













En los primeros días de la informática, las aplicaciones manejaban tareas de forma secuencial. A medida que la escala creció con millones de usuarios, este enfoque se volvió impráctico. El procesamiento asíncrono permitió manejar múltiples tareas de forma concurrente, pero el manejo de hilos/procesos en una sola máquina llevó a restricciones de recursos y complejidad.
Es aquí donde entra en juego el procesamiento paralelo distribuido. Al distribuir la carga de trabajo en varias máquinas, cada una dedicada a una parte de la tarea, se ofrece una solución escalable y eficiente. Si tienes una función para procesar un gran lote de archivos, puedes dividir la carga de trabajo entre múltiples máquinas para procesar archivos de forma concurrente en lugar de manejarlos de forma secuencial en una sola máquina. Además, mejora el rendimiento aprovechando los recursos combinados y proporciona escalabilidad y tolerancia a fallos. A medida que aumentan las demandas, puedes agregar más máquinas para aumentar los recursos disponibles.
Es un desafío construir y ejecutar aplicaciones distribuidas a gran escala, pero existen varios frameworks y herramientas para ayudarte. En esta publicación de blog, examinaremos un framework de computación distribuida de código abierto: Ray. También veremos KubeRay, un operador de Kubernetes que permite una integración fluida de Ray con clústeres de Kubernetes para la computación distribuida en entornos nativos de la nube. Pero primero, vamos a entender dónde ayuda el paralelismo distribuido.
¿Dónde Ayuda el Procesamiento Paralelo Distribuido?
Cualquier tarea que se beneficie de dividir su carga de trabajo entre varias máquinas puede utilizar el procesamiento paralelo distribuido. Este enfoque es particularmente útil para escenarios como el rastreo web, la analítica de datos a gran escala, el entrenamiento de modelos de aprendizaje automático, el procesamiento de transmisiones en tiempo real, el análisis de datos genómicos y el renderizado de video. Al distribuir tareas en varios nodos, el procesamiento paralelo distribuido mejora significativamente el rendimiento, reduce el tiempo de procesamiento y optimiza la utilización de recursos, lo que lo hace esencial para aplicaciones que requieren alto rendimiento y manejo rápido de datos.
Cuando no se necesita el procesamiento paralelo distribuido
- Aplicaciones a pequeña escala: Para conjuntos de datos pequeños o aplicaciones con requisitos de procesamiento mínimos, los costos de administrar un sistema distribuido pueden no estar justificados.
- Dependencias de datos fuertes: Si las tareas tienen una alta interdependencia y no se pueden paralelizar fácilmente, el procesamiento distribuido puede ofrecer poco beneficio.
- Restricciones de tiempo real: Algunas aplicaciones en tiempo real (por ejemplo, sitios web financieros y de reserva de boletos) requieren una latencia extremadamente baja, lo que puede no ser posible con la complejidad adicional de un sistema distribuido.
- Recursos limitados: Si la infraestructura disponible no puede soportar los costos de un sistema distribuido (por ejemplo, ancho de banda de red insuficiente, número limitado de nodos), puede ser mejor optimizar el rendimiento de una sola máquina.
Cómo Ray ayuda con el procesamiento paralelo distribuido
Ray es un marco de procesamiento paralelo distribuido que encapsula todos los beneficios de la computación distribuida y soluciones a los desafíos que discutimos, como tolerancia a fallas, escalabilidad, gestión de contexto, comunicación, y más. Es un marco Pythonico, que permite el uso de bibliotecas y sistemas existentes para trabajar con él. Con la ayuda de Ray, un programador no necesita manejar las piezas de la capa de cálculo de procesamiento paralelo. Ray se encargará de la programación y el escalado automático basado en los requisitos de recursos especificados.
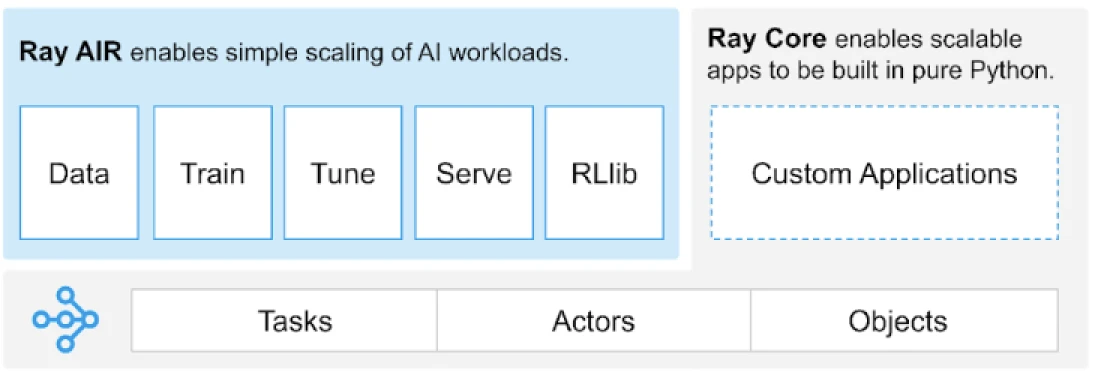
Ray proporciona una API universal de tareas, actores y objetos para construir aplicaciones distribuidas.
(Fuente de la imagen)
Ray proporciona un conjunto de bibliotecas construidas sobre los primitivos básicos, es decir, Tareas, Actores, Objetos, Controladores y Trabajos. Estos proporcionan una API versátil para ayudar a construir aplicaciones distribuidas. Echemos un vistazo a los primitivos básicos, también conocidos como Ray Core.
Primitivos básicos de Ray
- Tareas: Las tareas de Ray son funciones arbitrarias de Python que se ejecutan de forma asíncrona en trabajadores de Python separados en un nodo de un clúster de Ray. Los usuarios pueden especificar sus requisitos de recursos en términos de CPUs, GPUs y recursos personalizados que son utilizados por el planificador de clúster para distribuir tareas para una ejecución en paralelo.
- Actores: Lo que las tareas son para las funciones, los actores son para las clases. Un actor es un trabajador con estado, y los métodos de un actor se programan en ese trabajador específico y pueden acceder y modificar el estado de ese trabajador. Al igual que las tareas, los actores admiten requisitos de recursos de CPU, GPU y personalizados.
- Objetos: En Ray, las tareas y actores crean y computan objetos. Estos objetos remotos pueden ser almacenados en cualquier lugar en un clúster de Ray. Las Referencias de Objetos se utilizan para hacer referencia a ellos, y se almacenan en la memoria compartida distribuida de Ray.
- Controladores: La raíz del programa, o el programa “principal”: este es el código que ejecuta
ray.init() - Trabajos: La colección de tareas, objetos y actores que se originan (de forma recursiva) desde el mismo controlador y su entorno de ejecución
Para obtener información sobre los primitivos, puedes consultar la documentación central de Ray.
Métodos Clave de Ray Core
A continuación se muestran algunos de los métodos clave dentro de Ray Core que se utilizan comúnmente:
-
ray.init()– Inicia el tiempo de ejecución de Ray y se conecta al clúster de Ray.import ray ray.init()
-
@ray.remote– Decorador que especifica una función o clase de Python para ser ejecutada como una tarea (función remota) o actor (clase remota) en un proceso diferente@ray.remote def remote_function(x): return x * 2
-
.remote– Sufijo para las funciones y clases remotas; las operaciones remotas son asíncronasresult_ref = remote_function.remote(10)
-
ray.put()– Coloca un objeto en la tienda de objetos en memoria; devuelve una referencia de objeto usada para pasar el objeto a cualquier función remota o llamada de método.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Obtiene un objeto o varios objetos remotos de la tienda de objetos especificando la(s) referencia(s) del objeto.result = ray.get(result_ref) original_data = ray.get(data_ref)
Aquí tienes un ejemplo de cómo usar la mayoría de los métodos clave básicos:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Usando .remote para crear una tarea
future = calculate_square.remote(5)
# Obtener el resultado
result = ray.get(future)
print(f"The square of 5 is: {result}")¿Cómo funciona Ray?
El clúster Ray es como un equipo de computadoras que comparten el trabajo de ejecutar un programa. Consiste en un nodo principal y varios nodos trabajadores. El nodo principal gestiona el estado del clúster y la programación, mientras que los nodos trabajadores ejecutan tareas y gestionan actores
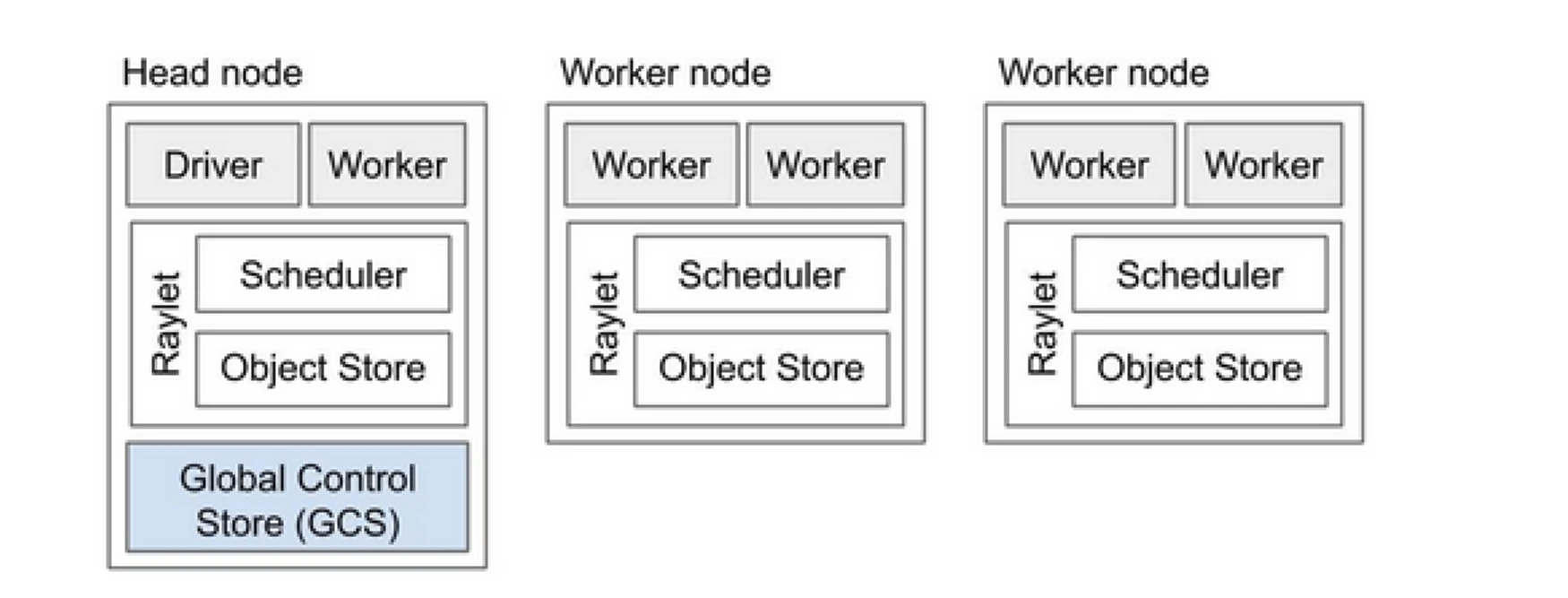
Componentes del clúster Ray
- Almacén de Control Global (GCS): El GCS gestiona los metadatos y el estado global del clúster Ray. Realiza un seguimiento de tareas, actores y disponibilidad de recursos, asegurando que todos los nodos tengan una vista consistente del sistema.
- Planificador: El planificador distribuye tareas y actores entre los nodos disponibles. Garantiza una utilización eficiente de recursos y equilibrio de carga al considerar los requisitos de recursos y las dependencias de tareas.
- Nodo principal: El nodo principal orquesta todo el clúster Ray. Ejecuta el GCS, gestiona la programación de tareas y supervisa la salud de los nodos trabajadores.
- Nodos trabajadores: Los nodos trabajadores ejecutan tareas y actores. Realizan los cálculos reales y almacenan objetos en su memoria local.
- Raylet: Gestiona recursos compartidos en cada nodo y se comparte entre todos los trabajos en ejecución concurrentemente.
Puedes consultar la documentación de Arquitectura Ray v2 para obtener información más detallada.
Trabajar con aplicaciones de Python existentes no requiere muchos cambios. Los cambios necesarios se centrarían principalmente en la función o clase que necesita ser distribuida de manera natural. Puedes agregar un decorador y convertirlo en tareas o actores. Veamos un ejemplo de esto.
Convertir una Función de Python en una Tarea de Ray
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Convertir una Clase de Python en un Actor de Ray
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Almacenar Información en Objetos de Ray
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Para aprender más sobre su concepto, dirígete a Ray Core Key Concept docs.
Ray vs Enfoque Tradicional de Procesamiento Paralelo Distribuido
A continuación se presenta un análisis comparativo entre el enfoque tradicional (sin Ray) y Ray en Kubernetes para habilitar el procesamiento paralelo distribuido.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Despliegue | Configuración y montaje manual | Automatizado con el Operador KubeRay |
| Escalado | Escalado manual | Escalado automático con RayAutoScaler y Kubernetes |
| Tolerancia a Fallos | Mecanismos de tolerancia a fallos personalizados | Tolerancia a fallos incorporada con Kubernetes y Ray |
| Gestión de Recursos | Asignación manual de recursos | Asignación y gestión de recursos automatizada |
| Balanceo de Carga | Soluciones de balanceo de carga personalizadas | Equilibrado de carga incorporado con Kubernetes |
| Gestión de dependencias | Instalación manual de dependencias | Entorno consistente con contenedores Docker |
| Coordinación de clústeres | Complejo y manual | Simplificado con el descubrimiento y coordinación de servicios de Kubernetes |
| Carga de desarrollo | Alta, con soluciones personalizadas necesarias | Reducida, con Ray y Kubernetes manejando muchos aspectos |
| Flexibilidad | Adaptabilidad limitada a cargas de trabajo cambiantes | Alta flexibilidad con escalado dinámico y asignación de recursos |
Kubernetes proporciona una plataforma ideal para ejecutar aplicaciones distribuidas como Ray debido a sus robustas capacidades de orquestación. A continuación se presentan los puntos clave que establecen el valor de ejecutar Ray en Kubernetes:
- Administración de recursos
- Escalabilidad
- Orquestación
- Integración con el ecosistema
- Implementación y gestión sencillas
El Operador KubeRay hace posible ejecutar Ray en Kubernetes.
¿Qué es KubeRay?
El Operador KubeRay simplifica la gestión de clústeres de Ray en Kubernetes al automatizar tareas como implementación, escalado y mantenimiento. Utiliza Definiciones de Recursos Personalizados (CRDs) de Kubernetes para gestionar recursos específicos de Ray.
CRDs de KubeRay
Tiene tres CRDs distintos:
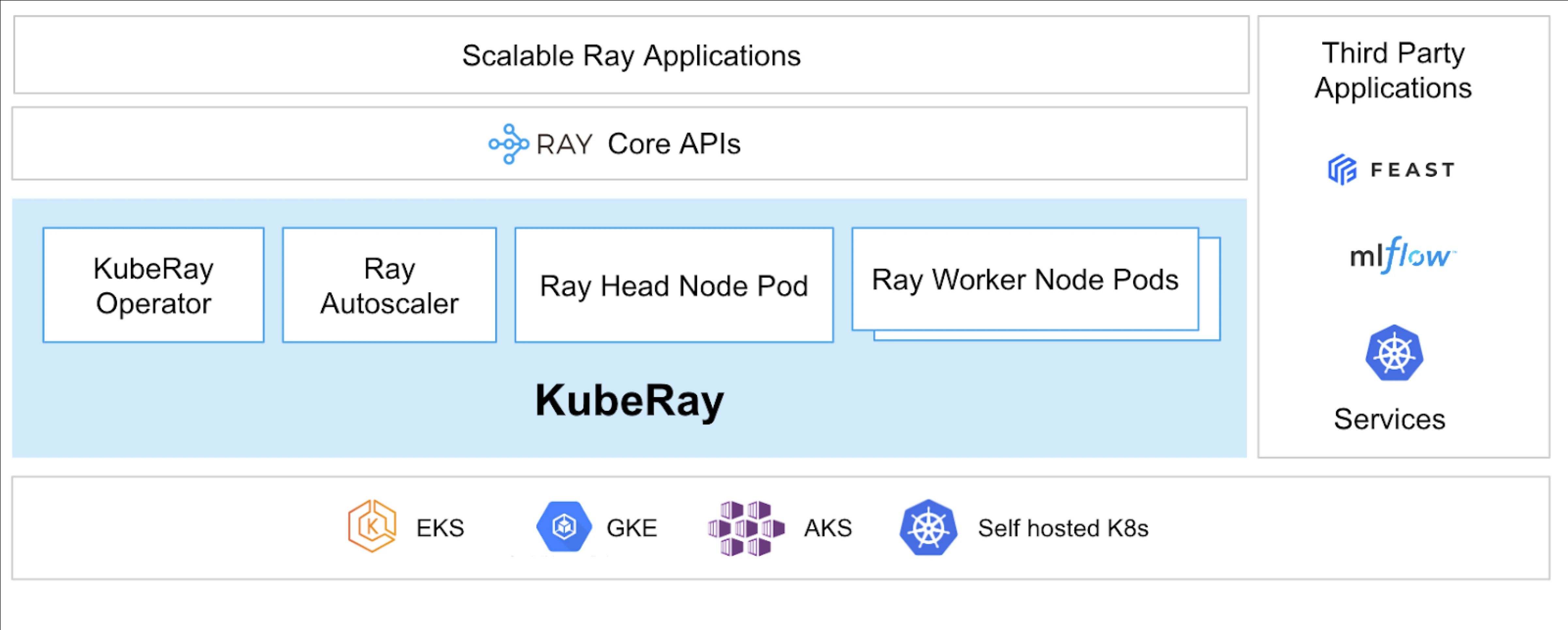
- RayCluster: Este CRD ayuda a gestionar el ciclo de vida de RayCluster y se encarga del escalado automático según la configuración definida.
- RayJob: Es útil cuando hay un trabajo único que se desea ejecutar en lugar de mantener un RayCluster en espera todo el tiempo. Crea un RayCluster y envía el trabajo cuando está listo. Una vez que el trabajo está hecho, elimina el RayCluster. Esto ayuda a reciclar automáticamente el RayCluster.
- RayService: Esto también crea un RayCluster pero despliega una aplicación RayServe en él. Este CRD hace posible realizar actualizaciones en el lugar de la aplicación, brindando actualizaciones sin tiempo de inactividad para garantizar la alta disponibilidad de la aplicación.
Casos de uso de KubeRay
Despliegue de un Modelo Bajo Demanda Usando RayService
RayService le permite desplegar modelos bajo demanda en un entorno de Kubernetes. Esto puede ser particularmente útil para aplicaciones como generación de imágenes o extracción de texto, donde los modelos se despliegan solo cuando se necesitan.
Aquí hay un ejemplo de difusión estable. Una vez que se aplica en Kubernetes, creará RayCluster y también ejecutará un RayService, que servirá el modelo hasta que elimine este recurso. Permite a los usuarios tomar el control de los recursos.
Entrenar un Modelo en un Grupo de GPU Utilizando RayJob
RayService satisface diferentes requisitos del usuario, donde mantiene el modelo o aplicación desplegada hasta que se elimina manualmente. En contraste, RayJob permite trabajos únicos para casos de uso como entrenamiento de un modelo, preprocesamiento de datos o inferencia para un número fijo de indicaciones dadas.
Ejecutar un Servidor de Inferencia en Kubernetes Utilizando RayService o RayJob
Generalmente, ejecutamos nuestra aplicación en Despliegues, que mantienen las actualizaciones continuas sin tiempo de inactividad. De manera similar, en KubeRay, esto se puede lograr utilizando RayService, que despliega el modelo o aplicación y maneja las actualizaciones continuas.
Sin embargo, puede haber casos en los que simplemente desee realizar inferencias por lotes en lugar de ejecutar los servidores de inferencia o aplicaciones durante mucho tiempo. Aquí es donde puede aprovechar RayJob, que es similar al recurso de Trabajo de Kubernetes.
La Inferencia por Lotes de Clasificación de Imágenes con Huggingface Vision Transformer es un ejemplo de RayJob, que realiza Inferencias por Lotes.
Estos son los casos de uso de KubeRay, que le permiten hacer más con el grupo de Kubernetes. Con la ayuda de KubeRay, puede ejecutar cargas de trabajo mixtas en el mismo grupo de Kubernetes y delegar la programación de cargas de trabajo basadas en GPU a Ray.
Conclusión
El procesamiento paralelo distribuido ofrece una solución escalable para manejar tareas de gran escala y que requieren muchos recursos. Ray simplifica las complejidades de construir aplicaciones distribuidas, mientras que KubeRay integra Ray con Kubernetes para un despliegue y escalado sin problemas. Esta combinación mejora el rendimiento, la escalabilidad y la tolerancia a fallos, lo que lo hace ideal para el web crawling, análisis de datos y tareas de aprendizaje automático. Al aprovechar Ray y KubeRay, puedes gestionar de manera eficiente la computación distribuida, satisfaciendo las demandas del mundo actual impulsado por datos con facilidad.
No solo eso, sino que a medida que nuestros tipos de recursos de computación cambian de CPU a basados en GPU, se vuelve importante contar con una infraestructura en la nube eficiente y escalable para todo tipo de aplicaciones, ya sea inteligencia artificial o procesamiento de grandes datos.
Si encontraste esta publicación informativa y atractiva, me encantaría conocer tus opiniones al respecto, así que inicia una conversación en LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray