













Einführung
In diesem Tutorial erstellen Sie eine Python-Anwendung, die in der Lage ist, Audio aus einem Eingangsvideo zu extrahieren, das extrahierte Audio zu transkribieren, basierend auf der Transkription eine Untertiteldatei zu generieren und dann den Untertitel zu einer Kopie des Eingangsvideos hinzuzufügen.
Um diese Anwendung zu erstellen, verwenden Sie FFmpeg, um Audio aus einem Eingangsvideo zu extrahieren. Sie verwenden OpenAI’s Whisper, um eine Transkription für das extrahierte Audio zu generieren und verwenden dann diese Transkription, um eine Untertiteldatei zu generieren. Zusätzlich verwenden Sie FFmpeg, um die generierte Untertiteldatei zu einer Kopie des Eingangsvideos hinzuzufügen.
FFmpeg ist eine leistungsstarke und Open-Source-Software-Suite zur Verarbeitung von Multimediadaten, einschließlich Audio- und Videobearbeitungsaufgaben. Es bietet ein Befehlszeilentool, das Benutzern ermöglicht, Multimedia-Dateien mit einer Vielzahl von Formaten und Codecs zu konvertieren, zu bearbeiten und zu manipulieren.
OpenAI’s Whisper ist ein automatisches Spracherkennungssystem, das gesprochene Sprache in schriftlichen Text umwandelt. Es ist auf einer großen Menge an mehrsprachigen und multikontextuellen überwachten Daten trainiert und zeichnet sich durch eine hohe Genauigkeit bei der Transkription verschiedener Audioinhalte aus.
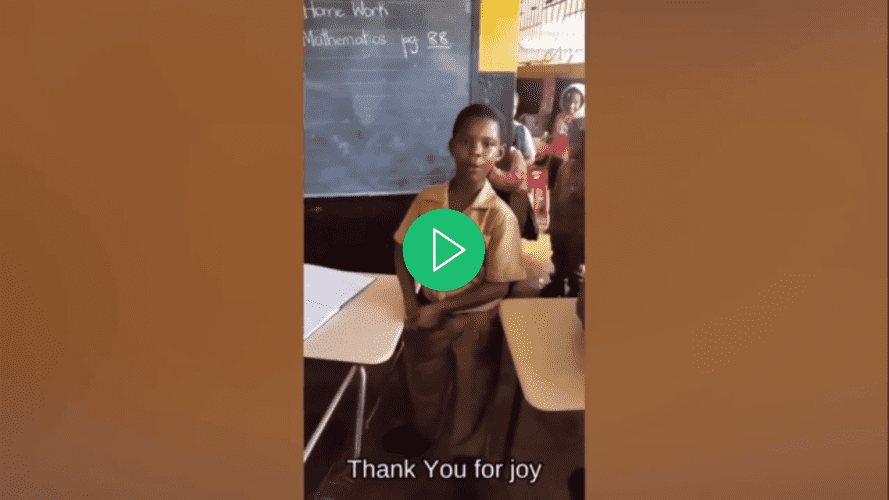
Am Ende dieses Tutorials verfügen Sie über eine Anwendung, die in der Lage ist, Untertitel zu einem Video hinzuzufügen:
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigt der Leser folgende Tools:
-
FFmpeg installiert.
-
Grundlegendes Verständnis von Python. Du kannst dieser Tutorial-Serie folgen, um das Programmieren in Python zu lernen.
Schritt 1 — Erstellen des Projekt-Root-Verzeichnisses
In diesem Abschnitt erstellst du das Projektverzeichnis, lädst das Eingabevideo herunter, erstellst und aktivierst eine virtuelle Umgebung und installierst die erforderlichen Python-Pakete.
Öffne ein Terminalfenster und navigiere zu einem geeigneten Ort für dein Projekt. Führe den folgenden Befehl aus, um das Projektverzeichnis zu erstellen:
Wechsle in das Projektverzeichnis:
Laden Sie dieses bearbeitete Video herunter und speichern Sie es im Stammverzeichnis Ihres Projekts als input.mp4. Das Video zeigt einen Jungen namens Rushawn, der Jermaine Edwards‘ „Beautiful Day“ singt. Das bearbeitete Video, das Sie in diesem Tutorial verwenden werden, wurde aus dem folgenden YouTube-Video entnommen:
Erstellen Sie eine neue virtuelle Umgebung und nennen Sie sie env:
Aktivieren Sie die virtuelle Umgebung:
Verwenden Sie nun den folgenden Befehl, um die für diese Anwendung benötigten Pakete zu installieren:
Mit dem oben genannten Befehl haben Sie die folgenden Bibliotheken installiert:
-
faster-whisper: ist eine neu gestaltete Version des Whisper-Modells von OpenAI, das CTranslate2 nutzt, eine leistungsstarke Inferenzmaschine für Transformer-Modelle. Diese Implementierung erreicht eine bis zu viermal höhere Geschwindigkeit als openai/whisper bei vergleichbarer Genauigkeit und verbraucht dabei weniger Speicher. -
ffmpeg-python: ist eine Python-Bibliothek, die eine Wrapper um das FFmpeg-Tool bietet und es Benutzern ermöglicht, FFmpeg-Funktionen in Python-Skripten einfach zu nutzen. Über eine Python-Schnittstelle ermöglicht es die Bearbeitung, Konvertierung und Manipulation von Video- und Audiodateien.
Führen Sie den folgenden Befehl aus, um die mit pip installierten Pakete innerhalb der virtuellen Umgebung in einer Datei namens requirements.txt zu speichern:
Die Datei requirements.txt sollte ähnlich wie folgt aussehen:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
In diesem Abschnitt haben Sie das Projektverzeichnis erstellt, das Eingabevideo heruntergeladen, eine virtuelle Umgebung eingerichtet, diese aktiviert und die erforderlichen Python-Pakete installiert. Im nächsten Abschnitt werden Sie eine Transkription für das Eingabevideo generieren.
Schritt 2 – Generieren der Video-Transkription
In diesem Abschnitt erstellen Sie das Python-Skript, in dem die Anwendung ausgeführt wird. In diesem Skript verwenden Sie die Bibliothek ffmpeg-python, um die Audiospur aus dem in dem vorherigen Abschnitt heruntergeladenen Video extrahieren und als WAV-Datei speichern. Anschließend verwenden Sie die Bibliothek faster-whisper, um eine Transkription für das extrahierte Audio zu generieren.
Erstellen Sie in Ihrem Projektstammverzeichnis eine Datei mit dem Namen main.py und fügen Sie den folgenden Code hinzu:
Hier beginnt der Code mit dem Import verschiedener Bibliotheken und Module, einschließlich time, math, ffmpeg von ffmpeg-python und einem benutzerdefinierten Modul mit dem Namen WhisperModel von faster_whisper. Diese Bibliotheken werden für die Video- und Audioverarbeitung, Transkription und Untertitelerstellung verwendet.
Dann setzt der Code den Eingabevideonamen, speichert ihn in einer Konstanten namens input_video und speichert den Videonamen ohne die Dateierweiterung .mp4 in einer Konstanten namens input_video_name. Das Setzen des Eingabedateinamens ermöglicht es Ihnen, an mehreren Eingabevideos zu arbeiten, ohne die für sie generierten Untertitel- und Ausgabevideodateien zu überschreiben.
Fügen Sie den folgenden Code am Ende Ihrer main.py-Datei hinzu:
Der obige Code definiert eine Funktion mit dem Namen extract_audio(), die für das Extrahieren des Audios aus dem Eingabevideo verantwortlich ist.
Zunächst wird der Name des extrahierten Audios auf einen Namen festgelegt, der sich aus dem Anhängen von audio- an den Basisnamen des Eingangsvideos mit der Erweiterung .wav bildet, und dieser Name wird in einer Konstanten namens extracted_audio gespeichert.
Dann ruft der Code die Methode ffmpeg.input() der Bibliothek ffmpeg auf, um das Eingangsvideo zu öffnen, und erstellt ein Eingangsstromobjekt namens stream.
Dann ruft der Code die Methode ffmpeg.output() auf, um ein Ausgangsstromobjekt mit dem Eingangsstrom und dem definierten Namen der extrahierten Audiodatei zu erstellen.
Nachdem der Ausgangsstrom festgelegt wurde, ruft der Code die Methode ffmpeg.run() auf und übergibt den Ausgangsstrom als Parameter, um den Audioextraktionsprozess zu starten und die extrahierte Audiodatei im Stammverzeichnis Ihres Projekts zu speichern. Zusätzlich wird ein boolescher Parameter overwrite_output=True verwendet, um jede vorhandene Ausgabedatei durch die neu generierte Datei zu ersetzen, falls bereits eine solche Datei vorhanden ist.
Zuletzt gibt der Code den Namen der extrahierten Audiodatei zurück.
Fügen Sie den folgenden Code unterhalb der Funktion extract_audio() hinzu:
Hier definiert der Code eine Funktion namens run() und ruft sie dann auf. Diese Funktion ruft alle Funktionen auf, die benötigt werden, um Untertitel zu einem Video hinzuzufügen.
In der Funktion ruft der Code die Funktion extract_audio() auf, um Audio aus einem Video zu extrahieren, und speichert dann den zurückgegebenen Audiodateinamen in einer Variable namens extracted_audio.
Gehen Sie zurück zu Ihrem Terminal und führen Sie den folgenden Befehl aus, um das Skript main.py auszuführen:
Nach Ausführung des oben genannten Befehls wird die Ausgabe von FFmpeg im Terminal angezeigt und eine Datei mit dem Namen audio-input.wav, die den aus dem Eingangsvideo extrahierten Audio enthält, wird im Stammverzeichnis Ihres Projekts gespeichert.
Gehen Sie zurück zu Ihrer main.py Datei und fügen Sie den folgenden Code zwischen den Funktionen extract_audio() und run() hinzu:
Der obige Code definiert eine Funktion namens transcribe, die für das Transkribieren der aus dem Eingangsvideo extrahierten Audiodatei verantwortlich ist.
Zuerst erstellt der Code eine Instanz des Objekts WhisperModel und setzt den Modelltyp auf small. OpenAI’s Whisper hat die folgenden Modelltypen: tiny, base, small, medium und large. Das tiny Modell ist das kleinste und schnellste und das large Modell ist das größte und langsamste, aber am genauesten.
Dann ruft der Code die Methode model.transcribe() mit dem extrahierten Audio als Argument auf, um die Funktions- und Audio-Informationen abzurufen und speichert sie in den Variablen info und segments. Die Funktionssegments ist ein Python-Generator, sodass die Transkription erst beginnt, wenn der Code darüber iteriert. Die Transkription kann durch das Sammeln der Segmente in einer list oder einer for-Schleife vollständig ausgeführt werden.
Dann speichert der Code die in der Audiodatei erkannte Sprache in einer Konstanten namens info und gibt sie in der Konsole aus.
Nachdem die erkannte Sprache gedruckt wurde, sammelt der Code die Transkriptionssegmente in einer list, um die Transkription auszuführen, und speichert die gesammelten Segmente auch in einer Variable namens segments. Der Code durchläuft dann die Transkriptionssegmente in der Liste und druckt die Startzeit, Endzeit und den Text jedes Segments in der Konsole aus.
Schließlich gibt der Code die erkannte Sprache im Audio und die Transkriptionssegmente zurück.
