













In een gedistribueerde architectuur vormen de communicatie tussen systemen de basis van de gehele infrastructuur. De prestaties, schaalbaarheid en betrouwbaarheid van de infrastructuur hangen sterk af van hoe evenementen/berichten/data worden uitgewisseld en opgeslagen.
Kafka en NATS zijn twee populaire tools voor het omgaan met streaming en messaging. Ze hebben verschillende architecturen en verschillende prestatiekenmerken. Ze zijn geschikt voor specifieke gebruikssituaties. In dit artikel zullen we de kenmerken van NATS vergelijken met die van Kafka en de gebruikssituaties uitleggen die ik op het werk heb besproken.
1. Architectuur en Complexiteit
NATS
NATS infrastructuur heeft twee hoofdcomponenten:
Core NATS
Core NATS is het basis messaging framework. Dit ondersteunt Publish-Subscribe (maakt het mogelijk om berichten naar meerdere abonnees te verspreiden), Request-Reply (maakt synchrone communicatie mogelijk) en Queue Groups (vergemakkelijkt load balancing tussen meerdere abonnees binnen een groep).
Dit is ontworpen voor eenvoud, lage latentie, hoge prestaties en schaalbaarheid. Het presteert zeer goed in scenario’s die lage latentie en hoge doorvoer vereisen. Echter, Core NATS alleen biedt alleen niet-gegarandeerde levering, wat betekent dat berichten alleen worden afgeleverd aan actieve abonnees. Gegevens gaan verloren als de abonnees offline zijn. Core NATS is een goede optie wanneer snelheid en schaal belangrijker zijn dan duurzaamheid.
JetStream
JetStream brengt persistentiemogelijkheden naar de top van Core NATS. Dit heeft geholpen om berichtduurzaamheid en betrouwbaarheid te bieden. Het maakt het mogelijk berichten of gebeurtenissen te persisteren (op schijf of in het geheugen) en opnieuw af te spelen. Gepersisteerde berichten kunnen opnieuw worden afgespeeld naar nieuwe of herstellende abonnees. Met JetStream krijgen gebruikers extra functies:
- Stroomretentie: Hoelang berichten worden bewaard. Dit kan gebaseerd zijn op grootte, tijd of abonneelimieten.
- Consumentduurzaamheid: Hiermee kunnen consumenten doorgaan waar ze gebleven waren.
- Berichtbevestiging: Dit waarborgt de betrouwbaarheid van de levering.
JetStream voegt een laag complexiteit toe aan Core NATS. Dit brengt echter het belangrijke kenmerk met zich mee van ondersteuning van de gebruikssituaties van gegarandeerde levering, persistentie en afspeelbaarheid.
Kafka
Kafka is een gedistribueerd messaging systeem dat is gebouwd op een op loggebaseerde brokerarchitectuur. Gegevens in Kafka zijn gerangschikt in onderwerpen en kunnen meerdere partities hebben. Consumenten zijn verbonden met deze partities. Deze architectuur stelt Kafka in staat om het verbruik van berichten voor een enkel onderwerp te paralleliseren. Gegevens worden sequentieel aan een onderwerp/partities toegevoegd. Kafka garandeert de volgorde in een partitie. In een Kafka-cluster kunnen er veel brokers zijn, die elk een lijst van onderwerpen en partities beheren. Om hoge beschikbaarheid te bereiken en gegevensverlies te voorkomen, vertrouwt Kafka op een replicatiefactor, waarbij partities over meerdere Kafka-brokers worden gerepliceerd. Zoals je kunt zien, zijn er verschillende componenten die beheerd moeten worden om een hoge doorvoer, fouttolerantie, gegevensretentie en horizontale schaalbaarheid te bereiken. Dit verhoogt de architectonische complexiteit van Kafka.
2. Hoge Beschikbaarheid en Prestaties
NATS
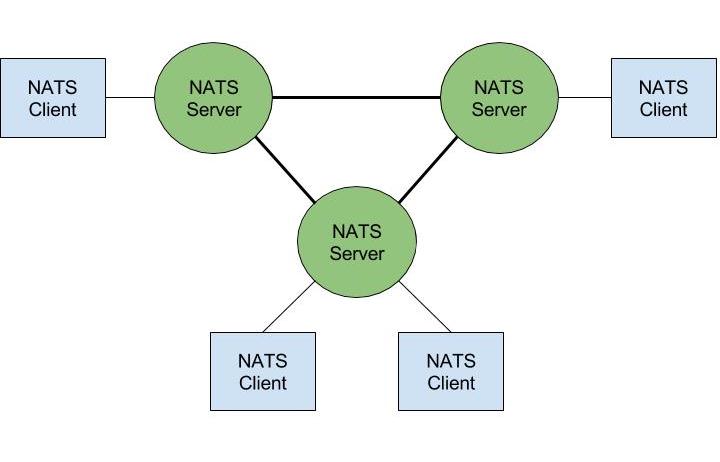
Alle knooppunten in een cluster zijn met elkaar verbonden in een mesh, en de cliënt kan verbinding maken met elk knooppunt. Deze configuratie voorkomt een enkel punt van falen. Als één knooppunt faalt, wordt de cliënt automatisch verbonden met de andere knooppunten zonder enige handmatige tussenkomst. Dit wordt zelfherstel in NATS genoemd. Een JetStream-ingeschakeld knooppunt verdeelt de streams over alle knooppunten. Streams worden hoog beheerd en gebalanceerd over de JetStream-ingeschakelde knooppunten binnen een mesh-cluster.
JetStream ondersteunt ook gegevensmirroring over meerdere clusters of knooppunten. In JetStream worden leiders per stream gekozen. De replicatie van elke stream kan worden geconfigureerd. Al deze dingen zorgen voor duurzaamheid en beschikbaarheid in NATS.
Kafka
De hoge beschikbaarheid van Kafka is gebaseerd op replicatie. Elk onderwerp kan één of meerdere partities hebben. Elke partitie wordt gerepliceerd over Kafka Brokers. Dit zorgt voor datareduntie en beschikbaarheid. Kafka volgt een Leader-Follower replicatiemechanisme. Een leider zorgt voor lezen en schrijven. En de volger werkt aan het repliceren van de gegevens.
Kafka onderhoudt iets dat ISR (In Sync Replicas) wordt genoemd voor elke partitie. Als de leider faalt, wordt een van de ISR’s de leider. Voor cluster metadata beheer en leidersverkiezingen vertrouwt Kafka op Zookeeper (KRaft in de nieuwere versies).
|
Performance and Scalability
|
||
|---|---|---|
|
Kenmerk
|
NATS
|
Kafka
|
|
Doorvoer
|
Hoge of lage latentie. Geoptimaliseerd voor kleine berichten
|
Geoptimaliseerd voor hoge doorvoer en grote berichten
|
|
Schaalbaarheid
|
Horizontaal schaalbaar met clustering
|
Horizontaal schaalbaar met partitionering
|
|
Latentie
|
Sub milliseconden
|
Milliseconden
|
|
Recovery and FAILOver
|
||
|---|---|---|
|
Kenmerk
|
NATS
|
Kafka
|
|
Fouttolerante tijd
|
Sub-seconde (client maakt sneller opnieuw verbinding)
|
Langzamer (afhankelijk van het leiderverkiezingsproces)
|
|
Naadloos herstel
|
Klanten verbinden automatisch opnieuw zonder onderbreking
|
Enige downtime tijdens leiderverkiezing
|
|
Risico op gegevensverlies
|
Minimaal bij replicatie (JetStream)
|
Minimaal indien replicatie en ISR zijn geconfigureerd
|
3. Berichtenpatronen
NATS
NATS maakt gebruik van op onderwerp gebaseerde berichtenuitwisseling. Dit stelt services en streams in staat om Pub-Sub, Verzoek-Antwoord en Wachtrij-Abonnee patronen te gebruiken. Onderwerpen in NATS kunnen worden geconstrueerd met hiërarchie en jokertekens. Een enkele NATS-stream kan meerdere onderwerpen opslaan en Client-toepassingen kunnen server-side filtering gebruiken om alleen de geïnteresseerde onderwerpen te ontvangen. De verbinding in NATS is bidirectioneel en stelt clients in staat om tegelijkertijd te publiceren en te abonneren. NATS ondersteunt ook wachtrijen die erg lijken op die van RabbitMQ.
Kafka
Streams in Kafka ondersteunen Pub-sub en op onderwerp gebaseerde berichtenuitwisseling. Load balancing kan worden bereikt via Consumentengroepen en het partitioneren van de onderwerpen.
4. Leveringsgaranties
NATS
NATS ondersteunt verschillende leveringsgaranties. Alleen NATS kan een hoogstens eenmaal-leveringsgarantie ondersteunen. NATS-servers met JetStream ingeschakeld kunnen twee extra soorten garanties ondersteunen. Dit zijn “minstens eenmaal” en “exact eenmaal” garanties. NATS kan ‘acks’ sturen naar individuele berichten. Raadpleeg de officiële documentatie van NATS voor de verschillende ‘acks’ die het ondersteunt. Op basis van het type ‘acks’ kan NATS berichten opnieuw afleveren.
Kafka
Kafka ondersteunt minstens eenmaal en exact eenmaal garanties. Berichtvolgorde is gegarandeerd op het partitieniveau. Globale volgorde is niet mogelijk in Kafka.
5. Berichtretentie en persistentie
NATS
NATS ondersteunt geheugen- en op bestand gebaseerde persistentie. Er zijn verschillende opties om het bericht opnieuw af te spelen. Het opnieuw afspelen van berichten kan op tijd, aantal of sequentienummer gebaseerd zijn.
Kafka
KAFKA ondersteunt alleen op bestanden gebaseerde persistentie. Berichten kunnen worden herhaald vanaf de laatste, vroegste of een specifieke offset. Logcompactering wordt ondersteund in KAFKA.
6. Talen en Platform
NATS
achtenveertig bekende clienttypes. Elk architectuur dat GOLANG ondersteunt, kan NATS-servers ondersteunen.
Kafka
achttien bekende clienttypes. Kafka-servers kunnen worden uitgevoerd op platformen die JVM ondersteunen.
Gebruiksscenario’s
Gebruiksscenario 1
Vereisten
We hebben een dataplatform met een streaming-pijplijn. Het platform gebruikt de Apache Flink-engine voor realtime streaming en Apache Beam voor het schrijven van de analysepipeline. Hieronder staan de belangrijkste vereisten:
- Hoge doorvoer en lage latentie bij berichtenverwerking
- Ondersteuning voor checkpoint en backpressure-behandeling
- Berichten verwerken in MB’s
- Berichtduurzaamheid en persistentie
Vergelijking
Kafka-voordelens:
- Hoge doorvoer
- Dataretentie met configureerbare retentiebeleid en replicatie van gegevens voor fouttolerantie
- Ondersteuning voor ten minste één berichtaflevergarantie
- Berichten lezen vanaf vroegste/laatste/specifieke offsets
- ‘Acks’ aan de serverzijde voor betrouwbare aflevering
- Massieve gegevensstromen en grote berichtgrootte verwerken
- Ondersteuning voor Compactieonderwerp
Kafka nadelen:
- Hoge bronnen gebruikt. Ons cluster was on-premises en beperkt in bronnen
- Kafka is alleen bijna real-time
Voordelen van NATS:
- Hoge prestaties met minimaal gebruik van bronnen. Het onze is een on-premises cluster met beperkte bronnen
- Ondersteuning voor ten minste eenmaal. We zochten naar een garantie voor ten minste eenmaal
- Lage latentie bij berichtverwerking
Nadelen van NATS:
- Geen connectors voor Flink/Beam, dus integratie was moeilijk
- Prestatievermindering bij berichtgrootte
Definitieve Beslissing
Na grondige analyse is er voor Kafka gekozen. We moesten een compromis sluiten tussen het gebruik van bronnen en de andere voordelen die Kafka bood, vooral de goede integratie met Apache Beam en Flink. Een ander voordeel van Kafka was de verwerking van grote berichtgroottes en berichtverwerking met een hoog doorvoervermogen
Gebruiksscenario 2
Vereisten
De gebeurtenissen die worden gegenereerd in een on-premises cluster verwerken, bijv. Audit Logs. Gebeurtenissen moeten met lage latentie worden verwerkt. En ondersteuning bieden voor communicatie tussen microservices. Duurzaamheid en persistentie waren geen vereiste. De berichtgrootte was klein. Geen behoefte om analyses uit te voeren op de gebeurtenissen. We zaten in een beperkte omgeving. Het gebruik van bronnen en geheugenfootprint moeten minimaal zijn
Beslissing
Waarom er voor NATS is gekozen:
- Efficiënt gebruik van bronnen
- Lage latentie bij de verwerking van gebeurtenissen.
- Aangezien het een Go-toepassing is, is het geheugengebruik zeer laag
- Mogelijkheid om kleine berichtgroottes te verwerken
- Ondersteuning voor verzoek-antwoord die de communicatie tussen Microservices kan helpen
- Wanneer JetStream niet geconfigureerd is, worden berichten niet opgeslagen
Waarom er niet voor Kafka is gekozen:
- Standaard worden berichten op schijf opgeslagen
- Het gebruik van middelen is hoog vergeleken met NATS
- Aangezien het JVM nodig heeft, is het geheugengebruik zeer hoog
Samenvatting
De keuze tussen Kafka en NATS hangt af van uw specifieke vereisten op drie belangrijke gebieden: Architectuur en Complexiteit, Prestaties en Schaalbaarheid, en Garanties voor berichtlevering. Kafka is ideaal voor systemen die robuuste gebeurtenisstromen, duurzame opslag en geavanceerde verwerkingsmogelijkheden vereisen, maar het is complexer. NATS daarentegen is lichtgewicht, eenvoudig te beheren en blinkt uit in situaties met lage latentie, hoge doorvoer en eenvoudigere berichtbehoeften.
Bij het ontwerpen van een gedistribueerd berichtensysteem, evalueer deze gebieden zorgvuldig om uw keuze af te stemmen op de doelen en beperkingen van uw toepassing. Zowel Kafka als NATS zijn krachtige tools en de juiste keuze zal afhangen van uw gebruikssituatie.
Belangrijke gebieden om te overwegen bij het kiezen tussen Kafka en NATS:
- Architectuur en complexiteit
- Beschikbaarheid en prestaties
- Garanties voor berichtlevering
Kafka is ideaal voor gedistribueerde systemen die gebeurtenisstreaming, duurzame opslag en geavanceerde verwerkingsmogelijkheden vereisen. Echter, Kafka gaat gepaard met een hoog verbruik van middelen en een groot geheugengebruik. En het beheer is zeer complex in vergelijking met NATS.
Aan de andere kant is NATS lichtgewicht en eenvoudig te beheren. Het vermogen van NATS om berichten met lage latentie te verwerken is kenmerkend.
Uiteindelijk zijn zowel Kafka als NATS krachtige tools voor gebeurtenisverwerking. De keuze hangt af van specifieke gebruikssituaties.
Source:
https://dzone.com/articles/kafka-vs-nats-message-processing