













Das Umwandeln Ihrer Rohdaten in organisierte und handlungsfähige Informationen mag komplex klingen. Nun, nicht wenn Sie eine schnelle und effiziente Lösung haben. Keine Sorge! Dieses anfängerfreundliche AWS Glue Tutorial steht Ihnen zur Seite.
In diesem Tutorial lernen Sie die entscheidenden Schritte zur Konfiguration und Ausführung von Daten-Transformationen mit AWS Glue.
Erkunden und optimieren Sie die Datenbereitstellung für Cloud-basierte Analysen!
Voraussetzungen
Bevor Sie mit AWS Glue arbeiten, stellen Sie sicher, dass Sie über ein aktives Amazon Web Services (AWS) Konto mit aktivierter Abrechnung verfügen. Ein kostenloses Konto reicht für dieses Tutorial aus.
Erstellen einer IAM-Rolle für AWS Glue
Bevor Sie einen Transformations-Job ausführen können, müssen Sie eine Identity and Access Management (IAM) Rolle erstellen, die der AWS Glue Service berechtigt. Diese Rolle definiert, auf welche Ressourcen AWS Glue in Ihrem AWS-Konto zugreifen darf.
Folgen Sie den nachstehenden Schritten, um die IAM-Rolle zu erstellen:
1. Öffnen Sie Ihren bevorzugten Webbrowser und melden Sie sich bei der AWS Management Console an.
2. Suchen Sie in der Ergebnisliste nach IAM und wählen Sie es aus, um auf die IAM-Konsole zuzugreifen.
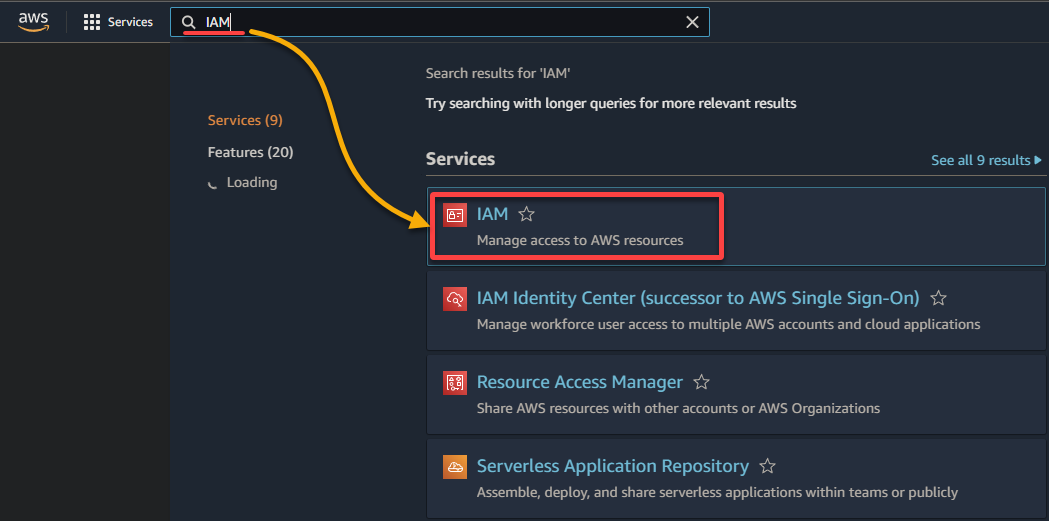
3. Navigieren Sie in der IAM-Konsole zu Rollen (linke Seite) und klicken Sie auf Rolle erstellen (oben rechts), um Ihren Browser auf eine neue Seite umzuleiten, die der Konfiguration der Rolle gewidmet ist.

4. Konfigurieren Sie nun die folgenden Einstellungen für die Rolle:
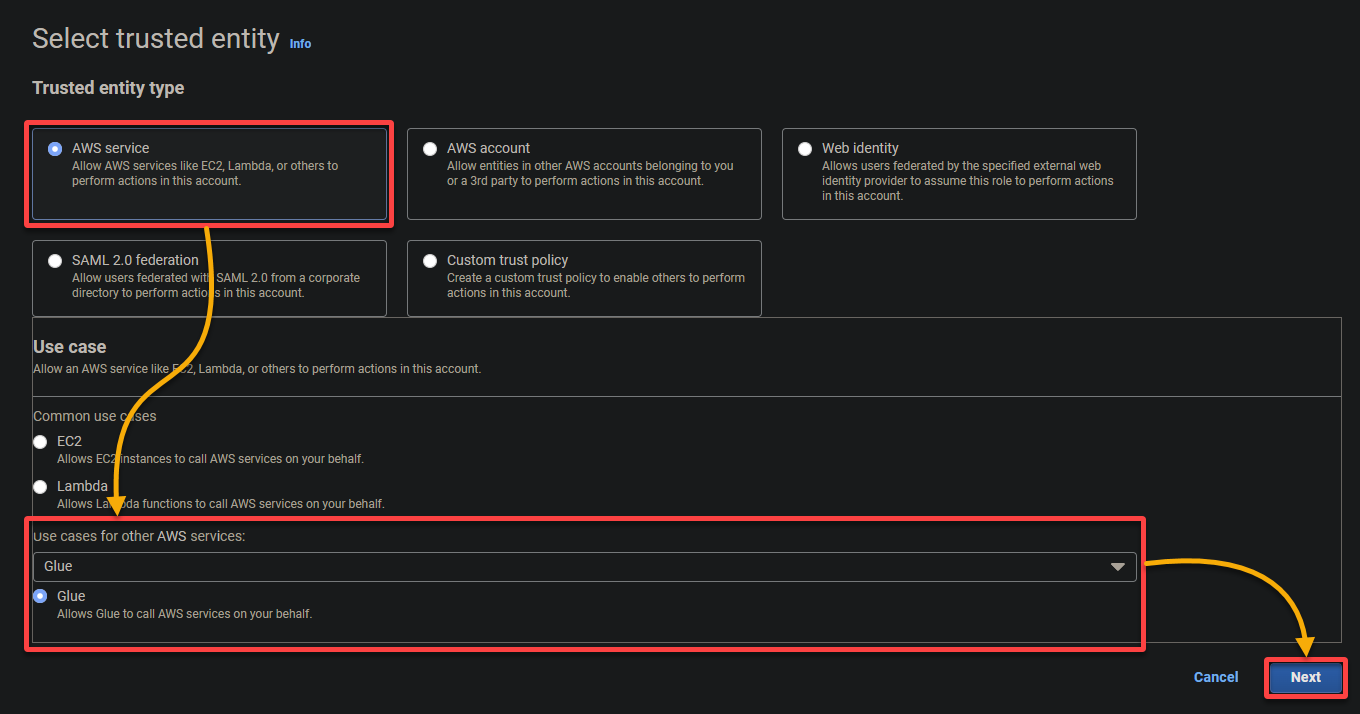
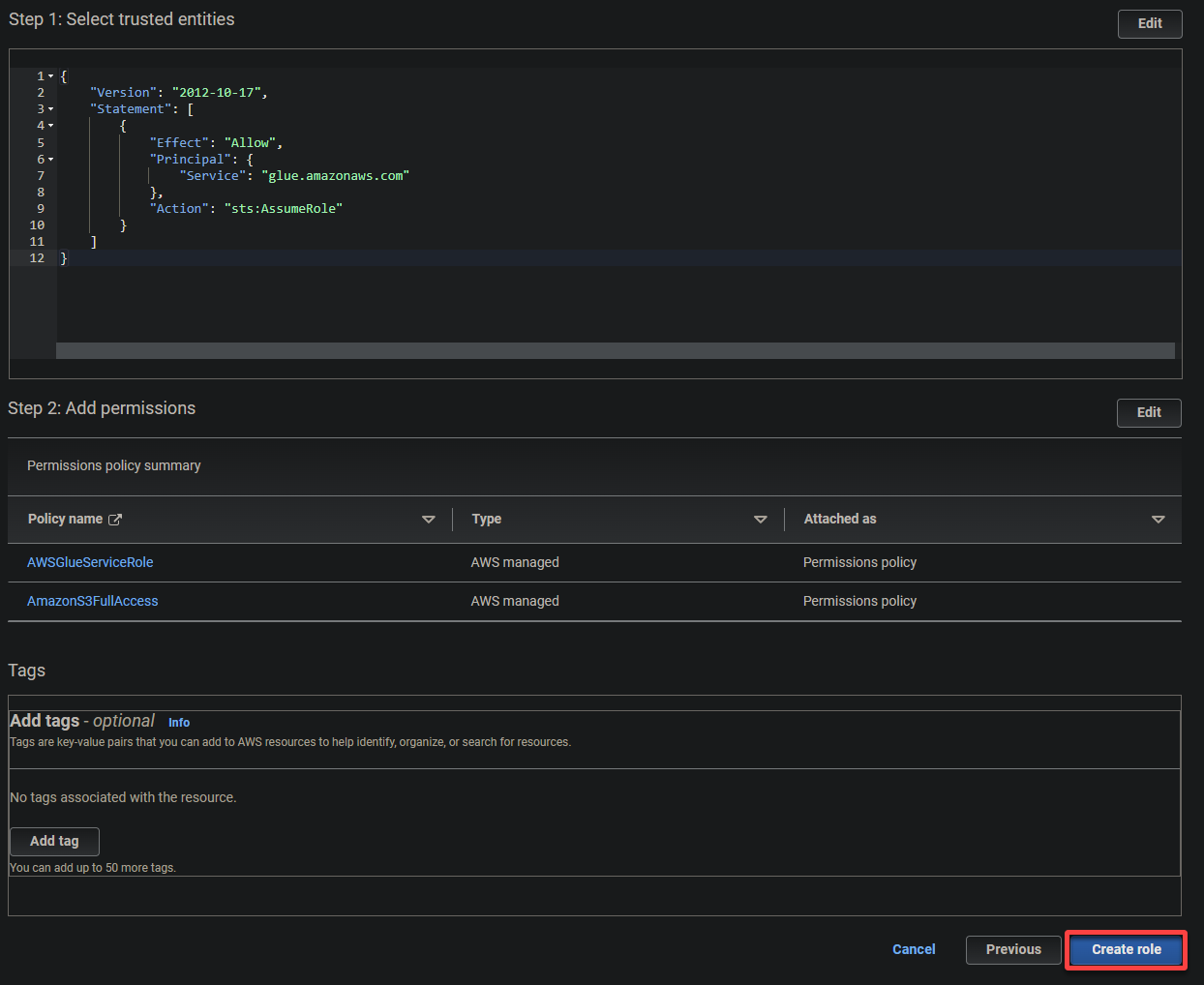
- Vertrauenswürdiger Entitätstyp – Wählen Sie AWS-Dienst, damit ein AWS-Dienst der Rolle vertraut. Dadurch kann dieser Dienst die Rolle übernehmen und in Ihrem Namen handeln.
- Anwendungsfall – Wählen Sie unter der Rubrik Anwendungsfälle für andere AWS-Dienste Glue aus, da Sie die IAM-Rolle speziell für AWS Glue erstellen werden, und klicken Sie auf Weiter.
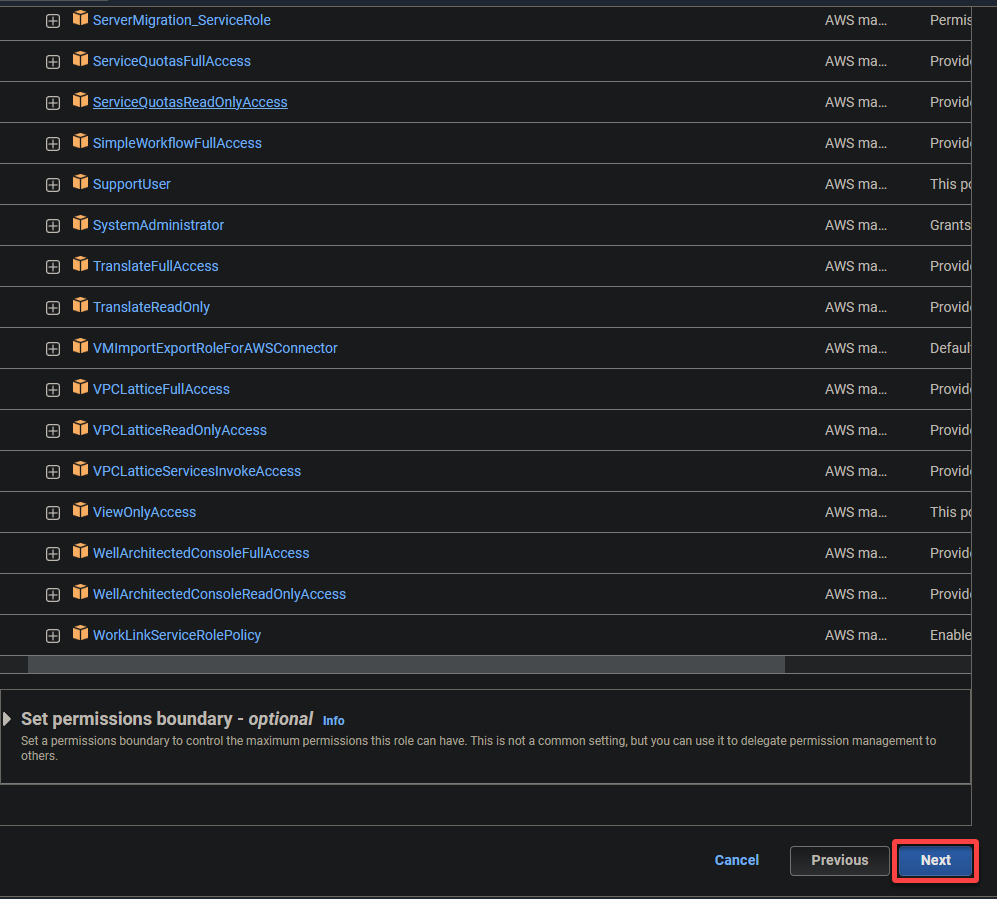
5. Suchen Sie die folgenden Richtlinien und wählen Sie sie aus, und klicken Sie auf Weiter.
- AWSGlueServiceRole – Gewährt dem AWS Glue-Dienst die erforderlichen Berechtigungen für seine Operationen.
- S3FullAccess – Gewährt vollen Zugriff auf die S3-Ressourcen und ermöglicht es AWS Glue, auf S3-Buckets zuzugreifen und in diese zu schreiben.
AWS Glue benötigt umfangreiche Berechtigungen, um ETL-Aufgaben (Extraktion, Transformation und Laden) effektiv in S3-Buckets durchführen zu können.
? Vermeiden Sie die Gewährung unnötiger übermäßiger Berechtigungen, da diese Sicherheitsrisiken darstellen können.
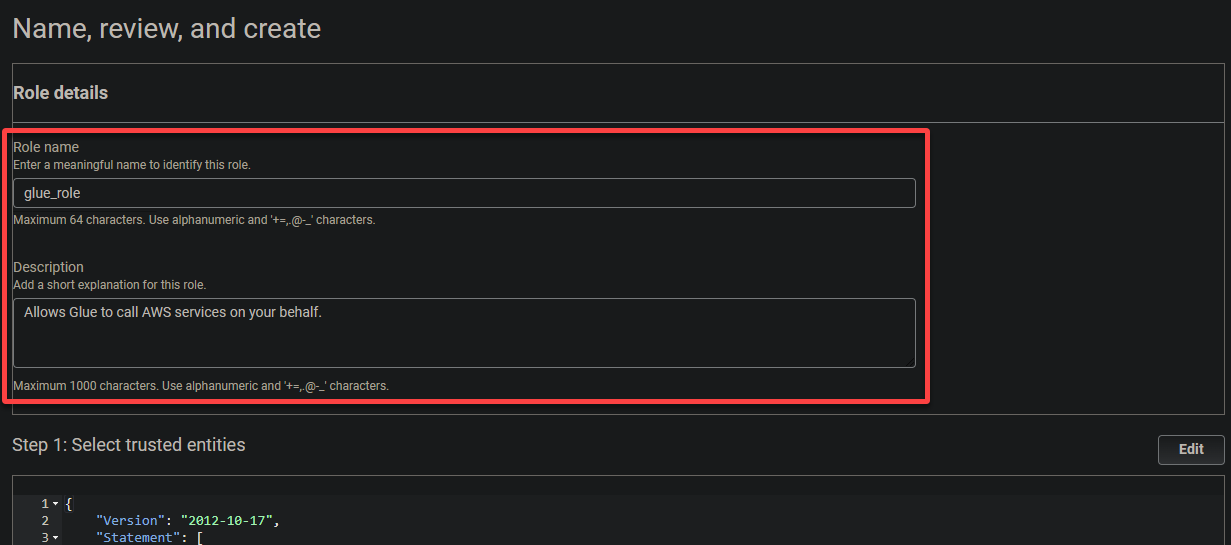
6. Geben Sie einen aussagekräftigen Namen für die Rolle (z.B. glue_role) und eine Beschreibung an.
7. Scrollen Sie schließlich nach unten, überprüfen Sie Ihre Einstellungen und klicken Sie auf Rolle erstellen (unten rechts), um die Erstellung der Rolle abzuschließen.
Erstellen eines S3-Buckets und Hochladen einer Beispieldatei
Da Sie nun eine IAM-Rolle für AWS Glue haben, benötigen Sie einen Ort, um Ihre Daten zu speichern, genauer gesagt, einen S3-Bucket. Ein S3-Bucket bietet einen zentralen Speicherort für die Daten, die von AWS Glue verarbeitet werden.
In diesem Beispiel wird AWS Glue AWS S3 als Datenspeicher für verschiedene Operationen wie Datenextraktion, Transformation und Laden (ETL) verwenden.
Um einen S3-Bucket zu erstellen und eine Beispieldatei hochzuladen, befolgen Sie diese Schritte:
1. Laden Sie eine Beispieldatei (z.B. Every Politician-Datensatz) auf Ihren lokalen Computer herunter. Diese Datei enthält eine unstrukturierte Sammlung von Datensätzen, die als Eingabe für den AWS Glue-Transformationsjob dienen.
2. Suchen und wählen Sie den S3-Dienst aus, um auf die S3-Konsole zuzugreifen.
3. Klicken Sie auf Einen Bucket erstellen, um die Erstellung eines neuen S3-Buckets zu starten.

4. Geben Sie nun einen eindeutigen Namen für Ihren Bucket ein (z.B. sampledata54675) und wählen Sie die Region aus, in der der Bucket erstellt werden soll.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
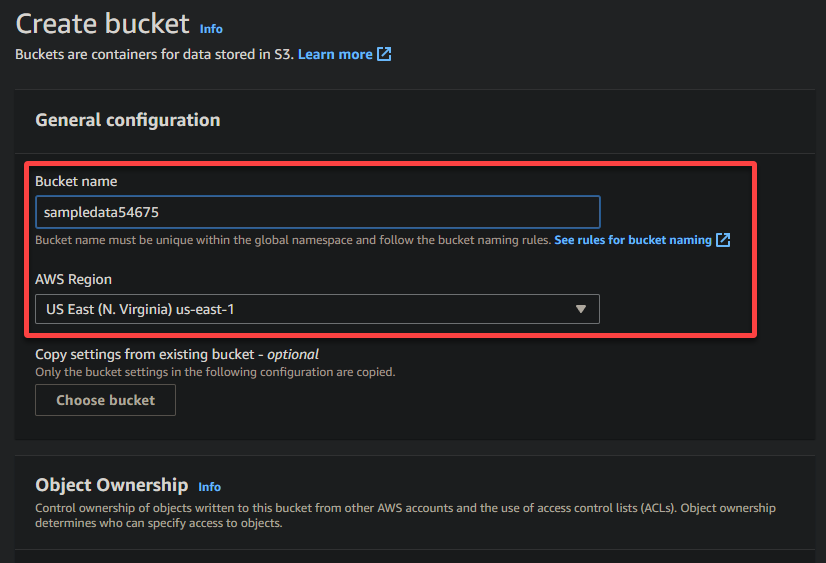
5. Scrollen Sie nach unten, lassen Sie die anderen Optionen unverändert und klicken Sie auf Bucket erstellen, um den Bucket zu erstellen.

6. Nach der Erstellung klicken Sie auf den Hyperlink für den neu erstellten S3-Bucket, um zum Bucket zu gelangen.

7. Klicken Sie auf Hochladen und suchen Sie die Beispieldatei, die Sie hochladen möchten.
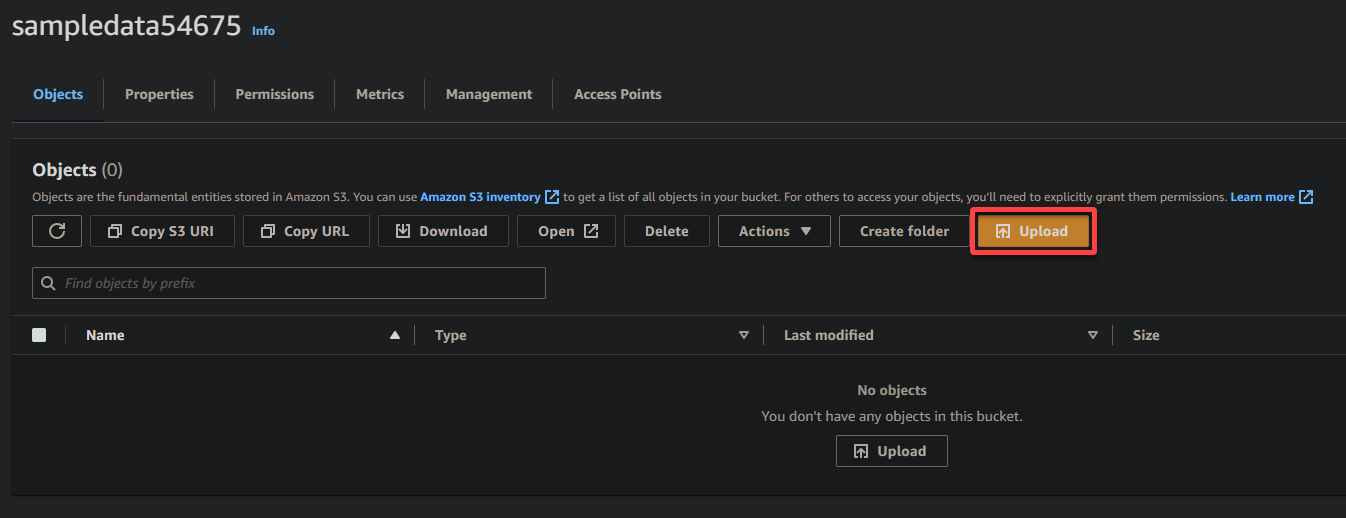
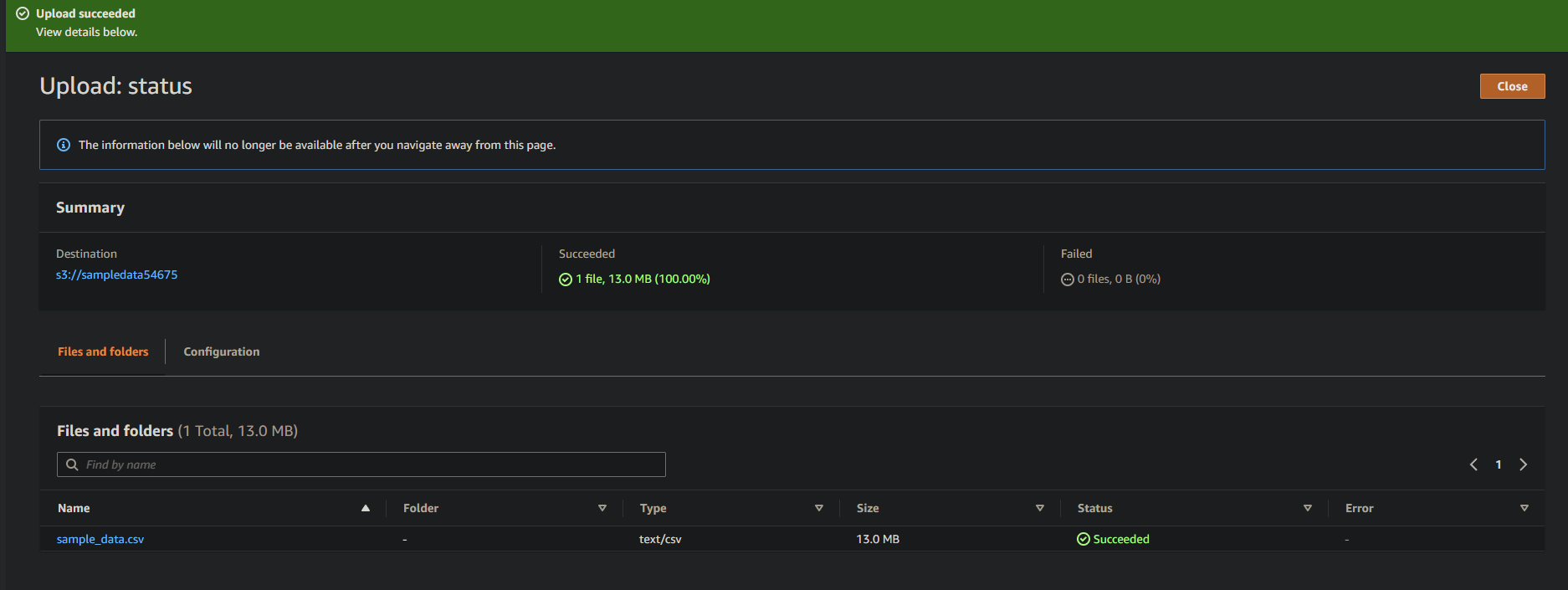
Zu guter Letzt lassen Sie die anderen Einstellungen wie sie sind und klicken Sie auf Hochladen, um die Beispieldatei in den neu erstellten Bucket hochzuladen.
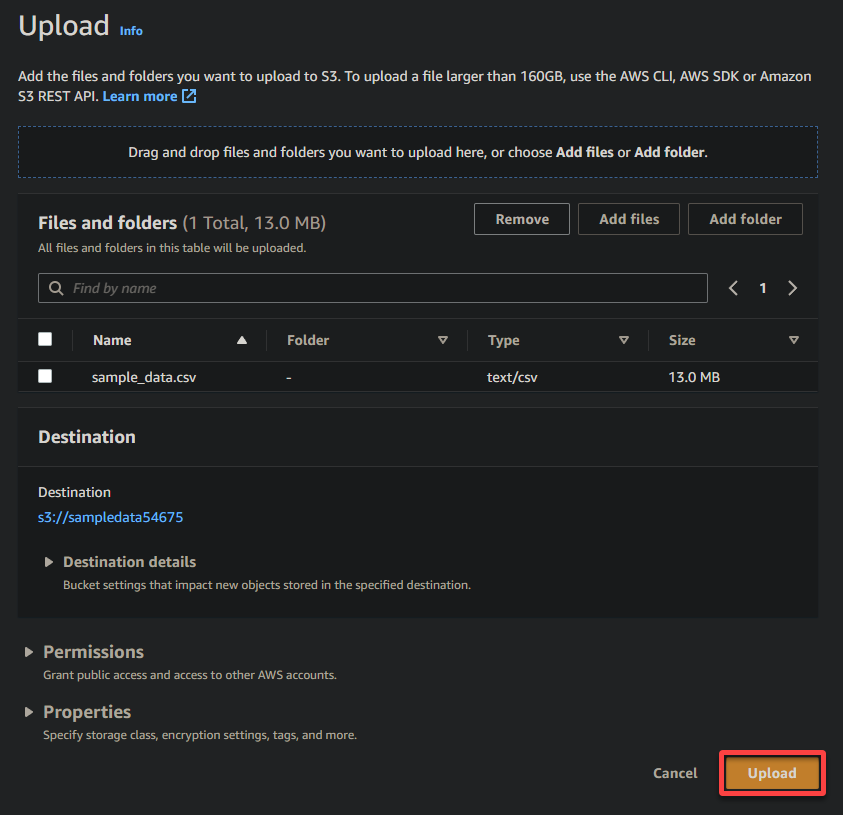
Wenn dies erfolgreich ist, sehen Sie Ihre neu hochgeladene Datei in Ihrem Bucket, wie unten gezeigt.
Erstellen eines Glue Crawlers zum Scannen und Katalogisieren von Daten
Sie haben gerade Beispieldaten in Ihren S3-Bucket hochgeladen, aber da diese derzeit unstrukturiert sind, benötigen Sie eine Möglichkeit, die Daten zu lesen und einen Metadatenkatalog zu erstellen. Wie? Indem Sie einen Glue Crawler erstellen, der die Daten automatisch scannt und katalogisiert.
Um einen Glue Crawler zu erstellen, befolgen Sie die folgenden Schritte:
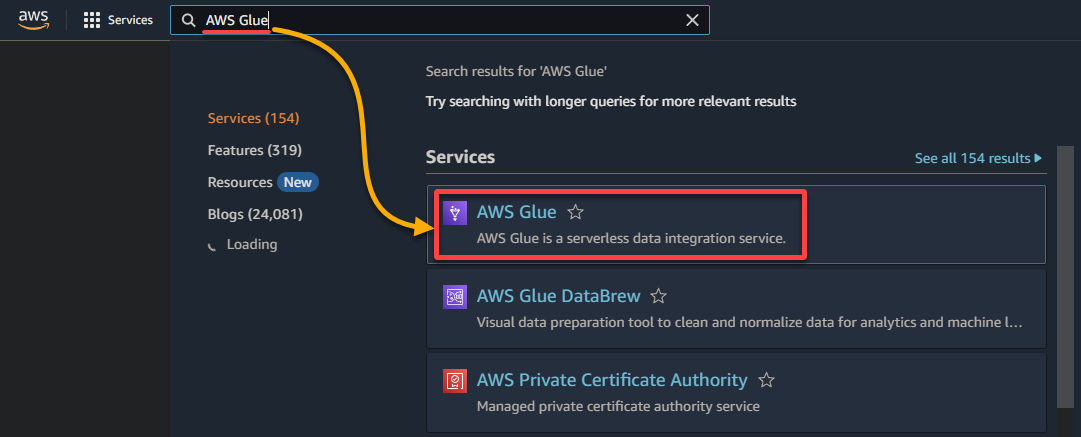
1. Navigieren Sie zur AWS Glue-Konsole über die AWS Management Console, wie unten gezeigt.
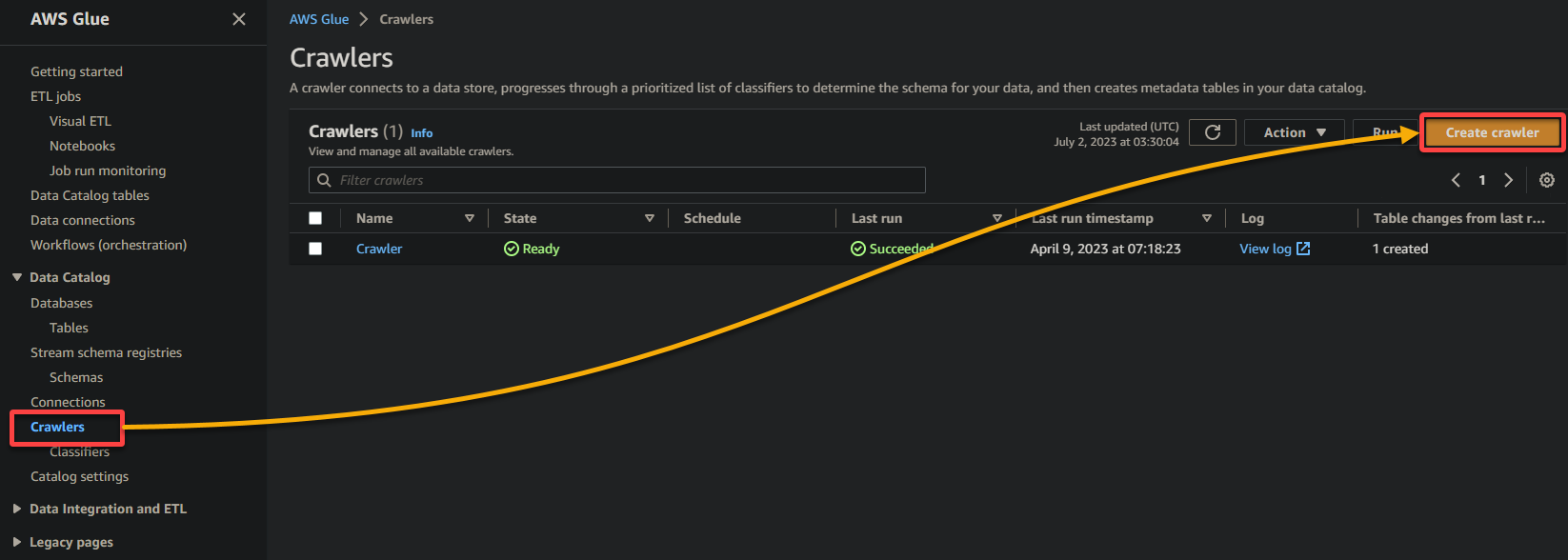
2. Navigieren Sie anschließend zu Crawler (linke Leiste) und klicken Sie auf Crawler hinzufügen (oben rechts), um einen neuen Glue Crawler zu erstellen.
3. Geben Sie einen aussagekräftigen Namen (z. B. glue_crawler) und eine Beschreibung für den Crawler ein, lassen Sie die anderen Einstellungen wie sie sind, und klicken Sie auf Weiter.
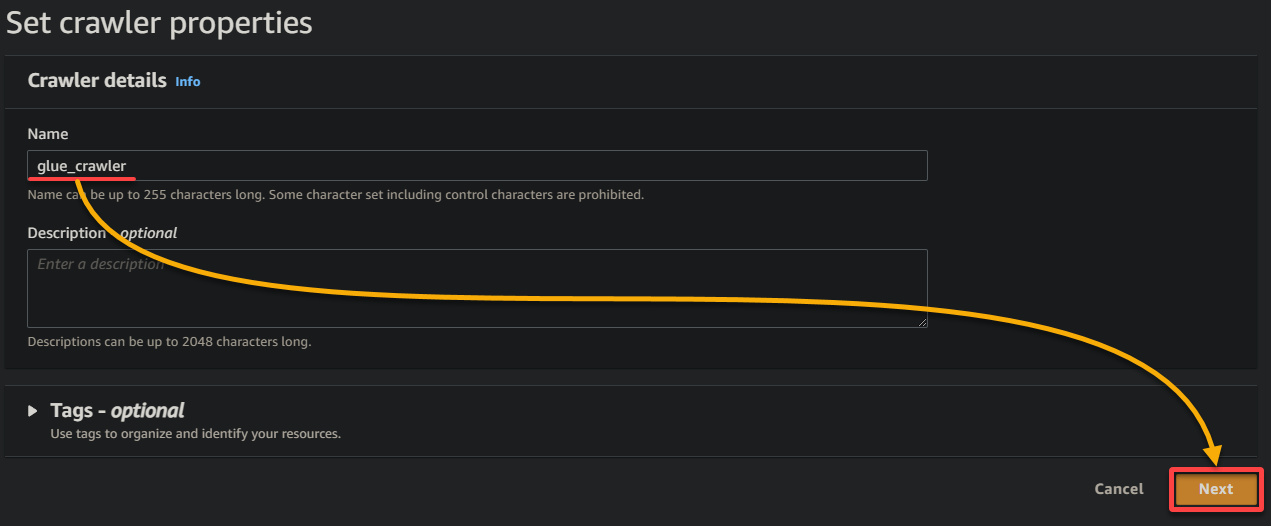
4. Klicken Sie nun auf Datenquelle hinzufügen unter Datenquellen, um eine neue Datenquelle für den Crawler hinzuzufügen.
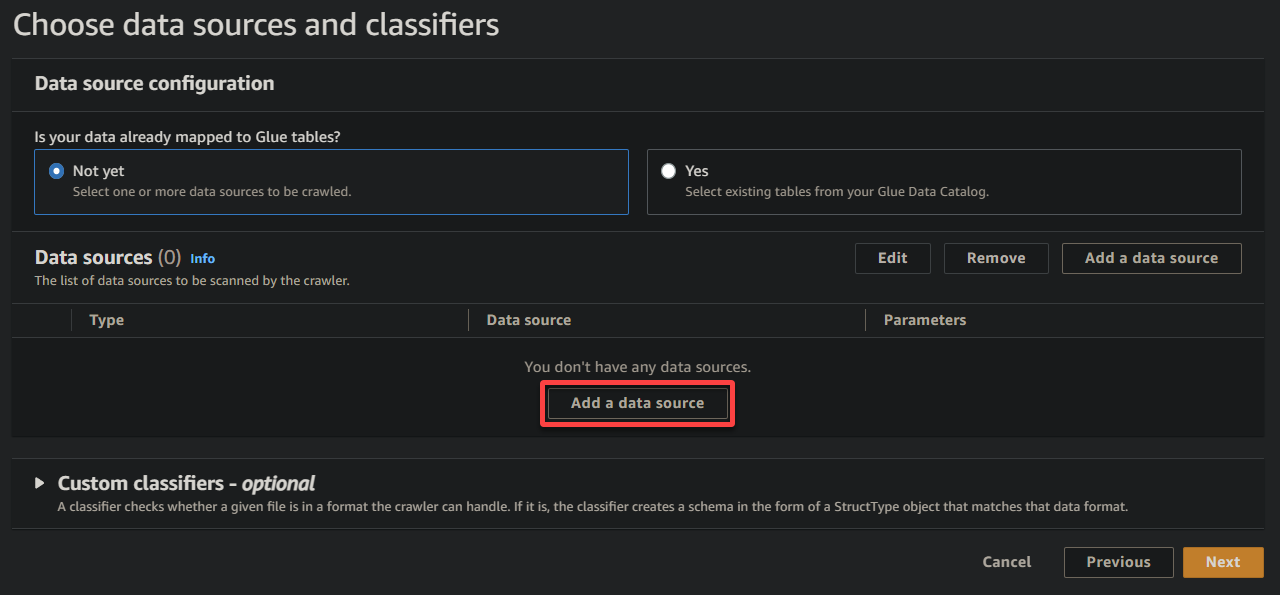
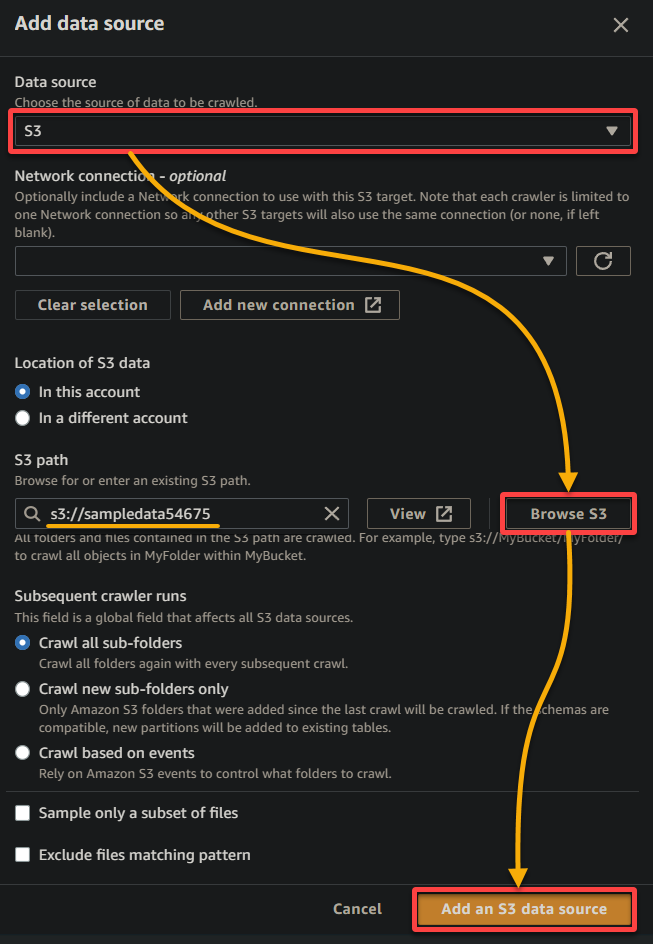
5. Konfigurieren Sie die Datenquelle im Popup-Fenster wie folgt:
- Datenquelle – Wählen Sie S3 aus, da sich Ihre Daten in Ihrem S3-Bucket befinden.
- S3-Pfad – Klicken Sie auf S3 durchsuchen und wählen Sie den Bucket aus, der Ihre hochgeladenen Beispieldaten enthält (sampledata54675).
- Behalten Sie die anderen Einstellungen bei und klicken Sie auf Eine S3-Datenquelle hinzufügen, um die Beispieldaten dem Crawler hinzuzufügen.
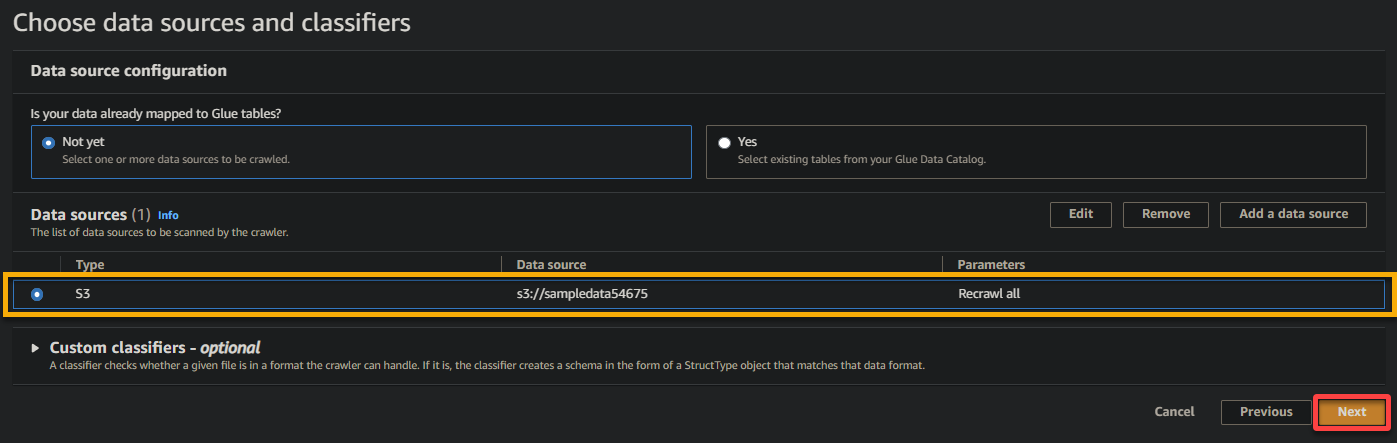
6. Überprüfen Sie nach der Konfiguration die Datenquelle, wie unten dargestellt, und klicken Sie auf Weiter, um fortzufahren.
7. Wählen Sie im nächsten Bildschirm die zuvor erstellte IAM-Rolle (glue_role) aus, behalten Sie die anderen Einstellungen bei und klicken Sie auf Weiter.
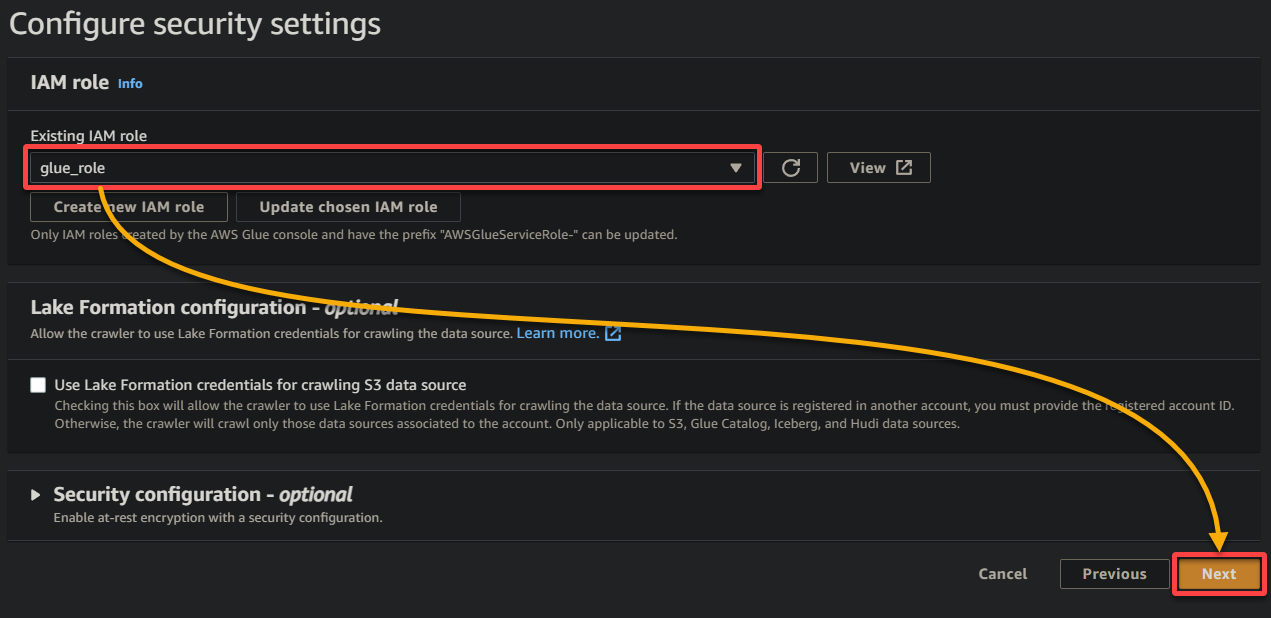
8. Klicken Sie unter Ausgabe und Zeitplanung auf Datenbank hinzufügen, um eine neue Datenbank zum Speichern der von Ihrem Glue-Crawler generierten verarbeiteten Daten und Metadaten zu erstellen. Diese Aktion öffnet einen neuen Browser-Tab, in dem Sie Ihre Datenbankdetails konfigurieren (Schritt acht).
Diese Datenbank bietet eine strukturierte Darstellung der Daten für Abfragen und Analysen.
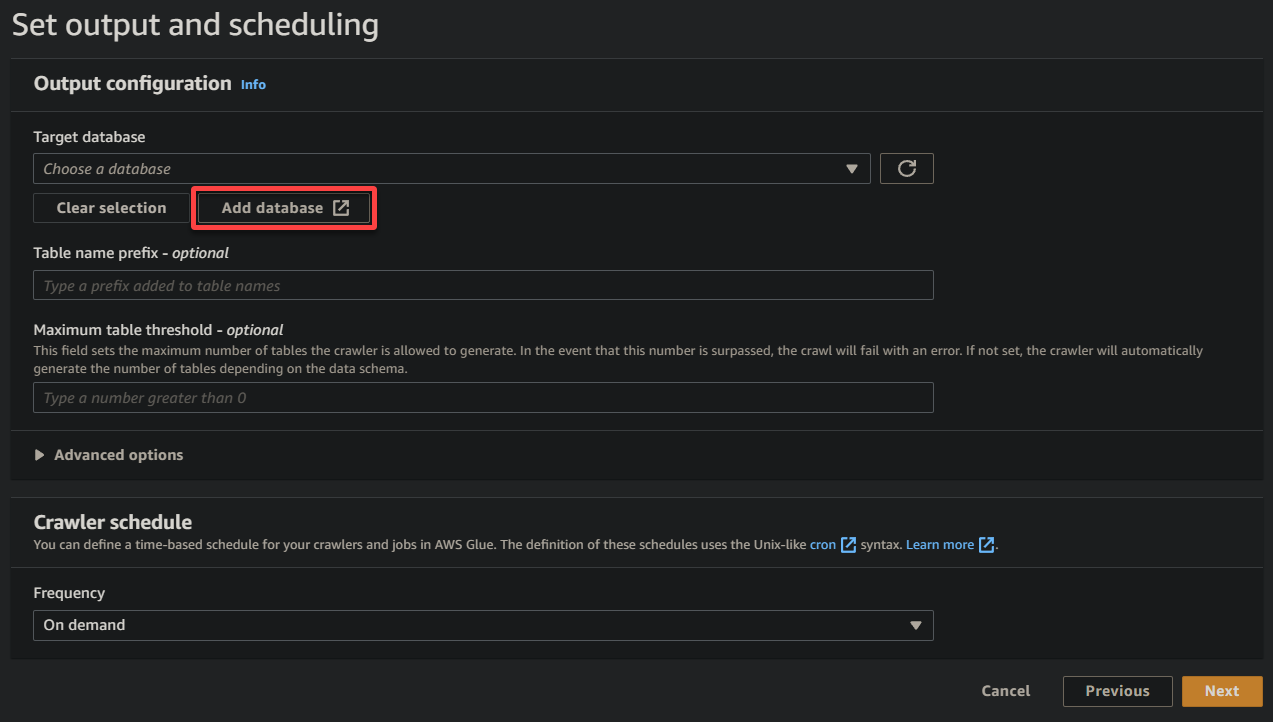
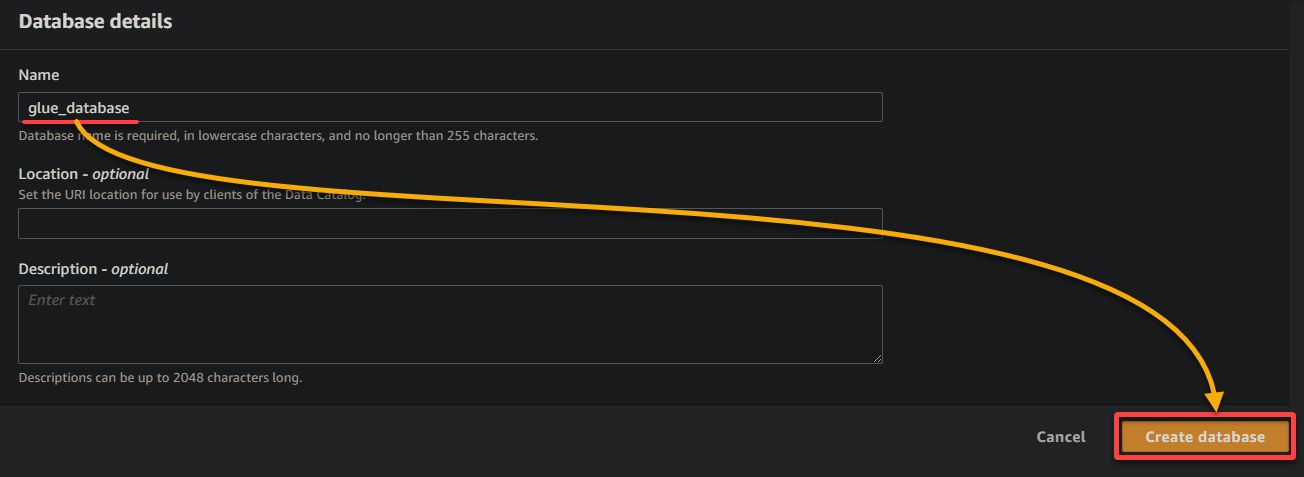
9. Geben Sie im neuen Browser-Tab einen beschreibenden Datenbanknamen ein (z. B. glue_database) und klicken Sie auf Datenbank erstellen, um die Datenbank zu erstellen.
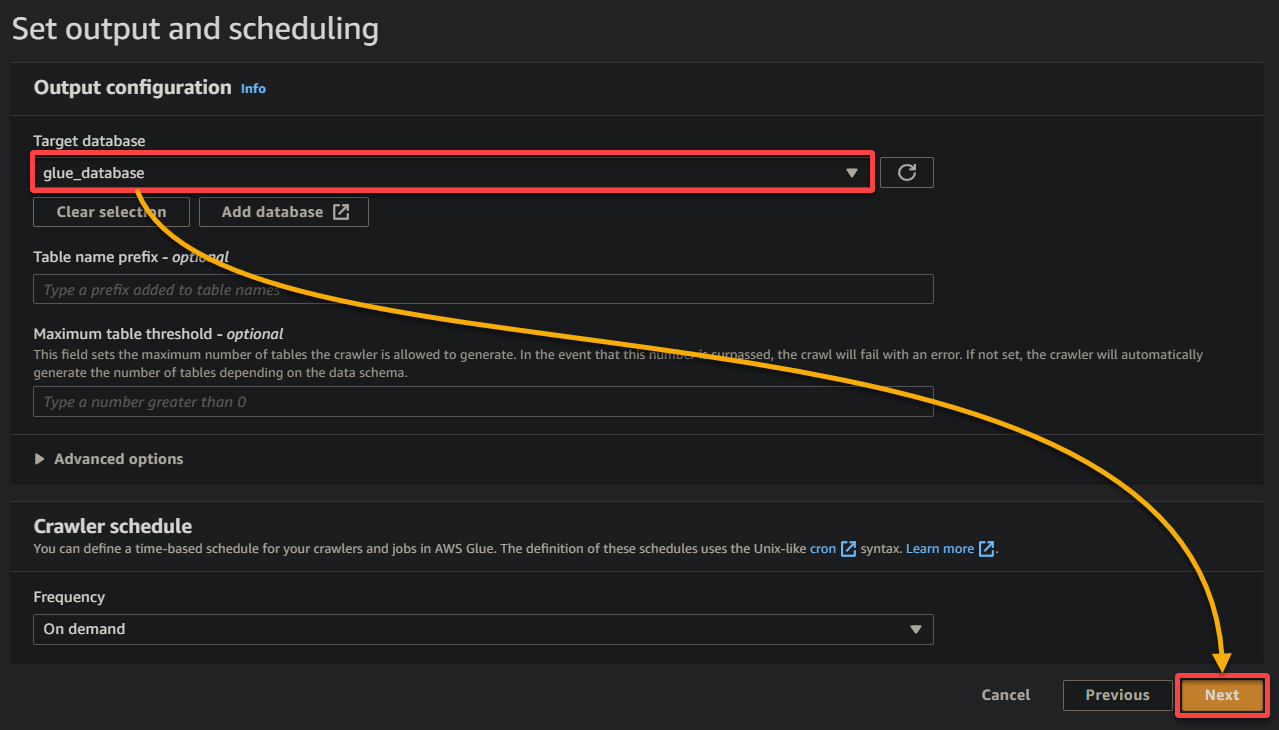
10. Wechseln Sie zum vorherigen Browser-Tab, wählen Sie die neu erstellte Datenbank (glue_database) aus dem Dropdown-Menü aus, behalten Sie die anderen Einstellungen bei und klicken Sie auf Weiter.
11. Überprüfen Sie abschließend Ihre Einstellungen auf dem letzten Bildschirm, um sicherzustellen, dass sie korrekt sind, und klicken Sie auf Crawler erstellen (unten rechts), um den neuen Crawler zu erstellen.
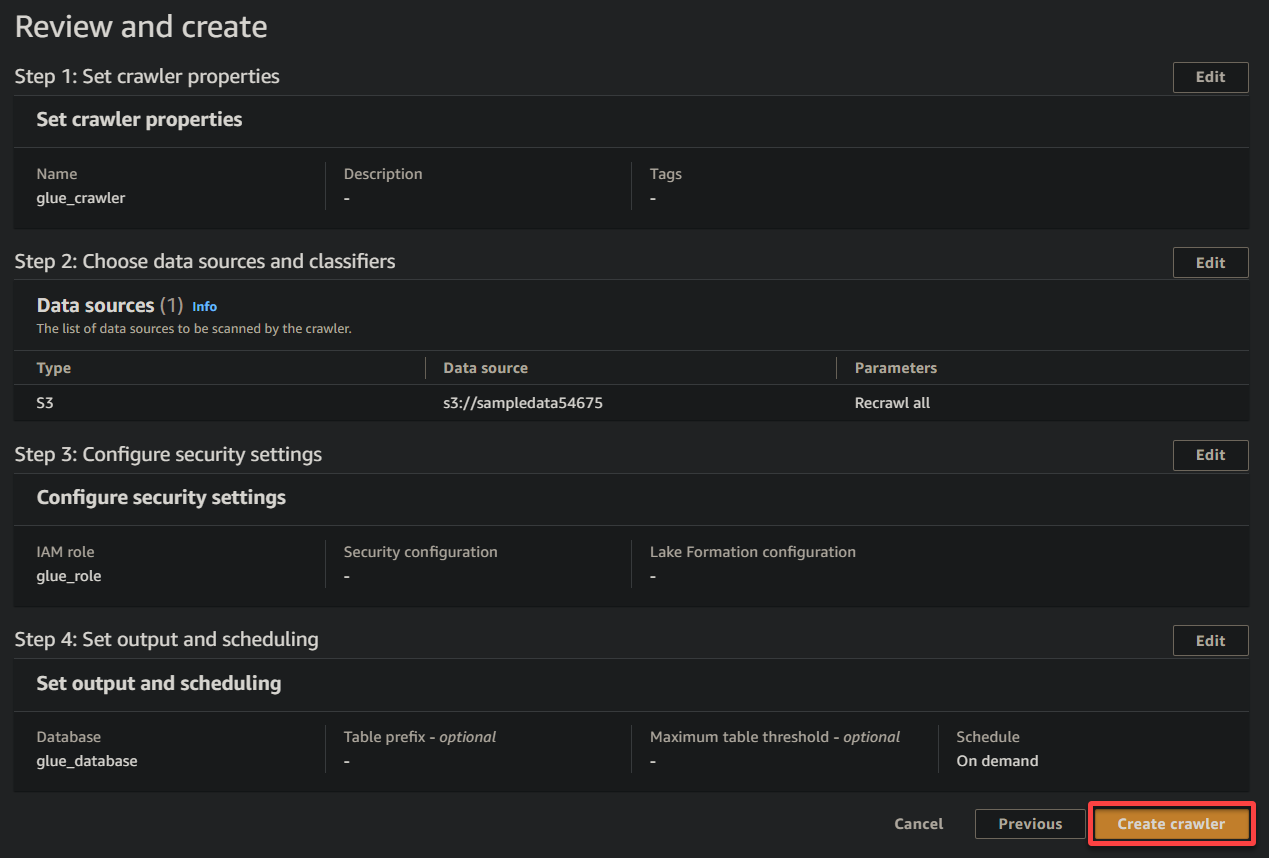
Wenn alles gut läuft, wird ein Bildschirm angezeigt, der die erfolgreiche Erstellung des Crawlers bestätigt. Schließen Sie diesen Bildschirm noch nicht, Sie werden diesen Crawler im folgenden Abschnitt ausführen.
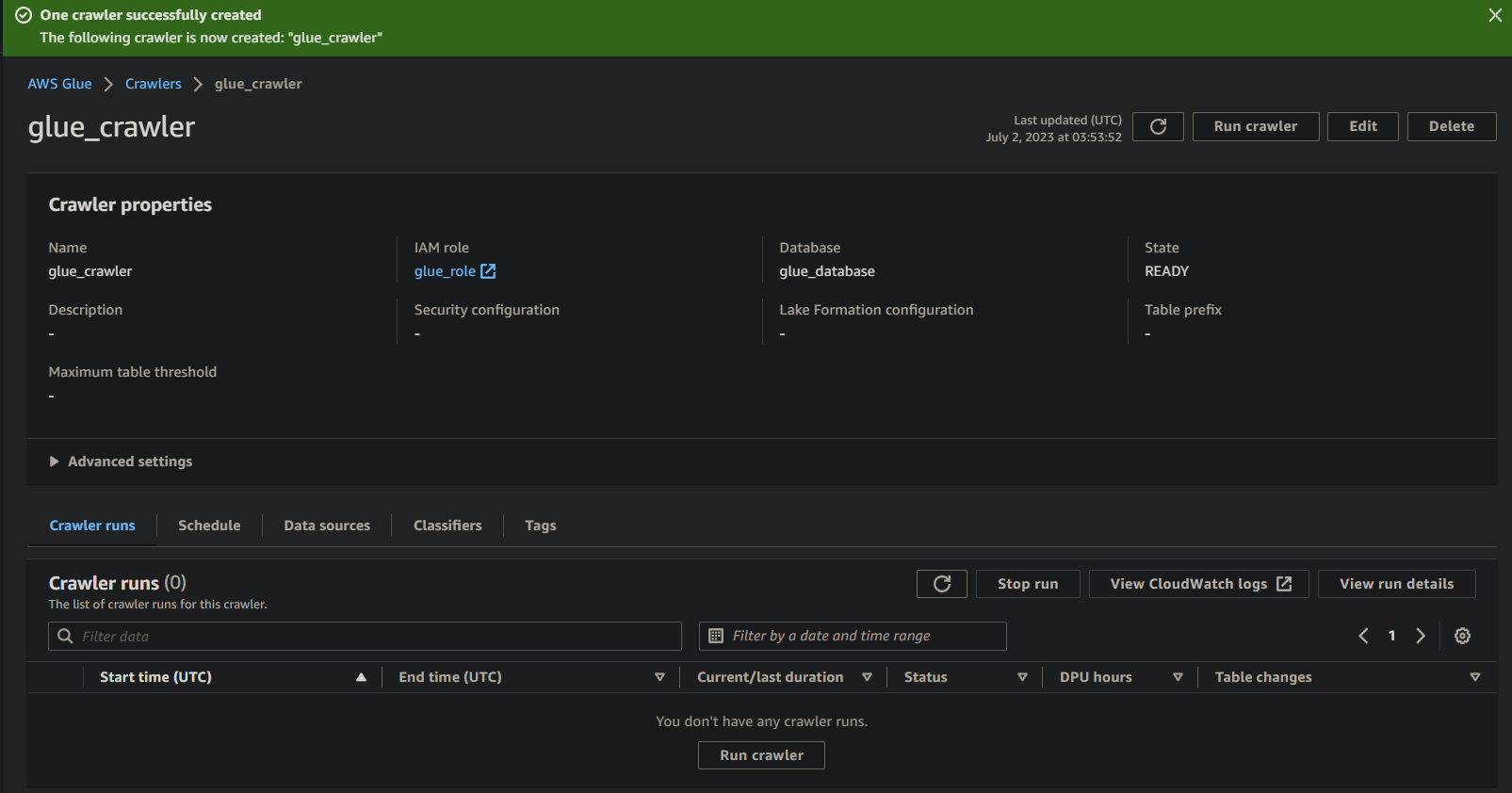
Das Ausführen des Glue Crawlers zum Erstellen eines Metadatenkatalogs
Mit einem neuen Crawler zur Verfügung ist das Ausführen des Crawlers unerlässlich, um den Scan- und Katalogisierungsprozess zu starten. Ihr Glue Crawler wird einen Metadatenkatalog erstellen, der eine strukturierte Darstellung Ihrer Daten für Abfrage- und Analysezwecke bietet.
Um Ihren neu erstellten Glue Crawler auszuführen:
1. Klicken Sie auf der Crawler-Detailseite unter dem Tab Crawler-Läufe auf Crawler ausführen, um die Ausführung des Crawlers zu starten.
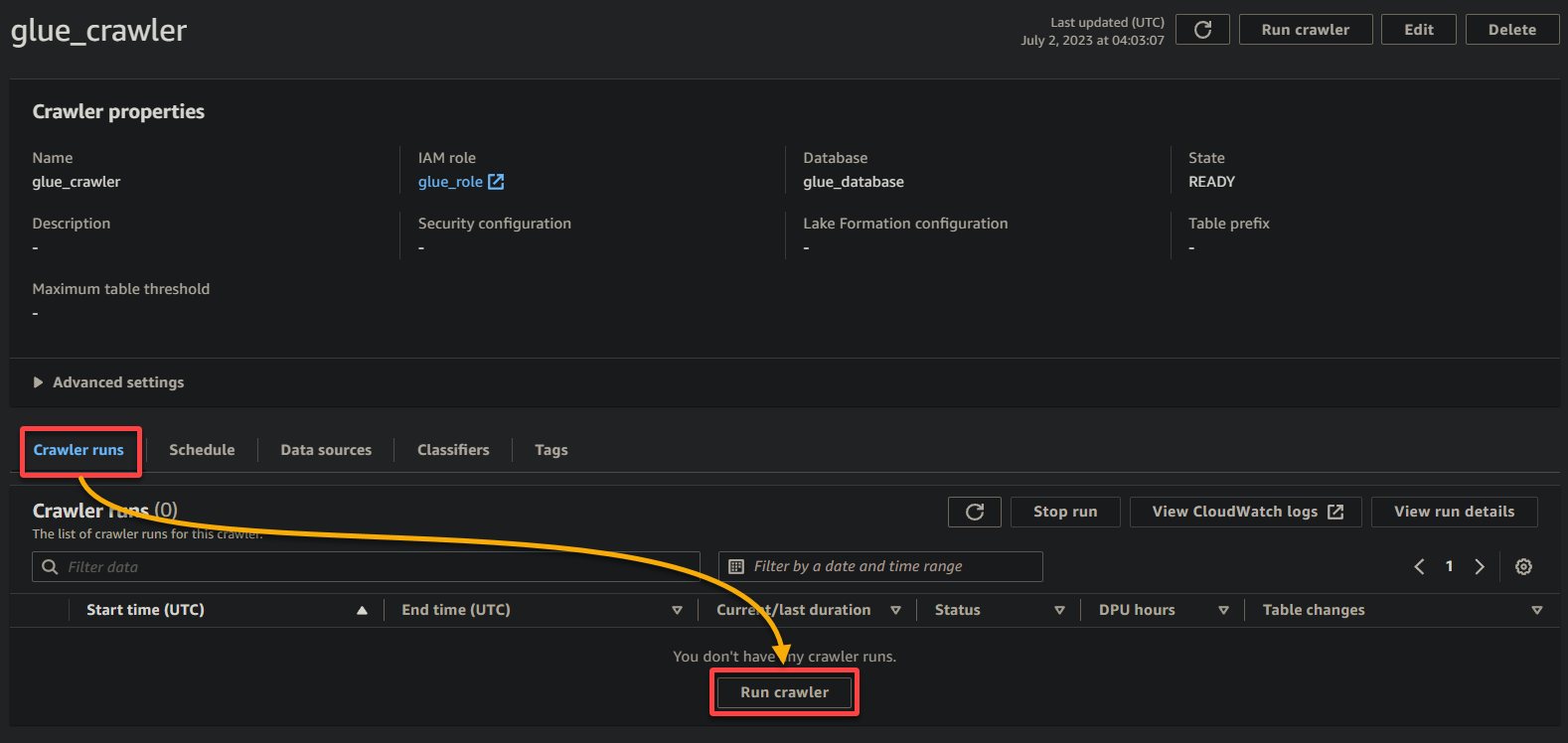
Sobald der Crawler gestartet ist, sehen Sie den Status und den Fortschritt auf der Crawler-Detailseite.
Abhängig von der Größe und Komplexität Ihrer Daten kann der Crawler einige Zeit benötigen, um seine Ausführung abzuschließen. Sie können die Seite regelmäßig aktualisieren, um den aktualisierten Status des Crawlers zu sehen.
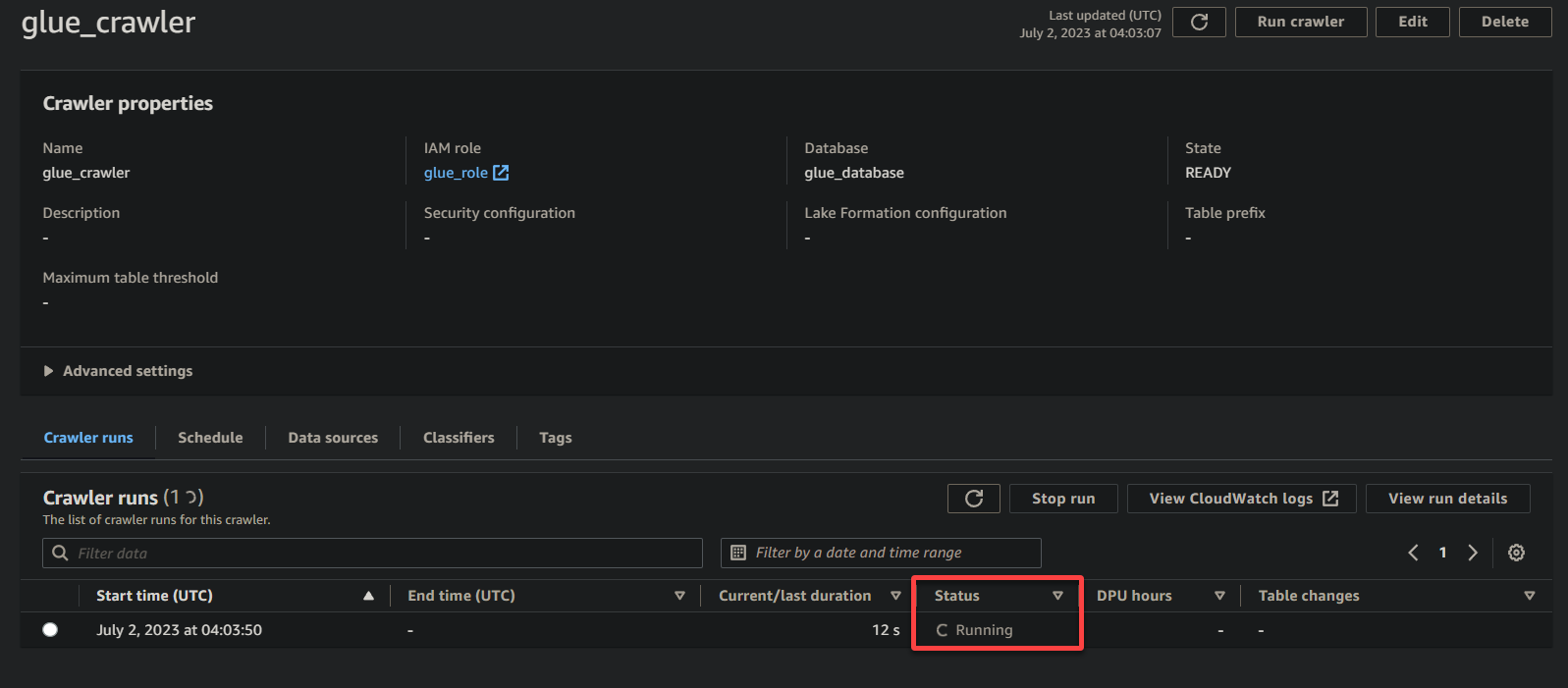
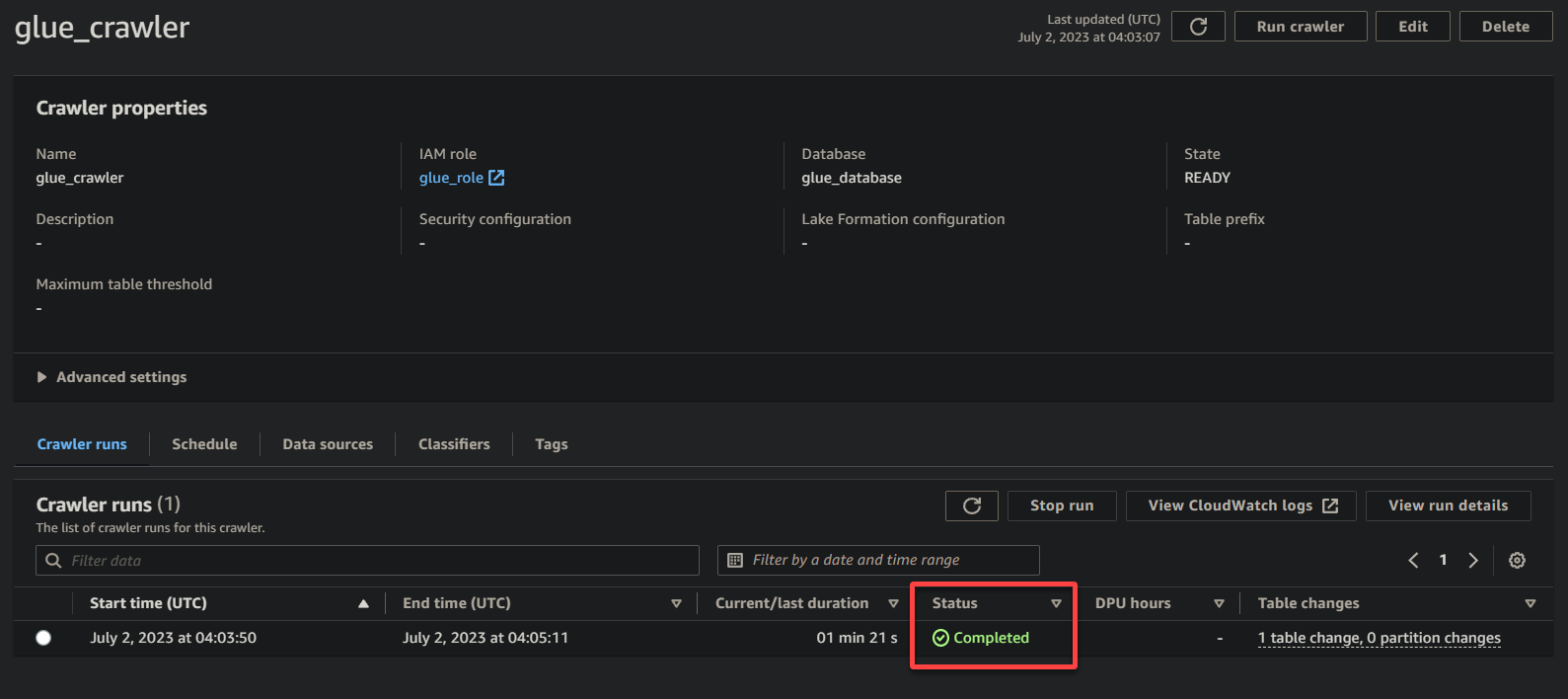
Wenn der Crawler seine Ausführung abgeschlossen hat, ändert sich der Status in Abgeschlossen, wie unten gezeigt. Zu diesem Zeitpunkt können Sie mit der Abfrage Ihrer Daten fortfahren.
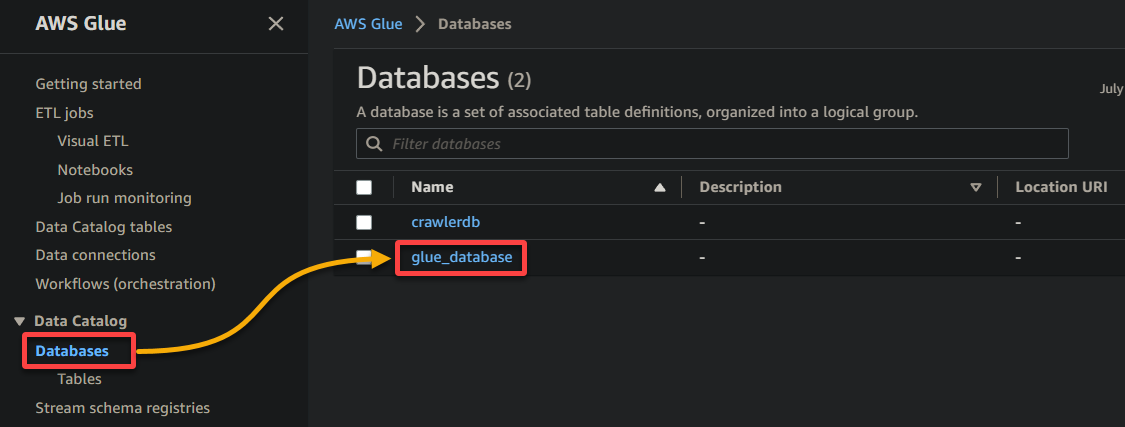
2. Navigieren Sie anschließend zu Datenbank (linke Leiste) und klicken Sie auf Ihre Datenbank, um auf ihre Eigenschaften und Tabellen zuzugreifen.
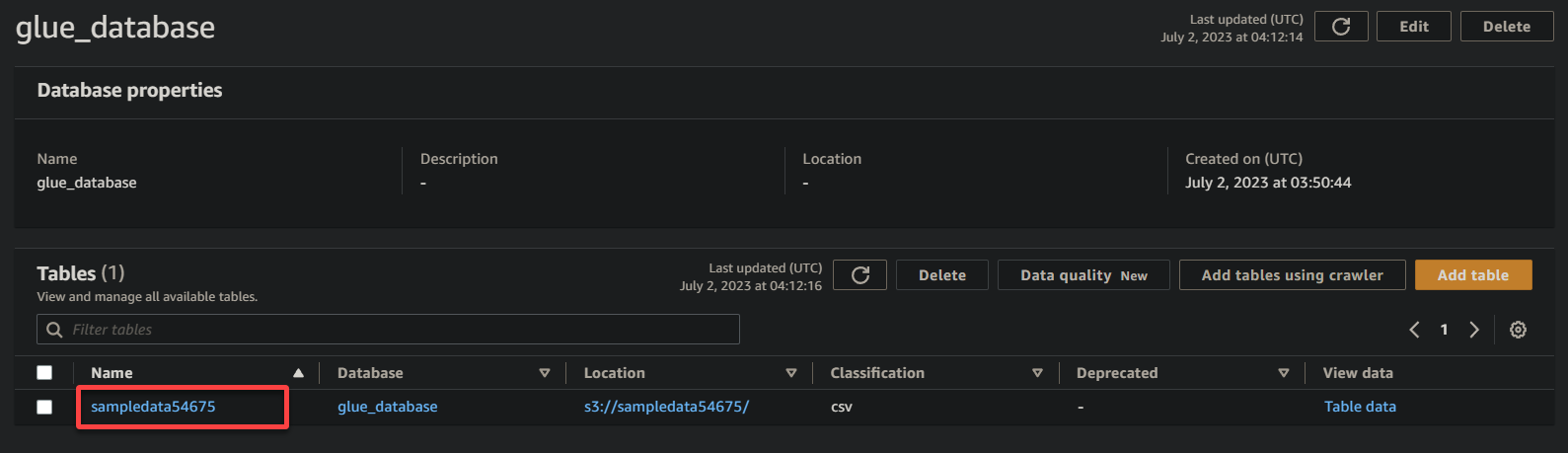
3. Klicken Sie schließlich auf den Namen Ihres Buckets (BeispielDaten54675), der nun eine Tabelle ist, um seine gespeicherten Daten anzuzeigen.
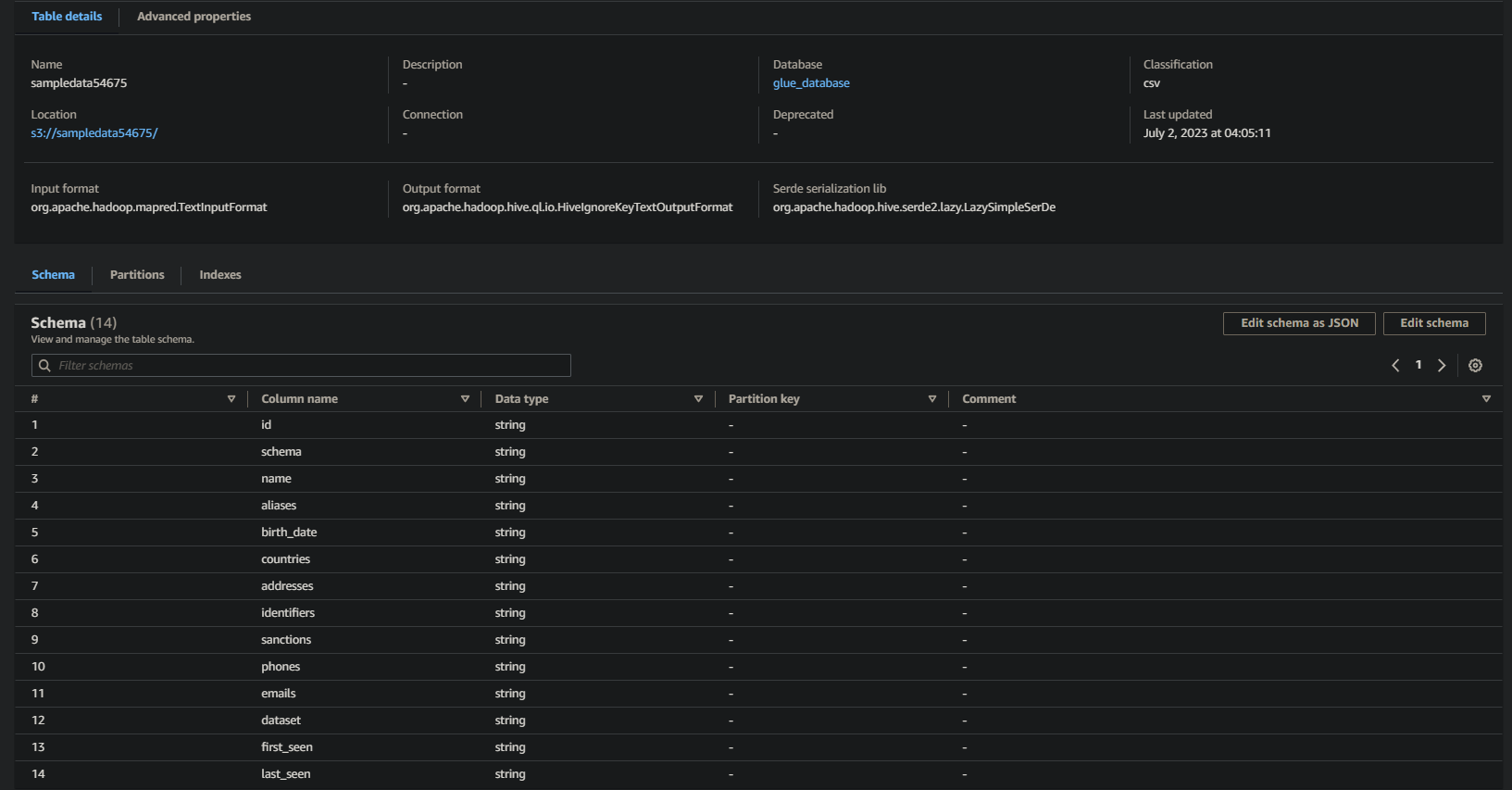
Wenn erfolgreich, sehen Sie ähnliche Informationen wie unten. Diese Informationen bestätigen, dass die Daten erfolgreich in die Datenbanktabelle transformiert wurden und wertvolle Details bereitstellen.
Abfragen von katalogisierten Daten über AWS Athena
Nachdem Ihre Daten im AWS Glue Data Catalog verfügbar sind, können Sie verschiedene Tools verwenden, um Ihre Daten abzufragen und zu analysieren. Ein solches Tool ist AWS Athena, ein interaktiver Abfragedienst, mit dem Sie Daten in der Cloud mithilfe von Standard-SQL analysieren können.
Um die Daten mithilfe von AWS Athena abzufragen, befolgen Sie die folgenden Schritte:
1. Suchen Sie nach der Athena-Konsole und greifen Sie darauf zu.
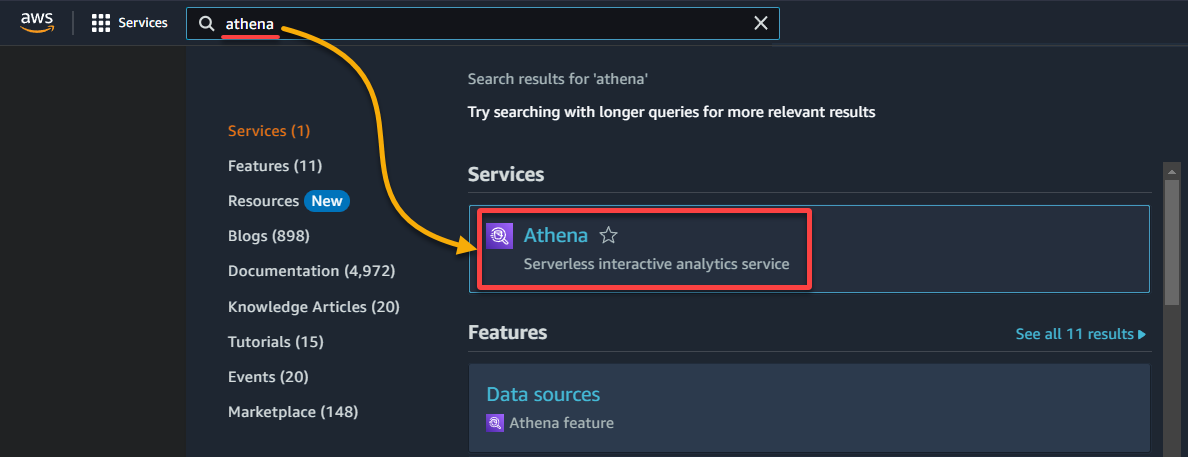
2. Wählen Sie die Datenbank aus, in der Ihre Daten im Bereich Daten katalogisiert sind, wie folgt:
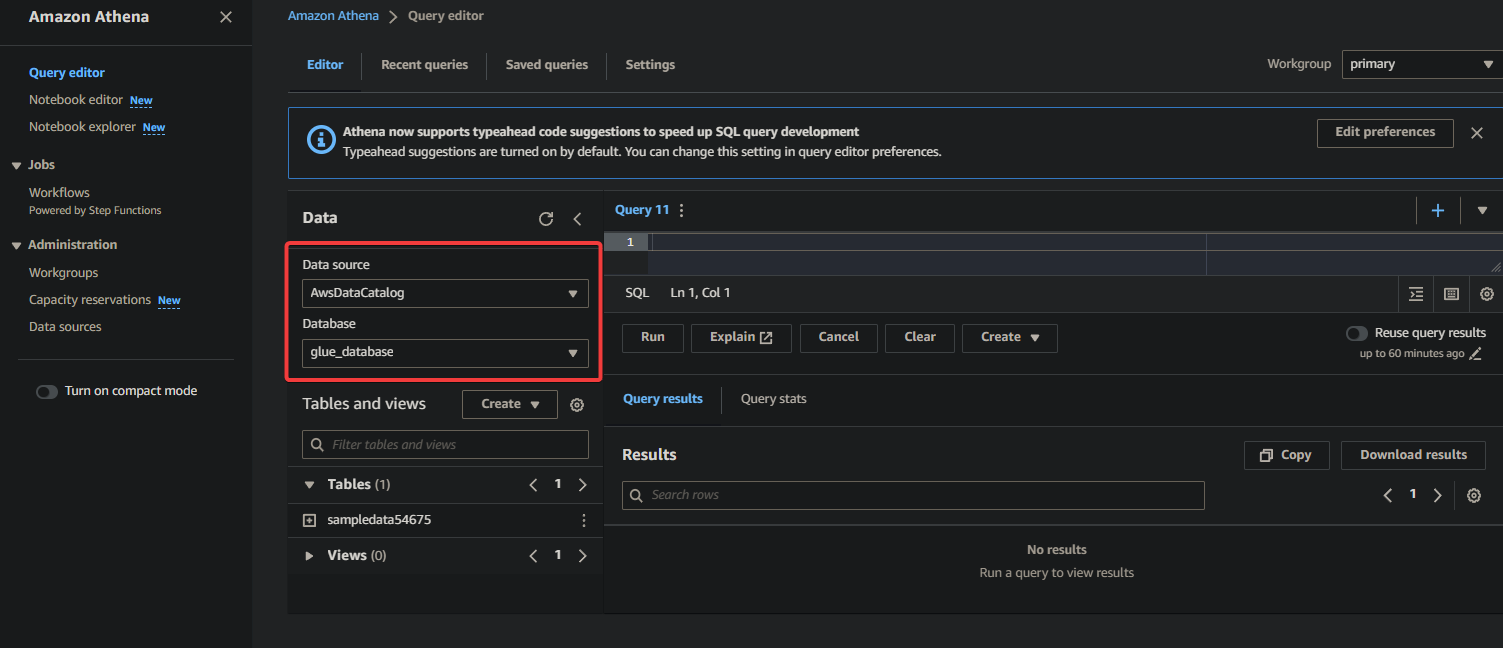
- Datenquelle – Wählen Sie AwsDataCatalog aus, um anzugeben, dass Sie die im AWS Glue katalogisierten Daten abfragen möchten.
- Datenbank – Wählen Sie die entsprechende Datenbank aus dem Dropdown-Feld aus (z. B. glue_database).
? Wenn Sie Ihre gewünschte Datenbank nicht im Dropdown-Menü sehen, stellen Sie sicher, dass der Crawler seine Ausführung abgeschlossen und die Daten katalogisiert hat.
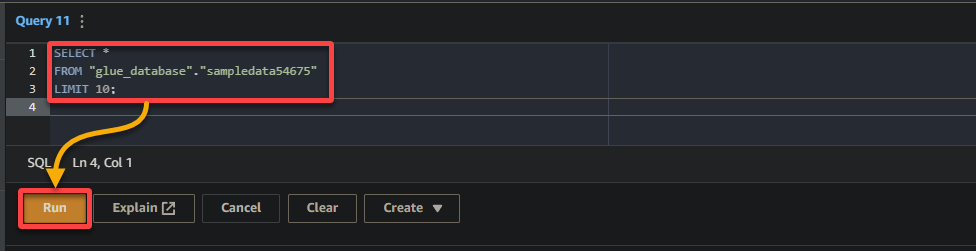
3. Geben Sie schließlich die folgende Abfrage in den Abfrage-Editor auf der rechten Seite ein und führen Sie sie aus.
Diese Abfrage liefert die ersten 10 Zeilen aus der Tabelle sampledata54675 in der Datenbank glue_database. Passen Sie die Abfrage bei Bedarf an Ihre spezifischen Anforderungen an.
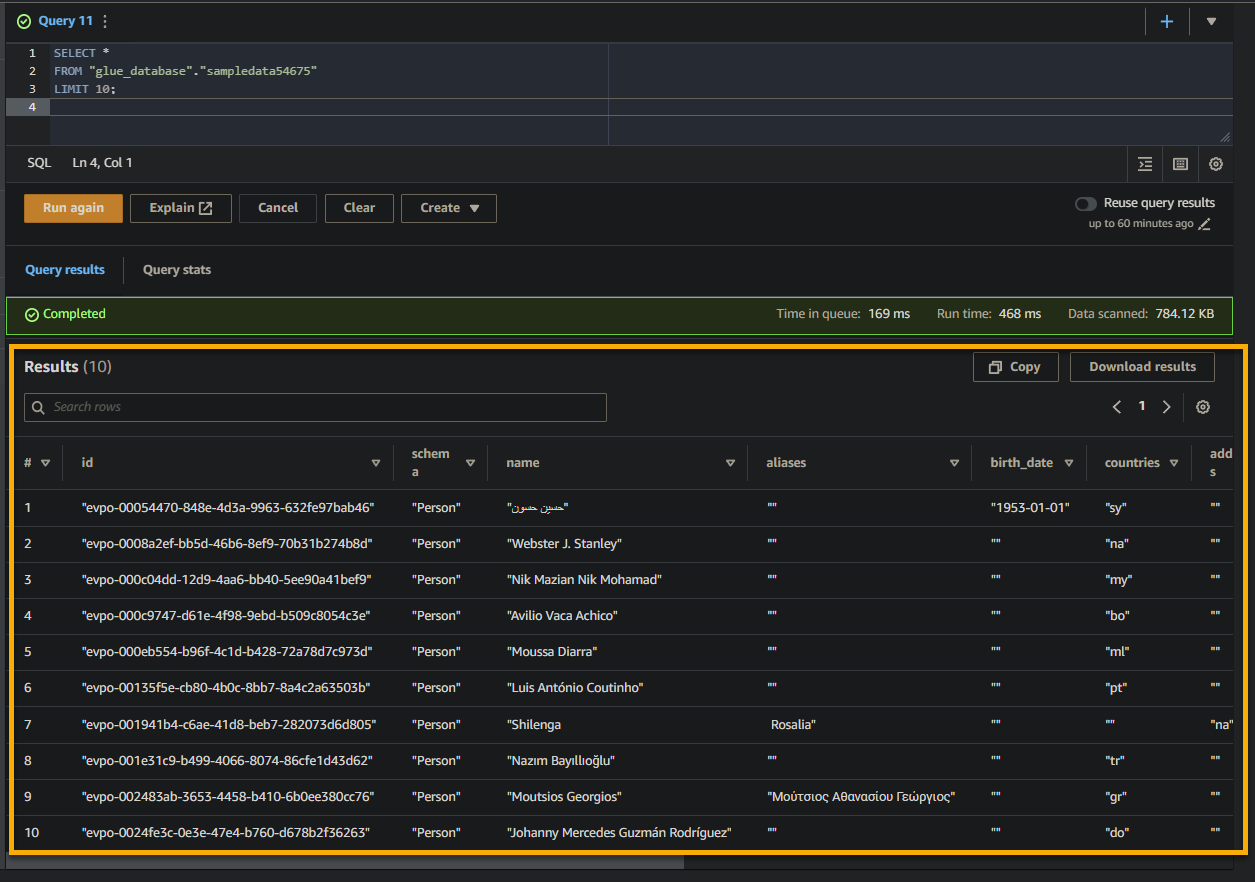
Wenn die Abfrage erfolgreich ist, werden die Ergebnisse im Bereich Ergebnis angezeigt, wie unten dargestellt. Die Ergebnisse enthalten Informationen über die in der Tabelle basierend auf Ihrer SQL-Abfrage gespeicherten Datensätze.
Notieren Sie sich die Spaltennamen, Datentypen und Werte, die im Ergebnisdatensatz zurückgegeben werden. Diese Informationen helfen Ihnen dabei, die Struktur und den Inhalt der abgefragten Daten zu verstehen.
Schlussfolgerung
In diesem Tutorial haben Sie die Grundlagen der Verwendung von AWS Glue gelernt, um einen Glue Crawler zu erstellen, Ihre Daten zu katalogisieren und Daten mit AWS Athena abzufragen. Datenbereitung und -analyse sind für jede datengetriebene Anwendung unerlässlich. Und Tools wie AWS Glue bieten eine schnelle Möglichkeit, Daten aus verschiedenen Quellen in eine Datenbanktabelle zu extrahieren, zu transformieren und zu laden (ETL).
Mit AWS Glue können Sie Daten jetzt schnell verwalten und organisieren, sodass Sie sich mehr auf die Analyse und Gewinnung von Erkenntnissen aus Ihren Daten konzentrieren können. Aber was Sie gesehen haben, ist nur die Spitze des Eisbergs. Entdecken Sie die vielfältigen Möglichkeiten und Funktionen, die AWS Glue bieten kann!
Warum nutzen Sie nicht AWS Glue-Verbindungen, um nahtlos mit anderen AWS-Diensten wie Amazon RDS oder Amazon Redshift zu integrieren? Diese Integration ermöglicht es Ihnen, komplexe ETL-Pipelines aufzubauen und noch größere Datenanalysefähigkeiten zu erreichen.