













In den Anfangstagen der Computertechnologie wurden Aufgaben sequenziell abgearbeitet. Mit dem Anstieg der Nutzerzahl auf Millionen wurde dieser Ansatz jedoch unpraktisch. Die asynchrone Verarbeitung ermöglichte die gleichzeitige Bearbeitung mehrerer Aufgaben, aber die Verwaltung von Threads/Prozessen auf einer einzelnen Maschine führte zu Ressourcenbeschränkungen und Komplexität.
Hier kommt die verteilte parallele Verarbeitung ins Spiel. Durch die Verteilung der Arbeitslast auf mehrere Maschinen, von denen jede einem Teil der Aufgabe gewidmet ist, bietet sie eine skalierbare und effiziente Lösung. Wenn Sie eine Funktion haben, um eine große Menge von Dateien zu verarbeiten, können Sie die Arbeitslast auf mehrere Maschinen aufteilen, um die Dateien gleichzeitig anstatt sequenziell auf einer Maschine zu verarbeiten. Darüber hinaus verbessert es die Leistung durch die Nutzung kombinierter Ressourcen und bietet Skalierbarkeit und Ausfallsicherheit. Wenn die Anforderungen steigen, können Sie weitere Maschinen hinzufügen, um verfügbare Ressourcen zu erhöhen.
Es ist eine Herausforderung, verteilte Anwendungen im großen Maßstab zu entwickeln und auszuführen, aber es gibt mehrere Frameworks und Tools, die Ihnen dabei helfen können. In diesem Blog-Beitrag werden wir ein solches Open-Source-Framework für verteilte Berechnungen untersuchen: Ray. Wir werden auch KubeRay betrachten, einen Kubernetes-Operator, der eine nahtlose Integration von Ray mit Kubernetes-Clustern für verteilte Berechnungen in Cloud-nativen Umgebungen ermöglicht. Aber zuerst wollen wir verstehen, wo verteilte Parallelverarbeitung hilfreich ist.
Wo hilft die verteilte parallele Verarbeitung?
Jede Aufgabe, die von der Verteilung ihrer Arbeitslast auf mehrere Maschinen profitiert, kann verteilte parallele Verarbeitung nutzen. Dieser Ansatz ist besonders nützlich für Szenarien wie Web-Crawling, groß angelegte Datenanalysen, das Training von Machine-Learning-Modellen, die Verarbeitung von Echtzeit-Streams, die Analyse genomischer Daten und das Rendering von Videos. Durch die Verteilung von Aufgaben auf mehrere Knoten verbessert die verteilte parallele Verarbeitung erheblich die Leistung, reduziert die Verarbeitungszeit und optimiert die Ressourcennutzung, was sie für Anwendungen, die eine hohe Durchsatzrate und schnelle Datenverarbeitung erfordern, unerlässlich macht.
Wann verteilte parallele Verarbeitung nicht benötigt wird
- Kleinere Anwendungen: Bei kleinen Datensätzen oder Anwendungen mit minimalen Verarbeitungsanforderungen ist der Aufwand für die Verwaltung eines verteilten Systems möglicherweise nicht gerechtfertigt.
- Starke Datenabhängigkeiten: Wenn Aufgaben stark voneinander abhängig sind und nicht leicht parallelisiert werden können, bietet die verteilte Verarbeitung möglicherweise nur geringe Vorteile.
- Echtzeitbeschränkungen: Einige Echtzeitanwendungen (z. B. Finanz- und Ticketbuchungswebsites) erfordern extrem niedrige Latenzzeiten, die mit der zusätzlichen Komplexität eines verteilten Systems möglicherweise nicht erreichbar sind.
- Begrenzte Ressourcen: Wenn die verfügbare Infrastruktur den Aufwand für ein verteiltes System nicht unterstützen kann (z. B. unzureichende Netzwerkbandbreite, begrenzte Anzahl von Knoten), kann es besser sein, die Leistung einer Einzelmaschine zu optimieren.
