













Las métricas de distancia forman el núcleo de numerosos algoritmos en ciencia de datos y aprendizaje automático, permitiendo la medición de similitud o diferencia entre puntos de datos. En este guía, exploraremos los fundamentos de la distancia de Minkowski, sus propiedades matemáticas y sus implementaciones. Examinaremos cómo se relaciona con otras medidas de distancia comunes y demostraremos su uso a través de ejemplos de codificación en Python y R.
Cualquiera que sea el desarrollo de algoritmos de agrupamiento, la labor en detección de anomalías o la ajuste fino de modelos de clasificación, entender la distancia de Minkowski puede mejorar su enfoque en el análisis de datos y el desarrollo de modelos. Vamos a echar un vistazo.
¿Qué es la Distancia de Minkowski?
La distancia de Minkowski es una métrica versátil utilizada en espacios vectoriales normados, nombrada en honor al matemático alemán Hermann Minkowski. Es una generalización de varias medidas de distancia bien conocidas, lo que la hace un concepto fundamental en varios campos como la matemática, la ciencia informática y el análisis de datos.
En su núcleo, la distancia de Minkowski proporciona una manera de medir la distancia entre dos puntos en un espacio multi dimensional. Lo que la hace particularmente útil es su capacidad para abarcar otras medidas de distancia como casos especiales, principalmente a través de un parámetro p. Este parámetro permite a la distancia de Minkowski adaptarse a diferentes espacios de problemas y características de los datos. La fórmula general para la distancia de Minkowski es:
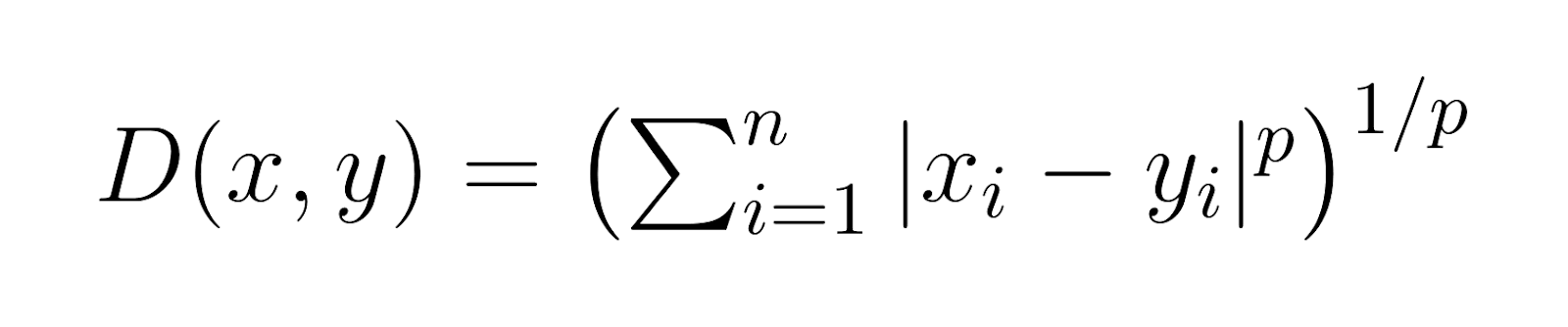
Donde:
-
xyyson dos puntos en un espacio n-dimensional -
pes un parámetro que determine el tipo de distancia (p ≥ 1) -
|xi - yi|representa la diferencia absoluta entre las coordenadas de x e y en cada dimensión
La distancia de Minkowski es útil por dos razones principales. Por una parte, proporciona flexibilidad para cambiar entre la distancia de Manhattan o la distancia de Euclides según sea necesario. Segundo, reconoce que no todos los conjuntos de datos (piense en espacios de alta dimensión) son bien-adaptados a la distancia puramente de Manhattan o puramente de Euclides.
En práctica, el parámetro p se elige típicamente integrando un flujo de trabajo de validación tren/prueba. Mediante la prueba de diferentes valores de p durante la validación cruzada, puede determinar cuál es el valor que proporciona el mejor rendimiento del modelo para su conjunto de datos específico.
Cómo funciona la Distancia de Minkowski
Veamos cómo la distancia de Minkowski se relaciona con otras fórmulas de distancia y luego pasemos por un ejemplo.
Generalización de otras métricas de distancia
La primera cosa que considerar es cómo la fórmula de distancia de Minkowski contiene dentro de ella las fórmulas para la distancia de Manhattan, la distancia de Euclides y la distancia de Chebyshev.
Distancia de Manhattan (p = 1):
Cuando p se establece en 1, la distancia de Minkowski se convierte en distancia de Manhattan.
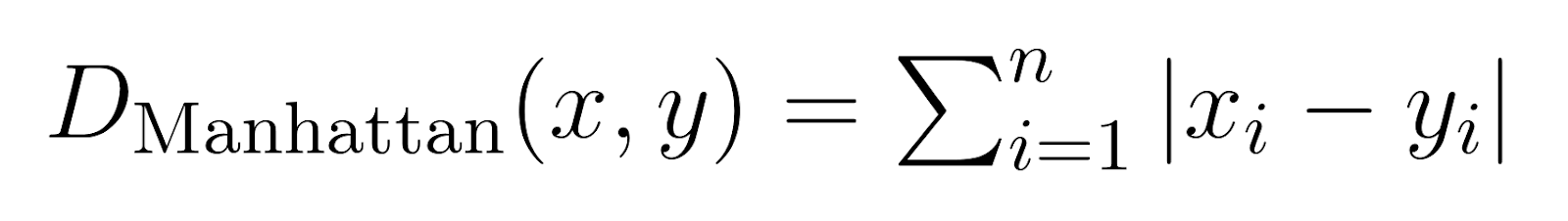
También conocida como distancia de bloques de la ciudad o norma L1, la Distancia de Manhattan mide la suma de las diferencias absolutas.
Distancia de Euclides (p = 2):
Cuando p se establece en 2, la distancia de Minkowski se convierte en distancia de Euclides.
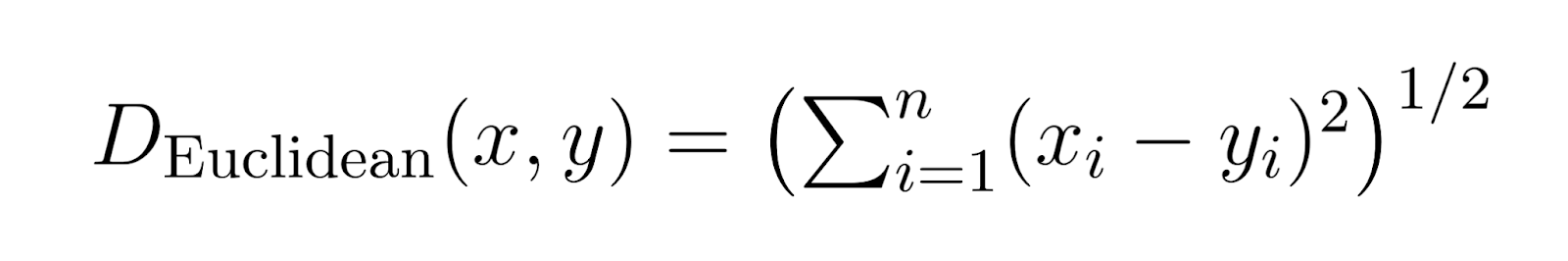
Distancia euclidiana es la métrica de distancia más común, que representa la distancia recta entre dos puntos.
Distancia de Chebyshev (p → ∞):
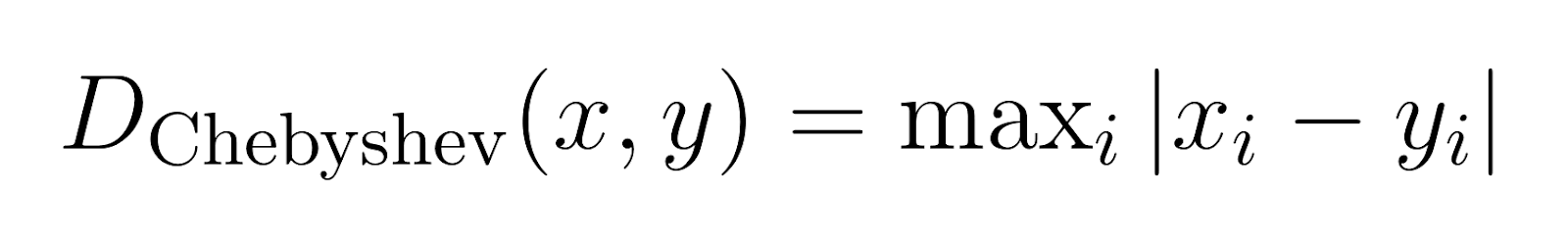
Distancia de Chebyshev, también conocida como distancia de tablero de ajedrez, mide la diferencia máxima en cualquier dimensión.
Ejemplo práctico
Para comprender realmente la funcionalidad y el poder de la distancia de Minkowski, trabajemos un ejemplo. Esta exploración nos ayudará a comprender cómo el parámetro p afecta la calculación e interpretación de distancias en espacios multi-dimensionales.
Consideremos dos puntos en un espacio 2D:
- Punto A: (2, 3)
- Punto B: (5, 7)
Calcularemos la distancia de Minkowski entre estos puntos para diferentes valores de p.

El parámetro p en la fórmula de distancia de Minkowski controla la sensibilidad de la métrica a las diferencias en los componentes individuales:
- Cuando p=1: Todas las diferencias contribuyen linealmente.
- Cuando p=2: Diferencias mayores tienen un mayor impacto debido a la cuadratura.
- Cuando p>2: Se pone énfasis aún mayor en las diferencias mayores.
- Cuando p→∞: Solo importa la diferencia máxima entre todas las dimensiones.
A medida que p aumenta, la distancia de Minkowski generalmente disminuye, acercándose a la distancia de Chebyshev. Esto se debe a que valores de p mayores dan más peso a la diferencia más grande y menos a las diferencias más pequeñas.
Para visualizar cómo los valores diferentes de p afectan la calculadora de distancia entre nuestros puntos A(2, 3) y B(5, 7), vamos a examinar el siguiente gráfico:
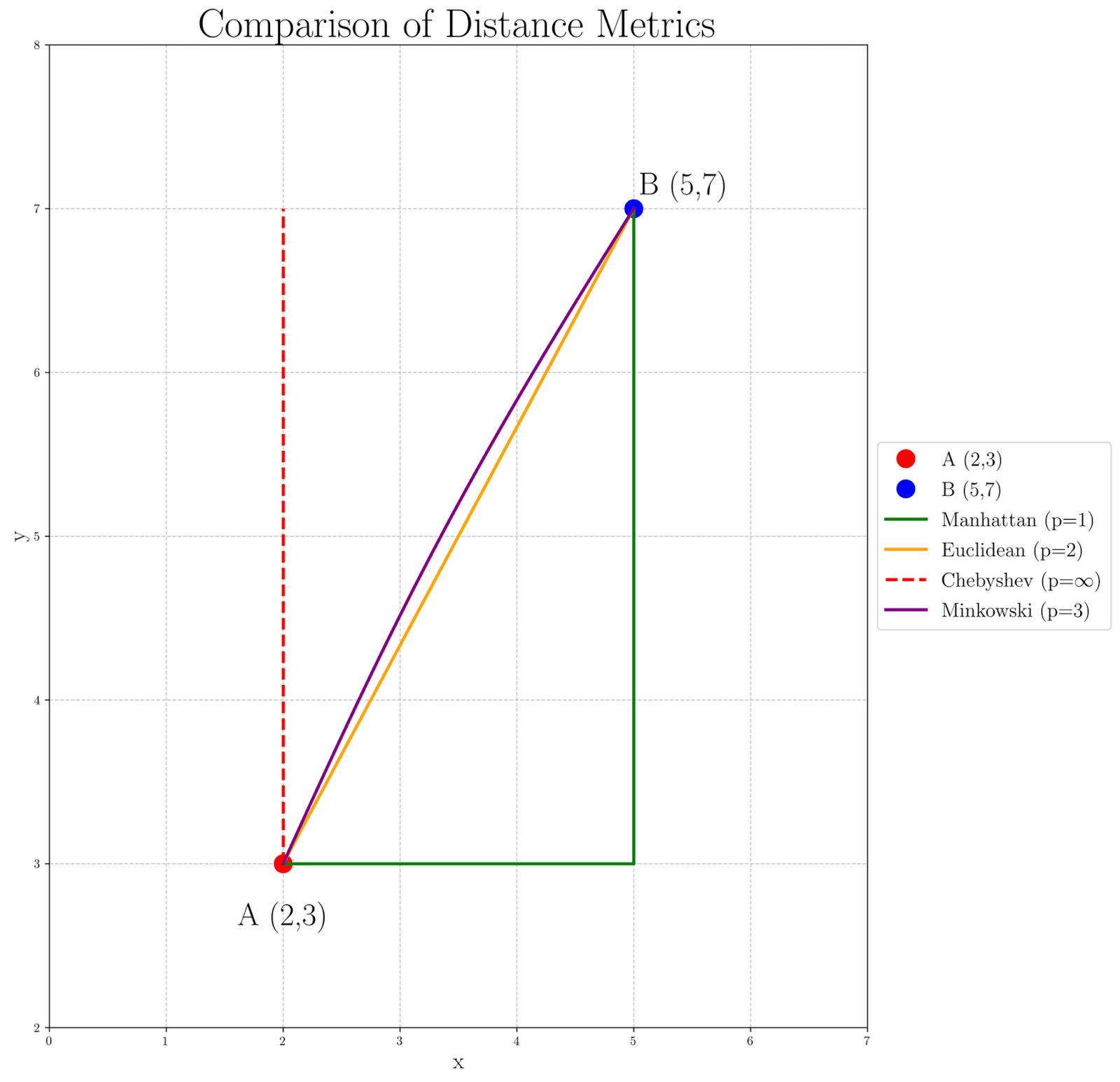
Observando el gráfico, podemos ver cómo la medida de distancia cambia a medida que p aumenta:
- La distancia de Manhattan (p=1), representada por la trayectoria verde, da la ruta más larga, ya que sigue estrictamente la cuadrícula.
- La distancia de Euclides (p=2), representada por la línea recta naranja, proporciona una ruta directa y recta.
- La distancia de Chebyshev (p=∞), representada por las líneas punteadas rojas, se enfoca exclusivamente en la diferencia de coordenadas más grande, creando una ruta que se mueve máximamente en una dimensión antes de abordar la otra.
- La distancia de Minkowski con p=3 en morado muestra una leve curva, apuntando a la transición entre las distancias de Euclides y Chebyshev.
Esta visualización nos ayuda a comprender por qué podrían elegirse diferentes valores de p para diferentes aplicaciones. Por ejemplo, la distancia de Manhattan podría ser más apropiada en problemas de navegación en la ciudad, mientras que la distancia de Euclides se utiliza a menudo en cálculos de espacio físico. Valores de p mayores, como en el caso de Minkowski p=3, pueden ser útiles en situaciones donde se deben enfatizar diferencias mayores, y la distancia de Chebyshev podría ser preferida cuando la diferencia máxima en cualquier dimensión es el factor más crítico.
Aplicaciones de la Distancia de Minkowski
La distancia de Minkowski, con su parámetro ajustable p, es una herramienta flexible utilizada en varios campos. Al cambiar p, podemos personalizar cómo medimos la distancia entre puntos, lo que la hace adecuada para diferentes tareas. A continuación se detallan cuatro aplicaciones donde la distancia de Minkowski juega un papel importante.
Machine learning y ciencia de datos
En machine learning y ciencia de datos, la distancia de Minkowski es fundamental para algoritmos que dependen de medir la similitud o la diferencia entre puntos de datos. Uno de los ejemplos más destacados es el algoritmo k-Nearest Neighbors (k-NN), que clasifica puntos de datos basándose en las categorías de sus vecinos más cercanos. Al utilizar la distancia de Minkowski, podemos ajustar el parámetro p para cambiar cómo calculamos la “proximidad” entre puntos.
Reconocimiento de patrones
El reconocimiento de patrones implica identificar patrones y regularidades en los datos, como la reconocición de escritura manual o la detección de características faciales. En este contexto, la distancia de Minkowski mide la diferencia entre vectores de características que representan patrones. Por ejemplo, en la reconocición de imágenes, cada imagen puede representarse por un vector de valores de pixel. Calcular la distancia de Minkowski entre estos vectores nos permite cuantificar cuán similares o diferentes son las imágenes.
Al ajustar p, podemos controlar la sensibilidad de la medida de distancia a las diferencias en características específicas. Un valor más bajo de p podría considerar diferencias generales entre todos los píxeles, mientras que un valor más alto de p podría enfatizar diferencias significativas en determinadas regiones de la imagen.
Detección de anomalías
La detección de anomalías se enfoca en identificar puntos de datos que se desvían significativamente del conjunto principal, lo que es crucial en áreas como detección de fraude, seguridad de redes y detección de fallos en sistemas. La distancia de Minkowski se utiliza para medir la distancia de un punto de datos de los demás en el conjunto de datos. Los puntos con grandes distancias son potenciales anomalías. Al elegir un p apropiado, los analistas pueden mejorar la sensibilidad de los sistemas de detección de anomalías a los tipos de desviaciones que son más relevantes para su contexto específico.
Geometría computacional y análisis espacial.
En geometría computacional y análisis espacial, la distancia de Minkowski se utiliza para calcular distancias entre puntos en el espacio, que es la base para muchos algoritmos geométricos. Por ejemplo, la detección de colisiones en estos dominios se basa en la distancia de Minkowski para determinar cuándo los objetos están lo suficientemente cerca para interactuar. Al ajustar p, los desarrolladores pueden crear diversas fronteras de colisión, que van desde angulares (menor p) hasta redondeadas (mayor p).
Más allá de la detección de colisiones, la distancia de Minkowski puede ser útil en el agrupamiento espacial y el análisis de formas. Variando el valor de p permite a los investigadores enfatizar diferentes aspectos de las relaciones espaciales, desde las distancias entre bloques de la ciudad hasta las similitudes en la forma general.
Propiedades matemáticas de la distancia de Minkowski
La distancia de Minkowski no solo es una herramienta versátil en aplicaciones prácticas sino también un concepto importante en la teoría matemática, particularmente en el estudio de los espacios métricos y las normas.
Propiedades del espacio métrico
La distancia de Minkowski satisface las cuatro propiedades esenciales requeridas para que una función sea considerada una métrica en un espacio métrico:
- No negatividad: La distancia de Minkowski entre cualesquiera dos puntos es siempre no negativa, d(x,y)≥0. Esto es evidente ya que es la raíz cuadrada de una suma de términos no negativos (valores absolutos elevados a la potencia p).
- Identidad de los Invisibles: La distancia de Minkowski entre dos puntos es cero si y solo si los dos puntos son idénticos. Matemáticamente, d(x,y) = 0 si y solo si x=y. Esto se sigue porque la diferencia absoluta entre componentes idénticos es cero.
- Simetría: La distancia de Minkowski es simétrica, lo que significa que d(x,y)=d(y,x). Esta propiedad se mantiene porque el orden de la resta en los términos de valor absoluto no afecta el resultado.
- Inecuación del Triángulo: La distancia de Minkowski satisface la inecuación del triángulo, que establece que para cualesquier tres puntos x, y y z, la distancia de x a z es como máximo la suma de la distancia de x a y y de y a z; formalmente, d(x,z)≤d(x,y)+d(y,z). Esta propiedad resulta menos intuitiva para demostrar directamente a partir de la fórmula y, por lo general, requiere matemáticas más avanzadas, pero básicamente asegura que tomar una ruta directa entre dos puntos es la ruta más corta.
Generalización de la norma
La distancia de Minkowski actúa como un marco general que unifica varias formas de medir distancias en espacios matemáticos a través del concepto de normas. En términos sencillos, una norma es una función que asigna una longitud o tamaño no negativo a un vector en un espacio vectorial, mediante lo cual se mide fundamentalmente “cuánto” es el vector. Al ajustar el parámetro p en la fórmula de distancia de Minkowski, podemos transicionar fluídamente entre diferentes normas, cada una proporcionando un método único para calcular la longitud de un vector.
Por ejemplo, cuando p=1, la distancia de Minkowski se convierte en la norma de Manhattan, que mide la distancia como la suma de las diferencias absolutas alongadas a lo largo de cada dimensión – imagina navegar una cuadrícula de calles de la ciudad. Con p=2, se convierte en la norma euclideana, calculando la distancia en línea recta (“como vuela el cuervo”) entre los puntos. A medida que p se acerca a la infinitud, se converge a la norma de Chebyshev, donde la distancia se determina por la diferencia única más grande entre dimensiones. Esta flexibilidad permite que la distancia de Minkowski se adapte a varios contextos matemáticos y prácticos, haciéndola una herramienta versátil para medir distancias en diferentes situaciones.
Calculando la Distancia de Minkowski en Python y R
Vamos a explorar implementaciones de cálculos de distancia de Minkowski utilizando Python y R. Examinaremos paquetes y bibliotecas disponibles fácilmente que pueden lograr esto.
Ejemplo de Python
Para calcular la distancia de Minkowski en Python, podemos usar la biblioteca SciPy, que ofrece implementaciones eficientes de varias métricas de distancia. Aquí tienes un ejemplo que calcula la distancia de Minkowski para diferentes valores de p:
import numpy as np from scipy.spatial import distance # Puntos de ejemplo point_a = [2, 3] point_b = [5, 7] # Diferentes valores de p p_values = [1, 2, 3, 10, np.inf] print("Minkowski distances using SciPy:") for p in p_values: if np.isinf(p): # Para p = infinito, use la distancia de Chebyshev dist = distance.chebyshev(point_a, point_b) print(f"p = ∞, Distance = {dist:.2f}") else: dist = distance.minkowski(point_a, point_b, p) print(f"p = {p}, Distance = {dist:.2f}")
Al ejecutar este código, los lectores pueden observar cómo la distancia cambia con diferentes valores de p, reforzando los conceptos discutidos anteriormente en el artículo.
Minkowski distances using SciPy: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
Este código demuestra:
- Cómo utilizar las funciones de distancia de SciPy para las distancias de Minkowski y Chebyshev.
- Cálculo de distancias para diferentes valores de p, incluyendo el infinito.
- La relación entre la distancia de Minkowski y otras métricas (Manhattan, Euclideana, Chebyshev).
Ejemplo en R
Para R, utilizaremos la función dist() de la biblioteca stats:
# Defina la función de distancia de Minkowski usando stats::dist minkowski_distance <- function(x, y, p) { points <- rbind(x, y) if (is.infinite(p)) { # Para p = Inf, use method = "maximum" para la distancia de Chebyshev distance <- stats::dist(points, method = "maximum") } else { distance <- stats::dist(points, method = "minkowski", p = p) } return(as.numeric(distance)) } # Ejemplo de uso point_a <- c(2, 3) point_b <- c(5, 7) # Valores de p diferentes p_values <- c(1, 2, 3, 10, Inf) cat("Minkowski distances between points A and B using stats::dist:\n") for (p in p_values) { distance <- minkowski_distance(point_a, point_b, p) if (is.infinite(p)) { cat(sprintf("p = ∞, Distance = %.2f\n", distance)) } else { cat(sprintf("p = %g, Distance = %.2f\n", p, distance)) } }
Este código demuestra:
-
Cómo crear una función
minkowski_distanceutilizando la funcióndist()destats. -
Tratamiento de diferentes valores de p, incluyendo infinito para la distancia de Chebyshev.
-
Cálculo de la distancia de Minkowski para diferentes valores de p.
-
Formateo de salida para mostrar distancias redondeadas a 2 decimales.
La salida de este código será:
Minkowski distances between points A and B using stats::dist: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
Esta implementación de R proporciona un contrapartida al ejemplo de Python, permitiendo a los lectores ver cómo se puede calcular la distancia de Minkowski en diferentes entornos de programación.
Conclusión
La distancia de Minkowski ofrece un enfoque flexible y adaptable para medir las distancias en espacios multidimensionales. Su capacidad para generalizar otras métricas de distancia comunes a través del parámetro p lo hace una herramienta valiosa en varios campos de ciencia de datos y aprendizaje automático. Ajustando p, los profesionales pueden personalizar sus cálculos de distancia según las características específicas de sus datos y los requisitos de sus proyectos, potencialmente mejorando los resultados en tareas que van desde el agrupamiento hasta la detección de anomalías.
Al aplicar la distancia de Minkowski en su propio trabajo, les animamos a que experimenten con diferentes valores de p y observe su impacto en sus resultados. Para aquellos que buscan profundizar su comprensión y habilidades, recomendamos explorar el curso Diseño de Flujos de Trabajo de Aprendizaje Automático en Python y considerar nuestro programa de carrera de Certificación de Científico de Datos. Estos recursos pueden ayudar a construir sobre su conocimiento de las métricas de distancia y aplicarlas efectivamente en diferentes situaciones.
Source:
https://www.datacamp.com/tutorial/minkowski-distance