













Hibernate
Hibernate allein bietet keine Volltextsuche. Es muss auf die Unterstützung des Datenbank-Engines oder Drittanbieterlösungen zurückgreifen.
Eine Erweiterung namens Hibernate Search integriert sich mit Apache Lucene oder Elasticsearch (es gibt auch eine Integration mit OpenSearch).
Postgres
Postgres verfügt seit Version 7.3 über Volltextsuche-Funktionalität. Obwohl es nicht mit Suchmaschinen wie Elasticsearch oder Lucene konkurrieren kann, bietet es dennoch eine flexible und robuste Lösung, die möglicherweise ausreicht, um die Erwartungen der Anwendungsbenutzer zu erfüllen – Funktionen wie Wortstammmerkmale, Rangfolge und Indizierung.
Wir werden kurz erklären, wie wir eine Volltextsuche in Postgres durchführen können. Weitere Informationen finden Sie in der Postgres-Dokumentation. Für den grundlegenden Textabgleich ist der wichtigste Teil der mathematische Operator @@.
Er gibt true zurück, wenn das Dokument (Objekt vom Typ tsvector) die Abfrage (Objekt vom Typ tsquery) entspricht.
Die Reihenfolge ist für den Operator nicht entscheidend. Daher spielt es keine Rolle, ob wir das Dokument auf der linken Seite des Operators und die Abfrage auf der rechten Seite oder in einer anderen Reihenfolge platzieren.
Für eine bessere Demonstration verwenden wir eine Datenbanktabelle namens tweet.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)Mit solchen Daten:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');Schauen wir uns nun an, wie das tsvector Objekt für die short_content Spalte für jede der Einträge aussieht.
SELECT id, to_tsvector('english', short_content) FROM tweet;Ausgabe:
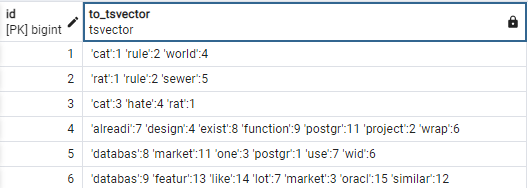
Die Ausgabe zeigt, wie to_tsvcector die Textspalte in ein tsvector Objekt für die ‚english‚ Textsuche konfiguriert.
Textsuche Konfiguration
Der erste Parameter für die to_tsvector Funktion in dem obigen Beispiel war der Name der Textsuche Konfiguration. In diesem Fall war es „english„. Laut Postgres Dokumentation ist die Textsuche Konfiguration wie folgt:
… die Volltextsuche Funktionalität beinhaltet die Fähigkeit, weitere Dinge zu tun: bestimmte Wörter (Stoppwörter) beim Indizieren zu überspringen, Synonyme zu verarbeiten und anspruchsvolle Analysen durchzuführen, z.B. Analysen basierend auf mehr als nur Leerzeichen. Diese Funktionalität wird von Textsuche Konfigurationen gesteuert.
Also ist die Konfiguration ein entscheidender Teil des Prozesses und von entscheidender Bedeutung für unsere Volltextsuchergebnisse. Bei verschiedenen Konfigurationen kann der Postgres-Engine unterschiedliche Ergebnisse zurückgeben. Dies muss jedoch nicht zwischen Wörterbüchern für verschiedene Sprachen der Fall sein. Sie können beispielsweise zwei Konfigurationen für dieselbe Sprache haben, wobei eine Namen, die Ziffern enthalten (z. B. einige Seriennummern), ignoriert. Wenn wir unserer Abfrage die spezifische Seriennummer übergeben, die wir suchen müssen, finden wir keine Aufzeichnung für die Konfiguration, die Wörter mit Zahlen ignoriert. Auch wenn wir solche Datensätze in der Datenbank haben, lesen Sie bitte die Konfigurationsdokumentation für weitere Informationen.
Textabfrage
Die Textabfrage unterstützt solche Operatoren wie & (UND), | (ODER), ! (NICHT) und <-> (NACHFOLGEND). Die ersten drei Operatoren erfordern keine tiefere Erklärung. Der <-> Operator überprüft, ob Wörter existieren und ob sie in einer bestimmten Reihenfolge angeordnet sind. So erwarten wir beispielsweise für die Abfrage „rat <-> cat„, dass das Wort „cat“ existiert und von „rat“ gefolgt wird.
Beispiele
- Inhalt, der das rat und das cat: enthält
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- Inhalt, der database und market, und das market ist das dritte Wort nach database enthält:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- Inhalt, der database enthält, aber nicht Postgres:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- Inhalt, der Postgres oder Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');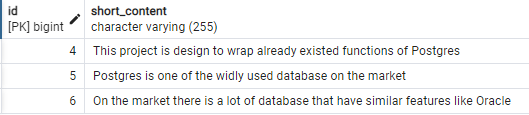
Wrapper-Funktionen
Eine der Wrapper-Funktionen, die Textabfragen erstellt, wurde bereits in diesem Artikel erwähnt, nämlich die to_tsquery. Es gibt weitere solcher Funktionen wie:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
Die plainto_tsquery wandelt alle übergebenen Wörter in eine Abfrage um, bei der alle Wörter mit dem & (UND) Operator kombiniert werden. Zum Beispiel ist das Äquivalent zu plainto_tsquery('english', 'Rat cat') to_tsquery('english', 'Rat & cat').
Bei folgendem Gebrauch:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');erhalten wir das Ergebnis unten:

phraseto_tsquery
Die phraseto_tsquery wandelt alle übergebenen Wörter in eine Abfrage um, bei der alle Wörter mit dem <-> (FOLLOW BY) Operator kombiniert werden. Zum Beispiel ist das Äquivalent zu phraseto_tsquery('english', 'cat rule') to_tsquery('english', 'cat <-> rule').
Bei folgendem Gebrauch:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');erhalten wir das Ergebnis unten:

websearch_to_tsquery
Die websearch_to_tsquery verwendet eine alternative Syntax zur Erstellung einer gültigen Textabfrage.
- Unzitierter Text: Wandelt einen Teil der Syntax auf die gleiche Weise wie
plainto_tsquery - Zitierter Text: Wandelt einen Teil der Syntax auf die gleiche Weise wie
phraseto_tsquery - ODER:Wandelt in „
|“ (ODER)-Operator - „
-„: Gleichwertig mit „!“ (NICHT)-Operator
Zum Beispiel ist das Äquivalent zu websearch_to_tsquery('english', '"cat rule" or database -Postgres') to_tsquery('english', 'cat <-> rule | database & !Postgres').
Für die folgende Verwendung:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');Erhalten wir das Ergebnis unten:

Postgres und Hibernate Native Support
Wie im Artikel erwähnt, verfügt Hibernate alleine nicht über Volltextsuche. Es muss sich auf die Unterstützung des Datenbank-Engines verlassen. Das bedeutet, dass wir native SQL-Abfragen wie in den folgenden Beispielen ausführen dürfen:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}Hibernate mit posjsonhelper-Bibliothek
Die posjsonhelper-Bibliothek ist ein Open-Source-Projekt, das die Unterstützung für Hibernate-Abfragen für PostgreSQL JSON-Funktionen und Volltextsuche hinzufügt.
Für das Maven Projekt müssen wir die folgenden Abhängigkeiten hinzufügen:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>Um Komponenten aus der posjsonhelper Bibliothek zu verwenden, müssen diese im Hibernate-Kontext registriert werden.
Dies bedeutet, dass eine spezifische Implementierung von org.hibernate.boot.model.FunctionContributor erforderlich ist. Die Bibliothek enthält eine Implementierung dieses Interfaces, nämlich com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor.
A file with the name „org.hibernate.boot.model.FunctionContributor“ under the „resources/META-INF/services“ directory is required to use this implementation.
Es gibt eine weitere Möglichkeit, Komponenten von posjsonhelper zu registrieren, die programmierbar erfolgen kann. Um zu sehen, wie das geht, schaut euch diesen Link an.
Ab sofort können wir Volltext-Suchoperatoren in Hibernate-Abfragen verwenden.
PlainToTSQueryFunction
Dies ist eine Komponente, die die plainto_tsquery Funktion einwickelt.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Für eine Konfiguration mit dem Wert 'english' wird der folgende Code die untenstehende Anweisung generieren:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
Dieser Baustein wickelt die Funktion phraseto_tsquery ein.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Bei der Konfiguration mit dem Wert 'english' wird der Code die folgende Anweisung generieren:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
Dieser Baustein wickelt die Funktion websearch_to_tsquery ein.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Bei der Konfiguration mit dem Wert 'english' wird der Code die folgende Anweisung generieren:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)HQL-Abfragen
Alle erwähnten Bausteine können in HQL-Abfragen verwendet werden. Um zu sehen, wie dies funktioniert, klicken Sie bitte auf diesen Link.
Warum die posjsonhelper-Bibliothek verwenden, wenn wir die native Herangehensweise mit Hibernate nutzen können?
Obwohl das dynamische Verketten eines Strings, der als HQL- oder SQL-Abfrage vorgesehen ist, möglicherweise einfach ist, ist die Implementierung von Prädikaten eine bessere Praxis, insbesondere wenn man Suchkriterien basierend auf dynamischen Attributen aus Ihrer API handhaben muss.
Schlussfolgerung
Wie im vorherigen Artikel erwähnt, kann die Unterstützung für Volltextsuche in Postgres in einigen Fällen eine gute Alternative für umfangreiche Suchmaschinen wie Elasticsearch oder Lucene sein. Dies könnte uns davor bewahren, Drittanbietersysteme zu unserer Technologiestapel hinzuzufügen, was auch mehr Komplexität und zusätzliche Kosten mit sich bringen könnte.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6