













في الأيام الأولى من الحوسبة، كانت التطبيقات تتعامل مع المهام بالتسلسل. ومع زيادة الحجم ليشمل ملايين المستخدمين، أصبح هذا النهج غير عملي. سمح المعالجة غير المتزامنة بالتعامل مع مهام متعددة في وقت واحد، لكن إدارة الخيوط/العمليات على جهاز واحد أدت إلى قيود في الموارد وتعقيد.
وهنا يأتي دور المعالجة الموازية الموزعة. من خلال توزيع عبء العمل عبر عدة أجهزة، كل منها مخصص لجزء من المهمة، فإنه يوفر حلاً قابلاً للتوسع وفعالاً. إذا كان لديك دالة لمعالجة دفعة كبيرة من الملفات، يمكنك تقسيم عبء العمل عبر عدة أجهزة لمعالجة الملفات بالتوازي بدلاً من التعامل معها بالتسلسل على جهاز واحد. بالإضافة إلى ذلك، يحسن الأداء من خلال الاستفادة من الموارد المجمعة ويقدم قابلية التوسع والتحمل للأخطاء. مع زيادة الطلبات، يمكنك إضافة المزيد من الأجهزة لزيادة الموارد المتاحة.
إن بناء وتشغيل التطبيقات الموزعة على نطاق واسع يعد تحديًا، لكن هناك العديد من الإطارات والأدوات لمساعدتك. في هذه التدوينة، سنستعرض إطار الحوسبة الموزعة مفتوح المصدر: راي. سننظر أيضًا إلى KubeRay، وهو مشغل Kubernetes يمكّن من دمج سلس لـ Ray مع مجموعات Kubernetes للحوسبة الموزعة في البيئات السحابية الأصلية. ولكن أولاً، دعونا نفهم أين يساعد التوازي الموزع.
أين يساعد المعالجة الموازية الموزعة؟
يمكن لأي مهمة تستفيد من تقسيم عبء العمل عبر عدة آلات أن تستفيد من المعالجة المتوازية الموزعة. هذه الطريقة مفيدة بشكل خاص في السيناريوهات مثل زحف الويب، وتحليل البيانات على نطاق واسع، وتدريب نماذج التعلم الآلي، ومعالجة تدفقات البيانات في الوقت الحقيقي، وتحليل بيانات الجينوم، وتقديم الفيديو. من خلال توزيع المهام عبر عدة عقد، تعزز المعالجة المتوازية الموزعة الأداء بشكل كبير، وتقلل من وقت المعالجة، وتزيد من استخدام الموارد، مما يجعلها ضرورية للتطبيقات التي تتطلب معدل نقل عالي ومعالجة سريعة للبيانات.
عندما لا تكون المعالجة المتوازية الموزعة ضرورية
- التطبيقات صغيرة النطاق: بالنسبة لمجموعات البيانات الصغيرة أو التطبيقات التي تتطلب معالجة بسيطة، قد لا يكون من المبرر إدارة نظام موزع.
- اعتماد البيانات القوي: إذا كانت المهام تعتمد بشكل كبير على بعضها البعض ولا يمكن تنفيذها بالتوازي بسهولة، فقد لا تقدم المعالجة الموزعة فائدة كبيرة.
- قيود الوقت الحقيقي: تتطلب بعض التطبيقات في الوقت الحقيقي (مثل مواقع التمويل وحجز التذاكر) زمن استجابة منخفض للغاية، وهو ما قد لا يمكن تحقيقه مع التعقيد المضاف لنظام موزع.
- الموارد المحدودة: إذا كانت البنية التحتية المتاحة لا تستطيع دعم الأعباء الإضافية لنظام موزع (مثل عرض النطاق الترددي للشبكة غير الكافي، أو عدد العقد المحدود)، فقد يكون من الأفضل تحسين الأداء على آلة واحدة.
كيف تساعد Ray في المعالجة المتوازية الموزعة
راي هو إطار عمل لمعالجة البيانات الموزعة بالتوازي يجمع بين جميع فوائد الحوسبة الموزعة وحلول التحديات التي ناقشناها، مثل تحمل الأخطاء، وقابلية التوسع، وإدارة السياقات، والتواصل، وما إلى ذلك. إنه إطار عمل بايثوني، مما يسمح باستخدام المكتبات والأنظمة الموجودة للعمل معه. مع مساعدة راي، لا يحتاج المبرمج إلى التعامل مع أجزاء طبقة معالجة البيانات الموزعة. سيتولى راي جدولة الموارد والتوسع التلقائي بناءً على متطلبات الموارد المحددة.
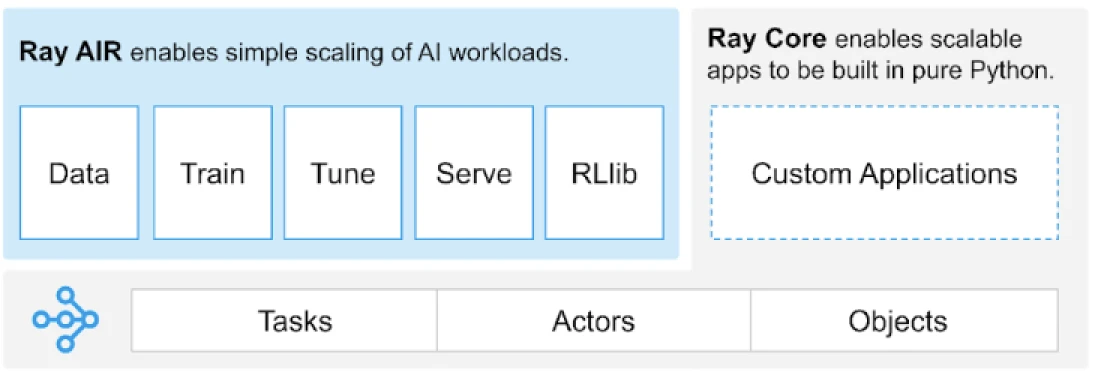
يوفر راي واجهة برمجة تطبيقات عالمية للمهام والممثلين والكائنات لبناء التطبيقات الموزعة.
(مصدر الصورة)
يوفر راي مجموعة من المكتبات المبنية على البدائيات الأساسية، وهي المهام، والممثلون، والكائنات، والسائقون، والوظائف. توفر هذه المكتبات واجهة برمجة تطبيقات متعددة الاستخدامات للمساعدة في بناء التطبيقات الموزعة. دعونا نلقي نظرة على البدائيات الأساسية، المعروفة أيضًا باسم، نواة راي.
بدائيات نواة راي
- المهام: مهام Ray هي وظائف Python تُنفذ بشكل غير متزامن على أجهزة Python منفصلة على عقدة مجموعة Ray. يمكن للمستخدمين تحديد متطلباتهم من الموارد بالنسبة لوحدات المعالجة المركزية ووحدات المعالجة الرسومية والموارد المخصصة التي يتم استخدامها من قبل جدول المجموعة لتوزيع المهام للتنفيذ المتوازي.
- الممثلون: بينما تكون المهام هي للوظائف، تكون الممثلون للفئات. الممثل هو عامل يحتفظ بالحالة، وتُجدول أساليب الممثل على ذلك العامل المحدد ويمكنها الوصول إلى الحالة وتغييرها. مثل المهام، يدعم الممثلون متطلبات وحدات المعالجة المركزية ووحدات المعالجة الرسومية والموارد المخصصة.
- الكائنات: في Ray، تنشئ المهام والممثلون الكائنات وتحسبها. يمكن تخزين هذه الكائنات البعيدة في أي مكان في مجموعة Ray. تُستخدم مراجع الكائنات للإشارة إليها، ويتم تخزينها في متجر ذاكرة النظام الموزع المشترك في Ray.
- السائقون: الجذر البرنامجي، أو البرنامج “الرئيسي”: هذا هو الكود الذي يشغل
ray.init() - الوظائف: تجميع المهام والكائنات والممثلون الناتجة (بشكل تكراري) من نفس السائق وبيئة تشغيلهم
للحصول على معلومات حول العناصر الأساسية، يمكنك الاطلاع على توثيق Ray Core.
أساليب مفتاحية في Ray Core
أدناه بعض الأساليب المفتاحية داخل Ray Core التي يتم استخدامها بشكل شائع:
-
ray.init()– تشغيل تشغيل Ray والاتصال بمجموعة Ray.import ray ray.init()
-
@ray.remote– ديكور يحدد دالة أو فئة بايثون لتنفيذها كوظيفة (دالة بعيدة) أو ممثل (فئة بعيدة) في عملية مختلفة@ray.remote def remote_function(x): return x * 2
-
.remote– لاحقة للدوال والفئات البعيدة؛ العمليات البعيدة غير متزامنةresult_ref = remote_function.remote(10)
-
ray.put()– وضع كائن في مخزن الكائنات في الذاكرة؛ يرجع مرجع كائن يُستخدم لتمرير الكائن إلى أي دالة أو استدعاء طريقة بعيدة.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– الحصول على كائن (أو كائنات) بعيدة من مخزن الكائنات من خلال تحديد مرجع (مراجع) الكائن.result = ray.get(result_ref) original_data = ray.get(data_ref)
إليك مثال على استخدام معظم الأساليب الأساسية الرئيسية:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# استخدام .remote لإنشاء مهمة
future = calculate_square.remote(5)
# الحصول على النتيجة
result = ray.get(future)
print(f"The square of 5 is: {result}")كيف يعمل Ray؟
تعتبر مجموعة Ray مثل فريق من الكمبيوترات التي تشترك في تشغيل برنامج. تتكون من عقدة رئيسية وعدة عقد عمال. تدير العقدة الرئيسية حالة العقدة وجدولة العمل، بينما تنفذ عقد العمال المهام وتدير الممثلين
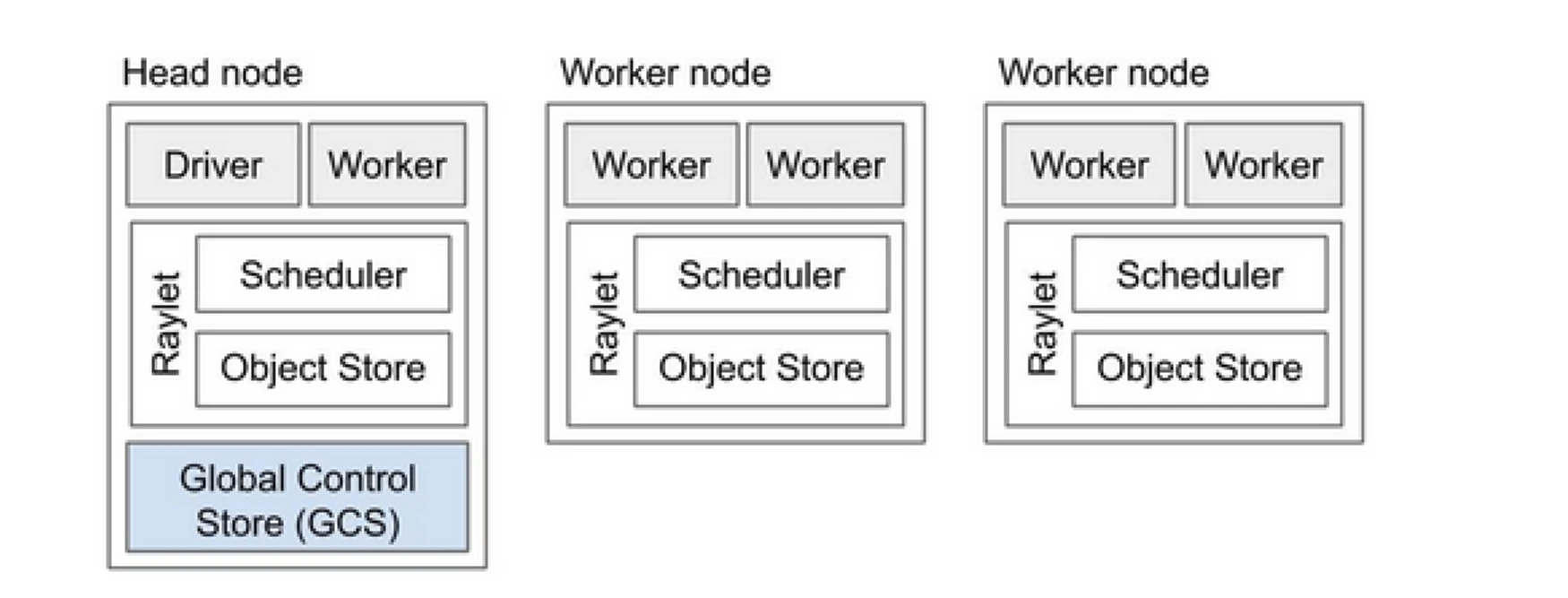
مكونات مجموعة Ray
- متجر التحكم العالمي (GCS): يدير GCS البيانات الوصفية والحالة العالمية لمجموعة Ray. يتتبع المهام والممثلين وتوافر الموارد، مما يضمن أن جميع العقد لديها رؤية متسقة للنظام.
- الجدول الزمني: يوزع الجدول الزمني المهام والممثلين عبر العقد المتاحة. يضمن استخدام الموارد الفعال وتوازن الحمولة من خلال النظر في متطلبات الموارد وتبعيات المهام.
- عقدة رئيسية: تنسق العقدة الرئيسية مجموعة Ray بأكملها. تشغل GCS، وتتعامل مع جدولة المهام، وتراقب صحة عقد العمال.
- عقد العمال: تنفذ عقد العمال المهام والممثلين. يقومون بالحسابات الفعلية ويخزنون الكائنات في الذاكرة المحلية لديهم.
- Raylet: يدير الموارد المشتركة على كل عقدة ويتم مشاركته بين جميع الوظائف التي تعمل بشكل متزامن.
يمكنك التحقق من مستند معمارية Ray v2 للحصول على مزيد من المعلومات التفصيلية.
العمل مع تطبيقات بايثون الحالية لا يتطلب الكثير من التغييرات. التغييرات المطلوبة ستكون في الأساس حول الدالة أو الفئة التي تحتاج إلى توزيع بشكل طبيعي. يمكنك إضافة زينة وتحويلها إلى مهام أو ممثلين. دعونا نرى مثالاً على ذلك.
تحويل دالة بايثون إلى مهمة راي
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
تحويل فئة بايثون إلى ممثل راي
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
تخزين المعلومات في كائنات راي
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
للتعرف على المزيد حول مفهومها، توجه إلى مفهوم راي الأساسي الوثائق.
راي مقابل النهج التقليدي للمعالجة الموازية الموزعة
فيما يلي تحليل مقارن بين النهج التقليدي (بدون راي) مقابل راي على Kubernetes لتمكين المعالجة الموازية الموزعة.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| النشر | إعداد وتكوين يدوي | آلي مع مشغل KubeRay |
| التوسع | توسع يدوي | توسع آلي مع RayAutoScaler و Kubernetes |
| تحمل الأخطاء | آليات تحمل الأخطاء مخصصة | تحمل الأخطاء المدمجة مع Kubernetes وراي |
| إدارة الموارد | تخصيص الموارد يدوي | تخصيص وإدارة الموارد بشكل آلي |
| توازن الحمل | حلول توازن الحمل مخصصة | توازن الحمل المدمج مع Kubernetes |
| إدارة التبعيات | تثبيت التبعيات يدوياً | بيئة متسقة مع حاويات Docker |
| تنسيق العنقود | معقدة ويدوية | مبسطة مع اكتشاف الخدمة والتنسيق من خلال Kubernetes |
| عبء التطوير | مرتفع، مع الحاجة إلى حلول مخصصة | مخفض، مع Ray وKubernetes يتوليان العديد من الجوانب |
| المرونة | قدرة محدودة على التكيف مع أحمال العمل المتغيرة | مرونة عالية مع التوسع الديناميكي وتخصيص الموارد |
توفر Kubernetes منصة مثالية لتشغيل التطبيقات الموزعة مثل Ray بسبب قدراتها القوية في التنسيق. فيما يلي النقاط الرئيسية التي تحدد القيمة في تشغيل Ray على Kubernetes:
- إدارة الموارد
- قابلية التوسع
- التنسيق
- التكامل مع النظام البيئي
- نشر وإدارة سهلة
يجعل KubeRay Operator من الممكن تشغيل Ray على Kubernetes.
ما هو KubeRay؟
يبسط KubeRay Operator إدارة عنقود Ray على Kubernetes من خلال أتمتة مهام مثل النشر، والتوسع، والصيانة. يستخدم تعريفات الموارد المخصصة لـ Kubernetes (CRDs) لإدارة الموارد المحددة لـ Ray.
تعريفات الموارد المخصصة لـ KubeRay
لديها ثلاثة CRDs مميزة:
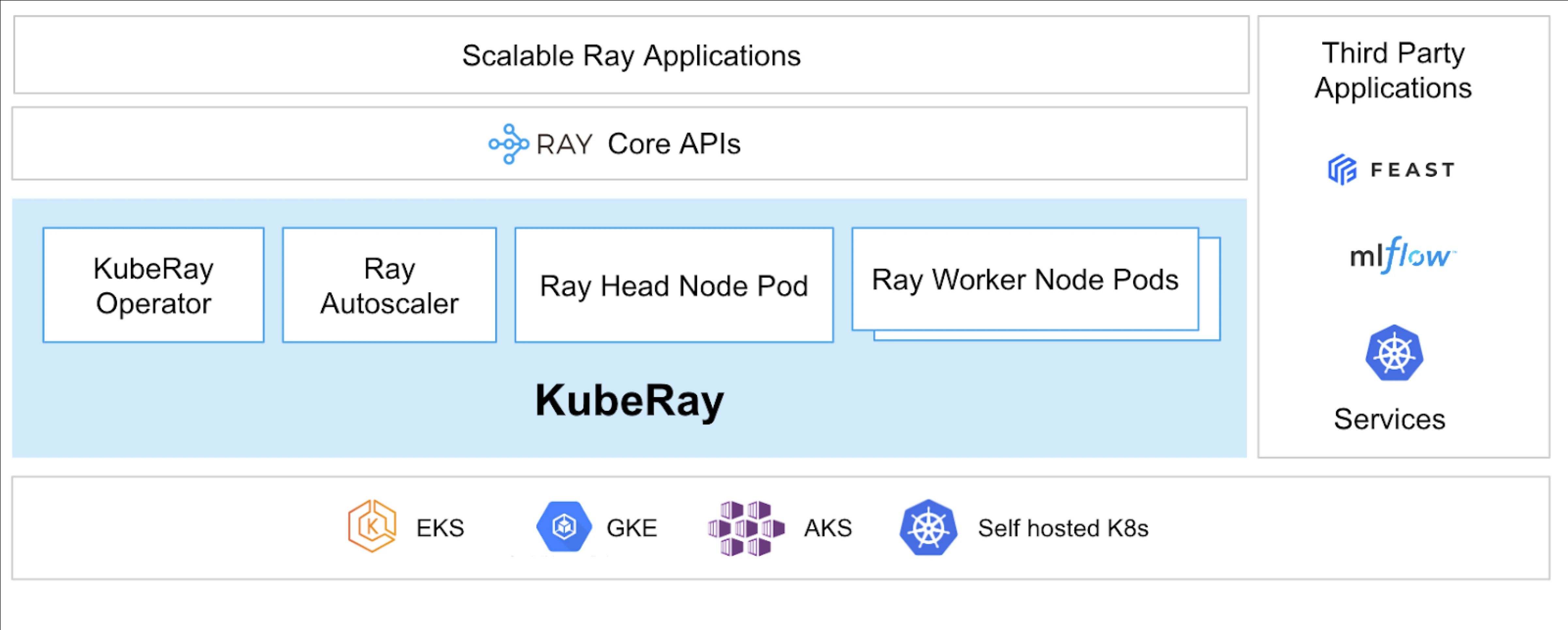
- RayCluster: يساعد هذا CRD في إدارة دورة حياة RayCluster ويعتني بالتوسع التلقائي استنادًا إلى التكوين المحدد.
- RayJob: يكون مفيدًا عندما يكون لديك وظيفة لمرة واحدة ترغب في تشغيلها بدلاً من إبقاء RayCluster احتياطيًا قيد التشغيل طوال الوقت. ينشئ RayCluster ويقدم الوظيفة عند الاستعداد. بمجرد الانتهاء من الوظيفة، يتم حذف RayCluster. يساعد ذلك في إعادة تدوير RayCluster تلقائيًا.
- RayService: ينشئ هذا أيضًا RayCluster ولكنه ينشر تطبيق RayServe عليه. يجعل هذا CRD من الممكن إجراء تحديثات في المكان على التطبيق، مما يوفر ترقيات وتحديثات بدون توقف لضمان التوافر العالي للتطبيق.
حالات استخدام KubeRay
نشر نموذج عند الطلب باستخدام RayService
يسمح لك RayService بنشر النماذج عند الطلب في بيئة Kubernetes. يمكن أن يكون ذلك مفيدًا بشكل خاص للتطبيقات مثل توليد الصور أو استخراج النصوص، حيث يتم نشر النماذج فقط عند الحاجة.
إليك مثال على الانتشار المستقر. بمجرد تطبيقه في Kubernetes، سوف ينشئ RayCluster ويشغل أيضًا RayService، الذي سيخدم النموذج حتى تقوم بحذف هذه المورد. يتيح للمستخدمين التحكم في الموارد.
تدريب نموذج على مجموعة معالجة الرسومات باستخدام RayJob
يخدم RayService متطلبات مختلفة للمستخدم، حيث يحتفظ بالنموذج أو التطبيق المنتشر حتى يتم حذفه يدويًا. بالمقابل، يسمح RayJob بالوظائف لمرة واحدة لحالات الاستخدام مثل تدريب نموذج، معالجة البيانات، أو استنتاج لعدد ثابت من الاستفسارات المعطاة.
تشغيل خادم الاستنتاج على Kubernetes باستخدام RayService أو RayJob
عمومًا، نقوم بتشغيل تطبيقنا في النشرات، التي تحافظ على التحديثات المتداولة من دون انقطاع. وبالمثل، في KubeRay، يمكن تحقيق ذلك باستخدام RayService، الذي ينشر النموذج أو التطبيق ويتعامل مع التحديثات المتداولة.
ومع ذلك، قد تكون هناك حالات حيث ترغب فقط في إجراء استنتاج دفعي بدلاً من تشغيل خوادم الاستنتاج أو التطبيقات لفترة طويلة. هنا يمكنك الاستفادة من RayJob، الذي يشبه مورد الوظيفة في Kubernetes.
استنتاج دفعي لتصنيف الصور باستخدام Huggingface Vision Transformer هو مثال على RayJob، الذي يقوم بالاستنتاج الدفعي.
هذه هي حالات استخدام KubeRay، التي تمكنك من القيام بالمزيد باستخدام مجموعة Kubernetes. بمساعدة KubeRay، يمكنك تشغيل أعباء عمل مختلطة على نفس مجموعة Kubernetes وتفويض جدولة الأعباء العاملة بالمعالجات الرسومية إلى Ray.
الاستنتاج
تقدم المعالجة الموزعة المتوازية حلاً قابلاً للتوسع للتعامل مع المهام كبيرة الحجم والتي تتطلب موارد كثيفة. يبسط Ray تعقيدات بناء التطبيقات الموزعة، بينما يدمج KubeRay Ray مع Kubernetes لتمكين النشر والتوسع بسلاسة. يعزز هذا المزيج الأداء والقابلية للتوسع وتحمل الأخطاء، مما يجعله مثالياً لعمليات الزحف على الويب، وتحليل البيانات، ومهام التعلم الآلي. من خلال الاستفادة من Ray وKubeRay، يمكنك إدارة الحوسبة الموزعة بكفاءة، مما يلبي متطلبات عالم اليوم المدفوع بالبيانات بسهولة.
ليس ذلك فحسب، بل مع تغير أنواع موارد الحوسبة لدينا من CPU إلى GPU، يصبح من المهم أن يكون لدينا بنية تحتية سحابية فعالة وقابلة للتوسع لجميع أنواع التطبيقات، سواء كانت ذكاءً اصطناعيًا أو معالجة بيانات كبيرة.
إذا وجدت هذه المقالة مفيدة وجذابة. أود أن أسمع آرائك حول هذه المقالة، لذا ابدأ محادثة على LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray