













Introdução
Organizações que estão cada vez mais adotando o Kubernetes para gerenciar seus contêineres precisam de uma solução para monitorar a saúde de seu sistema distribuído. Por esse motivo, entra o Prometheus – uma poderosa ferramenta de código aberto para monitorar aplicativos containerizados em seu espaço K8s.
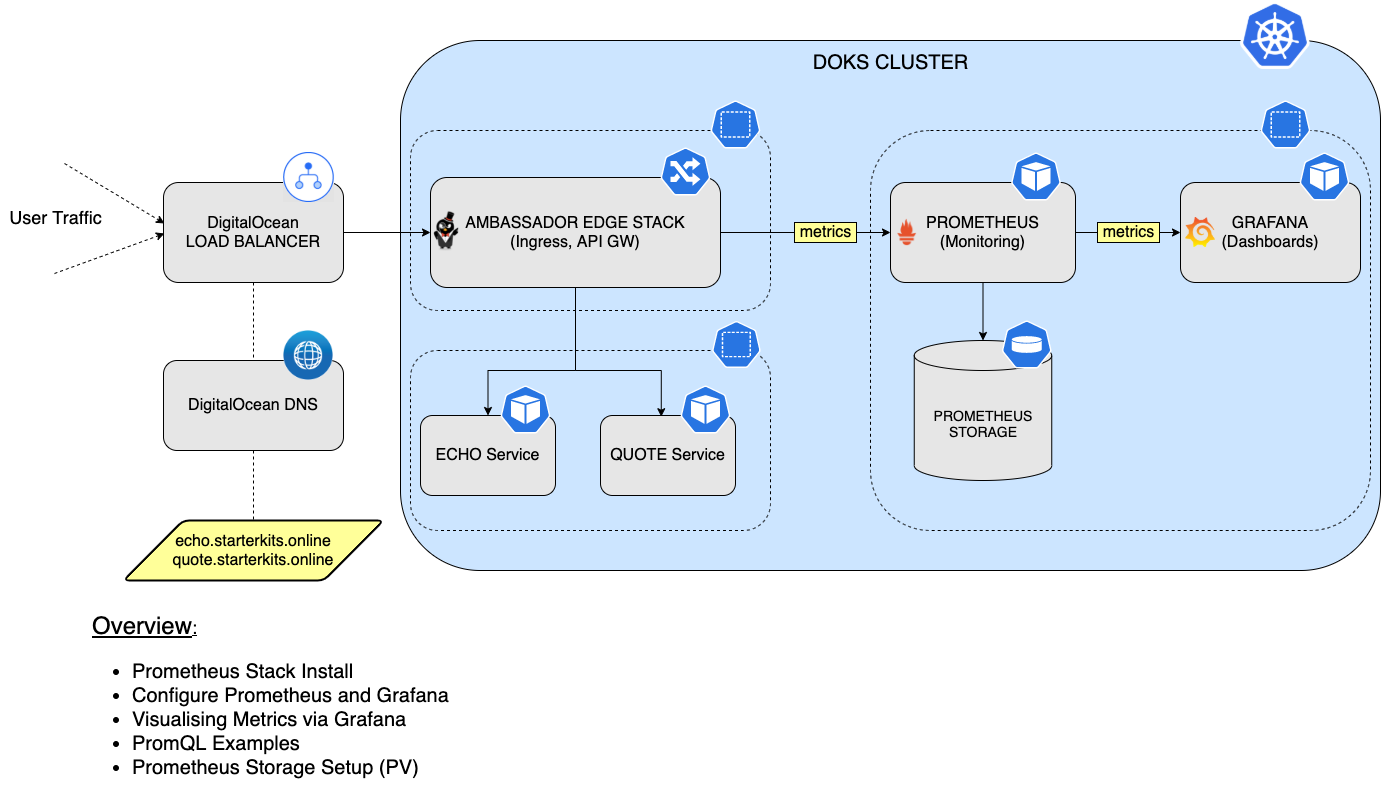
Neste tutorial, você aprenderá como instalar e configurar o conjunto Prometheus para monitorar todos os pods do seu cluster DOKS, bem como as métricas do estado do cluster Kubernetes. Em seguida, você conectará o Prometheus ao Grafana para visualizar todas as métricas e executar consultas usando a linguagem PromQL. Por fim, você configurará armazenamento persistente para sua instância do Prometheus, para persistir todos os dados de métricas do seu cluster DOKS e aplicativos.
Índice
- Pré-requisitos
- Passo 1 – Instalando o Conjunto Prometheus
- Passo 2 – Configurar Prometheus e Grafana
- Passo 3 – PromQL (Linguagem de Consulta do Prometheus)
- Passo 4 – Visualizando Métricas Usando Grafana
- Passo 5 – Configurando Armazenamento Persistente para o Prometheus
- Passo 6 – Configurando Armazenamento Persistente para o Grafana
- Conclusão
Pré-requisitos
Para completar este tutorial, você precisará de:
- A Git client to clone the Starter Kit repository.
- Helm para gerenciar lançamentos e atualizações do stack do Prometheus.
- Kubectl para interação com o Kubernetes.
- Curl para testar os exemplos (aplicações de back-end).
- Aplicativo de Exemplo Emojivoto implantado no cluster. Siga os passos no README do repositório correspondente.
Por favor, certifique-se de que o contexto do kubectl está configurado para apontar para o seu cluster Kubernetes. Consulte Passo 3 – Criando o Cluster DOKS do tutorial de configuração do DOKS.
Passo 1 – Instalando o Conjunto Prometheus
Neste passo, você irá instalar o conjunto kube-prometheus, que é um conjunto completo de monitoramento para Kubernetes. Ele inclui o Operador Prometheus, kube-state-metrics, manifestos pré-construídos, Exportadores de Nós, API de Métricas, Gerenciador de Alertas e Grafana.
Você vai usar o gerenciador de pacotes Helm para realizar esta tarefa. O gráfico Helm está disponível aqui para estudo.
Primeiro, clone o repositório do Starter Kit e altere o diretório para sua cópia local.
Em seguida, adicione o repositório Helm e liste os gráficos disponíveis:
A saída se parece com o seguinte:
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/alertmanager 0.18.1 v0.23.0 The Alertmanager handles alerts sent by client ...
prometheus-community/kube-prometheus-stack 35.5.1 0.56.3 kube-prometheus-stack collects Kubernetes manif...
...
O gráfico de interesse é prometheus-community/kube-prometheus-stack que irá instalar o Prometheus, Promtail, Alertmanager e Grafana no cluster. Por favor, visite a página kube-prometheus-stack para mais detalhes sobre este gráfico.
Em seguida, abra e inspecione o arquivo 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornecido no repositório do Starter Kit usando um editor de sua escolha (preferencialmente com suporte a lint YAML). Por padrão, as métricas de kubeSched e etcd estão desativadas – esses componentes são gerenciados pelo DOKS e não são acessíveis ao Prometheus. Note que o armazenamento está definido como emptyDir. Isso significa que o armazenamento será apagado se os pods do Prometheus reiniciarem (você corrigirá isso posteriormente na seção Configurando Armazenamento Persistente para o Prometheus).
[OPCIONAL] Se você seguiu – Passo 4 – Adicionando um nó dedicado para observabilidade do guia Configurando um Cluster Kubernetes Gerenciado pela DigitalOcean, você precisará editar o arquivo 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornecido no repositório do Starter Kit e descomentar as seções de affinity tanto para Grafana quanto para Prometheus.
Explicações para a configuração acima:
preferredDuringSchedulingIgnoredDuringExecution– o agendador tenta encontrar um nó que atenda à regra. Se um nó correspondente não estiver disponível, o agendador ainda agenda o Pod.preference.matchExpressions– seletor usado para corresponder a um nó específico com base em um critério. O exemplo acima indica ao agendador para colocar cargas de trabalho (por exemplo, Pods) em nós rotulados usando a chave –preferrede valor –observability.
Finalmente, instale o kube-prometheus-stack, usando Helm:
A specific version of the Helm chart is used. In this case 35.5.1 was picked, which maps to the 0.56.3 version of the application (see output from Step 2.). It’s a good practice to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
Agora, verifique o status do lançamento do Helm do stack Prometheus:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prom-stack monitoring 1 2022-06-07 09:52:53.795003 +0300 EEST deployed kube-prometheus-stack-35.5.1 0.56.3
A saída se parece com o seguinte. Observe o valor da coluna STATUS – deve dizer deployed.
Veja quais recursos do Kubernetes estão disponíveis para o Prometheus:
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prom-stack-kube-prome-alertmanager-0 2/2 Running 0 3m3s
pod/kube-prom-stack-grafana-8457cd64c4-ct5wn 2/2 Running 0 3m5s
pod/kube-prom-stack-kube-prome-operator-6f8b64b6f-7hkn7 1/1 Running 0 3m5s
pod/kube-prom-stack-kube-state-metrics-5f46fffbc8-mdgfs 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-gcb8s 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-kc5wz 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-qn92d 1/1 Running 0 3m5s
pod/prometheus-kube-prom-stack-kube-prome-prometheus-0 2/2 Running 0 3m3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m3s
service/kube-prom-stack-grafana ClusterIP 10.245.147.83 <none> 80/TCP 3m5s
service/kube-prom-stack-kube-prome-alertmanager ClusterIP 10.245.187.117 <none> 9093/TCP 3m5s
service/kube-prom-stack-kube-prome-operator ClusterIP 10.245.79.95 <none> 443/TCP 3m5s
service/kube-prom-stack-kube-prome-prometheus ClusterIP 10.245.86.189 <none> 9090/TCP 3m5s
service/kube-prom-stack-kube-state-metrics ClusterIP 10.245.119.83 <none> 8080/TCP 3m5s
service/kube-prom-stack-prometheus-node-exporter ClusterIP 10.245.47.175 <none> 9100/TCP 3m5s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m3s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prom-stack-prometheus-node-exporter 3 3 3 3 3 <none> 3m5s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prom-stack-grafana 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-prome-operator 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-state-metrics 1/1 1 1 3m5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prom-stack-grafana-8457cd64c4 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-prome-operator-6f8b64b6f 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-state-metrics-5f46fffbc8 1 1 1 3m5s
NAME READY AGE
statefulset.apps/alertmanager-kube-prom-stack-kube-prome-alertmanager 1/1 3m3s
statefulset.apps/prometheus-kube-prom-stack-kube-prome-prometheus 1/1 3m3s
Você deve ter os seguintes recursos implantados: prometheus-node-exporter, kube-prome-operator, kube-prome-alertmanager, kube-prom-stack-grafana e kube-state-metrics. A saída se parece com:
Então, você pode se conectar ao Grafana (usando credenciais padrão: admin/prom-operator – consulte o arquivo prom-stack-values-v35.5.1), encaminhando a porta para a máquina local:
Você NÃO deve expor o Grafana para a rede pública (por exemplo, criar um mapeamento de ingresso ou serviço de balanceamento de carga) com login/senha padrão.
A instalação do Grafana vem com vários painéis. Abra um navegador da web em localhost:3000. Uma vez dentro, você pode ir para Painéis -> Navegar e escolher diferentes painéis.
Na próxima parte, você descobrirá como configurar o Prometheus para descobrir alvos para monitoramento. Como exemplo, será utilizado o aplicativo de amostra Emojivoto. Você também aprenderá o que é um ServiceMonitor.
Passo 2 – Configurar Prometheus e Grafana
Você já implantou o Prometheus e o Grafana no cluster. Neste passo, você aprenderá a usar um ServiceMonitor. Um ServiceMonitor é uma das formas preferenciais de dizer ao Prometheus como descobrir um novo alvo para monitoramento.
A implantação do Emojivoto criada no Passo 5 da seção de Pré-requisitos fornece o endpoint /metrics por padrão na porta 8801 via um serviço Kubernetes.
Em seguida, você descobrirá os serviços Emojivoto responsáveis por expor dados de métricas para o Prometheus consumir. Os serviços em questão são chamados de emoji-svc e voting-svc (observe que está usando o namespace emojivoto):
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
emoji-svc ClusterIP 10.245.135.93 <none> 8080/TCP,8801/TCP 22h
voting-svc ClusterIP 10.245.164.222 <none> 8080/TCP,8801/TCP 22h
web-svc ClusterIP 10.245.61.229 <none> 80/TCP 22h
A saída se parece com o seguinte:
Em seguida, execute um port-forward para inspecionar as métricas:
As métricas expostas podem ser visualizadas navegando com um navegador da web para localhost ou via curl:
A saída se parece com o seguinte:
go_gc_duration_seconds{quantile="0"} 5.317e-05
go_gc_duration_seconds{quantile="0.25"} 0.000105305
go_gc_duration_seconds{quantile="0.5"} 0.000138168
go_gc_duration_seconds{quantile="0.75"} 0.000225651
go_gc_duration_seconds{quantile="1"} 0.016986437
go_gc_duration_seconds_sum 0.607979843
go_gc_duration_seconds_count 2097
# TYPE go_gc_duration_seconds summary
Para inspecionar as métricas do serviço voting-svc, pare o encaminhamento de porta do emoji-svc e execute as mesmas etapas para o segundo serviço.
- Em seguida, conecte o Prometheus ao serviço de métricas Emojivoto. Existem várias maneiras de fazer isso:
- <static_config> – permite especificar uma lista de alvos e um conjunto comum de rótulos para eles.
- <kubernetes_sd_config> – permite recuperar alvos de raspagem da API REST do Kubernetes e sempre permanecer sincronizado com o estado do cluster.
Operador Prometheus – simplifica o monitoramento do Prometheus dentro de um cluster Kubernetes via CRDs.
Em seguida, você usará o CRD ServiceMonitor exposto pelo Operador Prometheus para definir um novo alvo para monitoramento.
Primeiro, mude o diretório (se ainda não o fez) onde o repositório Git do Starter Kit foi clonado:
Em seguida, abra o arquivo 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornecido no repositório do Starter Kit usando um editor de texto de sua escolha (preferencialmente com suporte a lint YAML). Por favor, remova os comentários que cercam a seção additionalServiceMonitors. A saída se parece com:
- Explicações para a configuração acima:
selector -> matchExpressions– indica aoServiceMonitorqual serviço monitorar. Ele irá direcionar todos os serviços com a chave de rótulo app e os valoresemoji-svcevoting-svc. Os rótulos podem ser obtidos executando:kubectl get svc --show-labels -n emojivotonamespaceSelector– aqui, você deseja corresponder ao namespace onde oEmojivotofoi implantado.
endpoints -> port – faz referência à porta do serviço a ser monitorado.
Por fim, aplique as alterações usando Helm:
Em seguida, verifique se o alvo Emojivoto foi adicionado ao Prometheus para scraping. Crie um encaminhamento de porta para o Prometheus na porta 9090:
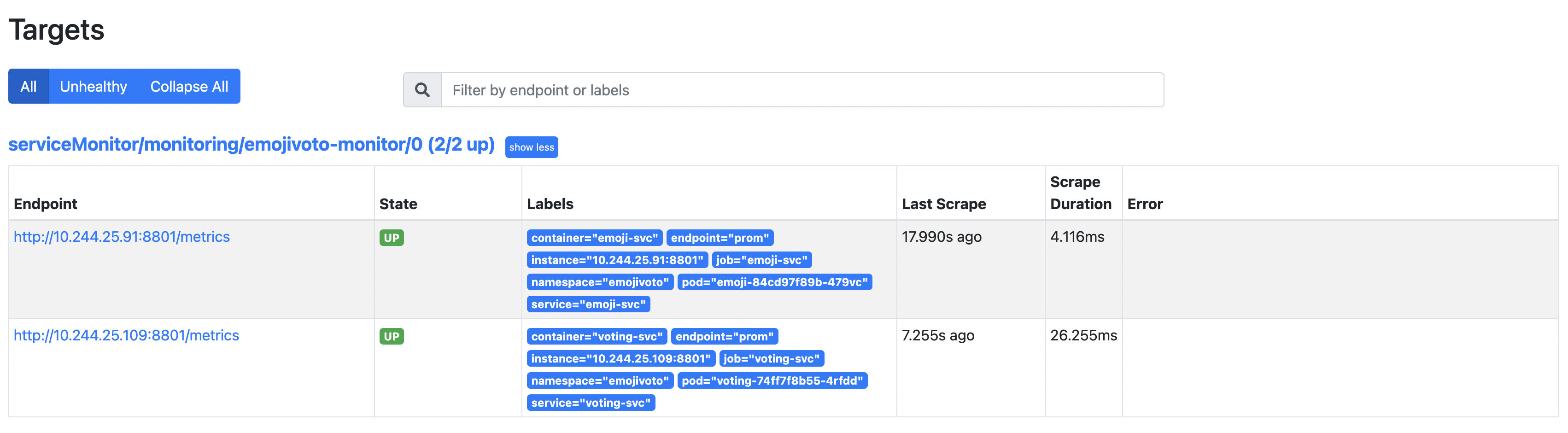
Abra um navegador da web em localhost:9090. Em seguida, vá para a página Status -> Targets e inspecione os resultados (observe o caminho serviceMonitor/monitoring/emojivoto-monitor/0):
Há 2 entradas nos alvos descobertos porque a implantação do Emojivoto consiste em 2 serviços expondo o endpoint de métricas.
No próximo passo, você descobrirá o PromQL junto com alguns exemplos simples para começar e aprender a linguagem.
Passo 3 – PromQL (Linguagem de Consulta do Prometheus)
Neste passo, você aprenderá o básico da Linguagem de Consulta do Prometheus (PromQL). O PromQL ajuda você a realizar consultas em várias métricas provenientes de todos os Pods e aplicativos do seu cluster DOKS.
O PromQL é uma DSL ou Linguagem Específica de Domínio que é especificamente construída para o Prometheus e permite que você consulte métricas. A expressão geral define o valor final, enquanto as expressões aninhadas representam valores para argumentos e operandos. Para explicações mais detalhadas, por favor visite a página oficial do PromQL.
Em seguida, você vai inspecionar uma das métricas do Emojivoto, nomeadamente o emojivoto_votes_total, que representa o número total de votos. É um valor de contador que aumenta a cada solicitação contra o endpoint de votos do Emojivoto.
Primeiro, crie um encaminhamento de porta para o Prometheus na porta 9090:
Em seguida, abra o navegador de expressão.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 20
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
No campo de entrada da consulta, cole emojivoto_votes_total e pressione enter. A saída se parece com:
Navegue até a aplicação Emojivoto e, a partir da página inicial, clique no emoji 100 para votar nele.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
Navegue até a página de resultados da consulta do Passo 3 e clique no botão Executar. Você deverá ver o contador para o emoji 100 aumentar em um. A saída se parece com:
O PromQL agrupa dados similares em algo chamado vetor. Como visto acima, cada vetor possui um conjunto de atributos que o diferencia dos outros. Você pode agrupar resultados com base em um atributo de interesse. Por exemplo, se você se importa apenas com as solicitações que vêm do serviço voting-svc, então por favor digite o seguinte no campo de consulta:
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 492
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 532
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 521
A saída se parece com (observe que seleciona apenas os resultados que correspondem aos seus critérios):
O resultado acima mostra as solicitações totais para cada Pod da implantação Emojivoto que emite métricas (que consiste em 2).
Isso é apenas uma introdução muito simples ao que o PromQL é e do que é capaz. Mas pode fazer muito mais do que isso, como contar métricas, calcular a taxa ao longo de um intervalo predefinido, etc. Por favor, visite a página oficial do PromQL para mais recursos da linguagem.
No próximo passo, você aprenderá como usar o Grafana para visualizar métricas para a aplicação de exemplo Emojivoto.
Passo 4 – Visualizando Métricas Usando o Grafana
Embora o Prometheus tenha algum suporte integrado para visualização de dados, uma maneira melhor de fazer isso é através do Grafana, que é uma plataforma de código aberto para monitoramento e observabilidade, que permite visualizar e explorar o estado do seu cluster.
A página oficial é descrita como sendo capaz de:
Consultar, visualizar, alertar e entender seus dados, não importa onde eles estão armazenados.
Nenhuma etapa extra é necessária para instalar o Grafana porque o Passo 1 – Instalando o Stack Prometheus instalou o Grafana para você. Tudo que você precisa fazer é um encaminhamento de porta como abaixo, e obter acesso imediato aos painéis (credenciais padrão: admin/prom-monitor):
Para ver todas as métricas do Emojivoto, você vai usar um dos painéis instalados por padrão do Grafana.
Navegue até a seção de Painéis Grafana.
Em seguida, procure pelo painel Geral/Kubernetes/Recursos de Computação/Namespace (Pods) e acesse-o.
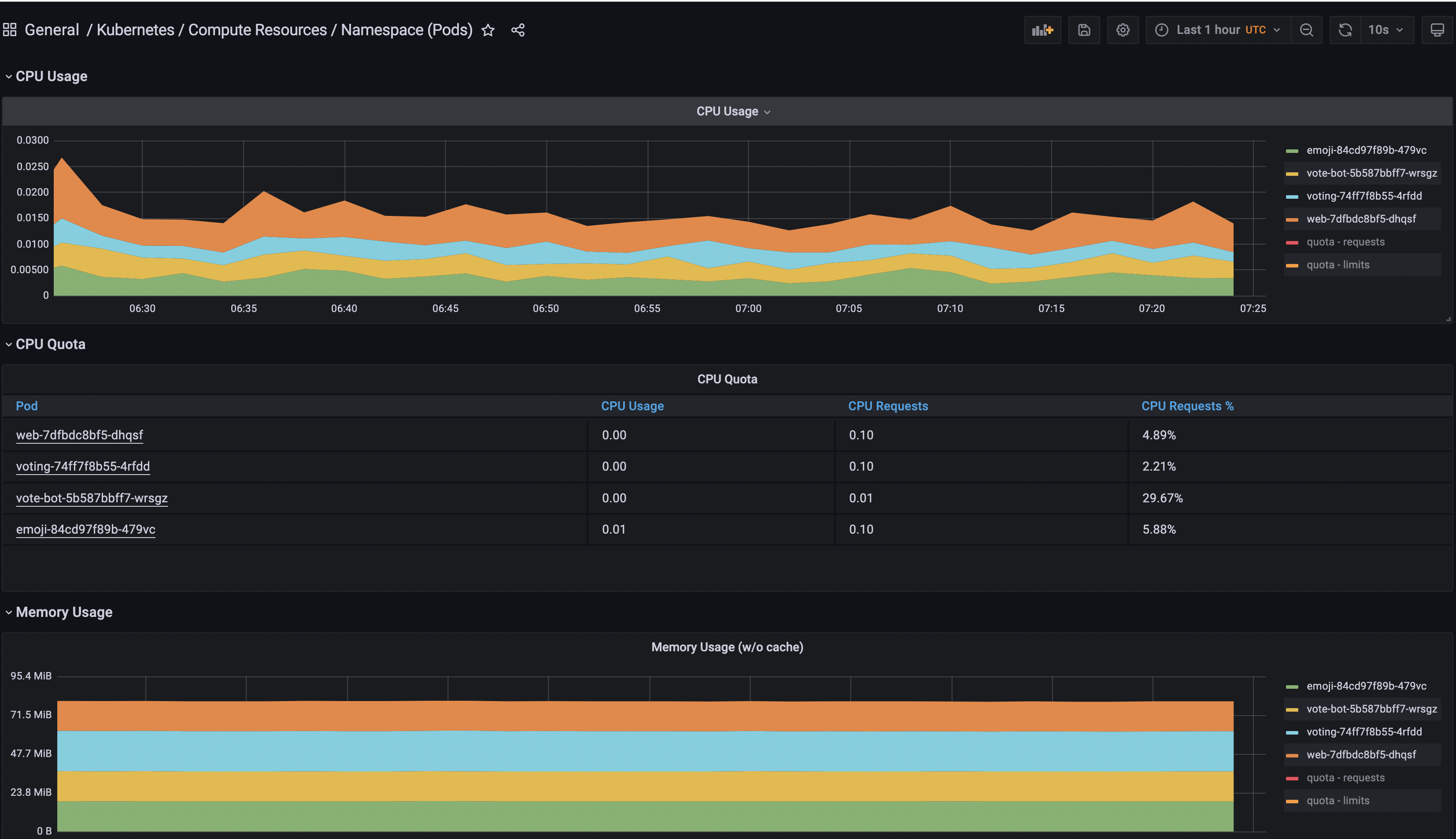
Por fim, selecione a fonte de dados Prometheus e adicione o namespace emojivoto.
Você pode brincar e adicionar mais painéis no Grafana para visualizar outras fontes de dados, bem como agrupá-los com base no escopo. Além disso, você pode explorar os painéis disponíveis para Kubernetes do projeto kube-mixin no Grafana.
Na próxima etapa, você irá configurar armazenamento persistente para o Prometheus usando armazenamento de blocos da DigitalOcean para persistir suas métricas do DOKS e do aplicativo em caso de reinicializações do servidor ou falhas do cluster.
Etapa 5 – Configurando Armazenamento Persistente para o Prometheus
Nesta etapa, você aprenderá como habilitar armazenamento persistente para o Prometheus para que os dados de métricas sejam mantidos em caso de reinicializações do servidor ou falhas no cluster.
Primeiro, você precisa de uma classe de armazenamento para prosseguir. Execute o seguinte comando para verificar qual está disponível.
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage (default) dobs.csi.digitalocean.com Delete Immediate true 4d2h
A saída deve ser semelhante ao seguinte. Observe que o armazenamento de blocos da DigitalOcean está disponível para você usar.
Em seguida, altere o diretório (se ainda não estiver) onde o repositório Git do Starter Kit foi clonado:
Em seguida, abra o arquivo 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornecido no repositório do Starter Kit usando um editor de texto de sua escolha (preferencialmente com suporte a lint YAML). Procure pela linha storageSpec e descomente a seção necessária para o Prometheus. A definição storageSpec deve ficar assim:
- Explicações para a configuração acima:
volumeClaimTemplate– define um novo PVC.storageClassName– define a classe de armazenamento (deve usar o mesmo valor obtido no comandokubectl get storageclass).
resources – define o valor solicitado de armazenamento. Neste caso, é solicitada uma capacidade total de 5 Gi para o novo volume.
Por fim, aplique as configurações usando o Helm:
Após concluir os passos acima, verifique o status do PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prome-prometheus-0 Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

A saída será semelhante ao seguinte. A coluna STATUS deve exibir Bound.
Passo 6 – Configurando Armazenamento Persistente para o Grafana
Nesta etapa, você aprenderá como habilitar armazenamento persistente para o Grafana, para que os gráficos sejam mantidos através de reinicializações do servidor ou em caso de falhas no cluster. Você definirá uma Requisição de Volume Persistente (PVC) de 5 Gi, utilizando o Armazenamento em Bloco da DigitalOcean. Os próximos passos são os mesmos que Passo 5 – Configurando Armazenamento Persistente para o Prometheus.
Primeiramente, abra o arquivo 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornecido no repositório do Starter Kit, utilizando um editor de texto de sua escolha (preferencialmente com suporte a validação YAML). A seção de armazenamento persistente para o Grafana deve se parecer com:
Em seguida, aplique as configurações usando o Helm:
Após concluir os passos acima, verifique o status do PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prom-stack-grafana Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

A saída será semelhante ao seguinte. A coluna STATUS deve exibir Bound.
Melhores Práticas para Dimensionamento de PV
- Para calcular o tamanho necessário para o volume com base em suas necessidades, siga o conselho e a fórmula da documentação oficial:
- Prometheus armazena uma média de apenas 1-2 bytes por amostra. Assim, para planejar a capacidade de um servidor Prometheus, você pode usar a fórmula aproximada:
espaço_em_disco_necessário = tempo_de_retenção_segundos * amostras_ingeridas_por_segundo * bytes_por_amostra
Para diminuir a taxa de amostras ingeridas, você pode reduzir o número de séries temporais que você raspa (menos alvos ou menos séries por alvo), ou você pode aumentar o intervalo de raspagem. No entanto, reduzir o número de séries é provavelmente mais eficaz, devido à compressão de amostras dentro de uma série.
Por favor, siga a seção Aspectos Operacionais para mais detalhes sobre o assunto.
Neste tutorial, você aprendeu como instalar e configurar o stack Prometheus, então usou o Grafana para instalar novos painéis e visualizar métricas de aplicativos do cluster DOKS. Você também aprendeu como realizar consultas de métricas usando PromQL. Por fim, configurou e habilitou armazenamento persistente para Prometheus armazenar suas métricas de cluster.
- Saiba Mais
- Monitoramento e Retenção de Logs do Kubernetes usando Grafana Loki e DigitalOcean Spaces
- Melhores Práticas no Monitoramento de um Cluster Kubernetes com Prometheus, Grafana e Loki
Configurar o Monitoramento do Cluster DOKS com Helm e Prometheus Operator