













Vuole la direzione della tua azienda sapere tutto sulle finanze e sulla produttività della tua azienda ma non vuole spendere un centesimo per strumenti di gestione IT di alta qualità? Non finire per rivolgerti a strumenti diversi per inventario, fatturazione e sistemi di ticketing. Hai bisogno solo di un sistema centrale. Perché non considerare Power BI Python?
Power BI può trasformare compiti noiosi e cronometrati in un processo automatizzato. E in questo tutorial, imparerai come suddividere e combinare i tuoi dati in modi che non avresti potuto immaginare.
Dai, risparmia lo stress di guardare attraverso report complessi!
Prerequisiti
Questo tutorial sarà una dimostrazione pratica. Se desideri seguirla, assicurati di avere quanto segue:
- Abbonamento Power BI – La prova gratuita sarà sufficiente.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop installato sul tuo server Windows – Questo tutorial utilizza Power BI Desktop v2.105.664.0.
- Server MySQL installato – Questo tutorial utilizza MySQL Server v8.0.29.
- Un gateway dati in locale installato su dispositivi esterni che intendono utilizzare una versione Desktop.
- Visual Studio Code (VS Code) – Questo tutorial utilizza VS Code v17.2
- Python v3.6 o successivo installato – Questo tutorial utilizza Python v3.10.5.
- DBeaver installato – Questo tutorial utilizza DBeaver v22.0.2.
Costruzione di un Database MySQL
Power BI può visualizzare i dati in modo splendido, ma è necessario recuperarli e memorizzarli prima di arrivare alla visualizzazione dei dati. Uno dei modi migliori per memorizzare i dati è in un database. MySQL è uno strumento di database gratuito e potente.
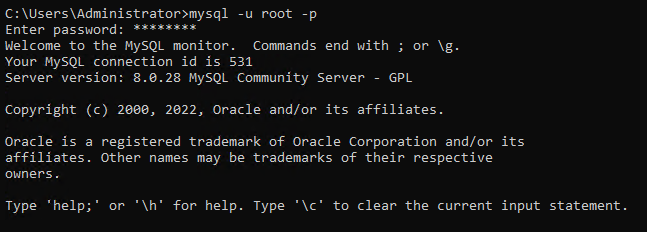
1. Apri il prompt dei comandi come amministratore, esegui il comando mysql di seguito e inserisci il nome utente root (-u) e la password (-p) quando richiesto.
Per impostazione predefinita, solo l’utente root ha il permesso di apportare modifiche al database.
2. Successivamente, esegui la query sottostante per creare un nuovo utente del database (CREATE USER) con una password (IDENTIFIED BY). Puoi nominare l’utente diversamente, ma la scelta di questo tutorial è ata_levi.

3. Dopo aver creato un utente, esegui la query sottostante per CONCEDERE al nuovo utente i permessi (ALL PRIVILEGES), come la creazione di un database sul server.

4. Ora, esegui il comando \q sottostante per uscire da MySQL.

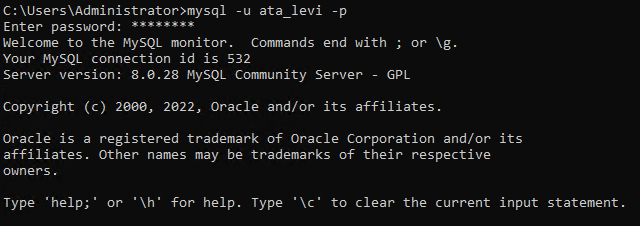
5. Esegui il comando mysql sottostante per accedere come utente del database appena creato (ata_levi).
6. Infine, esegui la seguente query per CREARE un nuovo DATABASE chiamato ata_database. Ma ovviamente, puoi nominare il database diversamente.

Gestione dei Database MySQL con DBeaver
Per gestire i database, di solito è necessario avere conoscenze SQL. Ma con DBeaver, hai una GUI per gestire i tuoi database in pochi clic, e DBeaver si occuperà per te delle istruzioni SQL.
1. Apri DBeaver dal tuo Desktop o dal menu Start.
2. Quando DBeaver si apre, clicca sul menu a tendina Nuova Connessione al Database e seleziona MySQL per iniziare a connetterti al tuo server MySQL.
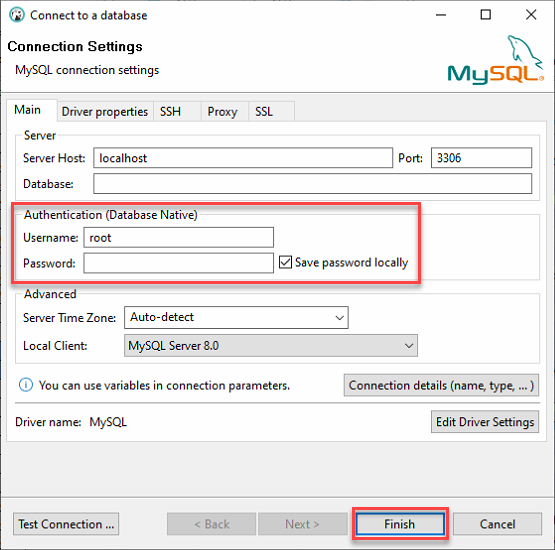
3. Accedi al tuo server MySQL locale con i seguenti:
- Mantieni il Server Host come localhost e la Porta a 3306 poiché ti stai connettendo a un server locale.
- Fornisci le credenziali dell’utente ata_levi (Nome utente e Password) dal passo due della sezione “Costruire un Database MySQL”, e clicca su Fine per accedere a MySQL.
4. Ora, espandi il tuo database (ata_database) sotto il Navigatore Database (pannello sinistro) → fai clic destro su Tabelle e seleziona Crea nuova tabella per avviare la creazione di una nuova tabella.
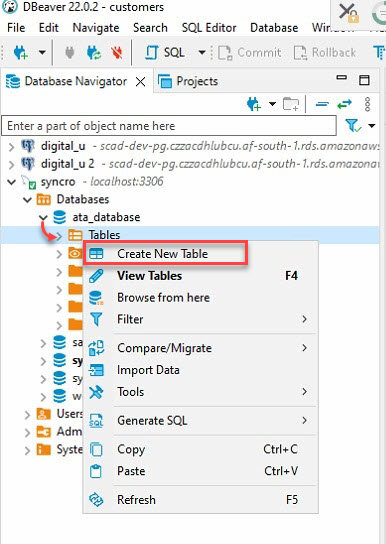
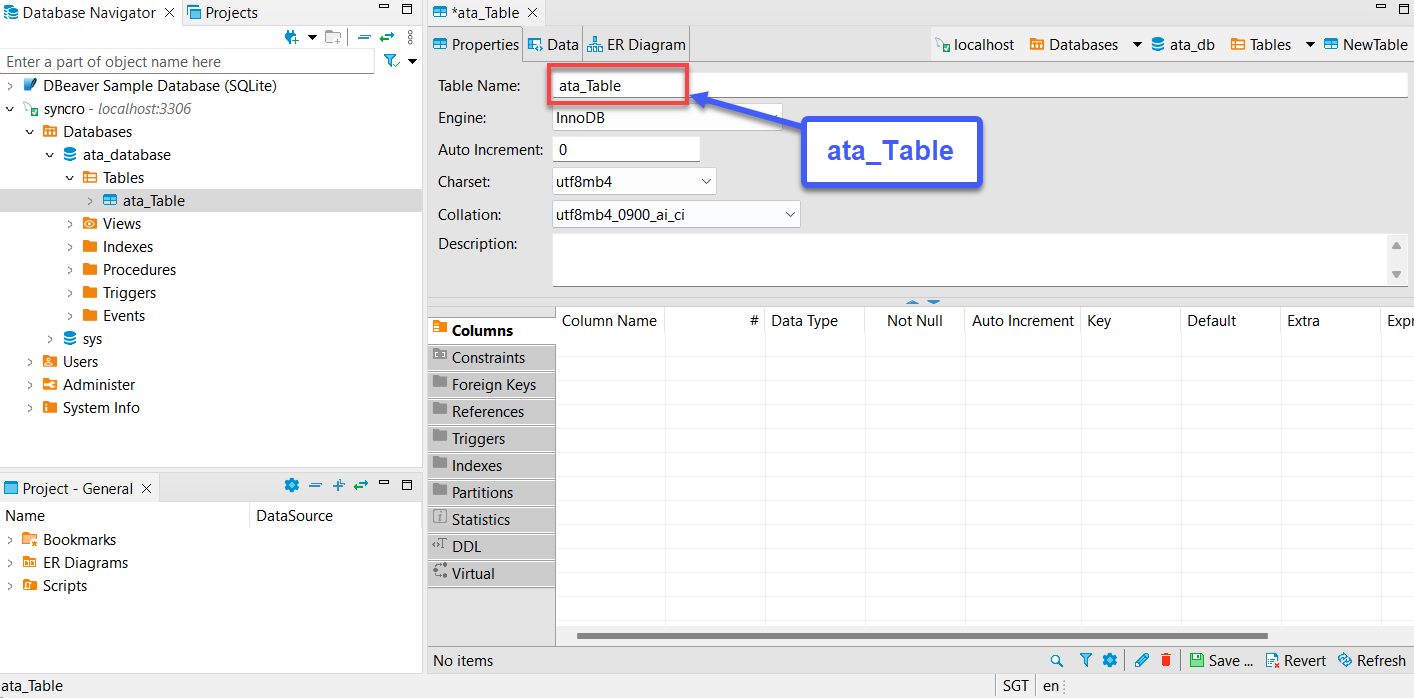
5. Nomi la tua nuova tabella, ma la scelta di questo tutorial è ata_Table, come mostrato di seguito.
Assicurati che il nome della tabella corrisponda al nome della tabella che specificherai nel metodo to_sql (“Nome tabella”) nel settimo passaggio della sezione “Ottenere e consumare i dati dell’API”.
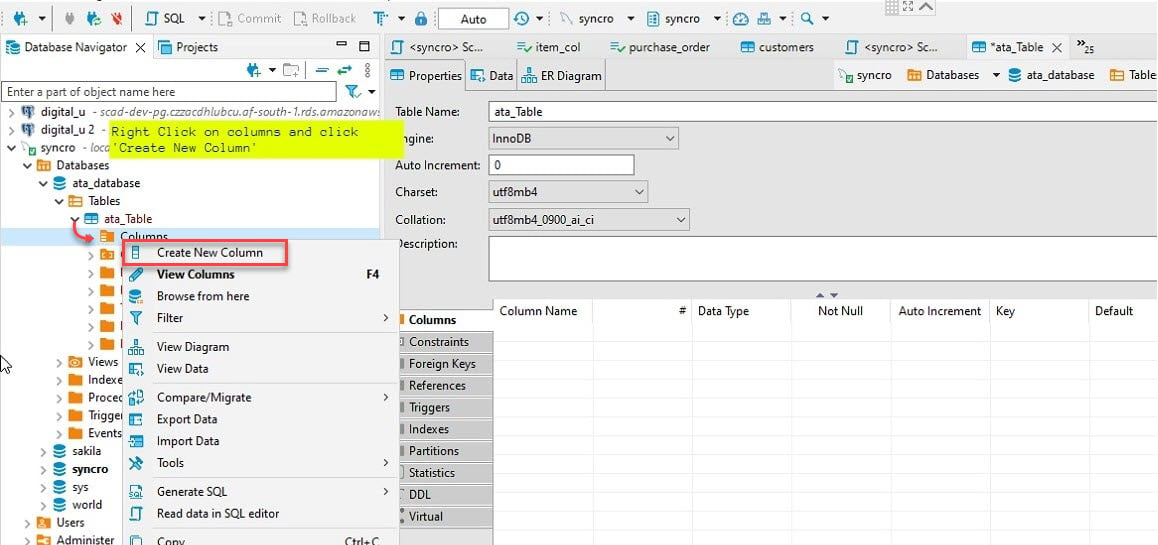
6. Successivamente, espandi la nuova tabella (ata_table) → fai clic destro su Colonne → Crea nuova colonna per creare una nuova colonna.
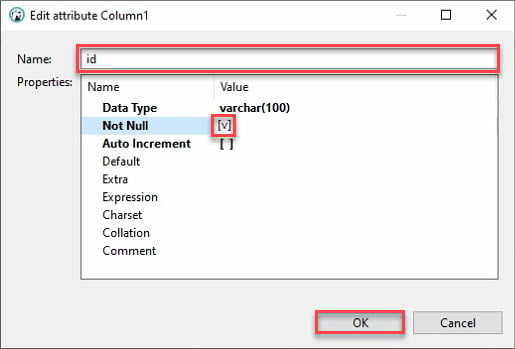
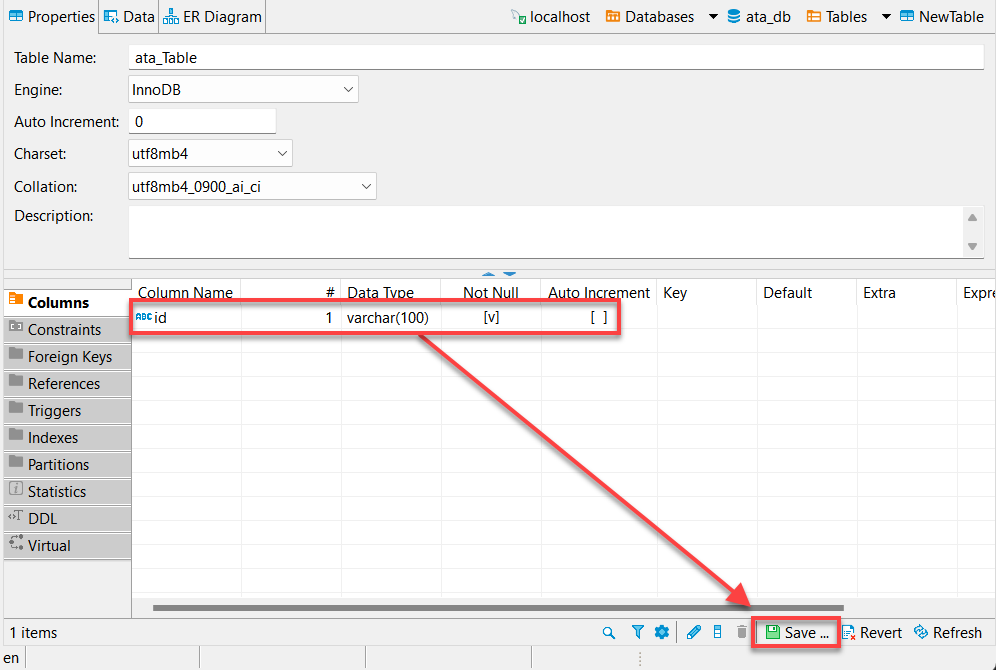
7. Fornisci un Nome colonna, come mostrato di seguito, e spunta la casella Non nullo, quindi fai clic su OK per creare la nuova colonna.
Idealmente, vorresti aggiungere una colonna chiamata “id”. Perché? La maggior parte delle API avrà un id, e il dataframe dei pandas di Python riempirà automaticamente le altre colonne.
8. Fai clic su Salva (in basso a destra) o premi Ctrl+S per salvare le modifiche una volta verificato che hai creato correttamente la nuova colonna (id), come mostrato di seguito.
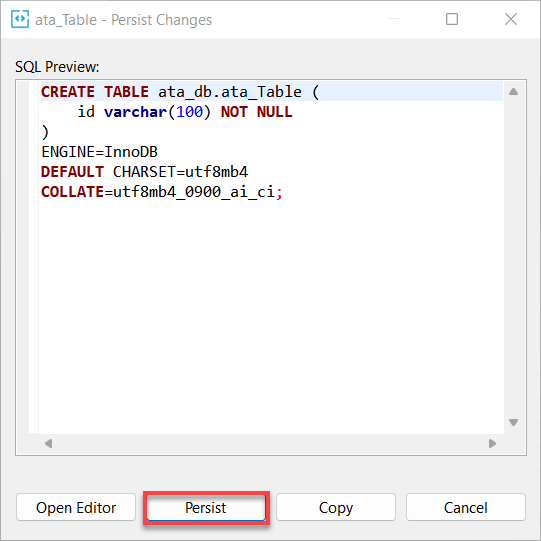
9. Infine, fai clic su Persisti per persistere le modifiche apportate al database.
Ottenere e Consumare Dati dell’API
Ora che hai creato il database per memorizzare i dati, devi recuperare i dati dal tuo rispettivo fornitore di API e caricarli nel tuo database usando Python. Fornirai i tuoi dati da visualizzare su Power BI.
Per connetterti al tuo fornitore di API, avrai bisogno di tre informazioni chiave; il metodo di autorizzazione, l’URL di base dell’API e il punto finale dell’API. Se hai dubbi su come ottenere queste informazioni, visita il sito di documentazione del tuo fornitore di API.
Ecco una pagina di documentazione da Syncro.
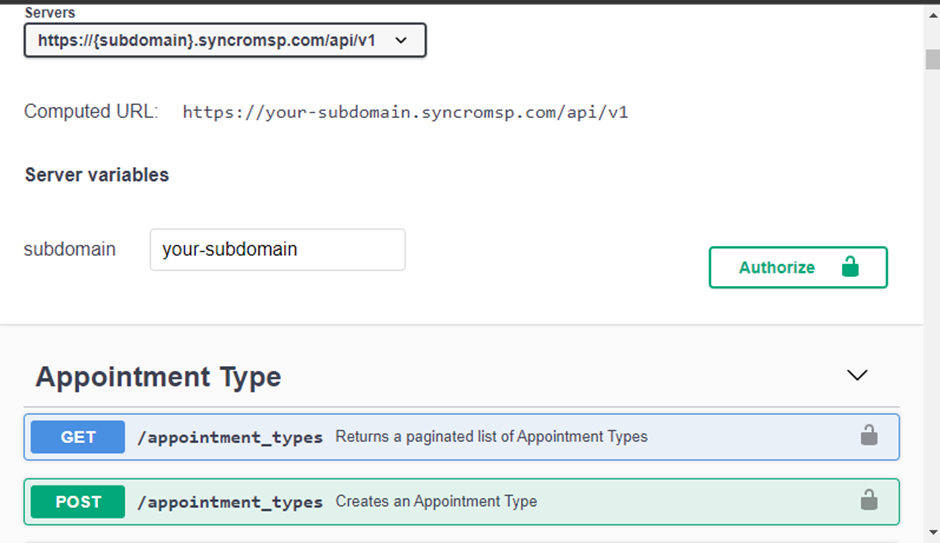
1. Apri VS Code, crea un file Python e nomina il file secondo i dati API attesi dal file. Questo file sarà responsabile del recupero e dell’invio dei dati API al tuo database (connessione al database).
Sono disponibili diverse librerie Python per aiutare con la connessione al database, ma in questo tutorial userai SQLAlchemy.
Esegui il comando pip di seguito nel terminale di VS Code per installare SQLAlchemy nel tuo ambiente.

2. Successivamente, crea un file chiamato connection.py, popola il codice di seguito, sostituisci i valori di conseguenza e salva il file.
