













Dans les premiers jours de l’informatique, les applications géraient les tâches de manière séquentielle. À mesure que l’échelle augmentait avec des millions d’utilisateurs, cette approche est devenue impraticable. Le traitement asynchrone a permis de gérer plusieurs tâches simultanément, mais la gestion des threads/processus sur une seule machine a entraîné des contraintes de ressources et de complexité.
C’est là que le traitement parallèle distribué entre en jeu. En répartissant la charge de travail sur plusieurs machines, chacune dédiée à une partie de la tâche, il offre une solution évolutive et efficace. Si vous avez une fonction pour traiter un grand lot de fichiers, vous pouvez diviser la charge de travail sur plusieurs machines pour traiter les fichiers simultanément au lieu de les gérer séquentiellement sur une seule machine. De plus, cela améliore les performances en tirant parti des ressources combinées et offre évolutivité et tolérance aux pannes. À mesure que les demandes augmentent, vous pouvez ajouter plus de machines pour augmenter les ressources disponibles.
Il est difficile de construire et d’exécuter des applications distribuées à grande échelle, mais il existe plusieurs frameworks et outils pour vous aider. Dans cet article de blog, nous examinerons un de ces frameworks de calcul distribué open-source : Ray. Nous verrons également KubeRay, un opérateur Kubernetes qui permet une intégration transparente de Ray avec des clusters Kubernetes pour le calcul distribué dans des environnements cloud-native. Mais d’abord, comprenons où le parallélisme distribué est utile.
Où le traitement parallèle distribué aide-t-il ?
Toute tâche qui bénéficie de la répartition de sa charge de travail sur plusieurs machines peut utiliser le traitement parallèle distribué. Cette approche est particulièrement utile pour des scénarios tels que le crawling web, l’analyse de données à grande échelle, la formation de modèles d’apprentissage automatique, le traitement de flux en temps réel, l’analyse de données génomiques et le rendu vidéo. En distribuant les tâches sur plusieurs nœuds, le traitement parallèle distribué améliore considérablement les performances, réduit le temps de traitement et optimise l’utilisation des ressources, le rendant essentiel pour les applications nécessitant un débit élevé et une manipulation rapide des données.
Lorsque le traitement parallèle distribué n’est pas nécessaire
- Applications à petite échelle: Pour de petits ensembles de données ou des applications avec des besoins de traitement minimes, les frais généraux liés à la gestion d’un système distribué peuvent ne pas être justifiés.
- Fortes dépendances de données: Si les tâches sont fortement interdépendantes et ne peuvent pas être facilement parallélisées, le traitement distribué peut offrir peu d’avantages.
- Contraintes en temps réel: Certaines applications en temps réel (par exemple, la finance et les sites de réservation de billets) nécessitent une latence extrêmement faible, ce qui pourrait ne pas être réalisable avec la complexité ajoutée d’un système distribué.
- Ressources limitées: Si l’infrastructure disponible ne peut pas supporter les frais généraux d’un système distribué (par exemple, bande passante réseau insuffisante, nombre limité de nœuds), il peut être préférable d’optimiser les performances d’une seule machine.
Comment Ray aide avec le traitement parallèle distribué
Ray est un cadre de traitement parallèle distribué qui encapsule tous les avantages de l’informatique distribuée et les solutions aux défis que nous avons discutés, tels que la tolérance aux pannes, l’évolutivité, la gestion du contexte, la communication, etc. C’est un cadre Pythonique, permettant l’utilisation de bibliothèques et de systèmes existants pour y travailler. Avec l’aide de Ray, un programmeur n’a pas besoin de gérer les éléments de la couche de calcul de traitement parallèle. Ray s’occupera de la planification et de l’autoscaling en fonction des exigences de ressources spécifiées.
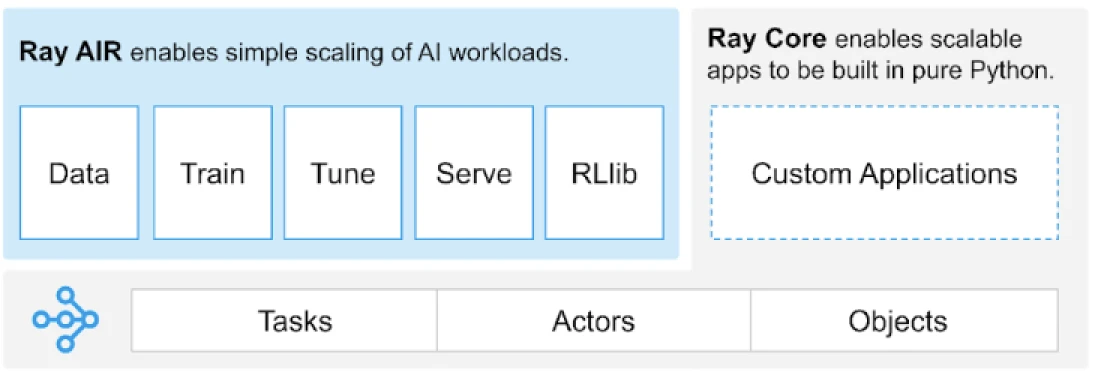
Ray fournit une API universelle de tâches, d’acteurs et d’objets pour construire des applications distribuées.
(Source de l’image)
Ray fournit un ensemble de bibliothèques construites sur les primitives fondamentales, c’est-à-dire, Tâches, Acteurs, Objets, Conducteurs et Travaux. Celles-ci offrent une API polyvalente pour aider à construire des applications distribuées. Jetons un coup d’œil aux primitives fondamentales, également connues sous le nom de Ray Core.
Primitives de Ray Core
- Tâches : Les tâches Ray sont des fonctions Python arbitraires qui sont exécutées de manière asynchrone sur des travailleurs Python séparés sur un nœud de cluster Ray. Les utilisateurs peuvent spécifier leurs exigences en ressources en termes de CPU, GPU et ressources personnalisées, qui sont utilisées par le planificateur de cluster pour distribuer les tâches pour une exécution parallélisée.
- Acteurs : Ce que les tâches sont pour les fonctions, les acteurs le sont pour les classes. Un acteur est un travailleur avec état, et les méthodes d’un acteur sont programmées sur ce travailleur spécifique et peuvent accéder et modifier l’état de ce travailleur. Comme les tâches, les acteurs prennent en charge les exigences en ressources CPU, GPU et personnalisées.
- Objets : Dans Ray, les tâches et les acteurs créent et calculent des objets. Ces objets distants peuvent être stockés n’importe où dans un cluster Ray. Les Références d’Objets sont utilisées pour y faire référence, et elles sont mises en cache dans le magasin d’objets de mémoire partagée distribuée de Ray.
- Conducteurs : La racine du programme, ou le programme « principal » : c’est le code qui exécute
ray.init() - Travaux : La collection de tâches, d’objets et d’acteurs provenant (récursivement) du même conducteur et de leur environnement d’exécution
Pour des informations sur les primitives, vous pouvez consulter la documentation Ray Core.
Principales Méthodes de Ray Core
Voici quelques-unes des méthodes clés dans Ray Core qui sont couramment utilisées :
-
ray.init()– Démarrer l’exécution de Ray et se connecter au cluster Ray.import ray ray.init()
-
@ray.remote– Décorateur qui spécifie une fonction ou une classe Python à exécuter en tant que tâche (fonction distante) ou acteur (classe distante) dans un processus différent@ray.remote def remote_function(x): return x * 2
-
.remote– Suffixe pour les fonctions et classes distantes ; les opérations distantes sont asynchronesresult_ref = remote_function.remote(10)
-
ray.put()– Mettre un objet dans le magasin d’objets en mémoire ; retourne une référence d’objet utilisée pour passer l’objet à toute fonction ou méthode distante.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Obtenir un ou plusieurs objets distants du magasin d’objets en spécifiant les références d’objet.result = ray.get(result_ref) original_data = ray.get(data_ref)
Voici un exemple d’utilisation de la plupart des méthodes clés de base :
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Utilisation de .remote pour créer une tâche
future = calculate_square.remote(5)
# Obtenir le résultat
result = ray.get(future)
print(f"The square of 5 is: {result}")Comment Ray fonctionne-t-il ?
Le cluster Ray est comme une équipe d’ordinateurs qui partagent le travail d’exécution d’un programme. Il se compose d’un nœud principal et de plusieurs nœuds travailleurs. Le nœud principal gère l’état du cluster et la planification, tandis que les nœuds travailleurs exécutent des tâches et gèrent les acteurs
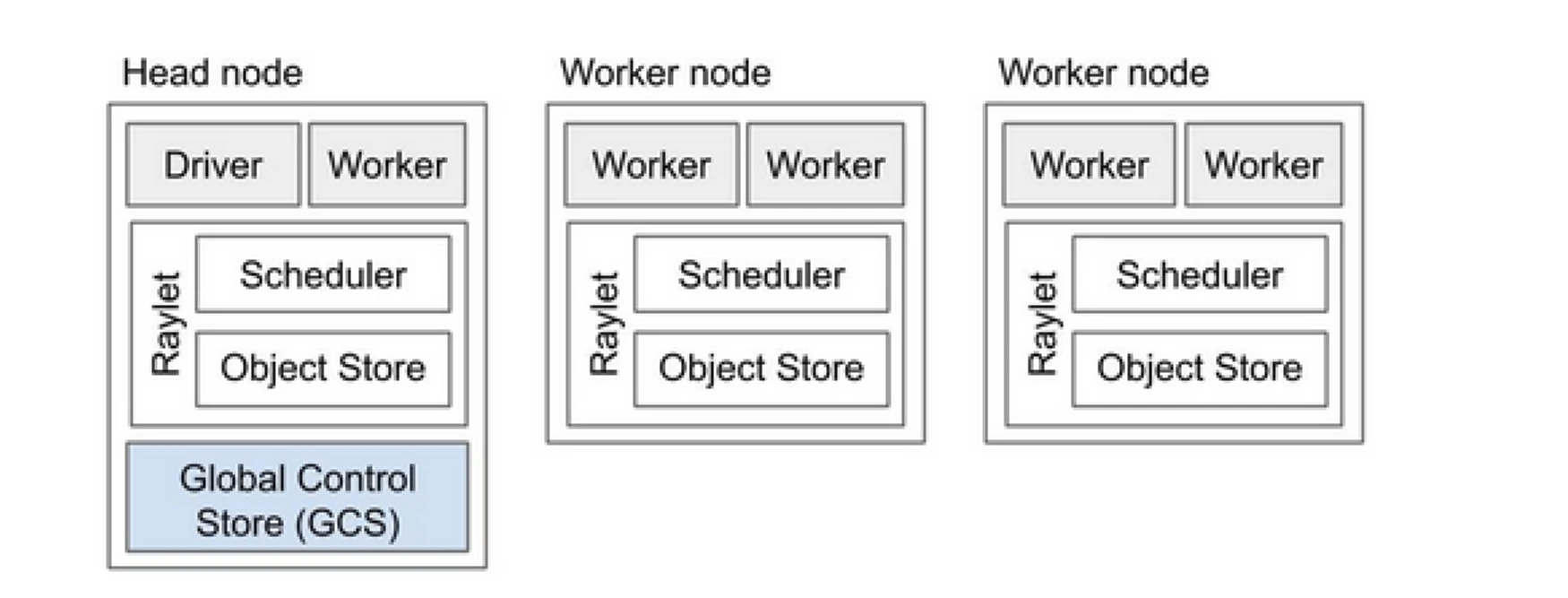
Composants du cluster Ray
- Global Control Store (GCS) : Le GCS gère les métadonnées et l’état global du cluster Ray. Il suit les tâches, les acteurs et la disponibilité des ressources, garantissant que tous les nœuds ont une vue cohérente du système.
- Planificateur : Le planificateur répartit les tâches et les acteurs sur les nœuds disponibles. Il assure une utilisation efficace des ressources et un équilibrage de charge en tenant compte des exigences en ressources et des dépendances des tâches.
- Nœud principal : Le nœud principal orchestre l’ensemble du cluster Ray. Il exécute le GCS, gère la planification des tâches et surveille la santé des nœuds travailleurs.
- Nœuds travailleurs : Les nœuds travailleurs exécutent des tâches et des acteurs. Ils effectuent les calculs réels et stockent des objets dans leur mémoire locale.
- Raylet : Il gère les ressources partagées sur chaque nœud et est partagé entre tous les travaux en cours d’exécution.
Vous pouvez consulter le document sur l’architecture Ray v2 pour des informations plus détaillées.
Travailler avec des applications Python existantes ne nécessite pas beaucoup de changements. Les changements nécessaires seraient principalement autour de la fonction ou de la classe qui doit être distribuée naturellement. Vous pouvez ajouter un décorateur et le convertir en tâches ou en acteurs. Voyons un exemple de cela.
Conversion d’une fonction Python en tâche Ray
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Conversion d’une classe Python en acteur Ray
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Stockage d’informations dans des objets Ray
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Pour en savoir plus sur son concept, consultez la documentation sur le Concept clé de base de Ray.
Ray par rapport à l’approche traditionnelle du traitement parallèle distribué
Voici une analyse comparative entre l’approche traditionnelle (sans Ray) et Ray sur Kubernetes pour permettre le traitement parallèle distribué.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Déploiement | Configuration et installation manuelles | Automatisé avec l’opérateur KubeRay |
| Scalabilité | Évolutivité manuelle | Évolutivité automatique avec RayAutoScaler et Kubernetes |
| Tolérance aux pannes | Mécanismes de tolérance aux pannes personnalisés | Tolérance aux pannes intégrée avec Kubernetes et Ray |
| Gestion des ressources | Allocation manuelle des ressources | Allocation et gestion automatisées des ressources |
| Équilibrage de charge | Solutions d’équilibrage de charge personnalisées | Équilibrage de charge intégré avec Kubernetes |
| Gestion des dépendances | Installation manuelle des dépendances | Environnement cohérent avec des conteneurs Docker |
| Coordination de cluster | Complexité et manuel | Simplifié avec la découverte de services et la coordination de Kubernetes |
| Surcharge de développement | Élevée, avec des solutions personnalisées nécessaires | Réduite, avec Ray et Kubernetes gérant de nombreux aspects |
| Flexibilité | Adaptabilité limitée aux charges de travail changeantes | Grande flexibilité avec mise à l’échelle dynamique et allocation de ressources |
Kubernetes fournit une plateforme idéale pour exécuter des applications distribuées comme Ray en raison de ses capacités d’orchestration robustes. Voici les principaux points qui définissent la valeur de l’exécution de Ray sur Kubernetes:
- Gestion des ressources
- Scalabilité
- Orchestration
- Intégration avec l’écosystème
- Déploiement et gestion faciles
L’opérateur KubeRay rend possible l’exécution de Ray sur Kubernetes.
Qu’est-ce que KubeRay?
L’opérateur KubeRay simplifie la gestion des clusters Ray sur Kubernetes en automatisant des tâches telles que le déploiement, la mise à l’échelle et la maintenance. Il utilise les Définitions de Ressources Personnalisées (CRDs) de Kubernetes pour gérer les ressources spécifiques à Ray.
CRDs KubeRay
Il a trois CRD distincts :
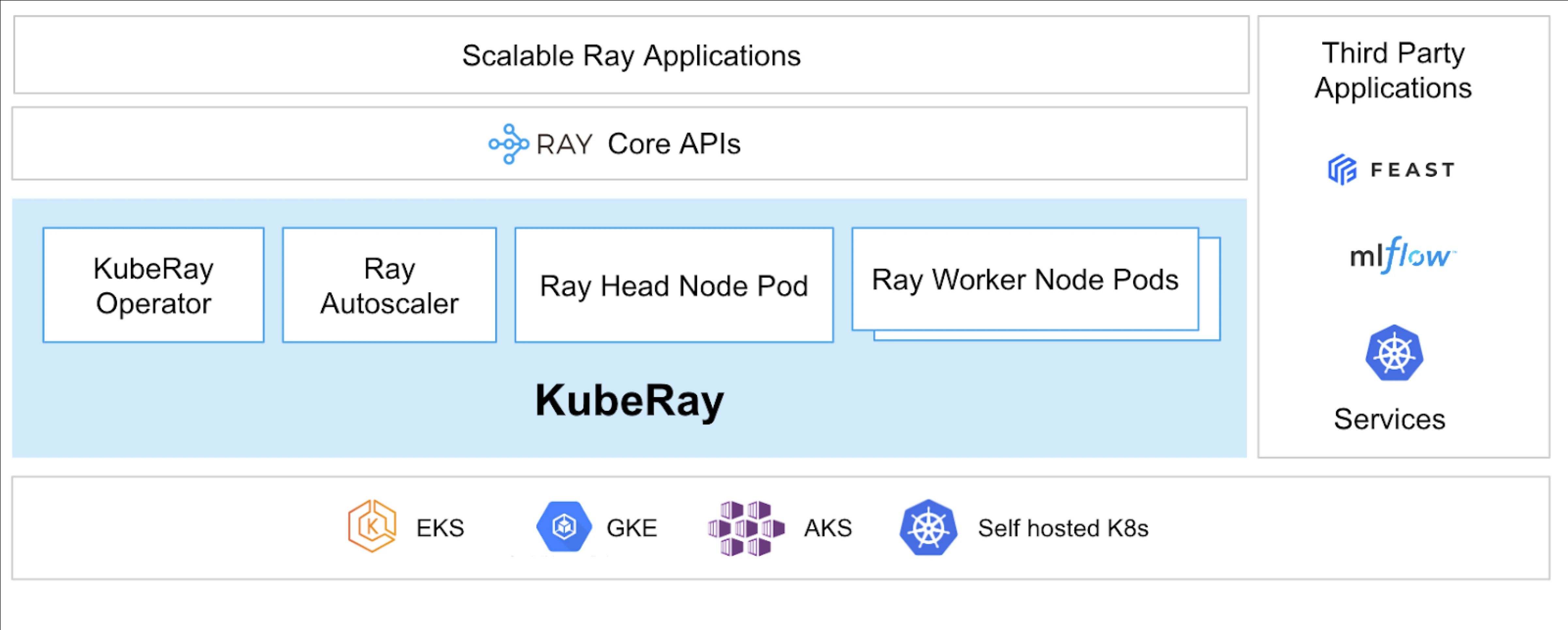
- RayCluster : Ce CRD permet de gérer le cycle de vie de RayCluster et prend en charge l’auto-scaling en fonction de la configuration définie.
- RayJob : Il est utile lorsqu’il y a un travail ponctuel que vous souhaitez exécuter au lieu de maintenir en permanence un RayCluster en attente. Il crée un RayCluster et soumet le travail lorsque celui-ci est prêt. Une fois le travail terminé, il supprime le RayCluster. Cela permet de recycler automatiquement le RayCluster.
- RayService : Cela crée également un RayCluster mais déploie une application RayServe dessus. Ce CRD permet d’effectuer des mises à jour sur place de l’application, offrant des mises à niveau et des mises à jour sans interruption pour garantir la disponibilité élevée de l’application.
Cas d’utilisation de KubeRay
Déploiement d’un modèle à la demande à l’aide de RayService
RayService vous permet de déployer des modèles à la demande dans un environnement Kubernetes. Cela peut être particulièrement utile pour des applications telles que la génération d’images ou l’extraction de texte, où les modèles sont déployés uniquement lorsque cela est nécessaire.
Voici un exemple de diffusion stable. Une fois appliqué dans Kubernetes, il créera RayCluster et exécutera également un RayService, qui servira le modèle jusqu’à ce que vous supprimiez cette ressource. Cela permet aux utilisateurs de prendre le contrôle des ressources.
Formation d’un Modèle sur un Cluster GPU en Utilisant RayJob
RayService répond à différents besoins de l’utilisateur, où il maintient le modèle ou l’application déployé jusqu’à ce qu’il soit supprimé manuellement. En revanche, RayJob permet des tâches ponctuelles pour des cas d’utilisation tels que la formation d’un modèle, le prétraitement des données ou l’inférence pour un nombre fixe de requêtes données.
Exécuter un Serveur d’Inférence sur Kubernetes en Utilisant RayService ou RayJob
En général, nous exécutons notre application dans des Déploiements, ce qui maintient les mises à jour progressives sans temps d’arrêt. De même, dans KubeRay, cela peut être réalisé en utilisant RayService, qui déploie le modèle ou l’application et gère les mises à jour progressives.
Cependant, il peut y avoir des cas où vous souhaitez simplement effectuer une inférence par lot au lieu de faire fonctionner les serveurs d’inférence ou les applications pendant une longue période. C’est ici que vous pouvez tirer parti de RayJob, qui est similaire à la ressource Job de Kubernetes.
Inférence par Lot pour la Classification d’Images avec Huggingface Vision Transformer est un exemple de RayJob, qui effectue une inférence par lot.
Voici les cas d’utilisation de KubeRay, vous permettant d’en faire plus avec le cluster Kubernetes. Avec l’aide de KubeRay, vous pouvez exécuter des charges de travail mixtes sur le même cluster Kubernetes et déléguer la planification des charges de travail basées sur GPU à Ray.
Conclusion
Le traitement parallèle distribué offre une solution évolutive pour gérer des tâches à grande échelle et gourmandes en ressources. Ray simplifie les complexités de la construction d’applications distribuées, tandis que KubeRay intègre Ray avec Kubernetes pour un déploiement et une mise à l’échelle sans couture. Cette combinaison améliore la performance, l’évolutivité et la tolérance aux pannes, ce qui la rend idéale pour le web crawling, l’analyse de données et les tâches d’apprentissage machine. En tirant parti de Ray et KubeRay, vous pouvez gérer efficacement le calcul distribué, répondant ainsi aux exigences du monde axé sur les données d’aujourd’hui avec aisance.
Non seulement cela, mais alors que nos types de ressources de calcul évoluent des CPU vers des GPU, il devient important d’avoir une infrastructure cloud efficace et évolutive pour toutes sortes d’applications, qu’il s’agisse d’IA ou de traitement de grandes données.
Si vous avez trouvé cet article informatif et engageant, j’aimerais connaître vos réflexions à ce sujet, alors n’hésitez pas à engager la conversation sur LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray