













¿Quiere la dirección de su empresa conocer todos los detalles sobre las finanzas y productividad, pero no está dispuesto a gastar ni un centavo en herramientas de gestión de IT de alta calidad? No termine recurriendo a diferentes herramientas para inventario, facturación y sistemas de tickets. Solo necesita un sistema central. ¿Por qué no considerar Power BI Python?
Power BI puede convertir tareas tediosas y que consumen mucho tiempo en un proceso automatizado. Y en este tutorial, aprenderá a segmentar y combinar sus datos de formas que no podría imaginar.
¡Vamos, ahorre el estrés de revisar informes complejos visualmente!
Prerrequisitos
Este tutorial será una demostración práctica. Si desea seguirlo, asegúrese de tener lo siguiente:
- Suscripción a Power BI – La prueba gratuita será suficiente.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop instalado en su servidor Windows – Este tutorial utiliza Power BI Desktop v2.105.664.0.
- Servidor MySQL instalado – Este tutorial utiliza MySQL Server v8.0.29.
- Un gateway de datos local instalado en dispositivos externos que planean utilizar una versión de escritorio.
- Visual Studio Code (VS Code) – Este tutorial utiliza VS Code v17.2.
- Python v3.6 o posterior instalado – Este tutorial utiliza Python v3.10.5.
- DBeaver instalado – Este tutorial utiliza DBeaver v22.0.2.
Creación de una base de datos MySQL
Power BI puede visualizar datos de manera excelente, pero necesitas obtenerlos y almacenarlos antes de llegar a la visualización de los datos. Una de las mejores formas de almacenar datos es en una base de datos. MySQL es una herramienta de base de datos gratuita y potente.
1. Abre el símbolo del sistema como administrador, ejecuta el comando mysql que se muestra a continuación e introduce el nombre de usuario root (-u) y la contraseña (-p) cuando se te solicite.
Por defecto, solo el usuario root tiene permiso para realizar cambios en la base de datos.
2. A continuación, ejecuta la consulta siguiente para crear un nuevo usuario de base de datos (CREATE USER) con una contraseña (IDENTIFIED BY). Puedes nombrar al usuario de manera diferente, pero la elección de este tutorial es ata_levi.

3. Después de crear un usuario, ejecuta la consulta siguiente para CONCEDER permisos al nuevo usuario (ALL PRIVILEGES), como la creación de una base de datos en el servidor.

4. Ahora, ejecuta el comando \q a continuación para cerrar sesión en MySQL.

5. Ejecuta el comando mysql a continuación para iniciar sesión como el usuario de base de datos recién creado (ata_levi).
6. Por último, ejecuta la siguiente consulta para CREAR una nueva BASE DE DATOS llamada ata_database. Pero, por supuesto, puedes nombrar la base de datos de manera diferente.

Gestión de bases de datos MySQL con DBeaver
Al gestionar bases de datos, normalmente necesitas tener conocimientos de SQL. Pero con DBeaver, tienes una interfaz gráfica para gestionar tus bases de datos en unos pocos clics, y DBeaver se encargará de las instrucciones SQL por ti.
1. Abre DBeaver desde tu escritorio o el menú de inicio.
2. Cuando DBeaver se abre, haz clic en el menú desplegable Nueva Conexión a Base de Datos y selecciona MySQL para iniciar la conexión a tu servidor MySQL.
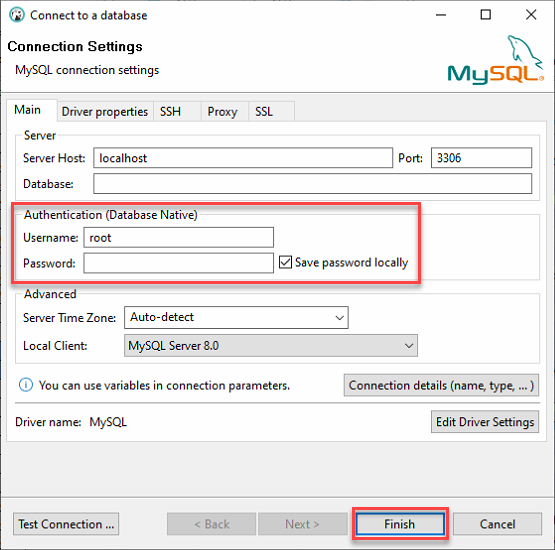
3. Inicia sesión en tu servidor MySQL local con lo siguiente:
- Mantén el Host del Servidor como localhost y el Puerto en 3306 ya que te estás conectando a un servidor local.
- Proporciona las credenciales del usuario ata_levi (Nombre de usuario y Contraseña) del paso dos de la sección “Creación de una Base de Datos MySQL”, y haz clic en Finalizar para iniciar sesión en MySQL.
4. Ahora, amplía tu base de datos (ata_database) en el Navegador de Base de Datos (panel izquierdo) → haz clic derecho en Tablas y selecciona Crear Nueva Tabla para iniciar la creación de una nueva tabla.
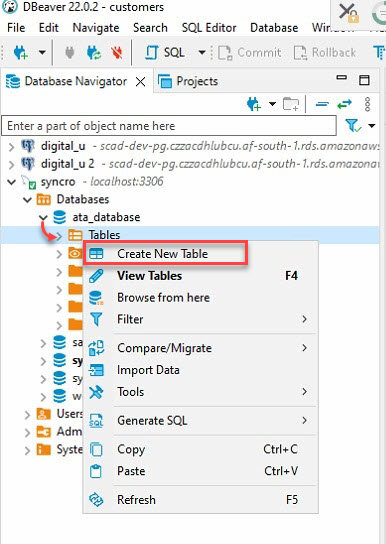
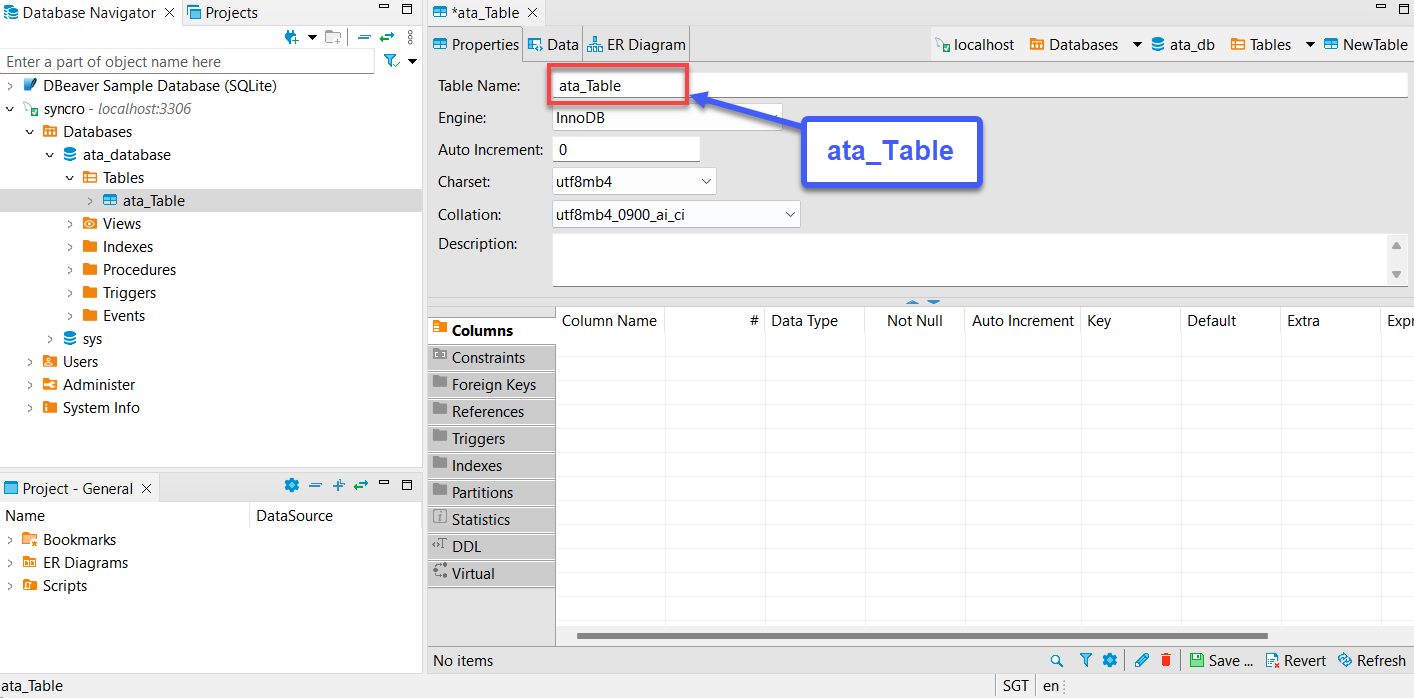
5. Nombre tu nueva tabla, aunque la elección de este tutorial es ata_Table, como se muestra a continuación.
Asegúrate de que el nombre de la tabla coincida con el nombre de tabla que especificarás en el método to_sql (“Nombre de la tabla”) en el paso siete de la sección “Obtención y Consumo de Datos de la API”.
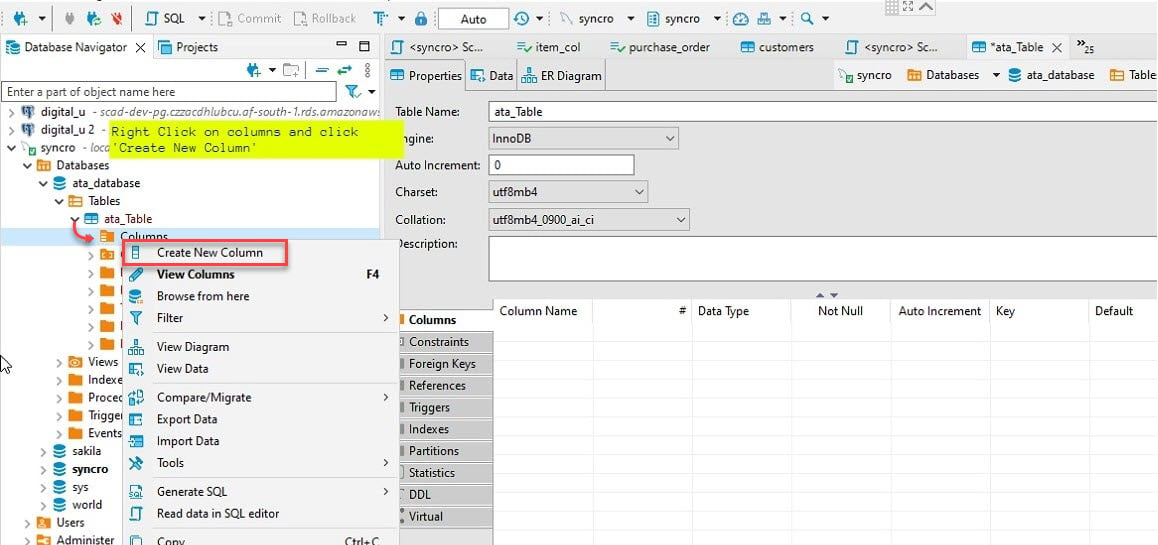
6. A continuación, amplía la nueva tabla (ata_table) → haz clic derecho en Columnas → Crear Nueva Columna para crear una nueva columna.
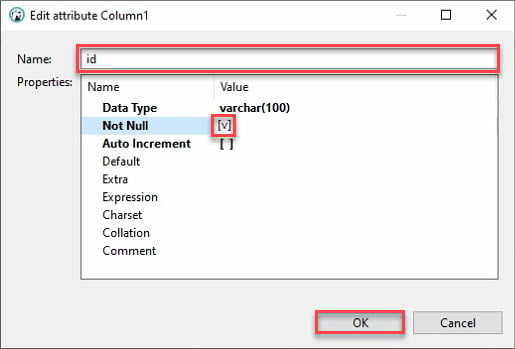
7. Proporciona un Nombre de columna, como se muestra a continuación, marca la casilla de No Nulo y haz clic en Aceptar para crear la nueva columna.
Idealmente, querrás agregar una columna llamada “id”. ¿Por qué? La mayoría de las APIs tendrán un id, y el marco de datos de pandas de Python llenará automáticamente las otras columnas.
8. Haz clic en Guardar (abajo a la derecha) o presiona Ctrl+S para guardar los cambios una vez que hayas verificado tu columna recién creada (id), como se muestra a continuación.
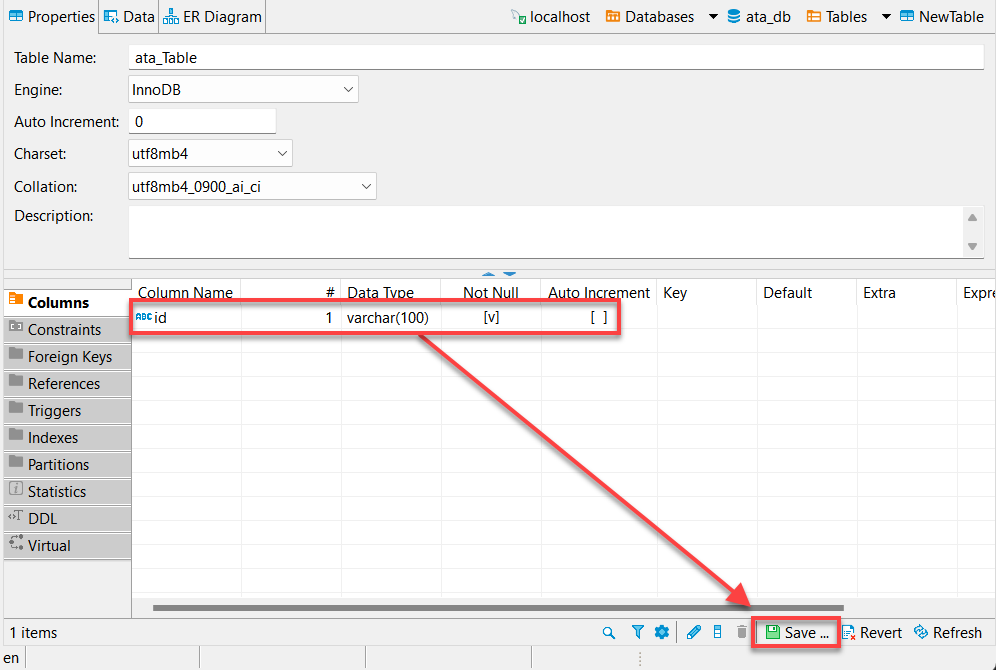
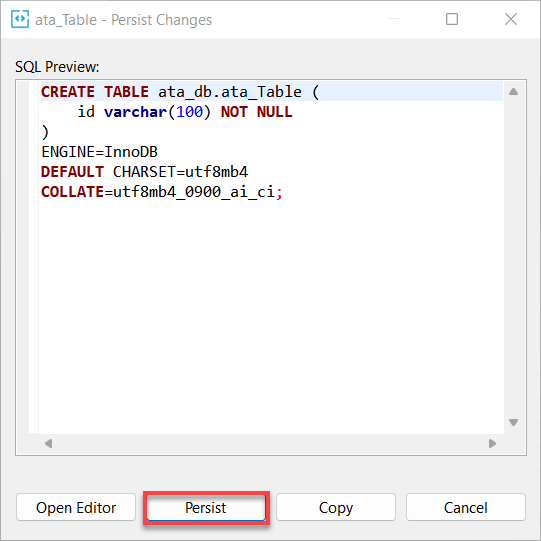
9. Por último, haz clic en Persistir para guardar los cambios que realizaste en la base de datos.
Obtención y Consumo de Datos de la API
Ahora que has creado la base de datos para almacenar datos, necesitas obtener los datos de tu proveedor de API respectivo y enviarlos a tu base de datos utilizando Python. Obtendrás tus datos para visualizarlos en Power BI.
Para conectarte a tu proveedor de API, necesitarás tres piezas clave de información: el método de autorización, la URL base de la API y el punto final de la API. Si tienes dudas sobre cómo obtener esta información, visita el sitio de documentación de tu proveedor de API.
A continuación se muestra una página de documentación de Syncro.
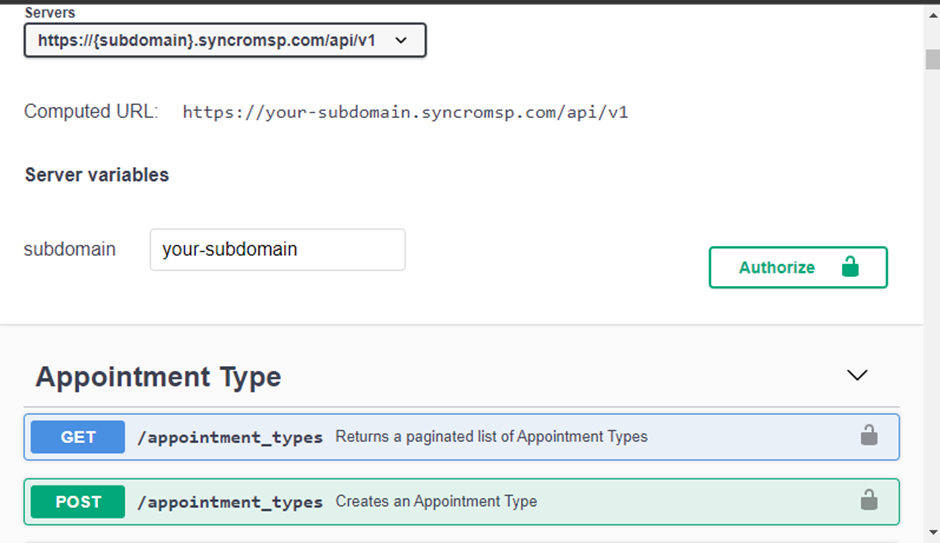
1. Abre VS Code, crea un archivo Python y nómbralo según los datos de la API esperados del archivo. Este archivo será responsable de obtener y enviar los datos de la API a tu base de datos (conexión de base de datos).
Existen varias bibliotecas de Python disponibles para ayudar con la conexión de la base de datos, pero en este tutorial utilizarás SQLAlchemy.
Ejecuta el siguiente comando pip en la terminal de VS Code para instalar SQLAlchemy en tu entorno.

2. A continuación, crea un archivo llamado connection.py, completa el código a continuación, reemplaza los valores correspondientes y guarda el archivo.
Una vez que comiences a escribir scripts para comunicarte con tu base de datos, es necesario establecer una conexión con la base de datos antes de que esta acepte cualquier comando.
Pero en lugar de volver a escribir la cadena de conexión de la base de datos para cada script que escribas, el código a continuación se dedica a realizar esta conexión para que pueda ser llamada/referenciada por otros scripts.
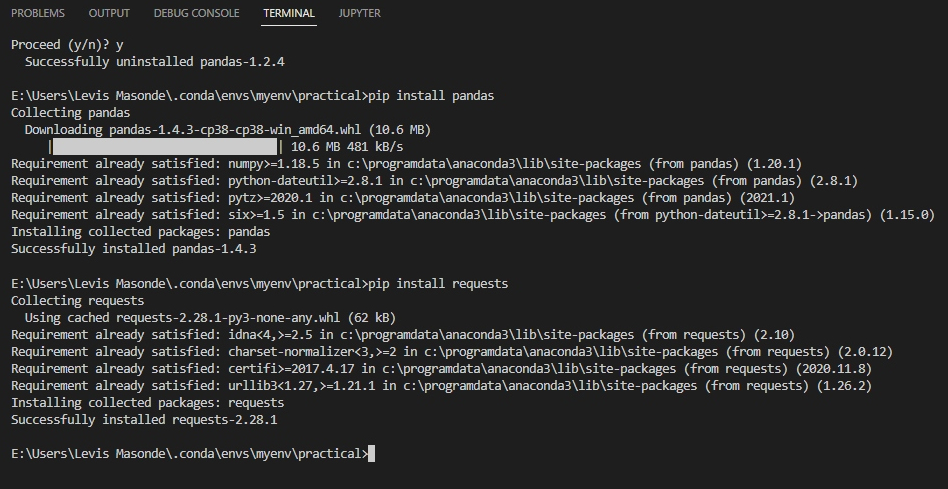
3. Abra la terminal de Visual Studio (Ctrl+Shift+`), y ejecute los siguientes comandos para instalar pandas y requests.
4. Cree otro archivo Python llamado invoices.py (o nombrelo de manera diferente), y agregue el siguiente código al archivo.
Añadirás fragmentos de código al archivo invoices.py en cada paso subsiguiente, pero puedes ver el código completo en ATA’s GitHub.
El script invoices.py se ejecutará desde el script principal descrito en la siguiente sección, que extrae los datos de su primer API.
El código a continuación realiza lo siguiente:
- Consumir datos de su API y escribirlos en su base de datos.
- Reemplazar el método de autorización, la clave, la URL base y los puntos finales de la API con las credenciales de su proveedor de API.
5. Agregue el fragmento de código a continuación al archivo invoices.py para definir los encabezados, por ejemplo:
- El tipo de formato de datos que espera recibir de su API.
- La URL base y el punto final deben acompañar al método de autorización y a la clave respectiva.
Asegúrese de cambiar los valores a continuación con los suyos.
6. A continuación, agrega la siguiente función asíncrona al archivo invoices.py.
El código a continuación utiliza AsyncIO para gestionar varios scripts desde un script principal, como se detalla en la sección siguiente. Cuando tu proyecto crece y abarca múltiples puntos finales de API, es buena práctica tener scripts de consumo de API en sus propios archivos.
7. Finalmente, agrega el código siguiente al archivo invoices.py, donde una función get_pages maneja la paginación de tu API.
Esta función devuelve el número total de páginas en tu API y ayuda a la función de rango a iterar a través de todas las páginas.
Contacta a los desarrolladores de tu API sobre el método de paginación utilizado por tu proveedor de API.
Si prefiere agregar más puntos finales de API a sus datos:
- Repita los pasos cuatro a seis de la sección “Gestión de bases de datos MySQL con DBeaver”.
- Repita todos los pasos bajo la sección “Obtención y Consumo de Datos de API”.
- Cambie el punto final de la API a otro que desee consumir.
Sincronización de Puntos Finales de API
Ahora tiene una conexión a la base de datos y a la API, y está listo para comenzar el consumo de la API ejecutando el código en el archivo invoices.py. Pero al hacerlo, se limitaría a consumir un punto final de API simultáneamente.
¿Cómo ir más allá del límite? Crearás otro archivo de Python como archivo central que llame a las funciones de la API desde varios archivos de Python y ejecute las funciones de forma asíncrona utilizando AsyncIO. De esta manera, mantendrás tu programación limpia y te permitirá agrupar varias funciones juntas.
1. Crea un nuevo archivo de Python llamado central.py y agrega el siguiente código.
Similar al archivo invoices.py, agregarás fragmentos de código al archivo central.py en cada paso, pero puedes ver el código completo en ATA’s GitHub.
El siguiente código importa módulos esenciales y scripts de otros archivos utilizando la sintaxis from <nombre de archivo> import <nombre de función>.
2. A continuación, agrega el siguiente código para controlar los scripts de invoices.py en el archivo central.py.
Necesitas hacer referencia/llamar a la función call_invoices de invoices.py a una tarea AsyncIO (invoice_task) en central.py.
3. Después de crear la tarea AsyncIO, espera a que la tarea obtenga y ejecute la función call_invoices de invoice.py una vez que la función chain (en el paso dos) comience a ejecutarse.
4. Crea un AsyncIOScheduler para programar un trabajo en el script. El trabajo agregado en este código ejecuta la función chain en intervalos de un segundo.
Este trabajo es importante para asegurar que tu programa siga ejecutando tus scripts y mantenga tus datos actualizados.
5. Por último, ejecuta el script central.py en VS Code, como se muestra a continuación.
Después de ejecutar el script, verás la salida en la terminal como la siguiente.
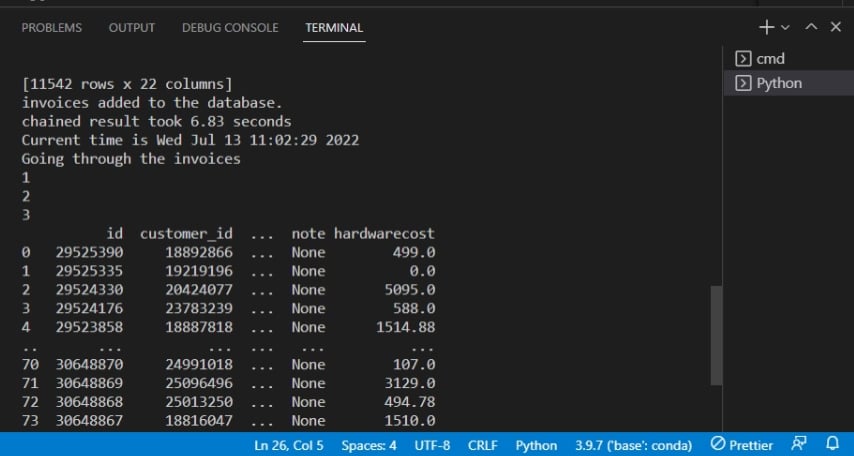
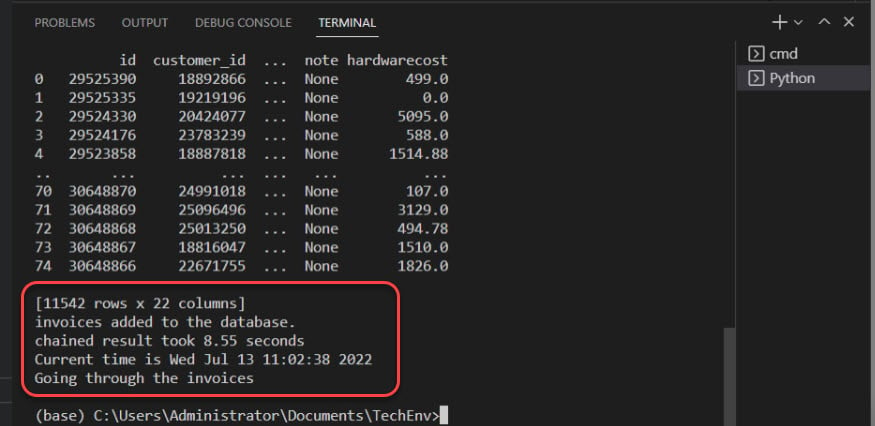
A continuación, la salida confirma que las facturas se han añadido a la base de datos.
Desarrollando Visualizaciones de Power BI
Después de codificar un programa que se conecta y consume datos de la API y envía estos datos a una base de datos, casi estás listo para cosechar tus datos. Pero primero, enviarás los datos de la base de datos a Power BI para su visualización, el objetivo final.
Un montón de datos no sirve de nada si no puedes visualizarlos y establecer conexiones profundas. Afortunadamente, las visualizaciones de Power BI son como los gráficos que pueden hacer que las ecuaciones matemáticas complicadas parezcan simples y predecibles.
1. Abre Power BI desde tu escritorio o menú de inicio.
2. Haz clic en el icono de origen de datos sobre el menú desplegable Obtener datos en la ventana principal de Power BI. Aparecerá una ventana emergente donde podrás seleccionar la fuente de datos a utilizar (paso tres).
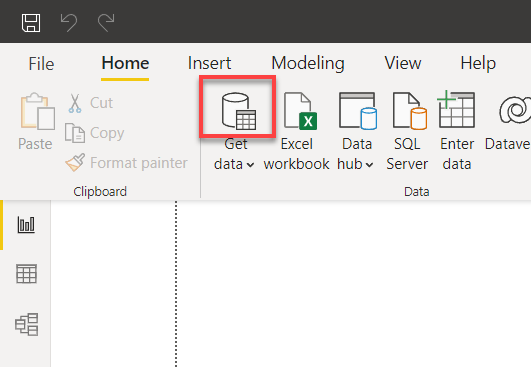
3. Busca mysql, selecciona la base de datos MySQL y haz clic en Conectar para iniciar la conexión a tu base de datos MySQL.
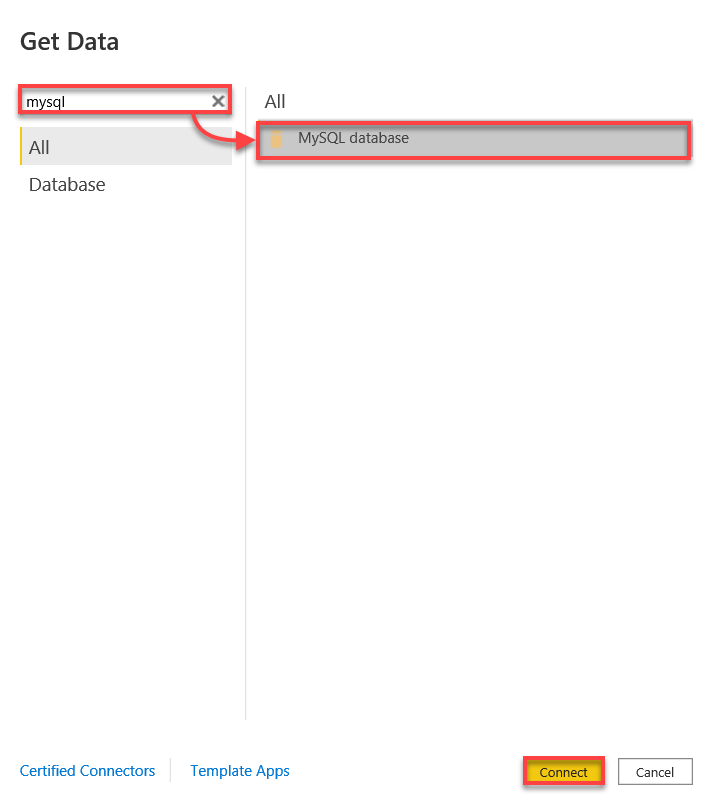
4. Ahora, conecta con tu base de datos MySQL con lo siguiente:
- Ingresa localhost:3306 ya que te estás conectando a tu servidor MySQL local en el puerto 3306.
- Proporciona el nombre de tu base de datos, en este caso, ata_db.
- Haz clic en OK para conectar con tu base de datos MySQL.

5. Ahora, haz clic en Transformar datos (esquina inferior derecha) para ver la descripción general de los datos en el editor de consultas de Power BI (paso cinco).

6. Después de previsualizar la fuente de datos, haz clic en Cerrar y aplicar para volver a la aplicación principal y confirmar si se aplicaron cambios.
El editor de consultas muestra tablas de tu fuente de datos en la parte izquierda. Al mismo tiempo, puedes verificar el formato de los datos antes de proceder a la aplicación principal.
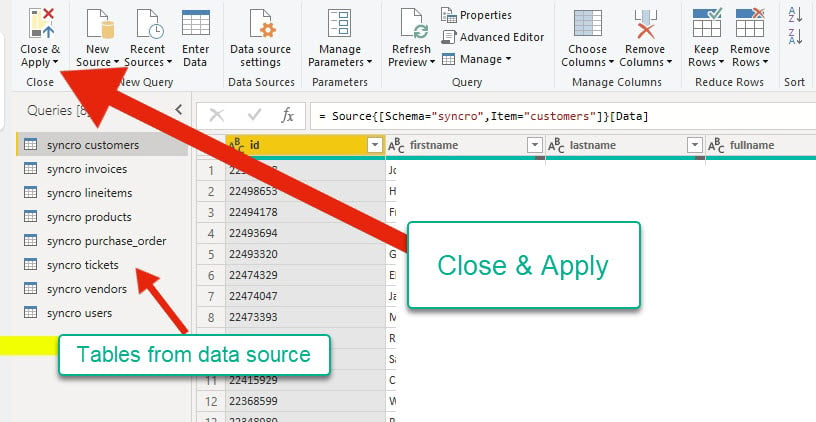
7. Haz clic en la pestaña de herramientas de tabla, selecciona cualquier tabla en el panel de campos y haz clic en Administrar relaciones para abrir el asistente de relaciones.
Antes de crear visuales, debes asegurarte de que tus tablas estén relacionadas, así que especifica cualquier relación entre tus tablas de manera explícita. ¿Por qué? Power BI aún no detecta automáticamente correlaciones complejas entre tablas.

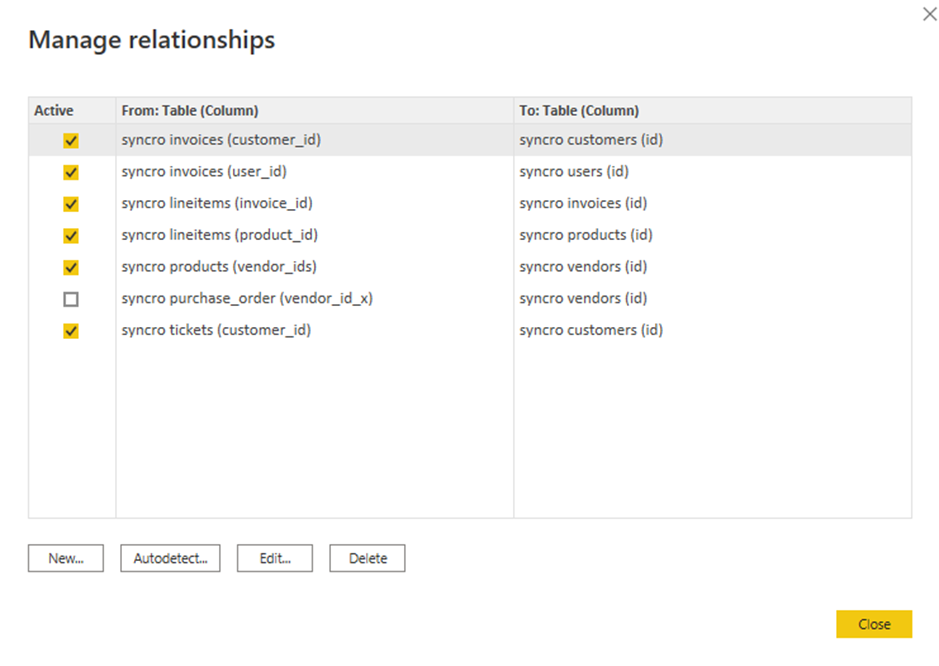
8. Marca las casillas de las relaciones existentes para editar y haz clic en Editar. Aparecerá una ventana emergente, donde podrás editar las relaciones seleccionadas (paso nueve).
Pero si prefieres agregar una nueva relación, haz clic en Nuevo en su lugar.
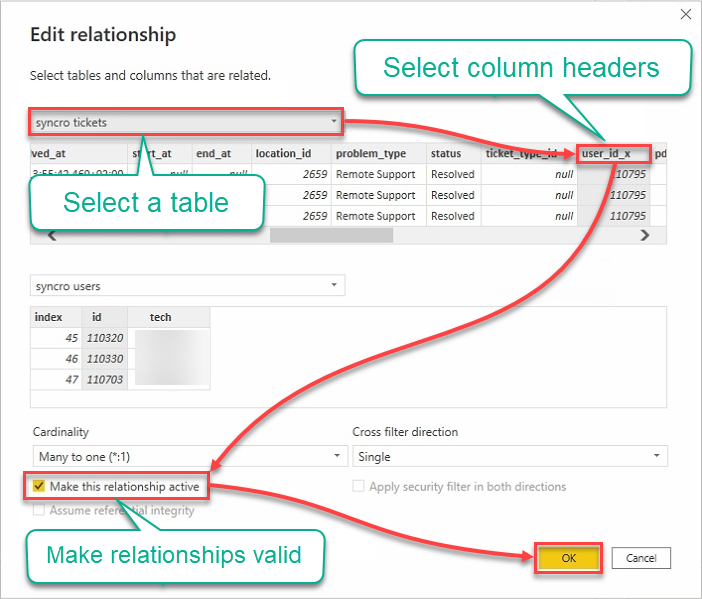
9. Edita las relaciones con lo siguiente:
- Haz clic en el campo desplegable de tablas y selecciona una tabla.
- Haz clic en los encabezados para seleccionar las columnas que se usarán.
- Marca la casilla Hacer esta relación activa para asegurar que las relaciones sean válidas.
- Haz clic en Aceptar para establecer la relación y cerrar la ventana de Edición de relación.
10. Ahora, haz clic en el tipo visual de Tabla bajo el panel Visualizaciones (más a la derecha) para crear tu primera visualización, y aparecerá una visualización de tabla vacía (paso 11).
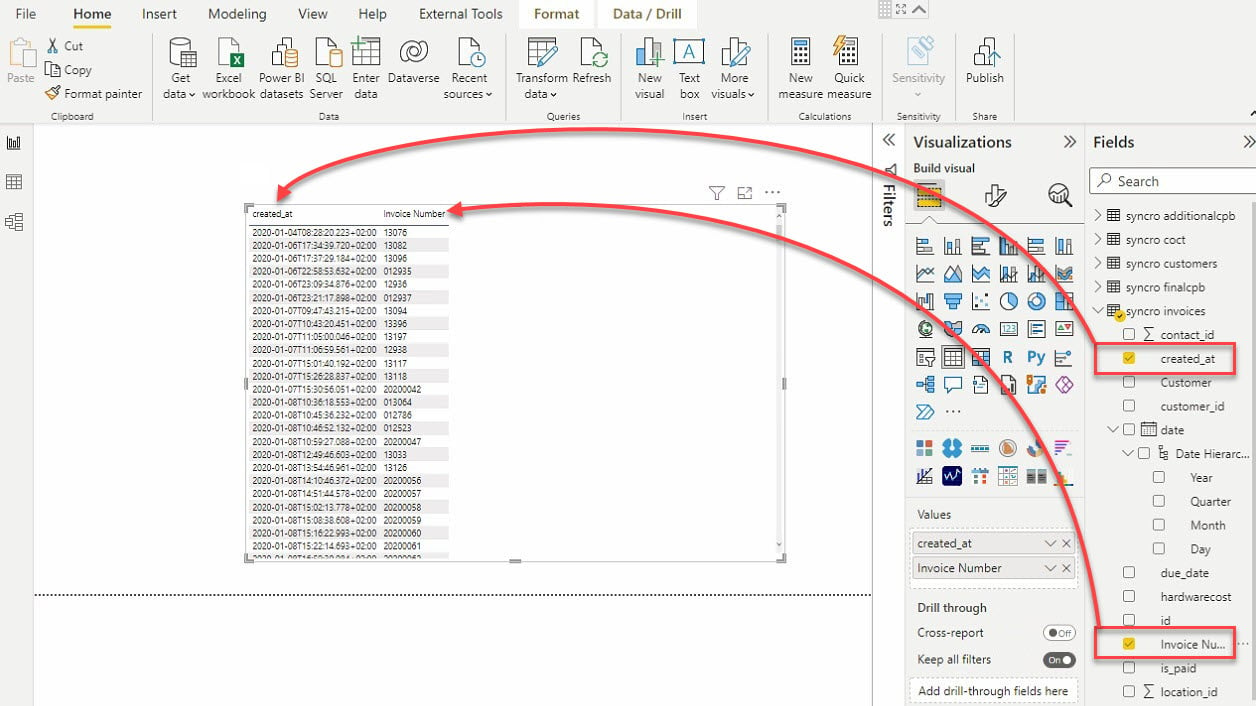
11. Selecciona la visualización de tabla y los campos de datos (en el panel Campos) para agregar a tu visualización de tabla, como se muestra a continuación.
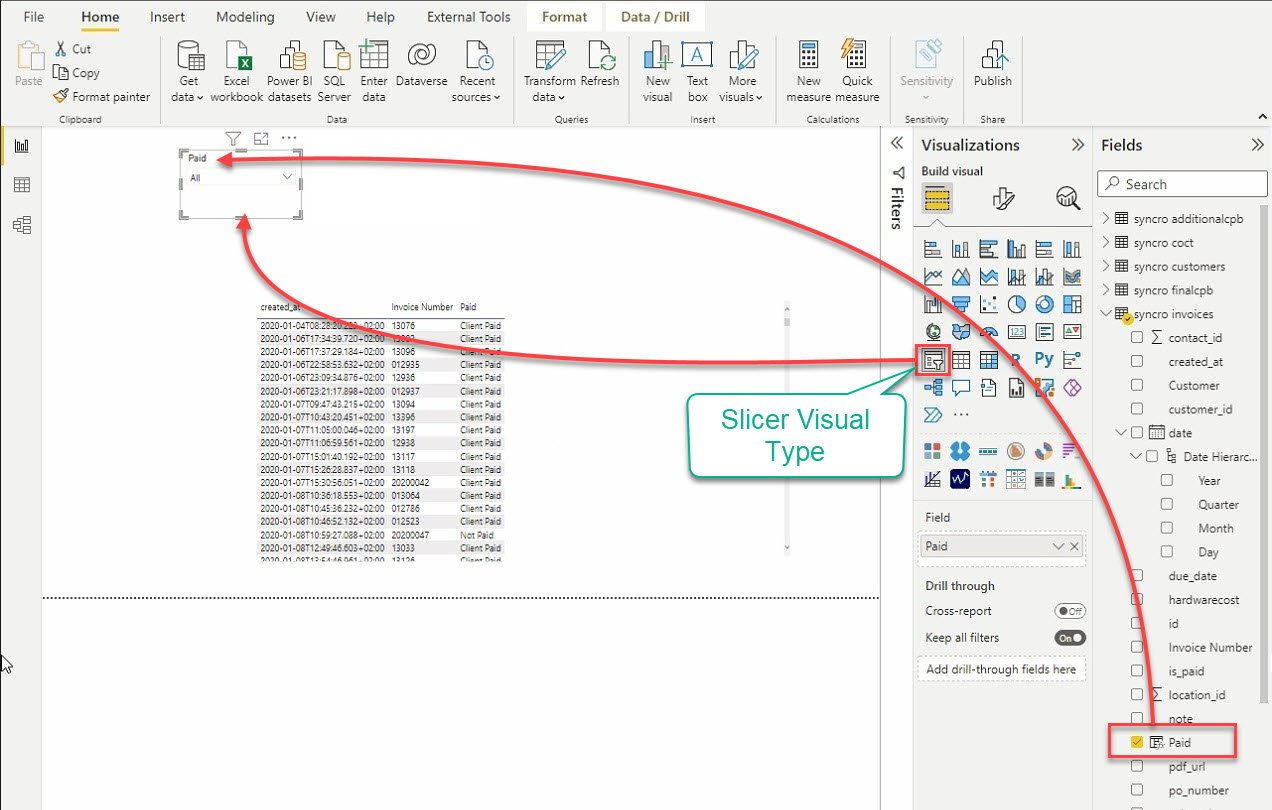
12. Finalmente, haz clic en el tipo visual de Cortador para agregar otra visual. Como su nombre indica, el visual de cortador corta los datos filtrando otras visualizaciones.
Después de agregar el cortador, selecciona datos desde el panel Campos para agregar al visual de cortador.
Cambiar Visualizaciones
La apariencia predeterminada de las visualizaciones es bastante decente. Pero ¿no sería genial si pudieras cambiar la apariencia de las visualizaciones a algo no tan soso? Deja que Power BI haga el truco.
Haz clic en el icono Formatear tu visualización bajo visualización para acceder al editor de visualización, como se muestra a continuación.
Dedica un tiempo a jugar con la configuración de visualización para obtener la apariencia deseada para tus visualizaciones. Tus visualizaciones se correlacionarán siempre y cuando establezcas una relación entre las tablas que involucres en tus visualizaciones.
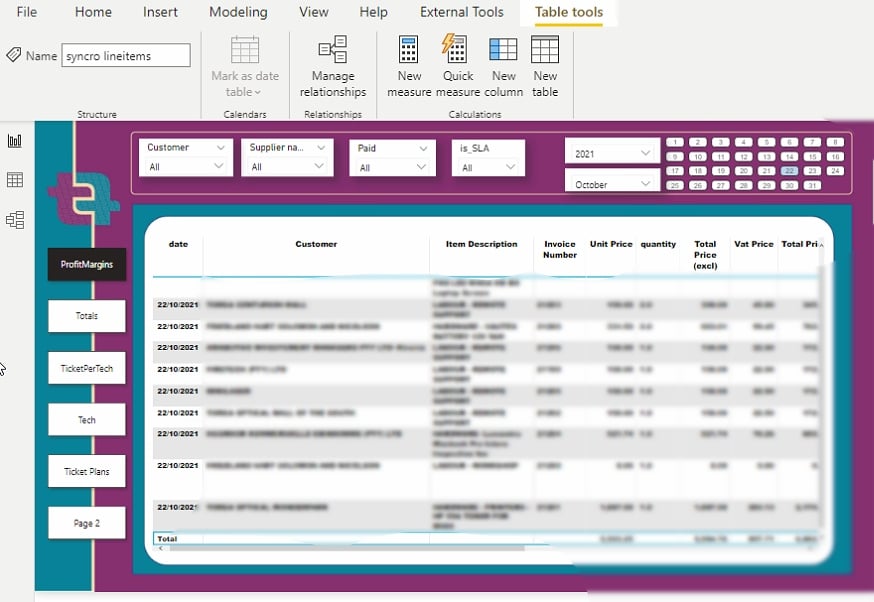
Después de cambiar la configuración de visualización, puedes generar informes como los siguientes.
Ahora, puedes visualizar y analizar tus datos sin complejidades ni dañar tus ojos.
En la siguiente visualización, al observar el gráfico de tendencias, notarás que algo salió mal en abril de 2020. Ese fue el momento en que comenzaron los confinamientos por Covid-19 en Sudáfrica.
Este resultado solo demuestra la eficacia de Power BI al proporcionar visualizaciones de datos precisas.

Conclusión
Este tutorial tiene como objetivo mostrarte cómo establecer un canal de datos dinámico en tiempo real mediante la obtención de datos de puntos finales de API. Además, procesar y enviar datos a tu base de datos y a Power BI utilizando Python. Con este conocimiento recién adquirido, ahora puedes consumir datos de API y crear tus propias visualizaciones de datos.
Cada vez más empresas están creando aplicaciones web con API Restful. Y en este punto, te sientes seguro/a al consumir APIs con Python y crear visualizaciones de datos con Power BI, lo que puede influir en las decisiones comerciales.