













对于容器应用程序,很难发现由内存过度使用导致的问题。如果使用量超过容器内存限制,应用程序可能会无声失败,而不留下任何痕迹。
在本文中,我将介绍一些可以用来识别Java容器应用程序中内存消耗源的技术。
内存类型
在典型的Java应用程序中,内存可以大致分为堆内存和非堆内存。启动任何Java应用程序时,可以通过提供相关的JVM参数来设置堆内存。
非堆内存由JVM自身使用或应用程序中使用的任何库通过JNI(Java本地接口)使用的本地内存组成。
方法
对于堆内存,可以获取堆转储并使用堆转储分析工具进行分析。进行堆转储分析的最佳工具之一是eclipse MAT。
Java提供了一个机制,通过启用本地内存跟踪来跟踪本地内存分配,但它可能无法揭示所有由本地库分配的内存。
Jemalloc 是一个实用工具,可用于追踪由本地库分配的内存。本地内存通过名为 malloc 的默认内存分配器进行分配。Jemalloc 是一种通用 malloc 实现,启用后可以跟踪所有本地内存分配并生成堆内存概况转储。
这些堆内存概况随后可通过 Jeprof 工具进行分析。Jeprof 生成堆内存分配报告,突出显示应用程序中函数使用的内存。
分析
以下是对一个示例容器化 Java 应用的内存分析。该应用加载一个示例 Tensorflow 模型以启用本地内存使用,并在 Docker 容器中运行。
以下是 Docker 内存消耗情况,显示为 254MB。我们来尝试确定内存消耗的来源。

总内存
为了了解应用程序进程使用的总内存,我们可以检查驻留集大小(RSS)。它是驻留在主内存或 RAM 中的总已提交内存。有多种工具可以帮助检查这一点,如 top、ps 或 pmap。
检查RSS无法帮助定位使用量的根本来源。对于示例应用,执行以下命令显示的总RSS为376MB。
ps --no-header -o rss $(pidof java)堆分析
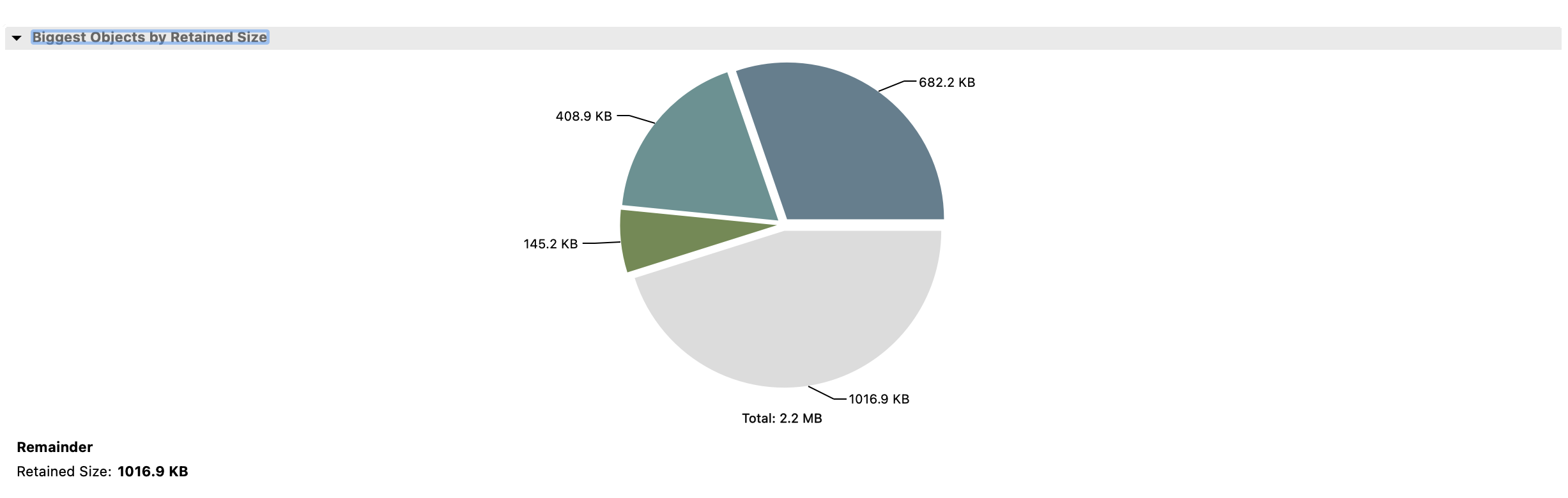
以下是使用Eclipse MAT工具生成的堆内存消耗情况。总保留堆内存显示为2.2MB,远低于Docker显示的总内存消耗,表明大部分消耗来自非堆区域。
原生内存分析
通过审查以下命令得到的原生内存摘要,总内存使用量约为99MB。然而,这一数值低于总内存消耗,并未准确识别问题的根本原因。
jcmd $(pidof java) VM.native_memory \
| grep -P "Total.*committed=" \
| grep -o -P "(?<=committed=)[0-9]+(?=KB)"堆外内存分析
使用Jemalloc和Jeprof进行的分析显示,原生内存使用主要归因于Tensorflow库,总消耗量约为112MB。
这一发现清晰指出了原生内存使用的来源,并可进一步调查以减少任何过度消耗。

结论
Java内存分析对于容器化应用尤为关键。了解应用中内存消耗的来源有助于我们理解内存需求,并通过消除不必要的消耗来降低应用成本。
在检查内存消耗时,需要明确所有类型内存及其来源。堆转储分析能定位堆内存消耗的源头,而Jemalloc和Jeprof在定位原生内存消耗源头方面十分有用。
示例应用程序代码链接
Source:
https://dzone.com/articles/java-container-application-memory-analysis