Una volta iniziato a scrivere script per comunicare con il tuo database, è necessario stabilire una connessione al database prima che il database accetti qualsiasi comando.
Ma anziché riscrivere la stringa di connessione al database per ogni script che scrivi, il codice qui sotto è dedicato a rendere questa connessione richiamabile/riferibile da altri script.
3. Apri il terminale di Visual Studio (Ctrl+Shift+`), e esegui i seguenti comandi per installare pandas e requests.
4. Crea un altro file Python chiamato invoices.py (o dandogli un nome diverso), e inserisci il codice qui sotto nel file.
Aggiungerai frammenti di codice al file invoices.py ad ogni passaggio successivo, ma puoi vedere il codice completo su GitHub di ATA.
Lo script invoices.py verrà eseguito dallo script principale descritto nella sezione seguente, che estrae i tuoi primi dati API.
Il codice qui sotto esegue le seguenti azioni:
- Consuma i dati dalla tua API e li scrive nel tuo database.
- Sostituisce il metodo di autorizzazione, la chiave, l’URL di base e i punti di accesso API con le credenziali del tuo fornitore di API.
5. Aggiungi il frammento di codice qui sotto al file invoices.py per definire gli header, ad esempio:
- Il formato dei dati che ci si aspetta di ricevere dalla tua API.
- L’URL di base e il punto di accesso dovrebbero accompagnare il metodo di autorizzazione e la rispettiva chiave.
Assicurati di modificare i valori qui sotto con i tuoi.
6. Successivamente, aggiungi la seguente funzione asincrona al file invoices.py.
Il codice di seguito utilizza AsyncIO per gestire i tuoi script multipli da uno script principale coperto nella sezione seguente. Quando il tuo progetto cresce includendo più endpoint API, è una pratica comune avere i tuoi script di consumo API nei loro file separati.
7. Infine, aggiungi il codice di seguito al file invoices.py, dove una funzione get_pages gestisce la paginazione della tua API.
Questa funzione restituisce il numero totale di pagine nella tua API e aiuta la funzione range a iterare attraverso tutte le pagine.
Contatta gli sviluppatori della tua API riguardo al metodo di paginazione utilizzato dal tuo fornitore API.
Se preferisci aggiungere più endpoint API ai tuoi dati:
- Ripeti i passaggi da quattro a sei della sezione “Gestione dei database MySQL con DBeaver”.
- Ripeti tutti i passaggi nella sezione “Ottieni e Consuma Dati dell’API”.
- Cambia l’endpoint API con un altro che desideri consumare.
Sincronizzazione degli Endpoint API
Ora hai un database e una connessione API e sei pronto per iniziare il consumo dell’API eseguendo il codice nel file invoices.py. Ma farlo ti limiterebbe a consumare un endpoint API contemporaneamente.
Come superare il limite? Creerai un altro file Python come file centrale che chiama le funzioni API da vari file Python ed esegue le funzioni in modo asincrono utilizzando AsyncIO. In questo modo, mantieni il tuo programma pulito e ti permette di raggruppare più funzioni insieme.
1. Crea un nuovo file Python chiamato central.py e aggiungi il codice di seguito.
Similmente al file invoices.py, aggiungerai frammenti di codice al file central.py in ogni passaggio, ma puoi visualizzare il codice completo su ATA’s GitHub.
Il codice di seguito importa moduli essenziali e script da altri file utilizzando la sintassi from <nome_file> import <nome_funzione>.
2. Successivamente, aggiungi il seguente codice per controllare gli script da invoices.py nel file central.py.
È necessario fare riferimento/chiamare la funzione call_invoices da invoices.py a un task AsyncIO (invoice_task) in central.py.
3. Dopo aver creato il task AsyncIO, attendere il completamento del task per richiamare ed eseguire la funzione call_invoices da invoice.py una volta che la funzione chain (nel passaggio due) viene eseguita.
4. Creare un AsyncIOScheduler per pianificare un lavoro da eseguire nello script. Il lavoro aggiunto in questo codice esegue la funzione chain ad intervalli di un secondo.
Questo lavoro è importante per garantire che il programma continui ad eseguire gli script per mantenere i dati aggiornati.
5. Infine, eseguire lo script central.py su VS Code, come mostrato di seguito.
Dopo aver eseguito lo script, vedrai l’output sul terminale come quello riportato di seguito.
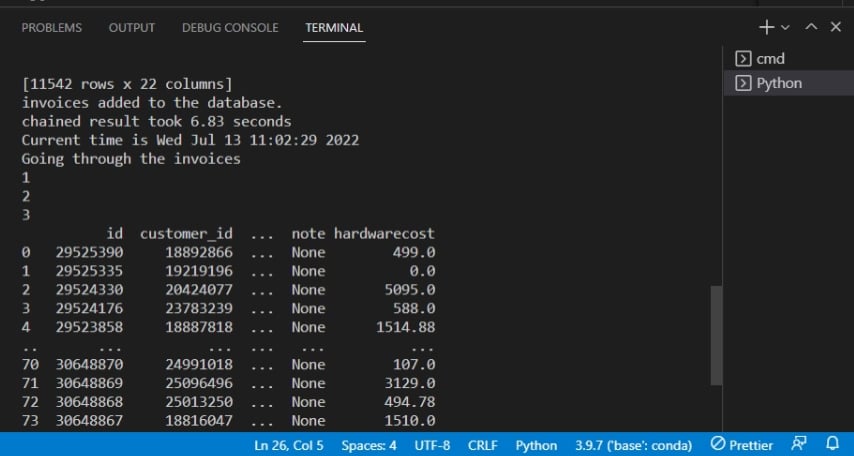
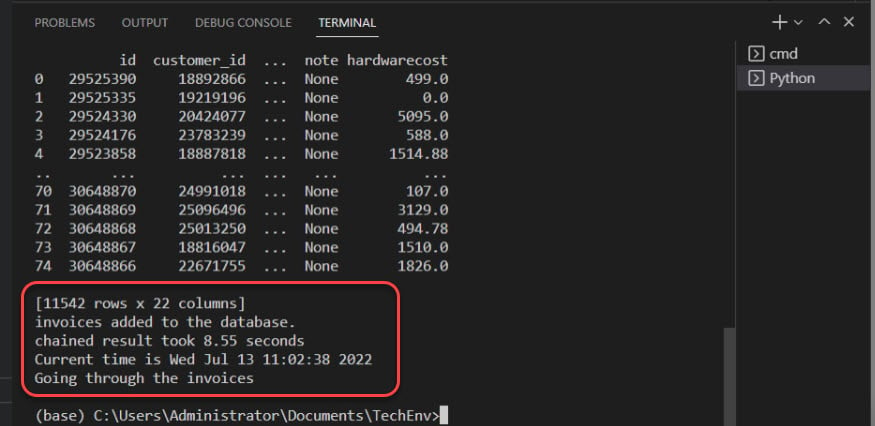
Di seguito, l’output conferma che le fatture vengono aggiunte al database.
Sviluppo di Power BI Visuals
Dopo aver programmato un programma che si connette e consuma dati da API e li spinge in un database, sei quasi pronto per sfruttare i tuoi dati. Ma prima, spingerai i dati nel database a Power BI per la visualizzazione, l’obiettivo finale.
Un sacco di dati è inutile se non puoi visualizzare i dati e fare connessioni profonde. Fortunatamente, i visual di Power BI sono simili a come i grafici possono rendere semplici e prevedibili le equazioni matematiche complicate.
1. Apri Power BI dal tuo desktop o dal menu Start.
2. Fare clic sull’icona della fonte dati sopra il menu a discesa Ottieni dati nella finestra principale di Power BI. Compare una finestra popup dove puoi selezionare la fonte dati da utilizzare (passaggio tre).
3. Cerca mysql, seleziona il database MySQL e fai clic su Connetti per avviare la connessione al tuo database MySQL.
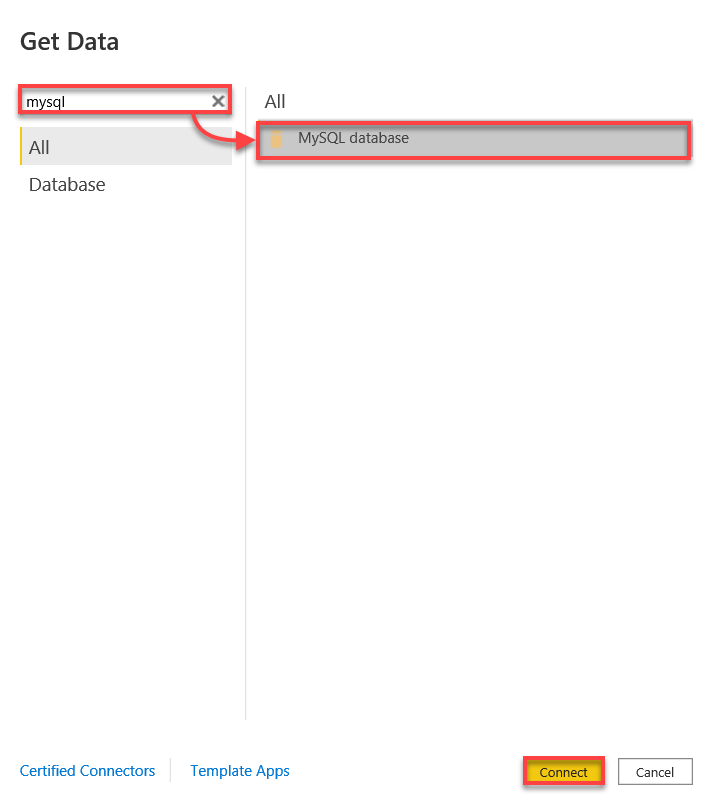
4. Ora, connettiti al tuo database MySQL con i seguenti dettagli:
- Inserisci localhost:3306 poiché stai collegandoti al tuo server MySQL locale sulla porta 3306.
- Fornisci il nome del tuo database, in questo caso, ata_db.
- Fai clic su OK per connetterti al tuo database MySQL.

5. Ora, fai clic su Trasforma dati (in basso a destra) per vedere l’anteprima dei dati nell’editor di query di Power BI (passaggio cinque).

6. Dopo aver visualizzato l’origine dati, fai clic su Chiudi e applica per tornare all’applicazione principale e confermare se sono stati applicati eventuali cambiamenti.
L’editor delle query mostra le tabelle dalla tua fonte dati sulla sinistra. Allo stesso tempo, puoi controllare il formato dei dati prima di procedere all’applicazione principale.
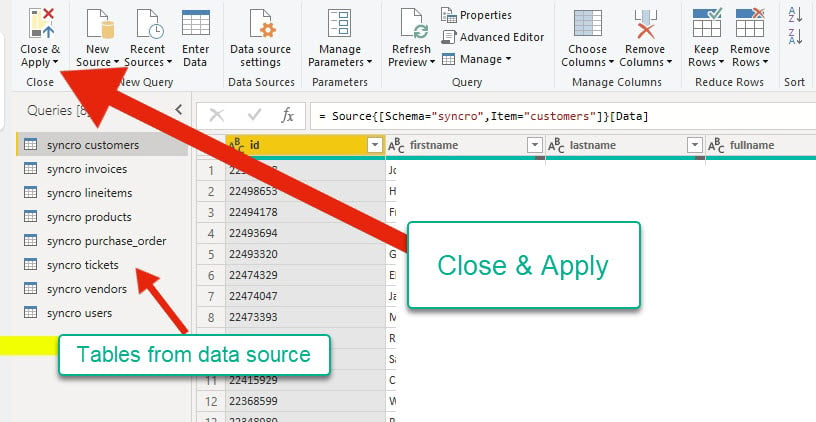
7. Fare clic sulla scheda della barra degli strumenti delle tabelle, selezionare una qualsiasi tabella nel riquadro dei campi e fare clic su Gestisci relazioni per aprire l’assistente per la creazione di relazioni.
Prima di creare visualizzazioni, è necessario assicurarsi che le tue tabelle siano correlate, quindi specificare esplicitamente qualsiasi relazione tra le tabelle. Perché? Power BI non rileva automaticamente la correlazione delle tabelle complesse.

8. Selezionare le caselle delle relazioni esistenti da modificare e fare clic su Modifica. Compare una finestra popup, dove è possibile modificare le relazioni selezionate (passaggio nove).
Ma se preferisci aggiungere una nuova relazione, fai clic su Nuovo invece.
