













Les systèmes RAG combinent la puissance des mécanismes de récupération et des modèles linguistiques, et permettent de générer des réponses pertinentes et bien ancrées dans le contexte. Cependant, évaluer les performances et identifier les modes de défaillance potentiels des systèmes RAG peut être très difficile.
D’où l’idée du RAG Triad – un ensemble de trois métriques qui couvrent les trois principales étapes de l’exécution d’un système RAG : Pertinence du Contexte, Ancrage, et Pertinence de la Réponse. Dans cet article de blog, je vais vous expliquer les subtilités du RAG Triad et vous guider dans le processus de configuration, d’exécution et d’analyse de l’évaluation d’un système RAG.
Introduction au RAG Triad:
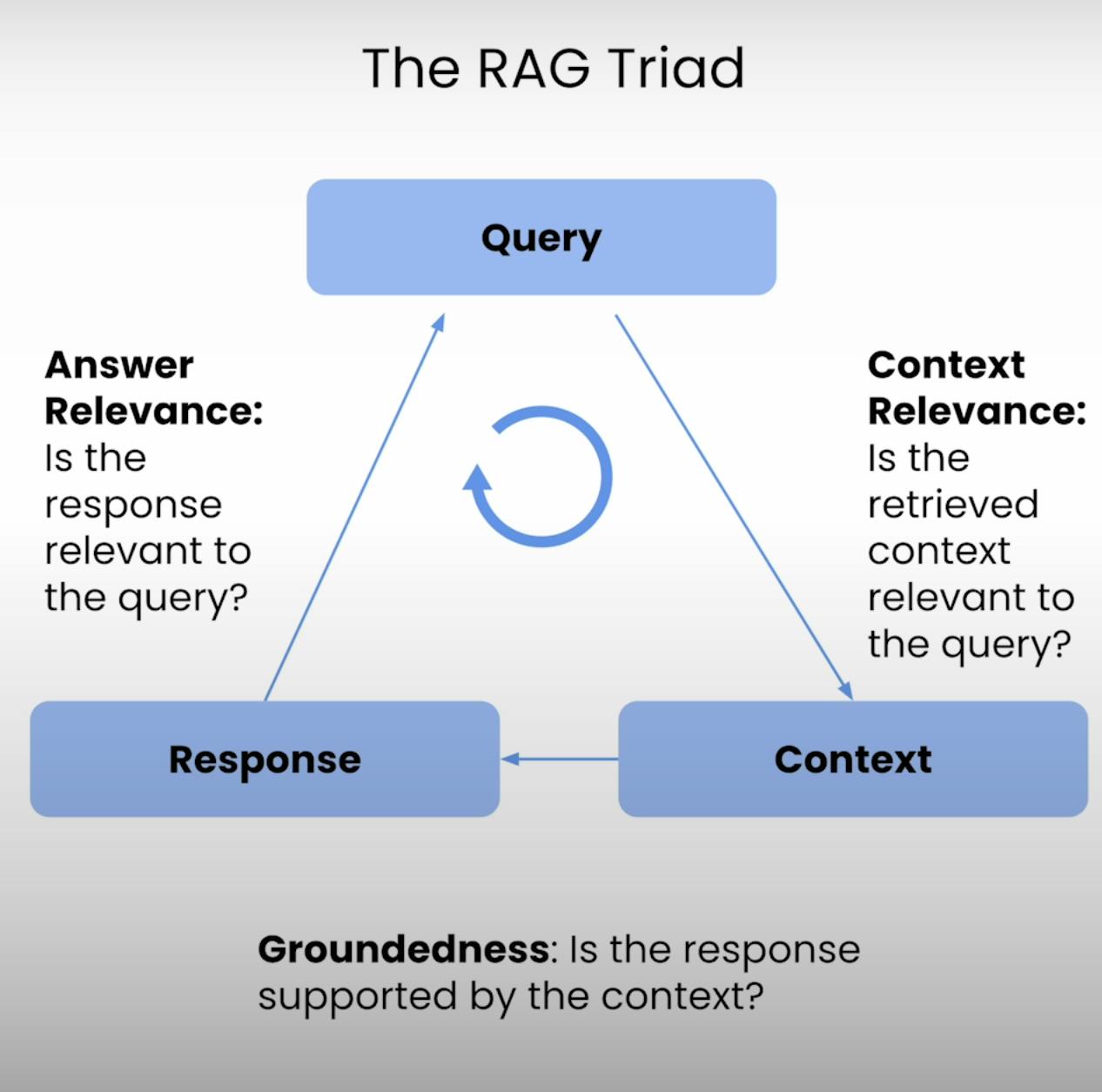
Au cœur de chaque système RAG se trouve un équilibre délicat entre la récupération et la génération. Le RAG Triad fournit un cadre global pour évaluer la qualité et les modes de défaillance potentiels de cet équilibre. Décomposons les trois composantes.
A. Context Relevance:
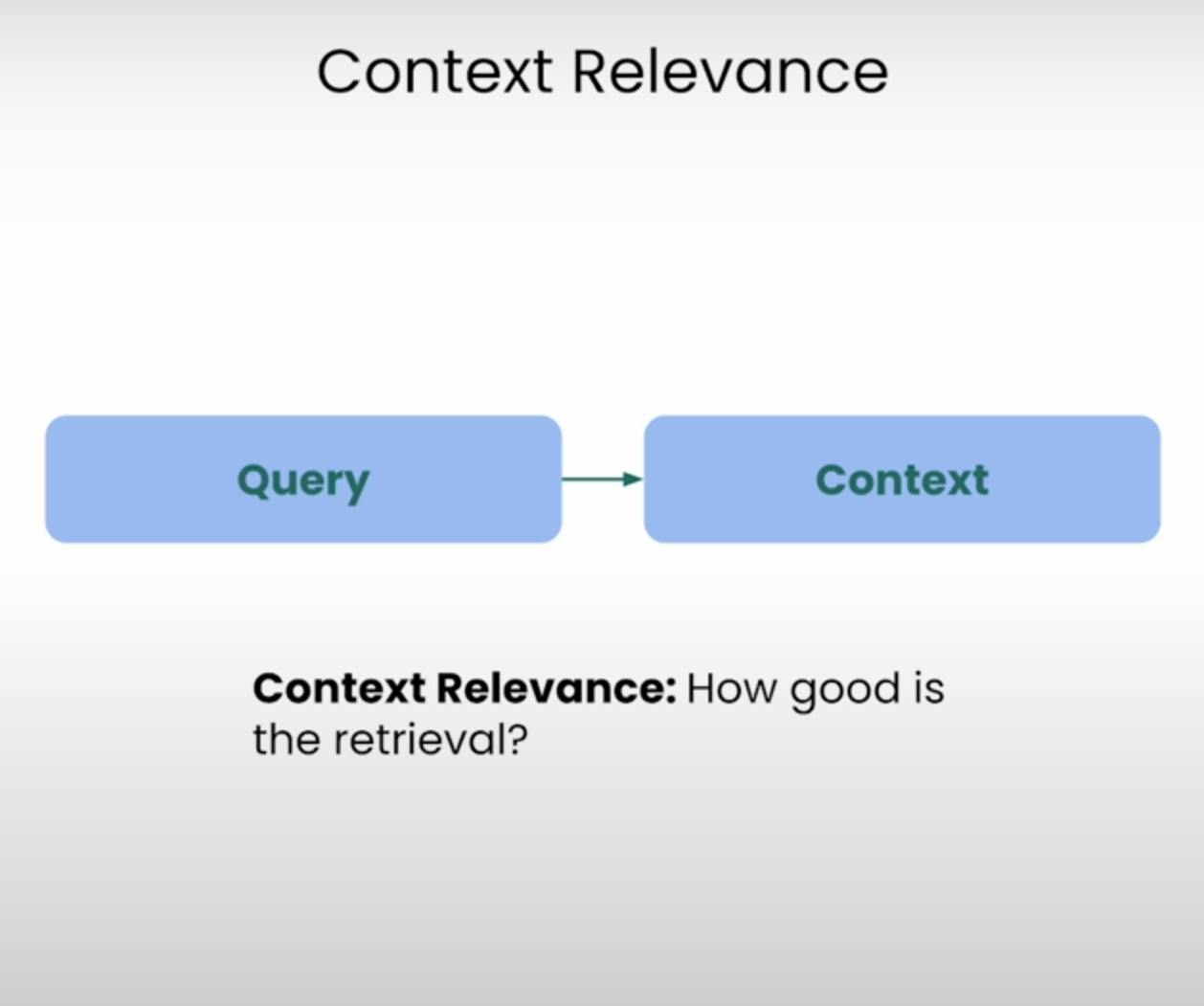
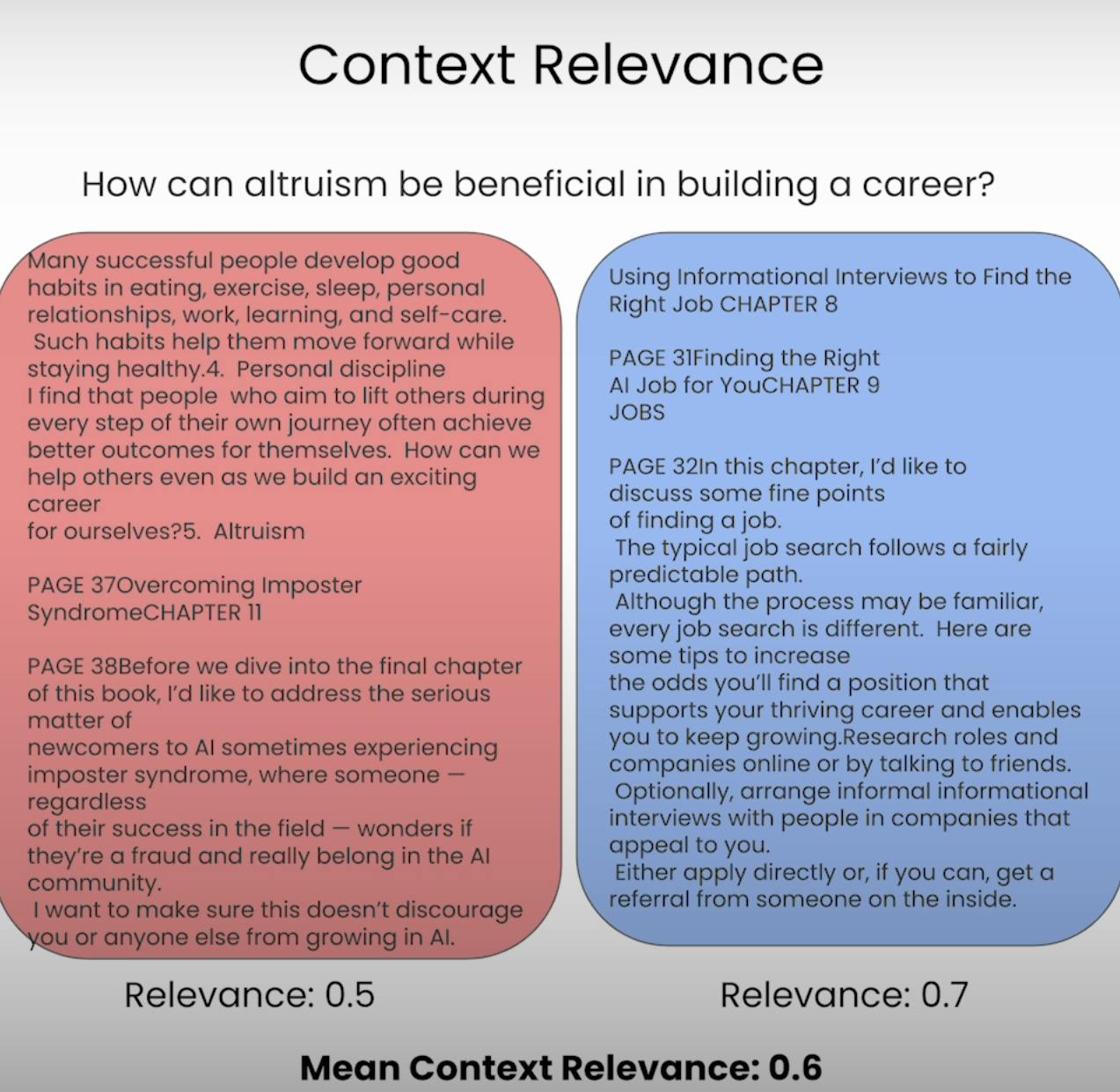
Imaginons être censé répondre à une question, mais que l’information fournie soit totalement sans rapport. C’est précisément ce que vise à éviter un système RAG. La Pertinence du Contexte évalue la qualité du processus de récupération en examinant à quel point chaque élément de contexte récupéré est pertinent par rapport à la requête initiale. En notant la pertinence du contexte récupéré, nous pouvons identifier d’éventuels problèmes dans le mécanisme de récupération et apporter les ajustements nécessaires.

B. Groundedness:
Avez-vous déjà eu une conversation où quelqu’un semblait inventer des faits ou fournir des informations sans fondement solide? C’est l’équivalent d’un système RAG manquant de solvabilité. La solvabilité évalue si la réponse finale générée par le système est bien ancrée dans le contexte récupéré. Si la réponse contient des déclarations ou des affirmations qui ne sont pas soutenues par les informations récupérées, le système peut être en train de halluciner ou trop dépendre de ses données de pré-entraînement, ce qui peut entraîner des inexactitudes ou des biais.
C. Answer Relevance:
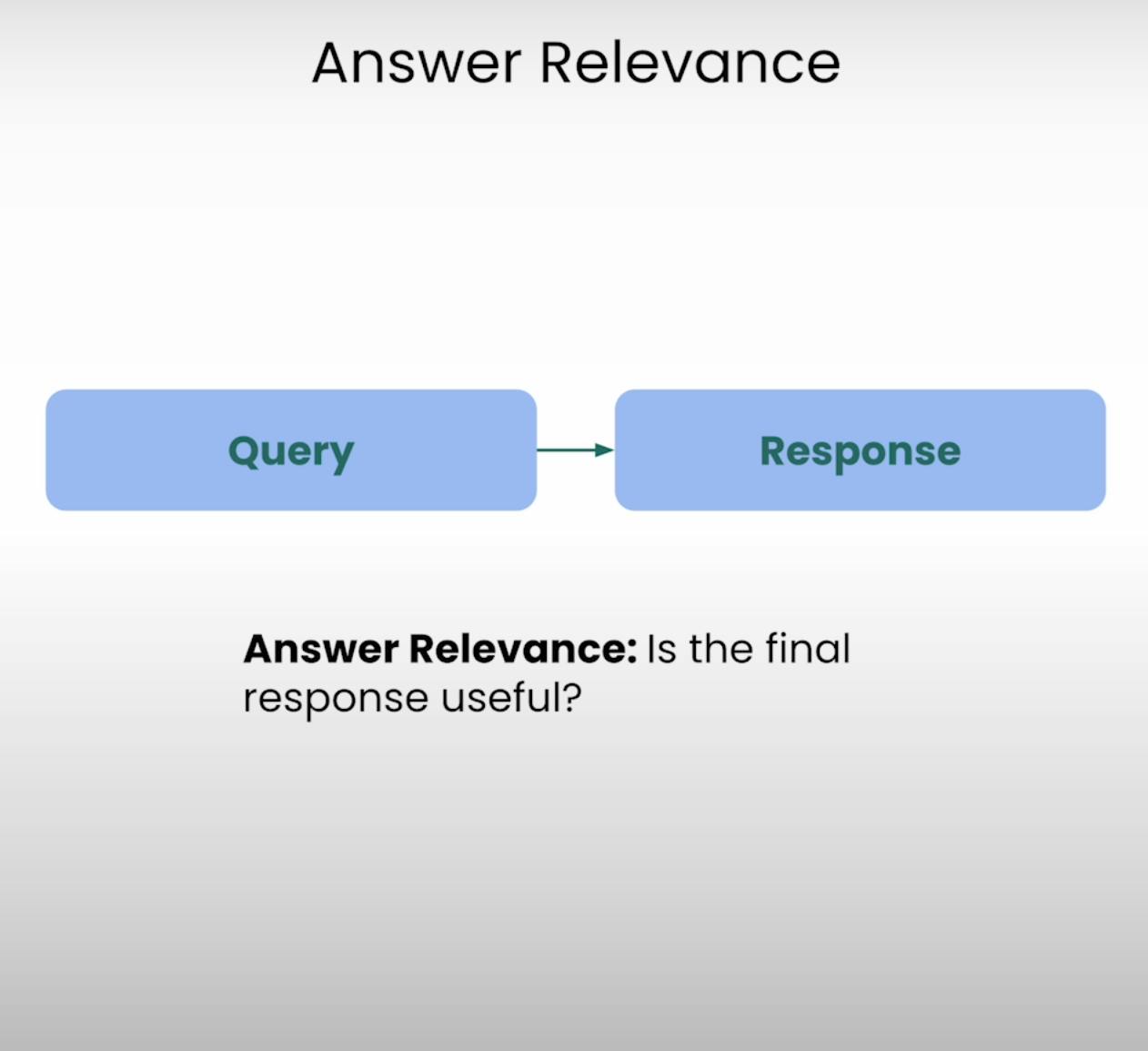
Imaginez demander des directions vers le café le plus proche et recevoir une recette détaillée pour cuisiner un gâteau. C’est le genre de situation que la pertinence des réponses vise à prévenir. Cette composante du RAG Triad évalue si la réponse finale générée par le système est vraiment pertinente par rapport à la requête initiale. En évaluant la pertinence de la réponse, nous pouvons identifier les cas où le système peut avoir mal compris la question ou s’être écarté du sujet intentionnel.

Configuration de l’évaluation du RAG Triad
Avant de pouvoir plonger dans le processus d’évaluation, nous devons poser les bases. Passons en revue les étapes nécessaires pour mettre en place l’évaluation du RAG Triad.
A. Importing Libraries and Establishing API Keys:
Tout d’abord, nous devons importer les bibliothèques et modules requis, y compris la clé API d’OpenAI et le fournisseur LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
Ensuite, nous chargerons et indexerons le corpus de documents sur lequel notre système RAG travaillera. Dans notre cas, nous utiliserons un document PDF intitulé « Comment construire une carrière dans l’IA » par Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

Au cœur de l’évaluation du RAG Triad se trouvent les fonctions de feedback – des fonctions spécialisées qui évaluent chaque composant du triade. Définissons ces fonctions en utilisant la bibliothèque TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Exécution de l’application et de l’évaluation RAG
Avec la configuration terminée, il est temps de mettre notre système RAG et le cadre d’évaluation en action. Passons en revue les étapes impliquées dans l’exécution de l’application et l’enregistrement des résultats de l’évaluation.
A. Preparing the Evaluation Questions:
Premièrement, nous chargerons un ensemble de questions d’évaluation que nous voulons que notre système RAG réponde. Ces questions serviront de base à notre processus d’évaluation.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Ensuite, nous configurerons l’enregistreur TruLens, qui nous aidera à enregistrer les prompts, les réponses et les résultats de l’évaluation dans une base de données locale.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
Alors que l’application RAG s’exécute sur chaque question d’évaluation, l’enregistreur TruLens capturera diligentement les prompts, les réponses, les résultats intermédiaires et les scores d’évaluation, les stockant dans une base de données locale pour une analyse ultérieure.
Analyse des résultats de l’évaluation
Avec les données d’évaluation à portée de main, il est temps d’examiner l’analyse et d’obtenir des informations. Regardons diverses façons d’analyser les résultats et d’identifier les domaines potentiels d’amélioration.
A. Examining Individual Record-Level Results:
Parfois, le diable est dans les détails. En examinant les résultats au niveau des enregistrements individuels, nous pouvons mieux comprendre les forces et les faiblesses de notre système RAG.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Ce fragment de code nous donne accès aux prompts, réponses et scores d’évaluation pour chaque enregistrement individuel, nous permettant d’identifier des cas spécifiques où le système a peut-être lutté ou excellé.
B. Viewing Aggregate Performance Metrics:
Reprenons du recul et jetons un oeil à la situation dans son ensemble. La bibliothèque TrueLens nous offre un classement qui agrège les indicateurs de performance à travers tous les enregistrements, nous donnant ainsi une vue d’ensemble de la performance globale de notre système RAG.
tru.get_leaderboard(app_ids=[])
Ce classement affiche les scores moyens pour chaque composante du Triade RAG, ainsi que des indicateurs tels que la latence et le coût. En analysant ces indicateurs agrégés, nous pouvons identifier des tendances et des schémas qui pourraient ne pas être évidents au niveau des enregistrements.
C. Exploring the TrueLens Streamlit Dashboard:
En plus de l’interface en ligne de commande (CLI), TrueLens propose également un tableau de bord Streamlit qui offre une interface graphique pour explorer et analyser les résultats de l’évaluation. Avec quelques commandes simples, nous pouvons lancer le tableau de bord.
tru.run_dashboard()
Une fois le tableau de bord opérationnel, nous obtenons une vue d’ensemble complète de la performance de notre système RAG. À première vue, nous pouvons voir les indicateurs agrégés pour chaque composante du Triade RAG, ainsi que les informations sur la latence et le coût.
En sélectionnant notre application dans le menu déroulant, nous pouvons accéder à une vue détaillée au niveau des enregistrements des résultats de l’évaluation. Chaque enregistrement est soigneusement présenté, avec l’invite d’entrée de l’utilisateur, la réponse du système RAG et les scores correspondants pour la Pertinence de la Réponse, la Pertinence du Contexte et la Groundedness.
En cliquant sur un enregistrement individuel, nous découvrons davantage d’insights. Nous pouvons explorer la chaîne de raisonnement derrière chaque score d’évaluation, expliquant le processus de pensée du modèle de langage effectuant l’évaluation. Ce niveau de transparence est utile pour identifier d’éventuelles modes de défaillance et des domaines d’amélioration.
Supposons que nous rencontrions un enregistrement où le score de Groundedness est faible. En examinant les détails, nous pourrions découvrir que la réponse du système RAG contient des affirmations qui ne sont pas bien ancrées dans le contexte récupéré. Le tableau de bord nous montrera exactement quelles affirmations manquent de preuves à l’appui, nous permettant de localiser la cause racine du problème.
Le tableau de bord TrueLens Streamlit est plus qu’un simple outil de visualisation. En utilisant ses capacités interactives et les insights basés sur les données, nous pouvons prendre des décisions éclairées et des mesures ciblées pour améliorer la performance de nos applications.
Techniques RAG Avancées et Amélioration Itérative
A. Introducing the Sentence Window RAG Technique:
Une technique avancée est la Sentence Window RAG, qui traite un mode de défaillance courant des systèmes RAG : taille de contexte limitée. En augmentant la taille de la fenêtre de contexte, la Sentence Window RAG vise à fournir au modèle de langue des informations plus pertinentes et exhaustives, potentiellement améliorant la pertinence du contexte et la Groundedness du système.
B. Re-evaluating with the RAG Triad:
Après avoir mis en œuvre la technique Sentence Window RAG, nous pouvons la soumettre à un test en l’évaluant à nouveau à l’aide du même cadre RAG Triad. Cette fois, nous nous concentrerons sur les scores de Pertinence du Contexte et de Groundedness, en recherchant des améliorations dans ces domaines en raison de la taille de contexte augmentée.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Bien que la technique Sentence Window RAG puisse potentiellement améliorer la performance, la taille de fenêtre optimale peut varier en fonction du cas d’utilisation et du jeu de données spécifiques. Une taille de fenêtre trop petite peut ne pas fournir suffisamment de contexte pertinent, tandis qu’une taille de fenêtre trop grande pourrait introduire des informations non pertinentes, affectant la Groundedness et la Pertinence de la réponse du système.
En expérimentant avec différentes tailles de fenêtres et en réévaluant en utilisant le RAG Triad, nous pouvons trouver le point optimal qui balance la pertinence du contexte avec la pertinence et la pertinence des réponses, conduisant finalement à un système RAG plus robuste et fiable.
Conclusion:
Le RAG Triad, composé de Pertinence du Contexte, Groundedness et Pertinence des Réponses, s’est avéré être un cadre utile pour évaluer les performances et identifier les modes de défaillance potentiels des systèmes de génération augmentée par récupération.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems