













Los sistemas RAG combinan el poder de los mecanismos de recuperación y los modelos de lenguaje, permitiendo que generen respuestas relevantes y bien fundamentadas en el contexto. Sin embargo, evaluar el rendimiento y detectar posibles modos de fallo en los sistemas RAG puede ser muy complicado.
Por ello, surge el Triángulo RAG, un conjunto de tres métricas que abordan las tres etapas principales de la ejecución de un sistema RAG: Pertinencia del Contexto, Fundamentación y Pertinencia de la Respuesta. En esta entrada de blog, exploraré las complejidades del Triángulo RAG y guiaré al lector a través del proceso de configuración, ejecución y análisis de la evaluación de un sistema RAG.
Introducción al Triángulo RAG:
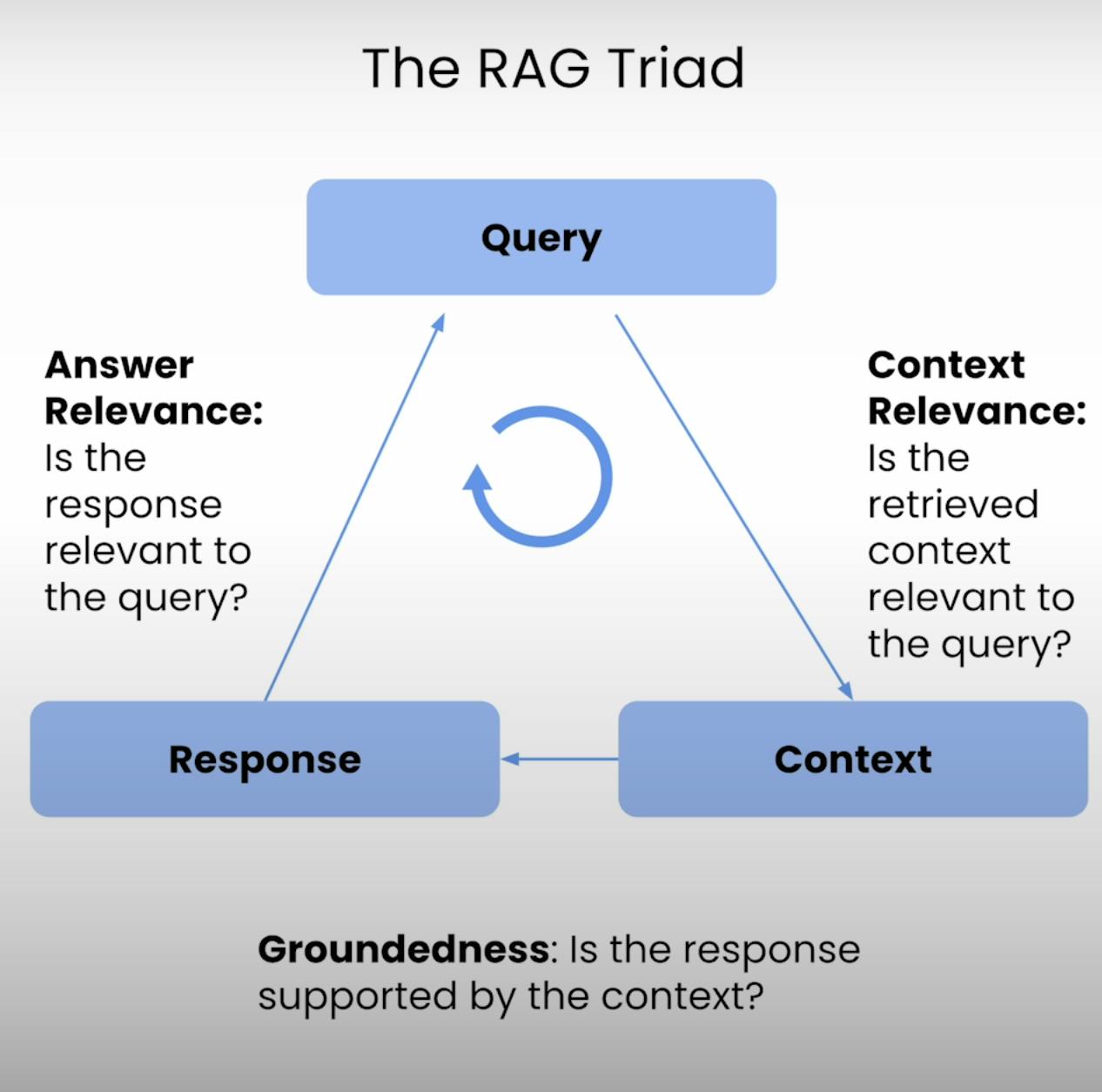
En el núcleo de todo sistema RAG se encuentra un delicado equilibrio entre recuperación y generación. El Triángulo RAG ofrece un marco integral para evaluar la calidad y los posibles modos de fallo de este equilibrio. Analicemos los tres componentes.