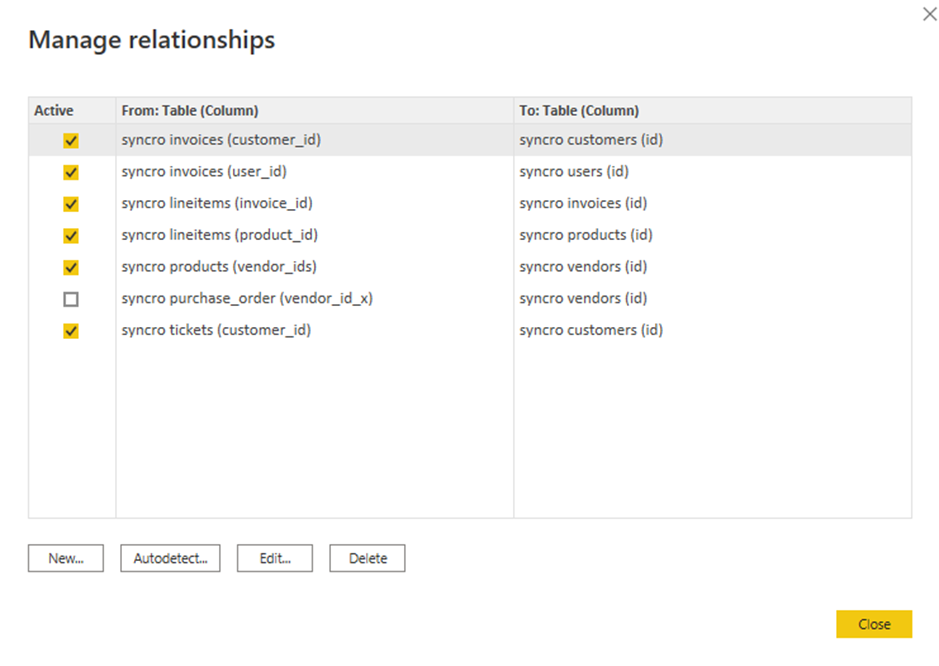
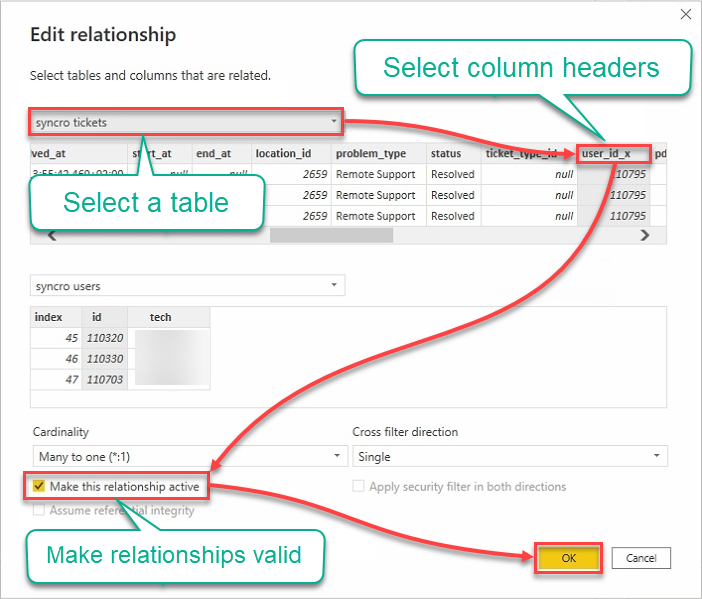
9. Modifica le relazioni con quanto segue:
- Fai clic sul menu a discesa delle tabelle e seleziona una tabella.
- Fai clic sulle intestazioni per selezionare le colonne da utilizzare.
- Spunta la casella Rendi attiva questa relazione per assicurarti che le relazioni siano valide.
- Fai clic su OK per stabilire la relazione e chiudere la finestra Modifica relazione.
10. Ora, fai clic sul tipo di visualizzazione Tabella nella riquadro Visualizzazioni (a destra) per creare la tua prima visualizzazione e apparirà una visualizzazione di tabella vuota (passo 11).
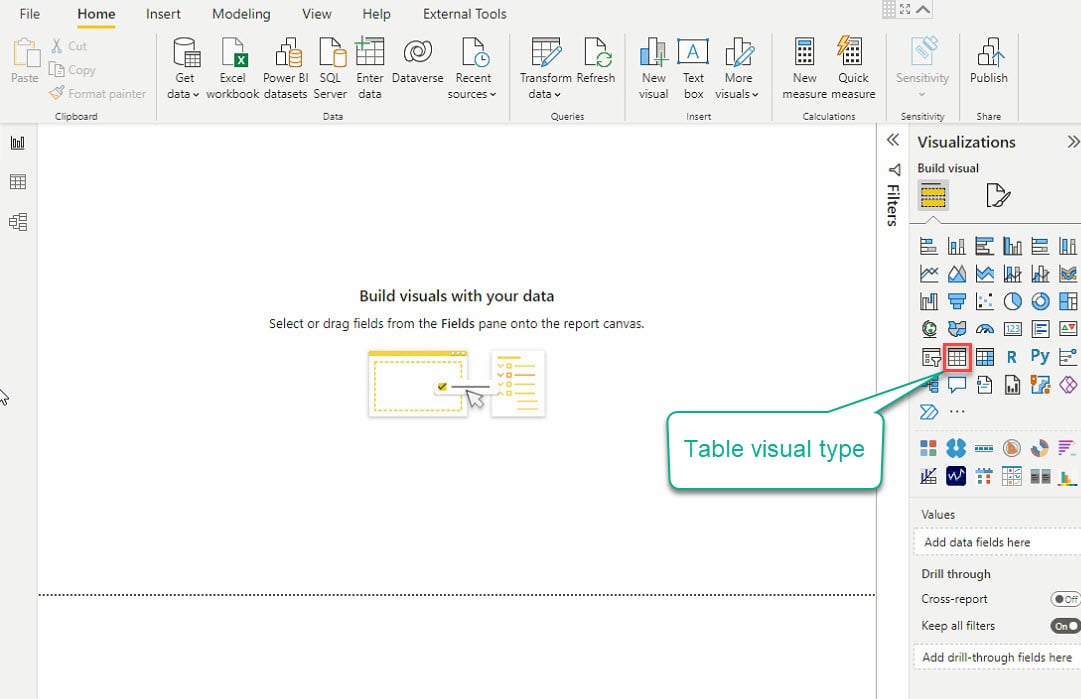
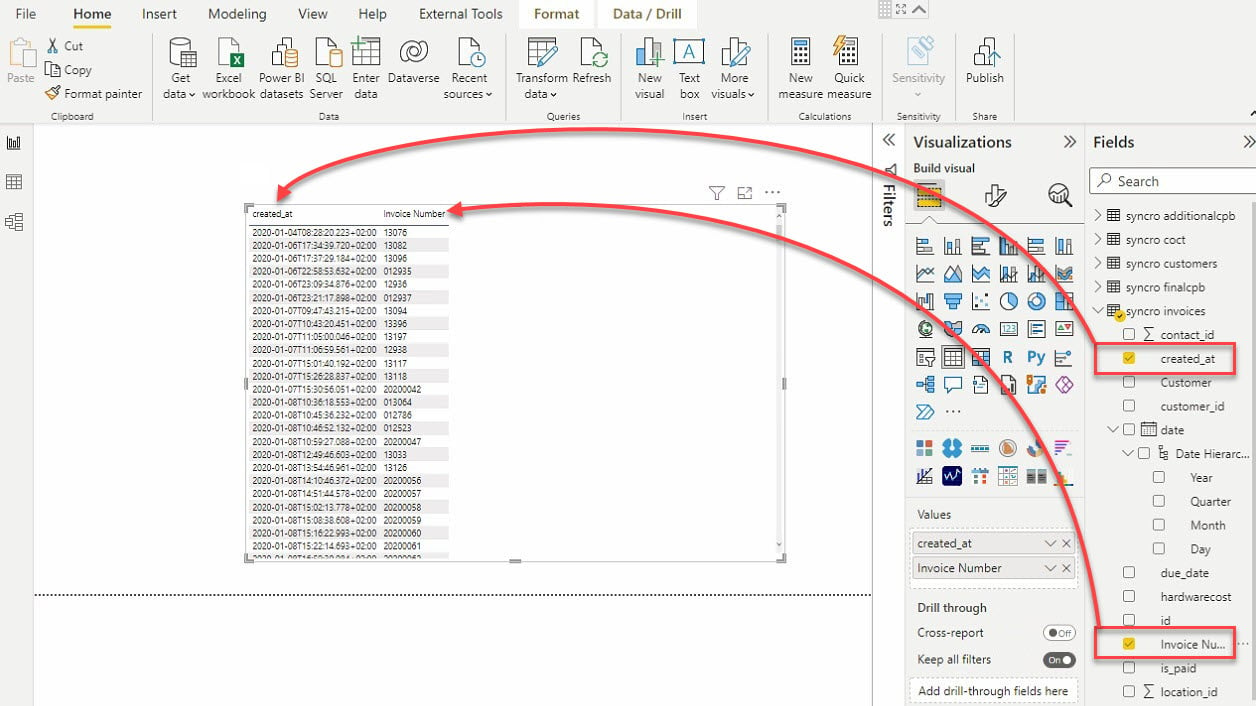
11. Seleziona la visualizzazione di tabella e i campi dati (nel riquadro Campi) da aggiungere alla tua visualizzazione di tabella, come mostrato di seguito.
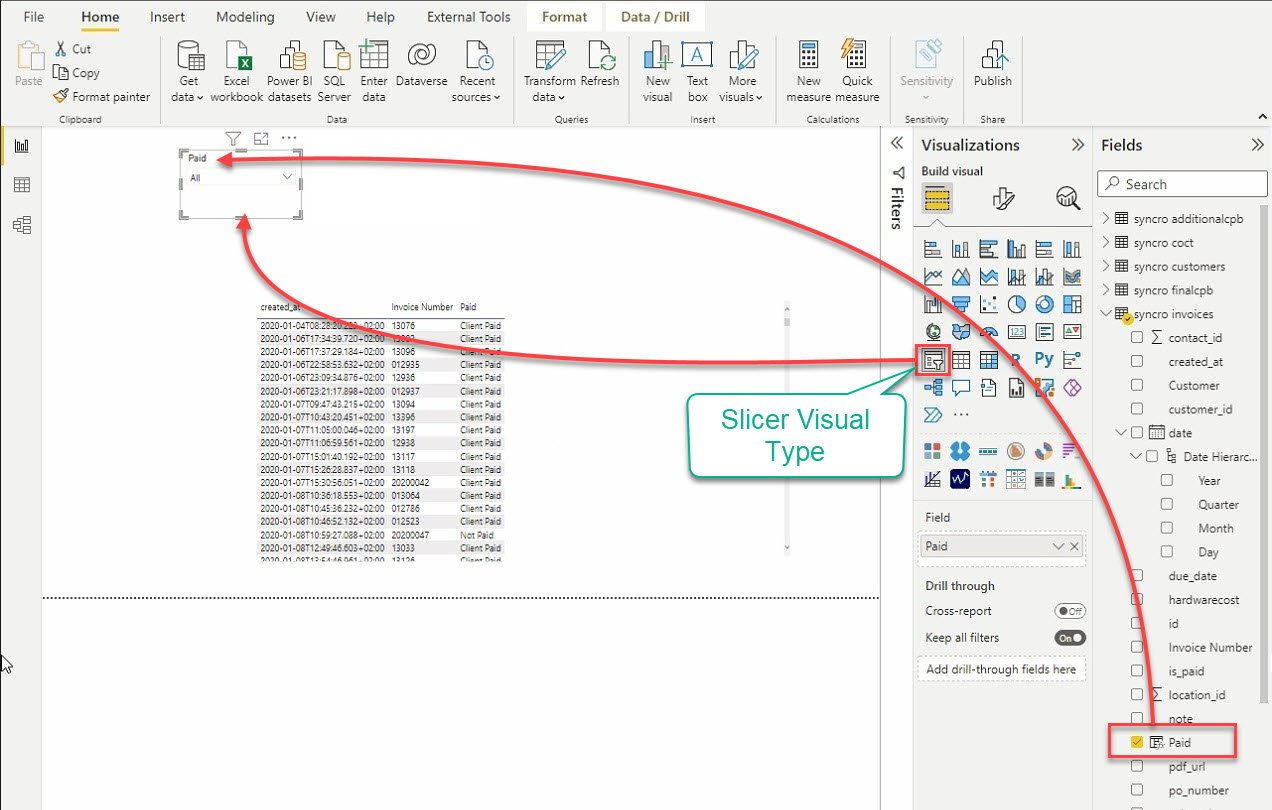
12. Infine, fai clic sul tipo di visualizzazione Slicer per aggiungere un’altra visualizzazione. Come suggerisce il nome, la visualizzazione Slicer suddivide i dati filtrando altre visualizzazioni.
Dopo aver aggiunto lo slicer, seleziona i dati dal riquadro Campi da aggiungere alla visualizzazione dello slicer.
Modifica delle visualizzazioni
Il look predefinito delle visualizzazioni è abbastanza decente. Ma non sarebbe fantastico se potessi cambiare l’aspetto delle visualizzazioni in qualcosa di meno monotono? Lascia che Power BI faccia la magia.
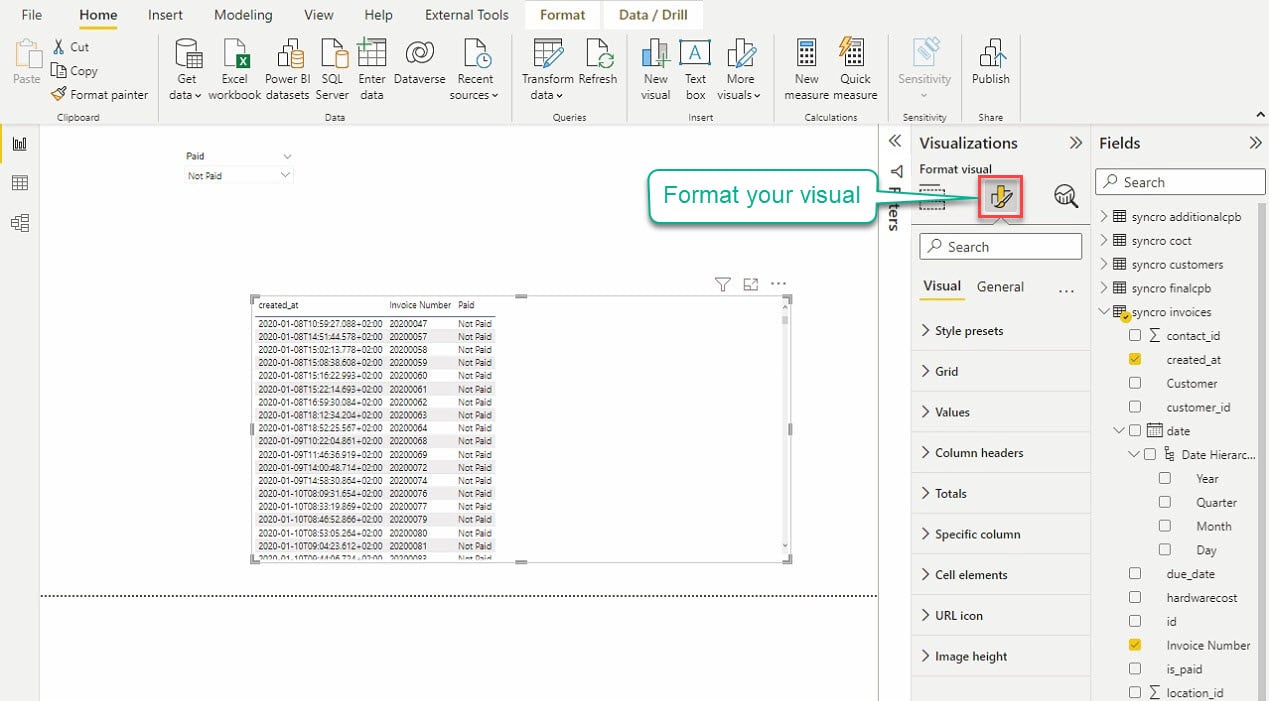
Fai clic sull’icona Formatta la tua visualizzazione sotto la visualizzazione per accedere all’editor di visualizzazione, come mostrato di seguito.
Passa un po’ di tempo a giocare con le impostazioni di visualizzazione per ottenere l’aspetto desiderato per le tue visualizzazioni. Le tue visualizzazioni saranno correlate finché stabilisci una relazione tra le tabelle coinvolte nelle tue visualizzazioni.
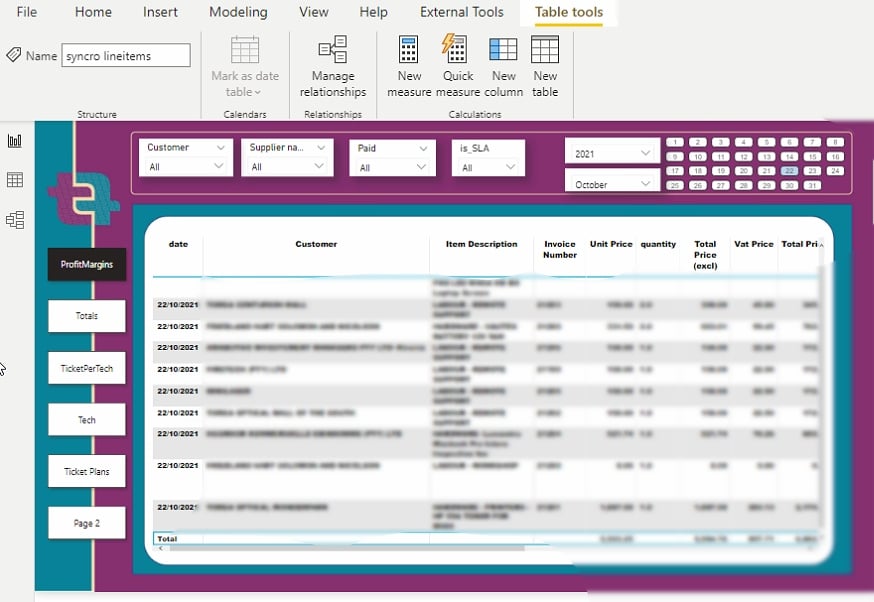
Dopo aver modificato le impostazioni di visualizzazione, è possibile estrarre report come quelli qui sotto.
Ora, è possibile visualizzare ed analizzare i tuoi dati senza complessità o affaticare gli occhi.
Nella seguente visualizzazione, guardando il grafico delle tendenze, vedrai che qualcosa è andato storto nell’aprile 2020. Quel momento è stato quando i blocchi Covid-19 hanno colpito inizialmente il Sud Africa.
Questo risultato dimostra solo l’abilità di Power BI nel fornire visualizzazioni dati precise.

Conclusione
Questo tutorial mira a mostrarti come stabilire un flusso di dati dinamico dal vivo estrarre i tuoi dati dai punti di accesso API. Inoltre, elaborare e spingere i dati al tuo database e Power BI usando Python. Con questa nuova conoscenza, ora puoi consumare i dati delle API e creare le tue visualizzazioni dati.
Sempre più aziende stanno creando app web API Restful. E a questo punto, sei ora sicuro nel consumare API utilizzando Python e creare visualizzazioni dati con Power BI, il che può aiutare ad influenzare le decisioni aziendali.