













Ihr Management möchte alles über die Finanzen und Produktivität Ihres Unternehmens wissen, gibt jedoch keinen Cent für erstklassige IT-Verwaltungstools aus? Verwenden Sie nicht verschiedene Tools für Inventar, Abrechnung und Ticketing. Sie benötigen nur ein zentrales System. Warum nicht Power BI Python in Betracht ziehen?
Power BI kann mühsame und zeitaufwendige Aufgaben automatisieren. In diesem Tutorial erfahren Sie, wie Sie Ihre Daten auf unvorstellbare Weise schneiden und kombinieren können.
Kommen Sie und ersparen Sie sich den Stress, komplexe Berichte manuell zu durchsuchen!
Voraussetzungen
Dieses Tutorial ist eine praktische Demonstration. Wenn Sie mitmachen möchten, stellen Sie sicher, dass Sie Folgendes haben:
- Power BI-Abonnement – Die kostenlose Testversion ist ausreichend.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Power BI Desktop auf Ihrem Windows Server installiert – Dieses Tutorial verwendet Power BI Desktop v2.105.664.0.
- MySQL Server installiert – Dieses Tutorial verwendet MySQL Server v8.0.29.
- Ein on-premises data gateway auf externen Geräten installiert, die eine Desktop-Version verwenden möchten.
- Visual Studio Code (VS Code) – Dieses Tutorial verwendet VS Code v17.2
- Python v3.6 oder höher installiert – Dieses Tutorial verwendet Python v3.10.5.
- DBeaver installiert – Dieses Tutorial verwendet DBeaver v22.0.2.
Erstellung einer MySQL-Datenbank
Power BI kann Daten wunderschön visualisieren, aber Sie müssen sie abrufen und speichern, bevor Sie mit der Visualisierung der Daten beginnen können. Eine der besten Möglichkeiten, Daten zu speichern, ist in einer Datenbank. MySQL ist ein kostenloses und leistungsstarkes Datenbanktool.
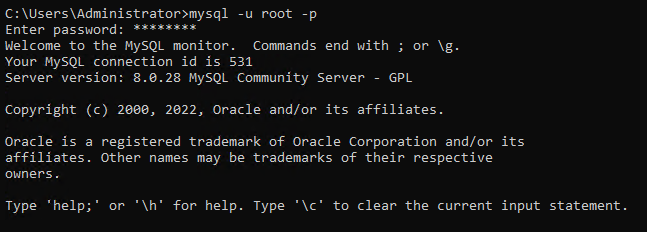
1. Öffnen Sie die Eingabeaufforderung als Administrator, führen Sie den untenstehenden MySQL-Befehl aus und geben Sie den Root-Benutzernamen (-u) und das Passwort (-p) ein, wenn Sie dazu aufgefordert werden.
Standardmäßig hat nur der Root-Benutzer die Berechtigung, Änderungen an der Datenbank vorzunehmen.
2. Als nächstes führen Sie die unten stehende Abfrage aus, um einen neuen Datenbankbenutzer (CREATE USER) mit einem Passwort (IDENTIFIED BY) zu erstellen. Sie können dem Benutzer einen anderen Namen geben, aber die Wahl dieses Tutorials ist ata_levi.

3. Nachdem Sie einen Benutzer erstellt haben, führen Sie die unten stehende Abfrage aus, um dem neuen Benutzer Berechtigungen zu erteilen (ALL PRIVILEGES), z. B. das Erstellen einer Datenbank auf dem Server.

4. Führen Sie nun die \q-Befehl unten aus, um sich bei MySQL abzumelden.

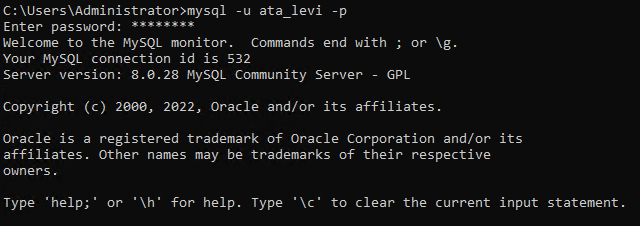
5. Führen Sie die unten stehende MySQL-Befehl aus, um sich als der neu erstellte Datenbankbenutzer (ata_levi) anzumelden.
6. Führen Sie schließlich die folgende Abfrage aus, um eine neue DATENBANK namens ata_database zu erstellen. Natürlich können Sie der Datenbank einen anderen Namen geben.

Verwalten von MySQL-Datenbanken mit DBeaver
Bei der Verwaltung von Datenbanken benötigen Sie normalerweise SQL-Kenntnisse. Mit DBeaver haben Sie jedoch eine grafische Benutzeroberfläche, um Ihre Datenbanken mit wenigen Klicks zu verwalten, und DBeaver kümmert sich um die SQL-Anweisungen für Sie.
1. Öffnen Sie DBeaver von Ihrem Desktop oder dem Startmenü.
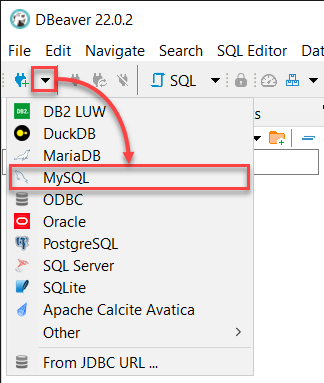
2. Wenn DBeaver geöffnet ist, klicken Sie auf das Dropdown-Menü für Neue Datenbankverbindung und wählen Sie MySQL, um eine Verbindung zu Ihrem MySQL-Server herzustellen.
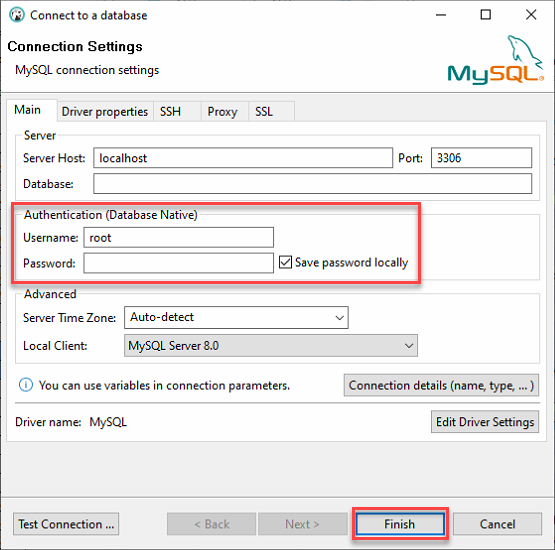
3. Melden Sie sich bei Ihrem lokalen MySQL-Server an mit folgenden Einstellungen:
- Behalten Sie den Server Host als localhost und Port auf 3306, da Sie sich mit einem lokalen Server verbinden.
- Geben Sie die Anmeldedaten des Benutzers ata_levi (Benutzername und Passwort) aus Schritt zwei des Abschnitts „Erstellen einer MySQL-Datenbank“ ein und klicken Sie auf Fertig, um sich bei MySQL anzumelden.
4. Erweitern Sie nun Ihre Datenbank (ata_database) unter dem Datenbanknavigator (linkes Panel) → klicken Sie mit der rechten Maustaste auf Tabellen und wählen Sie Neue Tabelle erstellen, um das Erstellen einer neuen Tabelle zu initiieren.
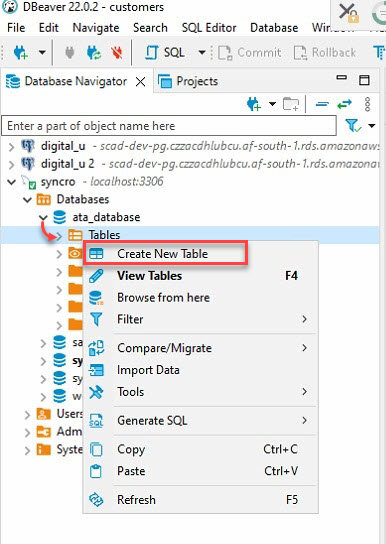
5. Benennen Sie Ihre neue Tabelle, aber die Wahl dieses Tutorials ist ata_Table, wie unten gezeigt.
Stellen Sie sicher, dass der Tabellenname mit dem Tabellennamen übereinstimmt, den Sie in Schritt sieben des Abschnitts „API-Daten abrufen und verarbeiten“ auf die to_sql („Tabellenname“)-Methode angeben werden.
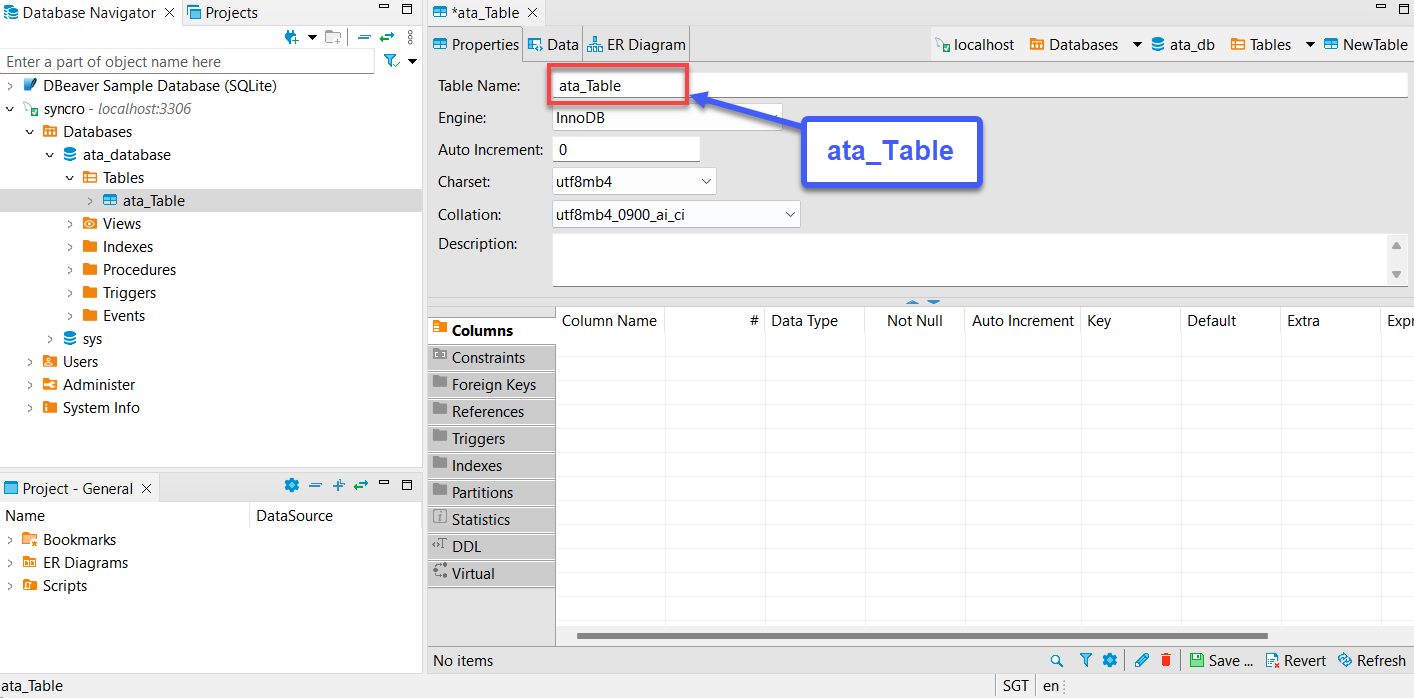
6. Erweitern Sie anschließend die neue Tabelle (ata_table) → klicken Sie mit der rechten Maustaste auf Spalten → Neue Spalte erstellen, um eine neue Spalte zu erstellen.
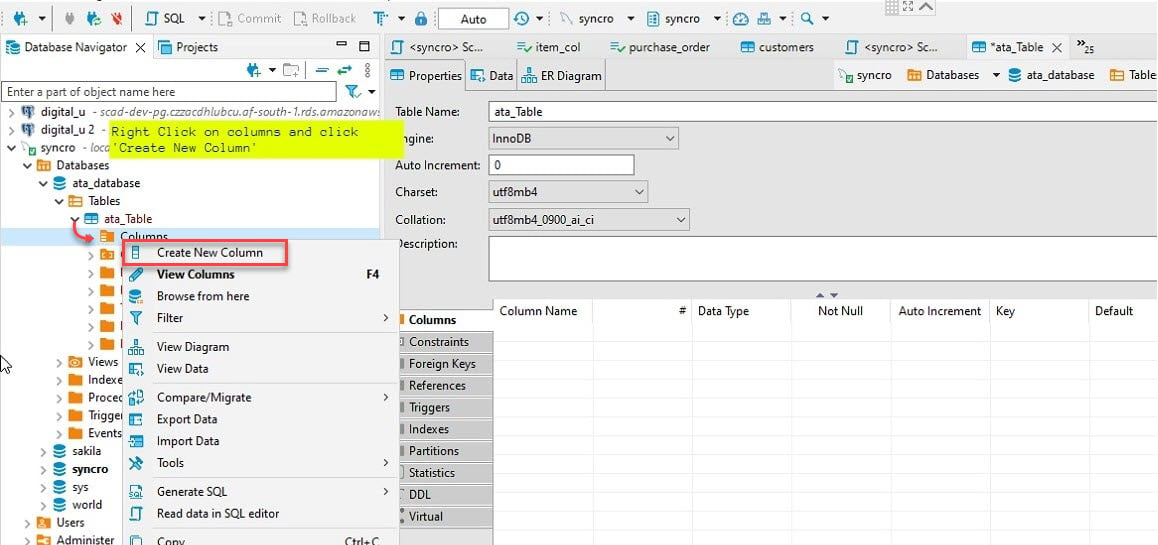
7. Geben Sie einen Spaltennamen an, wie unten gezeigt, aktivieren Sie das Kontrollkästchen Nicht Null und klicken Sie auf OK, um die neue Spalte zu erstellen.
Idealerweise möchten Sie eine Spalte mit dem Namen „id“ hinzufügen. Warum? Die meisten APIs haben eine ID, und das Pandas-Datenrahmen von Python füllt automatisch die anderen Spalten.
8. Klicken Sie auf Speichern (unten rechts) oder drücken Sie Strg+S, um die Änderungen zu speichern, sobald Sie Ihre neu erstellte Spalte (id) überprüft haben, wie unten gezeigt.
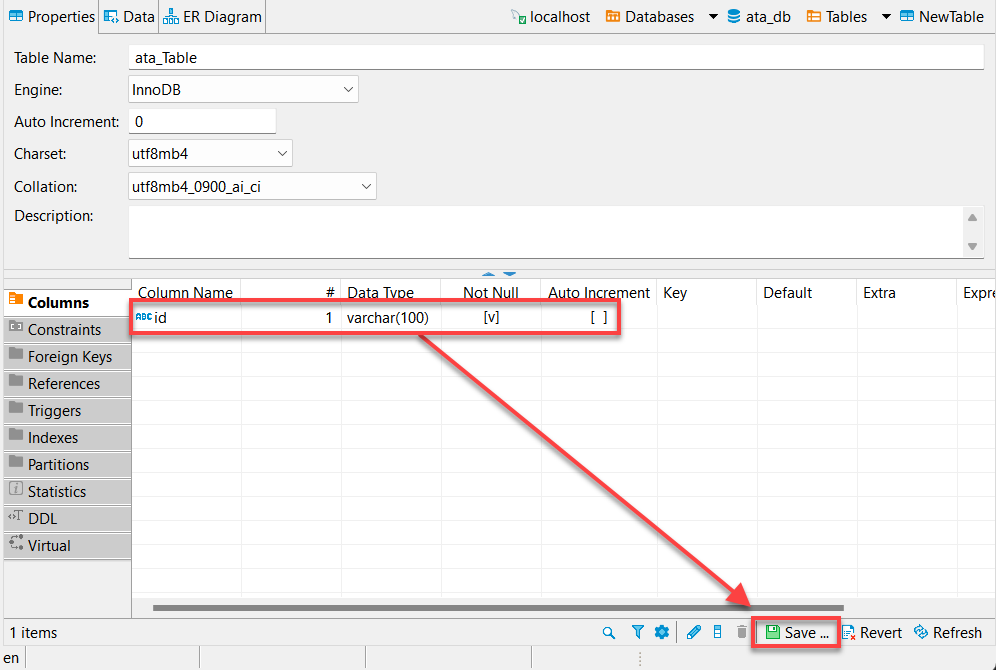
9. Klicken Sie abschließend auf Behalten, um die Änderungen, die Sie an der Datenbank vorgenommen haben, zu behalten.
Daten abrufen und verarbeiten API-Daten
Jetzt, da Sie die Datenbank zum Speichern von Daten erstellt haben, müssen Sie die Daten von Ihrem jeweiligen API-Anbieter abrufen und sie mithilfe von Python in Ihre Datenbank schieben. Sie werden Ihre Datenquelle für die Visualisierung in Power BI verwenden.
Um eine Verbindung zu Ihrem API-Anbieter herzustellen, benötigen Sie drei Schlüsselelemente; die Autorisierungsmethode, die API-Basis-URL und den API-Endpunkt. Wenn Sie unsicher sind, wie Sie diese Informationen erhalten oder wie Sie sie erhalten sollen, besuchen Sie die Dokumentationsseite Ihres API-Anbieters.
Im Folgenden finden Sie eine Dokumentationsseite von Syncro.
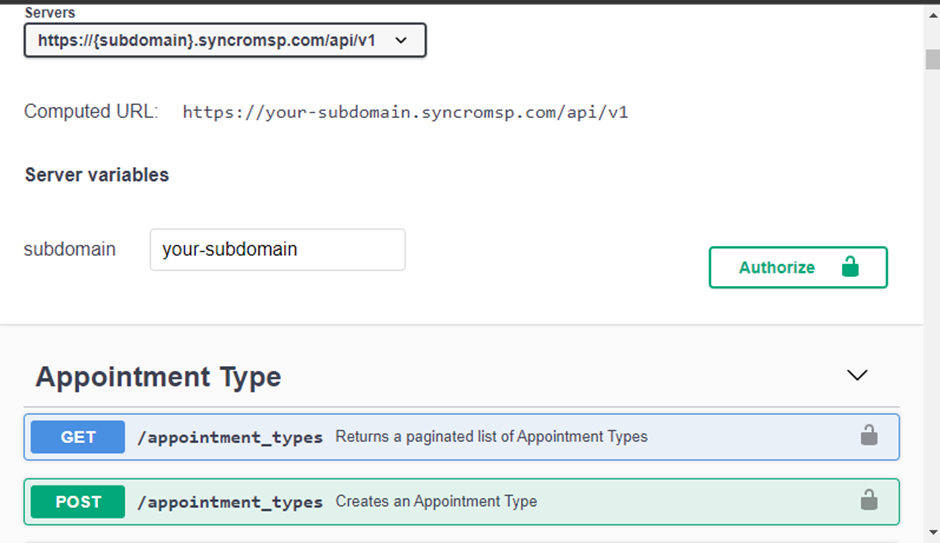
1. Öffnen Sie VS Code, erstellen Sie eine Python-Datei und benennen Sie die Datei entsprechend den erwarteten API-Daten aus der Datei. Diese Datei ist dafür verantwortlich, die API-Daten aus der Datenbank abzurufen und zu senden (Datenbankverbindung).
Es stehen mehrere Python-Bibliotheken zur Verfügung, um bei der Datenbankverbindung zu helfen, aber Sie werden in diesem Tutorial SQLAlchemy verwenden.
Führen Sie den folgenden Pip-Befehl in der VS Code-Terminal aus, um SQLAlchemy in Ihrer Umgebung zu installieren.

2. Erstellen Sie als nächstes eine Datei mit dem Namen connection.py, füllen Sie den unten stehenden Code aus, ersetzen Sie die Werte entsprechend und speichern Sie die Datei.
Sobald Sie Skripte schreiben, um mit Ihrer Datenbank zu kommunizieren, muss eine Verbindung zur Datenbank hergestellt werden, bevor die Datenbank einen Befehl akzeptiert.
Aber anstatt die Verbindungszeichenfolge zur Datenbank für jedes Skript neu zu schreiben, ist der folgende Code dafür gedacht, diese Verbindung herzustellen, um von anderen Skripten aufgerufen/referenziert zu werden.
3. Öffnen Sie das Terminal von Visual Studio (Strg+Umschalt+`), und führen Sie die unten stehenden Befehle aus, um pandas und requests zu installieren.
4. Erstellen Sie eine weitere Python-Datei namens invoices.py (oder benennen Sie sie anders) und fügen Sie den unten stehenden Code in die Datei ein.
Sie werden auf jedem nachfolgenden Schritt Codeausschnitte zur Datei invoices.py hinzufügen, aber den vollständigen Code auf GitHub von ATA anzeigen können.
Das Skript invoices.py wird aus dem im folgenden Abschnitt beschriebenen Hauptskript ausgeführt, das Ihre ersten API-Daten abruft.
Der unten stehende Code führt folgendes aus:
- Ruft Daten von Ihrer API ab und schreibt sie in Ihre Datenbank.
- Ersetzt die Autorisierungsmethode, den Schlüssel, die Basis-URL und die API-Endpunkte durch Ihre API-Anbieter-Anmeldeinformationen.
5. Fügen Sie den unten stehenden Codeausschnitt zur invoices.py-Datei hinzu, um die Header zu definieren, beispielsweise:
- Das Datentyp-Format, das Sie von Ihrer API erwarten.
- Die Basis-URL und der Endpunkt sollten die Autorisierungsmethode und den entsprechenden Schlüssel begleiten.
Achten Sie darauf, die unten stehenden Werte durch Ihre eigenen zu ersetzen.
6. Fügen Sie als Nächstes die folgende asynchrone Funktion zur Datei invoices.py hinzu.
Der unten stehende Code verwendet AsyncIO, um Ihre mehreren Skripte von einem Hauptskript aus zu verwalten, das im folgenden Abschnitt behandelt wird. Wenn Ihr Projekt wächst und mehrere API-Endpunkte umfasst, ist es ratsam, dass Ihre Skripte zur API-Verarbeitung ihre eigenen Dateien haben.
7. Fügen Sie schließlich den unten stehenden Code zur Datei invoices.py hinzu, wobei eine Funktion get_pages die Paginierung Ihrer API behandelt.
Diese Funktion gibt die Gesamtzahl der Seiten in Ihrer API zurück und hilft der range-Funktion dabei, alle Seiten zu durchlaufen.
Kontaktieren Sie die Entwickler Ihrer API bezüglich der Paginierungsmethode, die von Ihrem API-Anbieter verwendet wird.
Wenn Sie weitere API-Endpunkte zu Ihren Daten hinzufügen möchten:
- Wiederholen Sie die Schritte vier bis sechs des Abschnitts „Verwalten von MySQL-Datenbanken mit DBeaver“.
- Wiederholen Sie alle Schritte unter dem Abschnitt „Abrufen und Verbrauchen von API-Daten“.
- Ändern Sie den API-Endpunkt in einen anderen, den Sie verbrauchen möchten.
API-Endpunkte synchronisieren
Sie haben jetzt eine Datenbank- und API-Verbindung und sind bereit, mit dem Verbrauch der API zu beginnen, indem Sie den Code in der Datei invoices.py ausführen. Wenn Sie dies tun, sind Sie jedoch darauf beschränkt, gleichzeitig einen API-Endpunkt zu verbrauchen.
Wie man über das Limit hinausgeht? Sie erstellen eine weitere Python-Datei als zentrale Datei, die API-Funktionen aus verschiedenen Python-Dateien aufruft und die Funktionen asynchron mit AsyncIO ausführt. Auf diese Weise halten Sie Ihren Programmcode sauber und ermöglichen das Bündeln mehrerer Funktionen.
1. Erstellen Sie eine neue Python-Datei namens central.py und fügen Sie den untenstehenden Code hinzu.
Ähnlich wie in der Datei invoices.py fügen Sie auf jedem Schritt Code-Snippets zur Datei central.py hinzu, den vollständigen Code können Sie jedoch auf ATA’s GitHub einsehen.
Der folgende Code importiert wichtige Module und Skripte aus anderen Dateien mit der Syntax from <filename> import <function name>.
2. Fügen Sie nun den folgenden Code hinzu, um die Skripte aus invoices.py in der Datei central.py zu steuern.
Sie müssen die Funktion call_invoices aus invoices.py als AsyncIO-Aufgabe (invoice_task) in central.py aufrufen/referenzieren.
3. Nachdem Sie die AsyncIO-Aufgabe erstellt haben, warten Sie auf die Ausführung der Funktion „call_invoices“ aus der Datei invoice.py, sobald die Funktion „chain“ (im zweiten Schritt) gestartet wird.
4. Erstellen Sie einen AsyncIOScheduler, um einen Job für das Skript zu planen. Der in diesem Code hinzugefügte Job führt die Funktion „chain“ in Ein-Sekunden-Intervallen aus.
Dieser Job ist wichtig, um sicherzustellen, dass Ihr Programm Ihre Skripte ausführt und Ihre Daten aktuell hält.
5. Führen Sie schließlich das Skript central.py in VS Code aus, wie unten gezeigt.
Nach dem Ausführen des Skripts sehen Sie die Ausgabe auf der Konsole wie unten dargestellt.
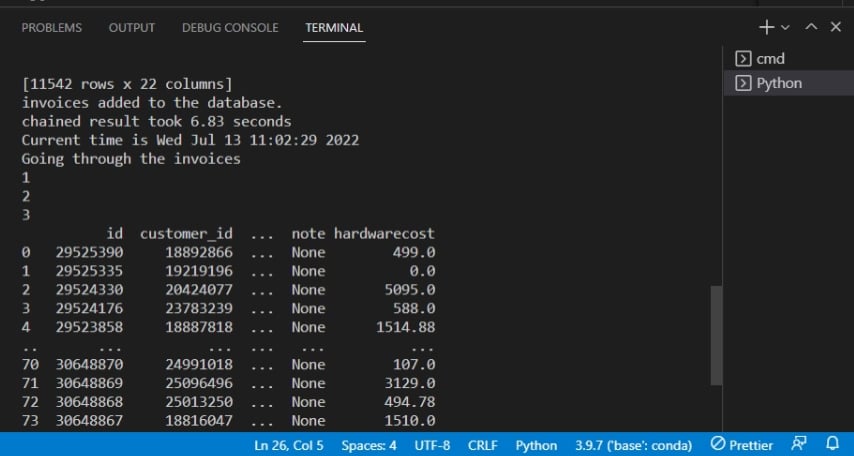
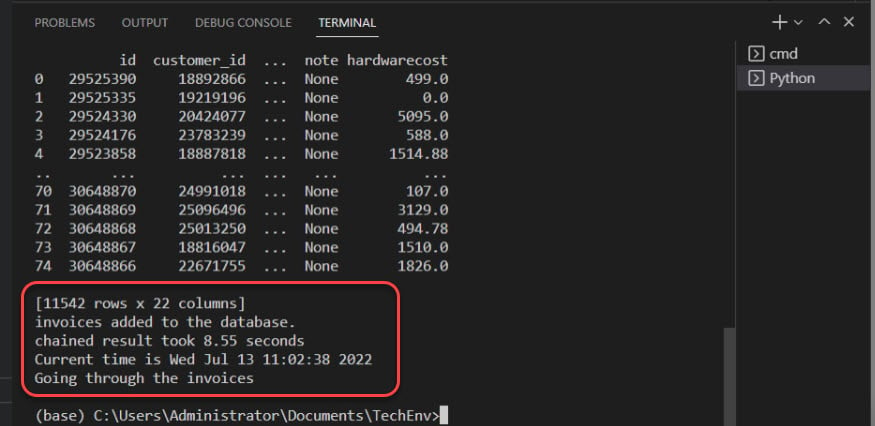
Unten bestätigt die Ausgabe, dass Rechnungen zur Datenbank hinzugefügt wurden.
Entwicklung von Power BI Visuals
Nachdem Sie ein Programm entwickelt haben, das eine Verbindung zur API herstellt, Daten konsumiert und diese Daten in eine Datenbank speichert, sind Sie fast bereit, Ihre Daten zu nutzen. Aber zuerst werden Sie die Daten in der Datenbank in Power BI für die Visualisierung nutzen, das Endziel.
Viele Daten sind nutzlos, wenn Sie sie nicht visualisieren und tiefe Verbindungen herstellen können. Glücklicherweise sind Power BI-Visuals ähnlich wie Graphen, mit denen komplizierte mathematische Gleichungen einfach und vorhersehbar erscheinen.
1. Öffnen Sie Power BI von Ihrem Desktop oder Startmenü aus.
2. Klicken Sie auf das Datensymbol über dem Dropdown-Menü „Daten abrufen“ im Hauptfenster von Power BI. Ein Pop-up-Fenster erscheint, in dem Sie die Datenquelle auswählen können (Schritt drei).
3. Suchen Sie nach MySQL, wählen Sie die MySQL-Datenbank aus und klicken Sie auf „Verbinden“, um eine Verbindung zu Ihrer MySQL-Datenbank herzustellen.
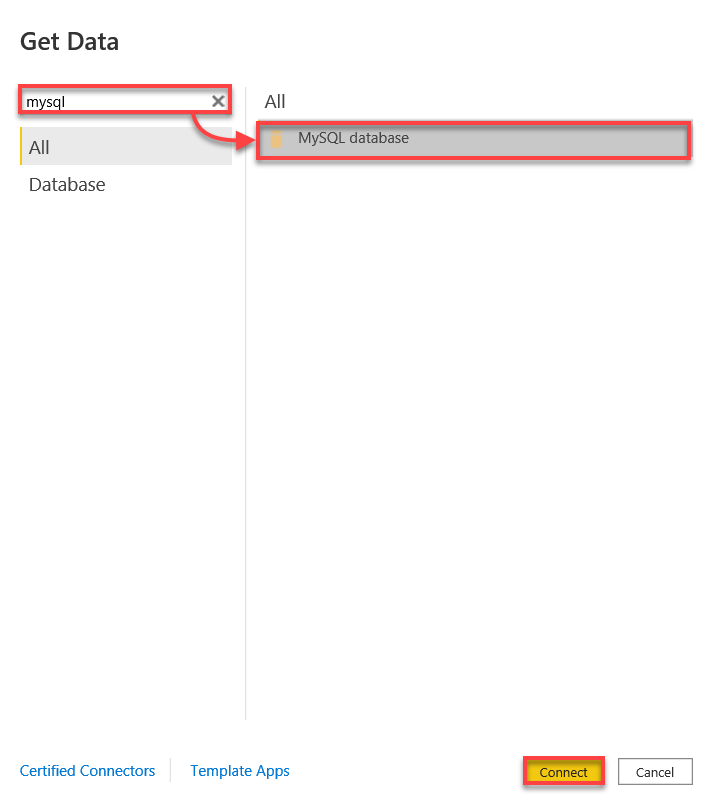
4. Stellen Sie nun eine Verbindung zu Ihrer MySQL-Datenbank her mit folgenden Einstellungen:
- Geben Sie localhost:3306 ein, da Sie sich mit Ihrem lokalen MySQL-Server auf Port 3306 verbinden.
- Geben Sie den Namen Ihrer Datenbank an, in diesem Fall ata_db.
- Klicken Sie auf OK, um sich mit Ihrer MySQL-Datenbank zu verbinden.

5. Klicken Sie nun auf „Daten transformieren“ (unten rechts), um eine Übersicht der Daten im Power BI Query Editor anzuzeigen (Schritt fünf).

6. Nachdem Sie die Datenquelle überprüft haben, klicken Sie auf „Schließen und übernehmen“, um zur Hauptanwendung zurückzukehren und zu bestätigen, ob Änderungen vorgenommen wurden.
Der Query Editor zeigt Tabellen Ihrer Datenquelle ganz links. Gleichzeitig können Sie das Format der Daten überprüfen, bevor Sie zur Hauptanwendung wechseln.
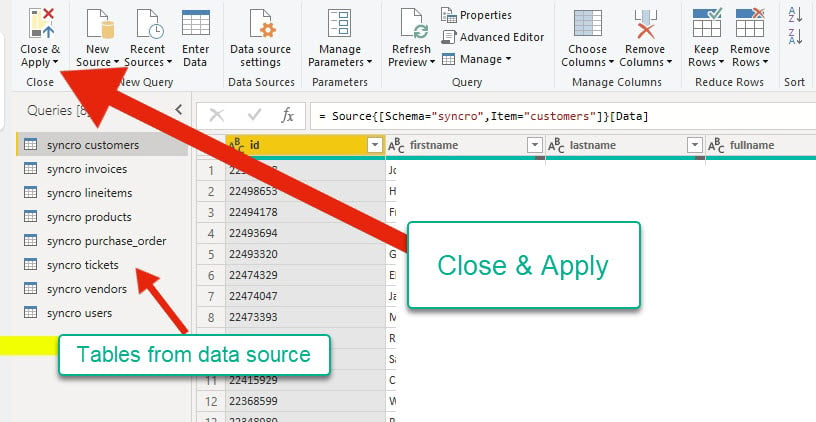
7. Klicken Sie auf das Register „Tabellentools“, wählen Sie eine Tabelle im Feldbereich aus und klicken Sie auf „Beziehungen verwalten“, um den Beziehungsassistenten zu öffnen.
Bevor Sie Visualisierungen erstellen, müssen Sie sicherstellen, dass Ihre Tabellen miteinander in Beziehung stehen. Warum? Power BI erkennt komplexe Tabellenkorrelationen noch nicht automatisch.

8. Aktivieren Sie die Kontrollkästchen der vorhandenen Beziehungen zum Bearbeiten und klicken Sie auf „Bearbeiten“. Ein Pop-up-Fenster erscheint, in dem Sie die ausgewählten Beziehungen bearbeiten können (Schritt neun).
Aber wenn Sie lieber eine neue Beziehung hinzufügen möchten, klicken Sie stattdessen auf Neu.
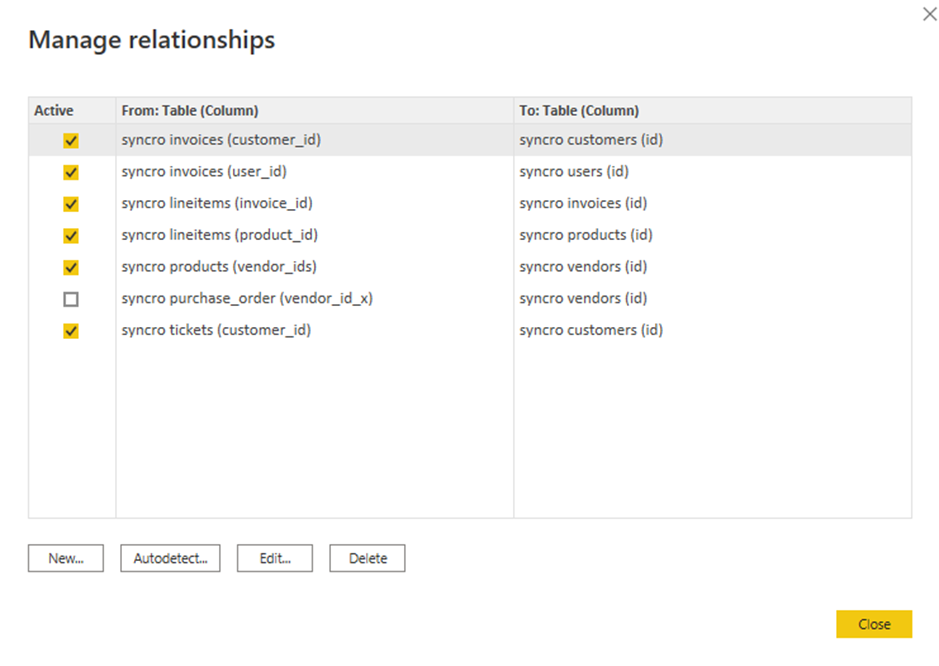
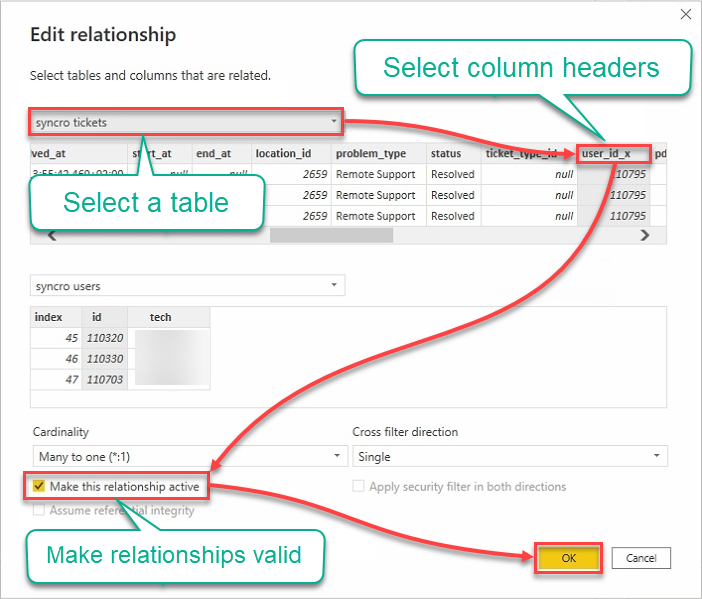
9. Bearbeiten Sie Beziehungen mit den folgenden:
- Klicken Sie auf das Dropdown-Feld „Tabellen“ und wählen Sie eine Tabelle aus.
- Klicken Sie auf die Überschriften, um die zu verwendenden Spalten auszuwählen.
- Aktivieren Sie das Kontrollkästchen Diese Beziehung aktivieren, um sicherzustellen, dass die Beziehungen gültig sind.
- Klicken Sie auf OK, um die Beziehung herzustellen und das Fenster „Beziehung bearbeiten“ zu schließen.
10. Klicken Sie nun auf den Tabellentyp unter dem Bereich „Visualisierungen“ (ganz rechts), um Ihre erste Visualisierung zu erstellen, und es erscheint eine leere Tabellenvisualisierung (Schritt 11).
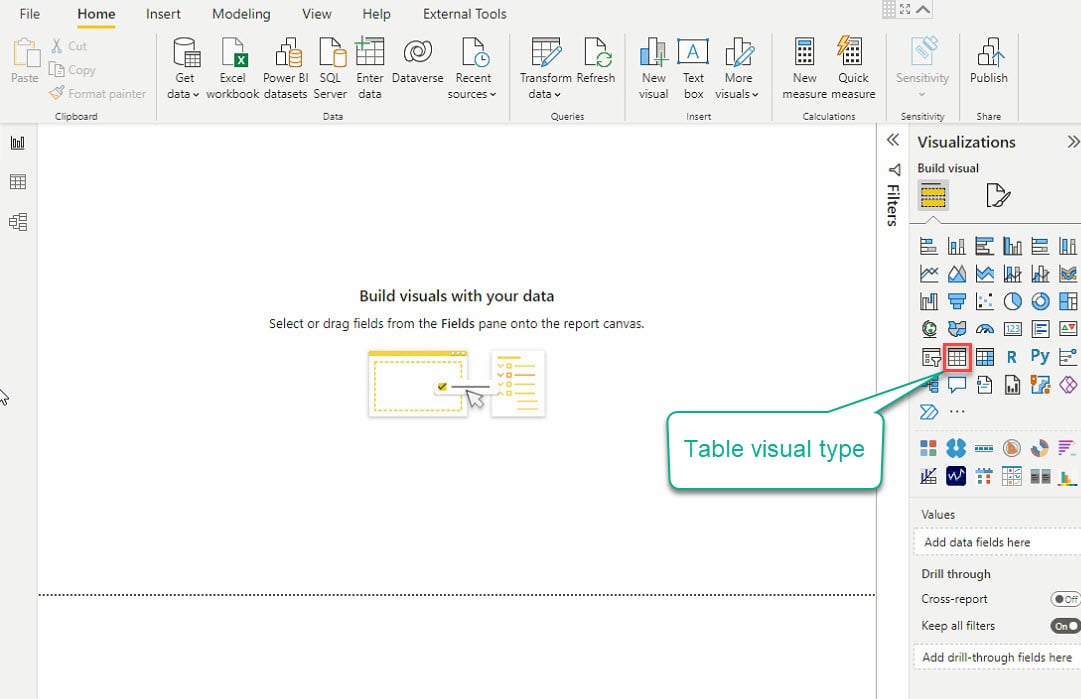
11. Wählen Sie die Tabellenvisualisierung und die Datenfelder (im Bereich „Felder“), die Sie Ihrer Tabellenvisualisierung hinzufügen möchten, wie unten gezeigt.
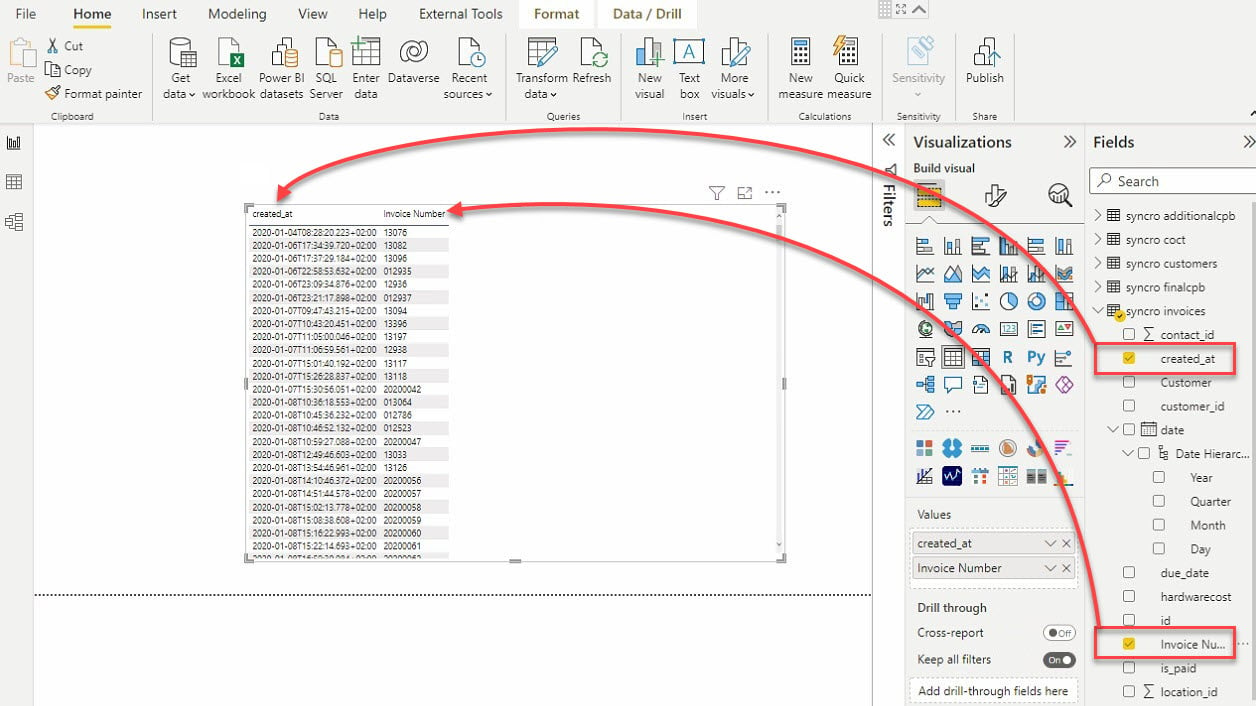
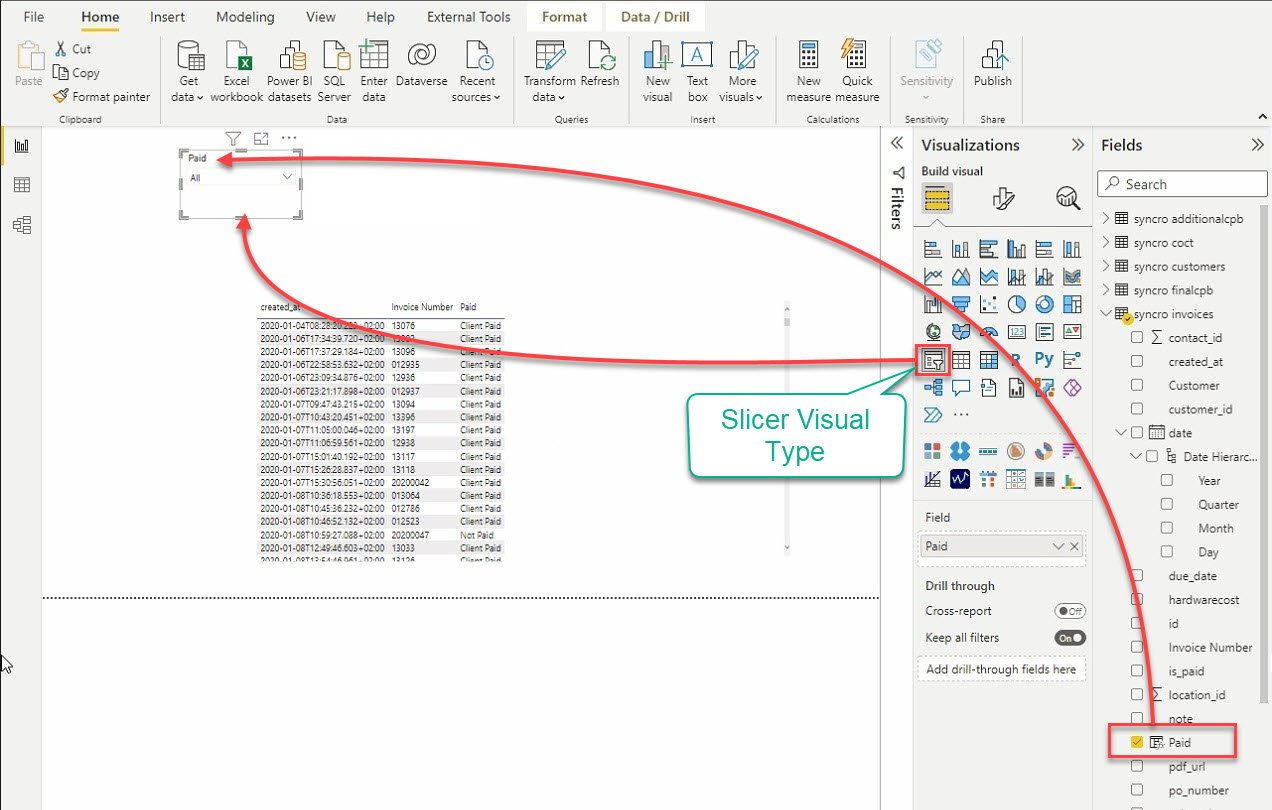
12. Klicken Sie schließlich auf den Schieberegler-Visualisierungstyp, um eine weitere Visualisierung hinzuzufügen. Wie der Name schon sagt, schneidet die Schieberegler-Visualisierung Daten durch Filtern anderer Visualisierungen.
Nachdem Sie den Schieberegler hinzugefügt haben, wählen Sie Daten aus dem Bereich „Felder“, die Sie der Schieberegler-Visualisierung hinzufügen möchten.
Ändern von Visualisierungen
Die Standardansichten der Visualisierungen sind ziemlich ansehnlich. Aber wäre es nicht großartig, wenn Sie die Optik der Visualisierungen auf etwas weniger langweiliges ändern könnten? Lassen Sie Power BI das für Sie erledigen.
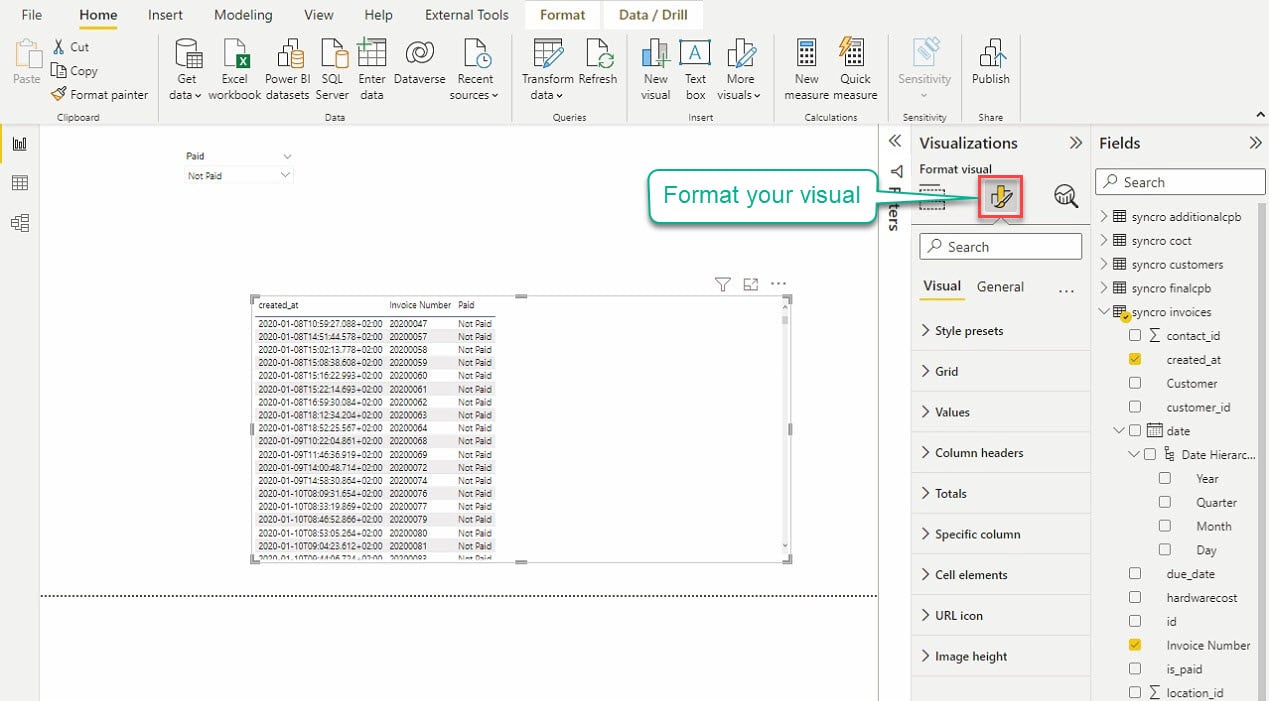
Klicken Sie auf das Symbol Ihre Visualisierung formatieren unter „Visualisierung“, um den Visualisierungseditor aufzurufen, wie unten gezeigt.
Verbringen Sie einige Zeit damit, mit den Einstellungen für die Visualisierung zu spielen, um das gewünschte Aussehen für Ihre Visualisierungen zu erhalten. Ihre Visualisierungen werden in Beziehung zueinander stehen, solange Sie eine Beziehung zwischen den Tabellen herstellen, die Sie in Ihre Visualisierungen einbeziehen.
Nachdem Sie die Visualisierungseinstellungen geändert haben, können Sie Berichte wie die folgenden abrufen.
Jetzt können Sie Ihre Daten visualisieren und analysieren, ohne Komplexität oder Belastung für Ihre Augen.
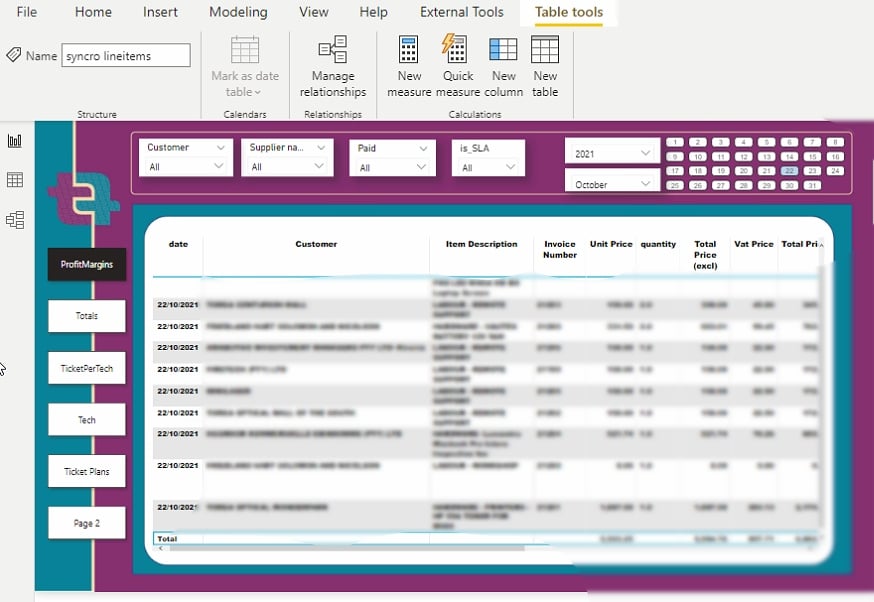
In der folgenden Visualisierung, beim Betrachten des Trenddiagramms, werden Sie feststellen, dass im April 2020 etwas schief gelaufen ist. Zu dieser Zeit trafen die anfänglichen Covid-19-Sperrungen Südafrika.
Dieser Output beweist nur die Kompetenz von Power BI bei der Bereitstellung präziser Datenvisualisierungen.

Schlussfolgerung
Dieses Tutorial zielt darauf ab, Ihnen zu zeigen, wie Sie eine lebendige, dynamische Datenpipeline aufbauen können, indem Sie Ihre Daten von API-Endpunkten abrufen. Zusätzlich verarbeiten und übertragen Sie Daten in Ihre Datenbank und Power BI mithilfe von Python. Mit diesem neuen Wissen können Sie nun API-Daten verbrauchen und Ihre eigenen Datenvisualisierungen erstellen.
Immer mehr Unternehmen erstellen Restful-API-Web-Apps. Und zu diesem Zeitpunkt sind Sie nun zuversichtlich darin, APIs mit Python zu verbrauchen und Datenvisualisierungen mit Power BI zu erstellen, was dazu beitragen kann, Geschäftsentscheidungen zu beeinflussen.