













저자는 자유 및 오픈 소스 기금을 Donate 프로그램의 일환으로 기부 대상으로 선택했습니다.
소개
데이터베이스 모니터링은 데이터베이스의 성능을 보여주는 다양한 지표를 체계적으로 추적하는 지속적인 과정입니다. 성능 데이터를 관찰함으로써 가치 있는 통찰력을 얻을 수 있으며 가능한 병목 현상을 식별하고 데이터베이스 성능을 향상시킬 수 있는 추가적인 방법을 찾을 수 있습니다. 이러한 시스템은 종종 관리자에게 문제가 발생했을 때 알림을 보내는 경보 기능을 구현합니다. 수집된 통계는 데이터베이스의 구성 및 작업 흐름 뿐만 아니라 클라이언트 응용 프로그램의 구성 및 작업 흐름을 개선하는 데에도 사용될 수 있습니다.
Elastic Stack (ELK 스택)을 사용하여 관리되는 데이터베이스를 모니터링하는 이점은 검색을 위한 탁월한 지원과 새로운 데이터를 매우 빠르게 수집할 수 있는 능력입니다. 데이터를 업데이트하는 데 뛰어나지는 않지만, 이러한 트레이드 오프는 거의 결코 과거 데이터가 변경되지 않는 모니터링 및 로깅 목적으로는 허용할 수 있습니다. Elasticsearch는 데이터를 쿼리하는 강력한 방법을 제공하며, 이를 통해 Kibana를 사용하여 데이터베이스가 다른 시간대를 통해 어떻게 수행되는지에 대한 더 나은 이해를 얻을 수 있습니다. 이를 통해 데이터베이스 부하와 실제 이벤트를 상관시켜 데이터베이스의 사용 방법에 대한 통찰력을 얻을 수 있습니다.
이 튜토리얼에서는 Redis INFO 명령으로 생성된 데이터베이스 메트릭을 Elasticsearch로 가져옵니다. 이를 위해 Logstash를 구성하여 주기적으로 명령을 실행하고 출력을 구문 분석한 다음 즉시 Elasticsearch로 보내 인덱싱합니다. 가져온 데이터는 나중에 Kibana에서 분석 및 시각화할 수 있습니다. 튜토리얼을 마치면 나중에 분석할 Redis 통계를 자동으로 가져오는 시스템이 구축됩니다.
필수 조건
- 우분투 18.04 서버는 적어도 8GB RAM, 루트 권한 및 보조 비 루트 계정이 필요합니다. 이를 설정하려면 이 초기 서버 설정 안내서를 따르십시오. 이 튜토리얼에서 보조 사용자는
sammy입니다. - 서버에 Java 8이 설치되어 있어야 합니다. 설치 지침은 우분투 18.04에 Java 설치하기를 참조하고 첫 번째 단계에 나와 있는 명령을 따르십시오. Java 개발 키트(JDK)를 설치할 필요는 없습니다.
- 서버에 Nginx가 설치되어 있어야 합니다. 설치 방법에 대한 안내서는 우분투 18.04에 Nginx 설치하기를 참조하십시오.
- 서버에 Elasticsearch 및 Kibana가 설치되어 있어야 합니다. 우분투 18.04에 Elasticsearch, Logstash 및 Kibana(Elastic Stack) 설치하기 튜토리얼의 처음 두 단계를 완료하십시오.
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- 서버에 Redli가 설치되어 있어야 합니다. 우분투 18.04에서 관리되는 데이터베이스에 연결하는 방법 튜토리얼에 따라 설치하십시오.
단계 1 — Logstash 설치 및 구성
이 섹션에서는 Logstash를 설치하고 Redis 데이터베이스 클러스터에서 통계를 추출하도록 구성한 다음 이를 Elasticsearch에 색인하기 위해 구문 분석합니다.
다음 명령을 사용하여 Logstash를 설치합니다:
Logstash를 설치한 후 서비스를 부팅시 자동으로 시작하도록 활성화합니다:
통계를 추출하기 전에 Logstash를 구성하기 전에 데이터 자체가 어떻게 보이는지 살펴보겠습니다. Redis 데이터베이스에 연결하려면 관리되는 데이터베이스 제어판으로 이동하여 드롭다운에서 연결 세부 정보 패널 아래에서 플래그를 선택하십시오:
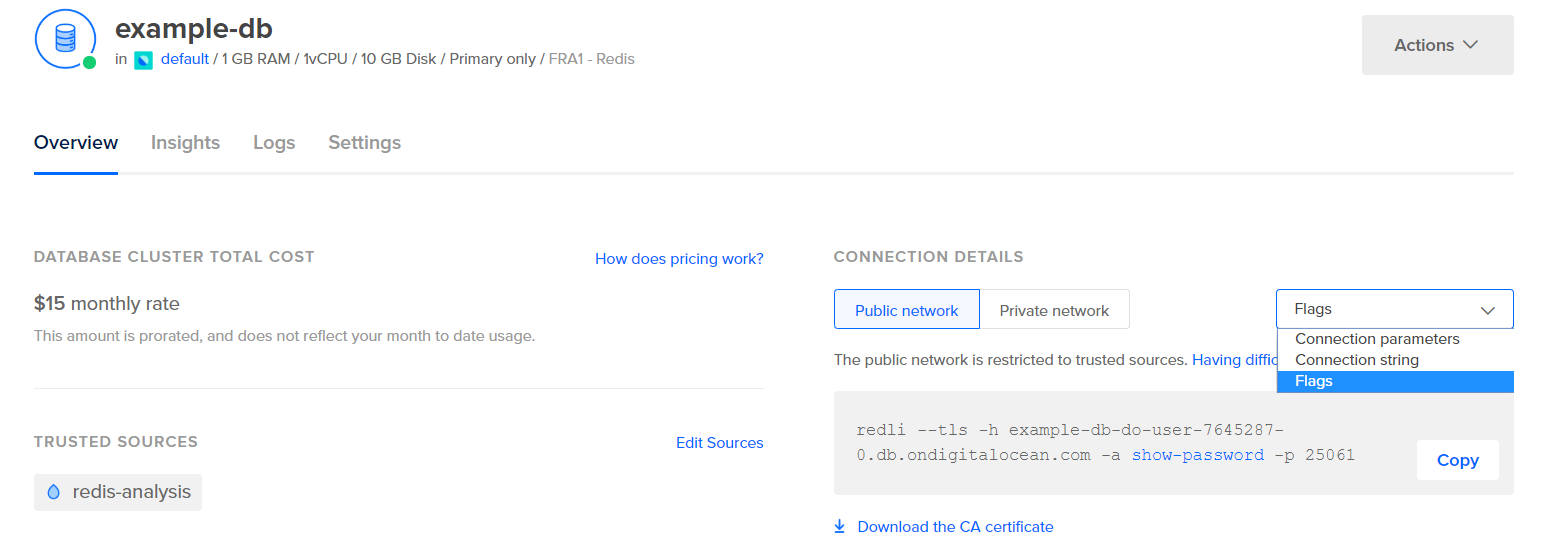
데이터베이스에 연결하기 위해 사용할 Redli 클라이언트에 대한 미리 구성된 명령이 표시됩니다. 명령을 복사하고 다음 명령을 서버에서 실행하십시오. 복사한 명령으로 redli_flags_command을(를) 대체하십시오:
이 명령의 출력이 긴 경우 이를 서로 다른 섹션으로 분할하여 설명하겠습니다.
Redis info 명령의 출력에서 섹션은 #으로 표시되며 이는 주석을 나타냅니다. 값은 key:value 형식으로 채워지며 이는 비교적 쉽게 구문 분석됩니다.
Server 섹션에는 Redis 빌드에 대한 기술적 정보가 포함되어 있으며, 버전 및 Git 커밋을 기반으로 합니다. Clients 섹션에는 현재 열려 있는 연결 수가 제공됩니다.
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memory는 Redis가 자체적으로 할당한 RAM 양과 최대로 사용할 수 있는 메모리 양을 확인합니다. 메모리가 부족해지면, 제어판에 지정한 전략을 사용하여 키를 해제합니다(이 출력의 maxmemory_policy 필드에 표시됨).
