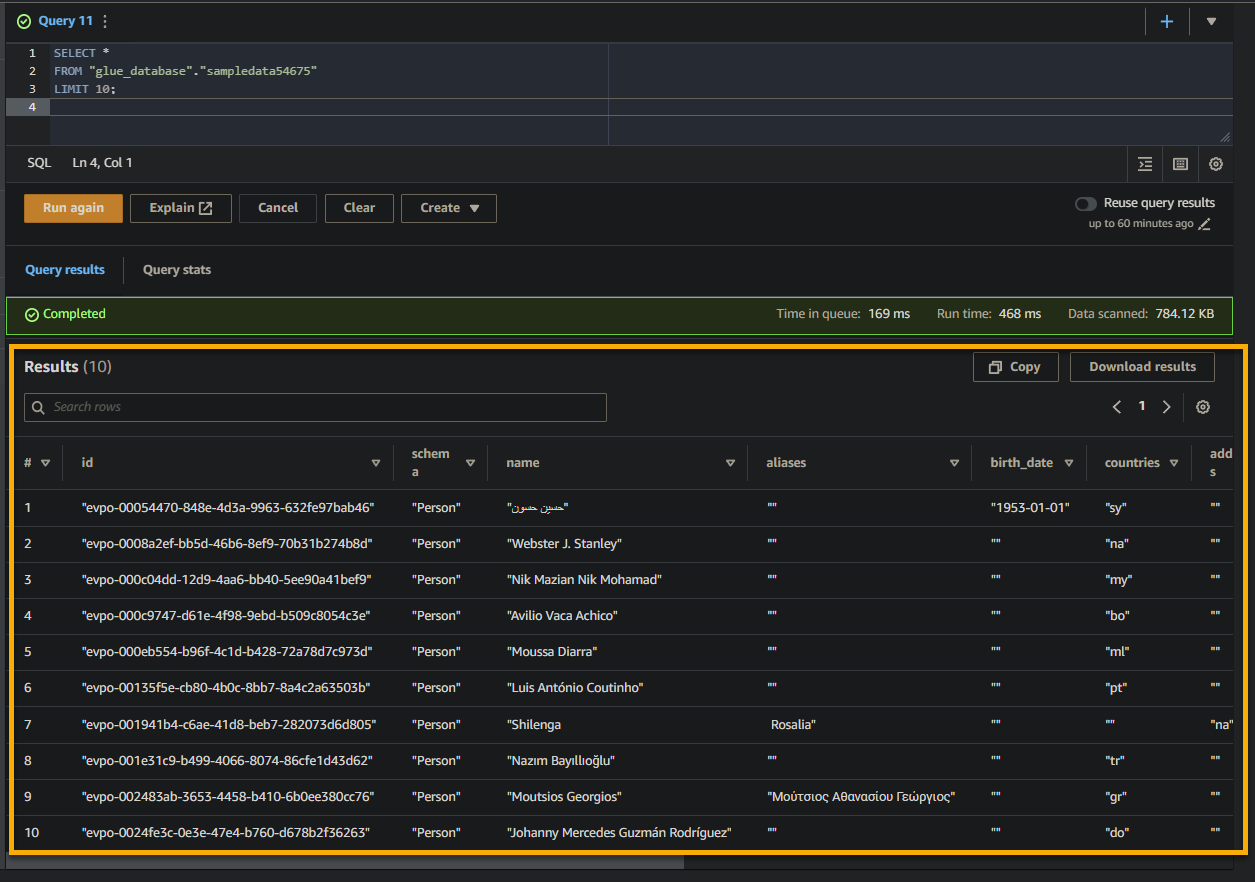
Se la query ha successo, vedrai i risultati nel riquadro Risultato, come mostrato di seguito. I risultati contengono informazioni sui record memorizzati nella tabella in base alla tua query SQL.
Fai attenzione ai nomi delle colonne, ai tipi di dati e ai valori restituiti nel set di risultati. Queste informazioni ti aiutano a comprendere la struttura e il contenuto dei dati interrogati.
Conclusione
In questo tutorial, hai imparato le basi dell’uso di AWS Glue per creare un Crawler Glue, catalogare i tuoi dati e interrogare i dati usando AWS Athena. La preparazione e l’analisi dei dati sono essenziali per qualsiasi applicazione basata sui dati. E strumenti come AWS Glue forniscono un modo rapido per estrarre, trasformare e caricare (ETL) dati da varie fonti in una tabella del database.
Con AWS Glue, puoi ora gestire e organizzare rapidamente i dati, consentendoti di concentrarti maggiormente sull’analisi e sull’ottenimento di approfondimenti dai tuoi dati. Ma quello che hai visto è solo la punta dell’iceberg. Esplora la vasta gamma di capacità e funzionalità che AWS Glue può offrire!
Perché non sfruttare le connessioni AWS Glue per integrarti senza problemi con altri servizi AWS, come Amazon RDS o Amazon Redshift? Questa integrazione ti consente di creare pipeline ETL complesse e di ottenere capacità di analisi dati ancora più elevate.