













Votre direction souhaite-t-elle tout savoir sur les finances et la productivité de votre entreprise mais refuse de dépenser un centime pour des outils de gestion informatique de qualité supérieure ? Ne vous retrouvez pas à utiliser différents outils pour la gestion des stocks, la facturation et les systèmes de billetterie. Vous avez seulement besoin d’un système centralisé. Pourquoi ne pas envisager Power BI Python ?
Power BI peut transformer des tâches fastidieuses et chronophages en processus automatisés. Et dans ce tutoriel, vous apprendrez comment découper et combiner vos données de manière inimaginable.
Allez-y et épargnez-vous le stress de parcourir des rapports complexes à l’œil nu !
Prérequis
Ce tutoriel sera une démonstration pratique. Si vous souhaitez suivre, assurez-vous de disposer des éléments suivants :
- Un abonnement Power BI – L’essai gratuit suffira.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop installé sur votre serveur Windows – Ce tutoriel utilise Power BI Desktop v2.105.664.0.
- MySQL Server installé – Ce tutoriel utilise MySQL Server v8.0.29.
- Une passerelle de données locale installée sur les appareils externes prévoyant d’utiliser une version Desktop.
- Visual Studio Code (VS Code) – Ce tutoriel utilise VS Code v17.2
- Python v3.6 ou version ultérieure installé – Ce tutoriel utilise Python v3.10.5.
- DBeaver installé – Ce tutoriel utilise DBeaver v22.0.2.
Construction d’une base de données MySQL
Power BI peut magnifiquement visualiser les données, mais vous devez les récupérer et les stocker avant d’arriver à la visualisation des données. L’une des meilleures façons de stocker les données est dans une base de données. MySQL est un outil de base de données gratuit et puissant.
1. Ouvrez l’invite de commande en tant qu’administrateur, exécutez la commande mysql ci-dessous et saisissez le nom d’utilisateur racine (-u) et le mot de passe (-p) lorsqu’on vous le demande.
Par défaut, seul l’utilisateur root a l’autorisation d’apporter des modifications à la base de données.
2. Ensuite, exécutez la requête ci-dessous pour créer un nouvel utilisateur de base de données (CREATE USER) avec un mot de passe (IDENTIFIED BY). Vous pouvez nommer l’utilisateur différemment, mais le choix de ce tutoriel est ata_levi.

3. Après avoir créé un utilisateur, exécutez la requête ci-dessous pour ACCORDER les permissions au nouvel utilisateur (ALL PRIVILEGES), telles que la création d’une base de données sur le serveur.

4. Maintenant, exécutez la commande \q ci-dessous pour vous déconnecter de MySQL.

5. Exécutez la commande mysql ci-dessous pour vous connecter en tant qu’utilisateur de base de données nouvellement créé (ata_levi).
6. Enfin, exécutez la requête suivante pour CRÉER une nouvelle BASE DE DONNÉES appelée ata_database. Mais bien sûr, vous pouvez nommer la base de données différemment.

Gestion des bases de données MySQL avec DBeaver
Dans la gestion des bases de données, vous avez généralement besoin de connaissances SQL. Mais avec DBeaver, vous avez une interface graphique pour gérer vos bases de données en quelques clics, et DBeaver se chargera des déclarations SQL pour vous.
1. Ouvrez DBeaver depuis votre bureau ou le menu Démarrer.
2. Lorsque DBeaver s’ouvre, cliquez sur la liste déroulante Nouvelle connexion de base de données et sélectionnez MySQL pour initier la connexion à votre serveur MySQL.
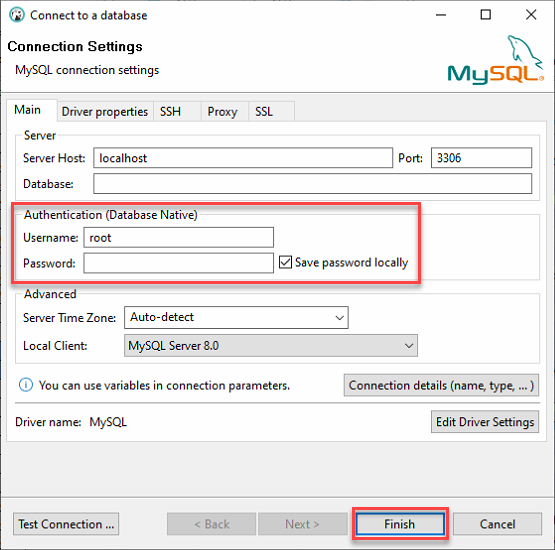
3. Connectez-vous à votre serveur MySQL local avec les informations suivantes :
- Conservez le Hôte du serveur comme localhost et le Port à 3306 car vous vous connectez à un serveur local.
- Fournissez les identifiants de l’utilisateur ata_levi (Nom d’utilisateur et Mot de passe) provenant de l’étape deux de la section « Construction d’une base de données MySQL », puis cliquez sur Terminer pour vous connecter à MySQL.
4. Maintenant, développez votre base de données (ata_database) dans le navigateur de base de données (panneau de gauche) → faites un clic droit sur Tables, puis sélectionnez Créer une nouvelle table pour initier la création d’une nouvelle table.
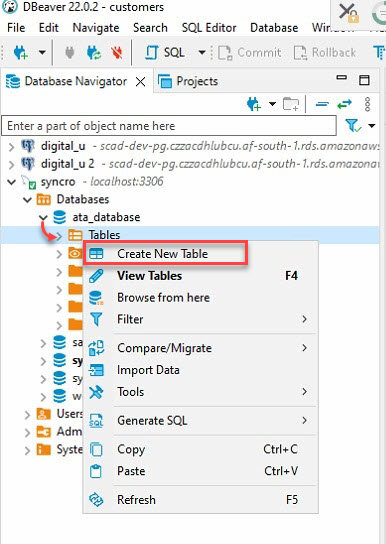
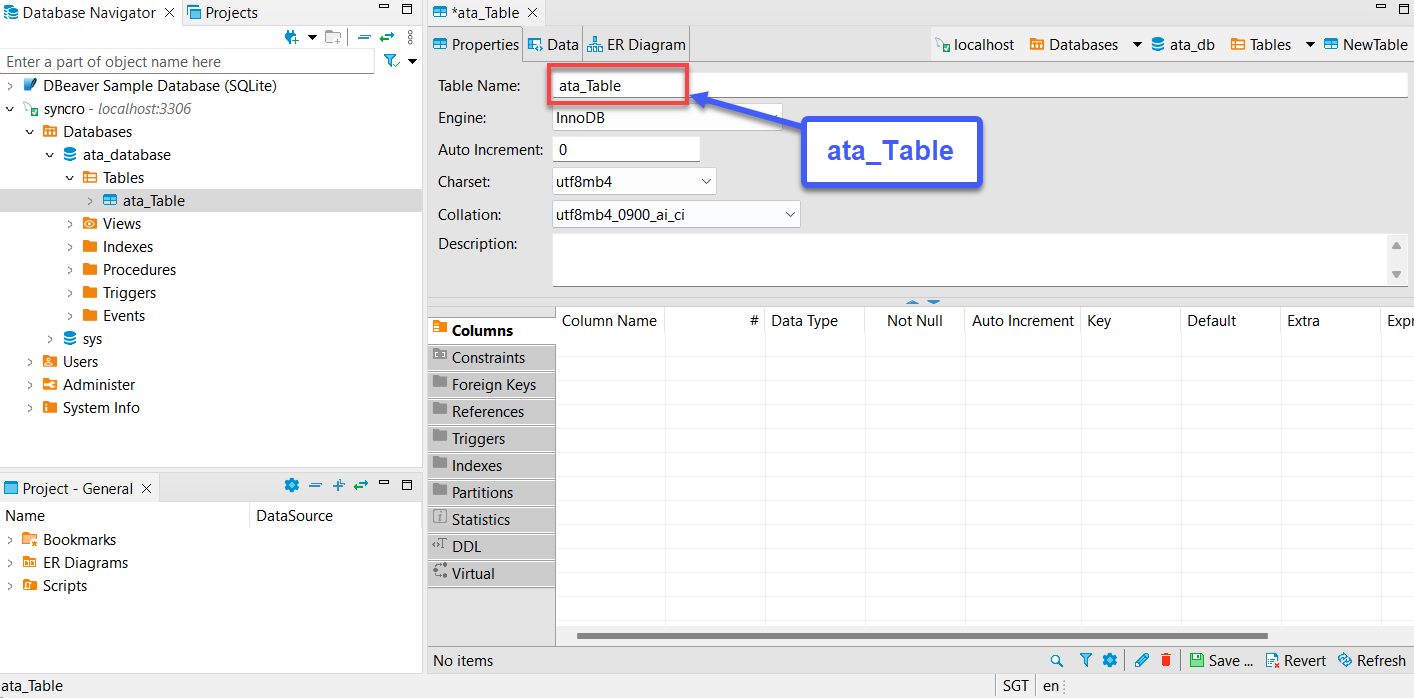
5. Nommez votre nouvelle table, mais le choix de ce tutoriel est ata_Table, comme indiqué ci-dessous.
Assurez-vous que le nom de la table correspond au nom de table que vous spécifierez dans la méthode to_sql (”Nom de la table”) à l’étape sept de la section « Obtenir et consommer des données d’API ».
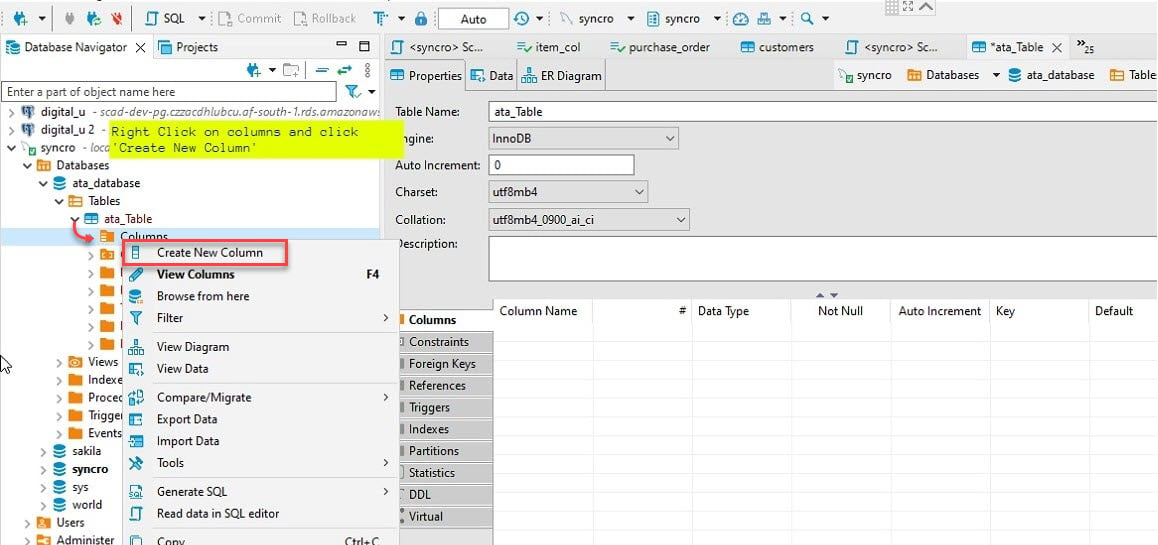
6. Ensuite, développez la nouvelle table (ata_table) → faites un clic droit sur Colonnes → Créer une nouvelle colonne pour créer une nouvelle colonne.
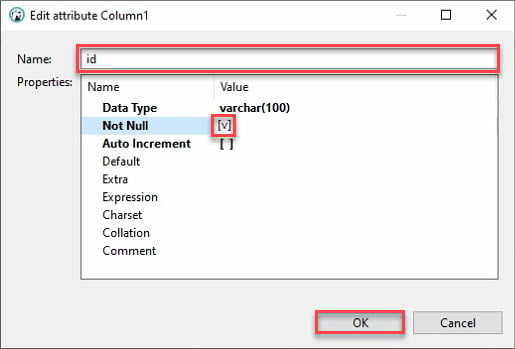
7. Fournissez un nom de colonne, comme indiqué ci-dessous, cochez la case Not Null, puis cliquez sur OK pour créer la nouvelle colonne.
Idéalement, vous voudriez ajouter une colonne appelée « id ». Pourquoi ? La plupart des API auront un id, et le dataframe de pandas de Python remplira automatiquement les autres colonnes.
8. Cliquez sur Enregistrer (en bas à droite) ou appuyez sur Ctrl+S pour enregistrer les modifications une fois que vous avez vérifié votre nouvelle colonne créée (id), comme indiqué ci-dessous.
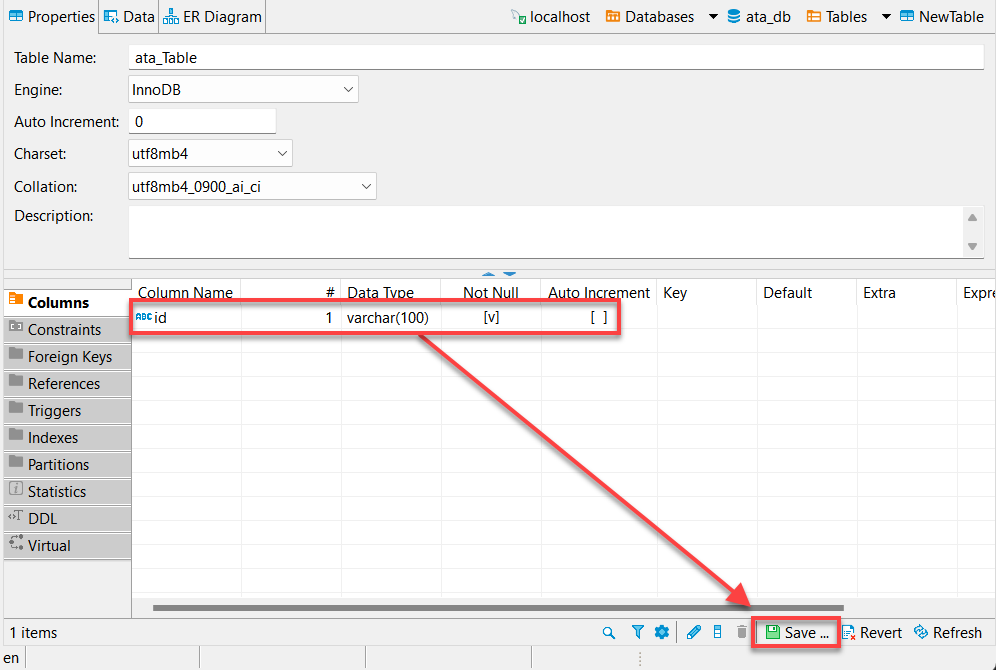
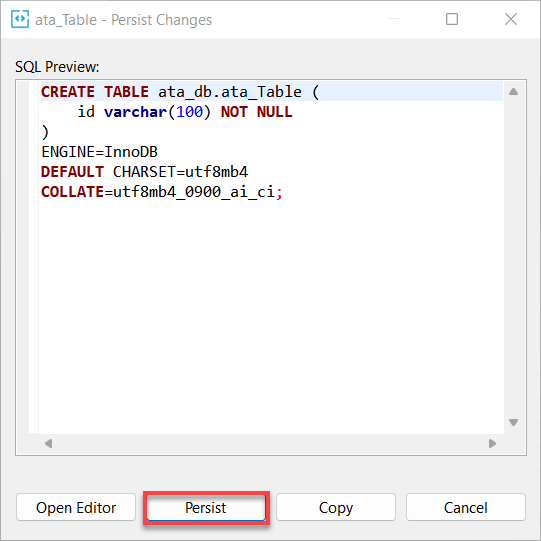
9. Enfin, cliquez sur Persister pour sauvegarder les modifications apportées à la base de données.
Obtention et consommation de données d’API
Maintenant que vous avez créé la base de données pour stocker les données, vous devez récupérer les données auprès de votre fournisseur d’API respectif et les pousser dans votre base de données à l’aide de Python. Vous utiliserez ces données pour les visualiser dans Power BI.
Pour vous connecter à votre fournisseur d’API, vous aurez besoin de trois éléments clés : la méthode d’autorisation, l’URL de base de l’API et le point de terminaison de l’API. Si vous avez des doutes sur la manière d’obtenir ces informations, consultez la documentation de votre fournisseur d’API.
Ci-dessous se trouve une page de documentation de Syncro.
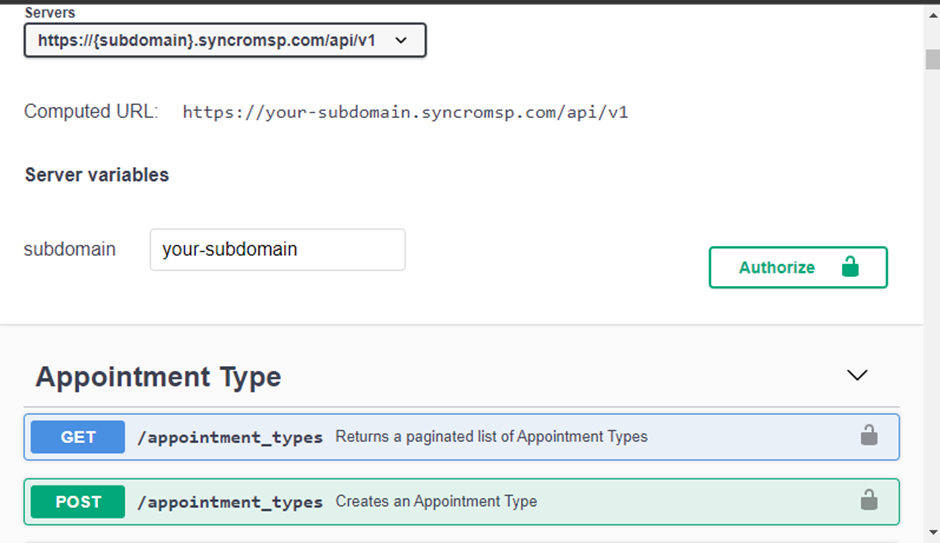
1. Ouvrez VS Code, créez un fichier Python et nommez-le en fonction des données API attendues du fichier. Ce fichier sera responsable de récupérer et de pousser les données API vers votre base de données (connexion à la base de données).
Plusieurs bibliothèques Python sont disponibles pour aider avec la connexion à la base de données, mais vous utiliserez SQLAalchemy dans ce tutoriel.
Exécutez la commande pip ci-dessous dans le terminal de VS Code pour installer SQLAalchemy sur votre environnement.

2. Ensuite, créez un fichier appelé connection.py, remplissez le code ci-dessous, remplacez les valeurs en conséquence, et enregistrez le fichier.
Une fois que vous commencez à écrire des scripts pour communiquer avec votre base de données, une connexion à la base de données doit être établie avant que la base de données n’accepte une commande quelconque.
Mais au lieu de réécrire la chaîne de connexion à la base de données pour chaque script que vous écrivez, le code ci-dessous est dédié à faire en sorte que cette connexion soit appelée/référencée par d’autres scripts.
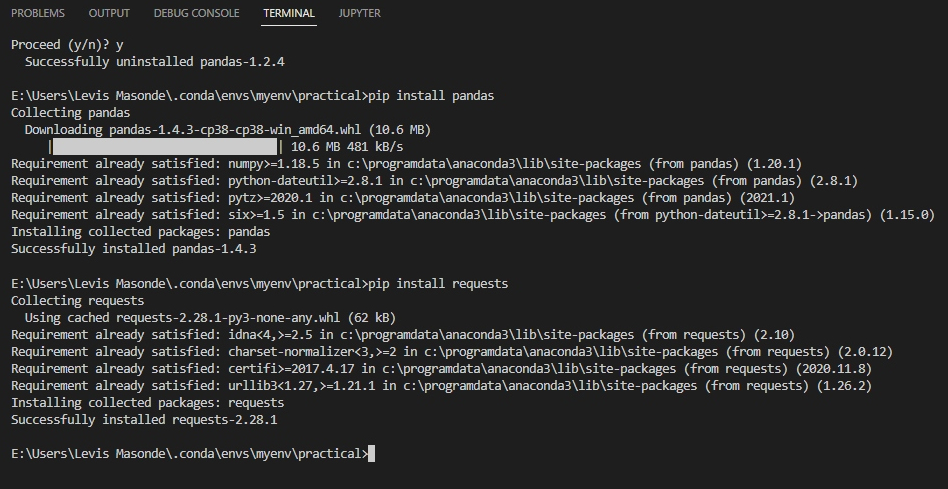
3. Ouvrez le terminal de Visual Studio (Ctrl+Shift+`), et exécutez les commandes ci-dessous pour installer pandas et requests.
4. Créez un autre fichier Python appelé invoices.py (ou donnez-lui un nom différent), et ajoutez le code ci-dessous au fichier.
Vous ajouterez des extraits de code au fichier invoices.py à chaque étape suivante, mais vous pouvez consulter le code complet sur GitHub d’ATA.
Le script invoices.py sera exécuté à partir du script principal décrit dans la section suivante, qui extrait vos premières données API.
Le code ci-dessous effectue les opérations suivantes:
- Consomme les données de votre API et les écrit dans votre base de données.
- Remplace la méthode d’autorisation, la clé, l’URL de base et les points de terminaison API par les informations d’identification de votre fournisseur API.
5. Ajoutez l’extrait de code ci-dessous au fichier invoices.py pour définir les en-têtes, par exemple:
- Le format de données que vous attendez de recevoir de votre API.
- L’URL de base et le point de terminaison doivent accompagner la méthode d’autorisation et la clé respective.
Assurez-vous de modifier les valeurs ci-dessous avec les vôtres.
6. Ensuite, ajoutez la fonction asynchrone suivante au fichier invoices.py.
Le code ci-dessous utilise AsyncIO pour gérer vos scripts multiples à partir d’un script principal couvert dans la section suivante. Lorsque votre projet s’étend pour inclure plusieurs points d’API, il est bon de pratique d’avoir des scripts de consommation d’API dans leurs propres fichiers.
7. Enfin, ajoutez le code ci-dessous au fichier invoices.py, où une fonction get_pages gère la pagination de votre API.
Cette fonction retourne le nombre total de pages dans votre API et aide la fonction de plage à itérer à travers toutes les pages.
Contactez les développeurs de votre API concernant la méthode de pagination utilisée par votre fournisseur d’API.
Si vous préférez ajouter plus de points d’accès API à vos données :
- Répétez les étapes quatre à six de la section « Gestion des bases de données MySQL avec DBeaver ».
- Répétez toutes les étapes de la section « Obtention et consommation des données de l’API ».
- Changez le point d’accès API pour un autre que vous souhaitez consommer.
Synchronisation des points d’accès API
Vous avez maintenant une base de données et une connexion API, et vous êtes prêt à commencer la consommation de l’API en exécutant le code dans le fichier invoices.py. Cependant, cela vous limiterait à consommer un seul point d’accès API simultanément.
Comment dépasser la limite ? Vous créerez un autre fichier Python en tant que fichier central qui appelle les fonctions API à partir de divers fichiers Python et exécute les fonctions de manière asynchrone en utilisant AsyncIO. De cette manière, vous gardez votre programmation propre et vous permettez de regrouper plusieurs fonctions ensemble.
1. Créez un nouveau fichier Python appelé central.py et ajoutez le code ci-dessous.
Similaire au fichier invoices.py, vous ajouterez des extraits de code au fichier central.py à chaque étape, mais vous pouvez consulter le code complet sur GitHub d’ATA.
Le code ci-dessous importe des modules essentiels et des scripts depuis d’autres fichiers en utilisant la syntaxe from <filename> import <function name>.
2. Ensuite, ajoutez le code suivant pour contrôler les scripts depuis invoices.py dans le fichier central.py.
Vous devez référencer/appeler la fonction call_invoices depuis invoices.py vers une tâche AsyncIO (invoice_task) dans central.py.
3. Après avoir créé la tâche AsyncIO, attendez la tâche pour récupérer et exécuter la fonction call_invoices de invoice.py une fois que la fonction chain (à l’étape deux) commence à s’exécuter.
4. Créez un AsyncIOScheduler pour planifier un travail pour que le script s’exécute. Le travail ajouté dans ce code exécute la fonction chain à des intervalles d’une seconde.
Ce travail est important pour garantir que votre programme continue d’exécuter vos scripts pour maintenir vos données à jour.
5. Enfin, exécutez le script central.py sur VS Code, comme indiqué ci-dessous.
Après avoir exécuté le script, vous verrez la sortie sur le terminal comme ci-dessous.
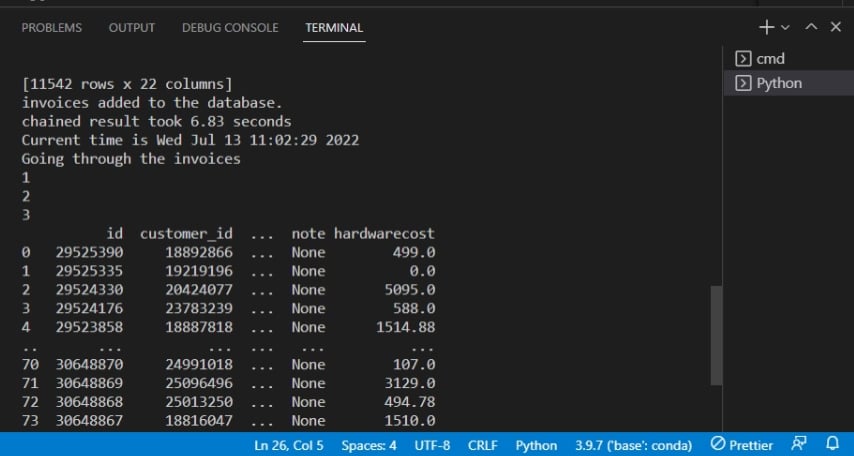
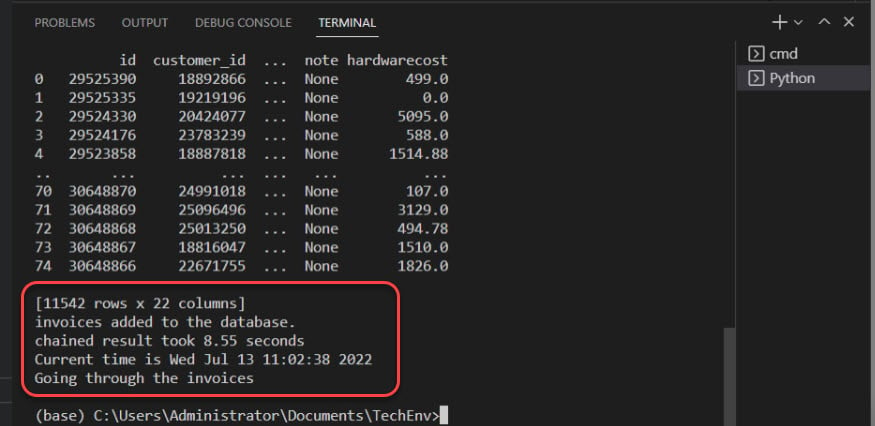
Plus bas, la sortie confirme que les factures sont ajoutées à la base de données.
Développement des Visualisations Power BI
Après avoir codé un programme qui se connecte et consomme des données d’API et pousse ces données dans une base de données, vous êtes presque prêt à récolter vos données. Mais d’abord, vous pousserez les données de la base de données vers Power BI pour la visualisation, le but ultime.
Beaucoup de données sont inutiles si vous ne pouvez pas visualiser les données et établir des liens profonds. Heureusement, les visualisations Power BI sont comme les graphiques qui peuvent rendre les équations mathématiques compliquées simples et prévisibles.
1. Ouvrez Power BI depuis votre bureau ou le menu Démarrer.
2. Cliquez sur l’icône de la source de données au-dessus du menu déroulant Obtenir des données dans la fenêtre principale de Power BI. Une fenêtre contextuelle apparaît où vous pouvez sélectionner la source de données à utiliser (étape trois).
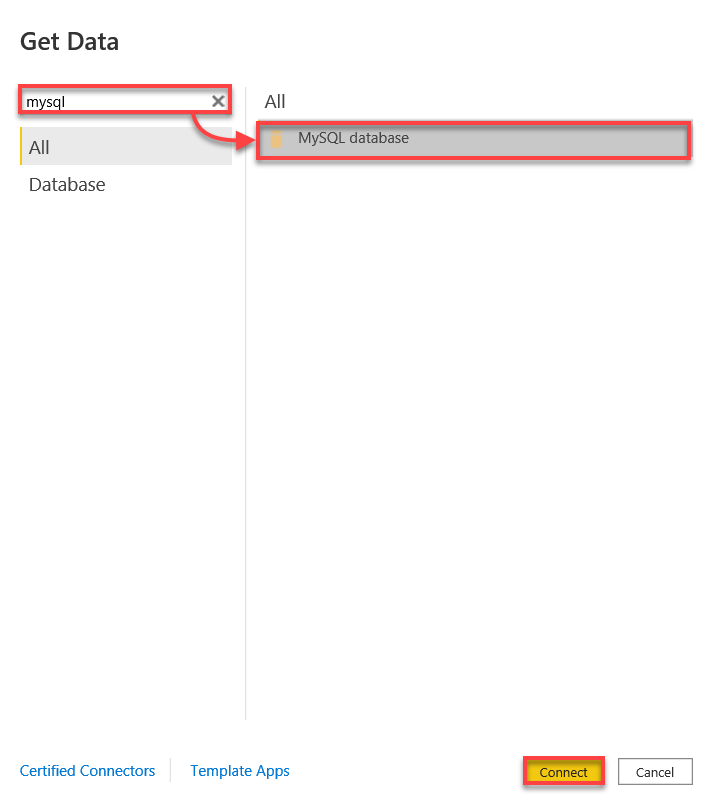
3. Recherchez mysql, sélectionnez la base de données MySQL et cliquez sur Connecter pour initier la connexion à votre base de données MySQL.
4. Maintenant, connectez-vous à votre base de données MySQL avec les paramètres suivants :
- Entrez localhost:3306 car vous vous connectez à votre serveur MySQL local sur le port 3306.
- Indiquez le nom de votre base de données, dans ce cas, ata_db.
- Cliquez sur OK pour vous connecter à votre base de données MySQL.

5. Maintenant, cliquez sur Transformer les données (en bas à droite) pour voir un aperçu des données dans l’éditeur de requêtes Power BI (étape cinq).

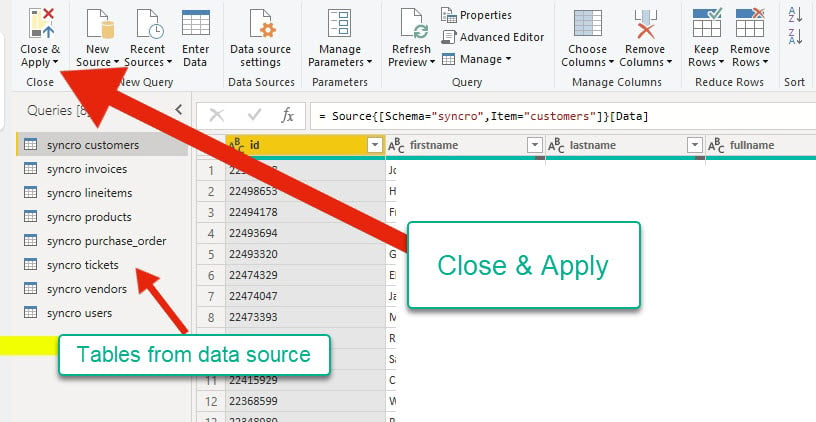
6. Après avoir prévisualisé la source de données, cliquez sur Fermer et appliquer pour revenir à l’application principale et confirmer si des changements ont été appliqués.
L’éditeur de requêtes affiche les tables de votre source de données à l’extrême gauche. En même temps, vous pouvez vérifier le format des données avant de passer à l’application principale.
7. Cliquez sur l’onglet ruban Outils de tableau, sélectionnez une table dans le volet Champs et cliquez sur Gérer les relations pour ouvrir l’assistant de relations.
Avant de créer des visualisations, assurez-vous que vos tables sont liées, spécifiez explicitement toute relation entre vos tables. Pourquoi ? Power BI ne détecte pas automatiquement les corrélations de table complexes pour le moment.

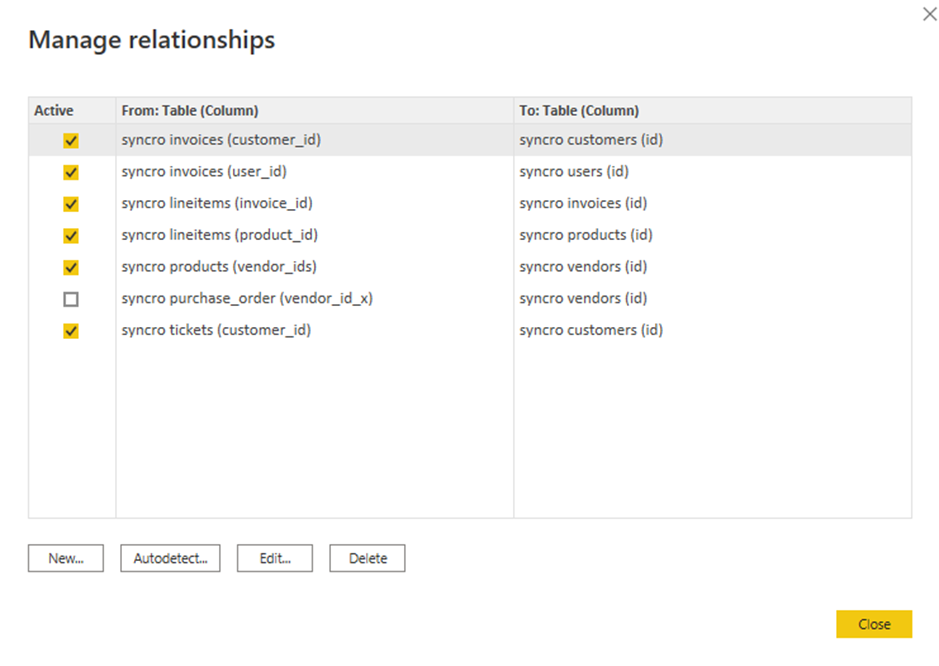
8. Cochez les cases des relations existantes à éditer, et cliquez sur Éditer. Une fenêtre contextuelle apparaît, où vous pouvez éditer les relations sélectionnées (étape neuf).
Mais si vous préférez ajouter une nouvelle relation, cliquez sur Nouveau à la place.
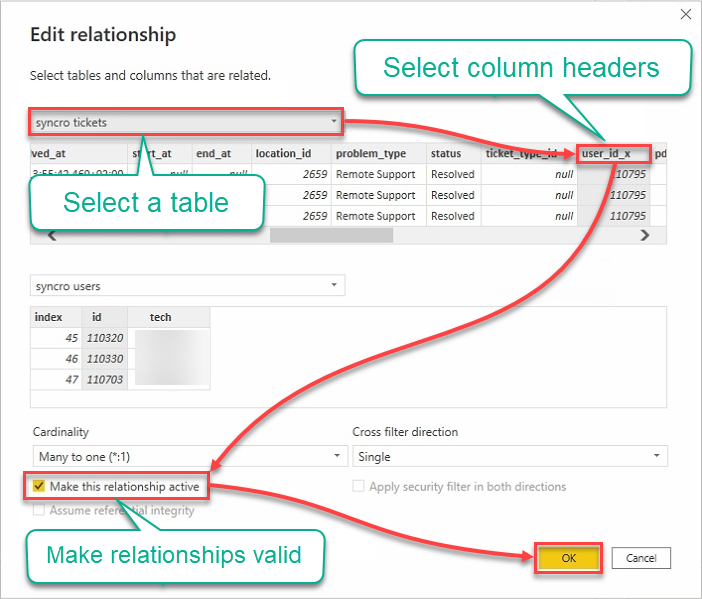
9. Modifiez les relations avec les étapes suivantes :
- Cliquez sur le champ de sélection des tables, puis sélectionnez une table.
- Cliquez sur les en-têtes pour sélectionner les colonnes à utiliser.
- Cochez la case Rendre cette relation active pour vous assurer que les relations sont valides.
- Cliquez sur OK pour établir la relation et fermer la fenêtre de modification de la relation.
10. Maintenant, cliquez sur le type de visualisation Table dans le volet Visualisations (à l’extrême droite) pour créer votre première visualisation, et une visualisation de table vide apparaît (étape 11).
11. Sélectionnez la visualisation de table et les champs de données (sur le volet Champs) à ajouter à votre visualisation de table, comme indiqué ci-dessous.
12. Enfin, cliquez sur le type de visualisation Trancheur pour ajouter une autre visualisation. Comme son nom l’indique, la visualisation de trancheur découpe les données en filtrant les autres visualisations.
Après avoir ajouté le trancheur, sélectionnez des données dans le volet Champs à ajouter à la visualisation de trancheur.
Changement de visualisations
Les apparences par défaut des visualisations sont assez décentes. Mais ne serait-il pas génial si vous pouviez changer l’apparence des visualisations pour quelque chose de moins fade ? Laissez Power BI faire le travail.
Cliquez sur l’icône Formater votre visualisation sous la visualisation pour accéder à l’éditeur de visualisation, comme indiqué ci-dessous.
Passez un peu de temps à jouer avec les paramètres de visualisation pour obtenir l’apparence désirée pour vos visualisations. Vos visualisations seront corrélées tant que vous établissez une relation entre les tables que vous impliquez dans vos visualisations.
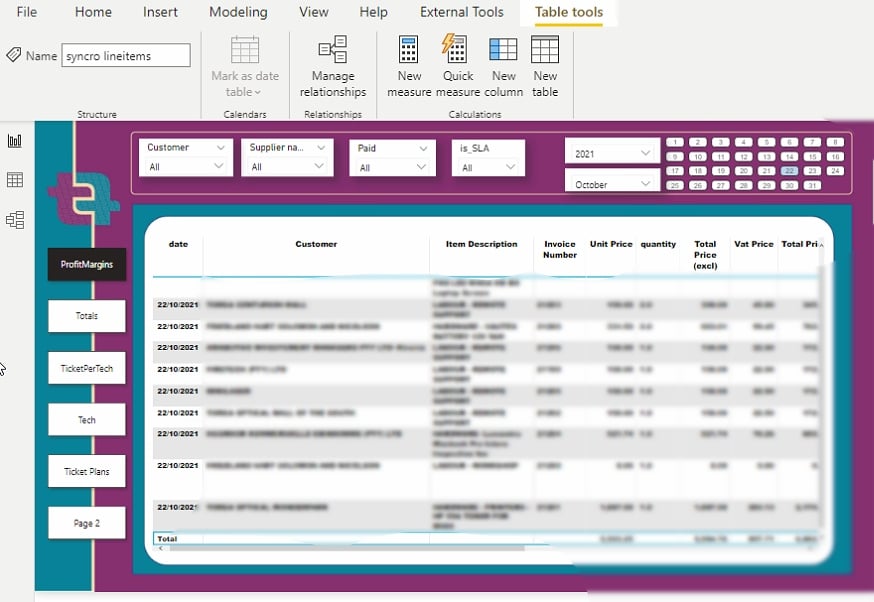
Après avoir modifié les paramètres de visualisation, vous pouvez extraire des rapports comme ceux ci-dessous.
Maintenant, vous pouvez visualiser et analyser vos données sans complexité ni fatigue pour les yeux.
Dans la visualisation suivante, en examinant le graphique des tendances, vous verrez qu’il s’est passé quelque chose d’anormal en avril 2020. C’était à ce moment-là que les premiers confinements liés au Covid-19 ont frappé l’Afrique du Sud.
Ce résultat prouve seulement l’expertise de Power BI dans la fourniture de visualisations de données précises.

Conclusion
Ce tutoriel vise à vous montrer comment établir un pipeline de données dynamique en temps réel en récupérant vos données à partir de points d’accès API. De plus, en traitant et en envoyant les données à votre base de données et à Power BI à l’aide de Python. Avec ces connaissances nouvellement acquises, vous pouvez maintenant consommer des données API et créer vos propres visualisations de données.
De plus en plus d’entreprises créent des applications Web API Restful. Et à ce stade, vous êtes maintenant confiant dans la consommation d’API en utilisant Python et dans la création de visualisations de données avec Power BI, ce qui peut aider à influencer les décisions commerciales.