













Introduction
Dans ce tutoriel, vous construirez une application Python capable d’extraire l’audio d’une vidéo d’entrée, de transcrire l’audio extrait, de générer un fichier de sous-titres basé sur la transcription, puis d’ajouter le sous-titre à une copie de la vidéo d’entrée.
Pour construire cette application, vous utiliserez FFmpeg pour extraire l’audio d’une vidéo d’entrée. Vous utiliserez Whisper d’OpenAI pour générer une transcription de l’audio extrait, puis utiliserez cette transcription pour créer un fichier de sous-titres. De plus, vous utiliserez FFmpeg pour ajouter le fichier de sous-titres généré à une copie de la vidéo d’entrée.
FFmpeg est une suite logicielle puissante et open source pour le traitement des données multimédias, y compris les tâches de traitement audio et vidéo. Il fournit un outil en ligne de commande permettant aux utilisateurs de convertir, éditer et manipuler des fichiers multimédias avec une large gamme de formats et de codecs.
Whisper d’OpenAI est un système de reconnaissance automatique de la parole (ASR) conçu pour convertir le langage parlé en texte écrit. Entraîné sur une grande quantité de données supervisées multilingues et multitâches, il excelle dans la transcription de contenus audio divers avec une grande précision.
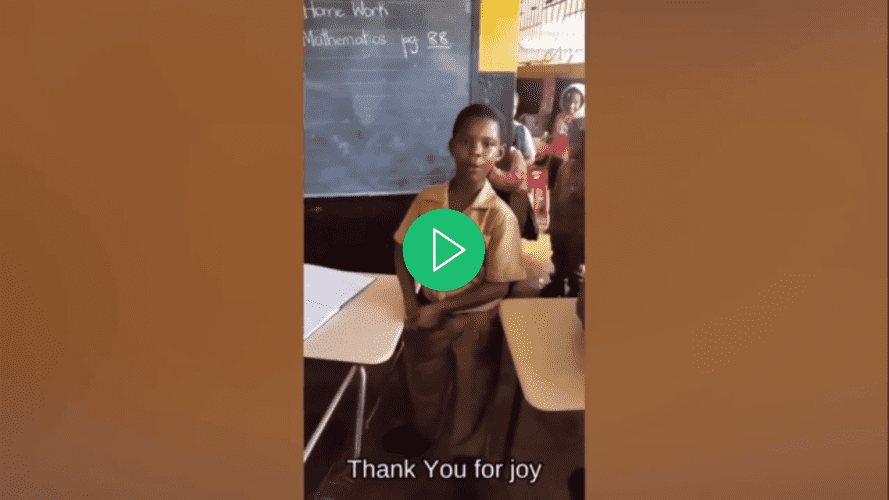
À la fin de ce tutoriel, vous disposerez d’une application capable d’ajouter des sous-titres à une vidéo :
Prérequis
Pour suivre ce tutoriel, le lecteur aura besoin des outils suivants :
-
FFmpeg installé.
-
Une compréhension de base de Python. Vous pouvez suivre cette série de tutoriels pour apprendre à coder en Python.
Étape 1 — Créer le Répertoire Racine du Projet
Dans cette section, vous allez créer le répertoire du projet, télécharger la vidéo d’entrée, créer et activer un environnement virtuel, et installer les paquets Python nécessaires.
Ouvrez une fenêtre de terminal et naviguez vers un emplacement adapté pour votre projet. Exécutez la commande suivante pour créer le répertoire du projet :
Naviguez dans le répertoire du projet :
Téléchargez cette vidéo modifiée et stockez-la dans le répertoire racine de votre projet sous le nom input.mp4. La vidéo présente un enfant nommé Rushawn chantant « Beautiful Day » de Jermaine Edward. La vidéo éditée que vous utiliserez dans ce tutoriel a été extraite de la vidéo YouTube suivante :
Créez un nouvel environnement virtuel et nommez-le env :
Activez l’environnement virtuel :
À présent, utilisez la commande suivante pour installer les packages nécessaires à la construction de cette application :
Avec la commande ci-dessus, vous avez installé les bibliothèques suivantes :
-
faster-whisper: est une version repensée du modèle Whisper d’OpenAI qui exploite CTranslate2, un moteur d’inférence haute performance pour les modèles Transformer. Cette implémentation atteint jusqu’à quatre fois plus de vitesse que openai/whisper avec une précision comparable, tout en consommant moins de mémoire. -
ffmpeg-python: est une bibliothèque Python qui fournit une enveloppe autour de l’outil FFmpeg, permettant aux utilisateurs d’interagir avec les fonctionnalités de FFmpeg dans des scripts Python facilement. À travers une interface Pythonique, elle permet des tâches de traitement vidéo et audio, telles que l’édition, la conversion et la manipulation.
Exécutez la commande suivante pour enregistrer les packages qui ont été installés à l’aide de pip dans l’environnement virtuel dans un fichier nommé requirements.txt:
Le fichier requirements.txt devrait ressembler à ce qui suit:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
Dans cette section, vous avez créé le répertoire du projet, téléchargé la vidéo d’entrée qui sera utilisée dans ce tutoriel, configuré un environnement virtuel, l’avez activé et installé les packages Python nécessaires. Dans la section suivante, vous générerez une transcription pour la vidéo d’entrée.
Étape 2 — Génération de la transcription vidéo
Dans cette section, vous créerez le script Python où l’application résidera. À l’intérieur de ce script, vous utiliserez la bibliothèque ffmpeg-python pour extraire la piste audio de la vidéo d’entrée téléchargée dans la section précédente et la sauvegarder en tant que fichier WAV. Ensuite, vous utiliserez la bibliothèque faster-whisper pour générer une transcription de l’audio extrait.
Dans le répertoire racine de votre projet, créez un fichier nommé main.py et ajoutez-y le code suivant:
Ici, le code commence par importer diverses bibliothèques et modules, y compris time, math, ffmpeg de ffmpeg-python, et un module personnalisé nommé WhisperModel de faster_whisper. Ces bibliothèques seront utilisées pour le traitement vidéo et audio, la transcription, et la génération de sous-titres.
Ensuite, le code définit le nom du fichier vidéo d’entrée, le stocke dans une constante nommée input_video, puis stocke le nom du fichier vidéo sans l’extension .mp4 dans une constante nommée input_video_name. Définir le nom du fichier d’entrée ici vous permettra de travailler sur plusieurs vidéos d’entrée sans écraser les fichiers de sous-titres et de sortie générés pour elles.
Ajoutez le code suivant en bas de votre fichier main.py:
Le code ci-dessus définit une fonction nommée extract_audio() qui est responsable de l’extraction de l’audio de la vidéo d’entrée.
Premièrement, il définit le nom de l’audio qui sera extrait en lui ajoutant audio- au nom de base de la vidéo d’entrée avec une extension .wav, et stocke ce nom dans une constante nommée extracted_audio.
Ensuite, le code appelle la méthode ffmpeg.input() de la bibliothèque ffmpeg pour ouvrir la vidéo d’entrée et crée un objet de flux d’entrée nommé stream.
Le code appelle ensuite la méthode ffmpeg.output() pour créer un objet de flux de sortie avec le flux d’entrée et le nom du fichier audio extrait défini.
Après avoir configuré le flux de sortie, le code appelle la méthode ffmpeg.run(), passant le flux de sortie en paramètre pour lancer le processus d’extraction audio et sauvegarder le fichier audio extrait dans le répertoire racine de votre projet. De plus, un paramètre booléen, overwrite_output=True, est inclus pour remplacer tout fichier de sortie préexistant par celui nouvellement généré s’il existe déjà.
Enfin, le code renvoie le nom du fichier audio extrait.
Ajoutez le code suivant en dessous de la fonction extract_audio():
Ici, le code définit une fonction nommée run() puis l’appelle. Cette fonction appelle toutes les fonctions nécessaires pour générer et ajouter des sous-titres à une vidéo.
À l’intérieur de la fonction, le code appelle la fonction extract_audio() pour extraire l’audio d’une vidéo et stocke ensuite le nom du fichier audio retourné dans une variable nommée extracted_audio.
Retournez à votre terminal et exécutez la commande suivante pour exécuter le script main.py :
Après avoir exécuté la commande ci-dessus, la sortie de FFmpeg s’affichera dans le terminal, et un fichier nommé audio-input.wav contenant l’audio extrait de la vidéo d’entrée sera stocké dans le répertoire racine de votre projet.
Revenez à votre fichier main.py et ajoutez le code suivant entre les fonctions extract_audio() et run():
Le code ci-dessus définit une fonction appelée transcribe qui est responsable de la transcription du fichier audio extrait de la vidéo d’entrée.
Tout d’abord, le code crée une instance de l’objet WhisperModel et définit le type de modèle sur small. Les modèles Whisper d’OpenAI sont disponibles en différents types : tiny, base, small, medium et large. Le modèle « tiny » est le plus petit et le plus rapide, tandis que le modèle « large » est le plus grand, le plus lent mais aussi le plus précis.
Ensuite, le code appelle la méthode model.transcribe() avec l’audio extrait comme argument pour récupérer la fonction de segments et les informations audio, qui sont ensuite stockées dans les variables info et segments respectivement. La fonction de segments est un générateur Python, donc la transcription ne commencera que lorsque le code itérera dessus. La transcription peut être exécutée jusqu’à la fin en regroupant les segments dans une liste ou une boucle for.
Ensuite, le code stocke la langue détectée dans l’audio dans une constante nommée info et l’affiche dans la console.
Après avoir imprimé la langue détectée, le code rassemble les segments de transcription dans une liste pour exécuter la transcription et stocke les segments rassemblés dans une variable également appelée segments. Ensuite, le code boucle sur la liste des segments de transcription et imprime le temps de début, le temps de fin et le texte de chaque segment dans la console.
Enfin, le code renvoie la langue détectée dans l’audio et les segments de transcription.
Ajoutez le code suivant à l’intérieur de la fonction run() :
Le code ajouté appelle la fonction transcribe avec l’audio extrait en tant qu’argument et stocke les valeurs renvoyées dans les constantes nommées language et segments.
Retournez à votre terminal et exécutez la commande suivante pour exécuter le script main.py :
La première fois que vous exécutez ce script, le code téléchargera et mettra en cache le modèle Whisper Small, les exécutions ultérieures seront beaucoup plus rapides.
Après avoir exécuté la commande ci-dessus, vous devriez voir la sortie suivante dans la console :
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
La sortie ci-dessus montre que la langue détectée dans l’audio est l’anglais (en). De plus, elle affiche le temps de début et de fin de chaque segment de transcription en secondes, ainsi que le texte.
Avertissement : Bien que la reconnaissance vocale Whisper d’OpenAI soit très précise, elle n’est pas totalement fiable à 100 %, elle peut présenter des limitations et des erreurs occasionnelles, en particulier dans des scénarios linguistiques ou audio complexes. Vérifiez toujours la transcription manuellement.
Dans cette section, vous avez créé un script Python pour l’application. À l’intérieur du script, ffmpeg-python a été utilisé pour extraire l’audio de la vidéo téléchargée et le sauvegarder en tant que fichier WAV. Ensuite, la bibliothèque faster-whisper a été utilisée pour générer une transcription de l’audio extrait. Dans la prochaine section, vous allez générer un fichier de sous-titres basé sur la transcription, puis vous ajouterez les sous-titres à la vidéo.
Étape 3 — Générer et ajouter les sous-titres à la vidéo
Dans cette section, tout d’abord, vous comprendrez ce qu’est un fichier de sous-titres et comment il est structuré. Ensuite, vous utiliserez les segments de transcription générés dans la section précédente pour créer un fichier de sous-titres. Après avoir créé le fichier de sous-titres, vous utiliserez la bibliothèque ffmpeg-python pour ajouter le fichier de sous-titres à une copie de la vidéo d’entrée.
Compréhension des sous-titres : Structure et types
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Index de sous-titre : Un numéro séquentiel indiquant l’ordre du sous-titre dans le fichier.
-
Timecodes : Marqueurs de début et de fin qui spécifient quand le texte des sous-titres doit être affiché. Les timecodes sont généralement formatés comme
HH:MM:SS,sss(heures, minutes, secondes, millisecondes). -
Texte des Sous-titres : Le texte réel de l’entrée des sous-titres, représentant un contenu parlé ou écrit. Ce texte est affiché à l’écran pendant l’intervalle de temps spécifié.
Par exemple, une entrée de sous-titre dans un fichier SRT pourrait ressembler à ceci :
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
Dans cet exemple, l’indice est 1, les timecodes indiquent que le sous-titre doit être affiché de 10.5 secondes à 15 secondes, et le texte des sous-titres est Ceci est un exemple de sous-titre.
Les sous-titres peuvent être divisés en deux types principaux :
-
Sous-titres Doux : Également connus sous le nom de légendes codées, ils sont stockés externe sous forme de fichiers séparés (comme SRT) et peuvent être ajoutés ou supprimés indépendamment de la vidéo. Ils offrent une flexibilité aux spectateurs, permettant de basculer, de changer de langue et de personnaliser les paramètres. Cependant, leur efficacité dépend du support du lecteur vidéo, et tous les lecteurs n’acceptent pas universellement les sous-titres doux.
-
Sous-titres durs : sont intégrés de manière permanente dans les images vidéo lors du montage ou de l’encodage, restant une partie fixe de la vidéo. Bien qu’ils garantissent une visibilité constante, même sur les lecteurs ne prenant pas en charge les fichiers de sous-titres externes, les modifications ou leur désactivation nécessitent une réencodage de l’ensemble de la vidéo, limitant le contrôle de l’utilisateur
Création du fichier de sous-titres
Revenez à votre fichier main.py et ajoutez le code suivant entre les fonctions transcribe() et run():
Voici, le code définit une fonction nommée format_time() qui est responsable de convertir le temps de début et de fin d’un segment de transcription donné en secondes en un format de temps compatible avec les sous-titres qui affiche les heures, les minutes, les secondes et les millisecondes (HH:MM:SS,sss).
Le code calcule d’abord les heures, les minutes, les secondes et les millisecondes à partir du temps donné en secondes, les formate en conséquence, puis renvoie le temps formaté.
Ajoutez le code suivant entre les fonctions format_time() et run():
Le code ajouté définit une fonction nommée generate_subtitle_file() qui prend en paramètres la langue détectée dans l’audio extrait et les segments de transcription. Cette fonction est responsable de générer un fichier de sous-titres SRT en fonction de la langue et des segments de transcription.
Tout d’abord, le code définit le nom du fichier de sous-titres comme un nom formé en ajoutant sub- et la langue détectée au nom de base de la vidéo d’entrée avec l’extension « .srt », et stocke ce nom dans une constante nommée subtitle_file. De plus, le code définit une variable nommée text où vous stockerez les entrées de sous-titres.
Ensuite, le code parcourt les segments transcrits, formate les temps de début et de fin en utilisant la fonction format_time(), utilise ces valeurs formatées ainsi que l’index du segment et le texte pour créer une entrée de sous-titre, puis ajoute une ligne vide pour séparer chaque entrée de sous-titre.
Enfin, le code crée un fichier de sous-titres dans le répertoire racine de votre projet avec le nom défini précédemment, ajoute les entrées de sous-titres au fichier, et retourne le nom du fichier de sous-titres.
Ajoutez le code suivant en bas de votre fonction run():
Le code ajouté appelle la fonction generate_subtitle_file() avec la langue détectée et les segments de transcription comme arguments, et stocke le nom du fichier de sous-titres retourné dans une constante nommée subtitle_file.
Retournez à votre terminal et exécutez la commande suivante pour exécuter le script main.py:
Après avoir exécuté la commande ci-dessus, un fichier de sous-titres nommé sub-input.en.srt sera enregistré dans le répertoire racine de votre projet.
Ouvrez le fichier de sous-titres sub-input.en.srt et vous devriez voir quelque chose de similaire à ce qui suit:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Ajout de sous-titres aux vidéos
Ajoutez le code suivant entre les fonctions generate_subtitle_file() et run():
Ici, le code définit une fonction nommée add_subtitle_to_video() qui prend en paramètres une valeur booléenne utilisée pour déterminer si elle doit ajouter des sous-titres souples ou des sous-titres durs, le nom du fichier de sous-titres, et la langue détectée dans la transcription. Cette fonction est responsable d’ajouter des sous-titres souples ou durs à une copie de la vidéo d’entrée.
Tout d’abord, le code utilise la méthode ffmpeg.input() avec la vidéo d’entrée et le fichier de sous-titres pour créer des objets de flux d’entrée pour la vidéo d’entrée et le fichier de sous-titres, et les stocke dans des constantes nommées respectivement video_input_stream et subtitle_input_stream.
Après avoir créé les flux d’entrée, le code définit le nom du fichier vidéo de sortie en ajoutant output- au nom de base de la vidéo d’entrée avec l’extension « .mp4 », et stocke ce nom dans une constante nommée output_video. De plus, il définit le nom de la piste de sous-titres en utilisant le nom du fichier de sous-titres sans l’extension .srt et stocke ce nom dans une constante nommée subtitle_track_title.
Ensuite, le code vérifie si le booléen soft_subtitle est défini sur True, ce qui indique qu’il doit ajouter un sous-titre souple.
Dans ce cas, le code appelle la méthode ffmpeg.output() pour créer un objet de flux de sortie avec les flux d’entrée, le nom du fichier vidéo de sortie et les options suivantes pour la vidéo de sortie:
-
"c": "copy": Il spécifie que le codec vidéo et les autres paramètres vidéo doivent être copiés directement de l’entrée vers la sortie sans ré-encodage. -
"c:s": "mov_text": Il spécifie que le codec et les paramètres des sous-titres doivent également être copiés de l’entrée à la sortie sans ré-encodage.mov_textest un codec de sous-titres couramment utilisé dans les fichiers MP4/MOV. -
”metadata:s:s:0”: f"language={subtitle_language}": Il définit les métadonnées de langue pour le flux de sous-titres. La langue est définie avec la valeur stockée danssubtitle_language -
"metadata:s:s:0": f"title={subtitle_track_title}": Il définit les métadonnées de titre pour le flux de sous-titres. Le titre est défini avec la valeur stockée danssubtitle_track_title
Enfin, le code appelle la méthode ffmpeg.run(), en passant le flux de sortie en tant que paramètre pour ajouter les sous-titres souples à la vidéo et enregistrer le fichier vidéo de sortie dans le répertoire racine de votre projet.
Ajoutez le code suivant à la fin de votre fonction add_subtitle_to_video() :
Le code surligné s’exécutera si le booléen soft_subtitle est défini sur False, ce qui indique qu’il doit ajouter un sous-titre dur.
Si tel est le cas, tout d’abord, le code appelle la méthode ffmpeg.output() pour créer un objet de flux de sortie avec le flux vidéo d’entrée, le nom du fichier vidéo de sortie et le paramètre vf=f"subtitles={subtitle_file}". Le vf signifie « filtre vidéo » et est utilisé pour appliquer un filtre au flux vidéo. Dans ce cas, le filtre appliqué est l’ajout du sous-titre.
Enfin, le code appelle la méthode ffmpeg.run(), en passant le flux de sortie en tant que paramètre pour ajouter le sous-titre dur à la vidéo et enregistrer le fichier vidéo de sortie dans le répertoire racine de votre projet.
Ajoutez le code surligné suivant à la fonction run():
Le code surligné appelle la méthode add_subtitle_to_video() avec le paramètre soft_subtitle défini sur True, le nom du fichier de sous-titres et la langue des sous-titres pour ajouter un sous-titre souple à une copie de la vidéo d’entrée.
Retournez dans votre terminal et exécutez la commande suivante pour exécuter le script main.py:
Après avoir exécuté la commande ci-dessus, un fichier vidéo de sortie nommé output-input.mp4 sera enregistré dans le répertoire racine de votre projet.
Ouvrez la vidéo à l’aide de votre lecteur vidéo préféré, sélectionnez un sous-titre pour la vidéo et remarquez comment le sous-titre ne sera pas affiché tant que vous ne l’aurez pas sélectionné :
Retournez au fichier main.py, accédez à la fonction run(), et dans l’appel de fonction add_subtitle_to_video(), définissez le paramètre soft_subtitle sur False:
Ici, vous définissez le paramètre soft_subtitle sur False pour ajouter des sous-titres durs à la vidéo.
Retournez dans votre terminal et exécutez la commande suivante pour exécuter le script main.py:
Après avoir exécuté la commande ci-dessus, le fichier vidéo output-input.mp4 situé dans le répertoire principal de votre projet sera écrasé.
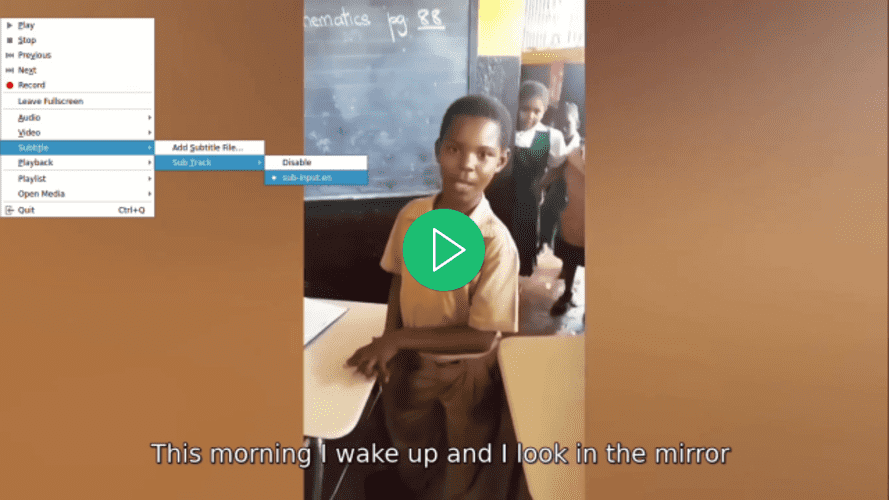
Ouvrez la vidéo à l’aide de votre lecteur vidéo préféré, essayez de sélectionner un sous-titre pour la vidéo, et remarquez comment un sous-titre n’est pas disponible mais un sous-titre est affiché:

Dans cette section, vous avez compris la structure d’un fichier de sous-titres SRT et utilisé les segments de transcription de la section précédente pour en créer un. Ensuite, la bibliothèque ffmpeg-python a été utilisée pour ajouter le fichier de sous-titres généré à la vidéo.
Conclusion
Dans ce tutoriel, vous avez utilisé les bibliothèques Python ffmpeg-python et faster-whisper pour construire une application capable d’extraire l’audio d’une vidéo d’entrée, de transcrire l’audio extrait, de générer un fichier de sous-titres basé sur la transcription, et d’ajouter le sous-titre à une copie de la vidéo d’entrée.