













מערכות RAG משלבות את כוחן של מנגנוני השליפה ומודלי השפה, ומאפשרות להם לייצר תשובות רלוונטיות בהקשר ומבוססות היטב. עם זאת, הערכת הביצועים וזיהוי מצבי כישלון אפשריים של מערכות RAG יכולה להיות מאוד קשה.
לכן, הטרייד RAG – טרייד מדדים שמספקים שלושה שלבים עיקריים בביצוע מערכת RAG: רלוונטיות ההקשר, מבוססות, ורלוונטיות התשובה. בפוסט הבלוג הזה, אעבור על המורכבויות של הטרייד RAG, ואנחנו נלווה אותך בתהליך ההקמה, ביצוע וניתוח הערכה של מערכת RAG.
הקדמה לטרייד RAG:
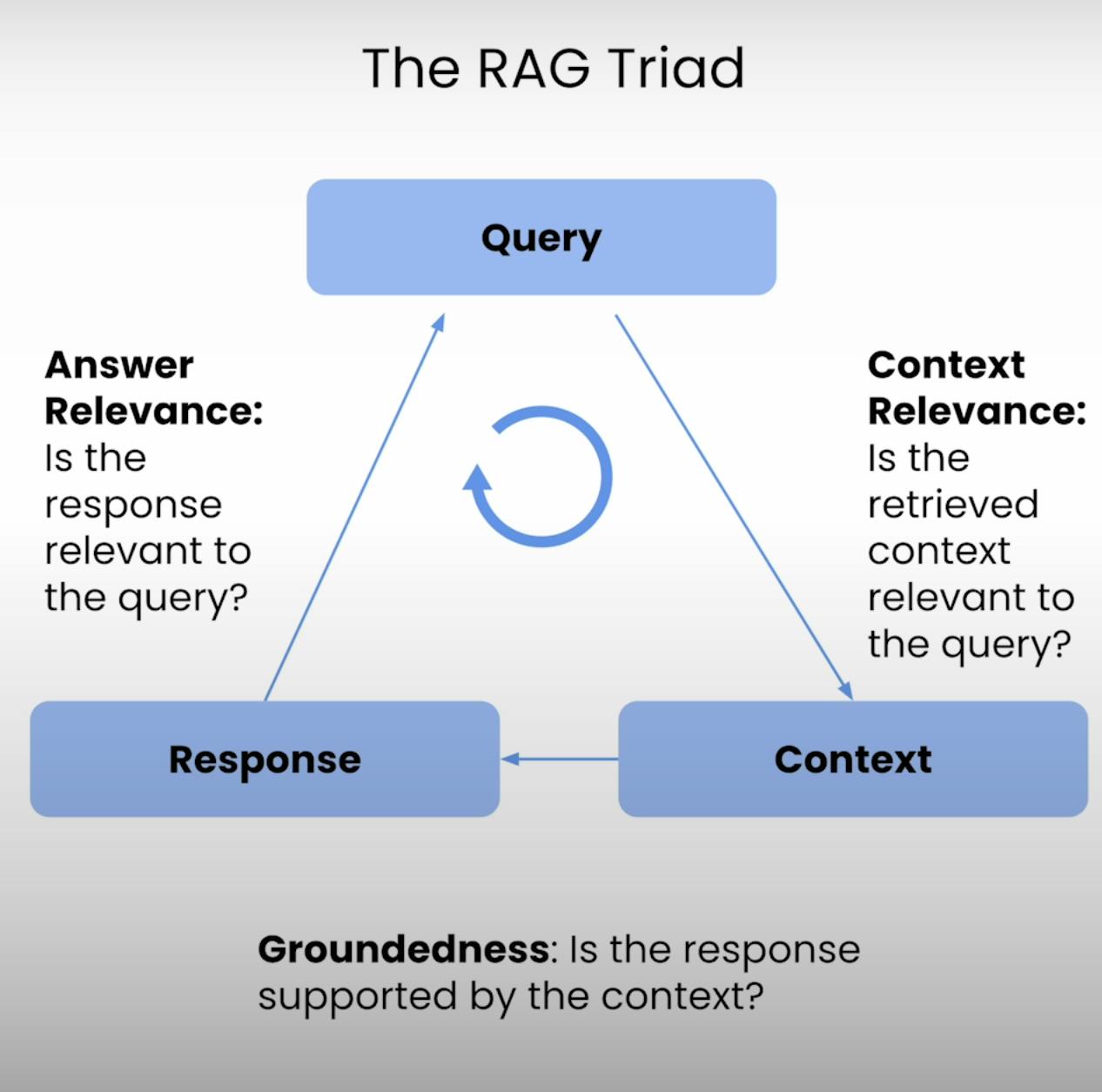
בלב כל מערכת RAG נמצאת איזון עדין בין השליפה לייצור. הטרייד RAG מספק מסגרת מקיפה להערכת האיכות ומצבי הכישלון האפשריים של איזון עדין זה. בואו נפרק את שלושת הרכיבים.
A. Context Relevance:
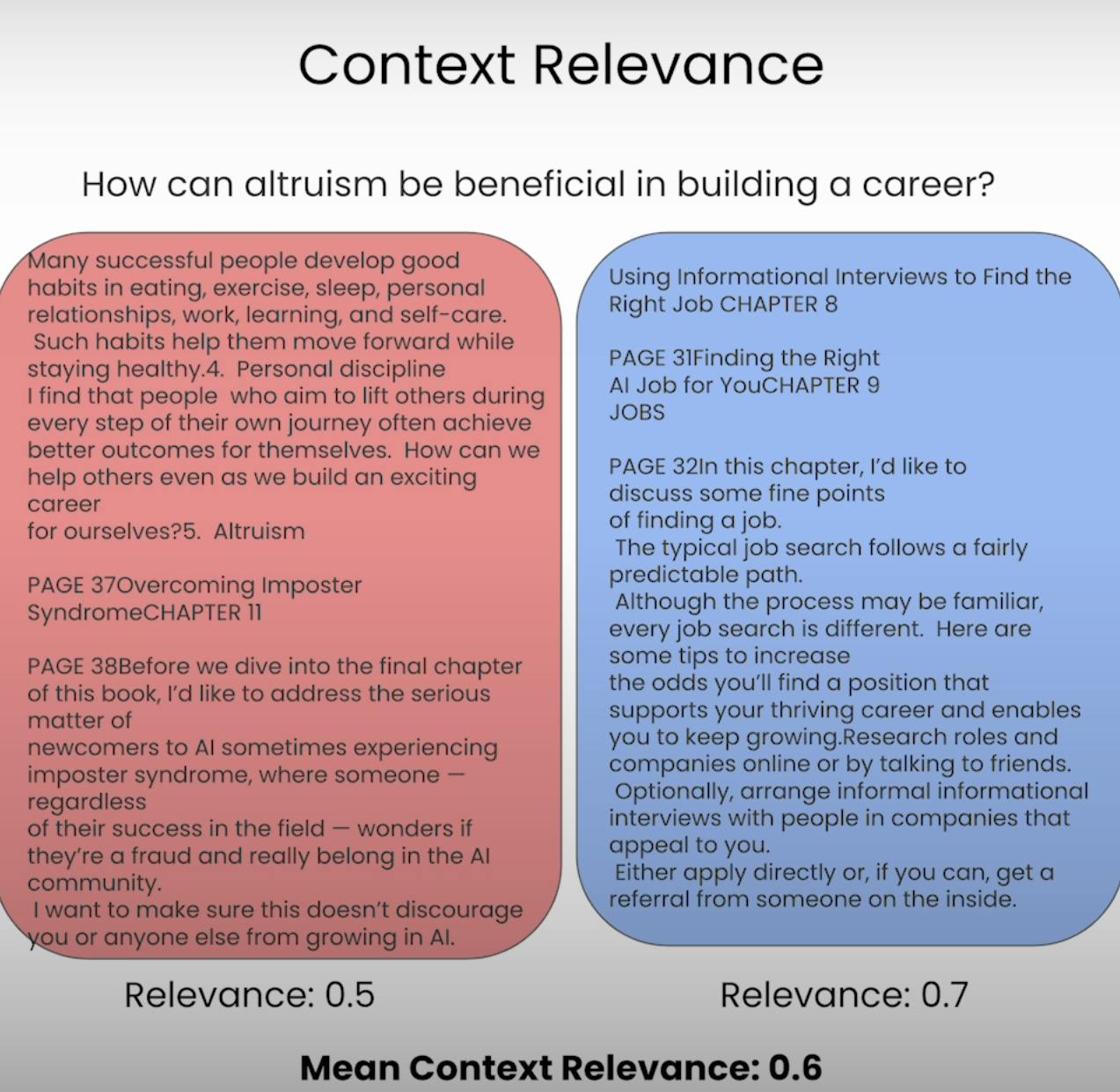
דמיין שמצופים ממך לענות על שאלה, אך המידע שניתן לך לגמרי לא קשור. זה בדיוק מה שמערכת RAG משמרת להימנע ממנו. רלוונטיות ההקשר מעריכה את איכות התהליך של השליפה על ידי הערכת כמה רלוונטי כל פיסת הקשר המשוחררת לשאלה המקורית. על ידי ציון הרלוונטיות של הקשר המשוחרר, אנו יכולים לזהות בעיות אפשריות במנגנון השליפה ולבצע את ההתאמות ההכרחיות.

B. Groundedness:
האם קיים דיאלוג שהיית בו ונראה שמישהו ממציא עובדות או מספק מידע ללא יסוד מוצק? זהו הדומה למערכת RAG שחסרה יסוד. יסוד מעריך האם התגובה הסופית שנוצרה על ידי המערכת מושתת היטב על ההקשר שנשלט. אם התגובה מכילה טענות או טענות שאינן נתמכות על ידי המידע הנשלט, המערכת עשויה להזיית או להסתמך יותר מדי על נתוני המידע הקיימים מראש, מה שמוביל לפגמים או הטיות אפשריים.
C. Answer Relevance:
דמיינו שאתם מבקשים כיוונים לחנות הקפה הקרובה ביותר ומקבלים מתכון מפורט לאפיית עוגה. זהו סוג המצב ש"תשובה רלוונטית" מנסה למנוע. רכיב זה של טריאד של RAG מעריך האם התגובה הסופית שנוצרה על ידי המערכת באמת רלוונטית לשאלה המקורית. על ידי הערכת הרלוונטיות של התשובה, אנו יכולים לזהות מקרים בהם המערכת עשויה לפספס את השאלה או לסטות מהנושא המיועד.

הכנת טריאד של RAG לבחינה
לפני שנוכל לצלול לתהליך ההערכה, עלינו להניח את היסודות. בואו נעבור על הצעדים הנדרשים להכנת בדיקת טריאד של RAG.
A. Importing Libraries and Establishing API Keys:
קודם כל, עלינו לייבא את הספריות והמודולים הנדרשים, כולל מפתח ה-API של OpenAI וספק ה-LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
לאחר מכן, נטען ונארגן את מאגר המסמכים שעליו תעבוד המערכת של RAG. במקרה שלנו, נשתמש במסמך PDF על "כיצד לבנות קריירה ב-AI" מאת אנדרו נג'.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

בלב הערכת הריבוע RAG נמצאות פונקציות המשוב – פונקציות מיוחדות המעריכות כל רכיב של הריבוע. בואו נגדיר את הפונקציות הללו באמצעות ספריית TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
ביצוע היישום והערכת RAG
כשההגדרה תואמת, הגיע הזמן להפעיל את מערכת ה RAG שלנו ואת ממשק הערכה. בואו נעבור על השלבים המעורבים בביצוע היישום והקלטת תוצאות הערכה.
A. Preparing the Evaluation Questions:
ראשית, נטען קבוצת שאלות ערכה שאנו רוצים שמערכת ה RAG שלנו תענה עליהן. שאלות אלו ישמשו כבסיס לתהליך הערכה שלנו.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
לאחר מכן, נקבע את מככיב ה TrueLens, אשר יעזור לנו לרשום את התביעות, התגובות ותוצאות הערכה במסד נתונים מקומי.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
כשיישום RAG פועל על כל שאלת ערכה, מככיב ה TrueLens ילכסן בקפידה את התביעות, התגובות, התוצאות הביניים וציוני הערכה, ויאחסן אותם במסד נתונים מקומי לניתוח נוסף.
ניתוח תוצאות הערכה
עם נתוני הערכה בהישג ידינו, הגיע הזמן לבדוק את הניתוח ולהשיג תובנות. בואו נבחן דרכים שונות בהן נוכל לנתח את התוצאות ולזהות אפשרויות לשיפור.
A. Examining Individual Record-Level Results:
לפעמים, השטן נמצא בפרטים. על ידי בחינת תוצאות רמת הרשומה האינדיבידואלית, נוכל להשיג הבנה עמוקה יותר של כוחות וחולשות של מערכת ה RAG שלנו.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
קטע הקוד הזה נותן לנו גישה לתביעות, תגובות וציוני הערכה עבור כל רשומה אינדיבידואלית, מה שמאפשר לנו לזהות מקרים ספציפיים בהם המערכת אולי נתקלה או הצליחה.
B. Viewing Aggregate Performance Metrics:
בואו ניקח צעד אחורה ונבחן את התמונה הגדולה. ספריית TrueLens מספקת לנו לשבש שמאסף את מדדי הביצועים של כל הרשומות, ומהווה תצוגה גבוהה של ביצועים כלליים של מערכת ה-RAG שלנו.
tru.get_leaderboard(app_ids=[])
לשבש זה מציג את הניקודים הממוצעים עבור כל רכיב ב-RAG Triad, יחד עם מדדים כמו עיכוב ועלות. על ידי ניתוח מדדים אגוציים אלו, אנו יכולים לזהות מגמות ותבניות שאולי לא יהיו ברורות ברמת הרשומה.
C. Exploring the TrueLens Streamlit Dashboard:
כ ,,בנוסף ל-CLI, TrueLens מספק גם לוח מחוונים Streamlit המספק GUI לחקירה וניתוח של תוצאות ההערכה. עם כמה פקודות פשוטות, אנו יכולים להשיק את הלוח.
tru.run_dashboard()
ברגע שהלוח פועל, אנו רואים סקירה מקיפה של ביצועים מערכת ה-RAG שלנו. במבט יחיד, אנו יכולים לראות את המדדים המצטברים עבור כל רכיב ב-RAG Triad, כ ,,בנוסף למידע על עיכוב ועלות.
על ידי בחירת היישום שלנו מתפריט הנחצים, אנו יכולים לגשת לתצוגה מפורטת ברמת הרשומה של תוצאות ההערכה. כל רשומה מוצגת בצורה מסודרת, עם הפרמט הקלט של המשתמש, התגובה של מערכת ה-RAG, והניקודים המתאימים עבור רלוונטיות התשובה, רלוונטיות ההקשר והמרומזות.
לחיצה על רשומה בודדת מחשף תובנות נוספות. אנו יכולים לחקור את שרשרת מחשבה שמאחורי כל ציון הערכה, המסביר את תהליך החשיבה של מודל השפה שמבצע את ההערכה. רמת השקיפות הזו שימושית לזיהוי של שגיאות ואפשרויות לשיפות.
נניח שאנו נתקלים ברשומה שבה ציון החומריות נמוך. על ידי הסתכלות על הפרטים, עשויים לגלות שתגובת מערכת RAG מכילה טענות שאינן מושתתות היטב על ההקשר שנמצא. הלוח המסך יראה לנו בדיוק אילו טענות חסרות ראיות תמיכה, מה שמאפשר לנו לזהות את שורש הבעיה.
לוח המסך TrueLens Streamlit הוא יותר מאשר רק כלי ייצוג. באמצעות יכולות האינטראקטיביות שלו ותובנות מבוססות נתונים, נוכל לקבל החלטות מושכלות ולפעול לפי מטרה כדי לשפר את ביצועי היישומים שלנו.
שיטות RAG מתקדמות ושיפור חוזר
A. Introducing the Sentence Window RAG Technique:
טכניקה מתקדמת אחת היא RAG חלון המשפט, שמתייחסת למצב כשל נפוץ של מערכות RAG: גודל מוגבל של הקשר. על ידי הגדלת גודל חלון ההקשר, RAG חלון המשפט מטה לספק למודל השפה מידע רלוונטי ומקיף יותר, מה שעשוי לשפר את קשירות ההקשר והחומריות של המערכת.
B. Re-evaluating with the RAG Triad:
לאחר יישום שיטת RAG חלון המשפט, נוכל לבחון אותה מחדש באמצעות מסגרת RAG Triad זהה. הפעם, נתמקד בציוני קשירות ההקשר וחומריות, ונחפש שיפורים בתחומים אלה כתוצאה מהגדלת גודל ההקשר.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
למרות ששיטת RAG חלון המשפט יכולה לשפר את הביצועים, גודל החלון האופטימלי עשוי להשתנות תלוי במקרה השימושי ובמערך הנתונים הספציפי. חלון קטן מדי עשוי לא לספק מספיק הקשר רלוונטי, וגודל חלון גדול מדי עשוי להכניס מידע לא רלוונטי, וזה יכול להשפיע על החומריות והרלוונטיות של המערכת.
על ידי ניסוי עם מידות חלונות שונות ובקרת תקינות מחדש באמצעות תריסר ה-RAG, נוכל למצוא את נקודת המפל המאזן בין רלוונטיות הקשר לבין מושכלות ורלוונטיות התשובה, ובסופו של דבר להביא למערכת RAG חזקה ואמינה יותר.
מסקנה:
תריסר ה-RAG, המורכב מרלוונטיות הקשר, מושכלות ורלוונטיות התשובה, הוכיח כמועיל מאוד כמודל להערכת הביצועים וגילוי נקודות כשל אפשריות של מערכות ייצור מוגברות על ידי רשות.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems