













Hibernate
Hibernate por sí solo no cuenta con soporte para búsquedas de texto completo. Debe depender del soporte del motor de base de datos o soluciones de terceros.
Una extensión llamada Hibernate Search se integra con Apache Lucene o Elasticsearch (también hay integración con OpenSearch).
Postgres
Postgres ha tenido funcionalidad de búsqueda de texto completo desde la versión 7.3. Aunque no puede competir con motores de búsqueda como Elasticsearch o Lucene, aún ofrece una solución flexible y robusta que podría ser suficiente para cumplir con las expectativas de los usuarios de la aplicación—características como stemming, ranking e indexación.
Explicaremos brevemente cómo podemos realizar una búsqueda de texto completo en Postgres. Para más información, visite la documentación de Postgres. En cuanto a la coincidencia de texto esencial, la parte más crucial es el operador matemático @@.
Devuelve true si el documento (objeto de tipo tsvector) coincide con la consulta (objeto de tipo tsquery).
El orden no es crucial para el operador. Por lo tanto, no importa si colocamos el documento en el lado izquierdo del operador y la consulta en el lado derecho o en un orden diferente.
Para una mejor demostración, utilizamos una tabla de base de datos llamada tweet.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)Con tal datos:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');Ahora veamos cómo se ve el objeto tsvector para la columna short_content de cada registro.
SELECT id, to_tsvector('english', short_content) FROM tweet;Salida:
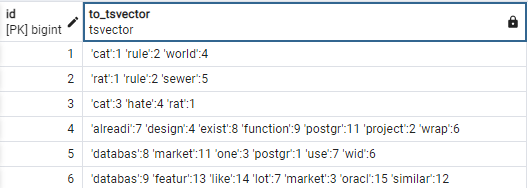
La salida muestra cómo to_tsvcector convierte la columna de texto en un objeto tsvector para la configuración de búsqueda de texto ‘english‘.
Configuración de Búsqueda de Texto
El primer parámetro para la función to_tsvector pasado en el ejemplo anterior fue el nombre de la configuración de búsqueda de texto. En ese caso, fue el “english“. Según la documentación de Postgres, la configuración de búsqueda de texto es la siguiente:
… la funcionalidad de búsqueda de texto completo incluye la capacidad de hacer muchas cosas más: omitir la indexación de ciertas palabras (palabras vacías), procesar sinónimos y utilizar un análisis sofisticado, por ejemplo, analizar basándose en más que solo espacios en blanco. Esta funcionalidad está controlada por configuraciones de búsqueda de texto.
Entonces, la configuración es una parte crucial del proceso y es vital para nuestros resultados de búsqueda de texto completo. Para diferentes configuraciones, el motor de Postgres puede devolver resultados diferentes. Esto no tiene por qué ser así entre diccionarios de diferentes idiomas. Por ejemplo, puede tener dos configuraciones para el mismo idioma, pero una ignora nombres que contengan dígitos (por ejemplo, algunos números de serie). Si pasamos nuestra consulta el número de serie específico que estamos buscando, que es obligatorio, no encontraremos ningún registro para la configuración que ignora palabras con números. A pesar de que tengamos tales registros en la base de datos, consulte la documentación de configuración para obtener más información.
Consulta de Texto
La consulta de texto admite tales operadores como & (AND), | (OR), ! (NOT) y <-> (SIGUIENTE POR). Los primeros tres operadores no requieren una explicación más profunda. El operador <-> verifica si las palabras existen y si están colocadas en un orden específico. Entonces, por ejemplo, para la consulta “rat <-> cat“, esperamos que exista la palabra “cat”, seguida por la “rat”.
Ejemplos
- Contenido que contiene el rat y cat:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- Contenido que contiene base de datos y mercado, y el mercado es la tercera palabra después de base de datos:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- Contenido que contiene base de datos pero no Postgres:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- Contenido que contiene Postgres o Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');
Funciones de Empaquetamiento
Se mencionó una de las funciones de envoltura que crea consultas de texto en este artículo, que es la to_tsquery. Existen más funciones como:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
La plainto_tsquery convierte todas las palabras pasadas en una consulta donde todas las palabras se combinan con el operador & (AND). Por ejemplo, el equivalente de plainto_tsquery('english', 'Rat cat') es to_tsquery('english', 'Rat & cat').
Para el siguiente uso:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');Obtenemos el resultado a continuación:

phraseto_tsquery
La phraseto_tsquery convierte todas las palabras pasadas en una consulta donde todas las palabras se combinan con el operador <-> (SIGUIENTE A). Por ejemplo, el equivalente de phraseto_tsquery('english', 'cat rule') es to_tsquery('english', 'cat <-> rule').
Para el siguiente uso:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');Obtenemos el resultado a continuación:

websearch_to_tsquery
La websearch_to_tsquery utiliza una sintaxis alternativa para crear una consulta de texto válida.
- Unquoted text: Convierte parte de la sintaxis de la misma manera que
plainto_tsquery - Quoted text: Convierte parte de la sintaxis de la misma manera que
phraseto_tsquery - OR: Convierte a “
|” (OR) operador - “
-“: Lo mismo que “!” (NOT) operador
Por ejemplo, el equivalente de la websearch_to_tsquery('english', '"cat rule" or database -Postgres') es to_tsquery('english', 'cat <-> rule | database & !Postgres').
Para el siguiente uso:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');Obtenemos el resultado a continuación:

Postgres and Hibernate Native Support
Como se menciona en el artículo, Hibernate por sí solo no tiene soporte de búsqueda de texto completo. Depende del soporte del motor de base de datos. Esto significa que se nos permite ejecutar consultas SQL nativas como se muestra en los ejemplos a continuación:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}Hibernate With posjsonhelper Library
La biblioteca posjsonhelper es un proyecto de código abierto que agrega soporte para consultas de Hibernate para funciones JSON de PostgreSQL y búsqueda de texto completo.
Para el proyecto Maven, necesitamos agregar las dependencias a continuación:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>Para utilizar componentes que existen en la biblioteca posjsonhelper, debemos registrarlos en el contexto de Hibernate.
Esto significa que debe haber una implementación especificada de org.hibernate.boot.model.FunctionContributor. La biblioteca tiene una implementación de esta interfaz, que es com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor.
A file with the name “org.hibernate.boot.model.FunctionContributor” under the “resources/META-INF/services” directory is required to use this implementation.
Existe otra forma de registrar el componente de posjsonhelper, que se puede hacer mediante programabilidad. Para ver cómo hacerlo, consulte este enlace.
Ahora, podemos usar operadores de búsqueda de texto completo en consultas de Hibernate.
PlainToTSQueryFunction
Este es un componente que envuelve la función plainto_tsquery.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Para una configuración con el valor 'english', el código generará la declaración a continuación:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
Este componente envuelve la función phraseto_tsquery.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Para la configuración con el valor 'english', el código va a generar la siguiente declaración:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
Este componente envuelve la función websearch_to_tsquery.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Para la configuración con el valor 'english', el código va a generar la siguiente declaración:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)Consultas HQL
Todos los componentes mencionados pueden ser utilizados en consultas HQL. Para ver cómo se puede hacer, por favor haga clic en este enlace.
¿Por qué usar la biblioteca posjsonhelper cuando podemos usar el enfoque nativo con Hibernate?
Aunque concatenar dinámicamente una cadena que se supone que es una consulta HQL o SQL puede ser fácil, implementar predicados sería mejor práctica, especialmente cuando tienes que manejar criterios de búsqueda basados en atributos dinámicos de tu API.
Conclusión
Como se mencionó en el artículo anterior, el soporte de búsqueda de texto completo de Postgres puede ser una buena alternativa para motores de búsqueda sustanciales como Elasticsearch o Lucene, en algunos casos. Esto podría ahorrarnos la decisión de agregar soluciones de terceros a nuestra pila tecnológica, lo que también podría agregar más complejidad y costos adicionales.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6