













لديكم إدارة تود معرفة كل شيء عن الشركة من حيث التمويل والإنتاجية ولكن لا ترغب في إنفاق أي مبلغ على أدوات إدارة تقنية المعلومات عالية المستوى؟ لا تقوموا باللجوء إلى أدوات مختلفة لأنظمة المخزون والفواتير ونظم التذاكر. ما تحتاجونه فقط هو نظام مركزي واحد. لماذا لا تفكرون في باور بي آي بيثون؟
يمكن لـ باور بي آي تحويل المهام المملة والمستهلكة للوقت إلى عملية آلية. وفي هذا البرنامج التعليمي، ستتعلم كيفية تقطيع ودمج بياناتك بطرق لم تكن تتخيلها.
هيا، وانقذ نفسك من التوتر الذي ينجم عن تصفح التقارير المعقدة!
المتطلبات المسبقة
سيكون هذا البرنامج التعليمي عرضًا تطبيقيًا عمليًا. إذا كنت ترغب في متابعته، تأكد من أن لديك ما يلي:
- اشتراك في باور بي آي – التجربة المجانية ستكون كافية.
- A Windows Server – This tutorial uses a Windows Server 2022.
- باور بي آي ديسكتوب مثبت على خادم Windows الخاص بك – يستخدم هذا البرنامج التعليمي باور بي آي ديسكتوب v2.105.664.0.
- خادم MySQL مثبت – يستخدم هذا البرنامج التعليمي خادم MySQL v8.0.29.
- بوابة بيانات داخلية مثبتة على الأجهزة الخارجية التي تخطط لاستخدام الإصدار السطحي.
- متجر الكود المرئي (VS Code) – يستخدم هذا البرنامج التعليمي إصدار VS Code v17.2
- Python v3.6 أو أحدث مثبت – يستخدم هذا البرنامج التعليمي Python v3.10.5.
- DBeaver مثبت – يستخدم هذا البرنامج التعليمي DBeaver v22.0.2.
بناء قاعدة بيانات MySQL
يمكن لـ Power BI تصور البيانات بشكل جميل، ولكن عليك استرجاعها وتخزينها قبل الوصول إلى تصور البيانات. أحد أفضل الطرق لتخزين البيانات هو في قاعدة بيانات. MySQL هو أداة قاعدة بيانات مجانية وقوية.
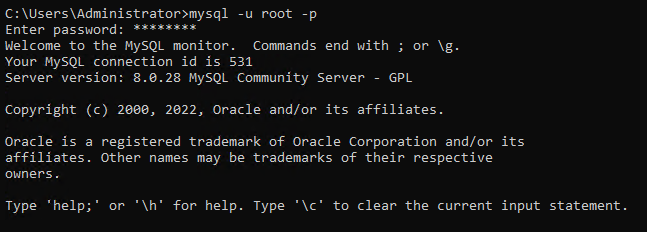
1. افتح موجه الأوامر كمسؤول، قم بتشغيل الأمر mysql أدناه وأدخل اسم المستخدم الرئيسي (-u) وكلمة المرور (-p) عندما يُطلب.
بشكل افتراضي، يمتلك مستخدم الجذر فقط الإذن لإجراء تغييرات على قاعدة البيانات.
2. بعد ذلك، قم بتشغيل الاستعلام أدناه لإنشاء مستخدم قاعدة بيانات جديد (CREATE USER) بكلمة مرور (IDENTIFIED BY). يمكنك تسمية المستخدم بشكل مختلف، ولكن اختيار هذا البرنامج التعليمي هو ata_levi.

3. بعد إنشاء مستخدم، قم بتشغيل الاستعلام أدناه لمنح أذونات المستخدم الجديد (ALL PRIVILEGES)، مثل إنشاء قاعدة بيانات على الخادم.

4. الآن، قم بتشغيل الأمر \q أدناه لتسجيل الخروج من MySQL.

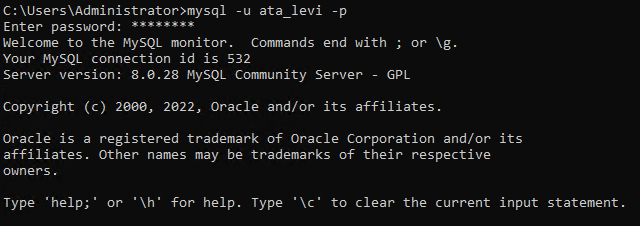
5. قم بتشغيل الأمر mysql أدناه لتسجيل الدخول كمستخدم قاعدة بيانات تم إنشاؤه حديثًا (ata_levi).
6. أخيرًا، قم بتشغيل الاستعلام التالي لإنشاء قاعدة بيانات جديدة تسمى ata_database. ولكن بالطبع، يمكنك تسمية قاعدة البيانات بشكل مختلف.

إدارة قواعد بيانات MySQL باستخدام DBeaver
عند إدارة قواعد البيانات، عادةً ما تحتاج إلى معرفة SQL. ولكن مع DBeaver، لديك واجهة رسومية لإدارة قواعد البيانات الخاصة بك ببضع نقرات، وسيقوم DBeaver بالعناية بالبيانات SQL بالنيابة عنك.
1. افتح DBeaver من سطح المكتب الخاص بك أو من قائمة “ابدأ”.
2. عند فتح DBeaver، انقر فوق القائمة المنسدلة “اتصال قاعدة بيانات جديد” وحدد MySQL لبدء الاتصال بخادم MySQL الخاص بك.
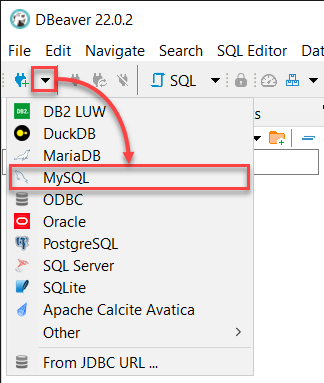
3. قم بتسجيل الدخول إلى خادم MySQL المحلي الخاص بك باستخدام البيانات التالية:
- احتفظ بـ اسم المضيف كـ localhost و المنفذ عند 3306 لأنك تقوم بالاتصال بخادم محلي.
- قم بتوفير بيانات اعتماد مستخدم ata_levi (اسم المستخدم وكلمة المرور) من الخطوة الثانية في قسم “بناء قاعدة بيانات MySQL”، وانقر على “إنهاء” لتسجيل الدخول إلى MySQL.
4. الآن، قم بتوسيع قاعدة البيانات (ata_database) تحت المستكشف قاعدة البيانات (لوحة الجانب الأيسر) → انقر بزر الماوس الأيمن على الجداول، واختر إنشاء جدول جديد لبدء إنشاء جدول جديد.
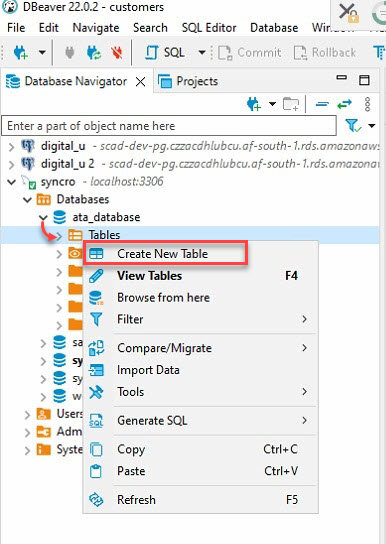
5. قم بتسمية الجدول الجديد الخاص بك، ولكن اختيار هذا البرنامج التعليمي هو ata_Table، كما هو موضح أدناه.
تأكد من أن اسم الجدول يتطابق مع اسم الجدول الذي ستحدده في طريقة to_sql (“اسم الجدول”) في الخطوة السابعة من قسم “الحصول واستهلاك بيانات واجهة برمجة التطبيقات”.
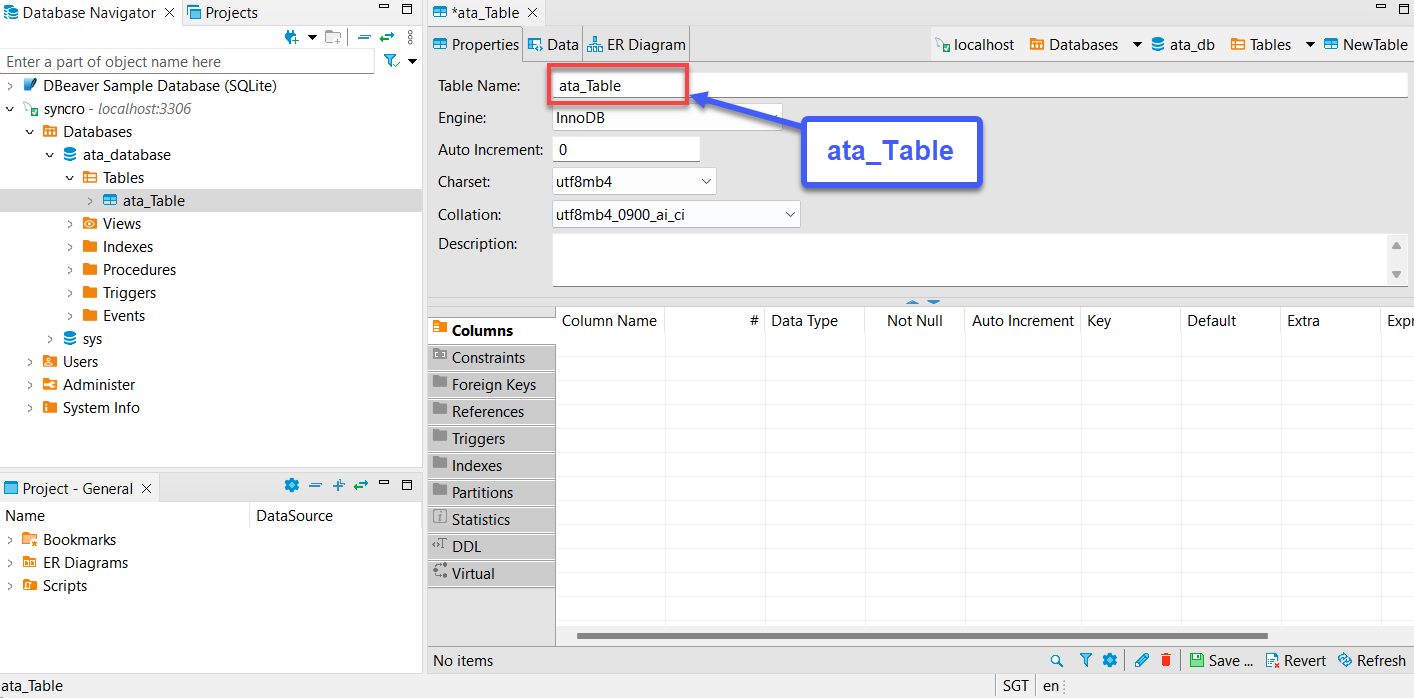
6. بعد ذلك، قم بتوسيع الجدول الجديد (ata_table) → انقر بزر الماوس الأيمن فوق الأعمدة → إنشاء عمود جديد لإنشاء عمود جديد.
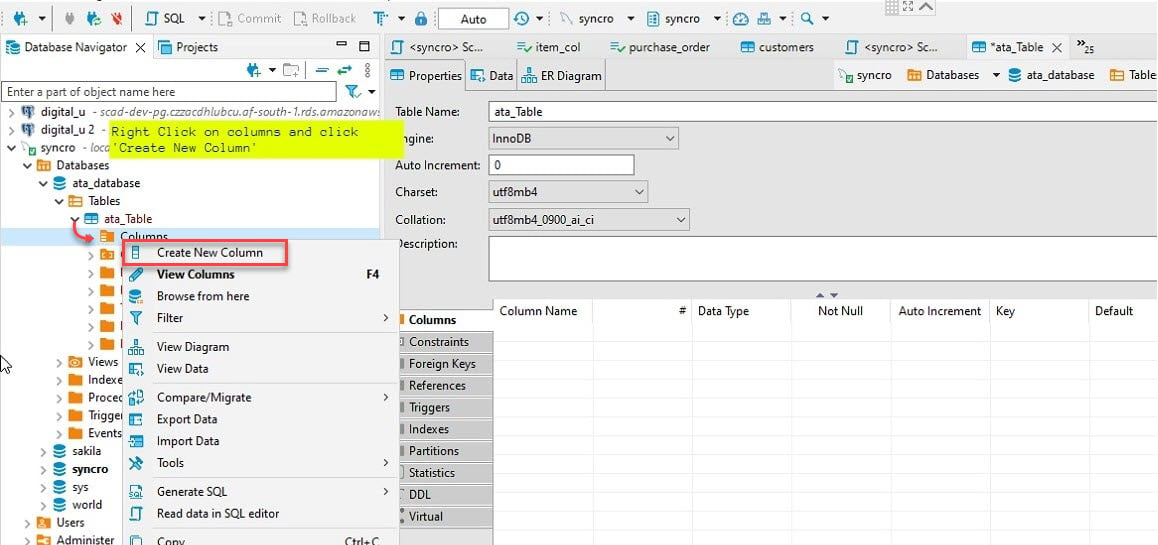
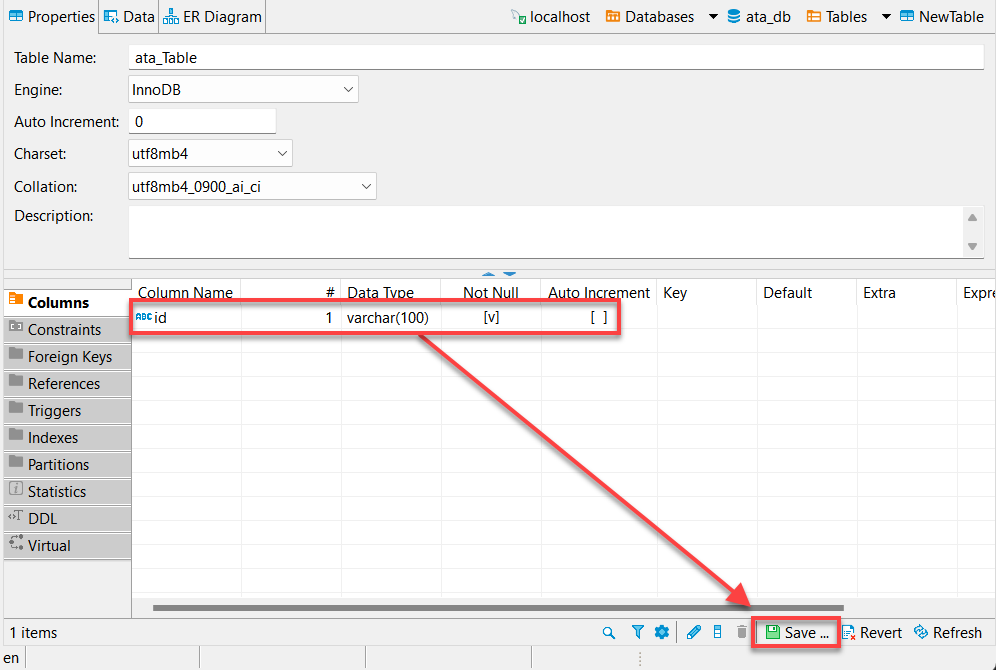
7. قم بتقديم اسم العمود، كما هو موضح أدناه، وحدد مربع Not Null، وانقر فوق موافق لإنشاء العمود الجديد.
في الواقع، سترغب في إضافة عمود يسمى “id”. لماذا؟ معظم واجهات برمجة التطبيقات ستحتوي على معرف، وستقوم إطار بيانات باندا الخاص بـ Python تلقائيًا بملء الأعمدة الأخرى.
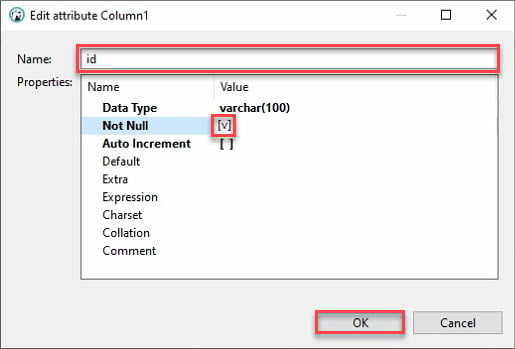
8. انقر فوق حفظ (أسفل اليمين) أو اضغط على Ctrl + S لحفظ التغييرات بمجرد التحقق من العمود الذي تم إنشاؤه حديثًا (id)، كما هو موضح أدناه.
9. أخيرًا، انقر فوق Persist للحفاظ على التغييرات التي قمت بها على قاعدة البيانات.
الحصول على بيانات واستهلاك واجهة برمجة التطبيقات
الآن بعد أن قمت بإنشاء قاعدة بيانات لتخزين البيانات، تحتاج إلى جلب البيانات من مزود واجهة برمجة التطبيقات الخاص بك ودفعها إلى قاعدة البيانات الخاصة بك باستخدام Python. ستستخدم بياناتك لتصورها على Power BI.
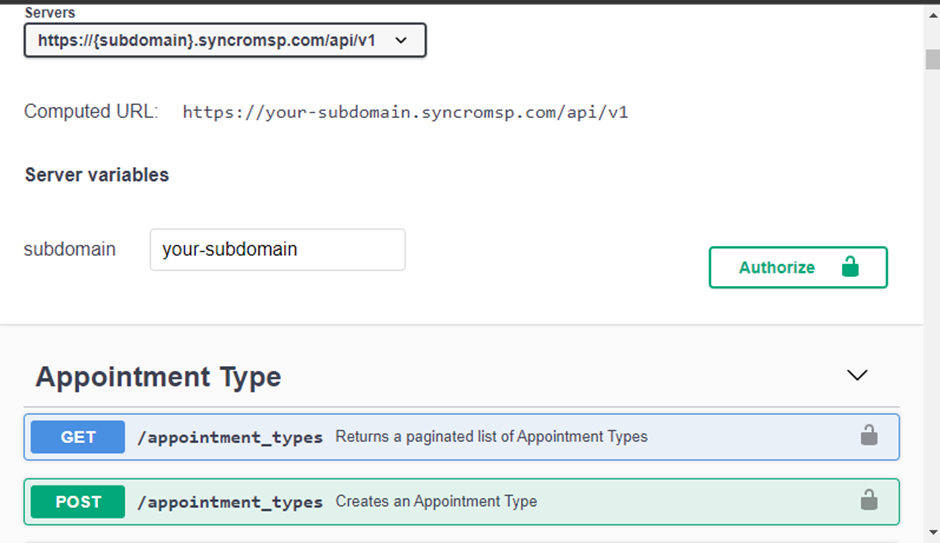
للاتصال بمزود واجهة برمجة التطبيقات الخاص بك، ستحتاج إلى ثلاث قطع رئيسية من المعلومات؛ طريقة الترخيص، عنوان URL الأساسي لواجهة برمجة التطبيقات، ونقطة النهاية لواجهة برمجة التطبيقات. إذا كنت غير متأكد من كيفية الحصول على هذه المعلومات، قم بزيارة موقع وثائق مزود واجهة برمجة التطبيقات الخاص بك.
أدناه صفحة توثيق من Syncro.
1. قم بفتح VS Code، أنشئ ملف Python وقم بتسمية الملف وفقًا لبيانات API المتوقعة من الملف. سيكون هذا الملف مسؤولًا عن جلب ودفع بيانات API إلى قاعدة البيانات الخاصة بك (اتصال قاعدة البيانات).
هناك العديد من مكتبات Python المتاحة للمساعدة في اتصال قاعدة البيانات، ولكنك ستستخدم SQLAlchemy في هذا البرنامج التعليمي.
قم بتشغيل الأمر أدناه في نافذة الأوامر في VS Code لتثبيت SQLAlchemy في بيئتك.

2. بعد ذلك، قم بإنشاء ملف يسمى connection.py، قم بملأ الكود أدناه، قم بتبديل القيم بما يتناسب، ثم احفظ الملف.
عندما تبدأ في كتابة النصوص للتفاعل مع قاعدة البيانات الخاصة بك، يجب إقامة اتصال بقاعدة البيانات قبل أن تقبل أي أمر من النص.
ولكن بدلاً من إعادة كتابة سلسلة اتصال قاعدة البيانات لكل نص تكتبه، يكرس الكود أدناه لإجراء هذا الاتصال بحيث يمكن استدعاؤه/الرجوع إليه من قبل نصوص أخرى.
3. افتح نافذة الأوامر في برنامج Visual Studio (Ctrl+Shift+`)، وقم بتشغيل الأوامر التالية لتثبيت pandas و requests.
4. قم بإنشاء ملف آخر بلغة Python يسمى invoices.py (أو اسمه بشكل مختلف)، واملأ الشفرة التالية في الملف.
سوف تضيف مقتطفات الشفرة إلى ملف invoices.py في كل خطوة تالية، ولكن يمكنك عرض الشفرة الكاملة على مستودع GitHub الخاص بـ ATA.
سيتم تشغيل النص البرمجي invoices.py من النص البرمجي الرئيسي الموضح في القسم التالي، الذي يستخرج بيانات API الأولى الخاصة بك.
الشفرة التالية تقوم بالأعمال التالية:
- تستهلك البيانات من API الخاص بك وتكتبها في قاعدة البيانات الخاصة بك.
- تستبدل طريقة التوثيق والمفتاح وعنوان URL الأساسي ونقاط نهاية الـ API ببيانات اعتماد مزود الـ API الخاص بك.
5. أضف مقتطف الشفرة التالي إلى الملف invoices.py لتعريف العناوين، على سبيل المثال:
- نوع تنسيق البيانات الذي تتوقع استلامه من API الخاص بك.
- يجب أن يرافق عنوان URL الأساسي ونقطة النهاية طريقة التوثيق والمفتاح المقابلين.
تأكد من تغيير القيم أدناه بالقيم الخاصة بك.
6. قم بإضافة الدالة الخاصة async التالية إلى ملف invoices.py.
يستخدم الكود أدناه AsyncIO لإدارة النصوص المتعددة من نص واحد رئيسي مشروح في الجزء التالي. عندما ينمو مشروعك ليشمل نقاط نهاية API متعددة ، فإنه من الممارسة الجيدة أن تكون للنصوص التي تستخدم API الخاص بك ملفاتها الخاصة.
7. أخيرًا ، قم بإضافة الكود أدناه إلى ملف invoices.py ، حيث تتعامل دالة get_pages مع ترقيم صفحات API الخاص بك.
تقوم هذه الدالة بإرجاع إجمالي عدد الصفحات في API الخاص بك وتساعد في استخدام دالة range في تكرار جميع الصفحات.
اتصل بمطوري API الخاص بك حول طريقة ترقيم الصفحات المستخدمة بواسطة مزود API الخاص بك.
إذا كنت تفضل إضافة مزيد من نقاط نهاية واجهة برمجة التطبيقات إلى بياناتك:
- كرر الخطوات من الرابعة إلى السادسة من قسم “إدارة قواعد البيانات MySQL باستخدام DBeaver”.
- كرر جميع الخطوات في قسم “الحصول على بيانات واجهة برمجة التطبيقات واستهلاكها”.
- قم بتغيير نقطة نهاية واجهة برمجة التطبيقات إلى أخرى ترغب في استهلاكها.
مزامنة نقاط نهاية واجهة برمجة التطبيقات
لديك الآن قاعدة بيانات واتصال بواجهة برمجة التطبيقات، وأنت جاهز لبدء استهلاك واجهة برمجة التطبيقات من خلال تشغيل الكود في ملف invoices.py. ولكن القيام بذلك سيقيدك إلى استهلاك نقطة نهاية واجهة برمجة التطبيقات واحدة في نفس الوقت.
كيفية التجاوز عن الحدود؟ ستقوم بإنشاء ملف Python آخر كملف مركزي يستدعي وظائف واجهة برمجة التطبيق (API) من ملفات Python المختلفة ويقوم بتشغيل الوظائف بشكل غير متزامن باستخدام AsyncIO. بهذه الطريقة ، تحافظ على نظافة برمجتك وتتيح لك تجميع العديد من الوظائف معًا.
1. قم بإنشاء ملف Python جديد يسمى central.py وأضف الكود أدناه.
تمامًا مثل ملف invoices.py ، ستقوم بإضافة مقتطفات الكود إلى ملف central.py في كل خطوة ، ولكن يمكنك عرض الشيفرة الكاملة على مستودع الشفرة الخاص بـ ATA على موقع GitHub.
الكود أدناه يستورد الوحدات الأساسية والنصوص من ملفات أخرى باستخدام بنية استيراد الوحدة
2. بعد ذلك ، أضف الكود التالي للتحكم في النصوص من ملف الفواتير في ملف central.py.
تحتاج إلى الإشارة/استدعاء الدالة call_invoices من ملف الفواتير إلى مهمة AsyncIO (invoice_task) في central.py.
3. بعد إنشاء مهمة AsyncIO، انتظر المهمة لاستدعاء وتنفيذ دالة call_invoices من invoice.py عندما يبدأ دالة chain (في الخطوة الثانية) في التشغيل.
4. إنشاء AsyncIOScheduler لجدولة وظيفة لتنفيذ البرنامج النصي. تقوم الوظيفة المضافة في هذا الكود بتشغيل دالة chain بفاصل زمني مقداره ثانية واحدة.
تعتبر هذه الوظيفة مهمة لضمان استمرار تشغيل البرنامج النصي وتحديث البيانات.
5. أخيرًا، قم بتشغيل البرنامج النصي central.py على VS Code، كما هو موضح أدناه.
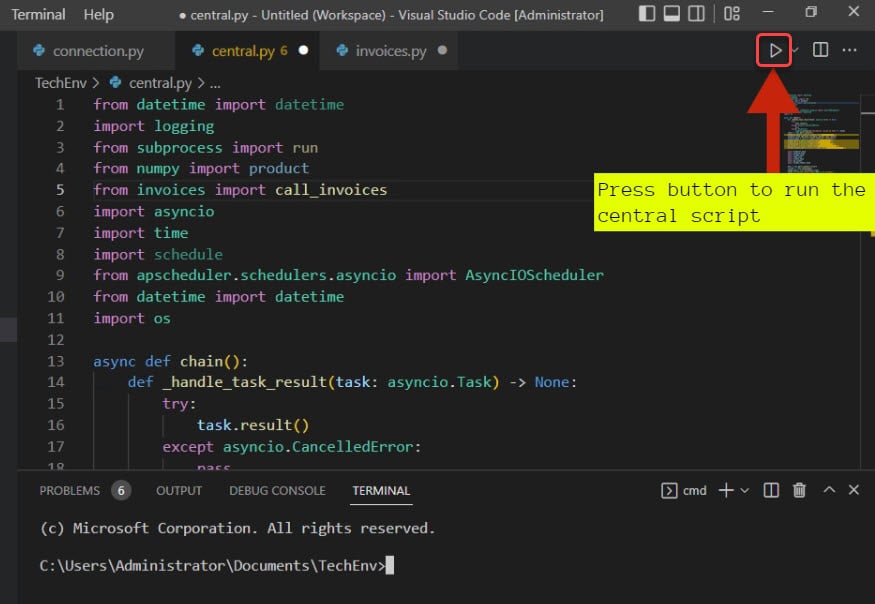
بعد تشغيل البرنامج النصي، سترى النتائج على الطرفية مثل النتيجة أدناه.
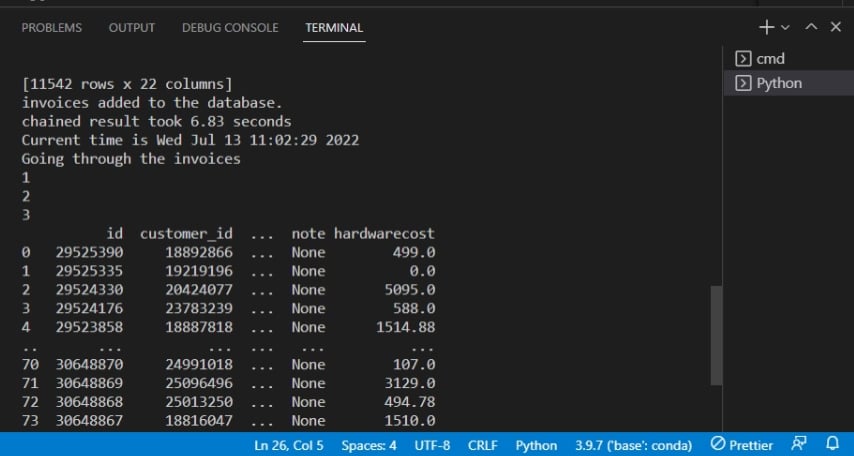
أدناه، تؤكد النتيجة أن الفواتير تمت إضافتها إلى قاعدة البيانات.
تطوير مرئيات Power BI
بعد كتابة برنامج يتصل ببيانات واجهة برمجة التطبيقات ويدفع هذه البيانات إلى قاعدة بيانات، أنت على استعداد تقريبًا لاستخدام بياناتك. ولكن أولاً، ستقوم بدفع البيانات في قاعدة البيانات إلى Power BI للتصور، وهو الهدف النهائي.
الكثير من البيانات غير مفيد إذا لم تتمكن من تصور البيانات وإجراء اتصالات عميقة. لحسن الحظ، فإن مرئيات Power BI تشبه الرسوم البيانية التي يمكن أن تجعل المعادلات الرياضية المعقدة تبدو بسيطة وقابلة للتنبؤ.
1. افتح Power BI من سطح المكتب أو قائمة البدء.
2. انقر فوق أيقونة مصدر البيانات أعلاه في القائمة المنسدلة “الحصول على البيانات” في النافذة الرئيسية لـ Power BI. تظهر نافذة منبثقة حيث يمكنك تحديد مصدر البيانات الذي ترغب في استخدامه (الخطوة الثالثة).
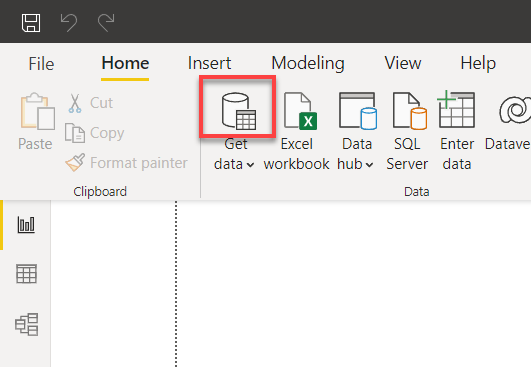
3. ابحث عن MySQL وحدد قاعدة بيانات MySQL ثم انقر على الاتصال للبدء في الاتصال بقاعدة بيانات MySQL الخاصة بك.
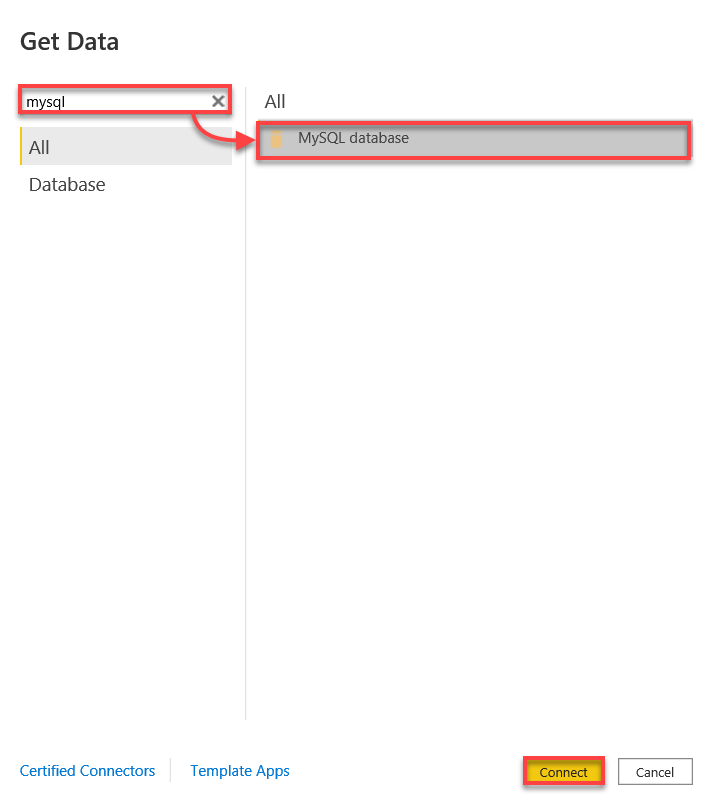
4. الآن، قم بالاتصال بقاعدة بيانات MySQL الخاصة بك باستخدام البيانات التالية:
- أدخل localhost:3306 لأنك تتصل بخادم MySQL المحلي الخاص بك على المنفذ 3306.
- قدم اسم قاعدة البيانات الخاصة بك، في هذه الحالة، ata_db.
- انقر فوق موافق للاتصال بقاعدة بيانات MySQL الخاصة بك.

5. الآن، انقر على تحويل البيانات (أسفل اليمين) لعرض نظرة عامة على البيانات في محرر الاستعلامات في Power BI (الخطوة الخامسة).

6. بعد معاينة مصدر البيانات، انقر على إغلاق وتطبيق للعودة إلى التطبيق الرئيسي وتأكيد ما إذا كانت هناك أي تغييرات تم تطبيقها.
يعرض محرر الاستعلامات الجداول من مصدر البيانات على الجانب الأيسر. في الوقت نفسه، يمكنك التحقق من تنسيق البيانات قبل المتابعة إلى التطبيق الرئيسي.
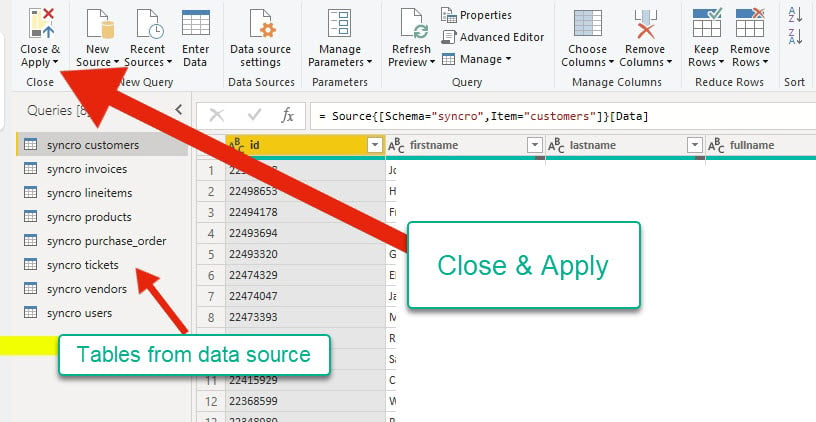
7. انقر على علامة تبويب أدوات الجدول، ثم حدد أي جدول في لوحة الحقول وانقر على إدارة العلاقات لفتح معالج العلاقات.
قبل إنشاء الرسوم البيانية، يجب التأكد من أن الجداول الخاصة بك متعلقة، لذا يجب تحديد أي علاقة بين الجداول بشكل صريح. لماذا؟ لأن Power BI لا يكتشف تلقائيًا الترابط المعقد بين الجداول بعد.

8. حدد علامات الصناديق للعلاقات الموجودة للتحرير، ثم انقر على تحرير. ستظهر نافذة منبثقة حيث يمكنك تحرير العلاقات المحددة (الخطوة التاسعة).
ولكن إذا كنت تفضل إضافة علاقة جديدة ، فانقر على “جديد” بدلاً من ذلك.
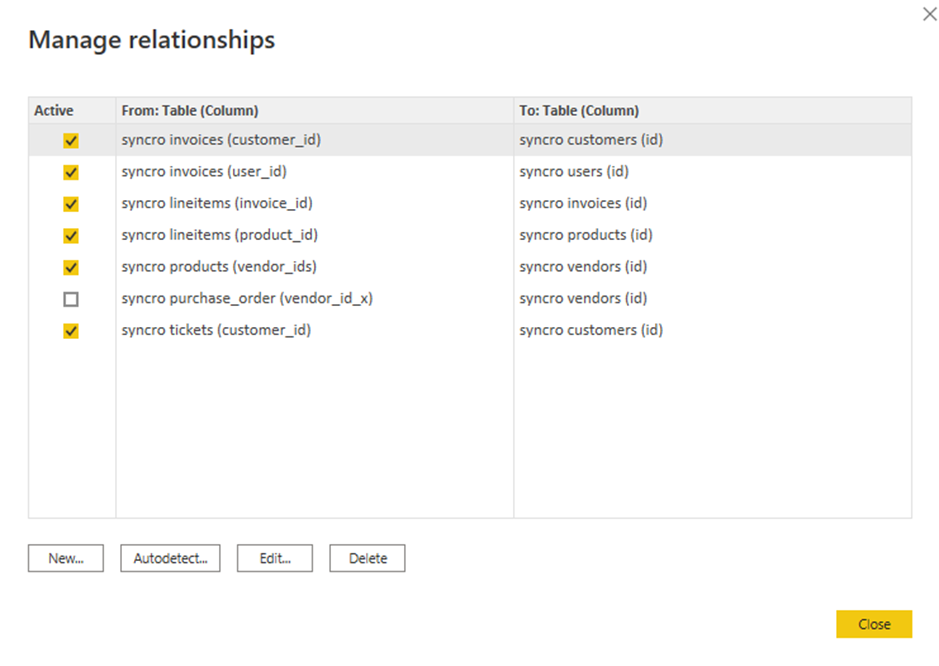
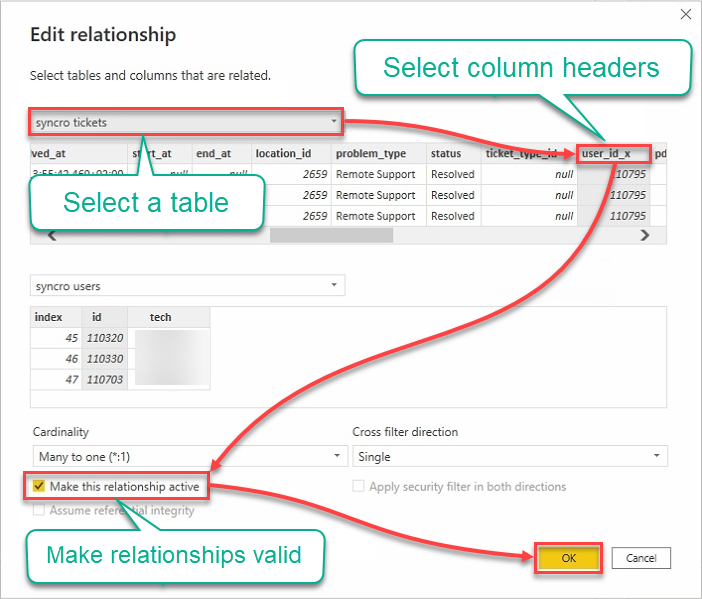
9. تحرير العلاقات باستخدام ما يلي:
- انقر فوق حقل القوائم المنسدلة للجداول وحدد جدولًا.
- انقر على الرؤوس لتحديد الأعمدة المراد استخدامها.
- حدد مربع “جعل هذه العلاقة نشطة” لضمان صحة العلاقات.
- انقر فوق موافق لإنشاء العلاقة وإغلاق نافذة تحرير العلاقة.
10. الآن ، انقر على نوع الجدول تحت لوحة التصورات (الأقصى اليمين) لإنشاء التصور الأول ، وسيظهر تصور الجدول الفارغ (الخطوة 11).
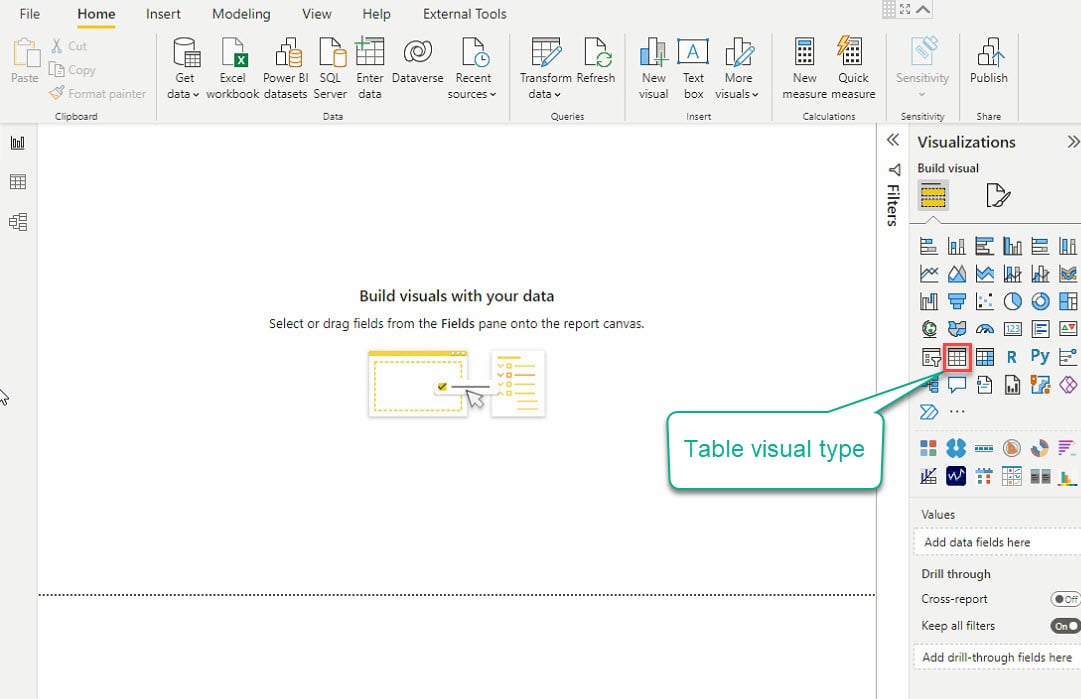
11. حدد التصور الجدول وحقول البيانات (في لوحة الحقول) لإضافتها إلى التصور الجدولي الخاص بك ، كما هو موضح أدناه.
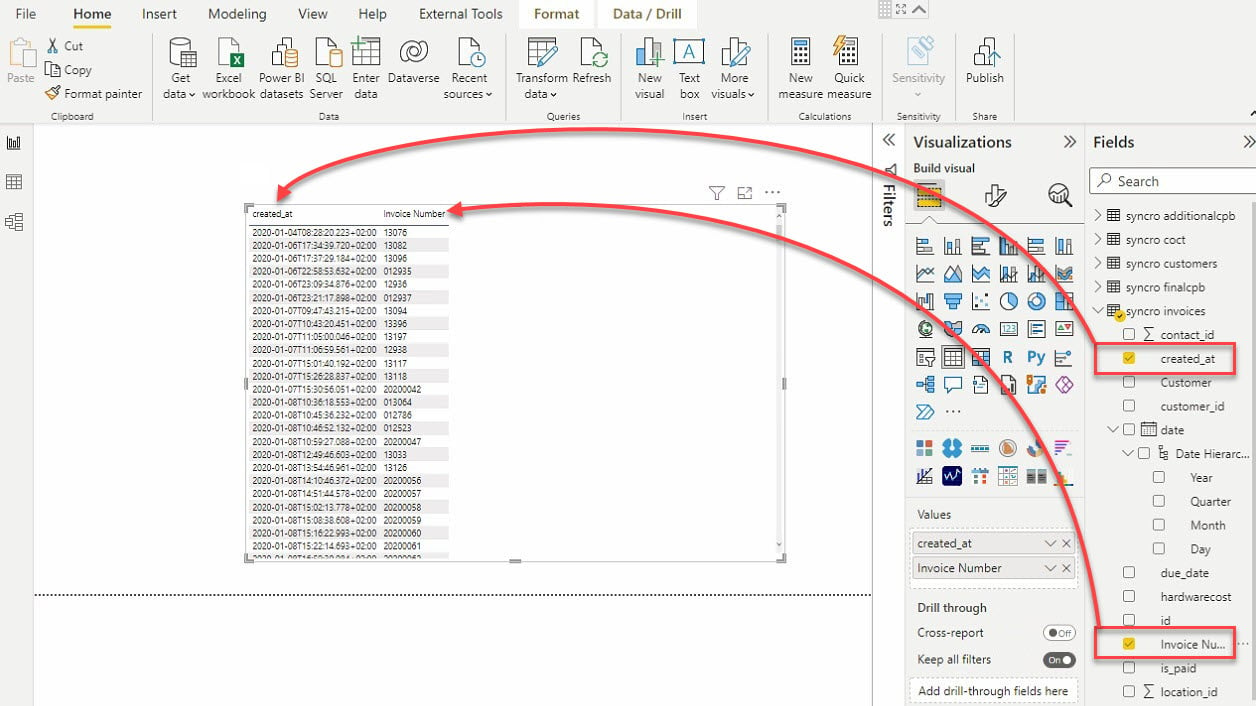
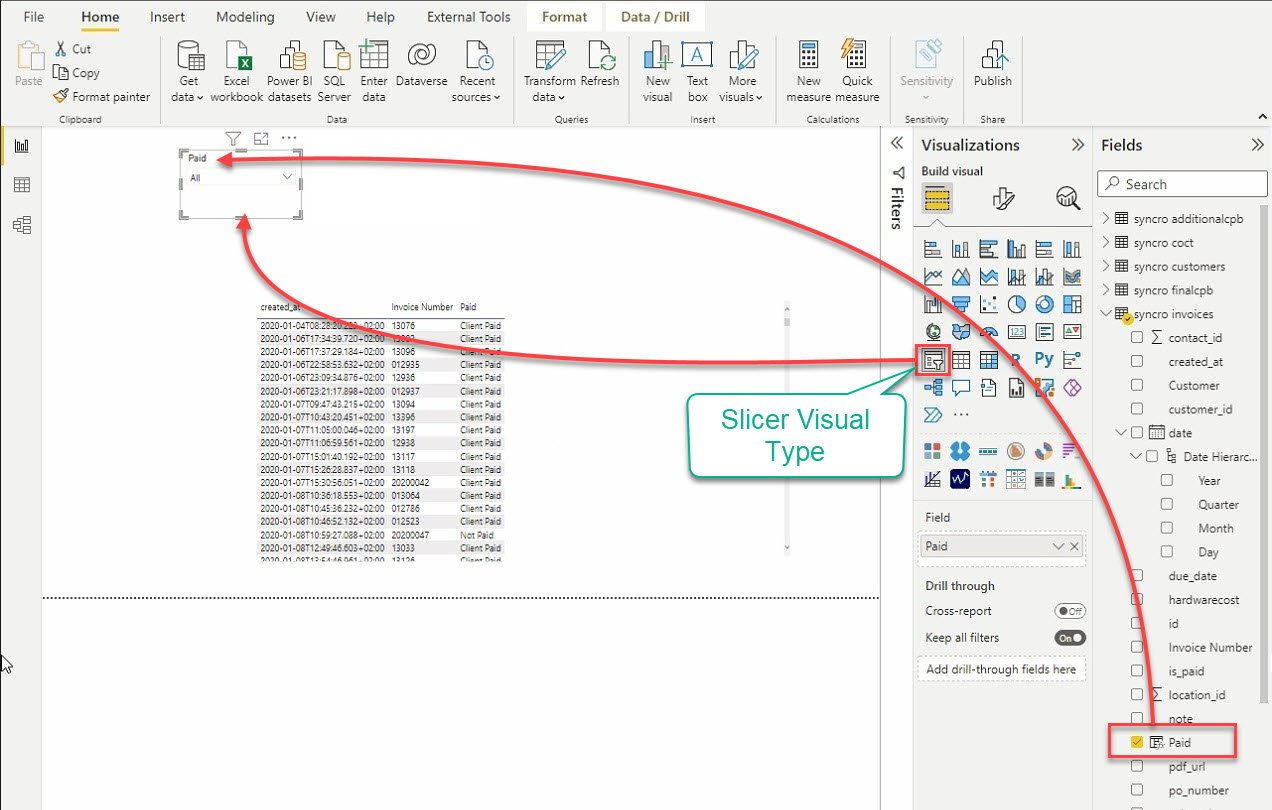
12. أخيرًا ، انقر على نوع التصور الفاصل لإضافة تصور آخر. كما يوحي الاسم ، يقوم التصور الفاصل بتقسيم البيانات من خلال تصفية التصورات الأخرى.
بعد إضافة التصور الفاصل ، حدد البيانات من لوحة الحقول لإضافتها إلى التصور الفاصل.
تغيير التصورات
مظاهر التصورات الافتراضية لطيفة جدًا. ولكن هل لا تكون رائعة إذا كنت تستطيع تغيير مظهر التصورات إلى شيء غير ممل؟ اسمح لـ Power BI أن يتولى الأمر.
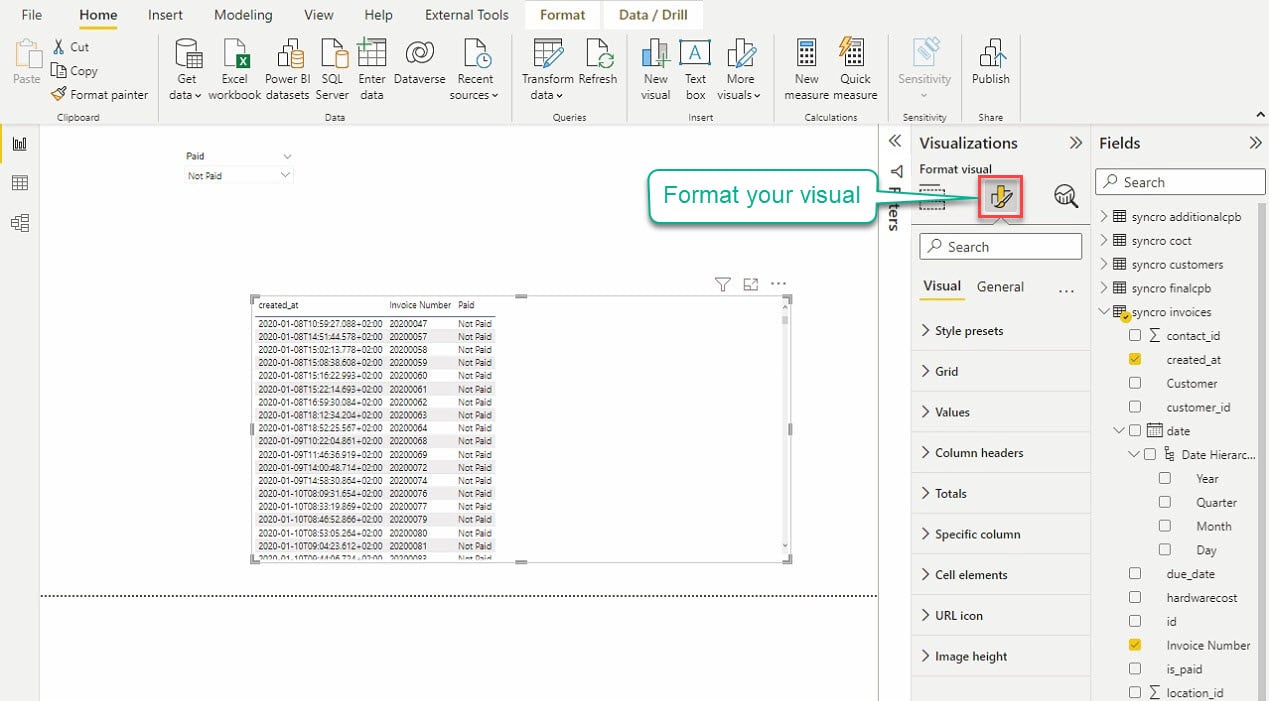
انقر على أيقونة “تنسيق التصور الخاص بك” تحت التصور للوصول إلى محرر التصور ، كما هو موضح أدناه.
استغرق بعض الوقت في التلاعب بإعدادات التصور للحصول على المظهر المطلوب للتصورات الخاصة بك. ستترابط التصورات الخاصة بك طالما أنك تقوم بإنشاء علاقة بين الجداول التي تشارك في التصورات الخاصة بك.
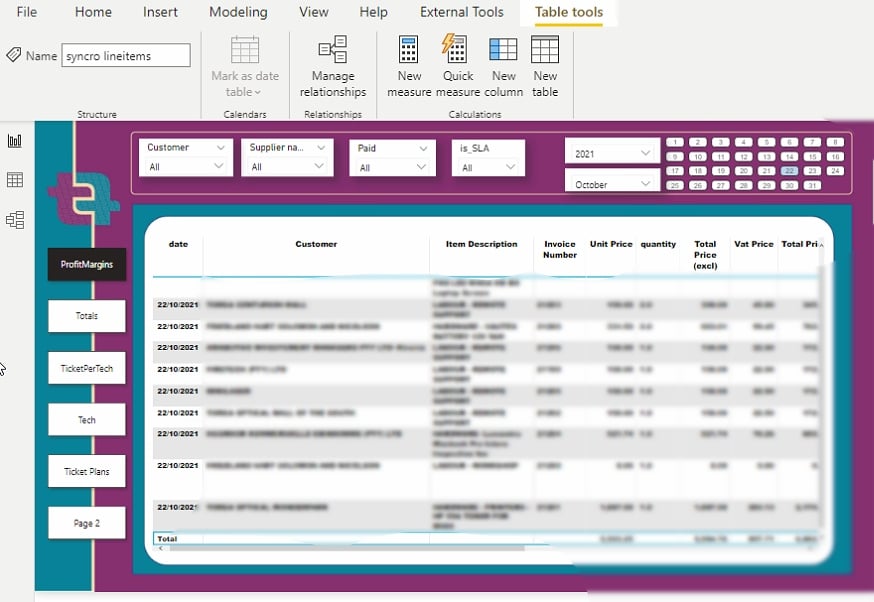
بعد تغيير إعدادات التصوير، يمكنك استخراج تقارير مثل تلك الموجودة أدناه.
الآن، يمكنك تصور وتحليل بياناتك بدون تعقيد أو إجهاد لعينيك.
في التصوير التالي، عند النظر إلى مخطط الاتجاهات، سترى أن هناك خطأً ما حدث في إبريل 2020. كان ذلك عندما بدأت إجراءات الإغلاق بسبب فيروس كوفيد-19 في جنوب أفريقيا.
هذا الإخراج يثبت فقط قوة Power BI في توفير تصورات دقيقة للبيانات.

استنتاج
يهدف هذا البرنامج التعليمي إلى عرض كيفية إنشاء خط أنابيب بيانات ديناميكي حي بجلب البيانات من نقاط واجهة برمجة التطبيقات (API). بالإضافة إلى ذلك، معالجة ودفع البيانات إلى قاعدة البيانات وPower BI باستخدام لغة Python. باستخدام هذه المعرفة الجديدة، يمكنك الآن استهلاك بيانات واجهة برمجة التطبيقات وإنشاء تصورات بيانات خاصة بك.
يقوم المزيد والمزيد من الشركات بإنشاء تطبيقات ويب باستخدام واجهات برمجة تطبيقات قائمة على مبدأ الراحة. وفي هذه اللحظة، أنت الآن واثق في التعامل مع واجهات برمجة تطبيقات باستخدام لغة Python وإنشاء تصورات بيانات باستخدام Power BI، مما يمكن أن يسهم في اتخاذ قرارات الأعمال.