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
Persistence 섹션에서는 Redis가 저장된 키를 디스크에 저장한 마지막 시간과 성공 여부를 볼 수 있습니다. Stats 섹션은 클라이언트 및 클러스터 연결과 요청된 키를 찾은(또는 찾지 못한) 횟수 등과 관련된 숫자를 제공합니다.
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Replication 아래의 role을 살펴보면 기본 노드에 연결되었는지 또는 복제 노드에 연결되었는지 알 수 있습니다. 나머지 섹션에는 현재 연결된 복제본 수와 주요에 비해 부족한 복제본의 데이터 양이 제공됩니다. 연결된 인스턴스가 복제본인 경우 추가 필드가 있을 수 있습니다.
참고: Redis 프로젝트는 문서 및 다양한 명령에서 “master” 및 “slave” 용어를 사용합니다. DigitalOcean은 일반적으로 “primary” 및 “replica”와 같은 대안 용어를 선호합니다. 이 가이드에서는 가능한 경우 “primary” 및 “replica” 용어를 기본으로 사용하지만, “master” 및 “slave” 용어가 피할 수 없게 사용되는 경우가 몇 가지 있음을 유의하십시오.
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
CPU 아래에서 현재 Redis가 사용하는 시스템 (used_cpu_sys) 및 사용자 (used_cpu_user) CPU 성능 양을 확인할 수 있습니다. Cluster 섹션에는 유일한 필드인 cluster_enabled만 포함되어 있으며, 이는 Redis 클러스터가 실행 중임을 나타냅니다.
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# 오류 통계
# 클러스터
cluster_enabled:0
# Keyspace
Logstash는 주기적으로 Redis 데이터베이스에서 info 명령을 실행하고 결과를 구문 분석하여 Elasticsearch로 전송할 것입니다. 그런 다음 Kibana에서 나중에 액세스할 수 있습니다.
Redis 통계를 Elasticsearch에 인덱싱하는 구성을 /etc/logstash/conf.d 디렉터리 아래의 redis.conf 파일에 저장합니다. 서비스로 시작하면 백그라운드에서 자동으로 실행됩니다.
즐겨 사용하는 편집기(예: nano)를 사용하여 redis.conf를 만듭니다:
다음 줄을 추가합니다:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
제어판에서 이전 단계에서 사용한 명령으로 redis_flags_command를 대체해야 합니다.
당신은 input을 정의하고, 이는 수집된 데이터에서 실행될 필터 세트이며, 필터링된 데이터를 Elasticsearch로 전송할 출력을 정의합니다. 입력은 주기적으로 서버에서 command를 실행할 exec 명령을 포함하며, 설정된 시간 간격(interval)(초 단위) 후에 실행됩니다. 또한 Elasticsearch에 인덱싱될 때 문서 유형을 정의하는 type 매개변수를 지정합니다. exec 블록은 command와 message 문자열을 포함하는 객체를 전달합니다. command 필드에는 실행된 명령이 포함되고, message에는 그 출력이 포함됩니다.
데이터에서 순차적으로 두 개의 필터가 실행됩니다. kv 필터는 키-값 필터를 나타내며, Logstash에 기본적으로 내장되어 있습니다. 이는 keyvalue_separatorvalue의 일반 형식으로 데이터를 구문 분석하는 데 사용되며, 어떤 것이 값 및 필드 구분 기호로 간주되는지를 지정하는 매개변수를 제공합니다. 필드 구분 기호는 일반 형식으로 포맷된 데이터를 서로 구분하는 문자열에 해당합니다. Redis INFO 명령의 출력의 경우, 필드 구분 기호(field_split)는 새 줄이고, 값 구분 기호(value_split)는 :입니다. 정의된 형식을 따르지 않는 행은 주석을 포함하여 버려집니다.
kv 필터를 구성하려면 value_split 매개변수에 :를 전달하고, field_split 매개변수에는 새 줄을 나타내는 \r\n을 전달합니다. 또한 remove_field에 현재 데이터 객체에서 command 및 message 필드를 배열 요소로 전달하여 더 이상 유용하지 않은 데이터를 제거하도록 지시합니다.
kv 필터는 값을 구문 분석한 값을 문자열(텍스트) 유형으로 나타냅니다. 이는 실제로 숫자인 경우에도 Kibana가 문자열 유형을 쉽게 처리할 수 없는 문제를 제기합니다. 이 문제를 해결하기 위해 가능한 경우 숫자만 있는 문자열을 숫자로 변환하는 사용자 정의 루비 코드를 사용할 것입니다. 두 번째 필터는 code 매개변수를 받아 실행할 코드를 포함하는 문자열을 받는 ruby 블록입니다.
event는 Logstash가 코드에 제공하는 변수로, 필터 파이프라인에서 현재 데이터를 포함합니다. 필터가 하나씩 순차적으로 실행되기 때문에 루비 필터는 kv 필터에서 구문 분석된 데이터를 받게 됩니다. 루비 코드 자체는 event를 해시로 변환하고 키를 통해 순회한 다음, 해당 키와 연결된 값이 정수 또는 소수점을 가진 부동 소수점 수(실수)로 표현될 수 있는지 확인합니다. 가능한 경우, 문자열 값은 구문 분석된 숫자로 대체됩니다. 루프가 종료되면 진행 상황을 보고하기 위해 메시지(Ruby filter finished)를 출력합니다.
출력은 처리된 데이터를 Elasticsearch로 색인화합니다. 생성된 문서는 입력에서 정의되고 출력 블록에 매개변수로 전달된 redis_info 인덱스에 저장됩니다.
파일을 저장하고 닫으세요.
단계 2 — Logstash 구성 테스트
이제 Logstash를 실행하여 데이터를 올바르게 가져오는지 확인하기 위해 구성을 테스트할 것입니다.
Logstash는 -f 매개변수에 파일 경로를 전달하여 특정 구성을 실행하는 것을 지원합니다. 다음 명령을 실행하여 이전 단계에서 새 구성을 테스트합니다:
출력이 표시되기까지 시간이 걸릴 수 있지만 곧 다음과 비슷한 것이 표시됩니다:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
일정한 간격으로(<이전 단계에서 10초로 설정됨) Ruby filter finished 메시지가 인쇄되는 것을 볼 수 있습니다. 이는 통계가 Elasticsearch로 전송되고 있는 것을 의미합니다.
이전에 언급한 대로 Logstash는 서비스로 시작될 때 /etc/logstash/conf.d에서 찾은 모든 구성 파일을 백그라운드에서 자동으로 실행합니다. 다음 명령을 실행하여 Logstash를 시작하세요:
Logstash를 실행하여 Redis 클러스터에 연결하고 데이터를 수집할 수 있는지 확인했습니다. 그다음에는 Kibana에서 일부 통계 데이터를 살펴볼 것입니다.
단계 3 — Kibana에서 가져온 데이터 탐색
이 섹션에서는 Kibana에서 데이터베이스 성능을 설명하는 통계 데이터를 탐색하고 시각화할 것입니다.
웹 브라우저에서 먼저 사전 준비 작업 중 일부로 Kibana를 노출한 도메인으로 이동하십시오. 기본 환영 페이지가 표시됩니다:
Elasticsearch에 Logstash가 보내는 데이터를 탐색하기 전에 먼저 Kibana에 redis_info 인덱스를 추가해야 합니다. 이를 위해 먼저 환영 페이지에서 직접 탐색을 선택한 다음 왼쪽 상단의 햄버거 메뉴를 엽니다. 분석 아래에서 검색을 클릭하십시오.
그러면 Kibana에서 새로운 인덱스 패턴을 만들라는 프롬프트가 표시됩니다:
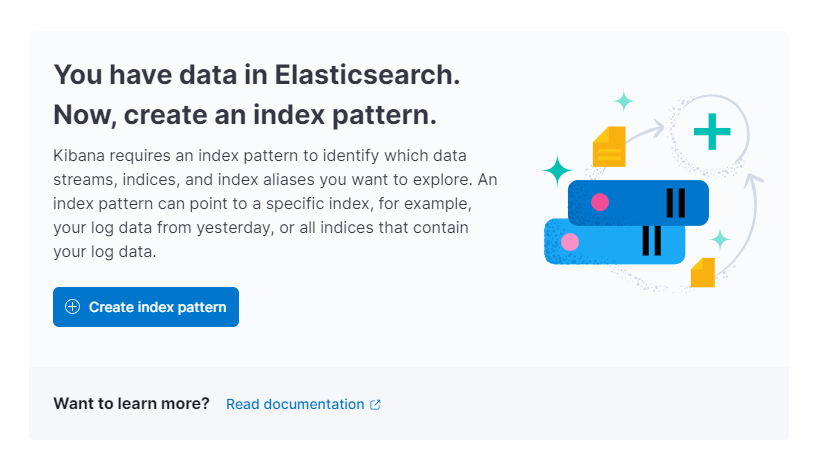
인덱스 패턴 생성을 누르십시오. 새로운 인덱스 패턴을 생성하기 위한 양식이 표시됩니다. Kibana의 인덱스 패턴은 여러 Elasticsearch 인덱스에서 데이터를 한꺼번에 가져오는 방법을 제공하며 하나의 인덱스만 탐색하는 데 사용할 수 있습니다.

오른쪽에는 Kibana가 구성한 Logstash에서 사용할 redis_info와 같은 모든 사용 가능한 인덱스가 나열됩니다. Name 텍스트 필드에 입력하고 드롭다운에서 @timestamp를 타임스탬프 필드로 선택하세요. 작업이 완료되면 아래에 있는 인덱스 패턴 생성 버튼을 누르세요.
시각화를 생성하고 기존 시각화를 보려면 햄버거 메뉴를 열어주세요. 분석 아래에서 대시보드를 선택하세요. 로드되면 새로운 시각화를 생성하기 위해 시각화 생성를 누르세요:
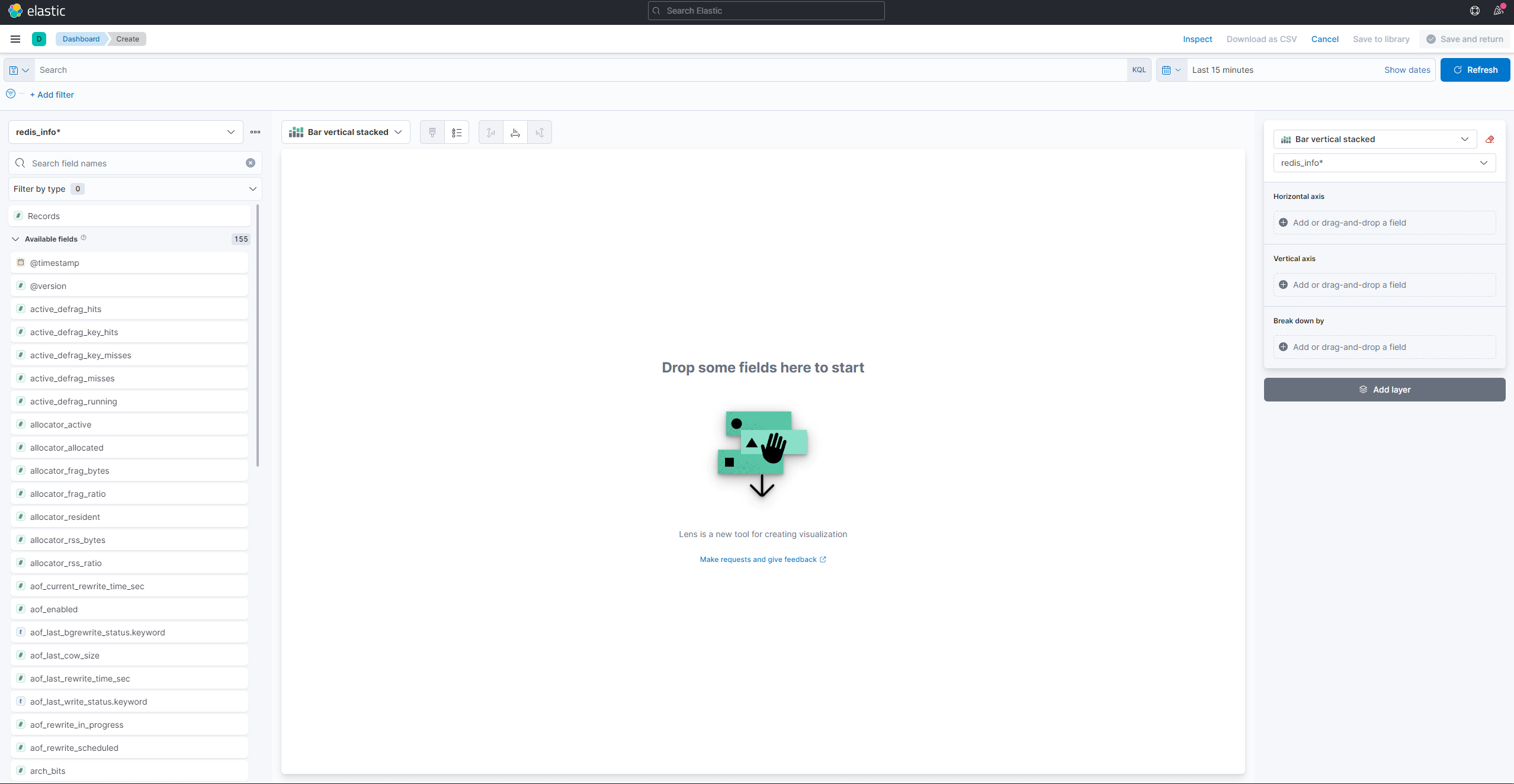
왼쪽 패널은 Kibana가 시각화를 그리는 데 사용할 수 있는 값 목록을 제공하며, 이는 화면의 중앙 부분에 표시됩니다. 화면의 오른쪽 상단에는 날짜 범위 선택기가 있습니다. 시각화에 @timestamp 필드가 사용되는 경우, Kibana는 범위 선택기에서 지정된 시간 간격에 속하는 데이터만 표시합니다.
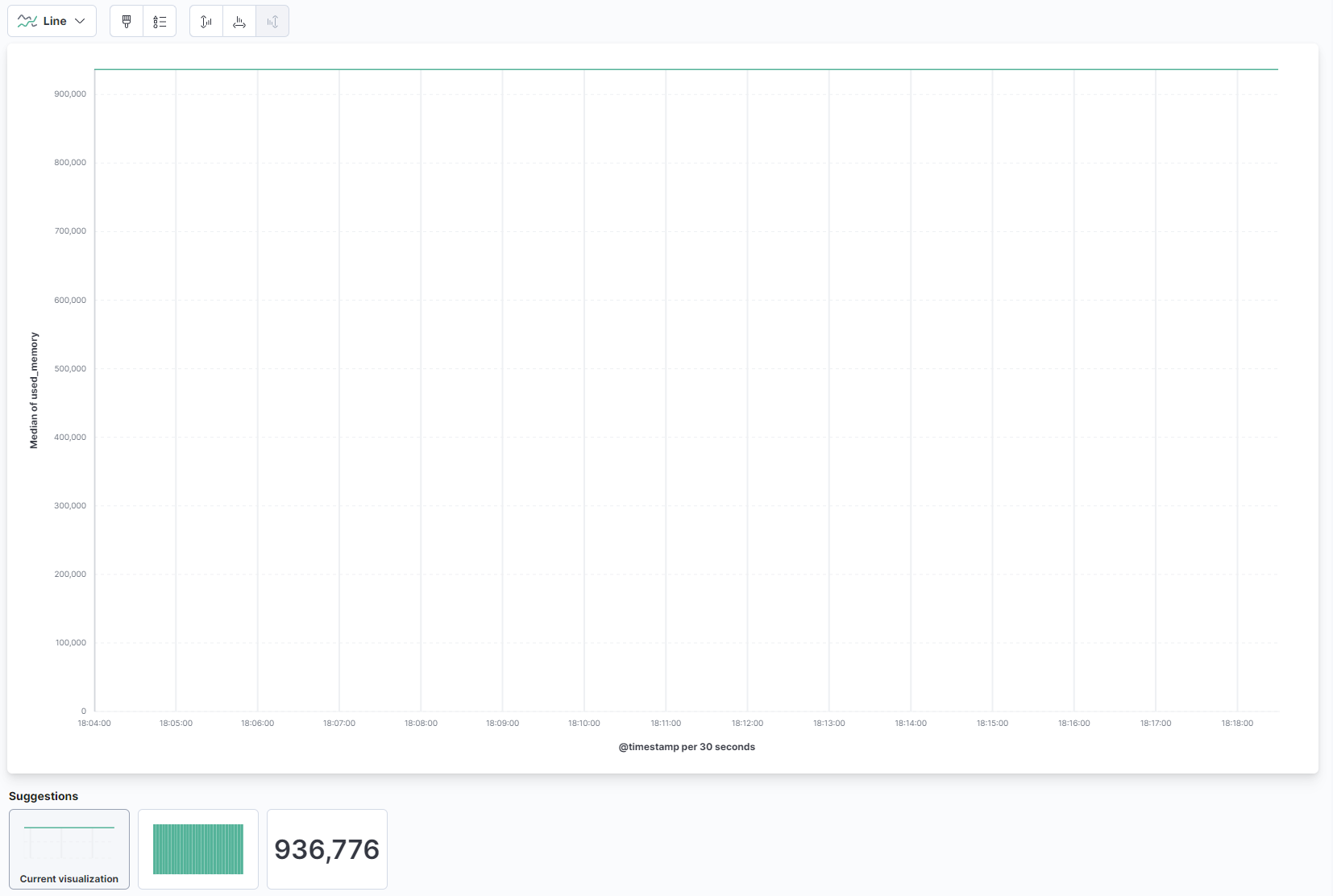
페이지의 주요 부분에서 드롭다운에서 선을 선택하고 선 및 영역 섹션에서 used_memory 필드를 왼쪽 목록에서 찾아 중앙 부분으로 끌어다 놓으세요. 곧 사용된 메모리의 중앙값에 대한 선 시각화를 볼 수 있습니다:
오른쪽에는 수평 및 수직 축이 처리되는 방식을 구성할 수 있습니다. 거기에서 표시된 축을 눌러 수직 축을 중앙값 대신 평균값으로 표시할 수 있습니다:
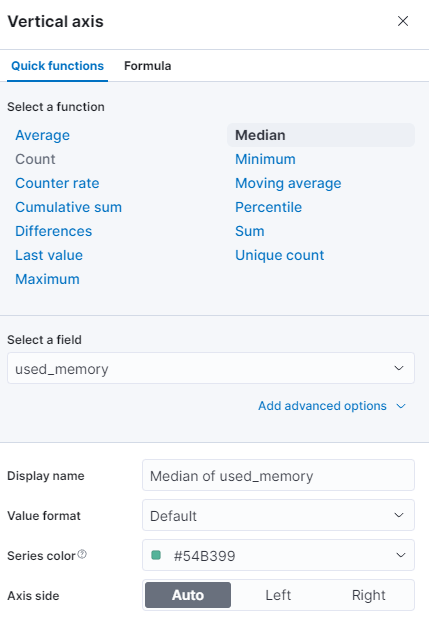
다른 함수를 선택하거나 자체 값을 제공할 수 있습니다:
그래프는 즉시 업데이트된 값으로 새로 고침됩니다.
이 단계에서는 Kibana를 사용하여 관리되는 Redis 데이터베이스의 메모리 사용량을 시각화했습니다. 이를 통해 데이터베이스가 어떻게 사용되고 있는지에 대한 더 나은 이해를 얻을 수 있으며, 이는 클라이언트 응용 프로그램 및 데이터베이스 자체를 최적화하는 데 도움이 될 것입니다.
결론
이제 Elastic 스택이 서버에 설치되어 관리되는 Redis 데이터베이스에서 주기적으로 통계 데이터를 가져오도록 구성되었습니다. 이제 Kibana 또는 다른 적합한 소프트웨어를 사용하여 데이터를 분석하고 시각화할 수 있으며, 이를 통해 데이터베이스의 성능에 대한 중요한 통찰력과 실제 세계의 상관 관계를 수집할 수 있습니다.
Redis 관리 데이터베이스로 수행할 수 있는 작업에 대한 자세한 내용은 제품 문서를 참조하십시오. 데이터베이스 통계를 다른 시각화 유형을 사용하여 표시하려는 경우 Kibana 문서에서 추가 지침을 확인하십시오.