













I sistemi RAG combinano il potere dei meccanismi di ricerca e dei modelli di linguaggio, consentendo loro di generare risposte pertinenti e ben fondate in contesto. Tuttavia, valutare le prestazioni e identificare potenziali modalità di errore dei sistemi RAG può essere molto difficile.
Perciò, il Triangolo RAG – un insieme di tre metriche che forniscono i tre principali passaggi dell’esecuzione di un sistema RAG: Pertinenza del contesto, Affidabilità e Pertinenza della Risposta. In questo post del blog, esplorerò le complessità del Triangolo RAG e vi guiderò attraverso il processo di impostazione, esecuzione e analisi della valutazione di un sistema RAG.
Introduzione al Triangolo RAG:
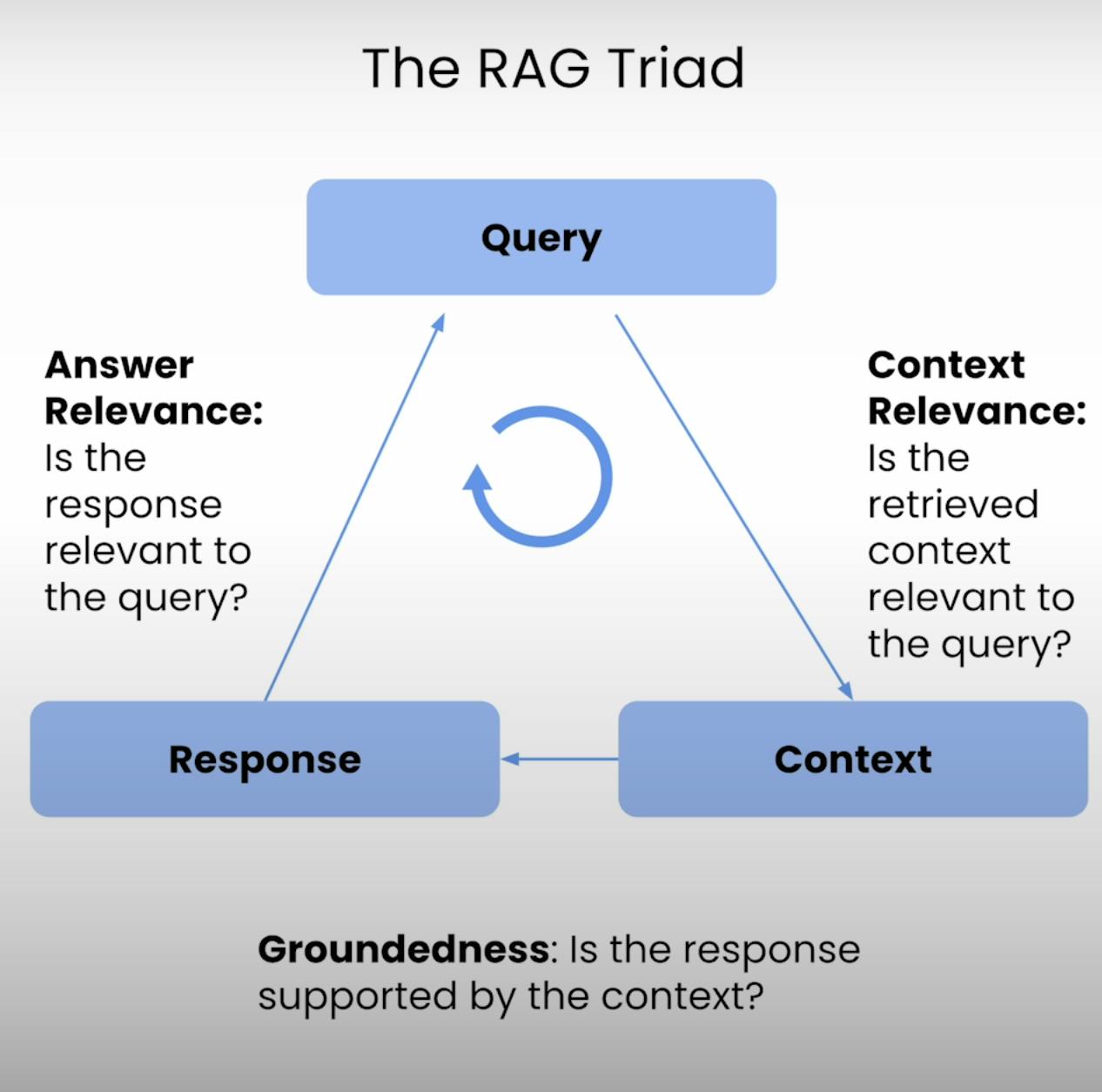
Al centro di ogni sistema RAG si trova un delicato equilibrio tra recupero e generazione. Il Triangolo RAG fornisce un quadro completo per valutare la qualità e le potenziali modalità di errore di questo delicato equilibrio. Analizziamo i tre componenti.
A. Context Relevance:
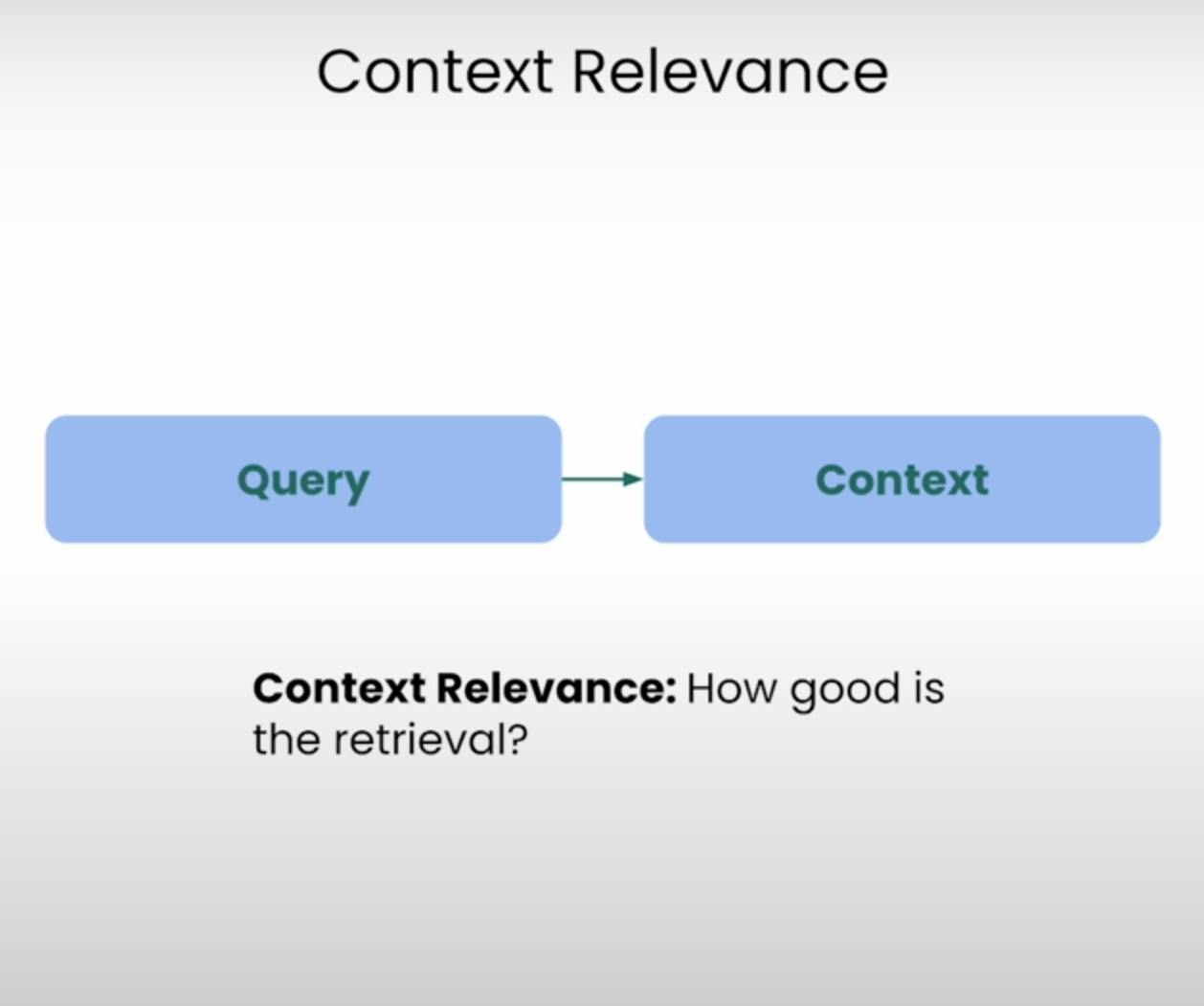
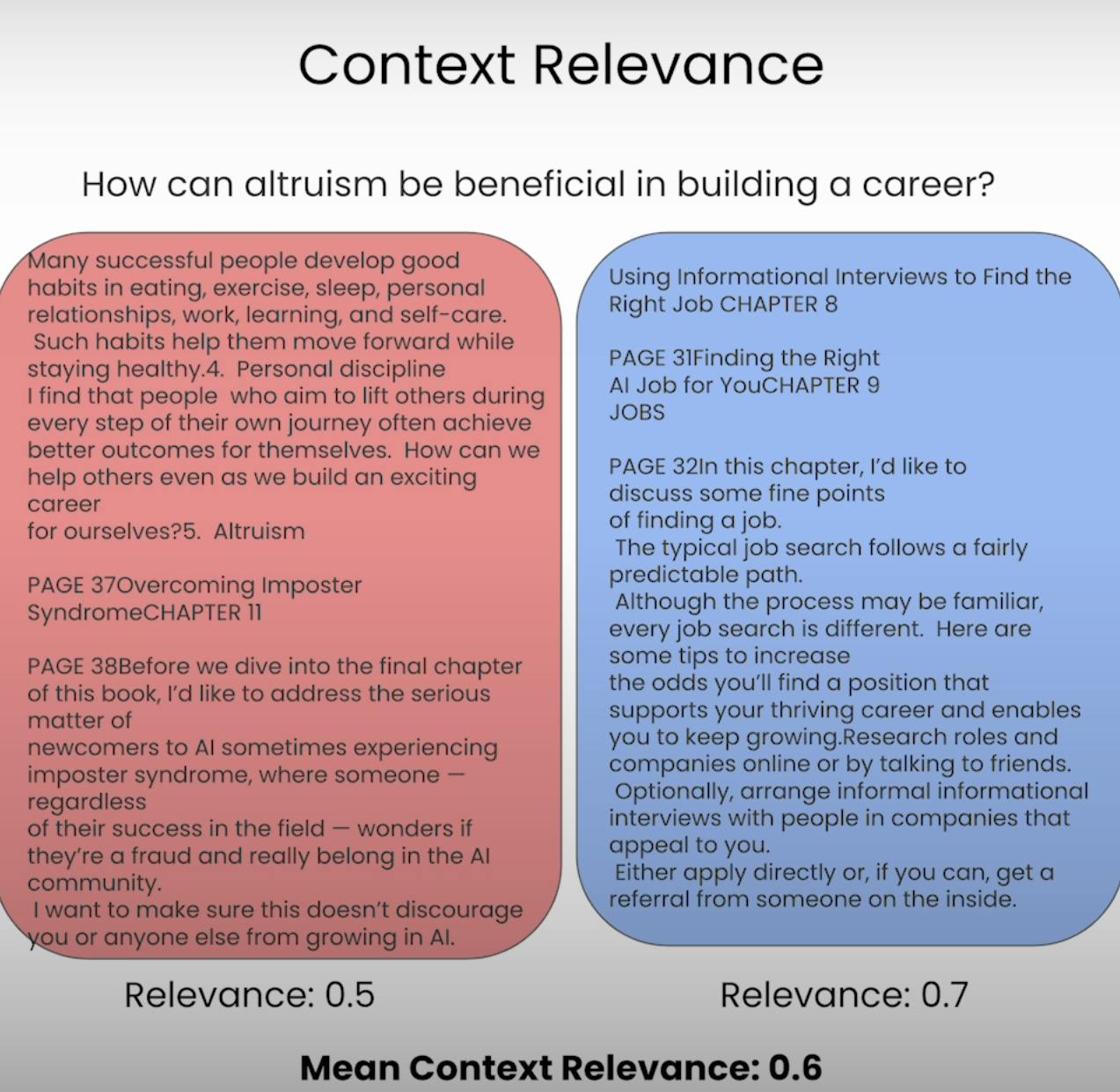
Immaginate di dover rispondere a una domanda, ma le informazioni che vi sono state fornite sono completamente irrilevanti. Questo è esattamente ciò che un sistema RAG cerca di evitare. La Pertinenza del Contest

B. Groundedness:
Hai mai avuto una conversazione in cui qualcuno sembrava inventare fatti o fornire informazioni senza una solida base? Questo equivale a un sistema RAG che manca di fondatezza. La fondatezza valuta se la risposta finale generata dal sistema è ben fondata nel contesto recuperato. Se la risposta contiene dichiarazioni o affermazioni che non sono supportate dalle informazioni recuperate, il sistema potrebbe essere soggetto a allucinazioni o essere troppo dipendente dai dati di pre-addestramento, portando a potenziali inesattezze o bias.
C. Answer Relevance:
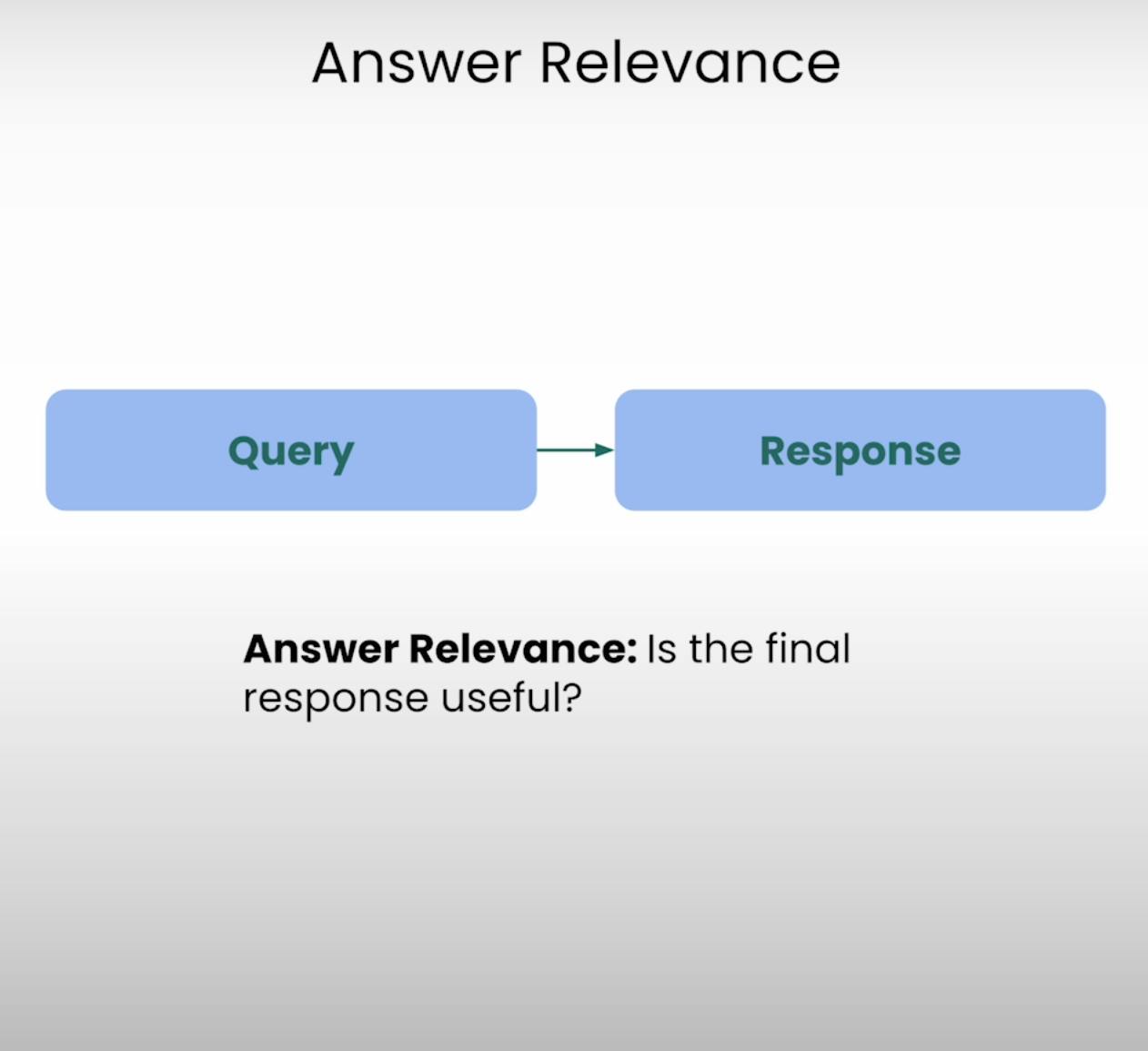
Immagina di chiedere indicazioni per il bar più vicino e ricevere una ricetta dettagliata per cuocere una torta. Questa è la situazione che Answer Relevance mira a prevenire. Questo componente del Triangolo RAG valuta se la risposta finale generata dal sistema è veramente rilevante per la query originale. Valutando la rilevanza della risposta, possiamo identificare casi in cui il sistema potrebbe aver frainteso la domanda o deviato dall’argomento previsto.

Configurazione della Valutazione del Triangolo RAG
Prima di poter approfondire il processo di valutazione, dobbiamo stabilire le basi. Passiamo attraverso i necessari passaggi per configurare la valutazione del Triangolo RAG.
A. Importing Libraries and Establishing API Keys:
Per prima cosa, dobbiamo importare le librerie e i moduli richiesti, inclusa la chiave API di OpenAI e il provider LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
Successivamente, carichiamo e indichiamo il corpus di documenti con cui lavorerà il nostro sistema RAG. In questo caso, utilizzeremo un documento PDF su “Come Costruire una Carriera nell’AI” di Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

Al centro dell’evaluazione del Triangolo RAG ci sono le funzioni di feedback – funzioni specializzate che valutano ogni componente del triangolo. Definiamo queste funzioni utilizzando la libreria TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Esecuzione dell’Applicazione e Valutazione RAG
Con il setup completo, è ora di mettere in azione il nostro sistema RAG e il framework di valutazione. Passiamo attraverso i passaggi coinvolti nell’esecuzione dell’applicazione e nella registrazione dei risultati della valutazione.
A. Preparing the Evaluation Questions:
In primo luogo, carichiamo un set di domande di valutazione che vogliamo che il nostro sistema RAG risponda. Queste domande serviranno come base per il nostro processo di valutazione.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Successivamente, configuriamo il registratore TruLens, che ci aiuterà a registrare i prompt, le risposte e i risultati della valutazione in un database locale.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
Mentre l’applicazione RAG viene eseguita su ogni domanda di valutazione, il registratore TruLens catturerà diligentemente i prompt, le risposte, i risultati intermedi e i punteggi di valutazione, memorizzandoli in un database locale per ulteriori analisi.
Analisi dei Risultati della Valutazione
Con i dati di valutazione a portata di mano, è ora di indagare l’analisi e ottenere le intuizioni. Esaminiamo vari modi in cui possiamo analizzare i risultati e identificare potenziali aree di miglioramento.
A. Examining Individual Record-Level Results:
A volte, il diavolo è nei dettagli. Esaminando i risultati a livello di record individuale, possiamo acquisire una comprensione più profonda dei punti di forza e di debolezza del nostro sistema RAG.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Questo frammento di codice ci fornisce accesso ai prompt, alle risposte e ai punteggi di valutazione per ogni record individuale, consentendoci di identificare specifici casi in cui il sistema potrebbe aver lottato o eccelso.
B. Viewing Aggregate Performance Metrics:
Riprendiamo un passo indietro e osserviamo il quadro d’insieme. La libreria TrueLens ci fornisce una classifica che aggrega le metriche di prestazione su tutti i record, offrendoci una visione di alto livello delle prestazioni complessive del nostro sistema RAG.
tru.get_leaderboard(app_ids=[])
Questa classifica mostra i punteggi medi per ciascuna componente del Triangolo RAG, insieme a metriche come latenza e costo. Analizzando queste metriche aggregate, possiamo identificare tendenze e pattern che potrebbero non essere evidenti a livello di record.
C. Exploring the TrueLens Streamlit Dashboard:
Oltre al CLI, TrueLens offre anche un dashboard Streamlit che fornisce un’interfaccia grafica per esplorare e analizzare i risultati dell’analisi. Con pochi semplici comandi, possiamo avviare il dashboard.
tru.run_dashboard()
Una volta che il dashboard è in funzione, vediamo una panoramica completa delle prestazioni del nostro sistema RAG. Ad una semplice occhiata, possiamo vedere le metriche aggregate per ciascuna componente del Triangolo RAG, nonché informazioni sulla latenza e sui costi.
Selezionando il nostro applicativo dall’elenco a discesa, possiamo accedere a una visualizzazione dettagliata a livello di record dei risultati dell’analisi. Ogni record è chiaramente presentato, completo del prompt dell’utente, della risposta del sistema RAG e dei corrispondenti punteggi per Relevanza della Risposta, Relevanza del Contesto e Affidamento.
Cliccando su un record individuale si rivelano ulteriori spunti. Possiamo esplorare la catena di ragionamento alla base di ogni punteggio di valutazione, spiegando il processo di pensiero del modello linguistico che esegue l’analisi. Questo livello di trasparenza è utile per identificare potenziali modi di fallimento e aree di miglioramento.
Supponiamo di trovare una registrazione in cui il punteggio di Groundedness è basso. Osservando i dettagli, potremmo scoprire che la risposta del sistema RAG contiene affermazioni che non sono ben fondate nel contesto recuperato. Il dashboard ci mostrerà esattamente quali affermazioni mancano di prove a sostegno, consentendoci di identificare la causa principale del problema.
Il dashboard TrueLens Streamlit è più di un semplice strumento di visualizzazione. Utilizzando le sue capacità interattive e le intuizioni guidate dai dati, possiamo prendere decisioni informate e adottare azioni mirate per migliorare le prestazioni delle nostre applicazioni.
Tecniche RAG Avanzate e Miglioramento Iterativo
A. Introducing the Sentence Window RAG Technique:
Una tecnica avanzata è il Sentence Window RAG, che affronta un modo comune di fallimento dei sistemi RAG: dimensione del contesto limitata. Aumentando la dimensione della finestra di contesto, il Sentence Window RAG mira a fornire al modello linguistico informazioni più rilevanti e complete, potenzialmente migliorando la Relevanza del Contesto e la Groundedness del sistema.
B. Re-evaluating with the RAG Triad:
Dopo aver implementato la tecnica del Sentence Window RAG, possiamo metterla alla prova rivalutandola utilizzando lo stesso framework RAG Triad. Questa volta, ci concentreremo sui punteggi di Relevanza del Contesto e Groundedness, cercando miglioramenti in queste aree a seguito dell’aumento della dimensione del contesto.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Mentre la tecnica del Sentence Window RAG può potenzialmente migliorare le prestazioni, la dimensione ottimale della finestra può variare a seconda del caso d’uso specifico e del dataset. Una finestra troppo piccola potrebbe non fornire abbastanza contesto rilevante, mentre una finestra troppo grande potrebbe introdurre informazioni irrilevanti, influenzando la Groundedness e la Relevanza delle Risposte del sistema.
Sperimentando con dimensioni diverse delle finestre e ri-valutando utilizzando il Triangolo RAG, possiamo trovare il punto dolce che bilancia la pertinenza del contesto con il radicamento e la pertinenza delle risposte, portando a un sistema RAG più robusto e affidabile.
Conclusione:
Il Triangolo RAG, composto da Pertinenza del Contesto, Radicamento e Pertinenza delle Risposte, si è dimostrato un quadro utile per valutare le prestazioni e identificare potenziali modalità di fallimento dei sistemi di Generazione Potenziata tramite Ricerca.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems