













Introducción
En este tutorial, construirás una aplicación en Python capaz de extraer audio de un video de entrada, transcribir el audio extraído, generar un archivo de subtítulos basado en la transcripción y luego agregar el subtítulo a una copia del video de entrada.
Para construir esta aplicación, utilizarás FFmpeg para extraer audio de un video de entrada. Usarás Whisper de OpenAI para generar una transcripción del audio extraído y luego usarás esta transcripción para generar un archivo de subtítulos. Además, utilizarás FFmpeg para agregar el archivo de subtítulos generado a una copia del video de entrada.
FFmpeg es una suite de software potente y de código abierto para el manejo de datos multimedia, incluyendo tareas de procesamiento de audio y video. Proporciona una herramienta de línea de comandos que permite a los usuarios convertir, editar y manipular archivos multimedia con una amplia gama de formatos y códecs.
Whisper de OpenAI es un sistema de reconocimiento automático de voz (ASR) diseñado para convertir lenguaje hablado en texto escrito. Entrenado en una vasta cantidad de datos supervisados multilingües y multitarea, sobresale en transcribir contenido de audio diverso con alta precisión.
Al final de este tutorial, tendrás una aplicación capaz de agregar subtítulos a un video.
Requisitos previos
Para seguir este tutorial, el lector necesitará las siguientes herramientas:
-
FFmpeg instalado.
-
Un conocimiento básico de Python. Puedes seguir esta serie de tutoriales para aprender a programar en Python.
Paso 1: Crear el Directorio Raíz del Proyecto
En esta sección, crearás el directorio del proyecto, descargarás el video de entrada, crearás y activarás un entorno virtual, e instalarás los paquetes de Python necesarios.
Abre una ventana de terminal y navega a una ubicación adecuada para tu proyecto. Ejecuta el siguiente comando para crear el directorio del proyecto:
Navega al directorio del proyecto:
Descarga este video editado y guárdalo en el directorio raíz de tu proyecto como `input.mp4`. El video muestra a un niño llamado Rushawn cantando “Beautiful Day” de Jermaine Edward. El video editado que vas a usar en este tutorial fue tomado del siguiente video de YouTube: `:
`.
Crea un nuevo entorno virtual y llámalo `env`: `
`. Activa el entorno virtual: `
`. Ahora, utiliza el siguiente comando para instalar los paquetes necesarios para construir esta aplicación: `
`.
Con el comando anterior, instalaste las siguientes bibliotecas: `
- `.
– “: es una versión rediseñada del modelo Whisper de OpenAI que aprovecha `CTranslate2`, un motor de inferencia de alto rendimiento para modelos Transformer. Esta implementación logra hasta cuatro veces más velocidad que openai/whisper con una precisión comparable, todo mientras consume menos memoria. `
`
– “: es una versión rediseñada del modelo Whisper de OpenAI que aprovecha `CTranslate2`, un motor de inferencia de alto rendimiento para modelos Transformer. Esta implementación logra hasta cuatro veces más velocidad que openai/whisper con una precisión comparable, todo mientras consume menos memoria. `
-
ffmpeg-python: es una biblioteca de Python que proporciona un envoltorio alrededor de la herramienta FFmpeg, permitiendo a los usuarios interactuar con las funcionalidades de FFmpeg en scripts de Python fácilmente. A través de una interfaz Pythonica, permite tareas de procesamiento de video y audio, como edición, conversión y manipulación.
Ejecuta el siguiente comando para guardar los paquetes que se instalaron usando pip en el entorno virtual en un archivo llamado requirements.txt:
El archivo requirements.txt debería lucir similar al siguiente:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
En esta sección, creaste el directorio del proyecto, descargaste el video de entrada que se utilizará en este tutorial, configuraste un entorno virtual, lo activaste e instalaste los paquetes de Python necesarios. En la siguiente sección, generarás una transcripción para el video de entrada.
Paso 2 — Generando la transcripción del video
En esta sección, crearás el script de Python donde residirá la aplicación. Dentro de este script, utilizarás la biblioteca ffmpeg-python para extraer la pista de audio del video de entrada descargado en la sección anterior y guardarla como un archivo WAV. A continuación, utilizarás la biblioteca faster-whisper para generar una transcripción para el audio extraído.
En el directorio raíz de tu proyecto, crea un archivo llamado main.py y agrega el siguiente código:
Aquí, el código comienza importando varias bibliotecas y módulos, incluyendo time, math, ffmpeg de ffmpeg-python, y un módulo personalizado llamado WhisperModel de faster_whisper. Estas bibliotecas serán utilizadas para el procesamiento de video y audio, transcripción y generación de subtítulos.
A continuación, el código establece el nombre del archivo de video de entrada, lo almacena en una constante llamada input_video, y luego almacena el nombre del archivo de video sin la extensión .mp4 en una constante llamada input_video_name. Establecer el nombre del archivo de entrada aquí te permitirá trabajar con múltiples videos de entrada sin sobrescribir los archivos de subtítulos y videos de salida generados para ellos.
Agrega el siguiente código al final de tu main.py:
El código anterior define una función llamada extract_audio() que es responsable de extraer el audio del video de entrada.
Primero, establece el nombre del archivo de audio que se extraerá como un nombre formado agregando audio- al nombre base del video de entrada con una extensión .wav, y guarda este nombre en una constante llamada extracted_audio.
Luego, el código llama al método ffmpeg.input() de la biblioteca ffmpeg para abrir el video de entrada y crea un objeto de flujo de entrada llamado stream.
A continuación, el código llama al método ffmpeg.output() para crear un objeto de flujo de salida con el flujo de entrada y el nombre del archivo de audio extraído definido.
Después de configurar el flujo de salida, el código llama al método ffmpeg.run(), pasando el flujo de salida como parámetro para iniciar el proceso de extracción de audio y guardar el archivo de audio extraído en el directorio raíz del proyecto. Además, se incluye un parámetro booleano, overwrite_output=True, para reemplazar cualquier archivo de salida preexistente con el recién generado si dicho archivo ya existe.
Finalmente, el código devuelve el nombre del archivo de audio extraído.
Agrega el siguiente código debajo de la función extract_audio():
Aquí, el código define una función llamada run() y luego la llama. Esta función llama a todas las funciones necesarias para generar y agregar subtítulos a un video.
Dentro de la función, el código llama a la función extract_audio() para extraer el audio de un video y luego almacena el nombre del archivo de audio devuelto en una variable llamada extracted_audio.
Regresa a tu terminal y ejecuta el siguiente comando para ejecutar el script main.py:
Después de ejecutar el comando anterior, la salida de FFmpeg se mostrará en la terminal, y se almacenará un archivo llamado `audio-input.wav` que contiene el audio extraído del video de entrada en el directorio raíz de tu proyecto.
Vuelve a tu archivo main.py y agrega el siguiente código entre las funciones extract_audio() y run():
El código anterior define una función llamada transcribe encargada de transcribir el archivo de audio extraído del video de entrada.
Primero, el código crea una instancia del objeto WhisperModel y establece el tipo de modelo en small. Whisper de OpenAI tiene los siguientes tipos de modelos: tiny, base, small, medium y large. El modelo tiny es el más pequeño y rápido, y el modelo large es el más grande y lento pero más preciso.
A continuación, el código llama al método model.transcribe() con el audio extraído como argumento para recuperar la función de segmentos y la información de audio y almacenarlos en variables llamadas info y segments respectivamente. La función de segmentos es un generador de Python, por lo que la transcripción solo comenzará cuando el código itere sobre ella. La transcripción puede completarse recopilando los segmentos en una lista o un for loop.
A continuación, el código almacena el idioma detectado en el audio en una constante llamada info e imprime en la consola.
Después de imprimir el idioma detectado, el código reúne los segmentos de transcripción en una lista para ejecutar la transcripción y almacena los segmentos reunidos en una variable también llamada segments. Luego, el código recorre la lista de segmentos de transcripción e imprime en la consola el tiempo de inicio, el tiempo de finalización y el texto de cada segmento.
Finalmente, el código devuelve el idioma detectado en el audio y los segmentos de transcripción.
Agrega el siguiente código dentro de la función run():
El código agregado llama a la función transcribe con el audio extraído como argumento y almacena los valores devueltos en constantes llamadas language y segments.
Vuelve a tu terminal y ejecuta el siguiente comando para ejecutar el script main.py:
La primera vez que ejecutes este script, el código primero descargará y almacenará en caché el modelo Whisper Small, las ejecuciones posteriores serán mucho más rápidas.
Después de ejecutar el comando anterior, deberías ver la siguiente salida en la consola:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
La salida anterior muestra que el idioma detectado en el audio es inglés (en). Además, muestra el tiempo de inicio y finalización de cada segmento de transcripción en segundos y el texto.
Advertencia: Aunque el reconocimiento de voz Whisper de OpenAI es muy preciso, no es 100% preciso, puede estar sujeto a limitaciones y errores ocasionales, especialmente en escenarios lingüísticos o de audio desafiantes. Así que siempre asegúrate de verificar la transcripción manualmente.
En esta sección, creaste un script de Python para la aplicación. Dentro del script, se utilizó ffmpeg-python para extraer el audio del video descargado y guardarlo como un archivo WAV. Luego, se utilizó la biblioteca faster-whisper para generar una transcripción del audio extraído. En la siguiente sección, generarás un archivo de subtítulos basado en la transcripción y luego agregarás los subtítulos al video.
Paso 3 — Generación y adición de subtítulos al video
En esta sección, primero comprenderás qué es un archivo de subtítulos y cómo está estructurado. Luego, usarás los segmentos de transcripción generados en la sección anterior para crear un archivo de subtítulos. Después de crear el archivo de subtítulos, utilizarás la biblioteca ffmpeg-python para agregar el archivo de subtítulos a una copia del video de entrada.
Comprendiendo los subtítulos: Estructura y Tipos
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Índice de Subtítulos: Un número secuencial que indica el orden del subtítulo en el archivo.
-
Timecodes: Marcadores de inicio y fin de tiempo que especifican cuándo se debe mostrar el texto de los subtítulos. Los timecodes suelen tener el formato
HH:MM:SS,sss(horas, minutos, segundos, milisegundos). -
Texto de los Subtítulos: El texto real de la entrada de subtítulo, que representa contenido hablado o escrito. Este texto se muestra en la pantalla durante el intervalo de tiempo especificado.
Por ejemplo, una entrada de subtítulo en un archivo SRT podría lucir así:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
En este ejemplo, el índice es 1, los timecodes indican que el subtítulo debe mostrarse desde 10.5 segundos hasta 15 segundos, y el texto del subtítulo es Este es un ejemplo de subtítulo.
Los subtítulos se pueden dividir en dos tipos principales:
-
Subtítulos blandos: También conocidos como subtítulos cerrados, se almacenan externamente como archivos separados (como SRT) y pueden agregarse o eliminarse de forma independiente del video. Brindan flexibilidad al espectador, permitiendo alternar, cambiar de idioma y personalizar configuraciones. Sin embargo, su efectividad depende del soporte del reproductor de video y no todos los reproductores acomodan universalmente los subtítulos blandos.
-
Subtítulos duros: Se incrustan permanentemente en los fotogramas del video durante la edición o codificación, permaneciendo como una parte fija del video. Aunque aseguran visibilidad constante, incluso en reproductores que no admiten archivos de subtítulos externos, las modificaciones o desactivación requieren la recodificación completa del video, limitando el control del usuario
Creación del archivo de subtítulos
Regrese a su archivo main.py y agregue el siguiente código entre las funciones transcribe() y run():
Aquí, el código define una función llamada format_time() que se encarga de convertir el tiempo de inicio y fin de un segmento de transcripción dado en segundos a un formato de tiempo compatible con los subtítulos que muestra horas, minutos, segundos y milisegundos (HH:MM:SS,sss).
El código primero calcula las horas, minutos, segundos y milisegundos a partir del tiempo dado en segundos, los formatea en consecuencia y luego devuelve el tiempo formateado.
Agrega el siguiente código entre las funciones format_time() y run():
El código añadido define una función llamada generate_subtitle_file() que toma como parámetros el idioma detectado en el audio extraído y los segmentos de transcripción. Esta función se encarga de generar un archivo de subtítulos SRT basado en el idioma y los segmentos de transcripción.
Primero, el código establece el nombre del archivo de subtítulos concatenando sub- y el idioma detectado al nombre base del vídeo de entrada con la extensión “.srt”, y guarda este nombre en una constante llamada subtitle_file. Además, el código define una variable llamada text donde se almacenarán las entradas de subtítulos.
Luego, el código itera a través de los segmentos transcritos, formatea los tiempos de inicio y fin usando la función format_time(), utiliza estos valores formateados junto con el índice del segmento y el texto para crear una entrada de subtítulo, y luego añade una línea vacía para separar cada entrada de subtítulo.
Por último, el código crea un archivo de subtítulos en el directorio raíz de tu proyecto con el nombre establecido anteriormente, añade las entradas de subtítulos al archivo, y devuelve el nombre del archivo de subtítulos.
Agrega el siguiente código al final de tu función run():
El código añadido llama a la función generate_subtitle_file() con el lenguaje detectado y los segmentos de transcripción como argumentos, y guarda el nombre del archivo de subtítulos devuelto en una constante llamada subtitle_file.
Vuelve a tu terminal y ejecuta el siguiente comando para correr el script main.py:
Después de ejecutar el comando anterior, se guardará un archivo de subtítulos llamado sub-input.en.srt en el directorio raíz de tu proyecto.
Abre el archivo de subtítulos sub-input.en.srt y deberías ver algo similar a lo siguiente:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Añadiendo subtítulos a vídeos
Agrega el siguiente código entre las funciones generate_subtitle_file() y run():
Aquí, el código define una función llamada add_subtitle_to_video() que toma como parámetros un valor booleano usado para determinar si debe añadir un subtítulo suave o duro, el nombre del archivo de subtítulos, y el lenguaje detectado en la transcripción. Esta función es responsable de añadir subtítulos suaves o duros a una copia del vídeo de entrada.
Primero, el código utiliza el método ffmpeg.input() con el archivo de video de entrada y el archivo de subtítulos para crear objetos de flujo de entrada para el video y el archivo de subtítulos, y los almacena en constantes llamadas video_input_stream y subtitle_input_stream respectivamente.
Después de crear los flujos de entrada, el código establece el nombre del archivo de video de salida concatenando output- al nombre base del video de entrada con la extensión “.mp4”, y almacena este nombre en una constante llamada output_video. Además, establece el nombre de la pista de subtítulos como el nombre del archivo de subtítulos sin la extensión .srt y almacena este nombre en una constante llamada subtitle_track_title.
A continuación, el código verifica si el booleano soft_subtitle está configurado como True, indicando que debería agregar un subtítulo suave.
En ese caso, el código llama al método ffmpeg.output() para crear un objeto de flujo de salida con los flujos de entrada, el nombre del archivo de video de salida y las siguientes opciones para el video de salida:
-
"c": "copy": Especifica que el códec de video y otros parámetros de video deben copiarse directamente desde la entrada hasta la salida sin volver a codificar. -
"c:s": "mov_text": Especifica que el códec de subtítulos y sus parámetros también deben copiarse desde la entrada hasta la salida sin volver a codificar.mov_textes un códec de subtítulos comúnmente utilizado en archivos MP4/MOV. -
"metadata:s:s:0": f"language={subtitle_language}": Establece los metadatos de idioma para el flujo de subtítulos. El idioma se establece en el valor almacenado ensubtitle_language -
"metadata:s:s:0": f"title={subtitle_track_title}": Establece los metadatos de título para el flujo de subtítulos. El título se establece en el valor almacenado ensubtitle_track_title
Finalmente, el código llama al método ffmpeg.run(), pasando el flujo de salida como parámetro para agregar el subtítulo suave al video y guardar el archivo de video de salida en el directorio raíz de tu proyecto.
Agrega el siguiente código al final de tu función add_subtitle_to_video():
El código resaltado se ejecutará si la variable booleana soft_subtitle está establecida en False, lo que indica que se debe agregar un subtítulo duro.
En ese caso, primero, el código llama al método ffmpeg.output() para crear un objeto de flujo de salida con el flujo de video de entrada, el nombre del archivo de video de salida y el parámetro vf=f"subtitles={subtitle_file}". El vf significa “filtro de video” y se utiliza para aplicar un filtro al flujo de video. En este caso, el filtro que se aplica es la adición del subtítulo.
Finalmente, el código llama al método ffmpeg.run(), pasando el flujo de salida como parámetro para agregar el subtítulo duro al video y guardar el archivo de video de salida en el directorio raíz de su proyecto.
Agregue el siguiente código resaltado a la función run():
El código resaltado llama al método add_subtitle_to_video() con el parámetro soft_subtitle establecido en True, el nombre del archivo de subtítulos y el idioma del subtítulo para agregar un subtítulo suave a una copia del video de entrada.
Vuelva a su terminal y ejecute el siguiente comando para ejecutar el script main.py:
Después de ejecutar el comando anterior, se guardará un archivo de video de salida con el nombre output-input.mp4 en el directorio raíz de su proyecto.
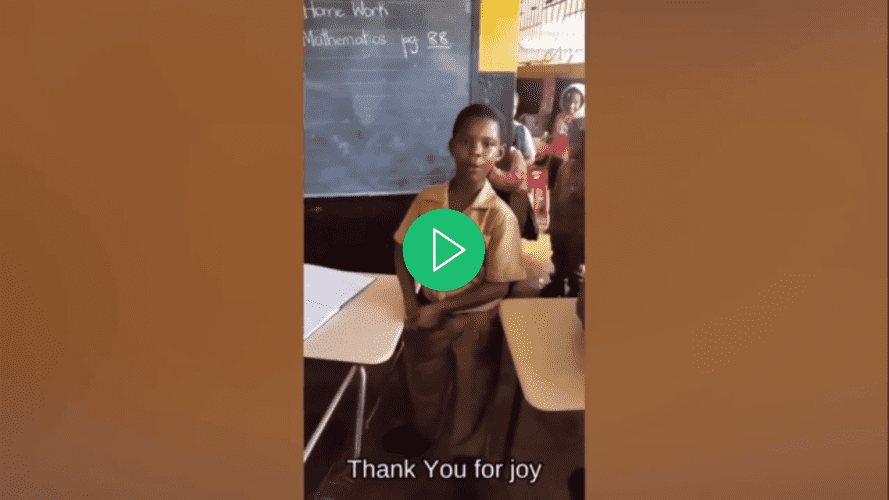
Abra el video usando su reproductor de video preferido, seleccione un subtítulo para el video y observe cómo el subtítulo no se mostrará hasta que lo seleccione.
Regresa al archivo main.py, navega hasta la función run(), y en la llamada a la función add_subtitle_to_video(), establece el parámetro soft_subtitle en False:
Aquí, estableces el parámetro soft_subtitle en False para agregar subtítulos fijos al vídeo.
Regresa a tu terminal y ejecuta el siguiente comando para correr el script main.py:
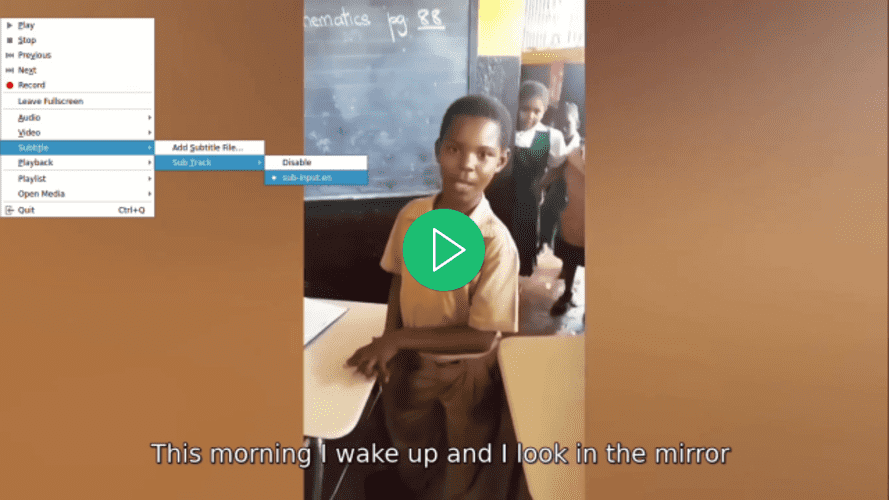
Después de ejecutar el comando anterior, el archivo de vídeo output-input.mp4 ubicado en el directorio raíz de tu proyecto será sobrescrito.
Abre el vídeo usando tu reproductor de vídeo preferido, intenta seleccionar un subtítulo para el vídeo y observa cómo no está disponible, pero aún así se muestra un subtítulo:

En esta sección, adquiriste una comprensión de la estructura de un archivo de subtítulos SRT y utilizaste los segmentos de transcripción de la sección anterior para crear uno. Posteriormente, se utilizó la biblioteca ffmpeg-python para añadir el archivo de subtítulos generado al vídeo.
Conclusión
En este tutorial, utilizaste las bibliotecas ffmpeg-python y faster-whisper de Python para construir una aplicación capaz de extraer audio de un vídeo de entrada, transcribir el audio extraído, generar un archivo de subtítulos basado en la transcripción y añadir el subtítulo a una copia del vídeo de entrada.