Fügen Sie den folgenden Code in die run()-Funktion ein:
Der hinzugefügte Code ruft die Funktion transcribe mit dem extrahierten Audio als Argument auf und speichert die zurückgegebenen Werte in den Konstanten language und segments.
Gehen Sie zurück zu Ihrem Terminal und führen Sie den folgenden Befehl aus, um das Skript main.py auszuführen:
Beim ersten Ausführen dieses Skripts wird der Code zunächst das Whisper Small-Modell herunterladen und zwischenspeichern. Bei weiteren Ausführungen wird es viel schneller sein.
Nach Ausführung des obigen Befehls sollten Sie die folgende Ausgabe in der Konsole sehen:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
Die obige Ausgabe zeigt, dass die im Audio erkannte Sprache Englisch (en) ist. Außerdem werden die Start- und Endzeit sowie der Text jedes Transkriptionssegments angezeigt.
Warnung: Obwohl die Spracherkennung von OpenAI’s Whisper sehr genau ist, ist sie nicht zu 100% genau und kann gelegentlich Fehler aufweisen, insbesondere in schwierigen sprachlichen oder audiovisuellen Szenarien. Überprüfen Sie daher immer die Transkription manuell.
In diesem Abschnitt haben Sie ein Python-Skript für die Anwendung erstellt. Innerhalb des Skripts wurde ffmpeg-python verwendet, um den Ton aus dem heruntergeladenen Video extrahieren und als WAV-Datei speichern. Anschließend wurde die Bibliothek faster-whisper verwendet, um eine Transkription für den extrahierten Ton zu generieren. Im nächsten Abschnitt werden Sie basierend auf der Transkription eine Untertiteldatei erstellen und diese dann dem Video hinzufügen.
Schritt 3 – Generieren und Hinzufügen von Untertiteln zum Video
In diesem Abschnitt werden Sie zunächst verstehen, was eine Untertiteldatei ist und wie sie strukturiert ist. Anschließend werden Sie die in dem vorherigen Abschnitt generierten Transkriptionssegmente verwenden, um eine Untertiteldatei zu erstellen. Nachdem Sie die Untertiteldatei erstellt haben, werden Sie die Bibliothek ffmpeg-python verwenden, um die Untertiteldatei zu einer Kopie des Eingabevideos hinzuzufügen.
Verständnis von Untertiteln: Struktur und Arten
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Untertitel-Index: Eine fortlaufende Nummer, die die Reihenfolge des Untertitels in der Datei angibt.
-
Zeitcodes: Start- und Endzeitmarkierungen, die angeben, wann der Untertitel angezeigt werden soll. Die Zeitcodes sind normalerweise im Format
HH:MM:SS,sss(Stunden, Minuten, Sekunden, Millisekunden) formatiert. -
Untertiteltext: Der eigentliche Text des Untertiteleintrags, der gesprochenen oder geschriebenen Inhalt repräsentiert. Dieser Text wird während des angegebenen Zeitintervalls auf dem Bildschirm angezeigt.
Zum Beispiel könnte ein Untertitelelement in einer SRT-Datei wie folgt aussehen:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
In diesem Beispiel ist der Index 1, die Zeitcodes geben an, dass der Untertitel von 10,5 Sekunden bis 15 Sekunden angezeigt werden soll, und der Untertiteltext ist Dies ist ein Beispieluntertitel.
Untertitel können in zwei Haupttypen unterteilt werden:
-
Weiche Untertitel: Auch bekannt als geschlossene Untertitel, werden sie extern als separate Dateien (wie SRT) gespeichert und können unabhängig vom Video hinzugefügt oder entfernt werden. Sie bieten dem Zuschauer Flexibilität, indem sie das Umschalten, das Wechseln der Sprache und die Anpassung der Einstellungen ermöglichen. Ihre Wirksamkeit hängt jedoch von der Unterstützung des Videoplayers ab, und nicht alle Player unterstützen weiche Untertitel universell.
-
Hard-Untertitel: Werden während der Bearbeitung oder Codierung dauerhaft in die Videoframes eingebettet und bleiben ein fester Bestandteil des Videos. Während sie eine konstante Sichtbarkeit gewährleisten, auch auf Playern, die keine Unterstützung für externe Untertiteldateien bieten, erfordern Änderungen oder das Ausschalten eine erneute Codierung des gesamten Videos, was die Benutzerkontrolle einschränkt.
Erstellen der Untertiteldatei
Gehen Sie zurück zu Ihrer main.py Datei und fügen Sie den folgenden Code zwischen die Funktionen transcribe() und run() hinzu:
Hier definiert der Code eine Funktion mit dem Namen format_time(), die dafür verantwortlich ist, die Start- und Endzeit eines Transkriptsegments in Sekunden in ein Untertitel-kompatibles Zeitformat umzuwandeln, das Stunden, Minuten, Sekunden und Millisekunden (HH:MM:SS,sss) anzeigt.
Der Code berechnet zuerst Stunden, Minuten, Sekunden und Millisekunden aus der gegebenen Zeit in Sekunden, formatiert sie entsprechend und gibt dann die formatierte Zeit zurück.
Fügen Sie den folgenden Code zwischen die Funktionen format_time() und run() hinzu:
Der hinzugefügte Code definiert eine Funktion mit dem Namen generate_subtitle_file(), die als Parameter die in der extrahierten Audiodatei erkannte Sprache und die Transkriptsegmente annimmt. Diese Funktion ist dafür verantwortlich, basierend auf der Sprache und den Transkriptsegmenten eine SRT-Untertiteldatei zu generieren.
Zuerst setzt der Code den Namen der Untertiteldatei auf einen Namen, der sich aus dem Hinzufügen von sub- und der erkannten Sprache zum Basisnamen des Eingangsvideos mit der Dateierweiterung „.srt“ ergibt, und speichert diesen Namen in einer Konstanten mit dem Namen subtitle_file. Zusätzlich definiert der Code eine Variable mit dem Namen text, in der Sie die Untertiteleinträge speichern werden.
Dann durchläuft der Code die transkribierten Segmente, formatiert die Start- und Endzeiten mithilfe der Funktion format_time(), verwendet diese formatierten Werte zusammen mit dem Segmentindex und dem Text, um einen Untertiteleintrag zu erstellen, und fügt dann eine leere Zeile zwischen jedem Untertiteleintrag hinzu.
Zuletzt erstellt der Code eine Untertiteldatei im Stammverzeichnis Ihres Projekts mit dem zuvor festgelegten Namen, fügt die Untertiteleinträge zur Datei hinzu und gibt den Namen der Untertiteldatei zurück.
Fügen Sie den folgenden Code am Ende Ihrer run()-Funktion hinzu:
Der hinzugefügte Code ruft die Funktion generate_subtitle_file() mit der erkannten Sprache und den Transkriptionssegmenten als Argumente auf und speichert den zurückgegebenen Dateinamen der Untertiteldatei in einer Konstanten mit dem Namen subtitle_file.
Gehen Sie zurück zu Ihrem Terminal und führen Sie den folgenden Befehl aus, um das Skript main.py auszuführen:
Nach Ausführung des obigen Befehls wird eine Untertiteldatei mit dem Namen sub-input.en.srt im Stammverzeichnis Ihres Projekts gespeichert.
Öffnen Sie die Untertiteldatei sub-input.en.srt und Sie sollten etwas Ähnliches wie folgt sehen:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Untertitel zu Videos hinzufügen
Fügen Sie den folgenden Code zwischen die Funktionen generate_subtitle_file() und run() hinzu:
Hier definiert der Code eine Funktion mit dem Namen add_subtitle_to_video(), die als Parameter einen booleschen Wert erhält, der verwendet wird, um zu bestimmen, ob ein weicher Untertitel oder ein harter Untertitel hinzugefügt werden soll, den Dateinamen der Untertiteldatei und die erkannte Sprache in der Transkription. Diese Funktion ist dafür verantwortlich, weiche oder harte Untertitel zu einer Kopie des Eingangsvideos hinzuzufügen.
Zuerst verwendet der Code die Methode ffmpeg.input() mit dem Eingabevideo und der Untertiteldatei, um Eingabestream-Objekte für das Eingabevideo und die Untertiteldatei zu erstellen und speichert sie in den Konstanten video_input_stream und subtitle_input_stream.
Nachdem die Eingabestreams erstellt wurden, setzt der Code den Namen der Ausgabevideodatei auf einen Namen, der durch das Anhängen von output- an den Basenamen des Eingabevideos mit der Erweiterung „.mp4“ gebildet wird, und speichert diesen Namen in einer Konstanten namens output_video. Zusätzlich setzt er den Namen der Untertitelspur auf den Untertiteldateinamen ohne die Erweiterung .srt und speichert diesen Namen in einer Konstanten namens subtitle_track_title.
Als nächstes überprüft der Code, ob das boolesche soft_subtitle auf True gesetzt ist, was darauf hinweist, dass er einen Soft-Untertitel hinzufügen soll.
Wenn das der Fall ist, ruft der Code die Methode ffmpeg.output() auf, um ein Ausgabestream-Objekt mit den Eingabestreams, dem Namen der Ausgabevideodatei und den folgenden Optionen für das Ausgabevideo zu erstellen:
-
"c": "copy": Es legt fest, dass der Videocodec und andere Videoparameter direkt von der Eingabe zur Ausgabe kopiert werden sollen, ohne erneut codiert zu werden. -
"c:s": "mov_text": Es gibt an, dass der Untertitel-Codec und die Parameter ohne Neucodierung von der Eingabe zur Ausgabe kopiert werden sollen.mov_textist ein häufig verwendeter Untertitel-Codec in MP4/MOV-Dateien. -
”metadata:s:s:0”: f"language={subtitle_language}": Es legt Metadaten für den Untertitel-Stream fest. Die Sprache wird auf den Wert gesetzt, der insubtitle_languagegespeichert ist. -
"metadata:s:s:0": f"title={subtitle_track_title}": Es legt Metadaten für den Untertitel-Stream fest. Der Titel wird auf den Wert gesetzt, der insubtitle_track_titlegespeichert ist.
Zum Schluss ruft der Code die Methode ffmpeg.run() auf und übergibt den Ausgabe-Stream als Parameter, um den Soft-Untertitel zum Video hinzuzufügen und die Ausgabedatei im Stammverzeichnis des Projekts zu speichern.
Fügen Sie den folgenden Code am Ende Ihrer Funktion add_subtitle_to_video() hinzu:
Der hervorgehobene Code wird ausgeführt, wenn der boolesche Wert soft_subtitle auf False gesetzt ist, was darauf hinweist, dass ein hartes Untertitel hinzugefügt werden soll.
Wenn das der Fall ist, ruft der Code zunächst die Methode ffmpeg.output() auf, um ein Ausgabestromobjekt mit dem Eingabevideostrom, dem Ausgabevideonamen und dem Parameter vf=f"subtitles={subtitle_file}" zu erstellen. vf steht für „Video-Filter“ und wird verwendet, um einen Filter auf den Videostrom anzuwenden. In diesem Fall wird der Filter für die Hinzufügung des Untertitels angewendet.
Zuletzt ruft der Code die Methode ffmpeg.run() auf und übergibt den Ausgabestrom als Parameter, um den harten Untertitel zum Video hinzuzufügen und die Ausgabevideodatei im Stammverzeichnis des Projekts zu speichern.
Fügen Sie den folgenden hervorgehobenen Code zur Funktion run() hinzu:
Der hervorgehobene Code ruft die Methode add_subtitle_to_video() mit dem Parameter soft_subtitle auf, der auf True gesetzt ist, dem Dateinamen des Untertitels und der Untertitelsprache, um einen weichen Untertitel zu einer Kopie des Eingabevideos hinzuzufügen.
Gehen Sie zurück zur Eingabeaufforderung und führen Sie den folgenden Befehl aus, um das Skript main.py auszuführen:
Nach Ausführung des obigen Befehls wird eine Ausgabevideodatei mit dem Namen output-input.mp4 im Stammverzeichnis des Projekts gespeichert.
Öffnen Sie das Video mit Ihrem bevorzugten Videoplayer, wählen Sie einen Untertitel für das Video aus und bemerken Sie, wie der Untertitel erst angezeigt wird, wenn Sie ihn auswählen:
Gehen Sie zurück zur Datei main.py, navigieren Sie zur Funktion run() und setzen Sie den Parameter soft_subtitle in dem Funktionsaufruf von add_subtitle_to_video() auf False:
Hier setzen Sie den Parameter soft_subtitle auf False, um harte Untertitel zum Video hinzuzufügen.
Gehen Sie zurück zu Ihrem Terminal und führen Sie den folgenden Befehl aus, um das Skript main.py auszuführen:
Nach Ausführung des obigen Befehls wird die Videodatei output-input.mp4 im Stammverzeichnis Ihres Projekts überschrieben.
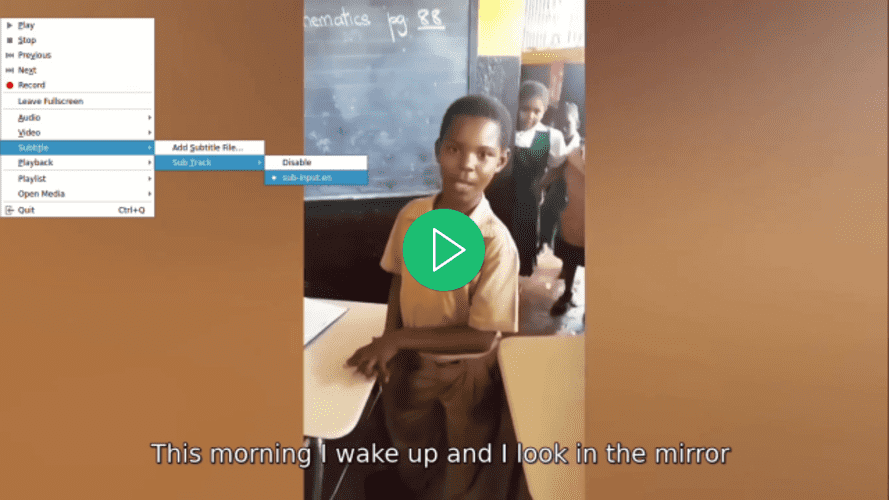
Öffnen Sie das Video mit Ihrem bevorzugten Videoplayer, versuchen Sie einen Untertitel für das Video auszuwählen und bemerken Sie, dass keiner verfügbar ist, obwohl ein Untertitel angezeigt wird:

In diesem Abschnitt haben Sie das Struktur einer SRT-Untertiteldatei verstanden und die Transkriptionsegmente aus dem vorherigen Abschnitt verwendet, um eine solche Datei zu erstellen. Anschließend wurde die Bibliothek ffmpeg-python verwendet, um die generierte Untertiteldatei zum Video hinzuzufügen.
Fazit
In diesem Tutorial haben Sie die Python-Bibliotheken ffmpeg-python und faster-whisper verwendet, um eine Anwendung zu erstellen, die in der Lage ist, Audio aus einem Eingabevideo zu extrahieren, das extrahierte Audio zu transkribieren, basierend auf der Transkription eine Untertiteldatei zu generieren und den Untertitel zu einer Kopie des Eingabevideos hinzuzufügen.