













نظام RAG يجمع بين قوة الآليات الاسترجاعية والنماذج اللغوية، ويمكّنهما من توليد ردود فعل ذات معنى متعلق بالسياق ومرتبطة بشكل جيد. ومع ذلك، قد يكون تقييم أداء نظام RAG وتحديد نقاط فشل محتملة من الصعب للغاية.
وبالتالي، فإن RAG Triad – ترادف من المقاييس التي توفر ثلاث خطوات رئيسية لتنفيذ نظام RAG: أهمية السياق، الارتباط المادي، وأهمية الإجابة. في هذا المنشور المدوني، سأستعرض تعقيدات RAG Triad، وأرشدكم عبر عملية إعداد وتنفيذ وتحليل تقييم نظام RAG.
مقدمة لـ RAG Triad:
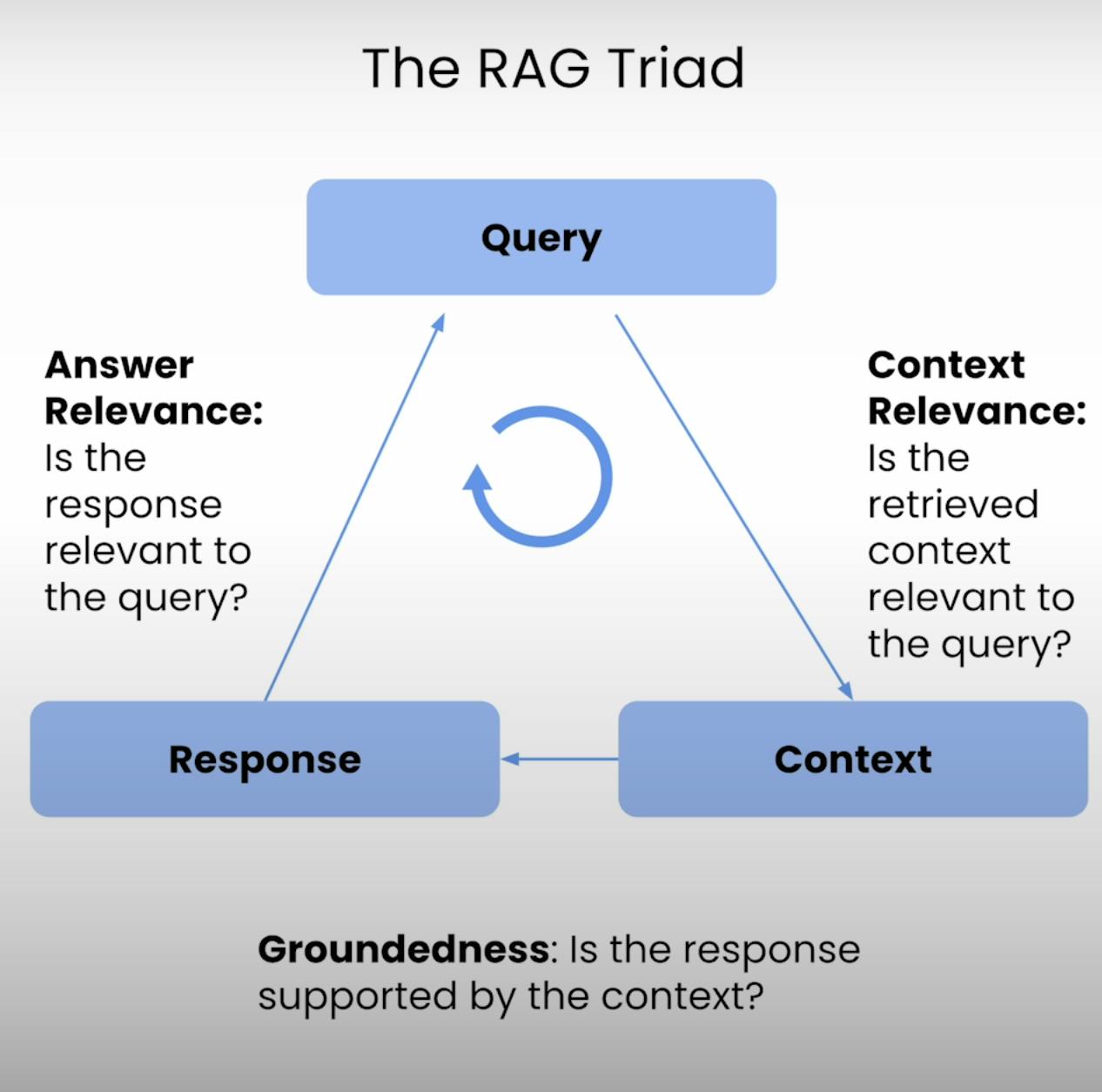
في قلب كل نظام RAG توجد توازن دقيق بين الاسترجاع والتوليد. RAG Triad يوفر إطارًا شاملًا لتقييم الجودة والنقاط المحتملة للفشل في هذا التوازن. دعونا ننشر المكونات الثلاثة.
A. Context Relevance:
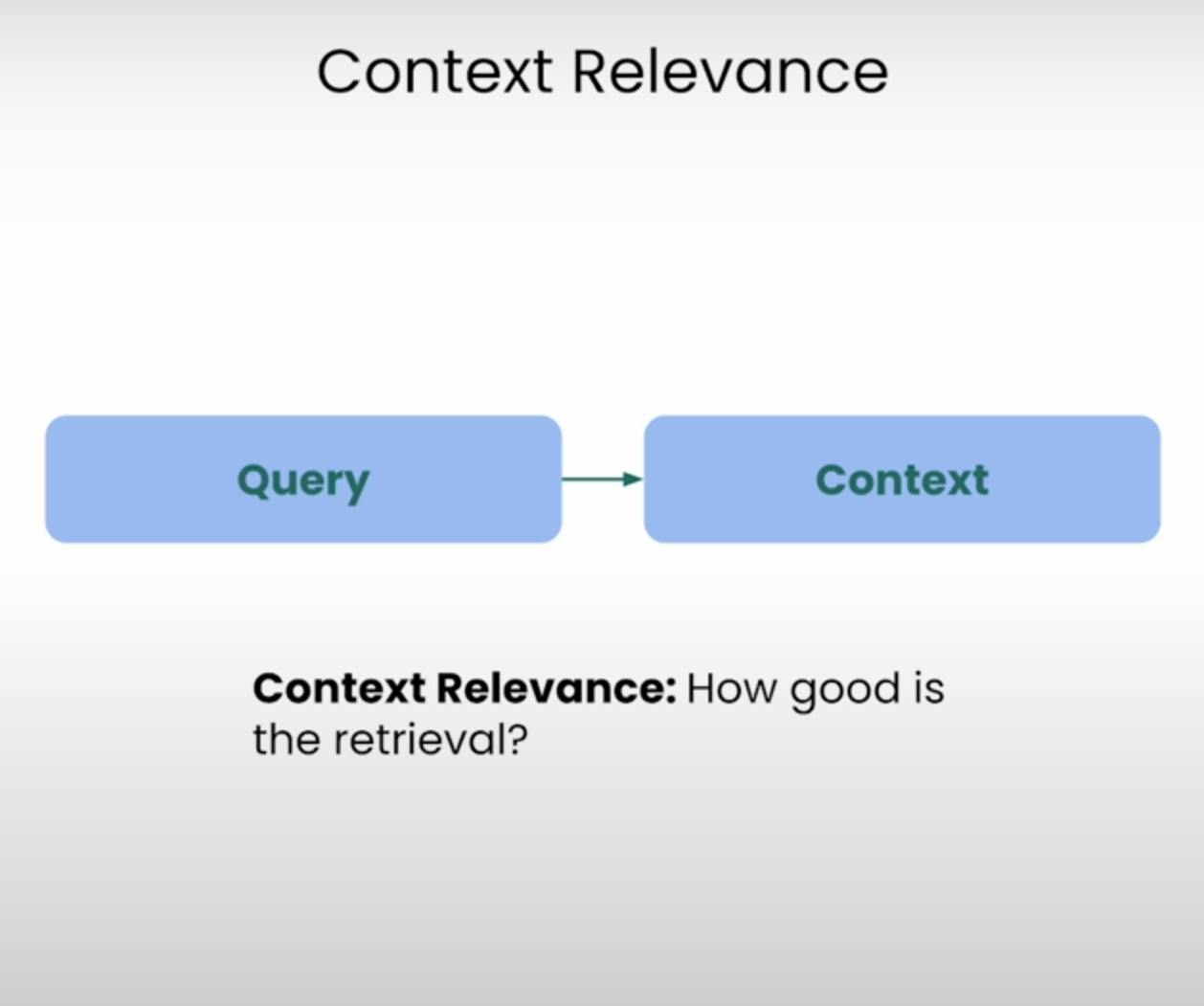
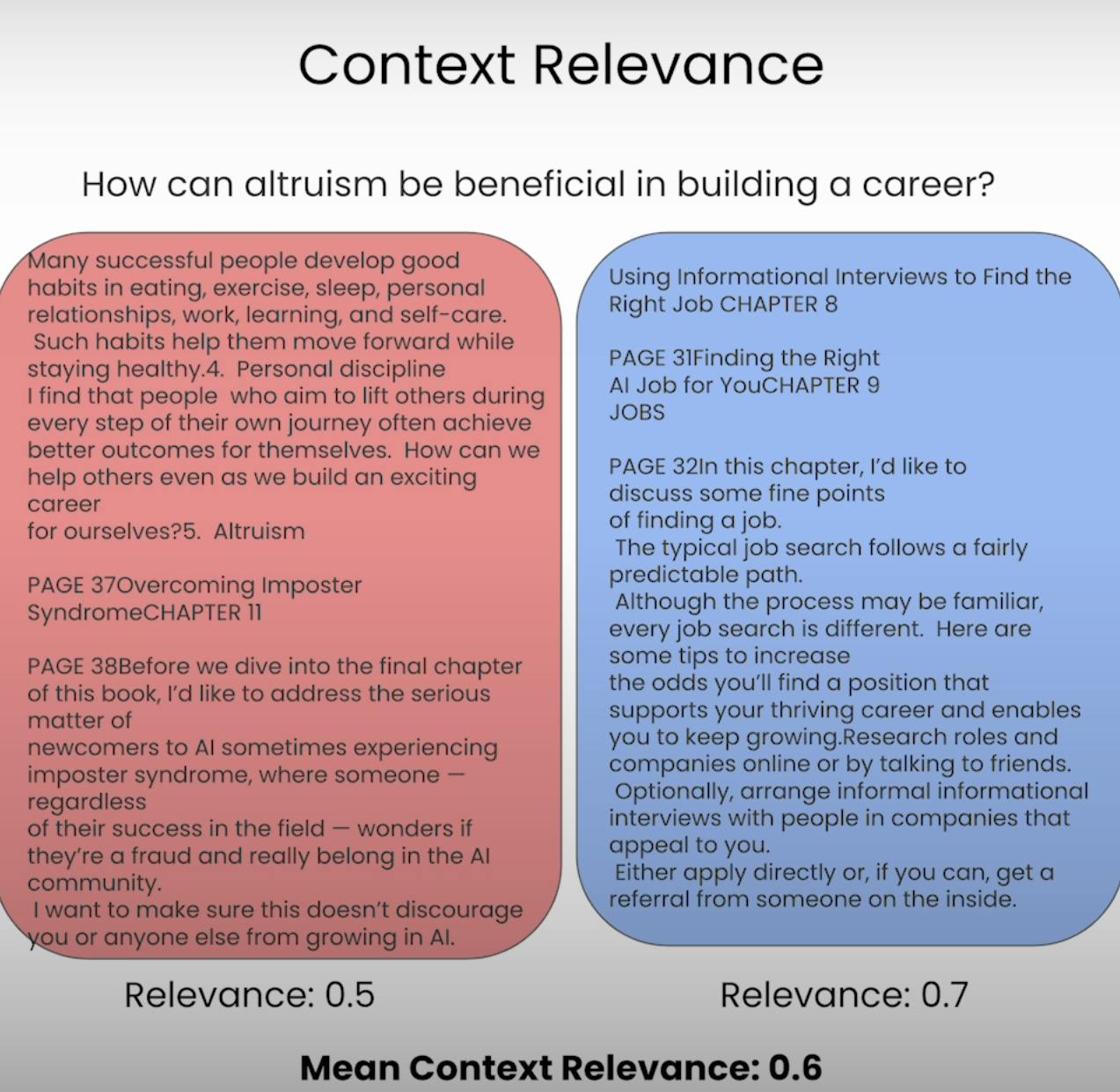
تخيل أنك متوقع أن تجيب على سؤال، لكن المعلومات التي تلقيتها غير ذات صلة تمامًا. هذا بالضبط ما يهدف نظام RAG لتجنبه. تقييم أهمية السياق يقيس جودة العملية الاسترجاعية من خلال تقييم مدى أهمية كل قطعة من السياق المسترجع إلى الاستفسار الأصلي. من خلال تسجيل درجة أهمية السياق المسترجع، يمكننا تحديد القضايا المحتملة في الآلية الاسترجاعية وتعديل ما يلزم.

B. Groundedness:
هل سبق لك أن خضعت لمحادثة حيث بدا أن شخصًا ما يختلق الحقائق أو يقدم معلومات بدون أساس صلب؟ هذا يعادل نظام RAG يفتقر إلى التأصيل. التأصيل يقيم ما إذا كانت الاستجابة النهائية التي يولدها النظام مرتبطة بشكل جيد بالسياق المسترجع. إذا كانت الاستجابة تحتوي على عبارات أو ادعاءات غير مدعومة بالمعلومات المسترجعة، قد يكون النظام يهذب أو يعتمد بشدة على بياناته المدربة مسبقًا، مما يؤدي إلى عدم دقة أو تحيز محتملين.
C. Answer Relevance:
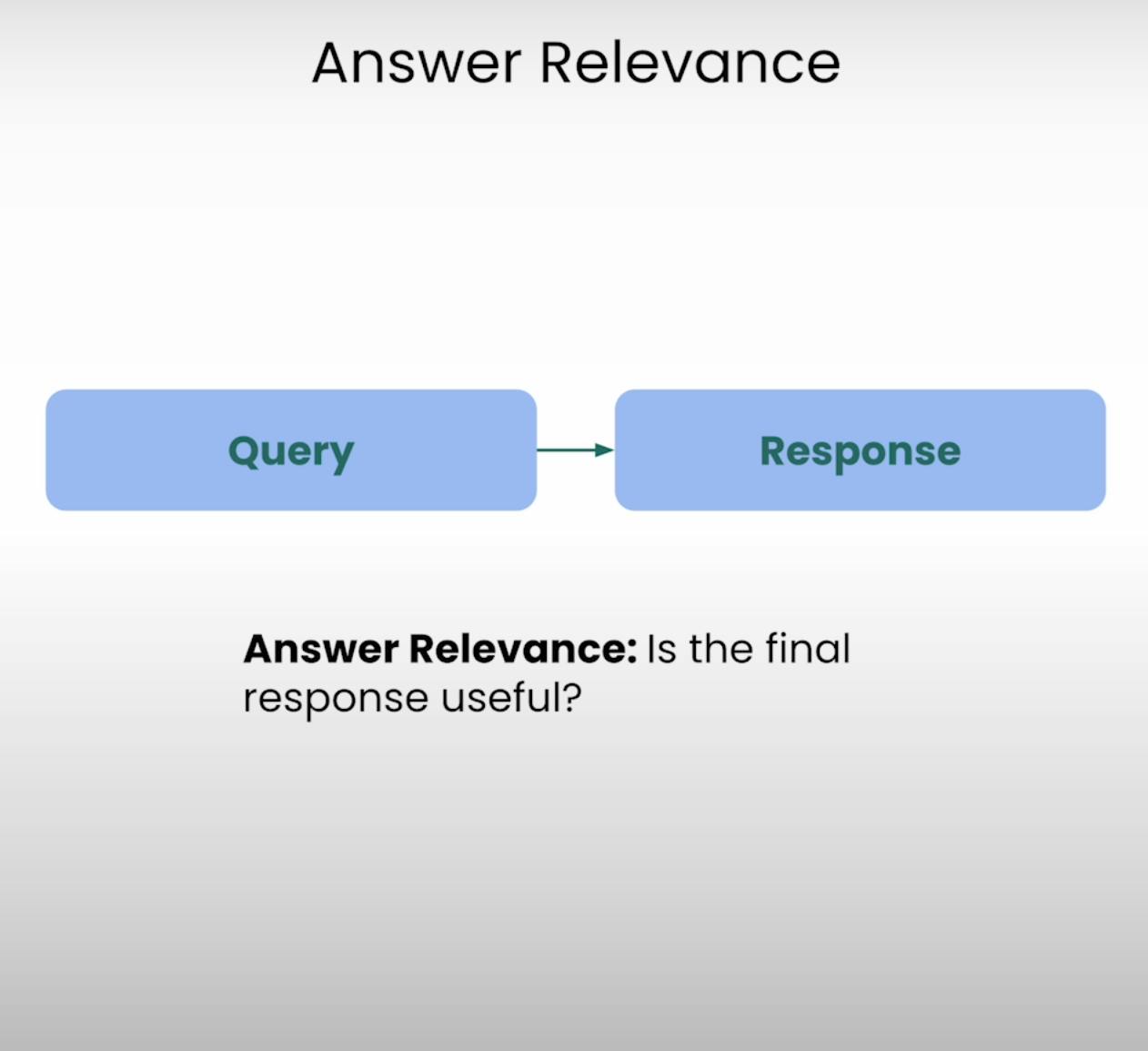
تخيل أنك تسأل عن الاتجاهات إلى أقرب مقهى وتتلقى وصفة تفصيلية لخبز كعكة. هذا هو نوع الموقف الذي يهدف Answer Relevance لمنعه. هذا الجزء من مثلث RAG يقيم ما إذا كانت الاستجابة النهائية التي يولدها النظام ذات صلة فعلية بالاستفسار الأصلي. من خلال تقييم صلة الجواب، يمكننا تحديد الحالات التي قد يكون فيها النظام قد أساء فهم السؤال أو انحرف عن الموضوع المقصود.

إعداد تقييم مثلث RAG
قبل أن نتعمق في عملية التقييم، نحتاج إلى تأسيس الأساس. دعونا نستعرض الخطوات اللازمة لإعداد تقييم مثلث RAG.
A. Importing Libraries and Establishing API Keys:
أولاً، نحتاج إلى استيراد المكتبات والوحدات اللازمة، بما في ذلك مفتاح API لـ OpenAI ومزود LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
بعد ذلك، سنقوم بتحميل وفهرسة مجموعة الوثائق التي سيعمل بها نظام RAG. في حالتنا، سنستخدم وثيقة PDF حول “كيفية بناء مهنة في الذكاء الاصطناعي” لأندرو جي.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

في صلب تقييم المثلث RAG توجد وظائف التعليق – وظائف متخصصة تقيم كل مكون من مكونات المثلث. دعونا نعرف هذه الوظائف باستخدام مكتبة TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
تنفيذ تطبيق RAG وتقييمه
بعد الانتهاء من الإعداد، حان الوقت لوضع نظامنا RAG وإطار التقييم في العمل. دعونا نروي الخطوات المتضمنة في تنفيذ التطبيق وتسجيل نتائج التقييم.
A. Preparing the Evaluation Questions:
أولاً، سنقوم بتحميل مجموعة من الأسئلة التي نرغب في أن يجيب عليها نظامنا RAG. ستكون هذه الأسئلة الأساس لعملية التقييم.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
بعد ذلك، سنقوم بإعداد جهاز تسجيل TrueLens، الذي سيساعدنا على تسجيل الموجهات، الردود، ونتائج التقييم في قاعدة بيانات محلية.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
عندما يعمل تطبيق RAG على كل سؤال تقييمي، سيقوم جهاز تسجيل TrueLens بجمع الموجهات، الردود، النتائج المتوسطة، ودرجات التقييم، وتخزينها في قاعدة بيانات محلية للتحليل المستقبلي.
تحليل نتائج التقييم
مع البيانات التي تقييم في متناول اليد، حان الوقت للبحث في التحليل والحصول على رؤى. دعونا ننظر في طرق مختلفة يمكننا من خلالها تحليل النتائج وتحديد المناطق المحتملة للتحسين.
A. Examining Individual Record-Level Results:
في بعض الأحيان، الشيطان يكمن في التفاصيل. من خلال فحص نتائج السجلات الفردية، يمكننا الوصول إلى فهم أعمق للقوى والضعفاء في نظام RAG.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
هذا المقطع البرمجي يمنحنا الوصول إلى الموجهات، الردود، ودرجات التقييم لكل سجل فردي، مما يسمح لنا بتحديد الحالات المحددة حيث ربما واجه النظام بعض الصعوبة أو تفوق.
B. Viewing Aggregate Performance Metrics:
لنتراجع قليلاً وننظر إلى الصورة الكاملة. توفر لنا مكتبة TrueLens لوحة المعارك التي تجمع بين مقاييس الأداء عبر جميع السجلات، مما يمنحنا نظرة من عالي المستوى لأداء نظام RAG الخاص بنا.
tru.get_leaderboard(app_ids=[])
تعرض هذه اللوحة المتوسط للنقاط لكل مكون من ثلاثي RAG، إلى جانب مقاييس مثل اللحظة المتأخرة والتكلفة. من خلال تحليل هذه المقاييس المجمعة، يمكننا تحديد الاتجاهات والأنماط التي قد لا تكون واضحة في مستوى السجل.
C. Exploring the TrueLens Streamlit Dashboard:
بالإضافة إلى واجهة الأوامر النصية، تقدم TrueLens أيضًا tableau Streamlit يوفر واجهة مرئية لاستكشاف وتحليل نتائج التقييم. ببضع أوامر بسيطة، يمكننا بدء تشغيل اللوحة.
tru.run_dashboard()
بمجرد أن يكون اللوحة قيد التشغيل، نرى نظرة موجزة شاملة على أداء نظام RAG الخاص بنا. بنظرة واحدة، يمكننا رؤية المقاييس المجمعة لكل مكون من ثلاثي RAG، وكذلك معلومات حول اللحظة المتأخرة والتكلفة.
من خلال تحديد تطبيقنا من قائمة التبويب المنسدلة، يمكننا الوصول إلى نظرة مفصلة عن مستوى السجل لنتائج التقييم. يتم عرض كل سجل بدقة، بما في ذلك محرك البحث الإدخال الموجه للمستخدم، رد نظام RAG، والنقاط المقابلة للصلة المتعلقة بالإجابة، والسياق، والترابط.
بالنقر على سجل فردي يكشف المزيد من الرؤى. يمكننا استكشاف سلسلة الفكر الوجهة وراء كل درجة تقييم، موضحًا عملية التفكير للنموذج اللغوي الذي يؤدي التقييم. هذا المستوى من الشفافية مفيد لتحديد النماذج الفشل المحتملة والمجالات للتحسين.
لنقل إننا نصادف سجلًا حيث تكون درجة التأصيل منخفضة. من خلال النظر إلى التفاصيل، قد نكتشف أن رد فعل نظام RAG يحتوي على بيانات ليست متأصلة بشكل جيد في السياق المسترجع. ستظهر لنا اللوحة الإعدادية بالضبط أي بيانات تفتقر إلى دليل مؤيد، مما يسمح لنا بتحديد سبب أساسي للمشكلة.
لوحة TrueLens Streamlit هي أكثر من مجرد أداة للتصور. باستخدام قدراتها التفاعلية والرؤى القائمة على البيانات، يمكننا اتخاذ قرارات مستنيرة والتصرفات المستهدفة لتعزيز أداء تطبيقاتنا.
تقنيات RAG المتقدمة والتحسين التكراري
A. Introducing the Sentence Window RAG Technique:
تقنية واحدة متقدمة هي RAG الناقل الجملة، التي تعالج نمط فشل شائع في أنظمة RAG: حجم السياق المحدود. من خلال زيادة حجم نافذة السياق، يهدف RAG الناقل الجملة إلى تزويد نموذج اللغة بمعلومات ذات صلة وشاملة أكثر، مما قد يحسن من جودة السياق والتأصيل للنظام.
B. Re-evaluating with the RAG Triad:
بعد تطبيق تقنية RAG الناقل الجملة، يمكننا اختبارها من خلال إعادة التraisal باستخدام نفس إطار RAG Triad. هذه المرة، سنركز انتباهنا على درجات الصلة والتأصيل في السياق، بحثًا عن تحسنات في هذه المجالات نتيجة لزيادة حجم السياق.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
في حين يمكن لتقنية RAG الناقل الجملة تحسين الأداء ربما، فإن الحجم الأمثل للنافذة قد يختلف اعتمادًا على الحالة الفعلية والمجموعة التعليمية المحددة. حجم النافذة الصغير جدًا قد لا يوفر ما يكفي من السياق ذي الصلة، بينما قد يضيف حجم النافذة الكبير جدًا معلومات غير ذات صلة، مما يؤثر على التأصيل وصلة الإجابة للنظام.
بتجربة انواع مختلفة من أحجام النوافذ وإعادة التقييم باستخدام مثلث RAG، يمكننا العثور على النقطة الحلوة التي توازن بين علاقة السياق بالمحتوى مع التأصيل وعلاقة الإجابة بالمحتوى، مما يؤدي في النهاية إلى نظام RAG أكثر قوة وموثوقية.
الخاتمة:
ثلاثي RAG، الذي يتألف من العلاقة بالسياق، التأصيل، والعلاقة بالإجابة، ثبت أنه إطار مفيد لتقييم الأداء وتحديد أنماط الفشل المحتملة في أنظمة التوليف التي تعزز بالاستعارة.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems