













Status: Verouderd
Dit artikel is verouderd en wordt niet langer onderhouden.
Reden
De stappen in deze handleiding werken nog steeds, maar resulteren in een configuratie die nu onnodig moeilijk te onderhouden is.
Zie in plaats daarvan
Dit artikel kan nog steeds nuttig zijn als referentie, maar volgt mogelijk niet de beste werkwijzen. We raden ten zeerste aan om een meer recent artikel te gebruiken.
Inleiding
Samen met het traceren en vastleggen zijn monitoring en alarmering essentiële componenten van een Kubernetes observability-stack. Door monitoring in te stellen voor uw DigitalOcean Kubernetes-cluster kunt u uw resourcegebruik volgen en applicatiefouten analyseren en oplossen.
A monitoring system usually consists of a time-series database that houses metric data and a visualization layer. In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack.
Een populaire monitoringoplossing is de open-source Prometheus, Grafana, en Alertmanager-stack, uitgerold samen met kube-state-metrics en node_exporter om metrieken op cluster niveau van Kubernetes-objecten en machine-level metrieken zoals CPU- en geheugengebruik bloot te leggen.
Het uitrollen van deze monitoring-stack op een Kubernetes-cluster vereist het configureren van individuele componenten, manifests, Prometheus-metrieken en Grafana-dashboards, wat enige tijd kan kosten. De DigitalOcean Kubernetes Cluster Monitoring Quickstart, uitgebracht door het DigitalOcean Community Developer Education-team, bevat volledig gedefinieerde manifests voor een Prometheus-Grafana-Alertmanager cluster monitoring-stack, evenals een reeks voorgeconfigureerde waarschuwingen en Grafana-dashboards. Het kan u helpen snel aan de slag te gaan en vormt een solide basis om uw observability-stack op te bouwen.
In deze handleiding zullen we deze vooraf geconfigureerde stack implementeren op DigitalOcean Kubernetes, toegang krijgen tot de Prometheus-, Grafana- en Alertmanager-interfaces, en beschrijven hoe deze aan te passen.
Vereisten
Voordat je begint, heb je een DigitalOcean Kubernetes-cluster nodig en moeten de volgende tools geïnstalleerd zijn in je lokale ontwikkelomgeving:
- De
kubectlcommand-line interface geïnstalleerd op je lokale machine en geconfigureerd om verbinding te maken met je cluster. Je kunt meer lezen over het installeren en configureren vankubectlin de officiële documentatie. - Het git versiebeheersysteem geïnstalleerd op je lokale machine. Om te leren hoe je git installeert op Ubuntu 18.04, raadpleeg Hoe Git te installeren op Ubuntu 18.04.
- De Coreutils base64 tool geïnstalleerd op je lokale machine. Als je een Linux-machine gebruikt, is dit waarschijnlijk al geïnstalleerd. Als je OS X gebruikt, kun je
openssl base64gebruiken, dat standaard is geïnstalleerd.
<$>[opmerking]
Opmerking: De Cluster Monitoring Quickstart is alleen getest op DigitalOcean Kubernetes-clusters. Om de Quickstart te gebruiken met andere Kubernetes-clusters, zijn mogelijk enkele aanpassingen aan de manifestbestanden nodig.
<$>
Stap 1 — Het klonen van de GitHub Repository en het configureren van omgevingsvariabelen
Om te beginnen, kloon de DigitalOcean Kubernetes Cluster Monitoring GitHub repository naar je lokale machine met behulp van git:
Vervolgens, navigeer naar de repository:
Je zou de volgende mappenstructuur moeten zien:
OutputLICENSE
README.md
changes.txt
manifest
De manifest map bevat Kubernetes-manifesten voor alle componenten van de monitorstack, inclusief Service Accounts, Deployments, StatefulSets, ConfigMaps, enz. Om meer te weten te komen over deze manifestbestanden en hoe je ze kunt configureren, ga verder naar Het configureren van de monitorstack.
Als je gewoon aan de slag wilt, begin dan met het instellen van de omgevingsvariabelen APP_INSTANCE_NAME en NAMESPACE, die worden gebruikt om een unieke naam te configureren voor de componenten van de stack en om de Namespace te configureren waarin de stack zal worden ingezet:
In deze tutorial stellen we APP_INSTANCE_NAME in op sammy-cluster-monitoring, wat voorvoegsels zal toevoegen aan alle namen van Kubernetes-objecten voor de monitoringstack. Vervang dit door een uniek beschrijvend voorvoegsel voor jouw monitoringstack. We stellen ook de Namespace in op default. Als je de monitoringstack naar een Namespace anders dan default wilt implementeren, zorg er dan voor dat je deze eerst aanmaakt in je cluster:
Je zou de volgende uitvoer moeten zien:
Outputnamespace/sammy created
In dit geval was de omgevingsvariabele NAMESPACE ingesteld op sammy. Gedurende de rest van de tutorial gaan we ervan uit dat NAMESPACE is ingesteld op default.
Gebruik nu het base64-commando om een veilig wachtwoord voor Grafana te coderen in base64-indeling. Vervang zeker het wachtwoord van jouw keuze voor jouw_grafana_wachtwoord:
Als je macOS gebruikt, kun je het openssl base64-commando gebruiken dat standaard is geïnstalleerd.
Op dit punt heb je de Kubernetes-manifesten van de stack opgehaald en de vereiste omgevingsvariabelen geconfigureerd, dus je bent nu klaar om de geconfigureerde variabelen in de Kubernetes-manifestbestanden te vervangen en de stack te maken in je Kubernetes-cluster.
Stap 2 – Het Monitoring Stack creëren
Het DigitalOcean Kubernetes Monitoring Quickstart-repo bevat manifesten voor de volgende monitoring-, scraping- en visualisatiecomponenten:
- Prometheus is een tijdreeksdatabase en monitoringtool die werkt door metrische eindpunten te bevragen en de gegevens bloot te leggen die door deze eindpunten worden blootgesteld. Het stelt u in staat om deze gegevens te bevragen met behulp van PromQL, een querytaal voor tijdreeksgegevens. Prometheus zal worden ingezet in het cluster als een StatefulSet met 2 replica’s die gebruik maakt van Persistent Volumes met DigitalOcean Block Storage. Daarnaast worden een voorgeconfigureerde set Prometheus Alerts, Rules en Jobs opgeslagen als een ConfigMap. Om hier meer over te weten te komen, ga verder naar de Prometheus-sectie van het configureren van de Monitoring Stack.
- Alertmanager, meestal geïmplementeerd naast Prometheus, vormt de waarschuwingslaag van de stack, waarbij waarschuwingen gegenereerd door Prometheus worden afgehandeld en gedupliceerd, gegroepeerd en doorgestuurd naar integraties zoals e-mail of PagerDuty. Alertmanager zal worden geïnstalleerd als een StatefulSet met 2 replica’s. Raadpleeg voor meer informatie over Alertmanager Alerting in de Prometheus-documentatie.
- Grafana is een tool voor gegevensvisualisatie en -analyse waarmee u dashboards en grafieken kunt maken voor uw metriekgegevens. Grafana wordt geïnstalleerd als een StatefulSet met één replica. Bovendien worden een voorgeconfigureerde set Dashboards gegenereerd door kubernetes-mixin opgeslagen als een ConfigMap.
- kube-state-metrics is een add-on-agent die luistert naar de Kubernetes API-server en metrieken genereert over de status van Kubernetes-objecten zoals Deployments en Pods. Deze metrieken worden als platte tekst geserveerd op HTTP-eindpunten en geconsumeerd door Prometheus. kube-state-metrics wordt geïnstalleerd als een automatisch schaalbare Deployment met één replica.
- node-exporter, een Prometheus-exporteur die draait op clusterknooppunten en OS- en hardwaremetrieken zoals CPU- en geheugengebruik aan Prometheus levert. Deze metrieken worden ook als platte tekst geserveerd op HTTP-eindpunten en geconsumeerd door Prometheus. node-exporter wordt geïnstalleerd als een DaemonSet.
Standaard zal Prometheus, samen met het schrapen van metrics gegenereerd door node-exporter, kube-state-metrics en de andere hierboven genoemde componenten, geconfigureerd worden om metrics te schrapen van de volgende componenten:
- kube-apiserver, de Kubernetes API-server.
- kubelet, de primaire node-agent die interactie heeft met kube-apiserver om Pods en containers op een node te beheren.
- cAdvisor, een node-agent die actieve containers ontdekt en hun CPU-, geheugen-, bestandssysteem- en netwerkgebruiksmetrics verzamelt.
Om meer te weten te komen over het configureren van deze componenten en Prometheus-schraaptaken, ga naar Het configureren van de monitoringsstack. We zullen nu de omgevingsvariabelen die gedefinieerd zijn in de vorige stap vervangen in de manifestbestanden van het repository en de afzonderlijke manifesten samenvoegen tot één masterbestand.
Begin met het gebruik van awk en envsubst om de variabelen APP_INSTANCE_NAME, NAMESPACE en GRAFANA_GENERATED_PASSWORD in de manifestbestanden van de repository in te vullen. Na het vervangen van de variabele waarden worden de bestanden samengevoegd en opgeslagen in een master-manifestbestand genaamd sammy-cluster-monitoring_manifest.yaml.
Overweeg om dit bestand op te slaan in versiebeheer zodat je wijzigingen in de monitoringstack kunt bijhouden en terug kunt rollen naar eerdere versies. Als je dit doet, zorg er dan voor dat je het admin-password-variabele uit het bestand verwijdert, zodat je je Grafana-wachtwoord niet in versiebeheer opneemt.
Nadat je het master-manifestbestand hebt gegenereerd, gebruik je kubectl apply -f om het manifest toe te passen en de stack te maken in de geconfigureerde Namespace:
Je zou output moeten zien die vergelijkbaar is met het volgende:
Outputserviceaccount/alertmanager created
configmap/sammy-cluster-monitoring-alertmanager-config created
service/sammy-cluster-monitoring-alertmanager-operated created
service/sammy-cluster-monitoring-alertmanager created
. . .
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/sammy-cluster-monitoring-prometheus-config created
service/sammy-cluster-monitoring-prometheus created
statefulset.apps/sammy-cluster-monitoring-prometheus created
Je kunt de voortgang van de implementatie van de stack volgen met kubectl get all. Zodra alle componenten van de stack RUNNING zijn, kun je toegang krijgen tot de voorgeconfigureerde Grafana-dashboards via de Grafana-webinterface.
Stap 3 — Toegang tot Grafana en Verkennen van Metriekgegevens
Het Grafana Service-manifest maakt Grafana beschikbaar als een ClusterIP-service, wat betekent dat het alleen toegankelijk is via een clusterinterne IP-adres. Om toegang te krijgen tot Grafana buiten je Kubernetes-cluster, kun je ofwel kubectl patch gebruiken om de Service ter plaatse bij te werken naar een type dat publiekelijk toegankelijk is, zoals NodePort of LoadBalancer, of kubectl port-forward gebruiken om een lokaal poort door te sturen naar een poort van een Grafana Pod. In deze tutorial sturen we poorten door, zodat je kunt doorgaan naar Het doorsturen van een lokaal poort om toegang te krijgen tot de Grafana-service. De volgende sectie over het extern blootstellen van Grafana is opgenomen ter referentie.
Het blootstellen van de Grafana-service met behulp van een Load Balancer (optioneel)
Als je een DigitalOcean Load Balancer voor Grafana wilt maken met een extern openbaar IP-adres, gebruik dan kubectl patch om de bestaande Grafana Service ter plaatse bij te werken naar het Service-type LoadBalancer:
De patch-opdracht van kubectl stelt u in staat om Kubernetes-objecten ter plaatse bij te werken om wijzigingen aan te brengen zonder de objecten opnieuw te hoeven implementeren. U kunt ook de hoofdmanifestbestand rechtstreeks wijzigen door een type: LoadBalancer-parameter toe te voegen aan de specificatie van de Grafana-service. Voor meer informatie over kubectl patch en Kubernetes-service typen, kunt u de bronnen API-objecten ter plaatse bijwerken met kubectl patch en Services raadplegen in de officiële Kubernetes-documentatie.
Na uitvoering van bovenstaand commando zou u het volgende moeten zien:
Outputservice/sammy-cluster-monitoring-grafana patched
Het kan enkele minuten duren voordat de Load Balancer is gemaakt en eraan een openbaar IP is toegewezen. U kunt de voortgang volgen met het volgende commando met de -w-vlag om wijzigingen te volgen:
Zodra de DigitalOcean Load Balancer is gemaakt en aan een extern IP-adres is toegewezen, kunt u het externe IP ophalen met de volgende commando’s:
U kunt nu toegang krijgen tot de Grafana UI door naar http://SERVICE_IP/ te navigeren.
Het doorsturen van een lokale poort om toegang te krijgen tot de Grafana-service
Als u de Grafana-service niet extern wilt blootstellen, kunt u ook lokaal poort 3000 doorsturen naar de cluster rechtstreeks naar een Grafana-pod met behulp van kubectl port-forward.
U zou de volgende uitvoer moeten zien:
OutputForwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Dit zal de lokale poort 3000 doorsturen naar containerPort 3000 van de Grafana Pod sammy-cluster-monitoring-grafana-0. Om meer te weten te komen over het doorsturen van poorten naar een Kubernetes-cluster, raadpleegt u Gebruik Poortdoorsturing om Toepassingen in een Cluster te Bereiken.
Bezoek http://localhost:3000 in uw webbrowser. U zou de volgende Grafana-aanmeldingspagina moeten zien:

Om in te loggen, gebruik de standaard gebruikersnaam admin (als u de parameter admin-user niet heeft gewijzigd), en het wachtwoord dat u hebt geconfigureerd in Stap 1.
U wordt gebracht naar het volgende Startdashboard:
In de navigatiebalk aan de linkerkant, selecteer de Dashboard-knop, klik vervolgens op Beheren:
U wordt gebracht naar de volgende dashboard-beheerinterface, die de dashboards opsomt die zijn geconfigureerd in het dashboards-configmap.yaml manifest:
Deze dashboards worden gegenereerd door kubernetes-mixin, een open-source project dat u in staat stelt om een gestandaardiseerde set clustermonitoring Grafana-dashboards en Prometheus-waarschuwingen te maken. Om meer te weten te komen, raadpleeg de kubernetes-mixin GitHub repo.
Klik op het Kubernetes / Nodes-dashboard, dat CPU-, geheugen-, schijf- en netwerkgebruik visualiseert voor een bepaalde node:
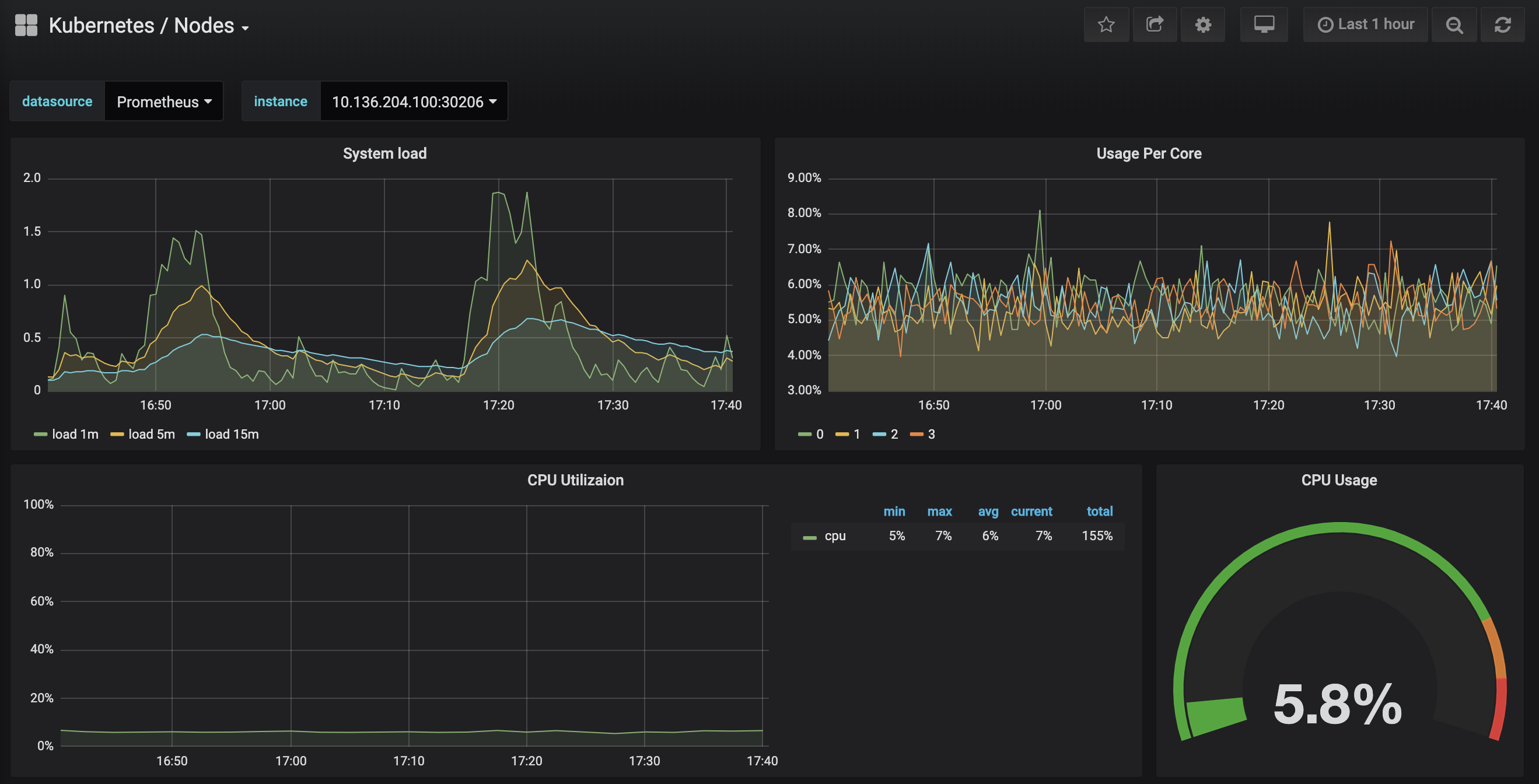
Een beschrijving van hoe u deze dashboards kunt gebruiken valt buiten de scope van deze tutorial, maar u kunt de volgende bronnen raadplegen om meer te weten te komen:
- Om meer te weten te komen over de USE-methode voor het analyseren van de prestaties van een systeem, kunt u de pagina The Utilization Saturation and Errors (USE) Method van Brendan Gregg raadplegen.
- Google’s SRE Book is een andere nuttige bron, met name Hoofdstuk 6: Monitoring Distributed Systems.
- Om te leren hoe u uw eigen Grafana-dashboards kunt bouwen, bekijk Grafana’s Getting Started-pagina.
In de volgende stap zullen we een vergelijkbaar proces volgen om verbinding te maken met en de Prometheus-bewakingssysteem te verkennen.
Stap 4 — Toegang tot Prometheus en Alertmanager
Om verbinding te maken met de Prometheus-pods, kunnen we kubectl port-forward gebruiken om een lokaal poort door te sturen. Als je klaar bent met het verkennen van Grafana, kun je de poort-doorstuurtunnel sluiten door op CTRL-C te drukken. Je kunt ook een nieuwe shell openen en een nieuwe poort-doorstuursverbinding maken.
Begin met het weergeven van de draaiende pods in de default namespace:
Je zou de volgende pods moeten zien:
Outputsammy-cluster-monitoring-alertmanager-0 1/1 Running 0 17m
sammy-cluster-monitoring-alertmanager-1 1/1 Running 0 15m
sammy-cluster-monitoring-grafana-0 1/1 Running 0 16m
sammy-cluster-monitoring-kube-state-metrics-d68bb884-gmgxt 2/2 Running 0 16m
sammy-cluster-monitoring-node-exporter-7hvb7 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-c2rvj 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-w8j74 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-0 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-1 1/1 Running 0 16m
We gaan de lokale poort 9090 doorsturen naar poort 9090 van de pod sammy-cluster-monitoring-prometheus-0:
Je zou de volgende uitvoer moeten zien:
OutputForwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Dit geeft aan dat de lokale poort 9090 succesvol wordt doorgestuurd naar de Prometheus-pod.
Bezoek http://localhost:9090 in je webbrowser. Je zou de volgende Prometheus Grafiek-pagina moeten zien:

Vanaf hier kun je PromQL gebruiken, de Prometheus-querytaal, om tijdreeksmetingen te selecteren en te aggregeren die zijn opgeslagen in de database. Raadpleeg voor meer informatie over PromQL Het bevragen van Prometheus in de officiële Prometheus-documentatie.
In het veld Expressie, typ kubelet_node_name en druk op Uitvoeren. Je zou een lijst met tijdreeksen moeten zien met de metriek kubelet_node_name die de Nodes in je Kubernetes-cluster rapporteert. Je kunt zien welke node de metriek heeft gegenereerd en welke taak de metriek heeft geschaad in de metrieklabels:

Tenslotte, klik op de bovenste navigatiebalk op Status en vervolgens op Doelen om de lijst met doelen te zien die Prometheus is geconfigureerd om te schrapen. Je zou een lijst met doelen moeten zien die overeenkomen met de lijst met bewakingsendpoints die aan het begin van Stap 2 zijn beschreven.
Om meer te weten te komen over Prometheus en hoe je je clustermetrieken kunt bevragen, raadpleeg de officiële Prometheus-documentatie.
Om verbinding te maken met Alertmanager, dat de door Prometheus gegenereerde waarschuwingen beheert, volgen we een vergelijkbaar proces als wat we hebben gebruikt om verbinding te maken met Prometheus. Over het algemeen kun je Alertmanager-waarschuwingen verkennen door naar Waarschuwingen te gaan in de bovenste navigatiebalk van Prometheus.
Om verbinding te maken met de Alertmanager-pods, zullen we opnieuw kubectl port-forward gebruiken om een lokale poort door te sturen. Als je klaar bent met het verkennen van Prometheus, kun je de port-forward-tunnel sluiten door op CTRL-C te drukken of een nieuwe shell te openen om een nieuwe verbinding tot stand te brengen.
We gaan lokale poort 9093 doorsturen naar poort 9093 van de sammy-cluster-monitoring-alertmanager-0 Pod:
Je zou de volgende uitvoer moeten zien:
OutputForwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
Dit geeft aan dat lokale poort 9093 succesvol wordt doorgestuurd naar een Alertmanager Pod.
Bezoek http://localhost:9093 in je webbrowser. Je zou de volgende Alertmanager Alerts pagina moeten zien:
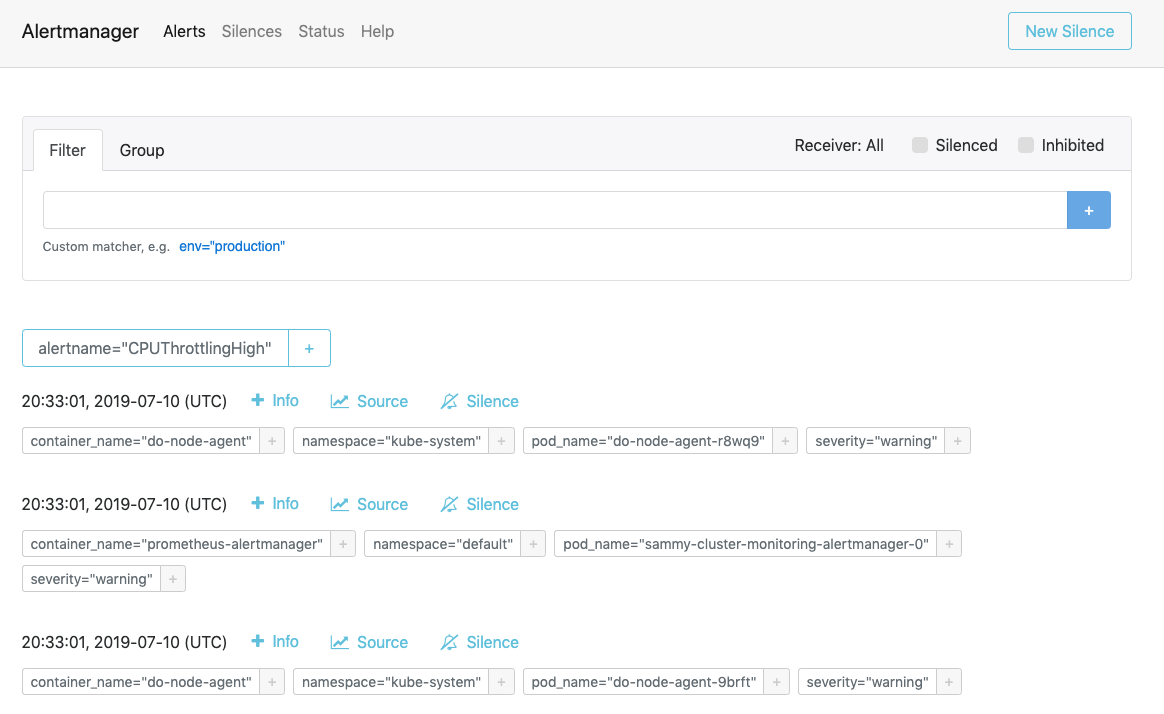
Vanaf hier kun je actieve meldingen verkennen en ze eventueel dempen. Voor meer informatie over Alertmanager, raadpleeg de officiële Alertmanager documentatie.
In de volgende stap leer je hoe je optioneel enkele van de componenten van de monitoringstack kunt configureren en schalen.
Stap 6 — Configuratie van de Monitoring Stack (optioneel)
De manifesten die zijn opgenomen in de DigitalOcean Kubernetes Cluster Monitoring Quickstart repository kunnen worden aangepast om verschillende containerimages, verschillende aantallen Pod-replica’s, verschillende poorten en aangepaste configuratiebestanden te gebruiken.
In deze stap zullen we een hoog niveau overzicht geven van het doel van elk manifest, en vervolgens demonstreren hoe je Prometheus kunt schalen tot 3 replica’s door het hoofdmanifestbestand te wijzigen.
Om te beginnen, navigeer naar de manifests submap in de repo, en lijst de inhoud van de map op:
Outputalertmanager-0serviceaccount.yaml
alertmanager-configmap.yaml
alertmanager-operated-service.yaml
alertmanager-service.yaml
. . .
node-exporter-ds.yaml
prometheus-0serviceaccount.yaml
prometheus-configmap.yaml
prometheus-service.yaml
prometheus-statefulset.yaml
Hier vind je manifesten voor de verschillende componenten van de monitoring stack. Om meer te weten te komen over specifieke parameters in de manifesten, klik op de links en raadpleeg de opmerkingen die zijn opgenomen in de YAML-bestanden:
Alertmanager
-
alertmanager-0serviceaccount.yaml: De Alertmanager Service Account, gebruikt om de Alertmanager Pods een Kubernetes-identiteit te geven. Om meer te weten te komen over Service Accounts, raadpleeg Configureer Service Accounts voor Pods. -
alertmanager-configmap.yaml: Een ConfigMap met een minimaal Alertmanager configuratiebestand, genaamdalertmanager.yml. Het configureren van Alertmanager valt buiten de reikwijdte van deze zelfstudie, maar u kunt meer leren door de Configuratie sectie van de Alertmanager documentatie te raadplegen. -
alertmanager-operated-service.yaml: De AlertmanagermeshService, die wordt gebruikt voor het routeren van verzoeken tussen Alertmanager Pods in de huidige 2-replica hoge beschikbaarheidsconfiguratie. -
alertmanager-service.yaml: De AlertmanagerwebService, die wordt gebruikt om toegang te krijgen tot de Alertmanager-webinterface, die u mogelijk in de vorige stap hebt gedaan. -
alertmanager-statefulset.yaml: De Alertmanager StatefulSet, geconfigureerd met 2 replicas.
Grafana
-
dashboards-configmap.yaml: Een ConfigMap met de voorgeconfigureerde JSON Grafana bewakingsdashboards. Het genereren van een nieuwe set dashboards en meldingen vanaf nul valt buiten de reikwijdte van deze tutorial, maar voor meer informatie kunt u de kubernetes-mixin GitHub-repo raadplegen. -
grafana-0serviceaccount.yaml: De Grafana-serviceaccount. -
grafana-configmap.yaml: Een ConfigMap met een standaardset minimale Grafana-configuratiebestanden. -
grafana-secret.yaml: Een Kubernetes Secret met de Grafana-beheerder gebruikersnaam en wachtwoord. Voor meer informatie over Kubernetes Secrets, raadpleeg Secrets. -
grafana-service.yaml: Het manifest dat de Grafana-service definieert. -
grafana-statefulset.yaml: De Grafana StatefulSet, geconfigureerd met 1 replica, die niet schaalbaar is. Het schalen van Grafana valt buiten de scope van deze tutorial. Om te leren hoe je een zeer beschikbare Grafana-opstelling kunt maken, kun je How to setup Grafana for High Availability raadplegen in de officiële Grafana-documentatie.
kube-state-metrics
-
kube-state-metrics-0serviceaccount.yaml: De kube-state-metrics Service Account en ClusterRole. Om meer te weten te komen over ClusterRoles, raadpleeg Role and ClusterRole in de Kubernetes-documentatie. -
kube-state-metrics-deployment.yaml: Het hoofdmanifest van kube-state-metrics Deployment, geconfigureerd met 1 dynamisch schaalbare replica met gebruik vanaddon-resizer. -
kube-state-metrics-service.yaml: De Service die dekube-state-metricsDeployment blootstelt.
node-exporter
-
node-exporter-0serviceaccount.yaml: De Service Account van node-exporter. -
node-exporter-ds.yaml: Het manifest van de DaemonSet van node-exporter. Aangezien node-exporter een DaemonSet is, wordt een node-exporter Pod uitgevoerd op elke Node in het cluster.
###Prometheus
-
prometheus-0serviceaccount.yaml: De Service Account, ClusterRole en ClusterRoleBinding van Prometheus. -
prometheus-configmap.yaml: Een ConfigMap die drie configuratiebestanden bevat:alerts.yaml: Bevat een voorgeconfigureerde set alerts gegenereerd doorkubernetes-mixin(die ook werd gebruikt om de Grafana-dashboards te genereren). Voor meer informatie over het configureren van waarschuwingsregels, raadpleeg Waarschuwingsregels in de Prometheus-documentatie.prometheus.yaml: Het hoofdconfiguratiebestand van Prometheus. Prometheus is vooraf geconfigureerd om alle componenten die aan het begin van Stap 2 zijn vermeld, te schrapen. Het configureren van Prometheus gaat buiten de scope van dit artikel, maar voor meer informatie kunt u Configuratie raadplegen in de officiële Prometheus-documentatie.rules.yaml: Een set Prometheus-opname regels die Prometheus in staat stellen om vaak benodigde of rekenintensieve expressies te berekenen, en hun resultaten op te slaan als een nieuwe set tijdreeksen. Deze worden ook gegenereerd doorkubernetes-mixin, en het configureren ervan gaat buiten de scope van dit artikel. Voor meer informatie kunt u Opnameregels raadplegen in de officiële Prometheus-documentatie.
-
prometheus-service.yaml: De Service die de Prometheus StatefulSet blootstelt. -
prometheus-statefulset.yaml: De Prometheus StatefulSet, geconfigureerd met 2 replica’s. Dit parameter kan worden geschaald afhankelijk van uw behoeften.
Voorbeeld: Prometheus schalen
Om te demonstreren hoe de monitoringstack aangepast kan worden, zullen we het aantal Prometheus replica’s verhogen van 2 naar 3.
Open het hoofdmanifestbestand sammy-cluster-monitoring_manifest.yaml met uw gekozen editor:
Scroll naar beneden naar de Prometheus StatefulSet sectie van het manifest:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 2
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Verander het aantal replica’s van 2 naar 3:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 3
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Als u klaar bent, sla het bestand op en sluit het af.
Pas de wijzigingen toe met kubectl apply -f:
Je kunt de voortgang volgen met kubectl get pods. Met dezelfde techniek kun je veel van de Kubernetes parameters en een groot deel van de configuratie voor deze observability stack bijwerken.
Conclusie
In deze tutorial heb je een Prometheus, Grafana en Alertmanager monitoring stack geïnstalleerd in je DigitalOcean Kubernetes cluster met een standaard set dashboards, Prometheus regels en alerts.
Je kunt er ook voor kiezen om deze monitoring stack uit te rollen met behulp van de Helm Kubernetes package manager. Voor meer informatie kun je How to Set Up DigitalOcean Kubernetes Cluster Monitoring with Helm and Prometheus raadplegen. Een alternatieve manier om een soortgelijke stack te implementeren is door gebruik te maken van de DigitalOcean Marketplace Kubernetes Monitoring Stack solution, momenteel in bèta.
Het DigitalOcean Kubernetes Cluster Monitoring Quickstart repository is sterk gebaseerd op en aangepast van de click-to-deploy Prometheus-oplossing van Google Cloud Platform. Een volledig manifest van wijzigingen en aanpassingen van het oorspronkelijke repository is te vinden in het changes.md bestand van het Quickstart repository.