Wie Ray bei verteilter paralleler Verarbeitung hilft
Ray ist ein verteilter paralleler Verarbeitungsrahmen, der alle Vorteile des verteilten Rechnens und Lösungen für die von uns diskutierten Herausforderungen wie Fehlertoleranz, Skalierbarkeit, Kontextverwaltung, Kommunikation usw. zusammenfasst. Es handelt sich um ein Pythonic-Framework, das die Verwendung vorhandener Bibliotheken und Systeme ermöglicht. Mit Rays Hilfe muss ein Programmierer sich nicht um die Teile der parallelen Verarbeitungsschicht kümmern. Ray kümmert sich um die Planung und das automatische Skalieren basierend auf den angegebenen Ressourcenanforderungen.
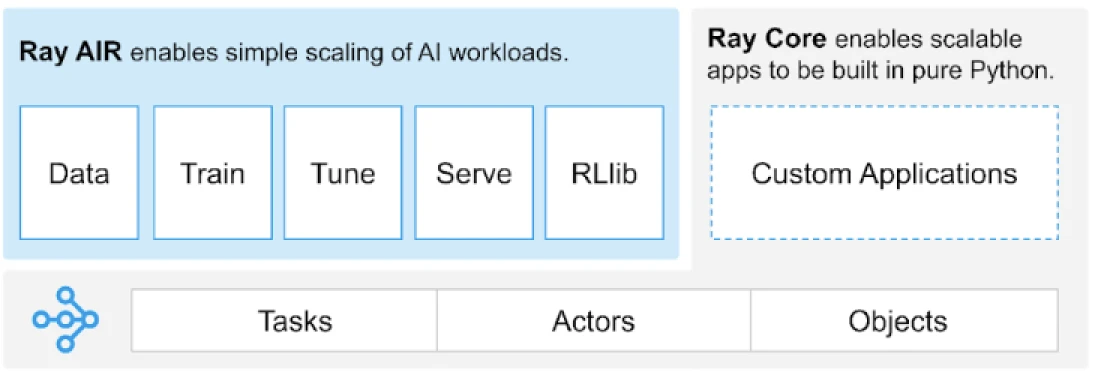
Ray bietet eine universelle API für Aufgaben, Schauspieler und Objekte zum Erstellen verteilter Anwendungen.
(Bildquelle)
Ray bietet eine Reihe von Bibliotheken, die auf den Kernprimitiven wie Aufgaben, Schauspielern, Objekten, Treibern und Jobs aufbauen. Diese bieten eine vielseitige API, um beim Aufbau verteilter Anwendungen zu helfen. Werfen wir einen Blick auf die Kernprimitiven, auch bekannt als Ray Core.
Ray Core Primitives
- Aufgaben: Ray-Aufgaben sind beliebige Python-Funktionen, die asynchron auf separaten Python-Workern auf einem Ray-Clusterknoten ausgeführt werden. Benutzer können ihre Ressourcenanforderungen in Bezug auf CPUs, GPUs und benutzerdefinierte Ressourcen angeben, die vom Cluster-Scheduler verwendet werden, um Aufgaben für parallele Ausführung zu verteilen.
- Aktoren: Was Aufgaben für Funktionen sind, sind Aktoren für Klassen. Ein Aktor ist ein zustandsbehafteter Worker, und die Methoden eines Aktors werden auf diesem spezifischen Worker geplant und können auf den Zustand dieses Workers zugreifen und ihn ändern. Wie Aufgaben unterstützen Aktoren CPU-, GPU- und benutzerdefinierte Ressourcenanforderungen.
- Objekte: In Ray erstellen und berechnen Aufgaben und Aktoren Objekte. Diese entfernten Objekte können überall in einem Ray-Cluster gespeichert werden. Objektverweise werden verwendet, um auf sie zu verweisen, und sie werden im verteilten gemeinsam genutzten Speicherobjektspeicher von Ray zwischengespeichert.
- Driver: Das Programmstammverzeichnis oder das „Hauptprogramm“: Dies ist der Code, der
ray.init()ausführt. - Jobs: Die Sammlung von Aufgaben, Objekten und Aktoren, die (rekursiv) von demselben Treiber und ihrer Laufzeitumgebung stammen
Für Informationen über Primitiven können Sie die Ray Core-Dokumentation durchgehen.
Ray Core-Schlüsselmethoden
Hier sind einige der Schlüsselmethoden innerhalb von Ray Core, die häufig verwendet werden:
-
ray.init()– Starten Sie die Ray-Laufzeit und verbinden Sie sich mit dem Ray-Cluster.import ray ray.init()
-
@ray.remote– Dekorator, der eine Python-Funktion oder -Klasse angibt, die als Aufgabe (Remote-Funktion) oder Schauspieler (Remote-Klasse) in einem anderen Prozess ausgeführt wird.@ray.remote def remote_function(x): return x * 2
-
.remote– Suffix für die Remote-Funktionen und -Klassen; Remote-Operationen sind asynchron.result_ref = remote_function.remote(10)
-
ray.put()– Legen Sie ein Objekt im In-Memory-Objektspeicher ab; liefert eine Objektreferenz, die zum Übergeben des Objekts an einen beliebigen Remote-Funktions- oder Methodenaufruf verwendet wird.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Holen Sie sich ein Remote-Objekt/-Objekte aus dem Objektspeicher, indem Sie die Objektreferenz(en) angeben.result = ray.get(result_ref) original_data = ray.get(data_ref)
Hier ist ein Beispiel für die Verwendung der meisten grundlegenden Schlüsselmethoden:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Verwendung von .remote zur Erstellung einer Aufgabe
future = calculate_square.remote(5)
# Ergebnisse abrufen
result = ray.get(future)
print(f"The square of 5 is: {result}")Wie funktioniert Ray?
Ray-Cluster ist wie ein Team von Computern, das die Arbeit zum Ausführen eines Programms teilt. Es besteht aus einem Hauptknoten und mehreren Arbeiterknoten. Der Hauptknoten verwaltet den Clusterzustand und die Planung, während die Arbeiterknoten Aufgaben ausführen und Akteure verwalten
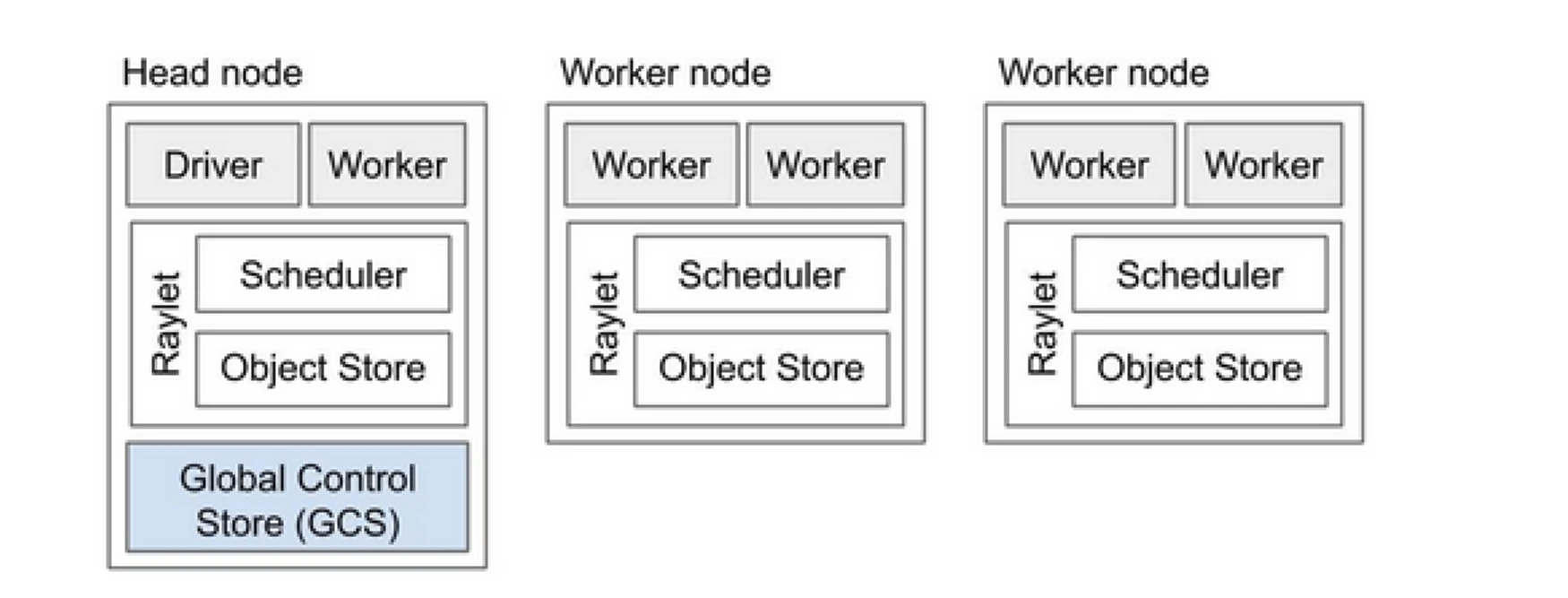
Komponenten des Ray-Clusters
- Global Control Store (GCS): Der GCS verwaltet die Metadaten und den globalen Zustand des Ray-Clusters. Er verfolgt Aufgaben, Akteure und die Verfügbarkeit von Ressourcen und stellt sicher, dass alle Knoten eine konsistente Sicht auf das System haben.
- Scheduler: Der Scheduler verteilt Aufgaben und Akteure auf die verfügbaren Knoten. Er sorgt für eine effiziente Ressourcennutzung und Lastverteilung, indem er die Ressourcenanforderungen und Abhängigkeiten der Aufgaben berücksichtigt.
- Hauptknoten: Der Hauptknoten orchestriert den gesamten Ray-Cluster. Er führt den GCS aus, verwaltet die Aufgabenplanung und überwacht die Gesundheit der Arbeiterknoten.
- Arbeiterknoten: Arbeiterknoten führen Aufgaben und Akteure aus. Sie führen die tatsächlichen Berechnungen durch und speichern Objekte in ihrem lokalen Speicher.
- Raylet: Es verwaltet gemeinsame Ressourcen auf jedem Knoten und wird von allen gleichzeitig laufenden Jobs geteilt.
Für detailliertere Informationen können Sie die Ray v2 Architektur-Dokumentation einsehen.
Die Arbeit mit bestehenden Python-Anwendungen erfordert nicht viele Änderungen. Die erforderlichen Änderungen würden hauptsächlich die Funktion oder Klasse betreffen, die natürlich verteilt werden muss. Sie können einen Dekorator hinzufügen und es in Aufgaben oder Akteure umwandeln. Lassen Sie uns ein Beispiel dafür ansehen.
Eine Python-Funktion in eine Ray-Aufgabe umwandeln
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Eine Python-Klasse in einen Ray-Akteur umwandeln
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Informationen in Ray-Objekten speichern
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Um mehr über das Konzept zu erfahren, gehen Sie zu Ray Core Key Concept Doku.
Ray vs. traditioneller Ansatz der verteilten parallelen Verarbeitung
Nachfolgend finden Sie eine vergleichende Analyse zwischen dem traditionellen (ohne Ray) Ansatz und Ray auf Kubernetes, um verteilte parallele Verarbeitung zu ermöglichen.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Bereitstellung | Manuelle Einrichtung und Konfiguration | Automatisiert mit KubeRay-Operator |
| Skalierung | Manuelle Skalierung | Automatische Skalierung mit RayAutoScaler und Kubernetes |
| Fehlertoleranz | Benutzerdefinierte Fehlertoleranzmechanismen | Integrierte Fehlertoleranz mit Kubernetes und Ray |
| Ressourcenmanagement | Manuelle Ressourcenallokation | Automatisierte Ressourcenallokation und -verwaltung |
| Lastenausgleich | Benutzerdefinierte Lastenausgleichslösungen | Integrierte Lastverteilung mit Kubernetes |
| Abhängigkeitsmanagement | Manuelle Abhängigkeitsinstallation | Konsistente Umgebung mit Docker-Containern |
| Cluster-Koordination | Komplex und manuell | Vereinfachte Koordination mit Kubernetes-Service-Discovery |
| Entwicklungsaufwand | Hoch, mit benötigten individuellen Lösungen | Reduziert, da Ray und Kubernetes viele Aspekte übernehmen |
| Flexibilität | Begrenzte Anpassungsfähigkeit an sich ändernde Arbeitslasten | Hohe Flexibilität mit dynamischer Skalierung und Ressourcenallokation |
Kubernetes bietet eine ideale Plattform für den Betrieb verteilter Anwendungen wie Ray aufgrund seiner robusten Orchestrierungsfähigkeiten. Im Folgenden sind die wichtigsten Punkte aufgeführt, die den Wert des Betriebs von Ray auf Kubernetes festlegen:
- Ressourcenmanagement
- Skalierbarkeit
- Orchestrierung
- Integration mit dem Ökosystem
- Einfache Bereitstellung und Verwaltung
Der KubeRay Operator ermöglicht es, Ray auf Kubernetes auszuführen.
Was ist KubeRay?
Der KubeRay Operator vereinfacht das Management von Ray-Clustern auf Kubernetes, indem er Aufgaben wie Bereitstellung, Skalierung und Wartung automatisiert. Er verwendet Kubernetes Custom Resource Definitions (CRDs), um Ray-spezifische Ressourcen zu verwalten.
KubeRay CRDs
Es hat drei verschiedene CRDs:
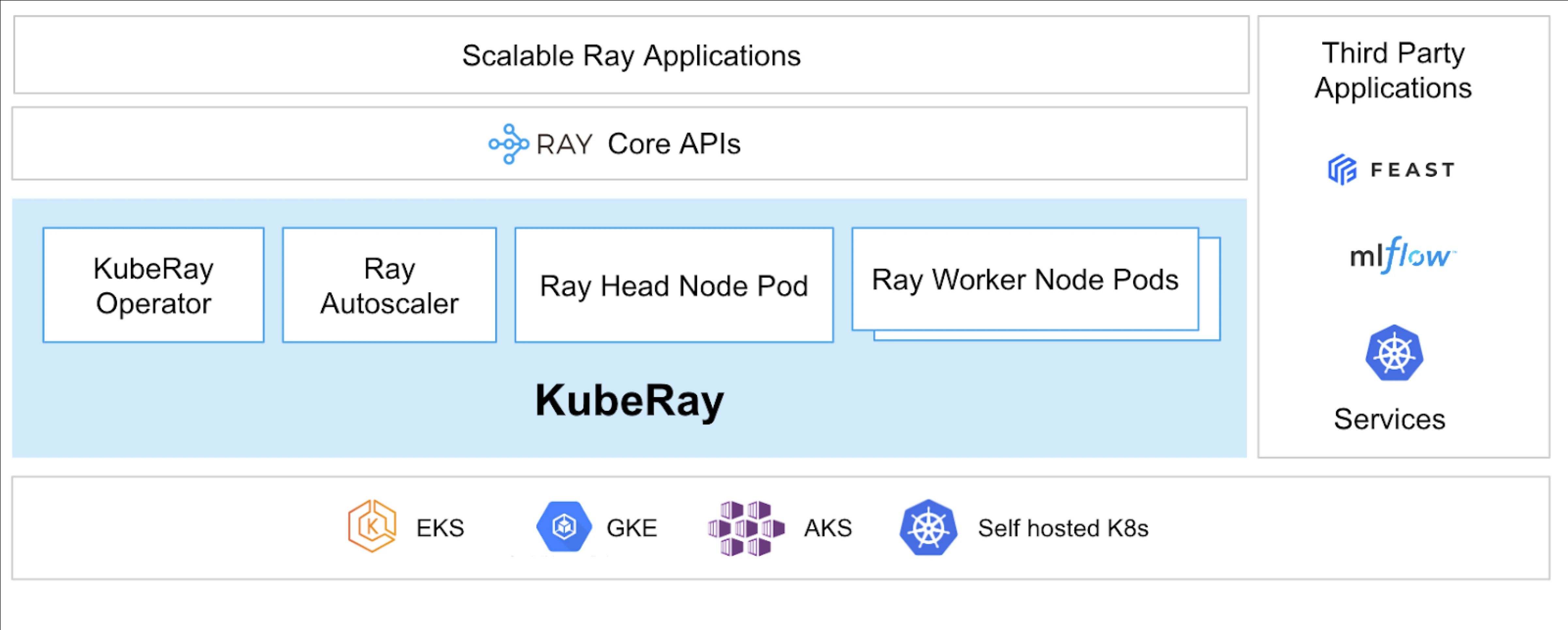
- RayCluster: Dieses CRD hilft, den Lebenszyklus von RayCluster zu verwalten und kümmert sich um AutoScaling basierend auf der definierten Konfiguration.
- RayJob: Es ist nützlich, wenn es einen einmaligen Job gibt, den Sie ausführen möchten, anstatt ständig einen Standby-RayCluster laufen zu lassen. Es erstellt einen RayCluster und reicht den Job ein, wenn er bereit ist. Sobald der Job abgeschlossen ist, wird der RayCluster gelöscht. Dies hilft, den RayCluster automatisch wiederzuverwerten.
- RayService: Dies erstellt ebenfalls einen RayCluster, aber deployt eine RayServe-Anwendung darauf. Dieses CRD ermöglicht es, In-Place-Updates der Anwendung durchzuführen, was null Ausfallzeiten bei Upgrades und Aktualisierungen gewährleistet, um die hohe Verfügbarkeit der Anwendung sicherzustellen.
Verwendungsfälle von KubeRay
Bereitstellung eines On-Demand-Modells mit RayService
RayService ermöglicht es Ihnen, Modelle nach Bedarf in einer Kubernetes-Umgebung bereitzustellen. Dies kann besonders nützlich für Anwendungen wie Bildgenerierung oder Textextraktion sein, bei denen Modelle nur bei Bedarf bereitgestellt werden.
Hier ist ein Beispiel für stabile Diffusion. Sobald es in Kubernetes angewendet wird, erstellt es RayCluster und führt auch einen RayService aus, der das Modell bereitstellt, bis Sie diese Ressource löschen. Es ermöglicht Benutzern, die Kontrolle über Ressourcen zu übernehmen.
Training eines Modells auf einem GPU-Cluster mit RayJob
RayService erfüllt verschiedene Anforderungen des Benutzers, indem es das Modell oder die Anwendung bereitstellt, bis sie manuell gelöscht wird. Im Gegensatz dazu ermöglicht RayJob einmalige Jobs für Anwendungsfälle wie das Trainieren eines Modells, das Vorverarbeiten von Daten oder Inferenz für eine feste Anzahl gegebener Eingaben.
Inference-Server auf Kubernetes mit RayService oder RayJob ausführen
Im Allgemeinen führen wir unsere Anwendung in Deployments aus, die die Rolling Updates ohne Ausfallzeiten aufrechterhalten. Ähnlich kann dies in KubeRay mit RayService erreicht werden, das das Modell oder die Anwendung bereitstellt und die Rolling Updates verwaltet.
Es könnte jedoch Fälle geben, in denen Sie nur Batch-Inferenz durchführen möchten, anstatt die Inferenzserver oder -anwendungen über längere Zeiträume auszuführen. Hier können Sie RayJob nutzen, das ähnlich wie die Kubernetes Job-Ressource funktioniert.
Batch-Inferenz zur Bildklassifizierung mit Huggingface Vision Transformer ist ein Beispiel für RayJob, das Batch-Inferenz durchführt.
Dies sind die Anwendungsfälle von KubeRay, die es Ihnen ermöglichen, mehr mit dem Kubernetes-Cluster zu tun. Mit Hilfe von KubeRay können Sie gemischte Workloads im selben Kubernetes-Cluster ausführen und die GPU-basierten Workload-Scheduling an Ray auslagern.
Fazit
Verteiltes paralleles Rechnen bietet eine skalierbare Lösung für die Bewältigung großangelegter, ressourcenintensiver Aufgaben. Ray vereinfacht die Komplexität des Aufbaus verteilter Anwendungen, während KubeRay Ray mit Kubernetes integriert, um eine nahtlose Bereitstellung und Skalierung zu ermöglichen. Diese Kombination verbessert die Leistung, Skalierbarkeit und Fehlertoleranz und macht sie ideal für Web-Crawling, Datenanalysen und maschinelles Lernen. Durch die Nutzung von Ray und KubeRay können Sie verteiltes Rechnen effizient verwalten und die Anforderungen der heutigen datengestützten Welt mühelos erfüllen.
Darüber hinaus wird es, da sich unsere Rechenressourcentypen von CPU zu GPU-basiert ändern, wichtig, eine effiziente und skalierbare Cloud-Infrastruktur für alle Arten von Anwendungen zu haben, sei es für KI oder große Datenverarbeitung.
Wenn Sie diesen Beitrag informativ und ansprechend fanden, würde ich gerne Ihre Gedanken dazu hören, also beginnen Sie ein Gespräch auf LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray