













En los últimos años, las aplicaciones nativas de la nube se han convertido en el estándar preferido por muchas empresas para construir aplicaciones escalables. Entre los muchos avances en tecnologías en la nube, las arquitecturas sin servidor destacan como un enfoque transformador. La facilidad de uso y la eficiencia son las dos propiedades más deseables para el desarrollo de aplicaciones modernas, y las arquitecturas sin servidor ofrecen esto. Esto ha hecho que las arquitecturas sin servidor sean el factor determinante tanto para los proveedores de servicios en la nube como para los consumidores.
Para las empresas que buscan construir aplicaciones con este enfoque, los principales proveedores de servicios en la nube ofrecen varias soluciones sin servidor. En este artículo, exploraremos las características, beneficios y desafíos de esta arquitectura, junto con casos de uso. En este artículo, utilicé AWS como ejemplo para explorar los conceptos, pero los mismos conceptos son aplicables en todos los principales proveedores de servicios en la nube.
Sin servidor
Sin servidor no significa que no haya servidores. Simplemente significa que la infraestructura subyacente para esos servicios es gestionada por los proveedores de servicios en la nube. Esto permite a los arquitectos y desarrolladores diseñar y construir las aplicaciones sin preocuparse por gestionar la infraestructura. Es similar a usar la aplicación de transporte compartido Uber: cuando necesitas un viaje, no te preocupas por tener o mantener un auto. Uber se encarga de todo eso, y tú te enfocas en llegar a donde necesitas yendo en el viaje que pagas.
Las arquitecturas sin servidor ofrecen muchos beneficios que las hacen adecuadas y atractivas para muchos casos de uso. Aquí están algunas de las principales ventajas:
Escalabilidad automática
Una de las mayores ventajas de la arquitectura sin servidor es que soporta inherentemente el escalado. Los proveedores de la nube se encargan de la mayor parte del trabajo pesado para ofrecer escalabilidad casi infinita de forma inmediata. Por ejemplo, si una aplicación construida con tecnologías sin servidor de repente gana popularidad, las herramientas o servicios se escalan automáticamente para satisfacer las necesidades de la aplicación. No tenemos que despertarnos en medio de la noche para añadir servidores u otros recursos.
Enfoque en la Innovación
Dado que ya no estás cargado con la gestión de servidores, puedes enfocarte en la construcción de la aplicación, añadiendo características para el crecimiento de la misma. Para cualquier organización, ya sea pequeña, mediana o grande, este enfoque ayuda a concentrarse en lo que realmente importa: el crecimiento del negocio.
Eficiencia en Costos
Con los modelos tradicionales de servidores, a menudo terminas pagando por recursos no utilizados, ya que se compran por adelantado y se gestionan incluso cuando no se usan. La arquitectura sin servidor cambia esto al cambiar a un modelo de pago por uso. En la mayoría de los casos, solo pagas por los recursos que realmente utilizas. Si la aplicación que construyes no obtiene tracción de inmediato, tus costos serán mínimos, como pagar por una sola sesión en lugar de un año entero. A medida que crece el tráfico de la aplicación, el costo crecerá en consecuencia.
Menor Tiempo de Lanzamiento al Mercado
Con los marcos de trabajo sin servidor, puedes construir y desplegar aplicaciones mucho más rápido en comparación con los modelos tradicionales de servidores. Cuando la aplicación está lista, se puede desplegar con un esfuerzo mínimo utilizando recursos sin servidor. En lugar de dedicar tiempo a la gestión de servidores, puedes concentrarte en el desarrollo y añadir nuevas características, lanzándolas a un ritmo más rápido.
Mantenimiento Operativo Reducido
Dado que los proveedores de servicios en la nube gestionan la infraestructura, los consumidores no necesitan preocuparse por aprovisionamiento, mantenimiento, escalabilidad o gestión de parches de seguridad y vulnerabilidades.
Los marcos sin servidor ofrecen flexibilidad y pueden aplicarse a una variedad de casos de uso. Ya sea para construir aplicaciones web o procesar datos en tiempo real, ofrecen la escalabilidad y eficiencia necesarias para estos casos de uso.
Construcción de APIs de Servicio Web con AWS Serverless
Ahora que hemos discutido los beneficios de las arquitecturas sin servidor, sumerjámonos en algunos ejemplos prácticos. En esta sección, crearemos una aplicación web de backend simple utilizando recursos sin servidor de AWS.
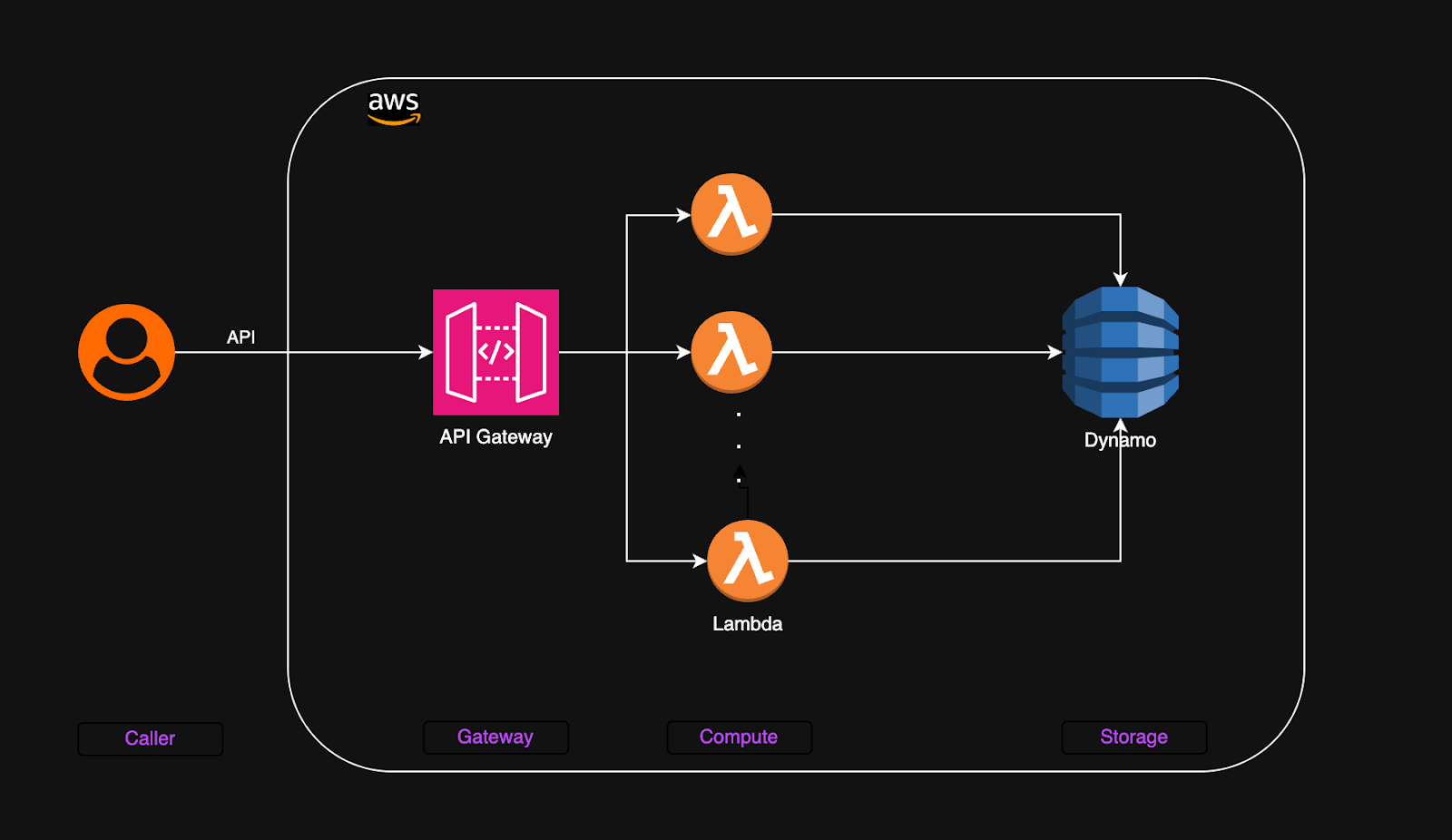
El diseño de la aplicación de backend mencionado anteriormente contiene tres capas para proporcionar APIs para una aplicación web. Una vez desplegado en AWS, el punto de entrada de la puerta de enlace está disponible para el consumo de la API. Cuando los usuarios llaman a las APIs, las solicitudes se dirigen a través de la puerta de enlace de la API a las funciones lambda apropiadas. Para cada solicitud de API, la función Lambda se activa y accede a DynamoDB para almacenar y recuperar datos. Este diseño es una solución simplificada y rentable que se escala automáticamente a medida que crece la demanda, convirtiéndose en una elección ideal para construir APIs con un mínimo sobrecosto. Los componentes en este diseño se integran bien entre sí proporcionando flexibilidad.
Existen dos componentes principales en esta arquitectura: computación y almacenamiento.
Computación sin servidor
La computación sin servidor cambió la forma en que se construyen y despliegan aplicaciones y servicios nativos de la nube. Promete un modelo real de pago por uso con granularidad a nivel de milisegundos sin desperdiciar recursos. Debido a su simplicidad y ventajas económicas, este enfoque ganó popularidad y muchos proveedores de nube apoyan estas capacidades.
La forma más simple de usar la computación sin servidor es proporcionando código que sea ejecutado por la plataforma bajo demanda. Este enfoque llevó al surgimiento de Función-como-servicio (FaaS), plataformas enfocadas en permitir que pequeños fragmentos de código representados como funciones se ejecuten durante un tiempo limitado. Las funciones son activadas por eventos como solicitudes HTTP, cambios de almacenamiento, mensajes o notificaciones. Dado que estas funciones se invocan y se detienen cuando la ejecución del código se completa, no mantienen ningún estado persistente. Para mantener el estado o persistir los datos, utilizan servicios como DynamoDB que proporcionan capacidades de almacenamiento duradero.
AWS Lambda es capaz de escalar según la demanda. Por ejemplo, AWS Lambda procesó más de 1.3 billones de invocaciones en el Día Prime 2024. Tales capacidades son cruciales para manejar los repentinos picos de tráfico.
Almacenamiento sin servidor
En el ecosistema de computación sin servidor, el almacenamiento sin servidor se refiere a soluciones de almacenamiento basadas en la nube que escalan automáticamente sin que los consumidores tengan que gestionar la infraestructura. Estos servicios ofrecen muchas capacidades, incluida la escalabilidad bajo demanda, alta disponibilidad y pago por uso. Por ejemplo, DynamoDB es una base de datos NoSQL totalmente gestionada y sin servidor diseñada para manejar modelos de datos de clave-valor y de documentos. Está diseñada específicamente para aplicaciones que requieren un rendimiento consistente a cualquier escala, ofreciendo una latencia de milisegundos de un solo dígito. También proporciona capacidades de integración perfecta con muchos otros servicios.
Los principales proveedores de servicios en la nube ofrecen numerosas opciones de almacenamiento sin servidor para necesidades específicas, como S3, ElastiCache, Aurora y muchos más.
Otros casos de uso
En la sección anterior, discutimos cómo aprovechar la arquitectura sin servidor para construir APIs de backend para una aplicación web. Hay varios otros casos de uso que pueden beneficiarse de la arquitectura sin servidor. Algunos de esos casos de uso incluyen:
Procesamiento de datos
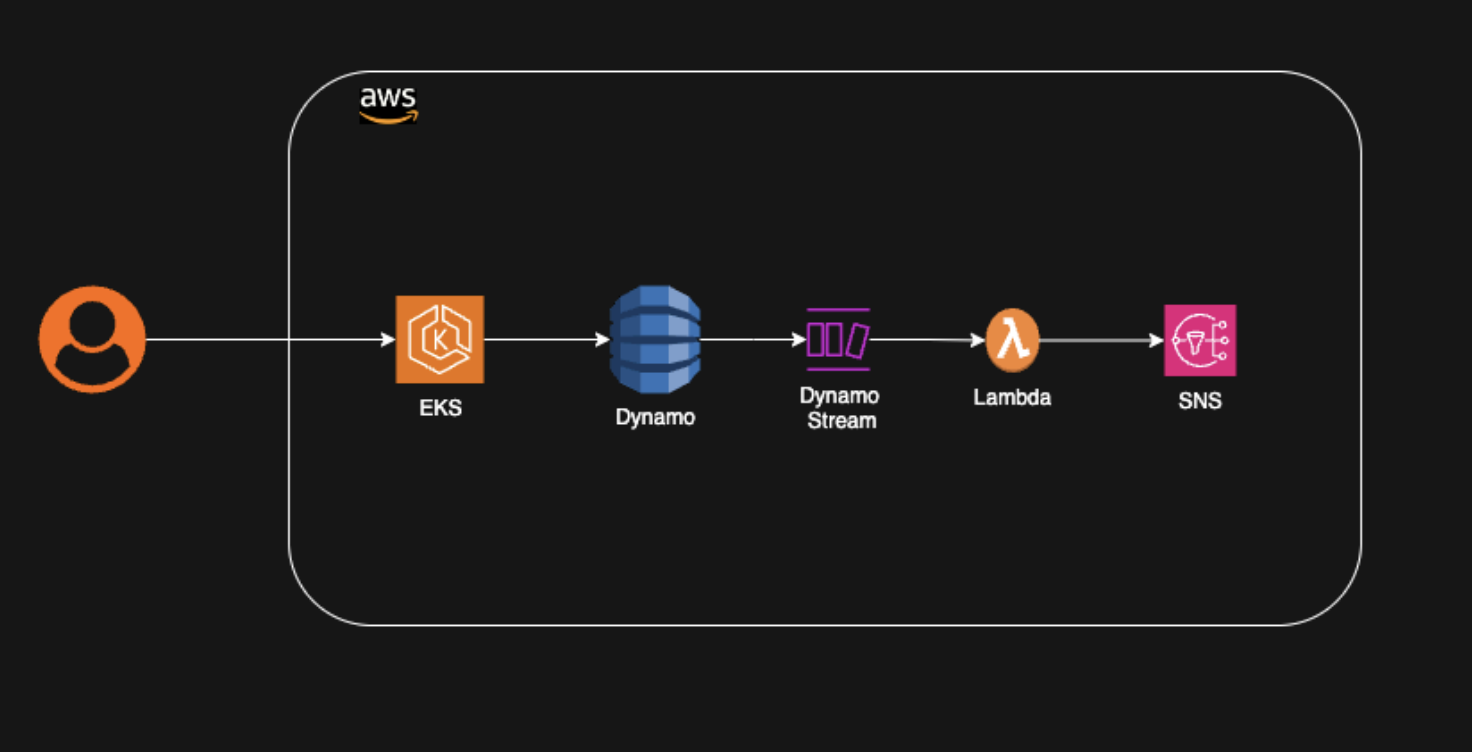
Exploraremos otro ejemplo de cómo la arquitectura sin servidor puede utilizarse para notificar a los servicios basados en cambios de datos en un almacén de datos. Por ejemplo, en una plataforma de comercio electrónico, digamos que al crear un pedido, varios servicios necesitan ser informados. Dentro del ecosistema de AWS, el pedido puede almacenarse en DynamoDB al crearse. Para notificar a otros servicios, se pueden desencadenar múltiples eventos basados en este evento de almacenamiento.
Usando DynamoDB Streams, una función Lambda puede ser invocada cuando ocurre este evento. Esta función Lambda puede luego enviar el evento de cambio a SNS (Simple Notification Service). SNS actúa como el servicio de notificación para notificar a varios otros servicios que están interesados en estos eventos.
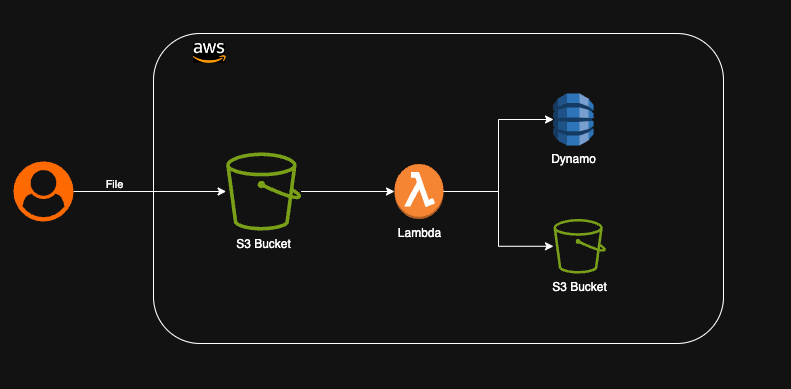
Procesamiento de Archivos en Tiempo Real
En muchas aplicaciones, los usuarios cargan imágenes que necesitan ser almacenadas, procesadas para cambiar de tamaño, convertidas a diferentes formatos y analizadas. Podemos lograr esta funcionalidad utilizando la arquitectura sin servidor de AWS de la siguiente manera. Cuando se carga una imagen, se envía a un bucket de S3 configurado para desencadenar un evento que invoque una función Lambda. La función Lambda puede procesar la imagen, almacenar metadatos en DynamoDB y almacenar imágenes redimensionadas en otro bucket de S3. Esta arquitectura escalable se puede utilizar para procesar millones de imágenes sin necesidad de gestionar ninguna infraestructura o intervención manual.
Desafíos
Las arquitecturas sin servidor ofrecen muchos beneficios, pero también plantean ciertos desafíos que deben ser abordados.
Inicio en Frío
Cuando se invoca una función serverless, la plataforma necesita crear, inicializar y ejecutar un nuevo contenedor para ejecutar el código. Este proceso, conocido como inicio en frío, puede introducir una latencia adicional en el flujo de trabajo. Técnicas como mantener las funciones activas o utilizar concurrencia provisionada pueden ayudar a reducir este retraso.
Monitoreo y Depuración
Dado que puede haber un gran número de invocaciones, el monitoreo y la depuración pueden volverse complejos. Puede ser desafiante identificar y depurar problemas en aplicaciones que son ampliamente utilizadas. Configurar herramientas como AWS CloudWatch para métricas, registros y alertas es altamente recomendado para abordar estos problemas.
Aunque las arquitecturas serverless se escalan automáticamente, las configuraciones de recursos deben estar optimizadas para prevenir cuellos de botella. La asignación adecuada de recursos y la implementación de estrategias de optimización de costos son esenciales.
Conclusión
La arquitectura serverless es un gran paso hacia el desarrollo de aplicaciones nativas de la nube respaldadas por cómputo y almacenamiento serverless. Se utiliza ampliamente en muchos tipos de aplicaciones, incluidos flujos de trabajo basados en eventos, procesamiento de datos, procesamiento de archivos y análisis de big data. Debido a su escalabilidad, agilidad y alta disponibilidad, la arquitectura serverless se ha convertido en una elección confiable para empresas de todos los tamaños.
Source:
https://dzone.com/articles/from-zero-to-scale-with-aws-serverless