A. Context Relevance:
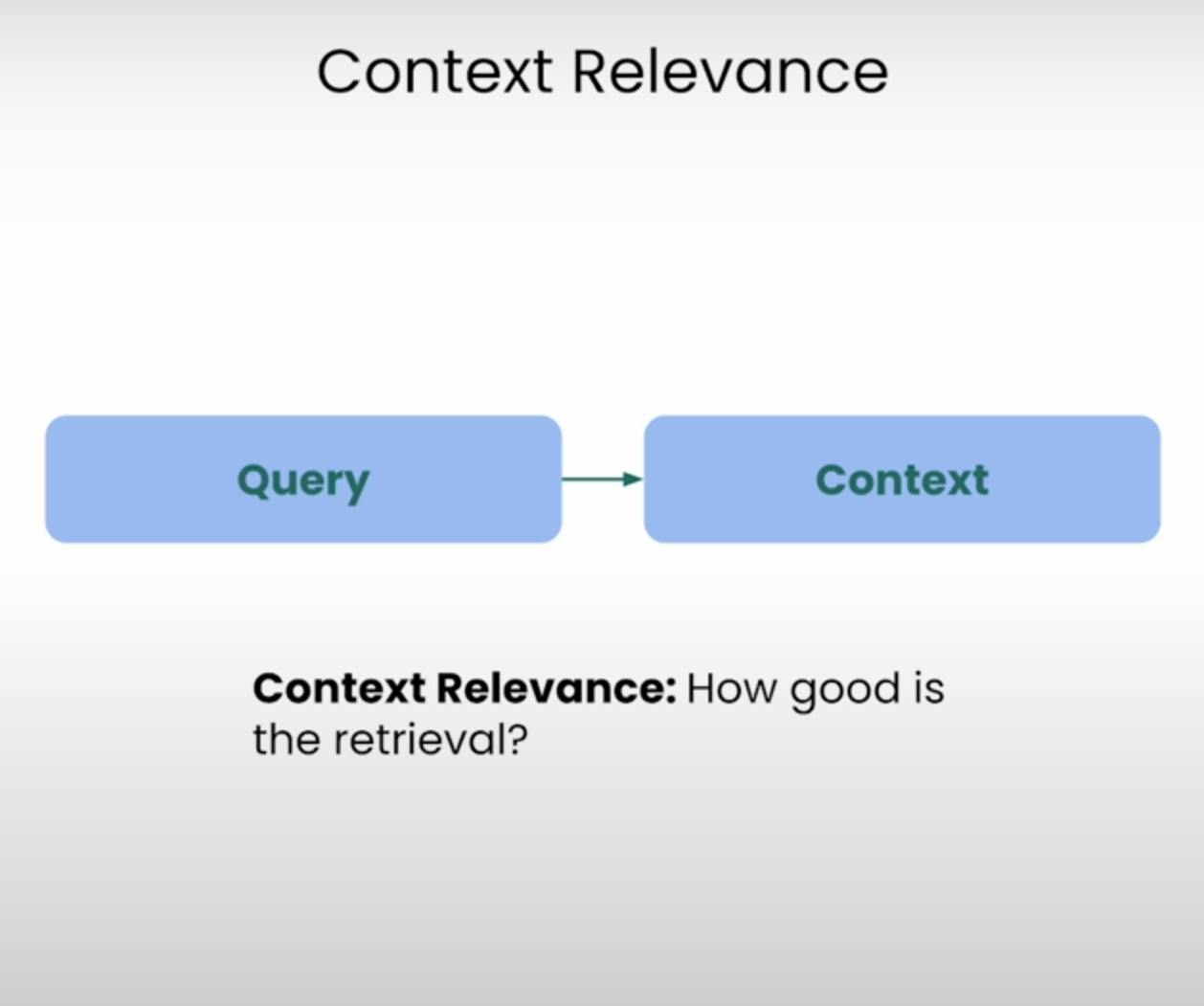
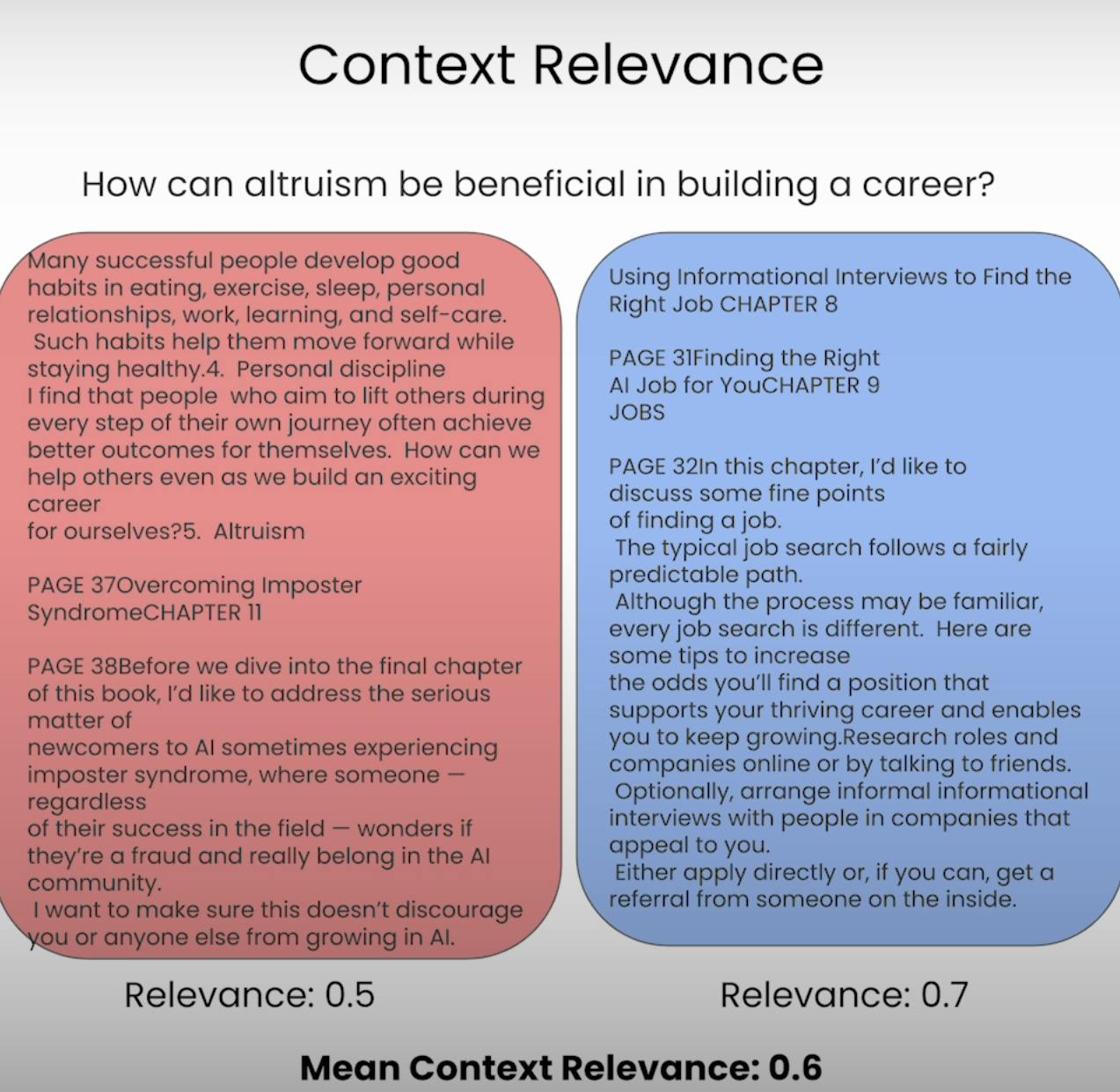
Imagina que se espera que respondas a una pregunta, pero la información que te han proporcionado es completamente irrelevante. Eso es precisamente lo que un sistema RAG busca evitar. La Pertinencia del Contexto evalúa la calidad del proceso de recuperación al analizar cuán relevante es cada fragmento de contexto recuperado respecto a la consulta original. Al puntuar la relevancia del contexto recuperado, podemos identificar posibles problemas en el mecanismo de recuperación y realizar los ajustes necesarios.

B. Groundedness:
¿Alguna vez has tenido una conversación en la que alguien parecía estar inventando hechos o proporcionando información sin una base sólida? Eso es equivalente a un sistema RAG que carece de fundamentación. La fundamentación evalúa si la respuesta final generada por el sistema está bien fundamentada en el contexto recuperado. Si la respuesta contiene declaraciones o afirmaciones que no están respaldadas por la información recuperada, el sistema podría estar alucinando o depender demasiado de sus datos de preentrenamiento, lo que podría llevar a posibles inexactitudes o sesgos.
C. Answer Relevance:
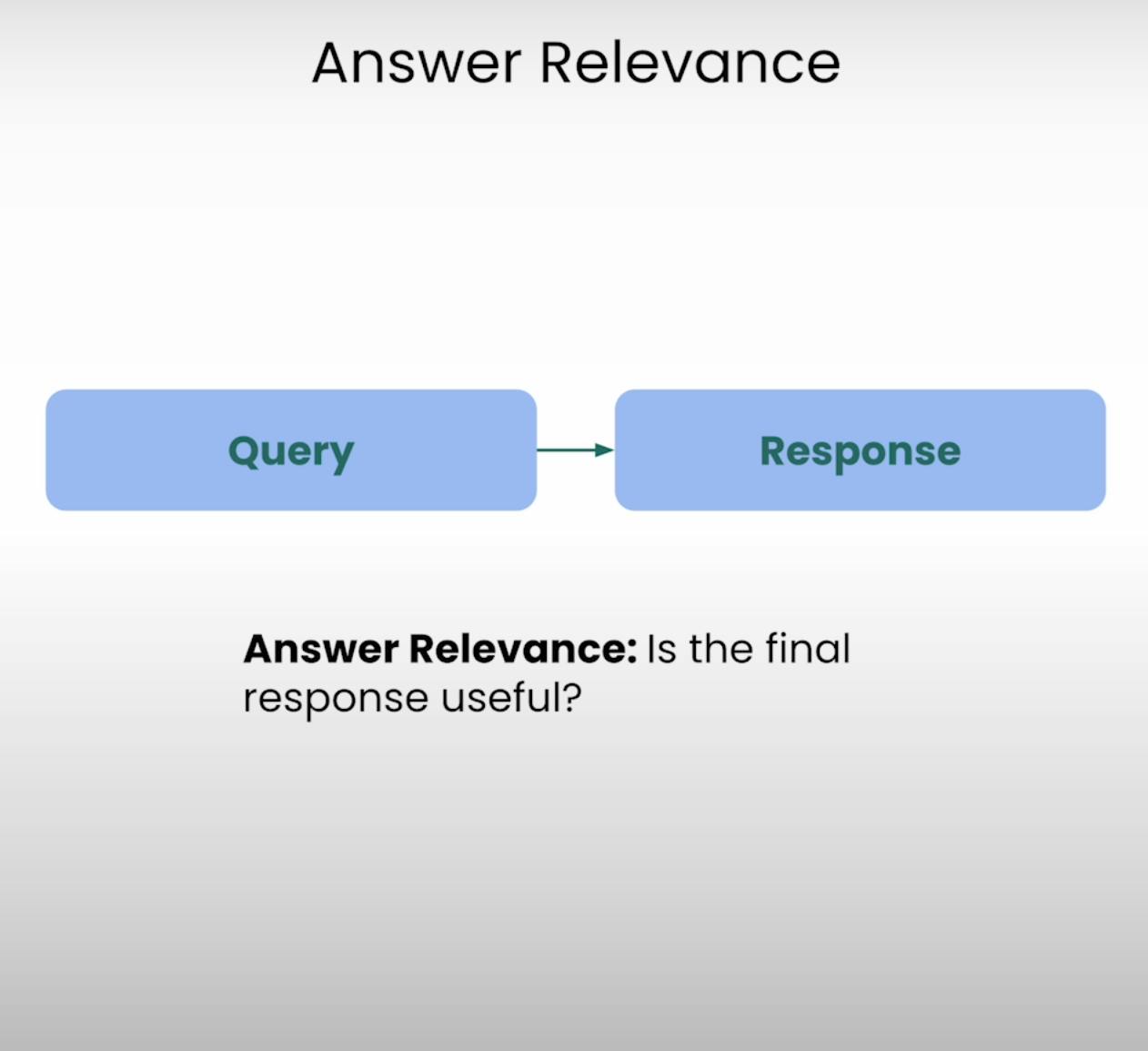
Imagina preguntar por direcciones a la cafetería más cercana y recibir una detallada receta para hornear un pastel. Esa es la clase de situación que Answer Relevance busca prevenir. Este componente del Triángulo RAG evalúa si la respuesta final generada por el sistema es realmente relevante al query original. Al evaluar la relevancia de la respuesta, podemos identificar instancias en las que el sistema puede haber malinterpretado la pregunta o desviado del tema previsto.

Configuración de la Evaluación del Triángulo RAG
Antes de adentrarnos en el proceso de evaluación, necesitamos establecer las bases. Vamos a recorrer los pasos necesarios para configurar la evaluación del Triángulo RAG.
A. Importing Libraries and Establishing API Keys:
En primer lugar, necesitamos importar las bibliotecas y módulos requeridos, incluyendo la clave API de OpenAI y el proveedor de LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
A continuación, cargaremos e indexaremos el corpus de documentos con el que trabajará nuestro sistema RAG. En nuestro caso, estaremos utilizando un documento PDF sobre “Cómo Construir una Carrera en IA” de Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

En el núcleo de la evaluación del Triángulo RAG se encuentran las funciones de feedback – funciones especializadas que evalúan cada componente del triángulo. Definamos estas funciones utilizando la biblioteca TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Ejecutando la Aplicación y Evaluación RAG
Con la configuración completa, es momento de poner en marcha nuestro sistema RAG y el marco de evaluación. Vamos a recorrer los pasos involucrados en la ejecución de la aplicación y la grabación de los resultados de la evaluación.
A. Preparing the Evaluation Questions:
Primero, cargaremos un conjunto de preguntas de evaluación que queremos que nuestro sistema RAG responda. Estas preguntas servirán como base para nuestro proceso de evaluación.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Luego, configuraremos el registrador de TruLens, que nos ayudará a registrar los prompts, respuestas y resultados de la evaluación en una base de datos local.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
A medida que la aplicación RAG se ejecuta en cada pregunta de evaluación, el registrador de TruLens capturará diligentemente los prompts, respuestas, resultados intermedios y puntuaciones de evaluación, almacenándolos en una base de datos local para su análisis posterior.
Analizando los Resultados de la Evaluación
Con los datos de evaluación a nuestro alcance, es hora de profundizar en el análisis y obtener las ideas clave. Veamos las diversas formas en que podemos analizar los resultados e identificar áreas potenciales de mejora.
A. Examining Individual Record-Level Results:
A veces, el detalle es lo que marca la diferencia. Examinando los resultados a nivel de registro individual, podemos obtener una comprensión más profunda de las fortalezas y debilidades de nuestro sistema RAG.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Este fragmento de código nos da acceso a los prompts, respuestas y puntuaciones de evaluación para cada registro individual, lo que nos permite identificar instancias específicas en las que el sistema pudo haber tenido dificultades o sobresalido.
