













在本教程中,我们将讨论Python Pickle示例。在我们之前的教程中,我们讨论了Python多进程。
Python Pickle
Python Pickle用于序列化和反序列化Python对象结构。Python中的任何对象都可以被pickle化,以便可以将其保存在磁盘上。首先,Python pickle序列化对象,然后将对象转换为字符流,以便该字符流包含重建对象所需的所有信息,在另一个Python脚本中。请注意,根据文档,pickle模块不安全,不能防止错误或恶意构造的数据。因此,永远不要从不受信任或未经身份验证的源解pickle数据。
Python Pickle dump
在这个部分,我们将学习如何使用Python的pickle模块存储数据。为此,我们首先要导入pickle模块。然后使用pickle.dump()函数将对象数据存储到文件中。pickle.dump()函数接受3个参数。第一个参数是您要存储的对象。第二个参数是以write-binary(wb)模式打开所需文件后获得的文件对象。第三个参数是键值参数。该参数定义了协议。有两种类型的协议 – pickle.HIGHEST_PROTOCOL和pickle.DEFAULT_PROTOCOL。查看示例代码以了解如何使用pickle进行数据转储。
import pickle
# 获取用户输入以获取数据量
number_of_data = int(input('Enter the number of data : '))
data = []
# 获取数据输入
for i in range(number_of_data):
raw = input('Enter data '+str(i)+' : ')
data.append(raw)
# 打开一个文件,您希望在其中存储数据
file = open('important', 'wb')
# 将信息转储到该文件
pickle.dump(data, file)
# 关闭文件
file.close()
以下程序将提示您输入一些内容。在我的情况下,它是这样的。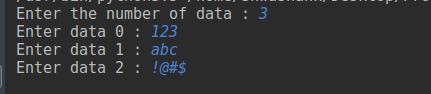
Python Pickle加载
检索pickled数据的步骤非常简单。您必须使用pickle.load()函数来执行此操作。pickle加载函数的主要参数是通过以读取二进制(rb)模式打开文件获取的文件对象。简单!是不是。让我们编写代码来检索我们使用pickle dump代码pickle的数据。请参阅以下代码以了解。
import pickle
# 打开一个文件,您存储了pickle数据
file = open('important', 'rb')
# 将信息转储到该文件
data = pickle.load(file)
# 关闭文件
file.close()
print('Showing the pickled data:')
cnt = 0
for item in data:
print('The data ', cnt, ' is : ', item)
cnt += 1
输出将如下:
Showing the pickled data:
The data 0 is : 123
The data 1 is : abc
The data 2 is : !@#$
Python Pickle示例
I made a short video showing execution of python pickle example programs – first to store data into file and then to load and print it. 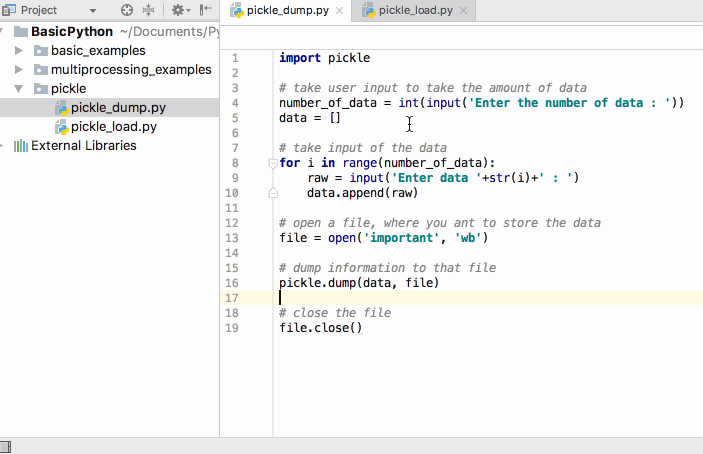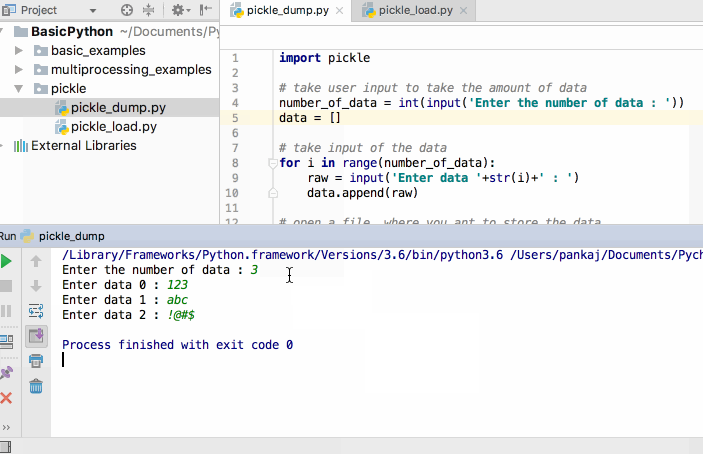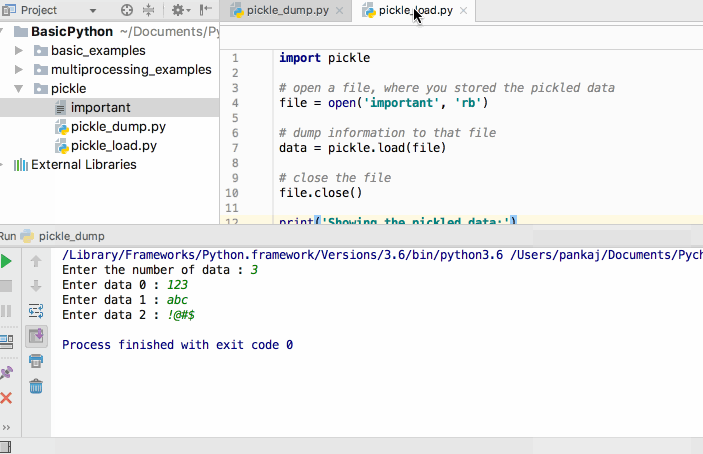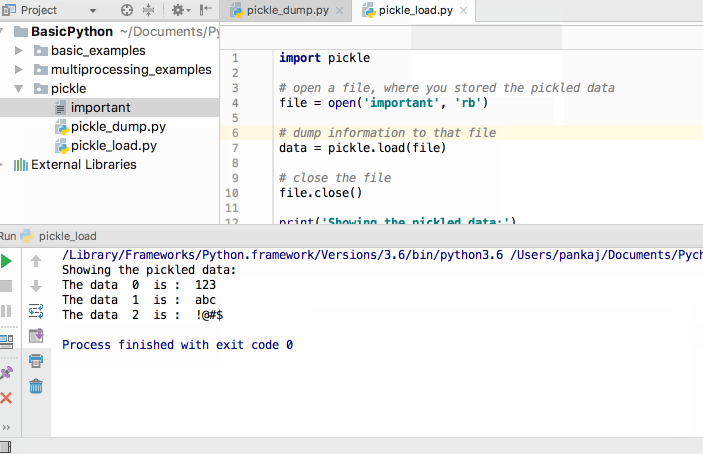 As you can see that the file created by python pickle dump is a binary file and shows garbage characters in the text editor.
As you can see that the file created by python pickle dump is a binary file and shows garbage characters in the text editor.
Python Pickle的重要注意事项
关于Python pickle模块的几个重要点是:
- pickle协议是特定于Python的 – 不能保证与其他编程语言兼容。这意味着您很可能无法转移信息以使其在其他编程语言中有用。
- 也不能保证不同版本的Python之间的兼容性,因为不是每个Python数据结构都可以被该模块序列化。
- 除非您手动更改,否则默认使用pickle协议的最新版本。
- 最后但并非最不重要的是,根据文档,pickle模块对错误或恶意构造的数据不安全。
所以,这就是关于Python pickle示例的全部内容。希望你理解得很好。如有进一步疑问,请使用评论部分。:) 参考:官方文档
Source:
https://www.digitalocean.com/community/tutorials/python-pickle-example