













Ces dernières années, les applications cloud-native sont devenues la norme privilégiée par de nombreuses entreprises pour construire des applications évolutives. Parmi les nombreuses avancées dans les technologies cloud, les architectures serverless se démarquent comme une approche transformative. La facilité d’utilisation et l’efficacité sont les deux propriétés les plus désirables pour le développement d’applications modernes, et les architectures serverless offrent cela. Cela a fait des architectures serverless un élément révolutionnaire à la fois pour les fournisseurs de services cloud et les consommateurs.
Pour les entreprises qui cherchent à construire des applications avec cette approche, les principaux fournisseurs de services cloud proposent plusieurs solutions serverless. Dans cet article, nous explorerons les fonctionnalités, avantages et défis de cette architecture, ainsi que des cas d’utilisation. Dans cet article, j’ai utilisé AWS comme exemple pour explorer les concepts, mais les mêmes concepts sont applicables à tous les principaux fournisseurs de services cloud.
Serverless
Serverless ne signifie pas qu’il n’y a pas de serveurs. Cela signifie simplement que l’infrastructure sous-jacente de ces services est gérée par les fournisseurs de services cloud. Cela permet aux architectes et développeurs de concevoir et construire les applications sans se soucier de la gestion de l’infrastructure. C’est similaire à l’utilisation de l’application de covoiturage Uber : lorsque vous avez besoin d’un trajet, vous ne vous souciez pas de posséder ou d’entretenir une voiture. Uber gère tout cela, et vous vous concentrez simplement sur l’endroit où vous devez aller en payant pour le trajet.
Les architectures serverless offrent de nombreux avantages qui les rendent adaptées et attrayantes pour de nombreux cas d’utilisation. Voici quelques-uns des principaux avantages :
Auto Scaling
Un des plus grands avantages de l’architecture sans serveur est qu’elle supporte intrinsèquement la mise à l’échelle. Les fournisseurs de cloud s’occupent de l’essentiel pour offrir une mise à l’échelle quasi infinie prête à l’emploi. Par exemple, si une application construite à l’aide de technologies sans serveur gagne soudainement en popularité, les outils ou services s’adaptent automatiquement pour répondre aux besoins de l’application. Nous n’avons pas à nous réveiller au milieu de la nuit pour ajouter des serveurs ou d’autres ressources.
Concentration sur l’Innovation
Puisque vous n’êtes plus accablé par la gestion des serveurs, vous pouvez plutôt vous concentrer sur le développement de l’application, en ajoutant des fonctionnalités pour favoriser la croissance de l’application. Pour toute organisation, qu’elle soit petite, moyenne ou grande, cette approche aide à se concentrer sur ce qui compte vraiment – la croissance de l’entreprise.
Efficacité Coût
Avec les modèles de serveurs traditionnels, vous finissez souvent par payer pour des ressources inutilisées car elles sont achetées à l’avance et gérées même lorsqu’elles ne sont pas utilisées. Le sans serveur change cela en passant à un modèle de paiement à l’utilisation. Dans la plupart des scénarios, vous ne payez que pour les ressources que vous utilisez réellement. Si l’application que vous construisez ne décolle pas immédiatement, vos coûts seront minimes, comme payer pour une seule session au lieu d’une année entière. À mesure que le trafic de l’application augmente, le coût augmentera en conséquence.
Rapidité de Mise sur le Marché
Avec les cadres sans serveur, vous pouvez construire et déployer des applications beaucoup plus rapidement par rapport aux modèles de serveurs traditionnels. Lorsque l’application est prête, elle peut être déployée avec un effort minimal en utilisant des ressources sans serveur. Au lieu de passer du temps sur la gestion des serveurs, vous pouvez vous concentrer sur le développement et l’ajout de nouvelles fonctionnalités, les expédiant à un rythme plus rapide.
Maintenance opérationnelle réduite
Étant donné que les fournisseurs cloud gèrent l’infrastructure, les consommateurs n’ont pas à se soucier de la provision, de la maintenance, de la mise à l’échelle, ou de la gestion des correctifs de sécurité et des vulnérabilités.
Les frameworks sans serveur offrent de la flexibilité et peuvent être appliqués à divers cas d’utilisation. Qu’il s’agisse de construire des applications web ou de traiter des données en temps réel, ils fournissent la scalabilité et l’efficacité nécessaires pour ces cas d’utilisation.
Construction d’API de services web avec AWS Serverless
Maintenant que nous avons discuté des avantages des architectures sans serveur, plongeons dans quelques exemples pratiques. Dans cette section, nous allons créer une application web backend simple en utilisant les ressources serverless d’AWS.
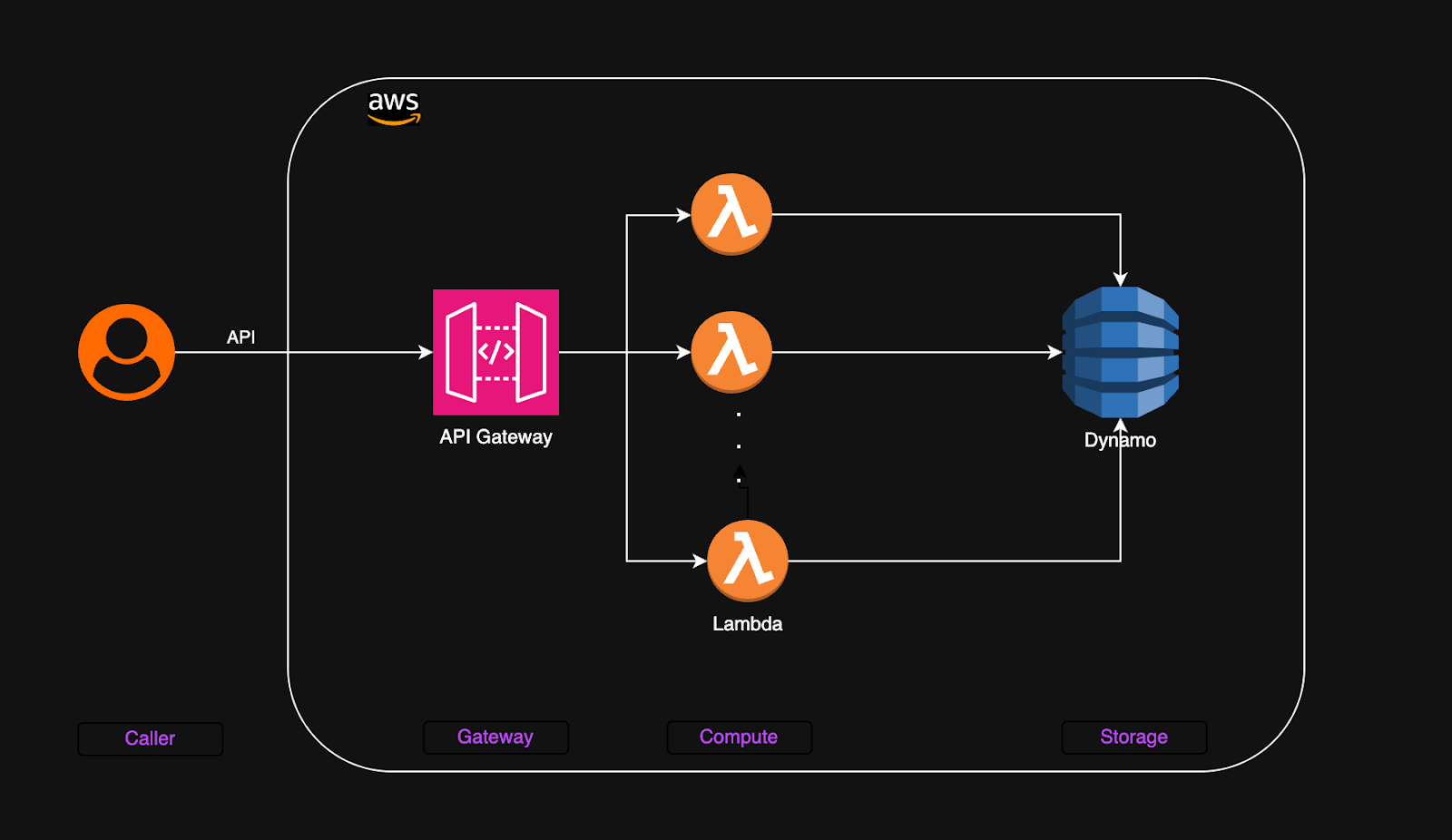
Le design de l’application backend ci-dessus contient trois couches pour fournir des APIs pour une application web. Une fois déployé sur AWS, le point de terminaison de la passerelle est disponible pour la consommation de l’API. Lorsque les APIs sont appelées par les utilisateurs, les requêtes sont routées à travers la passerelle API vers les fonctions lambda appropriées. Pour chaque requête API, la fonction Lambda est déclenchée, et elle accède à DynamoDB pour stocker et récupérer des données. Ce design est une solution rationalisée et rentable qui s’adapte automatiquement à la demande croissante, en en faisant un choix idéal pour la construction d’APIs avec un minimum de surcharge. Les composants de ce design s’intègrent bien les uns avec les autres en offrant de la flexibilité.
Il y a deux composants majeurs dans cette architecture — le calcul et le stockage.
Calcul sans serveur
Le calcul sans serveur a changé la manière dont les applications et services cloud-natifs sont construits et déployés. Il promet un véritable modèle de paiement à l’usage avec une granularité au niveau de la milliseconde sans gaspiller de ressources. En raison de sa simplicité et de ses avantages économiques, cette approche est devenue populaire, et de nombreux fournisseurs cloud soutiennent ces capacités.
La manière la plus simple d’utiliser le calcul sans serveur consiste à fournir du code à exécuter par la plateforme sur demande. Cette approche a conduit à l’émergence des plateformes Function-as-a-service (FaaS) qui se concentrent sur la possibilité de faire fonctionner de petits morceaux de code représentés sous forme de fonctions pendant une durée limitée. Les fonctions sont déclenchées par des événements tels que des requêtes HTTP, des modifications de stockage, des messages ou des notifications. Comme ces fonctions sont invoquées et arrêtées lorsque l’exécution du code est terminée, elles ne conservent aucun état persistant. Pour maintenir l’état ou persister les données, elles utilisent des services comme DynamoDB qui offrent des capacités de stockage durables.
AWS Lambda est capable de s’adapter à la demande. Par exemple, AWS Lambda a traité plus de 1,3 billion d’invocations lors du Prime Day 2024. De telles capacités sont cruciales pour gérer les pics soudains de trafic.
Stockage sans serveur
Dans l’écosystème de l’informatique sans serveur, le stockage sans serveur fait référence à des solutions de stockage basées sur le cloud qui s’adaptent automatiquement sans que les consommateurs gèrent l’infrastructure. Ces services offrent de nombreuses capacités, notamment la scalabilité à la demande, une haute disponibilité et le paiement à l’utilisation. Par exemple, DynamoDB est une base de données NoSQL sans serveur entièrement gérée conçue pour gérer les modèles de données clés-valeurs et documentaires. Elle est conçue pour les applications nécessitant des performances constantes à n’importe quelle échelle, offrant une latence de quelques millisecondes. Elle offre également des capacités d’intégration transparentes avec de nombreux autres services.
Les principaux fournisseurs de cloud proposent de nombreuses options de stockage sans serveur pour des besoins spécifiques, telles que S3, ElastiCache, Aurora, et bien d’autres.
Autres cas d’utilisation
Dans la section précédente, nous avons discuté de la façon de tirer parti de l’architecture sans serveur pour construire des API backend pour une application web. Il existe plusieurs autres cas d’utilisation qui peuvent bénéficier de l’architecture sans serveur. Quelques-uns de ces cas d’utilisation comprennent :
Traitement des données
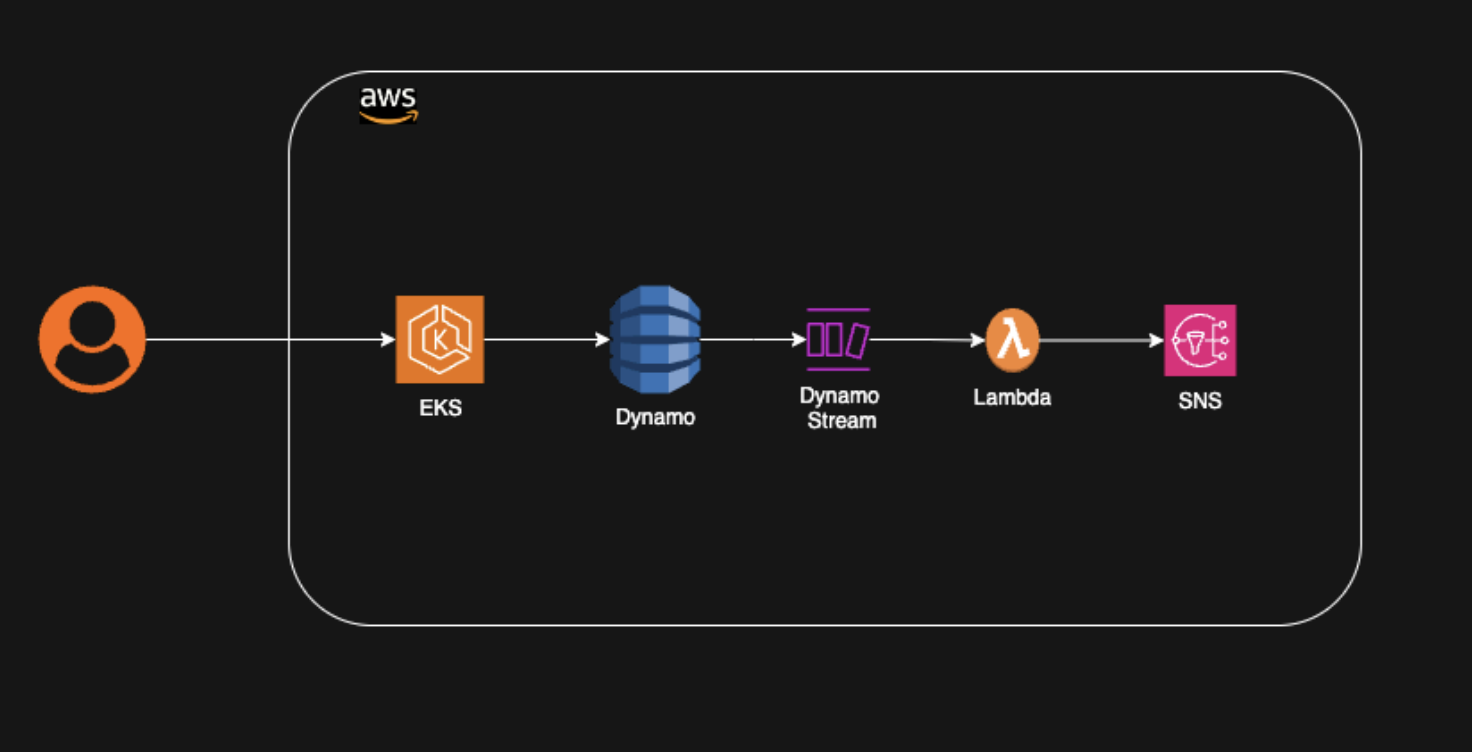
Explorons un autre exemple de la façon dont l’architecture sans serveur peut être utilisée pour notifier des services en fonction des changements de données dans un magasin de données. Par exemple, dans une plateforme de commerce électronique, disons qu’à la création d’une commande, plusieurs services doivent être informés. Au sein de l’écosystème AWS, la commande peut être stockée dans DynamoDB lors de sa création. Afin d’informer d’autres services, plusieurs événements peuvent être déclenchés en fonction de cet événement de stockage.
En utilisant les flux DynamoDB, une fonction Lambda peut être invoquée lorsque cet événement se produit. Cette fonction lambda peut ensuite pousser l’événement de changement vers SNS (Simple Notification Service). SNS agit en tant que service de notification pour informer plusieurs autres services qui sont intéressés par ces événements.
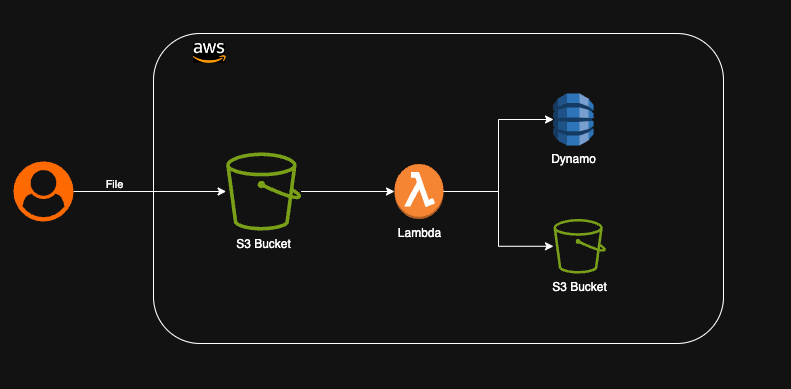
Traitement de fichiers en temps réel
Dans de nombreuses applications, les utilisateurs téléchargent des images qui doivent être stockées, traitées pour le redimensionnement, converties en différents formats et analysées. Nous pouvons réaliser cette fonctionnalité en utilisant l’architecture sans serveur AWS de la manière suivante. Lorsqu’une image est téléchargée, elle est poussée vers un compartiment S3 configuré pour déclencher un événement afin d’invoquer une fonction Lambda. La fonction Lambda peut traiter l’image, stocker les métadonnées dans DynamoDB et stocker les images redimensionnées dans un autre compartiment S3. Cette architecture évolutive peut être utilisée pour traiter des millions d’images sans nécessiter la gestion de toute infrastructure ou intervention manuelle.
Défis
Les architectures sans serveur offrent de nombreux avantages, mais elles posent également certains défis qui doivent être relevés.
Démarrage à froid
Lorsqu’une fonction serverless est invoquée, la plateforme doit créer, initialiser et exécuter un nouveau conteneur pour exécuter le code. Ce processus, appelé démarrage à froid, peut introduire une latence supplémentaire dans le flux de travail. Des techniques comme maintenir les fonctions au chaud ou utiliser la pré-allocation de la capacité peuvent aider à réduire ce retard.
Surveillance et débogage
Étant donné qu’il peut y avoir un grand nombre d’invocations, la surveillance et le débogage peuvent devenir complexes. Il peut être difficile d’identifier et de déboguer les problèmes dans les applications très utilisées. Il est fortement recommandé de configurer des outils comme AWS Cloudwatch pour les métriques, les journaux et les alertes afin de résoudre ces problèmes.
Bien que les architectures serverless se redimensionnent automatiquement, les configurations des ressources doivent être optimisées pour éviter les goulots d’étranglement. Une allocation efficace des ressources et la mise en œuvre de stratégies d’optimisation des coûts sont essentielles.
Conclusion
L’architecture serverless est une étape majeure vers le développement d’applications cloud natives soutenues par le calcul et le stockage serverless. Elle est largement utilisée dans de nombreux types d’applications, notamment les workflows déclenchés par des événements, le traitement des données, le traitement des fichiers et l’analyse de données volumineuses. En raison de sa scalabilité, de son agilité et de sa haute disponibilité, l’architecture serverless est devenue un choix fiable pour les entreprises de toutes tailles.
Source:
https://dzone.com/articles/from-zero-to-scale-with-aws-serverless