B. Viewing Aggregate Performance Metrics:
Volvamos a tomar perspectiva y observemos el panorama general. La biblioteca TrueLens nos proporciona una clasificación que aglutina las métricas de rendimiento a través de todos los registros, ofreciéndonos una visión de alto nivel del rendimiento general de nuestro sistema RAG.
tru.get_leaderboard(app_ids=[])
Esta clasificación muestra las puntuaciones promedio para cada componente del Triángulo RAG, junto con métricas como latencia y costo. Al analizar estas métricas agregadas, podemos identificar tendencias y patrones que pueden no ser evidentes a nivel de registro.
C. Exploring the TrueLens Streamlit Dashboard:
Además de la CLI, TrueLens también ofrece un panel Streamlit que proporciona una interfaz gráfica para explorar y analizar los resultados de la evaluación. Con unos sencillos comandos, podemos lanzar el panel.
tru.run_dashboard()
Una vez que el panel está en funcionamiento, vemos una visión completa del rendimiento de nuestro sistema RAG. A simple vista, podemos ver las métricas agregadas para cada componente del Triángulo RAG, así como información sobre latencia y costo.
Al seleccionar nuestra aplicación desde el menú desplegable, podemos acceder a una vista detallada a nivel de registro de los resultados de la evaluación. Cada registro se muestra ordenadamente, con el prompt de entrada del usuario, la respuesta del sistema RAG y las puntuaciones correspondientes para Relevancia de la Respuesta, Relevancia del Contexto y Fundamentación.
Al hacer clic en un registro individual se revelan más insights. Podemos explorar la cadena de razonamiento detrás de cada puntuación de evaluación, explicando el proceso de pensamiento del modelo de lenguaje que realiza la evaluación. Este nivel de transparencia es útil para identificar posibles modos de fallo y áreas de mejora.
Supongamos que encontramos un registro donde el puntaje de Groundedness es bajo. Al ver los detalles, podríamos descubrir que la respuesta del sistema RAG contiene declaraciones que no están bien fundamentadas en el contexto recuperado. El dashboard nos mostrará exactamente qué declaraciones carecen de evidencia de soporte, permitiéndonos identificar la causa raíz del problema.
El dashboard de TrueLens Streamlit es más que solo una herramienta de visualización. Al utilizar sus capacidades interactivas y las ideas basadas en datos, podemos tomar decisiones informadas y realizar acciones dirigidas para mejorar el rendimiento de nuestras aplicaciones.
Técnicas Avanzadas de RAG e Mejoras Iterativas
A. Introducing the Sentence Window RAG Technique:
Una técnica avanzada es la Ventana de Oración RAG, que aborda un modo de falla común en los sistemas RAG: tamaño de contexto limitado. Al aumentar el tamaño de la ventana de contexto, el RAG de Ventana de Oración busca proporcionar al modelo de lenguaje información más relevante y completa, posiblemente mejorando la Relevancia y Groundedness del sistema.
B. Re-evaluating with the RAG Triad:
Después de implementar la técnica de Ventana de Oración RAG, podemos ponerla a prueba reevaluándola utilizando el mismo marco RAG Triad. Esta vez, nos centraremos en los puntajes de Relevancia y Groundedness del Contexto, buscando mejoras en estas áreas como resultado del aumento del tamaño del contexto.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Si bien la técnica de Ventana de Oración RAG puede potencialmente mejorar el rendimiento, el tamaño óptimo de la ventana puede variar dependiendo del caso de uso específico y del conjunto de datos. Una ventana demasiado pequeña puede no proporcionar suficiente contexto relevante, mientras que una ventana demasiado grande podría introducir información irrelevante, afectando la Groundedness y la Relevancia de la Respuesta del sistema.
Al experimentar con diferentes tamaños de ventana y reevaluar utilizando el Triángulo RAG, podemos encontrar el punto óptimo que equilibra la relevancia del contexto con la fundamentación y la relevancia de la respuesta, lo que finalmente conduce a un sistema RAG más robusto y confiable.
Conclusión:
El Triángulo RAG, que comprende Relevancia del Contexto, Fundamentación y Relevancia de la Respuesta, se ha demostrado como un marco útil para evaluar el rendimiento e identificar posibles modos de fallo de los sistemas de Generación Ampliada por Búsqueda.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems