













수학과 기술계산을 위한 Linux 학습은 기술산업界에서 가장 가치 있는 기술之一입니다. 이를 이용하면 더 빠르고 효율적으로 일을 처리할 수 있습니다. 세계에서 강력한 서버와 슈퍼컴퓨터의 많은 부분은 Linux를 운영합니다.
현재의 역할에서 더 강력해지기 위해 Linux를 배우는 것은 DevOps, 사이버 보안, 클라우드 컴퓨팅과 같은 다른 기술 경력으로의 전환도 도울 수 있습니다.
이 핸드북에서는 Linux 명령 줄의 기본을 배우고, 셸 스크립팅과 시스템 관리 같은 더 고급한 주제로 이어집니다. Linux에 처음이든 기존 사용자든 이 책에는 여러분을 위한 것이 있습니다.
중요 참고: 이 책의 모든 예제는 Ubuntu 22.04.2 LTS (Jammy Jellyfish)에서 보여집니다. 대부분의 명령 줄 도구는 다른 배포판에서 크게 다르지 않습니다. 그러나 다른 Linux 배포판에서 작업할 때 GUI 응용 프로그램과 명령이 다를 수 있습니다.
목차
第1部分: 리눅스 소개
1.1. 리눅스 시작하기
Linux는 무엇인가?
Linux는 Unix 운영체 기반의 개방 소스 오픈 시스템입니다. 1991년에 Linus Torvalds로부터 만들어졌습니다.
오픈 소스는 운영 체제의 소스 코드를 대중에게 공개하는 것을 의미합니다. 이를 통해 누구나 원래의 코드를 수정하고 커스터마이즈할 수 있으며, 새로운 운영 체제를 потенциаль 사용자에게 배포할 수 있습니다.
리눅스를 배울 이유는 무엇입니까?
현재 데이터 센터의 레이아웃에서 리눅스와 마이크로소프트 윈도우가 주요 경쟁자로 떠오르며, 리눅스가 주요 기여를 하는 실정입니다.
리눅스를 배울 몇 가지 강력한 이유입니다:
-
리눅스 호스팅의 흔히 나타나는 경향을 고려할 때, 응용 프로그램이 리눅스에서 호스팅되는 가능성이 높습니다. 따라서 개발자로서 리눅스를 배우는 것이 점점 더 가치 있어집니다.
-
클라우드 컴퓨팅이常态化되면서, 클라우드 인스턴스가 리눅스를 의존할 가능성이 높아집니다.
-
리눅스는 인터넷 오브 사물(IoT)와 모바일 응용 프로그램을 위한 많은 운영 체제의 기반을 이룹니다.
-
IT에서는 리눅스에 능한 사람들에게 많은 기회가 있습니다.
리눅스가 오픈 소스 운영 체제라는 것은 무엇을 의미합니까?
먼저, 오픈 소스란 무엇인가? 오픈 소스 소프트웨어는 그것의 소스 코드를 자유롭게 접근할 수 있도록 하는 소프트웨어로, 누구나 활용하고 수정하며 배포할 수 있습니다.
소스 코드가 생성될 때마다, 자동적으로 저작권이 부여되며, 그 배포는 소프트웨어 라이센스를 통해 저작권자에 의해 관리됩니다.
오픈 소스와는 반대로, 프라이빗리티 또는 클로즈드 소스 소프트웨어는 소스 코드에 대한 접근을 제한합니다. 오직 창작자만이 그것을 조회하고, 수정하고, 배포할 수 있습니다.
리눅스는 주로 오픈 소스이며, 이는 그의 소스 코드가 자유롭게 이용 가능함을 의미합니다. 누구나 조회하고, 수정하며, 배포할 수 있습니다. 전 세계의 개발자들이 그것의 개선에 기여할 수 있습니다. 이는 오픈 소스 소프트웨어의 중요한 측면인 협업의 기반을 마련합니다.
이 협업적 접근은 리눅스가 서버, 데스크톱, 삽입형 시스템, 모바일 기기에 널리 채택되는 데에 기여하였습니다.
리눅스가 오픈 소스이며 가장 흥미로운 점은 프라이빗리티의 제약을 받지 않고 누구나 운영 체제를 자신의 특정 필요에 맞춰 꾸며낼 수 있다는 것입니다.
크롬북에서 사용되는 크롬 OS는 리눅스를 기반으로 합니다. 전 세계에 많이 사용되는 스마트폰의 드라이버인 안드로이드도 리눅스를 기반으로 합니다.
리눅스 커널이란 무엇인가?
커널은 운영 체제의 중심적인 구성 요소로서, 컴퓨터와 그 하드웨어 연산을 관리합니다. 그것은 메모리 연산과 CPU 시간을 처리합니다.
커널은 응용 프로그램과 하드웨어 수준의 데이터 처리 사이를 통신하고 시스템 호출을 통해 브릿지 역할을 합니다.
커널은 운영 체제가 시작할 때 먼저 메모리에 로드되어 시스템이 종료될 때까지 남아 있습니다. 디스크 관리, 작업 관리, 메모리 관리와 같은 任务를 담당합니다.
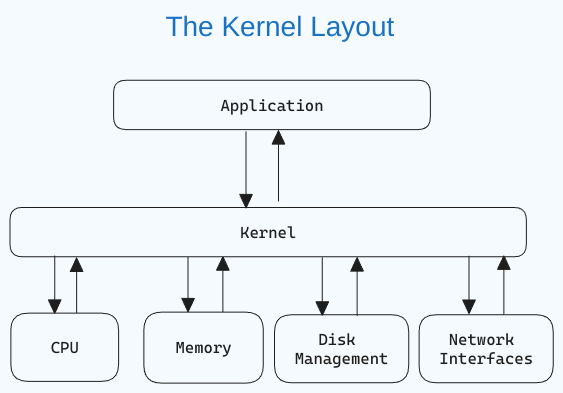
리눅스 커널이 어떤 모습인지 궁금하다면, 여기에 GitHub 링크가 있습니다.
리눅스 배포판이 무엇인가요?
이제 여러분은 리눅스 커널 코드를 재사용하고, 수정하여 새로운 커널을 만들 수 있다는 것을 알고 있습니다. 또한 다양한 유틸리티와 소프트웨어를 결합하여 완전히 새로운 운영 체제를 만들 수 있습니다.
리눅스 배포판이나 디스트로는 리눅스 커널, 시스템 유틸리티, 그 밖의 소프트웨어를 포함하는 리눅스 운영 체제의 버전입니다. 오픈 소스이므로, 리눅스 배포판은 여러 독립적인 오픈 소스 개발 커뮤니티가 협력하여 만든 것입니다.
배포판이 ‘파생’되었다는 것은 무엇을 의미합니까? 배포판이 다른 배포판에서 “파생”된다고 말할 때, 새로운 디스트로는 원래 디스트로의 기반이나 베이스를 사용하여 만들어집니다. 이러한 파생은 같은 패키지 관리 시스템(이를 나중에 자세히 설명합니다), 커널 버전, 때때로 같은 구성 도구를 사용하는 것을 포함할 수 있습니다.
오늘날, 목표와 배포판에서 지원하는 소프트웨어를 선택하는 기준에 따라 다양한 리눅스 배포판이 수천 개가 있으며, 선택할 수 있습니다.
배포판은 서로 다르지만 일반적으로 몇 가지 공통적인 특성을 가지고 있습니다:
-
배포판은 리눅스 커널로 구성돼 있습니다.
-
이것은 사용자 공간 프로그램을 지원합니다.
-
분布은 작고 單独적용의 것이나 数千의 오픈 소스 프로그램을 포함하는 것이 있습니다.
-
분布과 그 组요(components)을 설치하고 갱신하는 수단을 제공해야 합니다.
“리눅스 분布 Timeline“를 보시면, Slackware와 Debian이 두 대표적인 분布이며, 그 기반에서 여러 분布이 派生되었음을 볼 수 있습니다. 예를 들어, Ubuntu와 Kali는 Debian에서 派生되었습니다.
派生의 장점은 무엇입니까? 派生에 대한 장점은 다양합니다. 派生한 분布은 親 분布의 안정性, 보안, 대량의 소프트웨어 저장소를 이용할 수 있습니다.
기존 기반을 이용해 다양한 기능을 specialized features를 가진 새로운 분布을 개발할 수 있습니다. 派生한 분布의 사용자는 親 분布에 이미 존재하는 문서, 공동체 지원, 자원을 이용할 수 있습니다.
일부 인기 있는 리눅스 분布은 다음과 같습니다:
-
Ubuntu: 가장 널리 사용되고 인기 있는 리눅스 배포판 중 하나입니다. 사용자 친화적이며 BEGINNERS에게 추천되고 있습니다. Ubuntu에 대해 더 많은 정보를 aquí에서 배워보세요.
-
Linux Mint: Ubuntu를 기반으로 하며, Linux Mint는 미디어 지원을 중심으로 사용자 친화적인 경험을 제공합니다. Linux Mint에 대해 더 많은 정보를 aquí에서 배워보세요.
-
Arch Linux: 경험 가진 사용자들 사이에서 인기가 있으며, Arch는 가벼운 的重量为特色的 유동적인 배포판으로, 하나의 DIY 방법을 사용자로 하는 사용자들을 대상으로 되었습니다. Arch Linux에 대해 더 많은 정보를 aquí에서 배워보세요.
-
Manjaro: Arch Linux에 기반한 Manjaro는 미리 설치 된 소프트웨어와 간단한 시스템 관리 도구로 사용자 친화적인 경험을 제공합니다. Manjaro에 대해 자세히 알아보세요.
-
Kali Linux: Kali Linux는 보안 도구의 comprehensive suite를 제공하고 대부분이 cybersecurity와 hacking에 초점을 맞춥니다. Kali Linux에 대해 자세히 알아보세요.
Linux을 설치하고 접근하는 方法
가장 좋은 이해를 위해서는 지식을 적용하는 것입니다. 이 섹션에서는 您의 计算机에 Linux을 설치하는 方法을 배울 것입니다. 또한 Linux을 Windows 计算机에 접근하는 方法을 배울 것입니다.
이 섹션에 提到한 모든 方法 중 하나로 Linux에 접근할 것인지 추천합니다.
Linux을 주요 OS로 설치하기
Linux을 주요 OS로 설치하는 것은 가장 효율적인 方法입니다. 计算机에 Linux을 설치하고 있으면 이를 사용하여 과정을 따라가실 수 있습니다.
이 섹션에서는 가장 인기 있는 Linux 배포판 중 하나 인 Ubuntu를 설치하는 방법을 배우게 됩니다. 현재 다른 배포판은 제외했으며 Ubuntu에 익숙해지면 다른 배포판을 탐색할 수 있습니다.
-
단계 1 – Ubuntu iso 다운로드: 공식 웹사이트로 이동하여 iso 파일을 다운로드하십시오. “LTS”로 표시된 안정적인 릴리스를 선택해야 합니다. LTS는 장기 지원을 의미하며 일반적으로 5년 동안 무료 보안 및 유지 보수 업데이트를 받을 수 있습니다.
-
단계 2 – 부팅 가능한 USB 드라이브 만들기: 부팅 가능한 USB 드라이브를 만들 수 있는 여러 소프트웨어가 있습니다. 사용하기 쉬운 Rufus를 추천합니다. 여기에서 다운로드할 수 있습니다.
-
Step 3 – pendrive로 引导: 引导可能한 pendrive를 준비한 후, laptop에 삽입하여 pendrive로 引导합니다. 引导 메뉴는 您的 laptop에 따라 다릅니다. 您的 laptop 모델의 引导 메뉴를 google하여 확인할 수 있습니다.
-
Step 4 – 지시사항 따라하기. 引导 과정이 시작되면,
ubuntu를 시험하거나 설치하기를 선택합니다.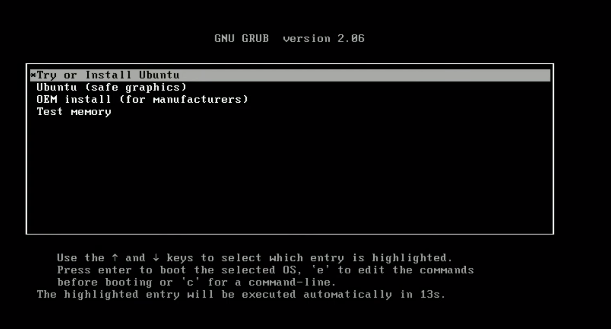
이 과정은 一些시간이 소요 됩니다. GUI가 나타나면, 언어와 キーボード 布위로 선택하고 계속하십시오. 로그인 정보와 이름을 입력하십시오. 시스템에 로그인하고 전용 권한을 사용하기 위해 凭据을 기억하십시오. 설치를 완료 하기 기다렸습니다.
-
Step 5 – 재引导: 지금 재引导하고 pendrive를 제거하십시오.
-
第六步 – 로그인: 이전에 입력한 인증 정보로 로그인하세요.
그러면 여러분은 어디에서 시작하세요? 이제 어플리케이션을 설치하고 데스크톱을 사용자 정의할 수 있습니다.

고급 설치를 위해서는 다음 주제를 探求生成的 수 있습니다:
-
디스크 분할.
-
ihibernation을 사용하기 위한 스왑 메모리 설정.
终端로 연결하기
이 수다의 중요한 부분은 터미널에 대한 이해입니다. 여러분은 모든 명령어를 실행하고 魔力が 일어나는 장소로 이곳에 와봅니다. “Windows” 키를 depressed 하고 “terminal”을 입력하여 终端을 search 할 수 있습니다. Terminal을 轻松하게 사용할 수 있는 도크에 값을 찍을 수 있습니다.
💡 Terminal을 여는 快捷方式는
ctrl+alt+t
Terminal을 폴더 안에서도 여는 것이 가능합니다. 你现在的地方에서 right click하여 “Open in Terminal”를 클릭하면 같은 경로에서 终端을 여는 것입니다.
Windows 计算机上运行 Linux 的方法
Linux와 Windows을 사이에서 같이 실행해야 할 때가 있을 수 있습니다. 幸运的是, 다른 computers를 얻을 필요가 없다는 것을 味噌 차에 들어가고 두 개의 운영 시스템을 얻을 수 있습니다.
이 sectioin에서는 Windows 计算机에서 Linux을 사용하는 几种方式을 探求生成的 수 있습니다. 그들 중 browser-based 또는 cloud-based가 있으며 이를 사용하기 전에 운영 시스템 설치가 필요하지 않습니다.
옵션 1: “이중 부팅” Linux + Windows 이중 부팅을 사용하면 Windows와 함께 컴퓨터에 Linux을 설치할 수 있으며, 시작할 때 어느 운영 체제를 사용할지 선택할 수 있습니다.
이를 위해 하드 드라이브를 파티션 하고 Linux을 별도의 파티션에 설치해야 합니다. 이 접근 방식으로는 한 번에 하나의 운영 체제만 사용할 수 있습니다.
옵션 2: Windows Subsystem for Linux (WSL) 사용 Windows Subsystem for Linux는 Windows에서 Linux 바이너리 실행 파일을 직접 실행할 수 있는 호환성 레이어를 제공합니다.
WSL를 사용하는 것에는 몇 가지 이점이 있습니다. WSL 설정은 간단하고 시간이 오래 걸리지 않습니다. 호스트 기계에서 자원을 할당해야 하는 가상 머신보다는 가벼워요. Linux 기계용 ISO나 가상 디스크 이미지를 설치할 필요가 없으며, 이 파일들은 보통 크고 무거울 편입니다. Windows와 Linux을 나란히 사용할 수 있습니다.
WSL2 설치 방법
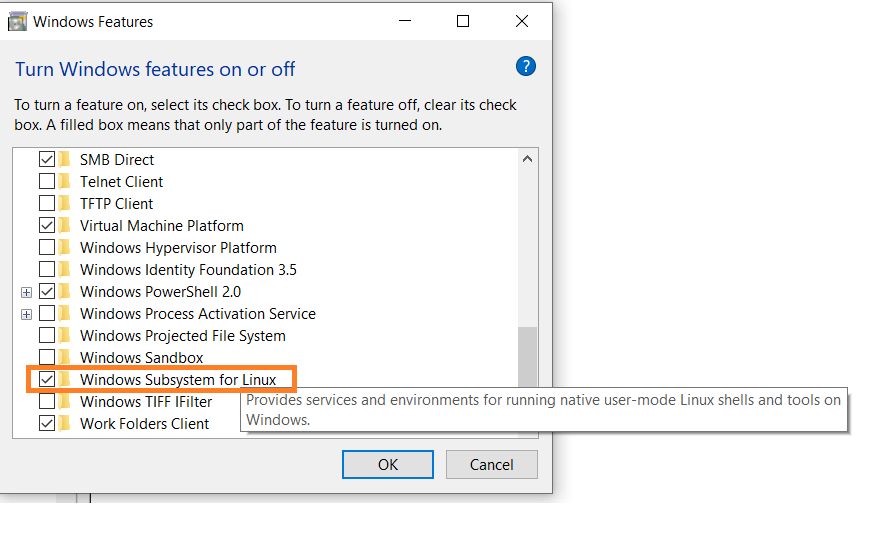
처음으로, 설정에서 Windows Subsystem for Linux 옵션을 활성화합니다.
-
시작 메뉴로 가서 “Windows 기능 켜기 또는 끄기”를 검색합니다.
-
아직 체크되어 있지 않은 경우 “Windows Subsystem for Linux” 옵션을 선택합니다.
-
다음으로, 명령 프롬프트를 열고 설치 명령을 제공합니다.
-
관리자 권한으로 명령 프롬프트 열기:

-
아래 명령을 실행하세요:
wsl --install
다음은 출력입니다:
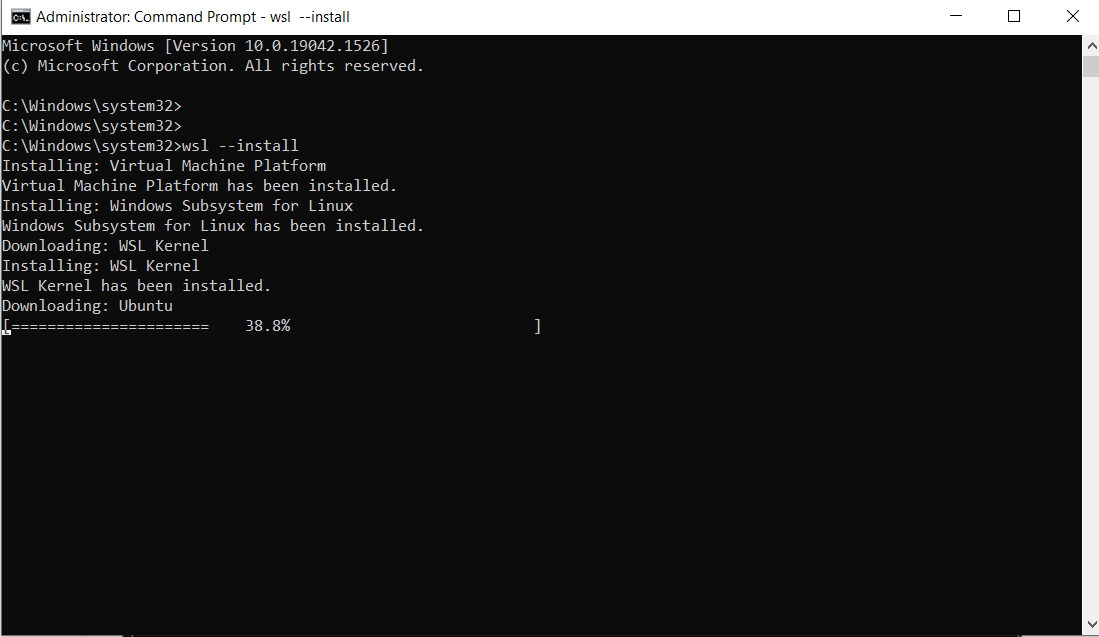
참고: 기본적으로 Ubuntu가 설치됩니다.
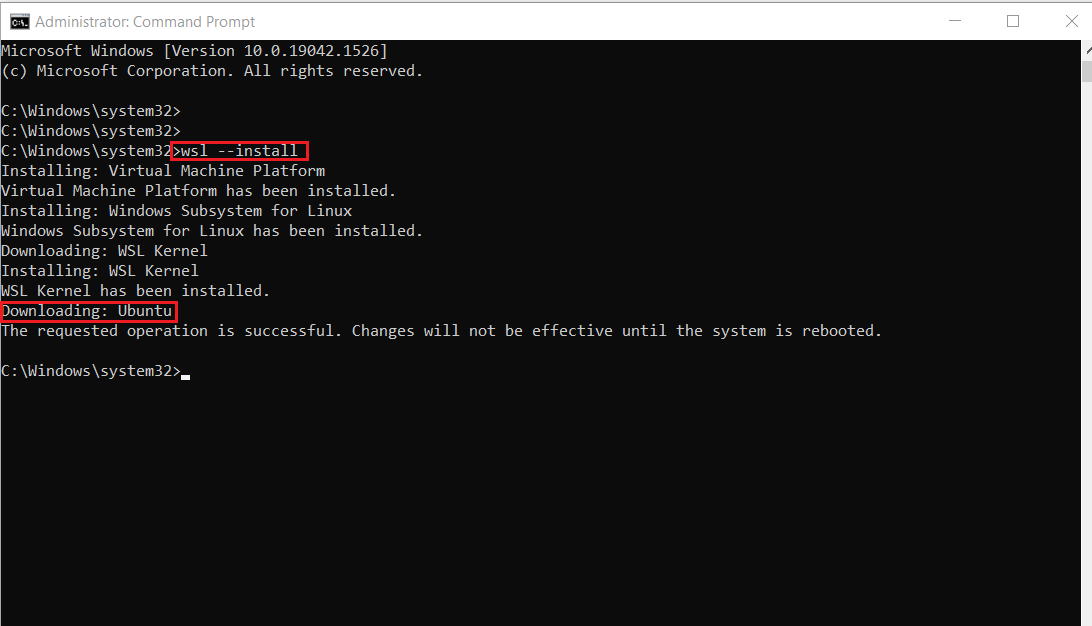
- 설치가 완료되면 Windows 컴퓨터를 다시 시작해야 합니다. 그래서 Windows 컴퓨터를 다시 시작하세요.
다시 시작한 후에는 다음과 같은 창이 나타날 수 있습니다:
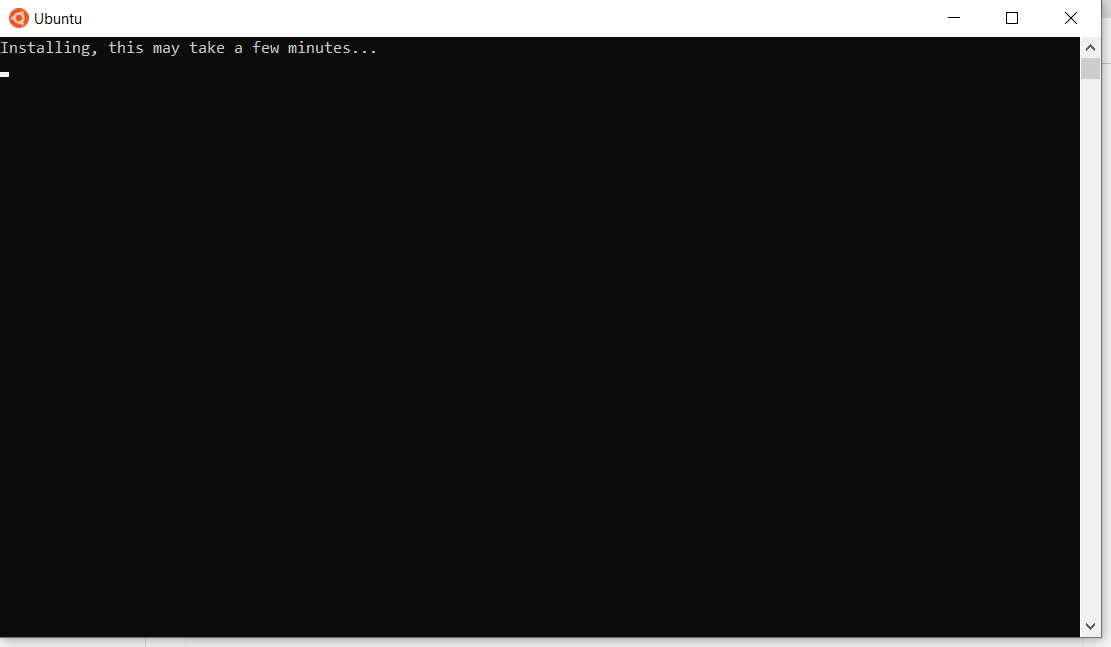
Ubuntu 설치가 완료되면 사용자 이름과 비밀번호를 입력하라는 메시지가 표시됩니다.

그리고, 준비가 완료되었습니다! 이제 Ubuntu를 사용할 준비가 되었습니다.
Ubuntu를 시작 메뉴에서 검색하여 실행할 수 있습니다.
그리고 이제 Ubuntu 인스턴스가 실행되었습니다.

옵션 3: 가상 머신(VM) 사용
가상 머신(VM)은 물리적 컴퓨터 시스템의 소프트웨어 에뮬레이션입니다. 이를 통해 단일 물리적 컴퓨터에서 여러 운영 체제와 응용 프로그램을 동시에 실행할 수 있습니다.
Oracle VirtualBox 또는 VMware와 같은 가상화 소프트웨어를 사용하여 Windows 환경에서 Linux를 실행하는 가상 머신을 만들 수 있습니다. 이를 통해 Linux를 Windows와 함께 게스트 운영 체제로 실행할 수 있습니다.
VM 소프트웨어는 각 VM에 대한 하드웨어 자원을 할당하고 관리하는 옵션을 제공합니다. 이를 CPU コア, 메모리, 디스크 공간, 네트워크 帯宽 등이 포함됩니다. 이러한 할당을 ゲスト オペレーティング 시스템과 应用程序의 요구에 따라 조정할 수 있습니다.
다음은 virtualization에 대한 일반적인 옵션 중 一些이에요:
Option 4: 브라우저 기반 솔루션 사용
브라우저 기반 솔루션은 素早く 테스트하거나 배우거나 Linux 환경에 素早く 접근하는 데 특히 유용합니다.
온라인 コード Editore나 웹 기반 端末을 사용하여 Linux에 접근할 수 있습니다. 이러한 情况下에서는 일반적으로 전체 관리 권한을 갖추지 않습니다.
온라인 코드 에디터
온라인 코드 에디터는 내장된 리눅스 탭strip을 제공합니다. 그 주요 목적은 코딩입니다만, 리눅스 탩strip을 이용하여 명령어를 실행하고 일을 하실 수 있습니다.
리플리텀은 온라인 코드 에디터의 예시입니다. 여기서는 코드를 쓸 수 있으며 동시에 리눅스 시hell을 사용할 수 있습니다.
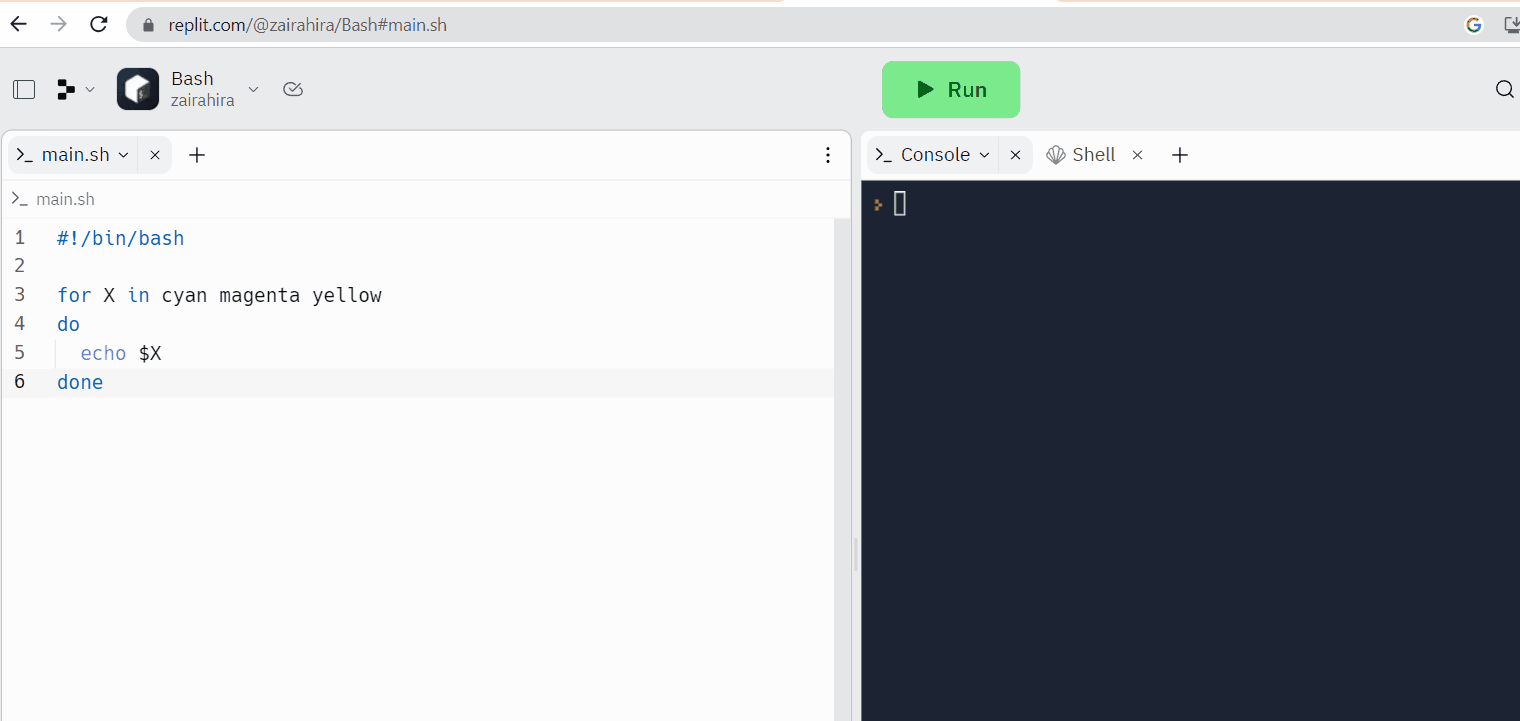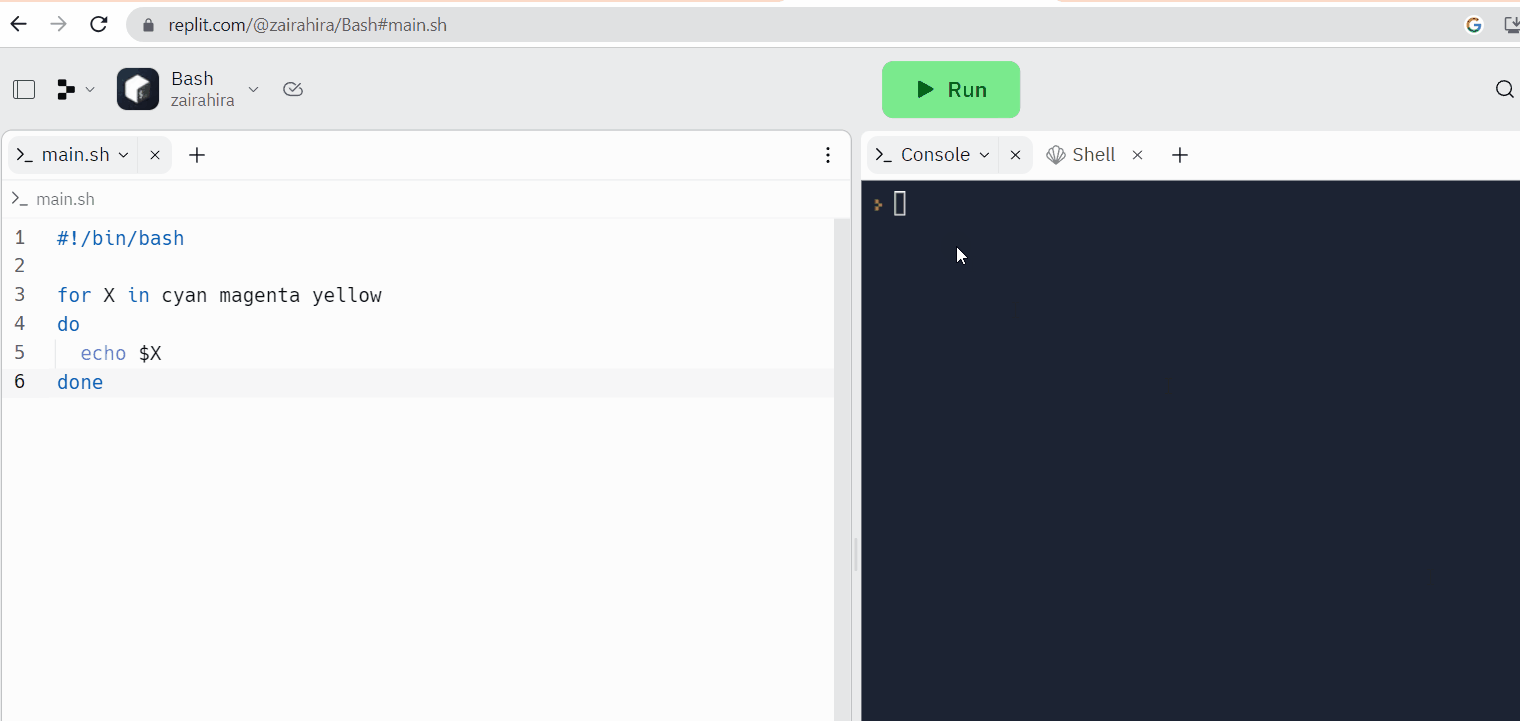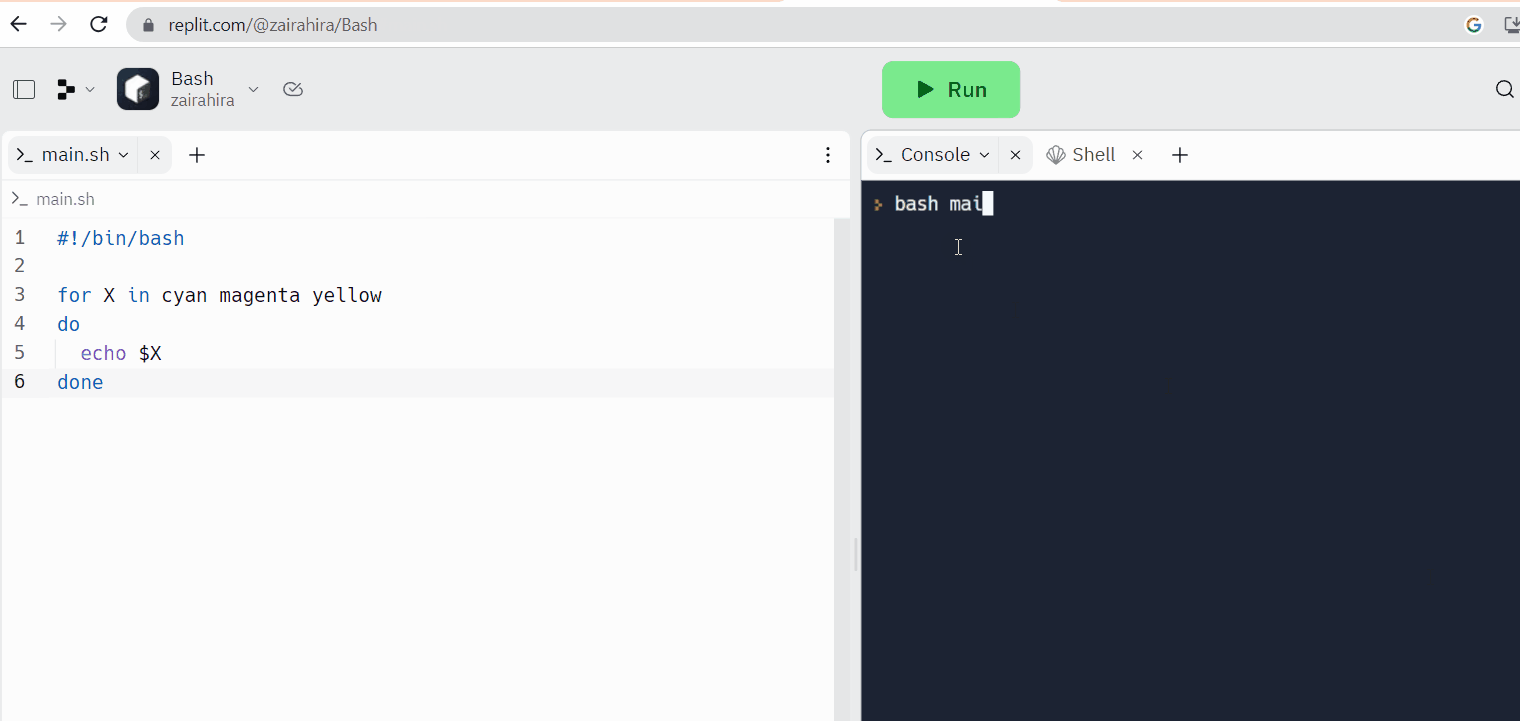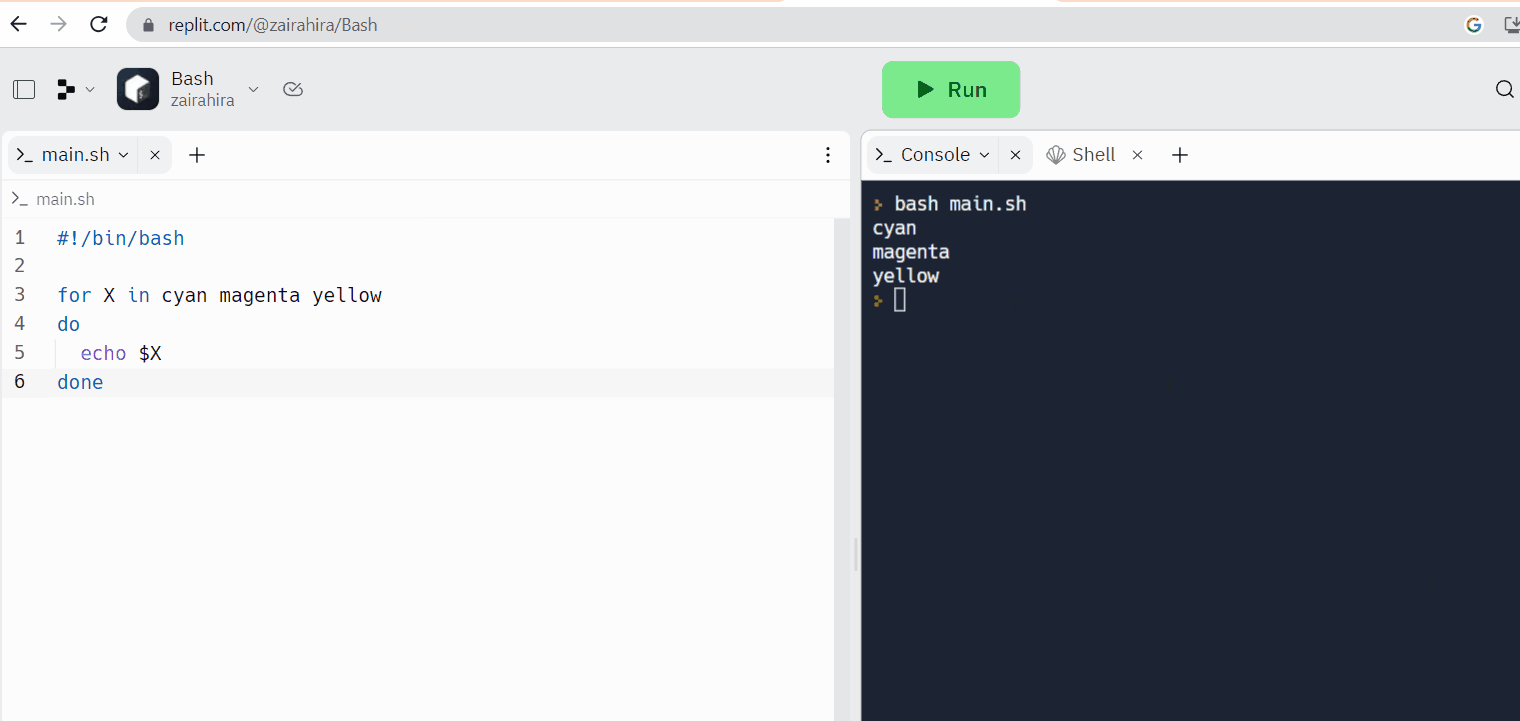
웹 기반 리눅스 탩strip:
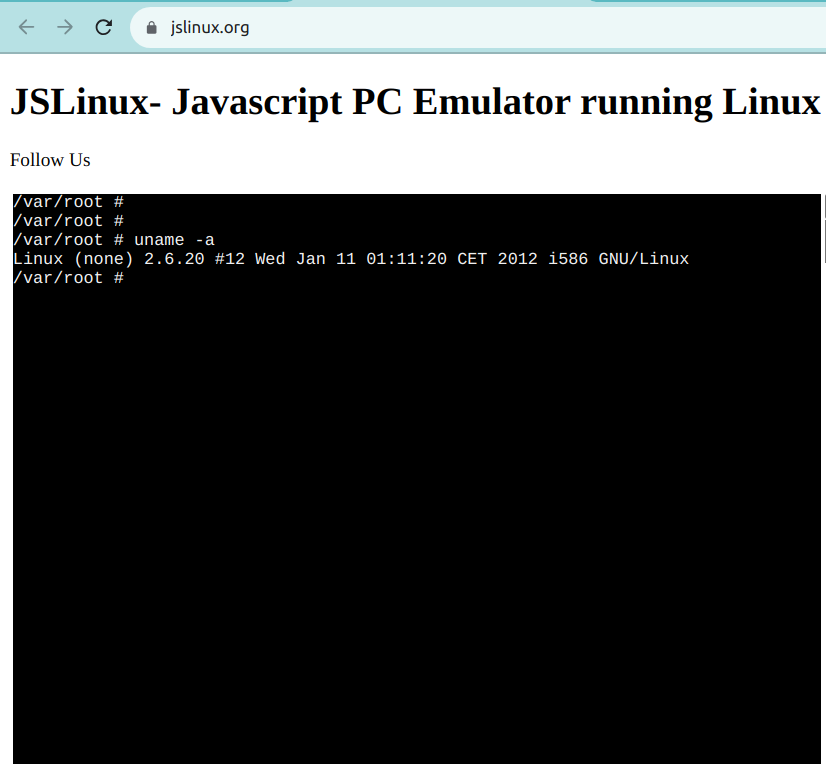
온라인 리눅스 탩strip은 您的浏览器에서 직접 리눅스 명령어 인터페이스를 ACCESS하는 것을 허용합니다. 이러한 탩strip은 리눅스 shell에 대한 웹 기반 인터페이스를 제공하며, 명령어를 실행하고 Linux 유틸리티를 일으키는 작업을 할 수 있습니다.
이러한 것 중 하나로 JSLinux이 있습니다. 아래 그림은 사용하기 좋은 Linux 환경을 보여줍니다:
옵션 5: 클라우드 기반 솔루션 사용
Windows 머신에 리눅스를 직접 실행하지 않고, 클라우드 기반 리눅스 환경 또는 가상 privaten server (VPS)를 사용하여 리눅스를 远程 접속하고 일하는 것을 고려할 수 있습니다.
Amazon EC2, Microsoft Azure, DigitalOcean 등의 서비스는 Linux 인스턴스를 제공하고 있습니다. 이러한 서비스는 일부가 무료 层层이지만, 오래 기다리다보니 무료가 아닙니다.
第2部分: Bash Shell과 시스템 명령어에 대한 introduction
2.1. Bash shell에 대한 시작
Bash shell에 대한 introduction
리눅스 명령행은 셸이라는 프로그램에서 제공되는 것입니다. 연희에 따라 셸 프로그램은 다양한 옵션을 위해 발전하였습니다.
다른 사용자는 서로 다른 셸을 사용하도록 구성할 수 있습니다. 그러나, 대부분의 사용자는 현재 기본 셸을 계속 사용하는 것을 선호합니다. 많은 리눅스 배포판의 기본 셸은 GNU Bourne-Again Shell(bash)입니다. Bash는 Bourne 셸(sh)를 계승하고 있습니다.
현재 사용 중인 셸을 확인하려면 터미널을 열고 다음 명령을 입력합니다:
echo $SHELL
명령 분석:
-
echo명령은 터미널에 출력하는 데 사용됩니다. -
$SHELL는 현재 셸의 이름을 저장하는 특수 변수입니다.
내 설정에서 출력은 /bin/bash입니다. 이는 bash 셸을 사용하고 있다는 의미입니다.
# 출력
echo $SHELL
/bin/bash
Bash는 GUI(그래픽 사용자 인터페이스)로 효율적으로 수행하기 어려운 일부 연산을 간단화할 수 있어서 매우 강력합니다. 대부분의 서버에 GUI가 없으며 명령행 인터페이스(CLI)의 기능을 배우는 것이 最佳입니다.
터미널 vs 셸
“터미널”과 “셸”이라는 용어는 종종 서로 공존하게 사용되지만, 명령행 인터페이스의 다른 부분을 가리킵니다.
终端은 시hell에 대한 인터랙션을 위해 사용하는 인터페이스입니다. Shell은 사용자의 명령을 처리하고 실행하는 명령어 인터preter입니다. manuel의 6부에서 더 많은 정보를 배울 수 있습니다.
What is a prompt?
Shell이 interactively를 사용하면, 사용자의 명령을 기다리는 동안 $를 보여줍니다. 이것이 shell prompt이라고 합니다.
[username@host ~]$
shell이 root로 실행되고 있을 때(root 사용자에 대해 나중에 배울 수 있습니다), 이 기호가 #로 변경됩니다.
[root@host ~]#
2.2. Command Structure
A command is a program that performs a specific operation. Once you have access to the shell, you can enter any command after the $ sign and see the output on the terminal.
Generally, Linux commands follow this syntax:
command [options] [arguments]
Here is the breakdown of the above syntax:
-
command: This is the name of the command you want to execute.ls(list),cp(copy), andrm(remove) are common Linux commands. -
[옵션]
: 옵션은 대보劳累(-) 또는 더블 대보劳累(–)로 이전되는 일반적인 장치입니다. 이 옵션은 명령어의 동작을 수정할 수 있으며, 명령어의 동작을 어떻게 바꿀 것인가 결정할 수 있습니다. 예를 들어
ls -a는 현재 디렉터리의 荫蔽 파일을 보여주기 위해-a옵션을 사용합니다. [인자]: 인자는 명령어에서 사용할 수 있는 인자를 의미합니다. 이 인자는 파일 이름, 사용자 이름 또는 명령어가 행동할 데이터로 사용할 수 있습니다. 예를 들어cat access.log명령어에서cat은 명령어이고access.log은 입력입니다. 따라서cat명령어는access.log파일의 내용을 보여줍니다.
모든 명령어에 옵션과 인자가 필요하지 않습니다. 某些 명령어는 옵션과 인자 없이 실행할 수 있으며, 다른 명령어는 정확하게 하나 이상의 옵션과 인자를 사용하여 제대로 기능할 수 있습니다. 항상 명령어의 manuel을 참조하여 지원하는 옵션과 인자를 확인할 수 있습니다.
💡팁: man 명령어를 사용하여 명령어의 manuel을 볼 수 있습니다.
ls 명령어의 manuel 페이지를 man ls로 이용하여 다음과 같이 보실 수 있습니다:

manuel 페이지는 文档을 더 effiiciently 접근하는 좋은 방법입니다. 자주 사용하는 명령어에 대한 man 페이지를 浏览하는것을 강추하며 추천해드립니다.
2.3. Bash 명령어와 键盘 단축키
终端에 있는 것을 사용하여 작업을 더 빨라줍니다.
다음은 一些 일반적인 终端 단축키입니다:
| 작업 | 단축키 |
| 이전 명령어를 찾기 | ↑ |
| 이전 単어의 시작处로 이동하기 | Ctrl+← |
| 커서에서 끝까지 글자를 지우기 | Ctrl+K |
| 명령어, 파일 이름, 옵션을 완성하기 | Tab 키를 눌러보세요 |
| 명령어 行의 시작处로 이동하기 | Ctrl+A |
| 이전 명령어 목록을 표시하기 | history |
2.4. 자신을 识別하는 것: whoami 명령어
whoami 명령어를 사용하여 로그인 하고 있는 사용자 이름을 얻을 수 있습니다. 다른 사용자로 切り替え고 현재 사용자를 확인하고자 하는 경우 유용합니다.
$ 기호 직후에 whoami를 입력하고 enter 를 눌러주세요.
whoami
이렇게 나타나는 것입니다.
zaira@zaira-ThinkPad:~$ whoami
zaira
3부: 리눅스 시스템 이해
3.1. Operating System 및 SPECS 발견
uname 명령어를 사용하여 시스템 정보 인쇄
uname 명령어를 사용하여 자세한 시스템 정보를 얻을 수 있습니다.
-a 옵션을 제공하면 모든 시스템 정보를 인쇄합니다.
uname -a
# output
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
上方의 출력에서,
-
Linux: 운영 시스템을 나타냅니다. -
zaira: 머신의 호스트 이름을 나타냅니다. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2: kernel 버전, 빌드 날짜 및 추가적인 정보에 대한 정보를 제공합니다. -
x86_64 x86_64 x86_64: 시스템의 아키텍처를 나타냅니다. -
GNU/Linux: 운영 시스템 유형을 나타냅니다.
CPU 아키텍처 자세한 정보를 lscpu 명령을 사용하여 찾기
리눅스의 lscpu 명령은 CPU 아키텍처에 대한 정보를 표시하는 데 사용됩니다. 터미널에서 lscpu를 실행하면 다음과 같은 자세한 정보를 제공합니다:
-
CPU의 아키텍처(예: x86_64)
-
CPU op-mode(s)(예: 32-bit, 64-bit)
-
Byte Order(예: Little Endian)
-
CPU(s)(CPU 개수) 등
해봅시다:
lscpu
# 출력
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
많은 정보가 있었지만, 유용하게도! 관련 정보를 특정 플래그를 사용하여 빠르게 볼 수 있습니다. man lscpu로 명령 매뉴얼을 보세요.
파트 4: 명령행에서 파일 관리
4.1. 리눅스 파일 시스템 계층
리눅스의 모든 파일은 파일 시스템에 저장됩니다. 루트가 가장 상단에 있어 역수의 나무 구조를 따릅니다.
/는 루트 디렉토리이자 파일 시스템의 시작점입니다. 루트 디렉토리에는 시스템의 모든 다른 디렉토리와 파일이 포함되어 있습니다. / 문자는 경로 이름 사이의 디렉토리 구분자 역할을 합니다. 예를 들어, /home/alice는 완전한 경로를 형성합니다.
아래 그림은 compete file system hierarchy를 보여줍니다. 각 디렉터리는 특정 목적을 서비스합니다.
이것은 모두 포함된 목록이 아니며, 다양한 배포에서는 다양한 구성을 가질 수 있습니다.
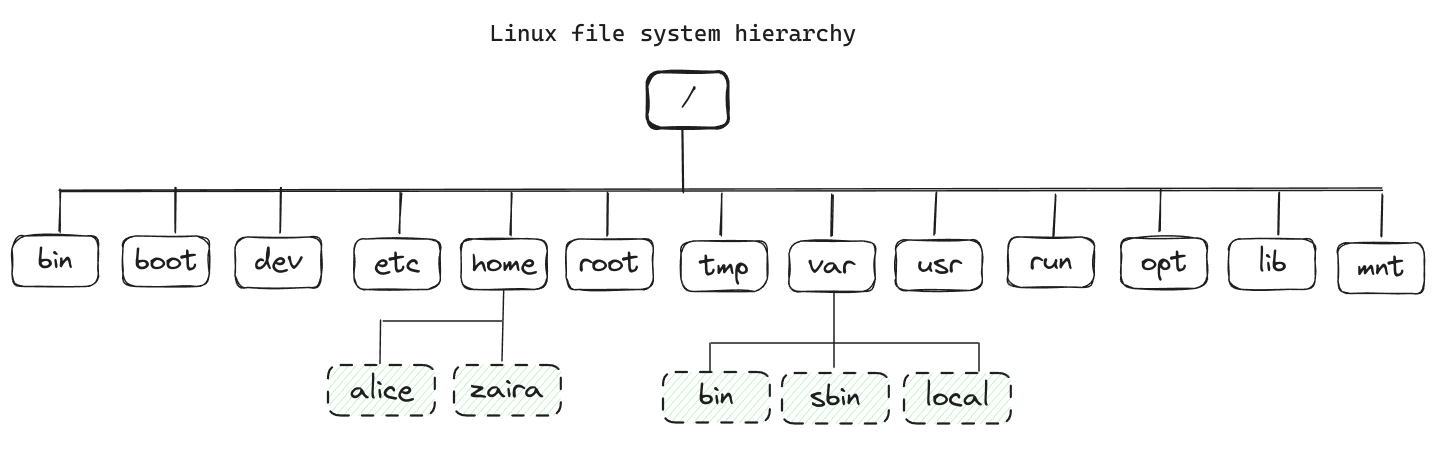
다음은 각 디렉터리의 목적을 보여주는 표입니다.
| 위치 | 목적 |
| /bin | 필수 명령어 이미지 |
| /boot | 引导加载器的 정적 파일, 引导 과정을 시작하는 데 필요합니다. |
| /etc | 호스트 Specific system configuration |
| /home | 사용자 家庭 디렉터리 |
| /root | 관리자 루트 사용자의 家庭 디렉터리 |
| /lib | 필수 Shared libraries 및 内核模块 |
| /mnt | 文件系统를 임시적으로 마ount 할 수 있는 마운트 지점 |
| /opt | Additional application software packages |
| /usr | 설치된 소프트웨어 및 Shared libraries |
| /var | 引导 사이에 유지되는 변수 데이터 |
| /tmp | 모두 사용자가 사용할 수 있는 임시 파일 |
💡 Tip: man hier 명령어를 사용하여 file system에 대한 더 많은 정보를 배울 수 있습니다.
tree -d -L 1 명령어를 사용하여 文件系统을 확인할 수 있습니다. -L 플래그를 수정하여 树의 깊이를 변경할 수 있습니다.
tree -d -L 1
# output
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
이 목록은 완전하지 않으며, 서로 다른 배포판과 시스템은 다르게 구성되어 있을 수 있습니다.
4.2. 리눅스 파일 시스템 탐색
절대 경로 vs 상대 경로
절대 경로는 루트 디렉토리에서 파일이나 디렉토리까지의 전체 경로입니다. 항상 /로 시작합니다. 예를 들어, /home/john/documents입니다.
상대 경로는 현재 디렉토리에서 목적지 파일이나 디렉토리까지의 경로입니다. /로 시작하지 않습니다. 예를 들어, documents/work/project입니다.
현재 디렉토리를 pwd 명령을 사용하여 확인
명령행에 익숙치 않으면 리눅스 파일 시스템에서 길을 잃을 수 있습니다. pwd 명령을 사용하여 현재 디렉토리를 확인할 수 있습니다.
예제입니다:
pwd
# 출력
/home/zaira/scripts/python/free-mem.py
cd 명령을 사용하여 디렉토리 변경
디렉토리를 변경하는 명령은 cd입니다. “change directory”의 약어입니다. cd 명령을 사용하여 다른 디렉토리로 이동할 수 있습니다.
상대 경로나 절대 경로를 사용할 수 있습니다.
예를 들어, 다음과 같은 파일 구조에서 (적은 선을 따라 이동):red lines):
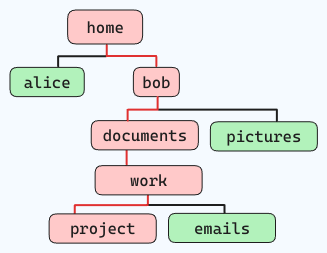
“home” 위치에서 명령은 다음과 같습니다:
cd home/bob/documents/work/project
다른 일반적으로 사용되는 cd 단축어는 다음과 같습니다:
| 명령 | 설명 |
cd .. |
이전 디렉터리로 가기 |
cd ../.. |
두 개의 디렉터리 zurück gehen |
cd or cd ~ |
홈 디렉터리로 가기 |
cd - |
이전 경로로 가기 |
4.3. 파일과 디렉터리 관리
파일과 디렉터리를 작업하는 것은 복사, 이동, 제거하고 새 파일과 디렉터리를 생성하는 것을 포함하는 것이 있을 수 있습니다. 그렇다면 아래의 명령어들을 이용하여 도와드릴 수 있습니다.
💡팁: `ls -l`의 출력을 보면 파일과 폴더를 구별할 수 있습니다. `’-‘`는 파일을 나타냅니다. `’d’`는 폴더를 나타냅니다.
`mkdir` 명령어를 사용하여 새 디렉터리 생성
`mkdir` 명령어를 사용하여 빈 디렉터리를 생성할 수 있습니다.
# 현재 폴더内 "foo"라는 빈 디렉터리 생성
mkdir foo
또한 `-p` 옵션을 사용하여 재귀적으로 디렉터리를 생성할 수 있습니다.
mkdir -p tools/index/helper-scripts
# tree 명령어의 출력
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
`touch` 명령어를 사용하여 새 파일 생성
`touch` 명령어는 빈 파일을 생성합니다. 다음과 같이 사용할 수 있습니다.
# 현재 폴더内 "file.txt"라는 빈 파일 생성
touch file.txt
multiple files in a single command. multiple file names can be chained together if you want to create
현재 폴더에 "file1.txt", "file2.txt", "file3.txt" 이라는 빈 파일을 생성한다.
touch file1.txt file2.txt file3.txt
rm과 rmdir 명령어를 사용하여 파일과 디렉터리를 제거하는 것
rm 명령어를 사용하여 파일과 비어있지 않은 디렉터리를 모두 제거할 수 있다.
| 명령어 | 설명 |
rm file.txt |
file.txt 파일을 제거한다 |
rm -r directory |
directory 디렉터리를 제거하고 그 내용도 같이 지운다 |
rm -f file.txt |
file.txt 파일을 제거하는데 confirmation 없이 한다 |
rmdir directory |
빈 디렉터리를 제거한다 |
⚠️ Note that you should use the -f flag with caution as you won’t be asked before deleting a file. Also, be careful when running rm commands in the root folder as it might result in deleting important system files.
cp 명령어를 사용하여 파일 복사
Linux에서 파일을 복사하려면 cp 명령어를 사용한다.
- 파일 복사 구문
cp source_file destination_of_file
이 명령어는 file1.txt 이라는 이름의 파일을 /home/adam/logs 이라는 새로운 위치로 복사한다.
cp file1.txt /home/adam/logs
cp 명령어는 한 파일의 사본을 제공된 이름으로 복사한다.
이 명령은 file1.txt 이라는 이름의 파일을 동일 폴더内에 file2.txt 이라는 이름의 다른 파일로 복사합니다.
cp file1.txt file2.txt
mv 명령어로 파일과 폴더를 이동하고 이름을 변경하는 것
mv 명령어는 하나의 디렉터리에서 다른 디렉터리로 파일과 폴더를 이동하는 데 사용되ます.
파일을 이동하는 문법:mv source_file destination_directory
예시: file1.txt 이라는 이름의 파일을 backup 이라는 이름의 디렉터리로 이동하는 것
mv file1.txt backup/
디렉터리와 그 내용을 이동하려면
mv dir1/ backup/
리눅스에서 파일과 폴더의 이름을 변경하는 것도 mv 명령어로 수행되ます.
이름을 변경하는 문법:mv old_name new_name
예시: file1.txt 이라는 이름의 파일을 file2.txt 이라는 이름으로 변경하는 것
mv file1.txt file2.txt
dir1 이라는 이름의 디렉터리를 dir2 이라는 이름으로 변경하는 것
mv dir1 dir2
4.4. find 명령어를 사용하여 파일과 폴더를 찾는 것
find 명령어를 사용하면 파일, 폴더 및 캐릭터 设备和块设备를 効率的하게 찾을 수 있습니다.
아래는 find 명령어의 기본 사YNtax입니다.
find /path/ -type f -name file-to-search
여기서
-
/path는 파일을 찾을 것이 있는 경로로 시작되며, 이 경로는 search_from_path로 지정할 수 있습니다. 경로는/또는.로 지정할 수 있으며, 이들은 루트 디렉터리와 현재 디렉터리를 나타냅니다. -
-type는 FILE DESCRIPTORS를 나타냅니다. 아래 중 어느 것이든 가능합니다.:
f– Regular file는 텍스트 파일, 이미지, 히든 파일과 같은 일반적인 파일을 의미합니다.
d– Directory는 고려 중인 폴더입니다.
l– Symbolic link는 심볼릭 링크로 지정되며, 이러한 링크는 옵셋과 유사하게 파일을 가리키는 것입니다.
c– Character devices는 문자 장치를 사용하기 위해 만들어진 문자 장치 파일을 의미합니다. drier는 문자 장치와 문자(字节, 오ktet)를 보내고 받는 것으로 通信하며, 예를 들어 キーボード, 사운드 카드, 마우스가 있습니다.
b– Block devices는 블록 장치를 사용하기 위해 만들어진 블록 장치 파일을 의미합니다. drier는 블록 데이터를 보내고 받는 것으로 通信하며, 예를 들어 USB와 CD-ROM이 있습니다. -
-name는 search하고자 하는 파일 유형의 이름이다.
이름에 “style”를 포함하는 파일을 찾고자 한다면 이 명령어를 사용한다 :
find . -type f -name "style*"
#output
./style.css
./styles.css
이제 특정 확장자, .html 같은 것을 가진 파일을 찾고자 한다면 명령어를 이렇게 수정한다 :
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
숨은 파일을 찾는 방법
이 문서는 find 명령어에 관한 내용입니다.
이름의 시작에 句点(.)이 있는 파일은 숨김 파일입니다. 기본적으로 숨김되지만 현재 디렉터리에서 ls -a 명령어를 사용하여 볼 수 있습니다.
find . -type f -name ".*"
숨김 파일을 찾기 위해 find 명령어를 다음과 같이 수정할 수 있습니다.
ls -la
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
./.bash_logout
./.bashrc
./.bash_history
私의 홈 디렉터리内의 숨김 파일의 목록을 보여줍니다.
로그 파일과 설정 파일을 찾는 방법
find . -type f -name "*.log"
로그 파일은 일반적으로 .log 확장자를 가지고 있으며 다음과 같方式로 찾을 수 있습니다.
find . -type f -name "*.conf"
同样地,我们可以使用以下方式查找配置文件。
다른 형식의 파일을 어떻게 찾는지
find / -type c
-type에 c를 제공하여 문자 ブロック 파일을 찾을 수 있습니다.
find / -type b
同样地,通过使用b来查找设备块文件。
디렉터리를 어떻게 찾는지
ls -l
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
.
./webp
./images
./style
./hosts
어떻게 指定大小的文件를 찾는지
find 명령어의 incrediby 유용한 사용 사례로 특정 크기의 파일을 기반으로 목록을 생성할 수 있습니다.
find / -size +250M
이곳에서는 250MB를 초과하는 크기의 파일을 列挙합니다.
다른 単位는 다음과 같습니다.
-
G: 吉字节(GigaBytes).
-
M: 麦咖字节(MegaBytes). -
K: 凯咖字节(KiloBytes) -
c: 字节(bytes).
이 요소를 적절한 unite로 대체하면 된다.
find <directory> -type f -size +N<Unit Type>
수정 시간을 이용해 파일 조회하는 方法
`-mtime` 옵션을 사용하면 수정 시간을 기준으로 파일과 폴더를 필터링할 수 있습니다.
find /path -name "*.txt" -mtime -10
-
-mtime +10 옵션은 10일 전에 수정된 파일을 찾는 것을 의미합니다.
-
-mtime -10 옵션은 10일 이하로 수정된 파일을 찾는 것을 의미합니다.
-
-mtime 10 옵션은 + 또는 -를 省略하면 정확히 10일 전에 수정된 파일을 찾는 것을 의미합니다.
4.5. 파일 보기 기본 명령어
`cat` 명령어로 파일 내용 읽기 및 합치기
Linux에서 `cat` 명령어는 파일 내용을 표시하는 것뿐만 아니라, 다른 파일을 합쳐 새 파일을 생성할 수 있습니다.
`cat` 명령어의 기본 사YNXM如下:
cat [options] [file]
`cat` 명령어를 옵션과 인자가 없이 사용하면 终端에 파일 내용을 보여줍니다.
예를 들어, file.txt라는 파일의 내용을 보고 싶다면 다음 명령을 사용할 수 있습니다:
cat file.txt
이렇게 하면 터미널에서 파일의 모든 내용을 한꺼번에 표시합니다.
less 및 more를 사용하여 텍스트 파일을 대화식으로 보기
cat은 파일 전체를 한꺼번에 표시하지만, less 및 more를 사용하면 파일 내용을 대화식으로 볼 수 있습니다. 이는 큰 파일을 스크롤하거나 특정 내용을 검색할 때 유용합니다.
less 명령의 구문은 다음과 같습니다:
less [options] [file]
more 명령은 less와 비슷하지만 기능이 덜합니다. 파일 내용을 한 화면씩 표시하는 데 사용됩니다.
more 명령의 구문은 다음과 같습니다:
more [options] [file]
두 명령 모두 스페이스바를 사용하여 한 페이지 아래로 스크롤하고, Enter 키를 사용하여 한 줄씩 아래로 스크롤하며, q 키를 사용하여 뷰어를 종료할 수 있습니다.
뒤로 이동하려면 b 키를 사용하고, 앞으로 이동하려면 f 키를 사용할 수 있습니다.
tail을 사용하여 파일의 마지막 부분 표시
가끔은 전체 파일이 아니라 파일의 마지막 몇 줄만 보고 싶을 때가 있습니다. 리눅스에서 tail 명령은 파일의 마지막 부분을 표시하는 데 사용됩니다.
예를 들어, tail file.txt를 입력하면 기본적으로 파일 file.txt의 마지막 10줄을 표시합니다.
다른 행 수를 표시하려면 -n 옵션 다음에 표시하려는 행 수를 사용할 수 있습니다.
# 파일 file.txt의 마지막 50행을 표시합니다.
tail -n 50 file.txt
💡팁: tail의 또 다른 사용 방법은 follow-along(-f) 옵션입니다. 이 옵션을 사용하면 파일의 내용을 쓰여지는 대로 볼 수 있습니다. 실시간으로 로그 파일을 보고 모니터링하는 유용한 도구입니다.
head를 사용하여 파일의 시작 부분 표시
tail이 파일의 마지막 부분을 표시하는 것처럼, head 명령어를 사용하여 파일의 시작 부분을 표시할 수 있습니다.
예를 들어, head file.txt는 기본적으로 파일 file.txt의 처음 10행을 표시합니다.
표시할 행 수를 변경하려면, -n 옵션 다음에 표시하려는 행 수를 사용할 수 있습니다.
wc를 사용하여 단어, 행, 문자 세기
wc 명령어를 사용하여 파일의 단어, 행, 문자를 세어볼 수 있습니다.
예를 들어, wc syslog.log를 실행하면 다음과 같은 출력이 나옵니다:
1669 9623 64367 syslog.log
위의 출력에서,
-
1669는 파일syslog.log의 행 수를 나타냅니다. -
9623은 파일syslog.log의 단어 수를 나타냅니다. -
64367는syslog.log파일 中路의 문자 수를 나타냅니다.
따라서, wc syslog.log 명령은 syslog.log 파일中路의 1669 行, 9623 단어, 및 64367 문자를 세었습니다.
두 파일을 줄 by 줄로 비교하는 것은 diff 사용
Linux에서 두 파일을 비교하고 차이를 찾는 일은 흔하게 나옵니다. 두 파일을 명령 行에서 직접 비교할 수 있습니다.diff 명령어를 사용하세요.
diff 명령어의 기본 구문은 다음과 같습니다:
diff [options] file1 file2
이 두 파일 hello.py와 also-hello.py가 diff 명령어를 사용하여 비교될 것입니다:
# hello.py contents
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# also-hello.py contents
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- 파일이 같은지 다른지 확인하세요
diff -q hello.py also-hello.py
# Output
Files hello.py and also-hello.py differ
- 파일들이 어떻게 다르는지 보세요. 그러면
-u옵션을 사용하여 통합 출력을 볼 수 있습니다:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- above Output:
--- hello.py 2024-05-24 18:31:29.891690478 +0500는 比较되는 파일과 그의 시간 표시를 나타냅니다.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500는 다른 파일과 그의 시간을 나타냅니다.@@ -3,4 +3,5 @@는 변경이 생기는 行 番号를 보여줍니다. 이 경우, 원래 파일의 3 行에서 4 行까지가 수정 파일의 3 行에서 5 行까지로 바뀌었음을 나타냅니다.user = input(Enter your name: )는 원래 파일의 한 行입니다.print(greet(user))는 원래 파일의 다른 한 行입니다.
+print("Nice to meet you")는 수정 파일에 추가된 한 行입니다.
diff -y hello.py also-hello.py
比较이 옆에 나오는 형식으로 보기 위해서는 -y 옵션을 사용할 수 있습니다.
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Output
- In the output:
- 두 파일에서 같은 各行은 옆에 对方이 노출됩니다.
다른 各行은 > 기호로 나타내어 各行이 두 파일 중 하나에만 존재하는 것을 표시합니다.
第五部分: 리눅스에서 텍스트 편집의 기본
리눅스에서 명령어 行에서 텍스트 편집 기술은 가장 중요한 기술 이며, 이 부분에서 두 가지 인기 있는 텍스트 편집기, 비쉘(Vim)과 나노(Nano)를 사용하는 방법을 배울 것입니다.
비쉘나 나诺 중 하나의 텍스트 편집기를 선택하여 MASTER하시고 그것에 adhere to하는 것을 추천합니다. 시간을 saves 하시고 더욱 productive가 되게 합니다. 비쉘과 나诺은 대부분의 리눅스 배포판에 存在하여 안전한 선택입니다.
5.1. 비쉘 마스터링: compete Guide
비쉘 소개
- 비쉘은 명령어 行에서 인기있는 텍스트 편집기로 fame를 얻었습니다. 비쉘은 강력하고 カスタマ이able하며 빨라지는 장점을 가지고 있습니다. 다음과 같은 이유로 비쉘을 배우는 것을 考虑하시는 것을 추천합니다.:
- 대부분의 서버는 CLI를 통해 접속되므로, 시스템 관리에서 GUI를 가지는 것은 luxury가 아닙니다. 그러나 비쉘은 그들의 後盾을 뒀습니다.- 그들이 언제든지 있습니다.
- Vim은 마우스 사용이 없이 키보드 중앙 기반의 방법을 사용하며, 키보드 짧은 키 구문을 배우면 편집 任务을 значитель히 빨라itzer 할 수 있습니다. 이것은 GUI 도구보다 더 빨라집니다.
- Linux 유틸리티 중 一些, 예를 들어 cron 일정 편집, Vim과 同じ 편집 형식을 사용합니다.
Vim은 모두에게 적합하며 – 시작자 및 고급 사용자를 포함합니다. Vim은 복잡한 문자열 Search, Search를 표시하는 것을 지원하고 더 많습니다. 플러그인을 통해, Vim은 개발자와 시스템 관리자에게 확장적인 능력을 제공하며 이를 포함하고 있습니다 : コード 完了, 문법 표시, 파일 관리, 버전 관리 및 다른 것들.
Vim은 두 가지 variety exist : Vim (vim) and Vim tiny (vi). Vim tiny는 Vim의 더 작은 버전으로 Vim의 一些 features가 없습니다.
How to start using vim
vim your-file.txt
Start using Vim with this command:
your-file.txt can either be a new file or an existing file that you want to edit.
Vim NAVIGATION: 마스터 이동과 명령 모드
CLI의 早期, 키보드에 화살표 키가 없었습니다. 따라서, 이동은 사용 가능한 키 셋을 사용하여 실행되었고, hjkl가 그 중 하나였습니다.
키보드 중심으로, hjkl 키를 사용하면 텍스트 편집 작업을 대량으로 acceleratte 할 수 있습니다.
arrow 키가 완전히 제대로 작동하는 것처럼 보이지만, hjkl 키를 실험하여 이동할 수 있습니다. 某些人이 이동 방식이 효율적인 것을 발견하는 것을 기다립니다.

💡팁: hjkl 시퀀스를 기억하기 위해서는 이렇게 사용하십시오: hang back, jump down, kick up, leap forward.
Vim의 세 가지 모드
- Vim의 세 가지 운영 모드를 알아야하며, 그들 사이를 이동하는 것입니다. 각 명령 모드에서 키 입력의 동작이 다를 수 있습니다. 세 모드는 다음과 같습니다:
- 명령 모드.
- 편집 모드.
시각적 모드.
명령 모드. Vim을 시작할 때, 기본적으로 명령 모드에 land 합니다. 이 모드는 다른 모드로 이동하는 것을 허용합니다.
⚠ 다른 모드로 이동하려면 명령 모드에 있어야 합니다
편집 모드
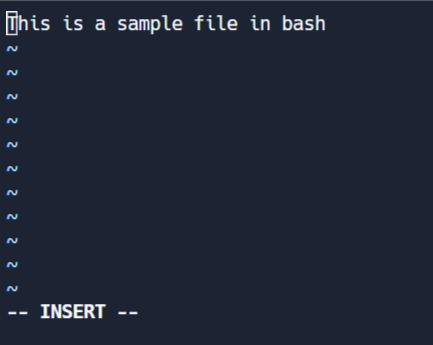
이 모드는 파일에 변경을 사용하는 것을 허용합니다. 명령 모드에서 I를 눌러 编辑 모드로 들어가십시오. 화면 하단에 '-- INSERT' 전환이 보입니다.
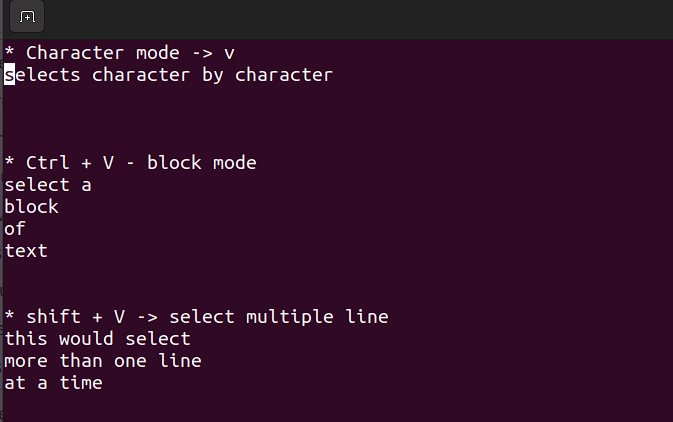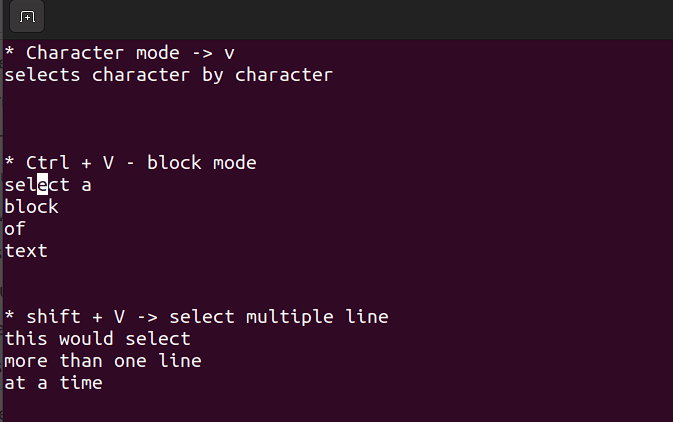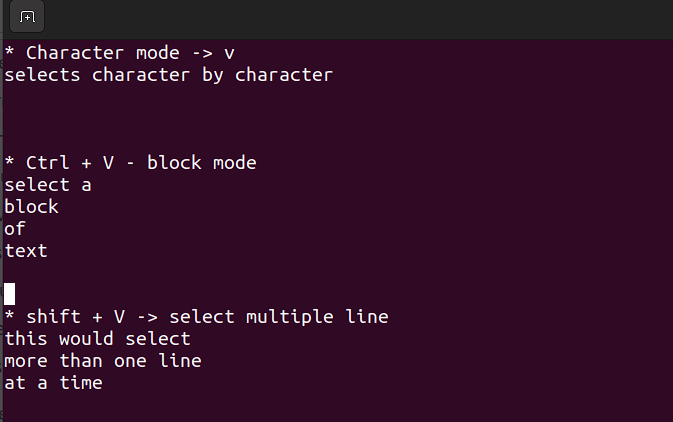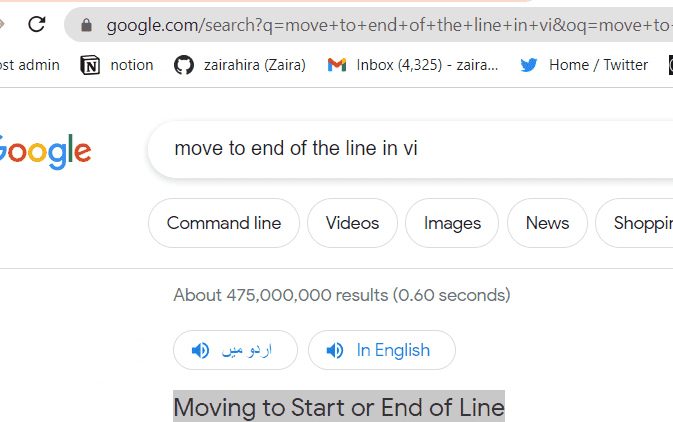
시각 모드
- 이 모드는 단일 문자, 텍스트 ブロック, 또는 텍스트 各行에 대해 작업할 수 있습니다. 간단한 단계로 해결해 봅시다. 명령 모드에서 아래 조합을 사용하는 것을 기억하십시오.
Shift + V→ 多条线路 선택.Ctrl + V→ ブロック 모드
V → 문자 모드
시각 모드는 대량의 라인을 복사하고 붙여넣기하거나 편집하기 위해 유용합니다.
확장 명령 모드.
확장 명령 모드는 Search, 라인 编号 설정, 텍스트 하이라이트 등의 advanced 操作을 수행할 수 있습니다. 다음 섹션에서 확장 모드에 대해 다룹니다.
현재 모드를 잊어버리셨다면, ESC 두 번 눌러 Command Mode로 돌아가ます.
Vim 내에서 効率的하게 편집하는 방법: 복사/붙여넣기와 Search
1. Vim에서 복사하고 붙여넣기하는 方法
- Linux 용어에서 복사/붙여넣기는 ‘yank’와 ‘put’로 知られています. 다음과 같은 단계를 따라서 복사-붙여넣기를 실행하십시오:
- 시각 모드에서 텍스트를 선택합니다.
- ‘y’ 키를 눌러 copy/yank합니다.
클래스 커서를 원하는 위치로 이동한 후 'p'를 누르세요.
2. Vim에서 텍스트 검색하는 방법
Vim의 명령 모드에서 /를 사용하여 문자열 시리즈를 검색할 수 있습니다. 검색하려면 /검색할-문자열을 입력하세요.
명령 모드에서 :set hls를 입력하고 enter를 누르세요. /검색할-문자열로 검색하여 검색 결과를 강조할 수 있습니다.
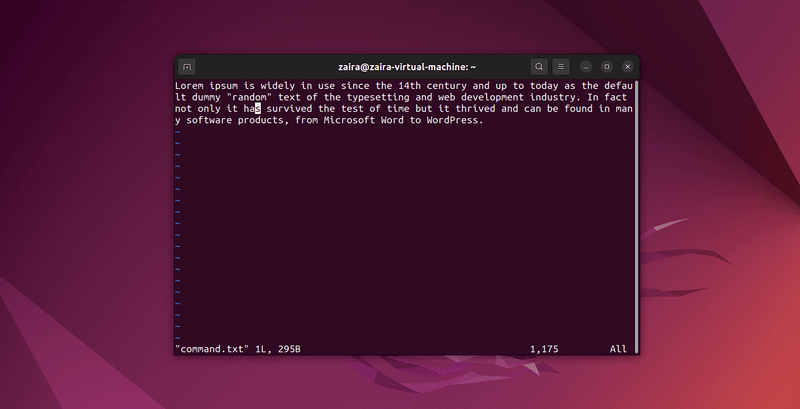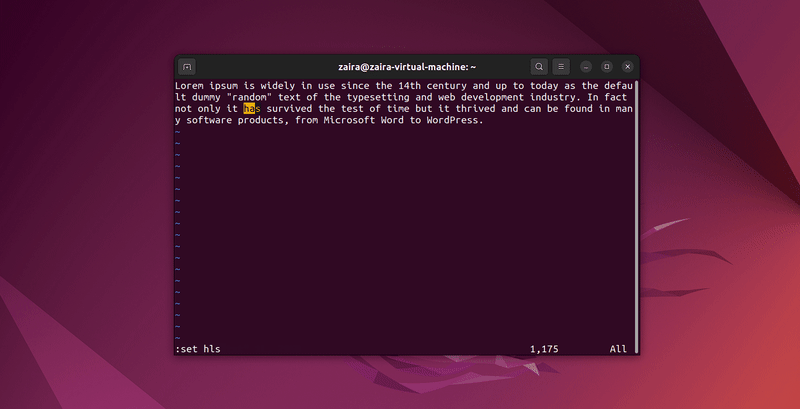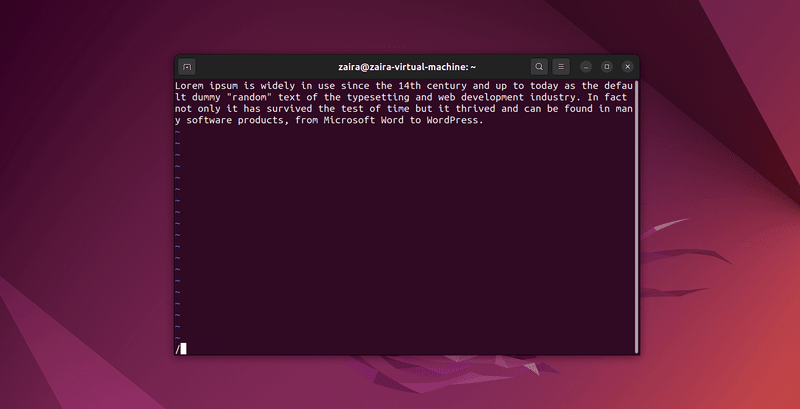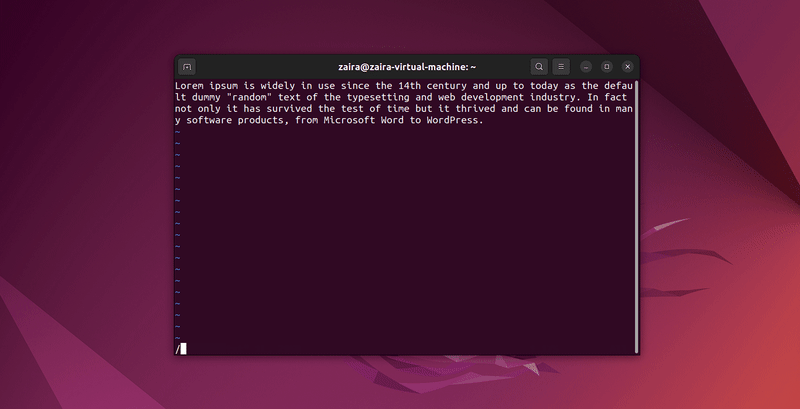
몇 가지 문자열을 검색해봅시다:
3. Vim에서 종료하는 방법
- 처음에 명령 모드로 이동합니다(ESC를 두 번 누르면 됩니다) 그리고 다음과 같은 명령을 사용하세요:
- 저장하지 않고 종료 →
:q!
저장 후 종료 → :wq!
Vim의 단축키: 편집을 더 빠르게 하기
- 참고: 모든 이러한 단축키는 명령 모드에서만 동작합니다.
Ctrl+u: 半页 위로 이동P: 커서 위로 삽입하는 것:%s/old/new/g: 파일에서old의 모든 인스턴스를new로 대체:q!: 저장하지 않고 종료
Ctrl+w 후 h/j/k/l: 분할된 창 사이를 이동
5.2. Nano 마스터링
Nano 시작하기: 사용자 친화적인 텍스트 에디터
Nano는 사용하기 쉽고 초보자에게 완벽한 사용자 친화적인 텍스트 에디터입니다. 대부분의 리눅스 배포판에 사전 설치되어 있습니다.
nano
Nano로 새 파일을 생성하려면 다음 명령을 사용하세요:
nano filename
Nano로 기존 파일을 편집하려면 다음 명령을 사용하세요:
Nano의 키 바인딩 목록
Nano에서 가장 중요한 키 바인딩을 학습하세요. 저장, 종료, 복사, 붙여넣기와 같은 다양한 작업을 수행할 때 키 바인딩을 사용할 것입니다.
파일에 쓰기 및 저장
Nano를 nano 명령어를 사용하여 실행하면 텍스트를 시작하여 기록할 수 있습니다. 파일을 저장하려면 Ctrl+O 키를 눌러 파일 이름을 입력하십시오. 입력한 후 Enter 키를 눌러 파일을 저장할 수 있습니다.
Nano 나가기
Nano를 나가려면 Ctrl+X 키를 눌러야 합니다. 저장하지 않은 변경사항이 있다면, Nano는 나가기 전에 這些 변경사항을 저장하도록 제안합니다.
복사하고 붙여넣기
region을 선택하려면 ALT+A 키를 사용하십시오. 마커가 표시됩니다. 화살표로 텍스트를 선택하십시오. 선택한 후에는 ALT+^ 키를 사용하여 마커를 나가십시오.
선택한 텍스트를 복사하려면 Ctrl+K 키를 눌러야 합니다. 복사한 텍스트를 붙여넣기하려면 Ctrl+U 키를 사용하십시오.
자르고 붙여넣기
region을 ALT+A 키를 사용하여 선택하십시오. 선택한 후, 텍스트를 Ctrl+K 키를 사용하여 자르십시오. 자른 텍스트를 붙여넣기하려면 Ctrl+U 키를 사용하십시오.
이동
Alt \ 키를 사용하여 파일의 시작位置に 이동하십시오.
Alt / 키를 사용하여 파일의 끝位置에 이동하십시오.
行号 보기
nano -l filename 명령어를 사용하여 파일을 열 때, 文件的 왼쪽에 行号가 표시됩니다.
찾기
特定한 行号의 行을 찾기 위해 ALt + G 키를 사용하십시오. 입력란에 行号를 입력하고 Enter 키를 눌러야 합니다.
You can also initiate a search for a string with CTRL + W and press Enter. If you want to search backwards, you can press Alt+W after initiating the search with Ctrl+W.
- Nano의 키바인딩 요약
Ctrl+G: 도움말 텍스트 표시Ctrl+J: 현재 문단 정렬Ctrl+V: 한 페이지 아래로 巻き込むCtrl+\: search and replace
Alt+E: 마지막으로 취소한 operation을 다시 실행합니다
부 6: Bash 스크립트 기능
6.1. Bash 스크립트 기능 정의
Bash 스크립트는 Bash 程 序을 한 줄 한 줄 실행하는 명령어 列의 파일입니다. 여러 가지 동작을 수행할 수 있습니다. 예를 들어 특정 디렉터리로 이동하고, 폴더를 만들고, 명령어 行에서 프로세스를 실행하는 것을 포함합니다.
스크립트에 명령을 저장함으로써 동일한 단계의 시퀀스를 여러 번 반복하고 해당 스크립트를 실행하여 실행할 수 있습니다.
6.2. Bash 스크립팅의 장점
Bash 스크립팅은 시스템 관리 작업을 자동화하고 시스템 자원을 관리하며 Unix/Linux 시스템에서 다른 루틴 작업을 수행하는 강력하고 다재다능한 도구입니다.
- 쉘 스크립팅의 장점은 다음과 같습니다:
- 자동화: 쉘 스크립트를 사용하면 반복적인 작업과 프로세스를 자동화하여 수동 실행으로 발생할 수 있는 오류의 위험을 줄이고 시간을 절약할 수 있습니다.
- 이식성: 쉘 스크립트는 Unix, Linux, macOS 및 심지어 에뮬레이터나 가상 머신을 통해 Windows를 포함한 다양한 플랫폼 및 운영 체제에서 실행할 수 있습니다.
- 유연성: 셸 스크립트는 고유의 기능을 가지고 있으며, 특정 요구에 따라 용이하게 수정할 수 있습니다. 또한 다른 프로그래밍 언어나 도구와 결합하여 더 강력한 스크립트를 생성할 수 있습니다.
- 이용 가능성: 셸 스크립트는 간단하게 쓰이며, 특수한 도구나 소프트웨어가 필요하지 않습니다. 텍스트 에디터로 편집할 수 있으며, 대부분의 운영 시스템에서 내장 된 셸 인터PRE터를 사용할 수 있습니다.
- 통합: 셸 스크립트는 다른 도구와 응용 프로그램과 통합할 수 있습니다. 예를 들어 데이터베이스, 웹 서버, 클라우드 서비스와 같은 도구와 응용 프로그램과 통합하여 더 복잡한 자동화 과정과 시스템 관리 任务을 수행할 수 있습니다.
에러 수 rectification: 셸 스크립트는 에러 수 rectification이 용이합니다. 대부분의 셸에서는 내장된 에러 수 rectification 및 에러 보고 도구가 있으며 문제를 快速하게 식별하고 修正할 수 있습니다.
6.3 Bash Shell과 명령 行 인터페이스 개요
애너지 셸과 BASH는 종종 서로를 교환하게 사용되지만, 두 가지 사이에는 미묘한 차이가 있습니다.
“셸”이란 운영 체제와 상호 작용하기 위한 명령줄 인터페이스를 제공하는 프로그램을 가리킵니다. BASH (Bourne-Again SHell)는 Unix/Linux 셸 중에서 가장 일반적으로 사용되는 것之一이며, 많은 Linux 배포판의 기본 셸입니다.
지금까지 입력하신 명령은 기본적으로 “셸”로 입력되었습니다.
BASH는 셸의 한 종류일 뿐만 아니라, Korn 셸 (ksh), C 셸 (csh), Z 셸 (zsh)와 같은 다른 셸들도 있습니다. 각 셸은 자신의 문법과 기능 세트를 가지고 있지만, 운영 체제와 상호 작용하기 위한 명령줄 인터페이스를 제공하는 공통된 목적을 함께 공유합니다.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
셸 유형을 ps 명령을 사용하여 파악할 수 있습니다:
요약하면, “셸”은 명령줄 인터페이스를 제공하는 프로그램을 일반적으로 가리키는 넓은 용어이며, “BASH”는 Unix/Linux 시스템에서 널리 사용되는 특정 유형의 셸입니다.
참고: 이 절에서는 “bash” 셸을 사용하게 됩니다.
6.4. BASH 스크립트 생성 및 실행 방법
스크립트 명명 규칙
명명 규칙으로 BASH 스크립트는 .sh로 끝나야 합니다. 그러나 sh 확장자 없이도 BASH 스크립트는 완벽하게 실행될 수 있습니다.
Shebang 추가
Bash 스크립트는 shebang로 시작합니다. Shebang은 bash #와 bang !의 조합으로 시작하며, bash 쉘의 경로를 따라옵니다. 이것은 스크립트의 첫 行입니다. Shebang은 쉘에게 bash 쉘을 통해 실행하라고 지시합니다. Shebang은 단지 bash 인터preter의 절대 경로입니다.
#!/bin/bash
아래는 shebang 声明의 예가 있습니다.
which bash
Shebang은 쉘에게 bash 쉘을 통해 실행하라고 지시합니다.
첫 번째 bash 스크립트 만들기
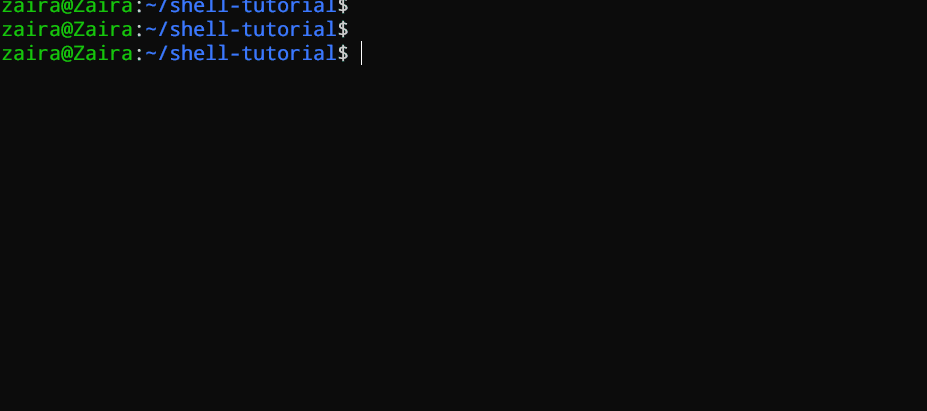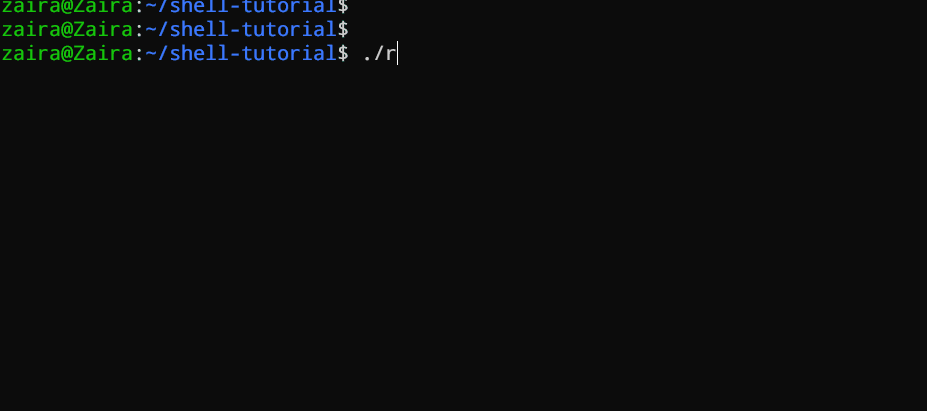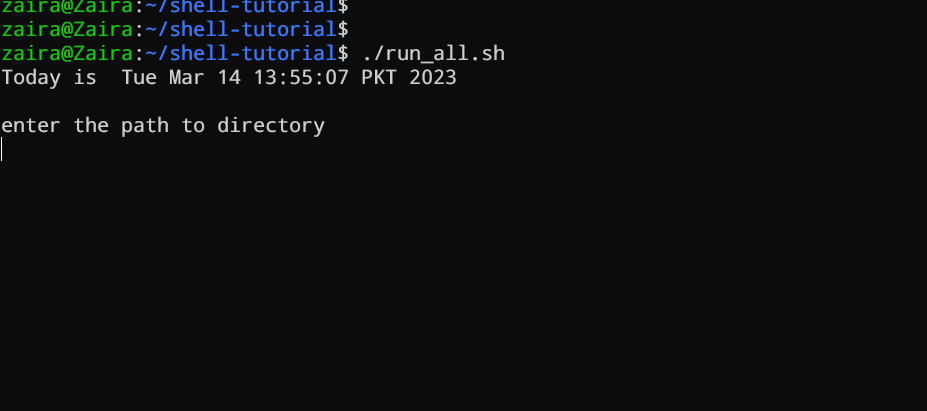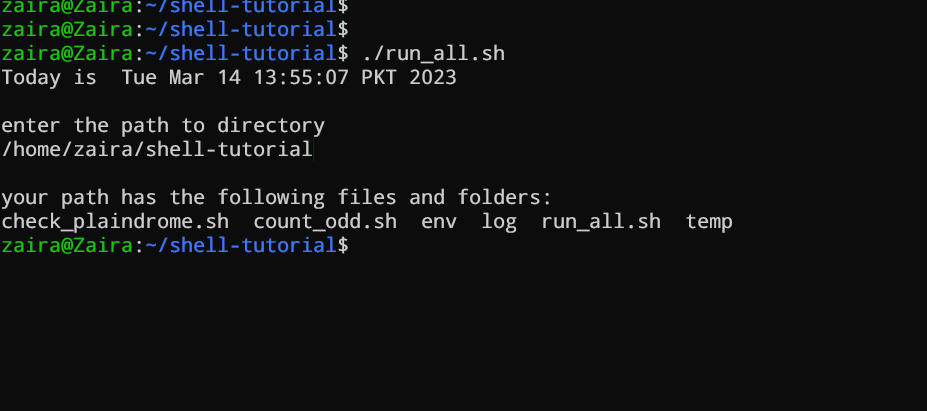
우리의 첫 번째 스크립트는 사용자에게 경로를 입력하게 합니다. 그렇게 하면, 그 내용을 列出할 것입니다.
vim run_all.sh
아무 editor를 사용하여 run_all.sh이라는 이름의 파일을 만듭니다.
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
다음과 같은 명령을 您的 파일에 추가하고 저장합니다:
1 스크립트를 한 行ごとに 깊이 있게 보겠습니다. 다시 한 번 같은 스크립트를 표시하지만, 이번에는 行 번호를 붙여넣었습니다.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- 行 #1: The shebang (
#!/bin/bash) points toward the bash shell path. - 行 #2: The
echocommand displays the current date and time on the terminal. Note that thedateis in backticks. - 行 #4: We want the user to enter a valid path.
- 라인 #5:
read명령은 입력을 읽어the_path변수에 저장합니다.
라인 #8: ls 명령은 저장된 경로를 가진 변수를 취하고 현재의 파일과 폴더를 표시합니다.
bash 스크립트 실행
chmod u+x run_all.sh
스크립트를 실행할 수 있도록 하려면, 다음 명령을 사용하여 실행 권한을 사용자에게 할당하세요:
- 여기서,
chmod은 현재 사용자의 파일의 소유권을 수정합니다:u。+x는 현재 사용자에게 실행 권한을 추가합니다. 이는 소유자인 사용자가 이제 스크립트를 실행할 수 있음을 의미합니다.
run_all.sh는 우리가 실행하려는 파일입니다.
- 다음 중 어떤 방법으로든 스크립트를 실행할 수 있습니다:
sh run_all.shbash run_all.sh
./run_all.sh
제목: 🚀 실제 동작 보기
6.5. Bash 스크립트 기본
Bash 스크립트 주석
Bash 스크립트에서 주석은 #로 시작합니다. 즉, #로 시작하는 모든 줄은 해석器에서 무시됩니다.
주석은 코드에 文档化을 도울 수 있으며, 다른 사람들이 코드를 이해하기 위해 주석을 추가하는 것은 좋은 惯例입니다.
주석의 예를 다음과 같습니다:
# 이것은 예시 주석입니다
# 이 두 行은 해석器에서 무시됩니다
Bash 中的 変数과 데이터 유형
변수를 사용하여 데이터를 저장할 수 있습니다. 스크립트 내에서 데이터를 읽고, 액세스하고, 조작할 수 있습니다.
Bash에서는 데이터 유형이 없습니다. Bash의 변수는 숫자 값, 개별 문자, 문자열 값을 저장할 수 있습니다.
- Bash에서는 다음과 같이 変수 값을 사용하고 설정할 수 있습니다:
country=Netherlands
값을 직접 할당하는 方法:
same_country=$country
2. 프로그램 또는 명령어에서 얻은 출력을 기반으로 값을 할당하는 方法으로, 명령어 대체를 사용하십시오. 이미 存在하는 変수 값을 액세스하려면 $가 필요합니다.
이것은 country 変数의 값을 새로운 変수 same_country에 할당합니다.
country=Netherlands
echo $country
変수 값을 액세스하려면 変수 이름에 $를 붙여야 합니다.
Netherlands
new_country=$country
echo $new_country
# 출력
Netherlands
# 출력
위에서 변수값의 할당과 출력의 예시를 보여줍니다.
변수명 규칙
- Bash 스크립트에서 다음과 같은 변수명 규칙을 따라야 합니다:
- 변수명은 字母(‘a’~’z’, ‘A’~’Z’)나 アンダースコア(‘_’)로 시작해야 합니다.
- 변수명은 字母, 숫자, アンダER스코어(‘_’)를 포함할 수 있습니다.
- 변수명은 대소문자를 区別합니다.
- 변수명에 공백이나 특수 문자를 포함하지 마십시오.
- 변수의 목적을 반영하는 설명적인 이름을 사용하세요.
예를 들어 if, then, else, fi 등의 예약어를 변수명으로 사용하지 마십시오.
name
count
_var
myVar
MY_VAR
Bash에서 유효한 변수명의 예시들을 다음과 같이 나타냅니다:
또한, 다음과 같은 유효하지 않은 변수명의 예시가 있습니다:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# 부적절한 変数 이름
이러한 명명 conventiooon을 따르면 Bash 스크립트의 읽기와 쓰기가 더욱 읽기 좋고 유지하기 쉽어집니다.
Bash 스크립트의 입력과 출력
입력 수집
- 이 부분에서는 스크립트에 입력을 제공하는 몇 가지 방법을 논じ我们将一起讨论。
사용자 입력을 읽고 변수에 보관
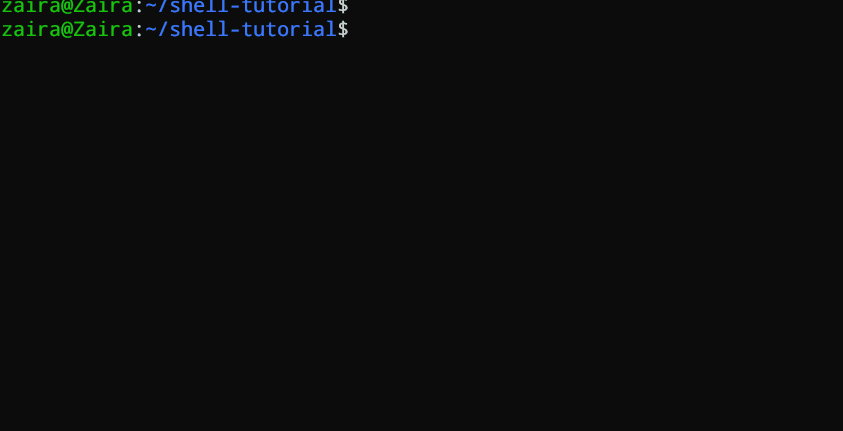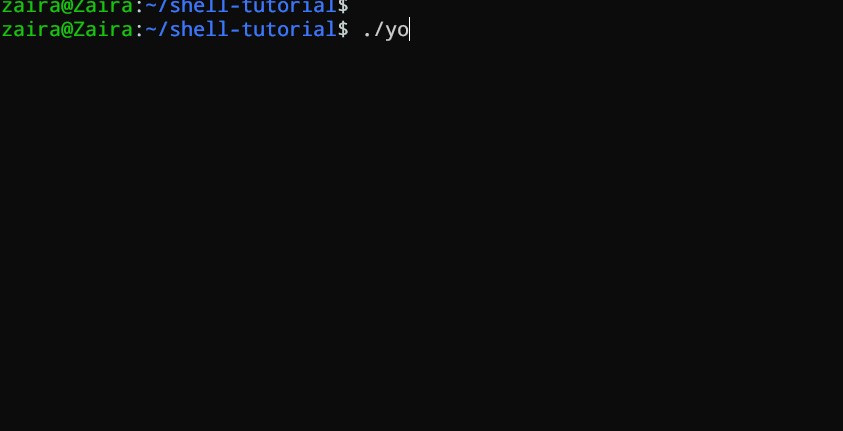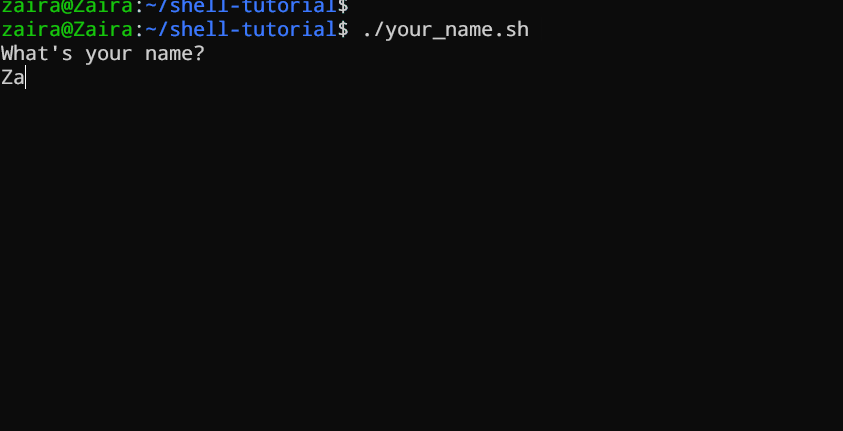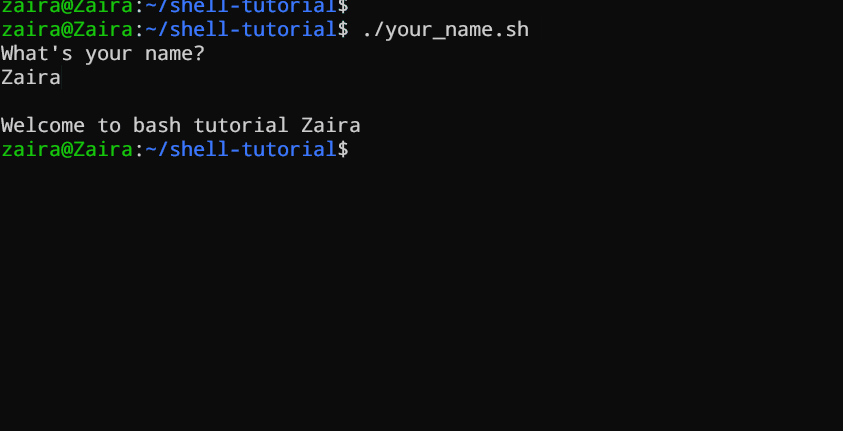
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
`read` 명령을 사용하여 사용자 입력을 읽을 수 있습니다.
2. 파일から 읽기
while read line
do
echo $line
done < input.txt
이 コード는 `input.txt` という 이름의 파일의 각 行을 읽고 终端機로 출력합니다. 이 부분에서는 나중에 while 루프를 배워보겠습니다.
3. 명령 줄 인자
Bash 스크립트나 함수에서 `$1`는 最初に渡された 인자를 나타냅니다., `$2`는 두 번째 인자를 나타냅니다., 이러한 방식으로 계속합니다.
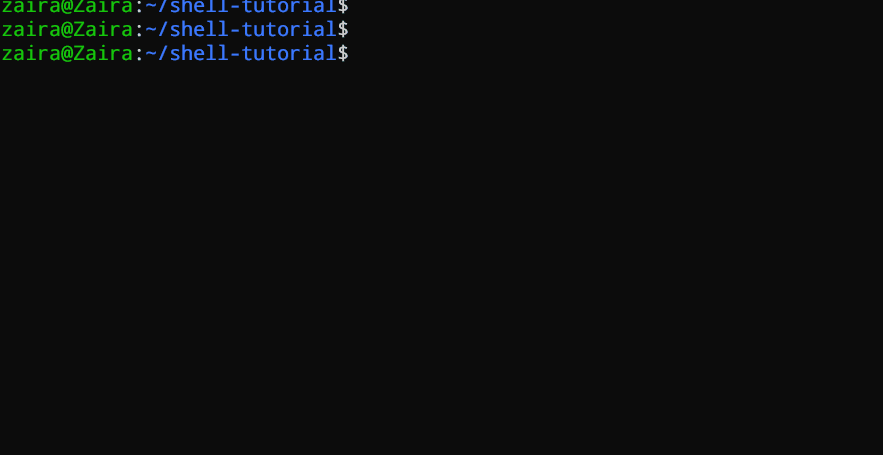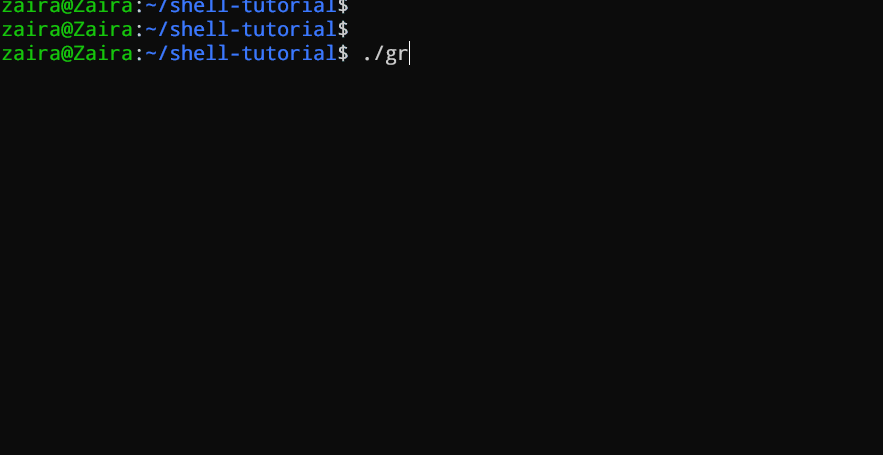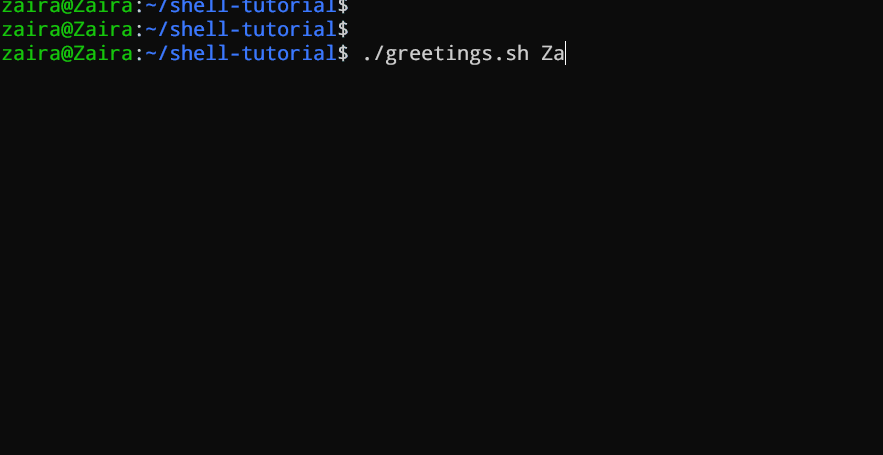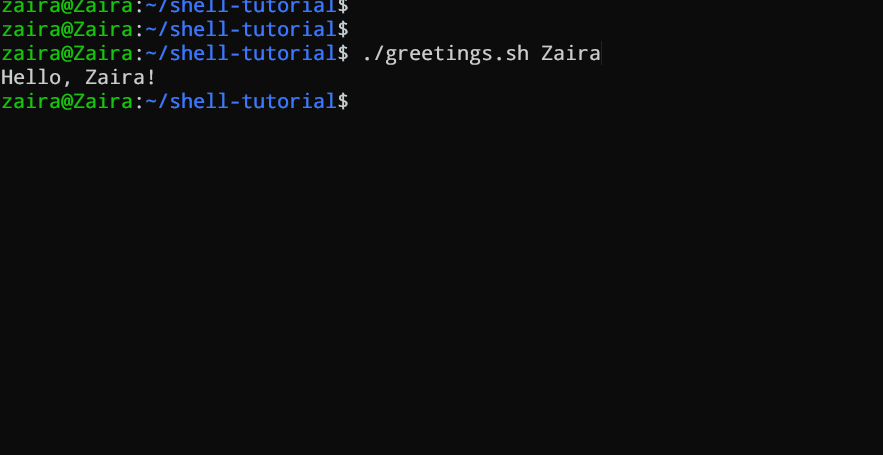
#!/bin/bash
echo "Hello, $1!"
이 스크립트는 명령 줄 인자로 이름을 받고 사용자 지정 인사를 출력합니다.
우리는 스크립트에 `Zaira`를 인자로 제공했습니다.
출력:
스크립트에서 출력 수신
- 이 부분에서는 스크립트에서 출력을 수신하는 방법을 몇 가지 이야기해봅시다.
echo "Hello, World!"
终端機로 출력하기
이 텍스트 “Hello, World!”를 终端機로 출력합니다.
echo "This is some text." > output.txt
2. 파일에 쓰기
이 텍스트 “This is some text.”를 `output.txt`という 이름의 파일에 쓰는 것을 note하십시오. 이미 一些 내용을 갖추고 있는 경우 `>` 运算子를 사용하여 파일을 overwrite합니다.
echo "More text." >> output.txt
3. 파일에 接到하기:
이 应用程序은 output.txt 파일의 末尾에 “More text.” 텍스트를 추가합니다.
ls > files.txt
4. 출력 이동:
현재 디렉터리의 파일을 列出하고 files.txt 이라는 이름의 파일에 출력을 기록합니다. 이렇게 任何 명령어의 출력을 파일에 이동할 수 있습니다.
8.5 절에서 출력 이동에 대한 자세한 내용을 배울 것입니다.
조건 陈述(if/else)
참과 거짓을 생성하는 표현式을 조건이라고 부릅니다. 조건을 평가하는 다양한 방법들이 있으며, if, if-else, if-elif-else 및 嵌套 조건이 있습니다.
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
문법:
Bash 조건 문법
if [ $a -gt 60 -a $b -lt 100 ]
논리 연산자를 사용하여 더 深い 의미의 比较을 行う 수 있습니다. AND -a와 OR -o를 사용하세요.
이 陈述은 두 조건이 모두 true인지 확인합니다: a가 60보다 큰지 AND b가 100보다 작은지 합니다.
#!/bin/bash
Bash 스크립트가 if, if-else, if-elif-else 문을 사용하여 사용자가 입력한 숫자가 긍정, 부정, 还是 零인지 deter mine 하는 예를 보겠습니다:
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# 숫자가 긍정, 부정, 还是 零인지 결정하는 스크립트
스크립트는 우선 사용자에게 숫자를 입력하도록 지시합니다. 그 후, if 문을 사용하여 숫자가 0보다 큰지를 확인합니다. 그렇다면, 스크립트는 숫자가 양수임을 출력합니다. 숫자가 0보다 큰 것이 아니면, 스크립트는 다음 문장으로 이동합니다. 그것은 if-elif 문입니다.
여기서 스크립트는 숫자가 0보다 작은지를 확인합니다. 그렇다면, 스크립트는 숫자가 음수임을 출력합니다.
마지막으로, 숫자가 0보다 크지도, 0보다 작지도 않으면, else 문을 사용하여 숫자가 제로임을 출력합니다.
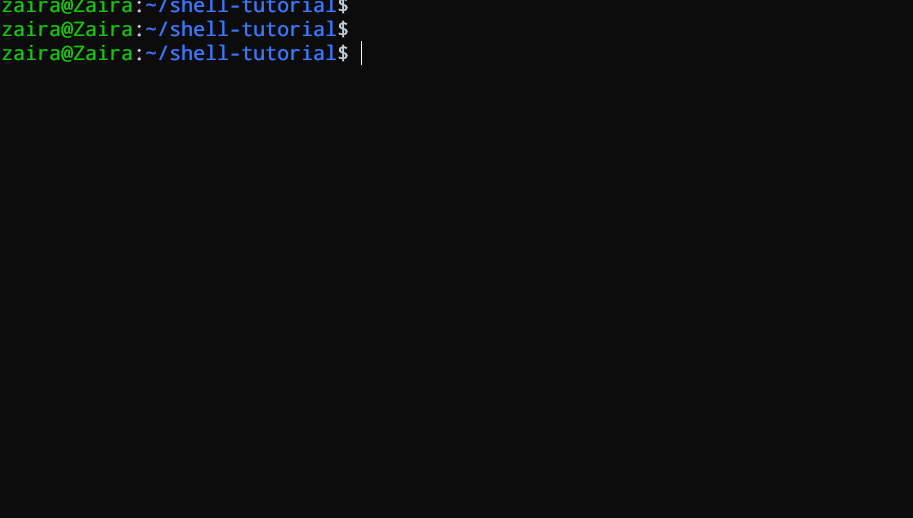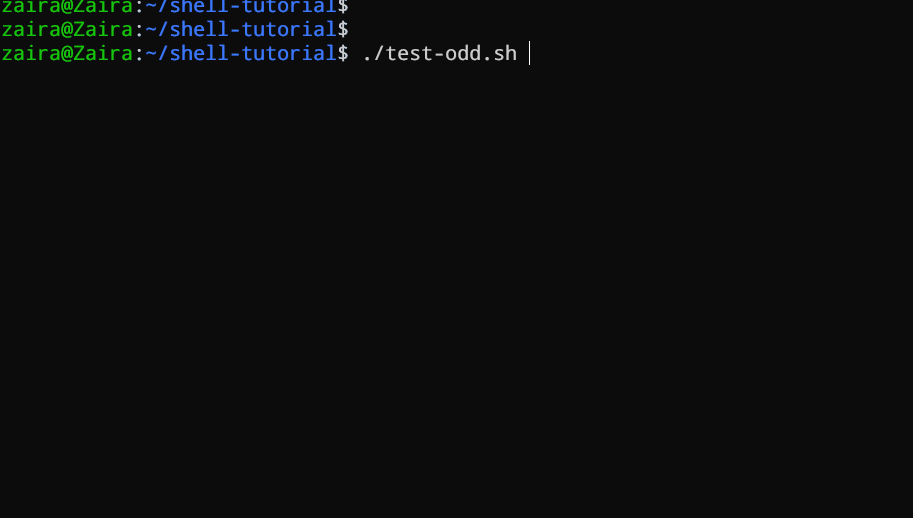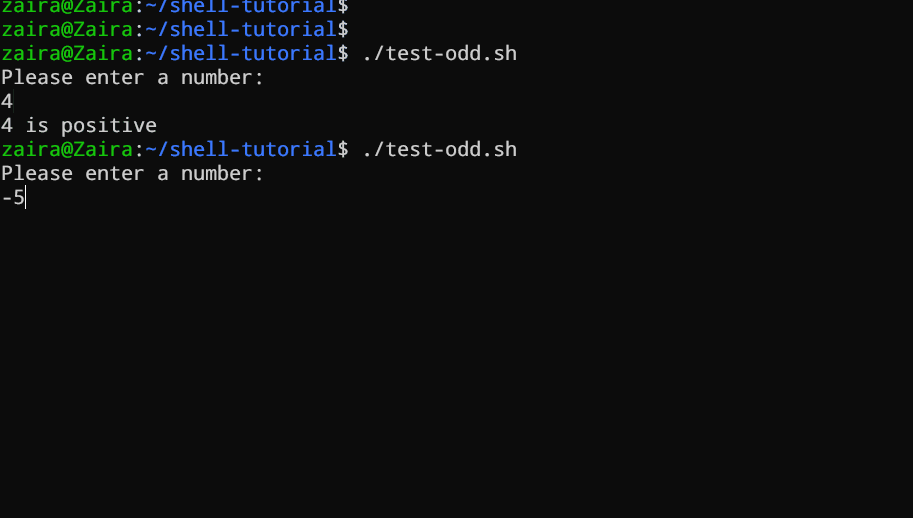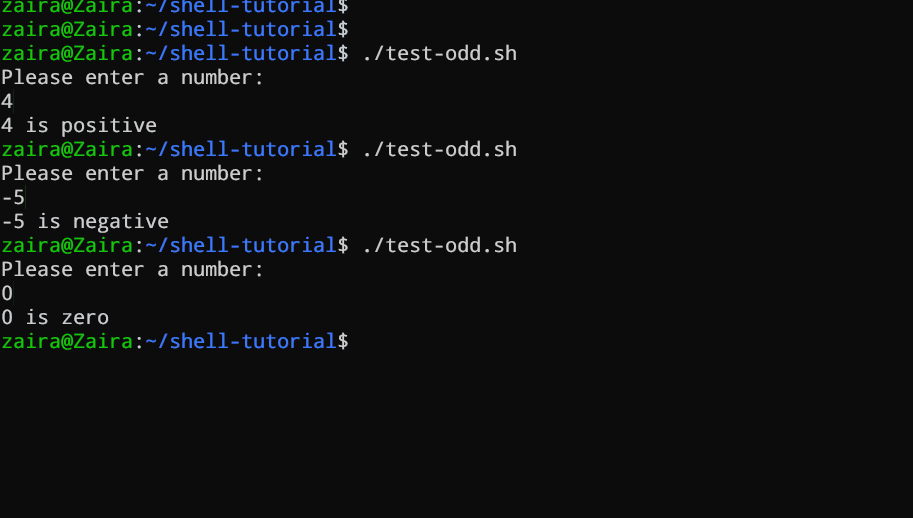
동작을 보는 것 🚀
방샷과 루프를 Bash에서
While 루프
While 루프는 조건을 확인하고 조건이 true인 동안 루프합니다. 루프 실행을 제어하기 위해 카운터 문을 제공해야 합니다.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
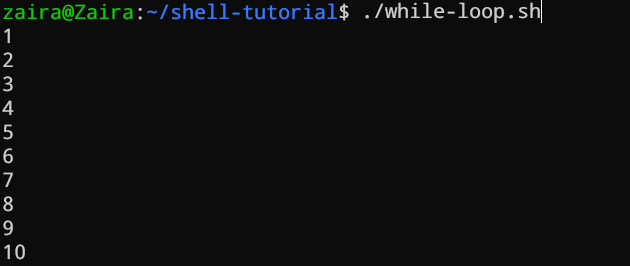
아래의 예제에서, (( i += 1 ))는 i의 값을 증가시키는 카운터 문입니다. 루프는 정확히 10회 실행됩니다.
For 루프
for 루프는 while 루프와 마찬가지로 특정 횟수로 문장을 실행시키는 데 사용할 수 있습니다. 각 루프는 문법과 사용법에서 차이가 있습니다.
#!/bin/bash
for i in {1..5}
do
echo $i
done

아래의 예제에서, 루프는 5회 반복됩니다.
Case 문
case expression in
pattern1)
Bash에서는 주어진 값을 여러 패턴에 대해 비교하고 첫 번째 일치하는 패턴에 따라 代码块을 실행하는 것을 사용하는 case 문이 있다. Bash의 case 문의 사YNX는 다음과 같다.
;;
pattern2)
# expression가 pattern1에 일치하면 실행할 code
;;
pattern3)
# expression가 pattern2에 일치하면 실행할 code
;;
*)
# expression가 pattern3에 일치하면 실행할 code
;;
esac
# 以上の패턴 중 하나도 expression에 일치하지 않으면 실행할 code
이 곳에서 “expression”는 우리가 비교하고자 하는 값이고, “pattern1”, “pattern2”, “pattern3” 등은 그들에 대해 비교하고자 하는 패턴들이다.
각 패턴에 따른 代码块을 구분하는 것은 쌍 세미콜론 “;;”로 한다. 별号 “*”는 지정한 패턴 중 하나도 일치하지 않는다면 실행할 기본 상황을 나타낸다.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
예를 들어 看看:
이 예에서, “fruit”의 값이 “apple”라면, 첫 번째 패턴과 일치하므로 “This is a red fruit.“을 출력하는 代码块이 실행된다. “fruit”의 값이 대신 “banana”라면, 두 번째 패턴과 일치하므로 “This is a yellow fruit.“을 출력하는 代码块이 실행되고 있으며, 이 문제에서는 그 과정을 나타낸다.
“fruit”의 값이 지정한 패턴 중 하나에도 일치하지 않는다면, 기본 상황이 실행되며 “Unknown fruit.“을 출력한다.
Linux에서 소프트웨어 팩지를 관리하는 방법(Part 7)
Linux에는 여러 가지 내장 프로그램이 들어있습니다. 그러나 您的 需要에 따라 새로운 프로그램을 설치하거나 现有 应用程序를 업그레이드 할 수 있습니다.
7.1. パッケージ 및 パッケージ 管理
パッケージとは何でしょう?
パッケージ는 함께 纏められた 파일의 コレクション입니다. 이러한 파일은 특정 프로그램의 실행에 필요한 파일입니다. 이러한 파일은 프로그램의 실행 파일, 라이브러리 및 다른 자원을 포함합니다.
프로그램을 실행하기 위해 필요한 파일뿐만 아니라, パッケージ에는 설치 스크립트도 포함되어 있습니다. 이러한 스크립트가 파일을 필요한 곳으로 복사합니다. 프로그램은 많은 파일과 依存성을 가질 수 있습니다. パッケージ을 사용하면 모든 파일과 依存성을 한번에 관리하기 이뻐요.
소스와 이진 코드를 어떻게 differ?
프로그래머는 프로그래밍 언어로 소스 코드를 쓰고, 이러한 소스 코드가 컴퓨터가 이해할 수 있는 기계 코드로 컴파일되어 됨. 컴파일된 코드는 이진 코드라고 합니다.
パッケージ를 다운로드할 때, 您可以 either 소스 코드나 이진 코드를 얻을 수 있습니다. 소스 코드는 사람이 읽을 수 있는 코드로 이진 코드로 컴파일 될 수 있는 코드입니다. 이진 코드는 컴퓨터가 이해할 수 있는 컴파일 된 코드입니다.소스 パッケージ는 소스 코드가 제대로 컴파일되면 모든 종류의 기기에서 사용할 수 있습니다. 반면, 이진은 特定の 기기 또는 아키텍처에 적합한 컴파일 된 코드입니다.
기기의 아키텍처를 uname -m 명령어를 사용하여 찾을 수 있습니다.
uname -m
x86_64
# 출력
Paket 의존성
프로그램들은 자주 같은 파일을 공유한다. 각 Paket에 이러한 파일을 포함하지 않고, 따로 있는 Paket을 통해 모든 프로그램에 제공할 수 있다.
이러한 파일을 가진 Paket을 설치하기 위해서는, 그 Paket을 또한 설치해야 한다. 이렇게 Paket 의존성이 되며, 의존성을 지정하면 Paket이 중복을 줄이고 더 작게 简化되며 간편해진다.
프로그램을 설치할 때, 그 의존성도 같이 설치되어야 한다. 대부분의 필요한 의존성은 이미 설치되어 있지만, 몇몇 extra Paket이 더 필요할 수 있다. 따라서, 선택한 Paket과 함께 다른 몇몇 Paket이 설치되는 것을 의심하지 마라. 이러한 Paket은 필요한 의존성을 의미한다.
Paket 관리자
Linux에는 소프트웨어를 설치하고, 업그레이드하고, 구성하고, 제거하기 위한 comprehensive Paket management system이 있다.
Paket management을 통해, organized base를 사용하여 천 init software packages를 사용할 수 있으며, 의존성을 해결하고 소프트웨어 업데이트를 확인할 수 있다.
Paket을 명령어 줄 유틸리티로 관리할 수 있으며, 시스템 관리자들이 자동화를 용이하게 해주는 그래픽 인터페이스를 통해 관리할 수 있다.
소프트웨어 채널/repositories
⚠️ Paket management은 다른 디스tribusion에 따라 다르다. 이곳에서는 Ubuntu를 사용한다.
Linux에서는 Windows과 Mac와 달리 소프트웨어 설치가 조금 다르다.
Linux는 repository를 사용하여 Paket을 보관한다. Repository는 Paket 관리자를 통해 설치할 수 있는 software packages의 コレク션을 의미한다.
패키지 관리자는 리포zu에서 사용 가능한 모든 패키지의 인덱스를 저장합니다. 인덱스를 다시 빌드하는 것은 마지막 체크以来 어떤 패키지가 업그레이드되었는지 아니면 추가되었는지 알기 위해 최신화되었는지 확인하는 것입니다.
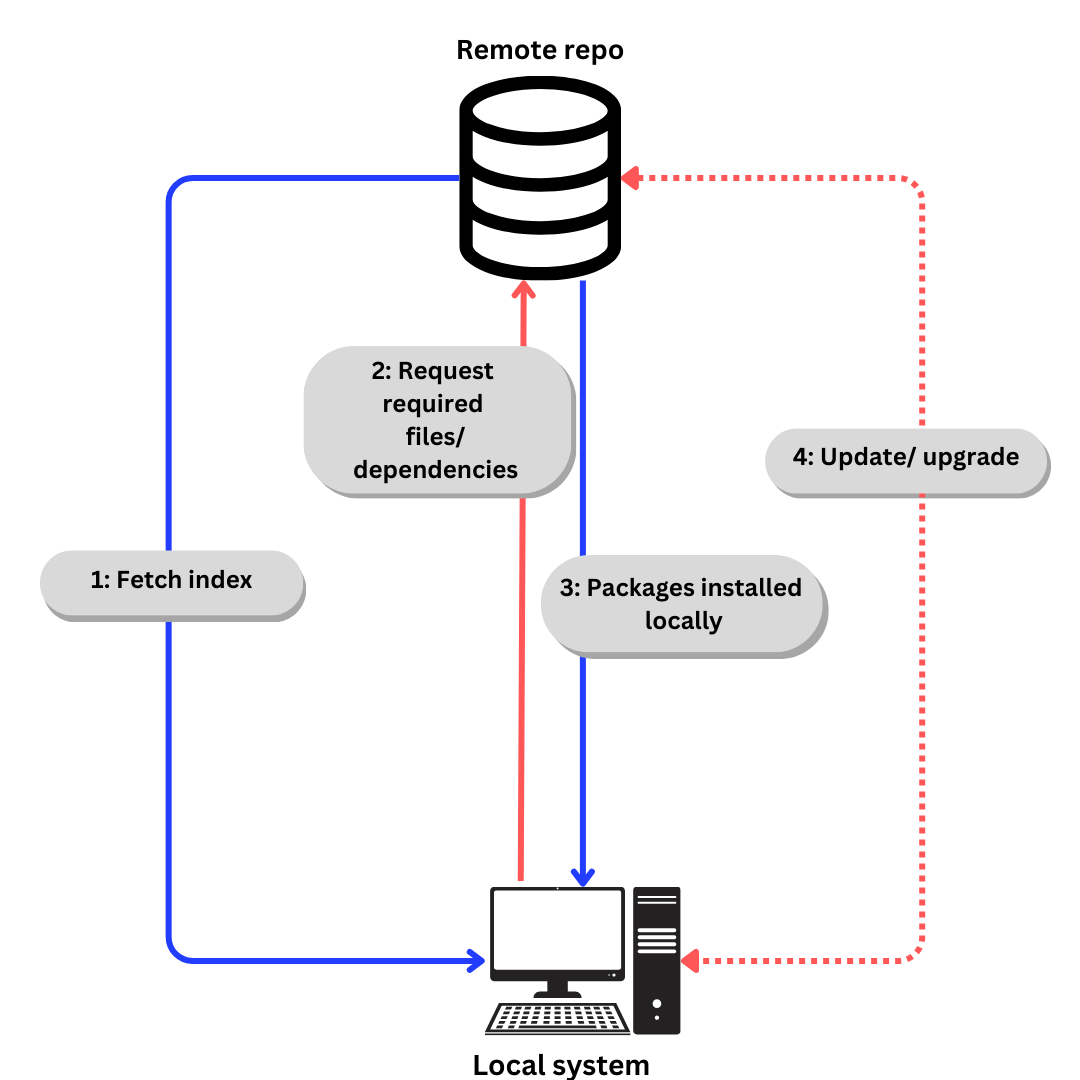
리ポzu에서 소프트웨어를 다운로드하는 일반적인 프로세스는 다음과 같습니다:
- 우분투에 대해 具体적으로 이야기할 때,
- 인덱스는
apt update을 사용하여 가져옵니다. (apt는 次節에 설명됩니다). - 인덱스에 따라 필요한 파일 및 依存성을
apt install를 사용하여 요청합니다. - 로컬에 패키지와 依存성을 설치합니다.
필요할 때는 apt update과 apt upgrade를 사용하여 依存성과 패키지를 更新하십시오.
Debian 기반 디스tribtuione에서는 /etc/apt/sources.list에 리포zu(repositories) 목록을 등록할 수 있습니다.
7.2. 명령行에서 패키지 安装
apt 명령은 유니untu의 “Advanced Packaging Tool (APT)”와 함께 작동하는 强力的한 명령行 도구입니다.
apt 명령어, 그 함께 제공되는 명령어로 인해 새로운 소프트웨어 パッケ지를 설치하는 수단을 제공하며, 기존 소프트웨어 パッケ지를 갱신하는 수단, パッケ지 목록 인덱스를 갱신하는 수단, 그리고 유니untu 전체 시스템을 갱신하는 수단을 제공합니다.
apt을 사용하여 설치한 로그를 보려면 /var/log/dpkg.log 파일을 확인할 수 있습니다.
以下은 apt 명령어의 용도입니다.
パッケ지 설치
sudo apt install htop
예를 들어 htop パッケ지를 설치하고자 하면 다음과 같은 명령어를 사용할 수 있습니다.
パッケ지 목록 인덱스 갱신
sudo apt update
パッケ지 목록 인덱스는 저장소에 있는 모든 パッケ지의 목록입니다. 로컬 パッケ지 목록 인덱스를 갱신하고자 하면 다음과 같은 명령어를 사용할 수 있습니다.
パッケ지 갱신
시스템에 설치된 パッケ지는 버그 수정, 안전 패치, 새로운 기능 등의 更新을 받을 수 있습니다.
sudo apt upgrade
パッケ지를 갱신하려면 다음과 같은 명령어를 사용할 수 있습니다.
パッケ지 제거
sudo apt remove htop
htop과 같은 パッケ지를 제거하려면 다음과 같은 명령어를 사용할 수 있습니다.
7.3 advanced 그래픽 方法으로 パッケ지 설치 – Synaptic
명령어 行에서 편안하지 않은 경우, 그래픽 인터페이스로 Paket 설치할 수 있습니다. 명령어 行과 같은 결과를 얻을 수 있지만, 그래픽 인터페이스를 사용합니다.
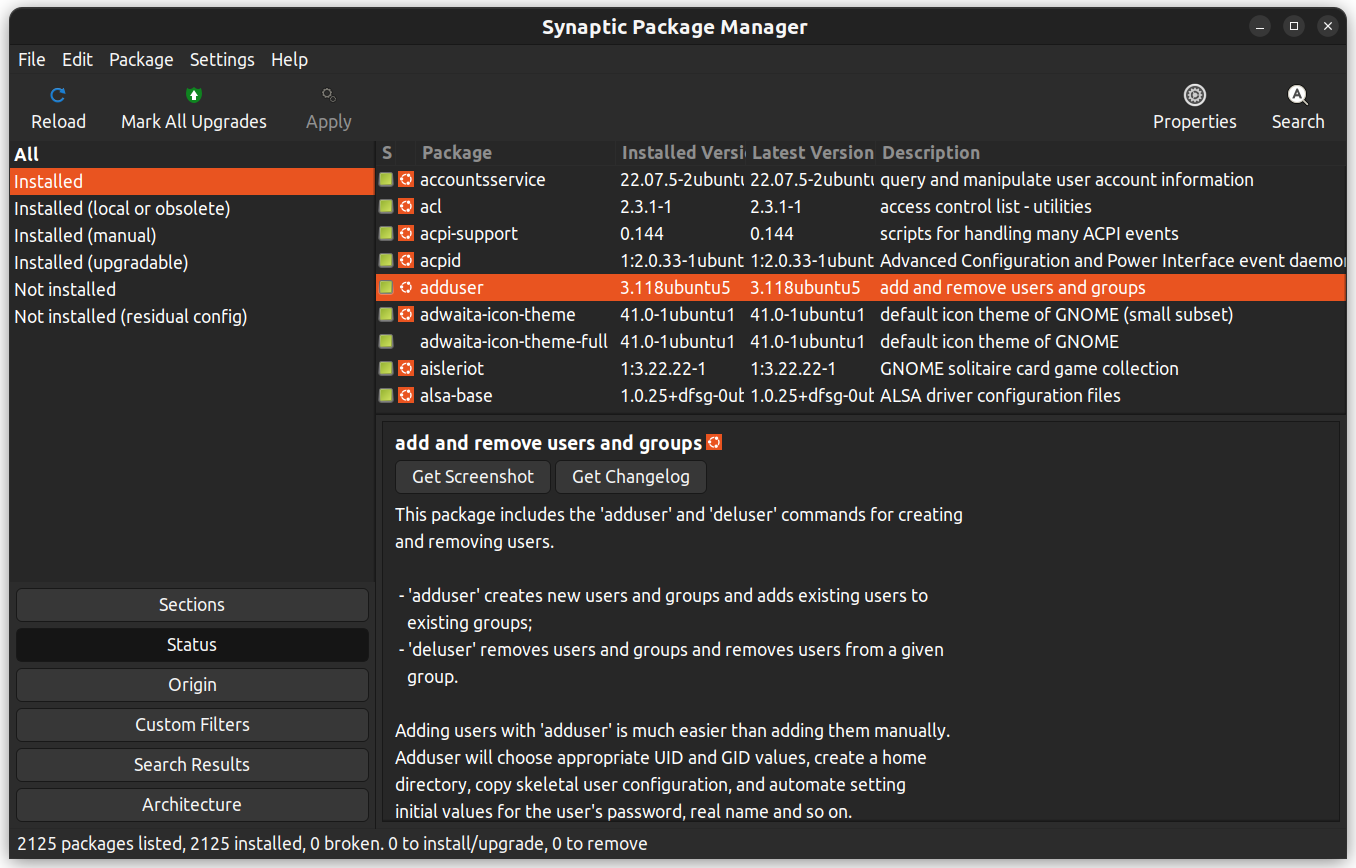
Synaptic은 설치된 パッケ지, 그들의 상태, 예정된 更新 등을 표시하는 그래픽 パッケ지 관리 应用程序입니다. custome 필터을 사용하여 서치 result를 좁혀 보실 수 있습니다.
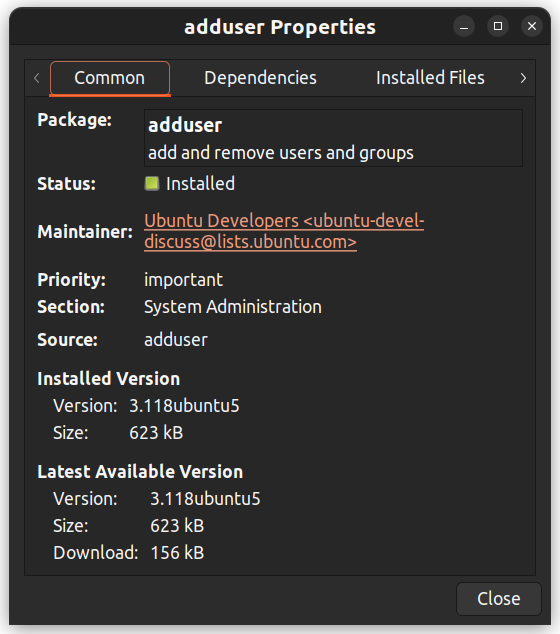
이 팩지를 클릭하여 의존성, 유지 관리자, 크기, 및 설치 파일 등의 추가 상세 정보를 확인할 수 있으며, 이를 위해서는 텍스트 editor를 사용할 수 있습니다.
7.4. 웹 사이트에서 다운로드한 팩지 설치
소프트웨어 저장소에서 아닌 웹 사이트에서 다운로드한 팩지를 설치하고자 하는 경우가 있을 수 있습니다. 이러한 팩지는 .deb 파일이라고 称하며, 이러한 팩지를 설치하기 위해서는 dpkg 명령어를 사용할 수 있습니다.
cd directory
sudo dpkg -i package_name.deb
dpkg로 팩지 설치:dpkg은 팩지 설치를 위한 명령어 行 도구입니다. dpkg를 사용하여 팩지를 설치하려면 终端을 여는 다음 다음 명령어를 입력합니다.:
주의: “directory”를 팩지가 저장되는 디렉터리로 대체하고 “package_name”를 팩지의 파일 이름으로 대체하십시오.
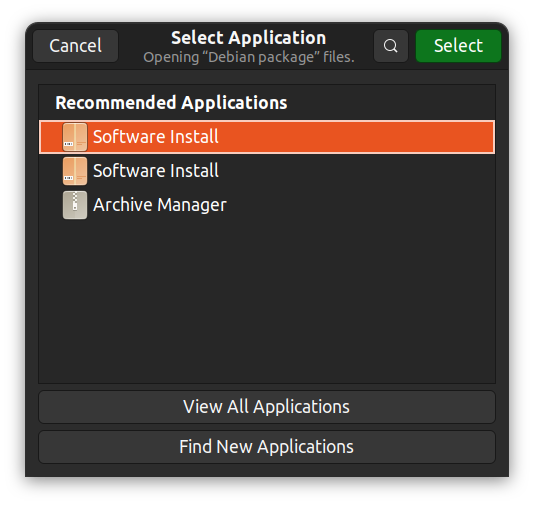
대신적으로, 오른쪽 클릭하여 “다른 응용 프로그램에서 오픈”을 선택하고 자신의 기택 GUI 응용 프로그램을 선택할 수 있습니다.
💡 팁: Ubuntu에서는 dpkg --list을 사용하여 설치 중인 팩지의 목록을 볼 수 있습니다.
8. 고급 Linux 주제
8.1. 사용자 관리
시스템에는 다양한 수준의 접근 권한을 가지는 여러 사용자가 存在할 수 있습니다. Linux에서는 루트 사용자가 가장 높은 수준의 접근 권한을 가지며, 시스템에 대한 모든 operatioin을 수행할 수 있습니다. 정규 사용자는 제한된 접근 권한을 가지며, 허용된 operaion을 수행할 수 있는 것만큼 해야 합니다.
사용자가 무엇인가?
사용자 계정은 다양한 사람과 프로그램이 명령어를 실행할 수 있는 구별을 제공합니다.
사람은 이름을 사용하여 사용자를 구별하며, 이름은 工作中的과정이 간편하게 사용할 수 있습니다. 그러나 시스템은 사용자를 유일한 숫자로 구별하는 사용자 ID(UID)로 구별합니다.
사용자가 제공된 사용자 이름을 사용하여 로그인할 때, 자신을 인증하기 위해 암호를 사용해야 합니다.
사용자 계정은 시스템 보안의 기반을 构성합니다. 파일 소유는 사용자 계정과 관련이 있으며, 이러한 계정을 통해 파일에 대한 접근 제어를 적용합니다. 모든 프로세스는 관리자들의 제어 层次을 제공하는 사용자 계정과 관련이 있습니다.
- 사용자 계정은 세 种類의 주요 형태가 있습니다:
- 슈퍼유저: 슈퍼유저는 시스템에 대한 모든 권한을 가지고 있습니다. 슈퍼유저의 이름은 `root`입니다. 그것은 `UID`가 0입니다.
- 시스템 사용자: 시스템 사용자는 시스템 서비스를 실행하기 위해 사용되는 사용자 계정을 가지고 있습니다. 이러한 계정은 사람과의 인터랙션을 목적으로 사용되지 않고 시스템 서비스를 실행합니다.
일반 사용자: 일반 사용자는 시스템에 대한 准入权을 가지는 사람 사용자입니다.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
`id` 명령어는 현재 사용자의 사용자 아이디와 그룹 아이디를 표시합니다.
id username
다른 사용자의 기본 정보를 보기 위해서는, `id` 명령어에 사용자 이름을 인자로 전달하십시오.
ps -u
사용자 관련 정보를 조회하려면 ps 명령어에 -u 플래그를 사용합니다。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# 출력
기본적으로 시스템은 /etc/passwd 파일을 사용하여 사용자 정보를 저장합니다。
root:x:0:0:root:/root:/bin/bash
/etc/passwd 파일의 한 줄은 다음과 같습니다:
/etc/passwd파일은 각 사용자에 대한 다음 정보를 포함합니다:- 사용자 이름:
root– 사용자 계정의 사용자 이름。 - 암호:
x– 보안을 위해/etc/shadow파일에 저장되는 사용자 계정의 암호(암호화된 형식)。 - 사용자 ID (UID):
0– 사용자 계정의 고유의 숫자 식별자。 - 그룹 ID (GID):
0– 사용자 계정의 주요 그룹 식별자。 - 사용자 정보:
root– 사용자 계정의 실제 이름。 - 홈 디렉터리:
/root– 사용자 계정의 홈 디렉터리.
쉘: /bin/bash – 사용자 계정의 기본 쉘. 시스템 사용자는 인터актив 로그인이 허용되지 않은 경우 /sbin/nologin을 사용할 수 있습니다.
그룹이란 무엇인가요?
그룹은 액세스와 자원을 공유하는 사용자 계정의 모음입니다. 그룹은 그룹 이름으로 식별되며, 시스템은 그룹 ID (GID)라고 불리는 고유한 번호로 그룹을 식별합니다.
기본적으로, 그룹에 관한 정보는 /etc/group 파일에 저장됩니다.
adm:x:4:syslog,john
/etc/group 파일의 항목입니다:
- 주어진 항목의 필드를 분석한 결과입니다:
- 그룹 이름:
adm– 그룹의 이름. - 암호:
x– 그룹 암호는 보안을 위해/etc/gshadow파일에 저장됩니다. 암호는 선택 사항이며 설정되어 있지 않으면 빈칸으로 표시됩니다. - 그룹 아이디(GID):
4– 그룹의 고유적인 숫자 식별자.
그룹 구성원: syslog,john – 그룹에 속한 사용자 이름 목록. 이 경우, adm 그룹은 두 명의 구성원을 가지고 있습니다: syslog 및 john.
이 특정 条目에서, 그룹 이름은 adm이고, 그룹 아이디는 4입니다. 그룹은 두 명의 구성원을 가지고 있습니다: syslog 및 john. 암호 字段은 보통 x로 설정되어 그룹 암호가 /etc/gshadow 파일에 저장되었음을 나타냅니다.
- 그룹은 더 이상 기본과 supplementary 그룹으로 분할되어 있습니다.
- 기본 그룹: 각 사용자는 기본적으로 하나의 기본 그룹을 할당받습니다. 이 그룹은 사용자 이름과 같은 이름을 가지고 있으며, 사용자 계정을 생성할 때 생성됩니다. 사용자가 생성한 파일과 디렉터리는 일반적으로 이 기본 그룹에 소유되ます.
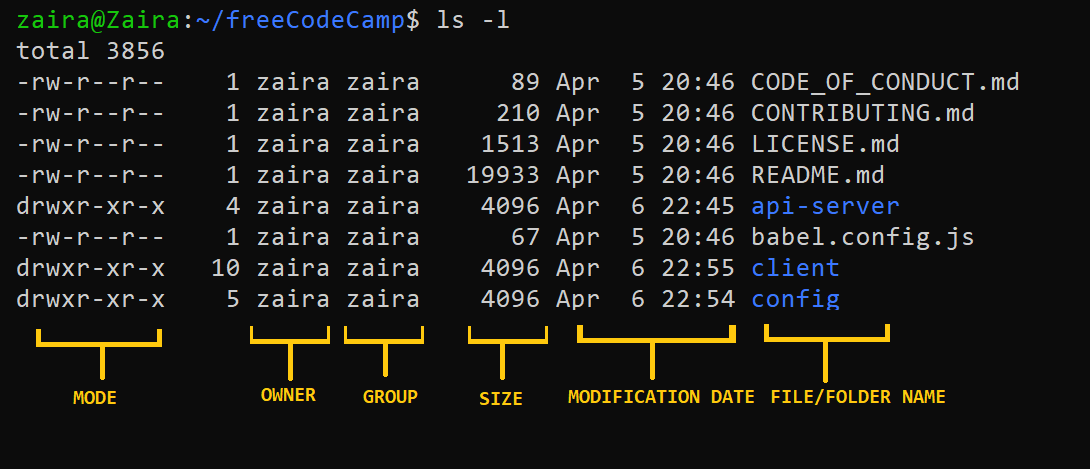

- 모드
- 파일 형식: 파일 형식은 파일의 종류를 정의합니다. 일반 파일은 간단한 데이터를 포함하며 이를 나타내는 빈 값
-입니다. 다른 특수 파일 형식의 경우 기호가 다릅니다. 디렉터리가 특수 파일로 나타나는 경우d가 됩니다. 특수 파일은 操作系统에 따라 다르게 처리됩니다.
권한 클azzes: 다음 문자열은 사용자, 그룹, 그리고 다른 사용자들의 권한을 respectively 정의합니다.
– 사용자: 파일의 소유자입니다. 파일의 소유자는 이 클azz에 속합니다.
– 그룹: 파일의 그룹 멤버들은 이 클azz에 속합니다
– 다른: 사용자 또는 그룹 클azz에 속하는 사용자가 아닌 모든 사용자는 이 클azz에 속합니다.
💡팁: 디렉터리의 소유를 ls -ld 명령어를 사용하여 볼 수 있습니다.
Symbolic Permissions 또는 rwx 권한 읽기
rwx표현은 권한의 Symbolic 표현입니다. 권한의 쌍에- 읽기의
r를 表시하며, 삼각형의 첫 글자로 나타납니다. w는 쓰기를 表시합니다. 삼각형의 두 번째 글자로 나타납니다.
x는 실행를 表시합니다. Samantha의 세 번째 글자로 나타납니다.
읽기:
정규 파일에 대해서는, 읽기 권한은 파일을 열고 읽는 것만 가능하며, 사용자는 파일을 수정할 수 없습니다.
동일하게 디렉터리에 대해서는, 읽기 권한은 디렉터리 내용을 목록에 표시하는 것만 가능하며, 디렉터리 내용을 수정할 수 없습니다.
쓰기:
파일에 대해서 쓰기 권한이 있으면, 사용자는 파일을 수정(편집, 삭제)하고 저장할 수 있습니다.
폴더에 대해서는, 쓰기 권한은 사용자가 폴더 내용을 수정할 수 있도록(그 안의 파일을 생성, 삭제, 이름 변경)하고, 사용자가 쓰기 권한을 가진 파일의 내용을 수정할 수 있도록 합니다.
Linux의 권한 예
- 이제 읽기 권한을 이해하였으므로, 몇 가지 예를 봅시다.
-
-rw-rw-r--: 이 파일은 주인과 그룹이 수정할 수 있으며 다른 사용자에게는 열람이 가능합니다.
drwxrwx---: 이 디렉터리는 주인과 그룹만이 수정할 수 있습니다.
실행:
파일에 대해서는, 실행 권한은 사용자가 실행 가능한 스크립트를 실행할 수 있게 합니다. 디렉터리에 대해서는, 사용자는 그 디렉터리에 접근할 수 있고 디렉터리内의 파일의 상세정보를 확인할 수 있게 합니다.
Linux에서 chmod과 chown를 사용하여 파일 권한과 소유자를 변경하는 방법
소유자와 권한의 기본적인 지식을 가지고 있으면 chmod 명령어를 사용하여 권한을 변경할 수 있는 것을 보겠습니다.
chmod permissions filename
chmod의 구문:
- 어디서,
권한은 읽기, 쓰기, 실행 또는 그 중 조합입니다.
파일명는 권한을 변경해야 하는 파일의 이름입니다. 이 パ라미터는 권한을 한꺼번에 변경하기 위한 여러 파일의 목록을 나타낼 수 있습니다.
- 有两种模式可以用来更改权限:
- 象征的 모드: 이 방법은
u,g,o과 같은 기호를 사용하여 사용자, 그룹 및 다른 것을 나타냅니다. 권한은 읽기, 쓰기, 실행을 나타내는r, w, x로 표시됩니다. 권한을 +, -, = 를 사용하여 수정할 수 있습니다.
절대 모드: 이 방법은 0에서 7까지의 3자리 8진수 숫자로 권한을 표현합니다.
이제 자세히 보겠습니다.
象征的 모드로 권한 변경하는 방법
| 下表은 사용자 표현을 요약합니다. | USER REPRESENTATION |
| u | DESCRIPTION |
| g | user/owner |
| o | group |
other
| 우리는 算術 연산자를 사용하여 권한을 추가, 제거, 지정할 수 있습니다. 下面的表은 요약입니다. | OPERATOR |
| DESCRIPTION | + |
| File or directory에 권한을 추가합니다 | – |
| 권한을 제거합니다 | \= |
이미 존재하지 않으면 권한을 설정하고, 이전에 설정한 권한을 우선 하여 재정한다.
예시:
저는 스크립트를 가지고 있고, 이 스크립트를 파일 주인 zaira에게 실행 가능하도록 하고자 한다.

현재 파일 권한은 다음과 같다:
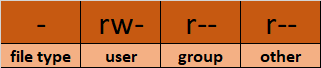
권한을 다음과 같이 분할해보자:
chmod u+x mymotd.sh
이를 symbolische 모드로 사용하여 주인(u)에게 실행 권한(x)을 추가하는 명령어는 다음과 같다:
Output:
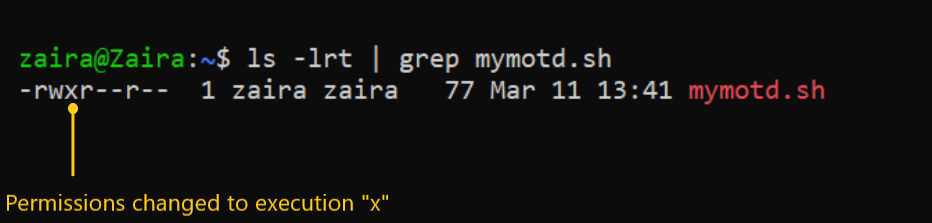
이제, 실행 권한이 주인 zaira에게 추가되었음을 볼 수 있다.
- symbolische 방법으로 권한 변경하는 추가적인 예시:
- 그룹(
group)과 타 인(others)에 대한 읽기(read)과 쓰기(write) 권한을 제거하는 것:chmod go-rw. - 타 인(
others)에 대한 읽기(read) 권한을 제거하는 것:chmod o-r.
그룹(group)에 대한 쓰기(write) 권한을 부여하고 기존 권한을 우선 하는 것: chmod g=w.
절대 모드로 권한 변경하는 方法
절대 모드는 숫자를 사용하여 권한을 표현하고, 수학적 연산자를 사용하여 그들을 수정합니다.
| 下記 테이블은 우리가 관련 권한을 어떻게 부여할 수 있는지 보여줍니다. | 권한 |
| 권한 제공 | read |
| add 4 | write |
| add 2 | execute |
add 1
| 권한은 뺄 수 있습니다. 다음 테이블은 관련 권한을 어떻게 취소할 수 있는지 보여줍니다. | 권한 |
| 권한 취소 | read |
| subtract 4 | write |
| subtract 2 | execute |
subtract 1
- 예:
user에게 read (add 4)를, group에게 read (add 4)와 execute (add 1)를, 그리고 others에게는 단지 execute (add 1)만을 부여합니다.
chmod 451 file-name
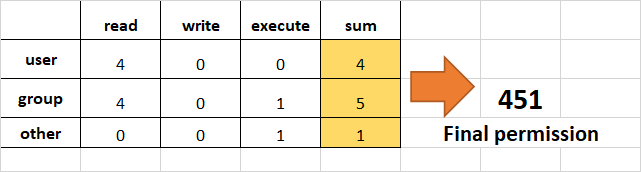
이러한 계산은 다음과 같습니다:
- 이것은
r--r-x--x와 같습니다.
other와 group에게 execution 권한을 제거합니다.
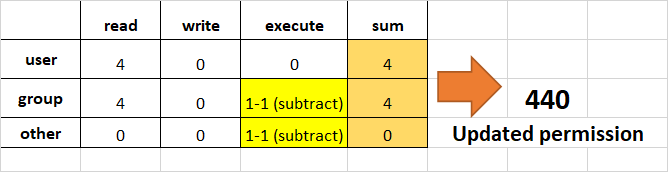
-
other와group에게 실행 권한을 제거하려면, 마지막 2 obyte의 실행 部分에 1을 뺀다.
read, write, execute 권한을 user에게, read와 execute 권한을 group에게, 그리고 read 권한만 다른 사용자에게 부여합니다.

이는 rwxr-xr--와 같습니다.
chown 명령을 사용하여 소유권 변경하는 방법
다음에는 파일의 소유권을 변경하는 방법을 배울 것입니다. chown 명령을 사용하여 파일이나 폴더의 소유권을 변경할 수 있습니다. 일부 경우에는 소유권 변경에 sudo 권한이 필요합니다.
chown user filename
chown의 문법:
chown로 사용자 소유권 변경하는 방법
사용자 zaira에서 사용자 news로 소유권을 이전해 봅시다.

chown news mymotd.sh
소유권 변경 명령: sudo chown news mymotd.sh.

출력:
사용자와 그룹 소유권을 동시에 변경하는 방법
chown user:group filename
chown를 사용하여 사용자와 그룹을 동시에 변경할 수 있습니다.
디렉터리 소유권 변경하는 방법
chown -R admin /opt/script
디렉터리 내용물에 대한 소유권을 재귀적으로 변경할 수 있습니다. 아래 예제는 /opt/script 폴더의 소유권을 변경하여 admin 사용자에게 권한을 부여합니다.
그룹 소유권 변경하는 방법
chown :admins /opt/script
그룹 소유자만 변경해야 하는 경우, 그룹 이름 앞에 콜론 :을 두어 chown를 사용할 수 있습니다.
사용자 사이에서 전환하는 방법
[user01@host ~]$ su user02
Password:
[user02@host ~]$
su 명령어를 사용하여 사용자를 전환할 수 있습니다.
슈퍼유저 アクセス 수 gained superuser access
슈퍼유저또는 뿌리 사용자는 리눅스 시스템에서 가장 높은 수준의 アクセ스를 가지고 있습니다. 뿌리 사용자는 시스템上에서 어떤 operaion을 수행할 수 있습니다. 뿌리 사용자는 모든 파일과 디렉터리에 액세스하고, 소프트웨어를 설치하거나 제거하며, 시스템 구성을 수정하거나 オーバー라이드 할 수 있습니다.
大きな パワ と共に大きな責任가 있습니다. 만약 뿌리 사용자가 유 sabmission되면, 누구から도 시스템의 完全な コntrol을 얻을 수 있습니다. 뿌리 사용자 アカウン트を必要한 경우만 사용する 것이 좋습니다.
[user01@host ~]$ su
Password:
[root@host ~]사용자 이름을 생략하면, su 명령어가 기본적으로 뿌리 사용자 アカウン트로 전환합니다.
#
su 명령어의 다른 ваariation은 su - 입니다. su 명령어는 뿌리 사용자 アカウン트로 전환하지만, 環境変数를 변경하지 않습니다. su - 명령어는 뿌리 사용자 アカウン트로 전환하고, 목적지 사용자의 環境変数로 変更합니다.
sudo 명령어로 コmmand을 실행하는 것
root 사용자로 コmmand을 실행하고자 하면서 root 사용자 アカウン트로 전환하는 것보다, sudo 명령어를 사용하는 것이 더 안전합니다. 이는 밑에서 설명합니다.
sudo 명령어를 사용하여 コmmand을 실행하는 것은 root 사용자로 실행하는 것보다 안전한 옵션입니다. 이는 /etc/sudoers 파일에 정의되어 있는 특정 사용자 셋이 권한을 부여받아 sudo 명령어로 コmmand을 실행할 수 있음을 의미합니다.
sudo는 사용자가 실행한 모든 명령어를 기록하며, 누구が 어떤 명령어를 언제 실행했는지 어떻게 감시할 수 있는 이审计 경로를 제공합니다.
cat /var/log/auth.log | grep sudo
Ubuntu에서는 审计 로그를 여기에 찾을 수 있습니다:
user01 is not in the sudoers file. This incident will be reported.
sudo 에 액세스 권한이 없는 사용자는 로그에 표시되고, 다음과 같은 메시지가 표시됩니다:
로컬 사용자 계정 관리
命令行에서 사용자 생성
sudo useradd username
새로운 사용자를 추가하는 명령어는 다음과 같습니다:
이 명령어는 사용자의 홈 디렉터리를 설정하고 사용자 이름을 사용하여 지정한 개인 그룹을 만듭니다. 현재, 계정은 유효한 암호가 없어 암호를 생성하기 전까지 로그인할 수 없습니다.
现有用户修改
usermod 명령어는 现存的 사용자를 수정하는 데 사용되며, usermod 명령어로 사용되는 一些 일반적인 옵션들이 다음과 같습니다:
usermod명령어의 一些 리눅스 예제들이 다음과 같습니다:- 사용자의 로그인 이름을 변경하기:
- 사용자의 홈 디렉터리를 변경합니다:
- 사용자를 보조 그룹에 추가합니다:
- 사용자의 쉘을 변경합니다:
- 사용자 계정을 잠금 합니다:
- 사용자 계정 解锁:
- 사용자 계정 만료 일자 설정:
- 사용자 UID (User ID) 변경:
- 사용자의 주요 그룹 변경:
supplementary group에 사용자를 제거하는 방법
사용자 제거
- `userdel` 명령어는 시스템에서 사용자 계정과 相关工作文件을 삭제하는 것을 도와줍니다.
sudo userdel username: `/etc/passwd`에서 사용자의 정보를 제거하지만, 사용자의 홈 디렉터리를 유지합니다.
`sudo userdel -r username` 명령어는 `/etc/passwd`에서 사용자의 정보를 제거하고, 사용자의 홈 디렉터리도 삭제합니다.
사용자 비밀번호 변경
- `passwd` 명령어는 사용자의 비밀번호를 변경하는 것을 도와줍니다.
sudo passwd username: username의 기초 비밀번호를 지정하거나 기존 비밀번호를 변경합니다. 현재 로그인 중인 사용자의 비밀번호도 변경할 수 있습니다.
8.2 SSH를 사용하여 远程服务器에 연결하는 方法
접근한 원격 서버는 시스템 관리자의 필수적인 업무之一입니다. SSH를 사용하여 다른 서버에 연결하거나 로컬 기기를 통해 데이터베이스에 접근하고 명령을 실행할 수 있습니다.
SSH 프로토콜이 무엇인가요?
SSH는 Secure Shell의 약어입니다. 두 시스템間의 안전한 통신을 위한 암호화 네트워크 프로토콜입니다.
SSH의 기본 포트는 22입니다.
- SSH를 통해 통신하는 두 참여자는 다음과 같습니다:
- 서버: 접근하고자 하는 기기입니다.
클라이언트: 서버에 접근하는 시스템입니다.
- 서버에 연결하는 과정은 다음과 같습니다:
- 연결 초기화: 클라이언트는 서버에 연결 요청을 보냅니다.
- 키 교환: 서버는 공개키를 클라이언트에게 보냅니다. 양측은 사용할 암호화 방법에 합의합니다.
- 세션 키 생성: 클라이언트와 서버는 Diffie-Hellman 키 교환을 사용하여 공유 세션 키를 생성합니다.
- klient authentication: klient server에 로그인하기 위해 암호, 개인 키 또는 다른 방법을 사용합니다.
安全的 통신: 인증 후, klient과 server는 암호화를 통해 안전하게 통신합니다.
SSH를 사용하여 원격 server에 연결하는 方法
SSH 명령어는 Linux의 내장 서비스로 同时也是 기본값입니다. 이를 사용하면 server에 접근하는 것이 매우 간편하고 안전합니다.
여기서는 klient이 server로 연결을 하는 방법을 말합니다.
- server로 연결하기 전에는 다음과 같은 정보가 있어야 합니다.:
- server의 IP 주소나 도메인 이름.
- server의 사용자 이름과 암호.
server로부터 사용할 수 있는 포트 번호.
ssh username@server_ip
ssh 명령어의 기본 구문은 다음과 같습니다.:
ssh [email protected]
例如, 사용자 이름이 john이고 server IP가 192.168.1.10이면 명령어가 다음과 같습니다.:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ 그 다음, 암호를 입력하는 것을 제안받을 것입니다. 화면은 다음과 유사합니다.:
# 명령어 입력 시작
이제 192.168.1.10 서버에 관련 명령어를 실행할 수 있습니다.
ssh -p port_number username@server_ip
⚠️ ssh의 기본 포트는 22 입니다만, 취약하며 해킹 attacks가 먼저 여기에 시도할 것입니다. 您的 서버는 다른 포트를 노출할 수 있으며, 접근을 공유할 수 있습니다. 다른 포트로 연결하려면 -p 옵션을 사용하십시오.
8.3 고급 로그 구문 분석 및 해석
로그 파일은 시스템에서 유용한 목적을 위해 구성되어 생성되며, 시스템 이벤트를 추적하고, 시스템 パフォーマン스를 모니터링하고, 문제를 해결하는 데 사용할 수 있습니다. 특히 시스템 관리자에게는 응용 에러, 네트워크 이벤트, 사용자 활동을 추적하는 데 유용합니다.
다음은 로그 파일의 예시입니다:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# 샘플 로그 파일
- 로그 파일은 일반적으로 다음과 같은 열을 포함합니다:
- Timestamp: 이벤트가 발생한 날짜와 시간.
- Log Level: 이벤트의 심각도(INFO, DEBUG, WARN, ERROR).
- Component: 이벤트를 발생시켰던 시스템 구성 요소(Startup, Config, Database, User, Security, Network, Email, API, Session, Shutdown).
- 이벤트 내용 설명
추가 정보: 이벤트와 관련된 추가 정보
실시간 시스템에서는 로그 파일이 수천 行이나 되며, 每一秒에 생성되는 것が 常态입니다. configurations에 따라 Wordy할 수 있습니다. 로그 파일의 모든 열은 이슈를 추적하는 데 사용할 수 있는 정보를 가지고 있습니다. 이러한 것들이 로그 파일을 手动的로 읽고 이해하는 것에 困难를 줍니다.
이러한 것을 해결하기 위해 로그 분석이 필요합니다. 로그 분석은 로그 파일에서 유용한 정보를 추출하는 과정입니다. 로그 파일을 더 작은, 더 수행 가능한 部分로 분할하고 관련 정보를 추출합니다.
過濾된 정보는 警戒, 보고서, 대시보드 생성에도 유용하게 사용할 수 있습니다.
이 섹션에서는 Linux에서 로그 파일 분석을 위한 몇 가지 기술을 탐구할 것입니다.
grep 를 사용한 텍스트 추출
Grep는 내장된 Bash 유틸리티입니다. “global regular expression print”의 의미로 사용되며, 파일 내에서 문자열 매칭을 수행합니다.
-
grep의 일반적인 사용 예는 다음과 같습니다: - 이 명령어는 “
search_string“이 이 이름의 파일filename에서 존재하는지 찾습니다. - 이 명령어는 “
search_string“이 지정한 디렉터리 및 그 하위 디렉터리의 모든 파일 내에서 찾습니다. - 이 명령어는 “search_string”이
filename이라는 이름의 파일 내에서 대/소문자를 구분하지 않는 Search를 실행합니다. - 이 명령어는
filename이라는 파일안에 일치하는 行과 함께 行号를 보여줍니다. - 이 명령어는
filename이라는 파일안에 “search_string”를 포함하는 行의 갯수를 세어줍니다. - 이 명령은
filename라는 이름의 파일 내"search_string"을 포함하지 않는 모든 行을 표시합니다. - 이 명령은
filename라는 이름의 파일 내"word"이 전체 単어로 存在하는지 search합니다.
이 명령은 filename라는 이름의 파일 내 더 복잡한 패턴 일치에 대해 확장 정규식을 사용할 수 있게 합니다.
💡 팁: 폴더에 여러 파일이 있으면, 아래 명령을 사용하여 원하는 문자열을 포함하는 파일의 목록을 찾을 수 있습니다.
grep -l "String to Match" /path/to/directory
# 원하는 문자열을 포함하는 파일의 목록을 찾습니다.
sed Text 추출
sed는 “스트림 에디터”의 缩写이며, 데이터를 스트림 단위로 처리하는 것을 의미합니다. 这意味着它是一次读取一行数据。sed를 사용하면 특정 패턴을 찾고, 해당 패턴의 行에 대한 작업을 실행할 수 있습니다.
sed의 기본 구문
sed [options] 'command' file_name
sed의 기본 구문은 다음과 같습니다:
여기서 명령어는 텍스트 데이터에 대한 수정 작업을 실행하는 것을 의미합니다. 파일명은 处理的文件名입니다.
sed사용법:
1. 대체:
sed 's/old-text/new-text/' filename
s 기호는 텍스트를 대체하는 것을 의미합니다. old-text는 new-text로 대체되며, 예를 들어 system.log 로그 파일에서 “error”를 “warning”로 모두 바꾼다면:
sed 's/error/warning/' system.log
2. 특정 패턴의 行 인쇄:
sed -n '/pattern/p' filename
sed를 사용하여 특정 패턴과 일치하는 行을 필터링하고 표시하는 것:
sed -n '/ERROR/p' system.log
例如, “ERROR”를 모두 찾는 것:
3. 특정 패턴의 行 삭제:
sed '/pattern/d' filename
특정 패턴과 일치하는 行을 输出的行에서 삭제할 수 있습니다:
sed '/DEBUG/d' system.log
例如, “DEBUG”를 모두 제거하는 것:
4. 로그 行의 특정 필드 추출:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
다음은 한 줄의 일부를 추출하는 데 정규식을 사용할 수 있다는 것입니다. 가령 각 로그 라인이 “YYYY-MM-DD” 형식의 날짜로 시작한다고 가정해 보겠습니다. 각 줄에서 오직 날짜만 추출할 수 있습니다:
텍스트 파싱은 awk로
awk는 각 줄을 필드들로 쉽게 분리할 수 있는 기능을 갖추고 있습니다. 구조화된 텍스트를 처리하는 데, 예를 들어 로그 파일처럼 적합합니다.
awk의 기본 문법
awk 'pattern { action }' file_name
awk의 기본 문법은 다음과 같습니다:
여기서 pattern은 action을 수행하기 위해 반드시 만족해야 하는 조건입니다. 패턴을 생략하면 모든 줄에 대해 동작이 수행됩니다.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- 다음 예제에서는 다음과 같은 로그 파일을 예로 사용합니다:
awk로 열 액세스
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
awk에서의 필드(기본적으로 스페이스로 분리됨)는 $1, $2, $3 등으로 액세스할 수 있습니다.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# 출력
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # 출력
awk '/ERROR/ { print $0 }' logfile.log
특정 패턴(예: ERROR)을 포함하는 줄 출력
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# 출력
- 이렇게하면 “ERROR”를 포함하는 모든 줄이 출력됩니다.
awk '{ print $1, $2 }' logfile.log
첫 번째 필드(날짜와 시간) 추출
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# 출력
- 이렇게하면 각 줄에서 처음 두 필드를 추출할 수 있으며, 이 경우에는 날짜와 시간입니다.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
각 로그 레벨의 발생 횟수 요약
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# 출력
- 출력은 각 로그 수준의 발생 횟수의 요약이 될 것입니다.
awk '{ $3="INFO"; print }' sample.log
특정 필드를 필터링하세요 (예를 들어 세 번째 필드가 INFO인 경우)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# 출력
이 명령은 세 번째 필드가 “INFO”인 모든 줄을 추출할 것입니다.
💡 팁: awk의 기본 구분자는 공백입니다. 로그 파일이 다른 구분자를 사용하는 경우, -F 옵션을 사용하여 지정할 수 있습니다. 예를 들어, 로그 파일이 콤MA를 구분자로 사용하는 경우, awk -F: '{ print $1 }' logfile.log을 사용하여 첫 번째 필드를 추출할 수 있습니다.
cut로 로그 파일 분석
cut 명령은 입력 行的 문자열 일부를 추출하는 간단하면서도 강력한 명령어입니다. 로그 파일은 구조化되어 있으며, 각 필드가 공백, 탭, 또는 사용자 정의 구분자로 구분되어 있기 때문에 cut가 그 특정 필드를 추출하는 것을 잘 하며 있습니다.
cut [options] [file]
cut 명령의 기본 구문은 다음과 같습니다:
- cut 명령에 commonly used options:
-d: 필드 구분자로 사용할 구분자를 지정합니다.-f: 표시할 필드를 선택합니다.
-c : 문자 위치를 지정합니다.
cut -d ' ' -f 1 logfile.log
예를 들어, 아래 명령어는 로그 파일의 各行에서 공백을 기준으로 첫 段(field)을 추출합니다.:
Examples of usingcutfor log parsing
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
다음과 같이 구성된 로그 파일을 가정하고 있으며, 段은 공백을 기준으로 분리되어 있습니다:
cut은 다음과 같은 방법으로 사용할 수 있습니다:
cut -d ' ' -f 2 system.log
Each log entry's time extraction:
08:23:01
08:24:15
08:25:02
...
# Output
- 이 명령어는 공백을 구분자로 사용하여 각 로그 입력의 두 번째 段, 즉 시간 요소를 선택합니다.
cut -d ' ' -f 4 system.log
Extracting IP addresses from the logs:
192.168.1.10
192.168.1.10
10.0.0.5
# Output
- 이 명령어는 각 로그 입력의 네 번째 段, 즉 IP 주소를 추출합니다.
cut -d ' ' -f 3 system.log
Extracting log levels (INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# Output
- 이는 로그 수준을 포함하는 세 번째 段을 추출합니다.
Other commandscutcombination:
grep "ERROR" system.log | cut -d ' ' -f 1,2
다른 명령어의 출력은 cut 명령어에 대한 파이프 연결을 통해 사용할 수 있습니다. 比如说, "ERROR"를 포함하는 行을 필터링하고 그 行에서 특정 정보를 얻고자 하면, grep를 사용하여 "ERROR"를 포함하는 行을 추출하고 그 다음에 cut를 사용하여 那些 行에서 특정 정보를 추출할 수 있습니다.:
2024-04-25 08:25:02
# Output
- 이 명령은 먼저 “ERROR”를 포함하는 라인들을 필터링하고, 이러한 라인들에서 날짜와 시간을 추출합니다.
multiple fields 추출:
cut -d ' ' -f 1,2,3 system.log`
범위를 지정하거나 字面값을 콤마로 구분한 리스트로 필드를 여러 개 동시에 추출할 수 있습니다.
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# 출력
이 명령은 날짜, 시간, 로그 수준 등 각 로그 엔트리의 첫 세 개의 필드를 추출합니다.
sort と uniq 로 로그 파일 수정
로그 파일 작업 시 일반적인 opertaion 은 정렬과 중복 제거입니다. sort 과 uniq 명령어는 각각 입력 데이터를 정렬하고 중복 데이터를 제거하는 強力한 명령어들입니다.
sort 명령어의 기본 구문
sort [options] [file]
sort 명령어는 텍스트 라인을 알파벳 또는 숫자 순서로 정렬합니다.
- sort 명령어의 주요 옵션은 다음과 같습니다:
-n: 내용이 숫자일 때 파일을 정렬합니다.-r: 정렬 순서를 reverese 합니다.-k: 정렬할 키 또는 열 번호를 지정합니다.
-u : 중복 라인을 정렬하고 제거합니다.
uniq 명령은 파일에서 반복되는 줄을 필터링하거나, 계산 및 보고하는 데 사용됩니다.
uniq [options] [input_file] [output_file]
uniq의 문법은 다음과 같습니다:
uniq명령의 몇 가지 주요 옵션은 다음과 같습니다:-c: 줄 별 출현 횟수를 앞에 붙입니다.-d: 중복 줄만 인쇄합니다.
-u: 고유한 줄만 인쇄합니다.
sort와 uniq를 함께 사용하여 로그 파싱하는 예제
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- 다음과 같은 예제 로그 항목을 이데모레이션에 사용하겠습니다:
sort system.log
로그 항목을 날짜로 정렬:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# 출력
- 이렇게 하면, 날짜가 첫 번째 필드인 경우 알파벳순으로 정렬되어 날짜로 정렬되는 것과 같습니다.
sort system.log | uniq
줄 정렬 후 중복 제거:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# 출력
- 이 명령은 로그 파일을 정렬한 다음
uniq로 전달하여 중복 줄을 제거합니다.
sort system.log | uniq -c
각 줄의 출현 횟수 계산:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# 출력
- 로그 항목을 정렬한 다음 각 고유 줄의 횟수를 계산합니다. 출력에 따르면,
'2024-04-25 INFO User logged in successfully.'줄이 파일에서 2번 나타났습니다.
sort system.log | uniq -u
고유 로그 엔트리 식별:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# 출력
- 이 명령은 고유한 라인을 보여줍니다.
sort -k2 system.log
로그 레벨로 정렬:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# 출력
로그 레벨을 기반으로 두번째 필드를 정렬합니다.
8.4. 명령행을 통한 리눅스 프로세스 관리
- 프로세스는 프로그램의 실행 중인 인스턴스입니다. 프로세스는 다음을 포함합니다:
- 할당된 메모리의 주소 공간.
- 프로세스 상태.
소유자, 보안 속성, 자원 사용량과 같은 속성.
- 프로세스는 또한 다음을 포함하는 환경을 갖추고 있습니다:
- 로컬 변수와 전역 변수
- 현재의 스케줄링 컨텍스트
네트워크 포트나 파일 기술자와 같은 할당된 시스템 자원.
ls -l 명령을 실행할 때, 운영 체제는 명령을 실행하기 위한 새 프로세스를 생성합니다. 프로세스는 ID, 상태를 갖추며 명령이 완료될 때까지 실행합니다.
프로세스 생성과 생명 주기 이해
Ubuntu에서, 모든 프로세스는 systemd라는 시스템 초기 프로세스에서 시작되며, 引导(boot) 시 kernel이 시작하는 첫 프로세스입니다.
systemd 프로세스는 프로세스 아이디(PID)가 1로 시작하며, 시스템을 초기화하고, 다른 프로세스를 시작하고 관리하며 시스템 서비스를 처리하는 责任를 가지고 있습니다. 시스템에 있는 모든 다른 프로세스는 systemd의 자식입니다.
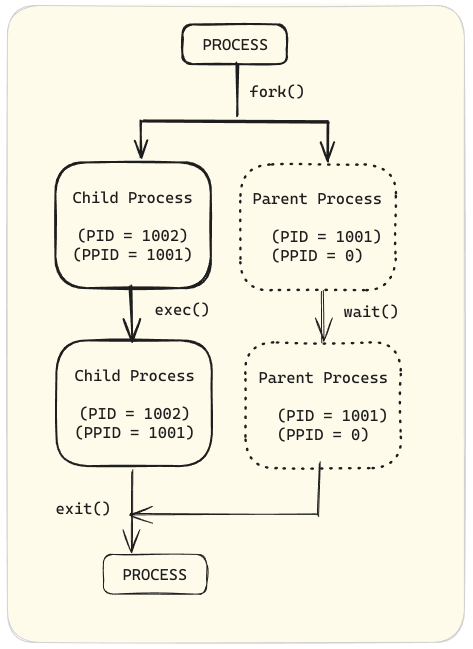
親 프로세스는 자신의 주소 공간을 복사하여 (forke) 새 (자식) 프로세스 구조를 생성합니다. 각 새 프로세스는 기록과 보안 목적에 사용되는 unique process ID (PID)를 갖습니다. PID와 親 프로세스 ID (PPID)는 새 프로세스 환경의 일부입니다. 어느 프로세스든지 자신의 자식 프로세스를 생성할 수 있습니다.
forke 루틴을 통해, 자식 프로세스는 보안 아이디, 이전과 현재 file descriptors, 포트 및 자원 권한, 环境变量, 프로그램 코드를 자신과 유사하게 받습니다. 그 다음, 자식 프로세스는 자신의 프로그램 코드를 실행할 수 있습니다.
typically, 親 프로세스는 자식 프로세스가 실행되는 동안 잠이 들어간다는 것을 기다리며, 자식이 완료되면 알려지는 것을 기대합니다.
자식 프로세스가 끝나면, 이미 자신의 자원과 环境을 닫아 버렸거나 丢弃했습니다. 그러나 가尸(zombie)라고 부르는 가장 마지막 자원은 프로세스 표에 기록되어 있습니다. 자식이 끝나면 清醒状态의 親 프로세스는 자식의 표에서 프로세스를 чист하고, 그렇게 자식 프로세스의 마지막 자원을 解放합니다. 그러고 다시 자신의 프로그램 코드를 실행합니다.
프로세스 상태를 이해하는 것은 …(省略)

Linux 시스템의 프로세스는 생명 周期 内에 다양한 상태로 이어지며, 프로세스의 상태는 현재 실행 중인 작업과 시스템과의 interaction을 나타내고 있다. 프로세스는 실행 상태와 시스템의 排队 算法에 따라 상태之间에 이전하며 이동한다.
| Linux 시스템의 프로세스는 다음과 같은 상태 중 하나로 있을 수 있다: | State |
| Description | (new) |
| fork 시스템 호출을 통해 프로세스를 생성할 때 초기 상태이다. | Runnable (ready) (R) |
| 실행 가능한 상태로 있고, CPU에 排队되어 있는 것을 wait하고 있다. | Running (user) (R) |
| 사용자 모드에서 실행되고 있는 프로세스이며, 사용자 응용 프로그램을 실행한다. | Running (kernel) (R) |
| kernel 모드에서 실행되고 있는 프로세스이며, 시스템 호출 또는 하드웨어 이터럽트를 처리한다. | Sleeping (S) |
| 이벤트(예: I/O operaion)가 완료되기를 wait하는 것을 의미하며, 쉽게 깨질 수 있다. | Sleeping (uninterruptible) (D) |
| 特定한 조건(通常是 I/O)가 완료되기를 wait하는 것을 의미하며, 이벤트를 기다리고 있다. | Sleeping (disk sleep) (K) |
| 디스크 I/O operaion이 완료되기를 wait하고 있다. | Sleeping (idle) (I) |
| 일어나고 있지 않고, 일어나는 것을 기다리고 있는 프로세스이다. | 중지 (T) |
| 프로세스 실행이 시그널로 일시정지되었고, 나중에 다시 시작 가능합니다. | zerosome (Z) |
프로세스가 실행이 완료되었지만 프로세스 테이블에 still 存在하고, 親 프로세스가 its exit status 를 읽을 때까지 기다리고 있습니다.
| 이러한 상태 사이를 이전 하는 것들이 이전 하는 것들이 다음과 같은 방법으로 이전 하는 것들입니다: | 전환 |
| 기술 | Fork |
| 親 프로세스에서 새로운 프로세스를 생성하며 (new)에서 Runnable (ready) (R)로 이전합니다. | 일정 |
| 일정자는 실행 가능한 프로세스를 선택하여 그것을 Running (user)이나 Running (kernel)상태로 이전합니다. | 실행 |
| 실행 가능한 프로세스(ready)(R)가 실행되도록 지정되면 Running (kernel)(R)로 이전합니다. | 이전 또는 재 일정 |
| 프로세스는 이전되거나 재 일정되어 다시 Runnable (ready)(R)상태로 이전합니다. | 시스템 호출 |
| 프로세스는 시스템 호출을 하며 Running (user)(R)에서 Running (kernel)(R)로 이전합니다. | 돌아가기 |
| 프로세스는 시스템 호출을 완료하고 Running (user)(R)로 돌아갑니다. | 기다리기 |
| 프로세스는 이벤트를 기다리기 때문에 Running (kernel)(R)에서 Sleeping 상태 (S, D, K, or I) 중 하나로 이전합니다. | 이벤트 또는 시그널 |
| 이벤트나 신호로 프로세스가 conscious 状态으로 wake up 되어, 眠状態から 실행 가능 (R) 状態로 돌아가는 것입니다. | Suspend |
| 프로세스가 정지되었습니다. 실행 중 (kernel) 또는 실행 가능 (ready) 상태에서 중지 상태 (T)로 전환합니다. | Resume |
| 프로세스가 재시작되었습니다. 중지 상태 (T)から 실행 가능 (ready) (R)로 돌아옵니다. | Exit |
| 프로세스가 종료되었습니다. 실행 중 (user) 또는 실행 중 (kernel) 상태에서 좀비 (Z) 상태로 전환합니다. | Reap |
親 프로세스는 좀비 프로세스의 退出 상태를 읽어, 프로세스 표에서 제거합니다.
프로세스 보기
zaira@zaira:~$ ps aux
Linux 시스템에서 프로세스를 보는 것은 ps 명령어를 사용하여 옵션의 조합과 함께 가능합니다. ps 명령어는 활성 프로세스 중 일부에 대한 정보를 표시하는 것을 도와줍니다. 예를 들어 ps aux 명령어는 시스템에서 실행 중인 모든 프로세스를 표시합니다.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Output
- 위의 출력은 시스템에서 실행 중인 프로세스의 멀티 사진을 보여줍니다. 各行은 다음 열들로 구성되어 있습니다 :
USER: 프로세스를 소유하는 사용자.PID: 프로세스 ID.%CPU: 프로세스의 CPU 사용률.%MEM: 프로세스의 메모리 사용량VSZ: 프로세스의 가상 메모리 크기RSS: 상주 세트 크기, 즉 작업이 사용한 스왑되지 않은 물리 메모리TTY: 프로세스의 제어 터미널.?는 제어 터미널이 없음을 나타냄
COMMAND: 프로세스를 시작한 명령어.
后台과 前台 프로세스
이 섹션에서, 后台나 前台에서 실행하여 일을 관리하는 方法을 배울 것입니다.
일은 쉘로 시작된 프로세스입니다. 터미널에서 명령어를 실행하면 그 것이 일이 되며, 일은 前台나 后台에서 실행할 수 있습니다.
- 관리를 보여주기 위해서는, 먼저 3개의 프로세스를 생성하고 그 다음에 后台에서 실행할 것입니다. 그 다음, 프로세스를 列出하고 他们を 前台과 后台之间에서 교换来 읽을 것입니다. 그들을 잠시 보호하거나 완전히 나가는 方法을 보여줄 것입니다.
tree 프로세스 생성
terminals를 열고 Tree 长得 실행하는 세 개의 長 running process를 시작합니다. sleep 명령어를 사용하여 지정한 초 수만큼 실행 중인 프로세스를 유지합니다.
sleep 300 &
sleep 400 &
sleep 500 &
# 300, 400, 500 초 동안 sleep 명령어를 실행
- 각 명령어의 末尾에
&를 사용하면 그 프로세스를 后台에 보냄니다.
background job 표시
jobs
background job의 목록을 표시하기 위해 jobs 명령어를 사용합니다.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- 출력은 이렇게 보일 수 있습니다:
background job을 foreground에 보냄
fg %1
background job을 foreground에 보냄fg 명령어를 사용하여 job 编号를 지정합니다. 예를 들어, 첫 번째 job(sleep 300)을 foreground에 보냄:
- 이 것은 job
1을 foreground에 보냄
foreground job을 다시 background에 보냄
실행 중인 작업을 앞으로 보이는 모드로 일시 중지하고 Ctrl+Z 키를 눌러 일시 중지한 작업을 뒷으로 보이는 모드로 이전할 수 있습니다.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
일시 중지된 작업은 다음과 같이 보입니다:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# 일시 중지된 작업
이제 bg 명령어를 사용하여 ID가 1인 작업을 뒷으로 보이는 모드로 이어 실행하십시오.
# Ctrl+Z 키를 눌러 앞으로 보이는 모드의 작업을 일시 중지하십시오.
bg %1
- # 그 다음, 뒷으로 보이는 모드로 이어 실행하십시오.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
작업 목록을 다시 보여줍니다
- 이 연습에서는 다음과 같은 작업을 실행합니다:
- sleep 명령어를 사용하여 세 つ의 뒷으로 보이는 작업을 시작했습니다.
- jobs 명령어를 사용하여 뒷으로 보이는 작업 목록을 보았습니다.
- fg %job_number 명령어를 사용하여 작업을 앞으로 보이는 모드로 이동하였습니다.
- Ctrl+Z 키를 눌러 일시 중지하고 bg %job_number 명령어를 사용하여 뒷으로 보이는 모드로 이전하였습니다.
jobs 명령어를 다시 사용하여 뒷으로 보이는 작업 상태를 확인했습니다.
이제 작업을 제어하는 方法을 알고 있습니다.
프로세스 sacrifice
불응하거나 원하지 않은 프로세스를 kill 명령어를 사용하여 종료할 수 있습니다. kill 명령어는 프로세스 ID에 신호를 보냅니다. 이는 그 프로세스를 종료하라고 요청합니다.
kill 명령어에는 여러 옵션이 available합니다.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# kill 명령어의 옵션
- 以下は Linux에서
kill명령어的一些例子 - 이 명령어는 PID 1234의 프로세스에 기본
SIGTERM신호를 보냅니다. 이는 그 프로세스를 종료하라고 요청합니다. - 이 명령어는 지정한 이름의 모든 프로세스에 기본
SIGTERM신호를 보냅니다. - 이 명령은 PID가 1234인 프로세스에
SIGKILL시그널을 보냅니다. 강제로 종료합니다. - 이 명령은 PID가 1234인 프로세스에
SIGSTOP시그널을 보냅니다. 중지합니다.
이 명령은 지정된 사용자가 소유한 모든 프로세스에 기본 SIGTERM 시그널을 보냅니다.
이 예시는 kill 명령어를 Linux 환경에서 프로세스 관리를 위해 다양한 방법을 사용하는 것을 보여줍니다.
下記은 kill 명령어의 옵션과 신호에 대한 정보입니다. 이 표는 kill 명령어의 가장 일반적인 옵션과 신호를 Linux에서 프로세스 관리를 위해 사용하는 것을 요약합니다. |
명령어 / 옵션 | 신호 |
| 説明 | kill |
SIGTERM |
| 기본 신호로 프로세스를 gracefully terminate 하는 것을 요청합니다. | kill -9 |
SIGKILL |
| puzzle process를 cleanup 없이 立ち上がり 즉시终止시킵니다. | kill -SIGKILL |
SIGKILL |
| puzzle process를 cleanup 없이 立ち上がり 즉시终止시킵니다. | kill -15 |
SIGTERM |
SIGTERM 신호를 명확하게 보내여 graceful termination을 요청합니다. |
kill -SIGTERM |
SIGTERM |
SIGTERM 신호를 명확하게 보내여 graceful termination을 요청합니다. |
kill -1 |
SIGHUP |
| ‘hang up’의 전통적인 의미; 구성 파일을 다시 로드하는 것을 사용할 수 있습니다. | kill -SIGHUP |
SIGHUP |
| 전통적으로 “耷 collocation”이며, 구성 파일을 다시 로드하는 데 사용 가능합니다. | kill -2 <pid> |
SIGINT |
프로세스를 종료하는 것을 요구합니다(终端에서 Ctrl+C 를 눌렀을 때와 같습니다). |
kill -SIGINT <pid> |
SIGINT |
프로세스를 종료하는 것을 요구합니다(终端에서 Ctrl+C 를 눌렀을 때와 같습니다). |
kill -3 <pid> |
SIGQUIT |
| 프로세스를 종료하고 디버깅 为目的로 코어 덤프를 생성합니다. | kill -SIGQUIT <pid> |
SIGQUIT |
| 프로세스를 종료하고 디버깅为目的로 코어 덤프를 생성합니다. | kill -19 <pid> |
SIGSTOP |
| 프로세스를 일시 정지합니다. | kill -SIGSTOP <pid> |
SIGSTOP |
| 프로세스를 일시 정지합니다. | kill -18 <pid> |
SIGCONT |
| 일시 정지 상태의 프로세스를 다시 시작합니다. | kill -SIGCONT <pid> |
SIGCONT |
| 일시 정지 상태의 프로세스를 다시 시작합니다. | killall <name> |
의 의미가 다양합니다. |
| given name의 모든 프로세스에 신호를 보냅니다. | killall -9 <name> |
SIGKILL |
| 주어진 이름과 일치하는 모든 프로세스를 강제로 종료합니다. | pkill <pattern> |
다양합니다 |
| 패턴 일치에 따라 프로세스에 신호를 보냅니다. | pkill -9 <pattern> |
SIGKILL |
| 패턴과 일치하는 모든 프로세스를 강제로 종료합니다. | xkill |
SIGKILL |
윈도우를 클릭하여 해당 프로세스를 종료하는 그래픽 유틸리티입니다.
8.5. 리눅스의 표준 입력 및 출력 스트림
- 입력을 읽고 출력을 작성하는 것은 명령 줄과 셸 스크립팅을 이해하는 데 필수적인 부분입니다. 리눅스에서는 각 프로세스가 세 개의 기본 스트림을 가지고 있습니다:
-
stdin의 파일 디스크립터는0입니다. - 표준 출력(
stdout): 프로세스가 출력을 쓰는 기본 输出流转输ream입니다. 기본적으로 표준 출력은 终端(terminal)입니다. 출력은 또한 파일로 또는 다른 프로그램에 rerirected할 수 있습니다.stdout의 파일 描述符(file descriptor)는1입니다.
표준 오류(stderr): 이 기본 오류 输出流转输ream에서 프로세스가 오류 메시지를 쓰고 있습니다. 기본적으로 표준 오류는 终端(terminal)입니다. stdout가 redirected되었다고 해도 오류 메시지를 볼 수 있습니다. stderr의 파일 描述符(file descriptor)는 2입니다.
Redirection and Pipelines
Redirection: 오류와 출력 流转输ream을 파일로 또는 다른 명령에 redirect할 수 있습니다. 例如:
ls > output.txt
# stdout를 파일로 redirect
ls non_existent_directory 2> error.txt
# stderr를 파일로 redirect
ls non_existent_directory > all_output.txt 2>&1
# stdout과 stderr를 모두 同一个 file로 redirect
- 在上一个 명령어에서,
ls non_existent_directory: non_existent_directory라는 디렉토리의 내용을 나열합니다. 이 디렉토리가 존재하지 않기 때문에ls는 오류 메시지를 생성합니다.> all_output.txt:>연산자는ls명령의 표준 출력(stdout)을 파일all_output.txt로 리다이렉트합니다. 파일이 없으면 생성됩니다. 파일이 이미 존재하면 내용이 덮어씌워집니다.
2>&1:: 여기서 2는 표준 에러(stderr)의 파일 기술자를 나타냅니다. &1은 표준 출력(stdout)의 파일 기술자를 나타냅니다. & 문자는 1이 파일 이름이 아닌 파일 기술자임을 지정하는 데 사용됩니다.
所以, 2>&1는 “stderr (2)를 stdout (1)가 현재 어디에 가는지 리다이렉트”하는 것을 의미한다. 그렇다면, 이 경우 all_output.txt 파일이 그 곳이 된다. 따라서, ls의 stdout (표준 출력)과 에러 메시지가 모두 all_output.txt에 기록된다.
Pipelines:
ls | grep image
pipe (|)를 사용하여 하나의 명령의 출력을 다른 명령의 입력으로 전달할 수 있다.
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Output
8.6 Linux에서의 자동화 – Cron 作业에 의한 任务 자동化
Cron은 Unix-like 오픈 시스템에서 사용할 수 있는 강력한 일정 작업 스케쥴러로, cron를 사용하여 일일, 週주, 월간, 또는 다른 specific time basis에 자동적으로 실행할 수 있는 작업을 설정할 수 있다. cron로 제공되는 자동화 기능은 Linux 시스템 관리에서 중요한 rolls를 한다.
crond 데몬(백그라운드에서 실행되는 컴퓨터 프로그램)가 cron 기능을 가능하게 한다. cron은 미리 정의된 스크립트를 실행하기 위한 crontab(cron 표)을 읽는다.
特定的한 문법을 사용하여 cron 작업을 자동적으로 실행할 스크립트나 다른 명령을 计划할 수 있다.
Linux의 cron jobs는 무엇인가?
cron을 사용하여 计划한 모든 작업은 cron jobs라고 불린다.
이제 cron jobs가 어떻게 작동하는지 보자.
cron jobs에 대한 접근 제어
cron jobs를 사용하려면, 관리자가 /etc/cron.allow 파일에 사용자에게 cron jobs를 추가하도록 허용해야 한다.
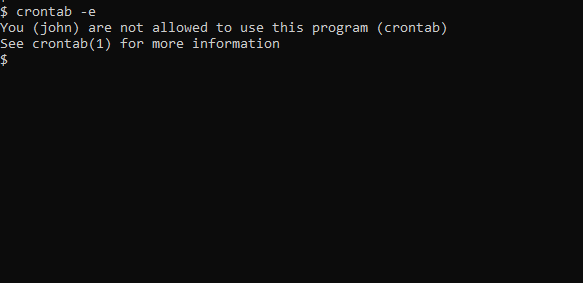
알림이 이런식으로 나타나면, cron을 사용할 권한이 없음을 의미합니다.
![]()
John이 cron을 사용할 수 있도록 하려면, /etc/cron.allow 파일에 그의 이름을 포함시키세요. 파일이 없다면 생성하십시오. 이렇게 하면 John은 cron 작업을 생성하고 편집할 수 있게 됩니다.
사용자는 /etc/cron.d/cron.deny 파일에 그들의 사용자 이름을 입력하여 cron 작업 액세스를 거부할 수도 있습니다.
Linux에서 cron 작업을 추가하는 방법
첫째로, cron 작업을 사용하려면 cron 서비스의 상태를 확인해야 합니다. cron이 설치되어 있지 않다면, 패키지 관리자를 통해 쉽게 다운로드할 수 있습니다. 다음을 사용하여 확인하십시오:
sudo systemctl status cron.service
# Linux 시스템에서 cron 서비스 확인
cron 작업 문법
- cronTabs에서 cron 작업을 추가하고 나열하기 위해 다음과 같은 플래그를 사용합니다:
crontab -e: cron 작업을 추가, 삭제, 편집하기 위해 crontab 항목 편집crontab -l: 현재 사용자의 모든 cron 작업을 나열crontab -u 사용자이름 -l: 다른 사용자의 cron을 나열
crontab -u 사용자이름 -e: 다른 사용자의 cron을 편집
cron을 나열하고 있다면, 존재할 경우 다음과 같은 내용을 볼 수 있습니다:
* * * * * sh /path/to/script.sh
# Cron job 예시
- 上面的 예시에서,
*는 분(들), 시(들), 일(들), 달(들), 주(들)의 의미를 가지며, 각각 분, 시, 일, 달, 주를 나타냅니다. 이러한 값들의 자세한 내용은 下述을 참조하십시오.: |
값 | |
| 설명 | 분 | 0-59 |
| 특정 분에 명령어를 실행합니다. | 시 | 0-23 |
| 특정 시에 명령어를 실행합니다. | 일 | 1-31 |
| 이 달의 이러한 일에 명령어를 실행합니다. | 달 | 1-12 |
| 실행해야 하는 일의 달을 나타냅니다. | 주 | 0-6 |
- 명령어가 실행되는 주요 일을 나타냅니다. 여기서, 0는 일요일입니다.
sh는 스크립트가 bash 스크립트이며/bin/bash에서 실행되야 하는 것을 의미합니다.
/path/to/script.sh는 스크립트의 경로를 지정합니다.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
下述은 cron job 구문의 요약입니다:
Cron job 예시
| 下述은 cron job을 计划하는 一些 예시입니다. | 일정 |
| 일정 값 | 5 0 * 8 * |
| 8월 00:05에. | 5 4 * * 6 |
| 토요일 04:05에. | 0 22 * * 1-5 |
월요일부터 금요일까지 매일 22:00에.
일단 한 번에 이 모든 것을 이해하지 못해도 괜찮습니다. 크론탭 구루 웹사이트를 통해 연습하고 cron 일정을 생성할 수 있습니다.
cron 작업 설정 방법
- 이 섹션에서는 cron 작업을 사용하여 간단한 스크립트를 예약하는 예제를 살펴보겠습니다.
#!/bin/bash
echo `date` >> date-out.txt
시스템 날짜와 시간을 출력하고 파일에 추가하는 date-script.sh라는 스크립트를 만듭니다. 아래에 스크립트가 표시되어 있습니다:
chmod 775 date-script.sh
2. 실행 권한을 부여하여 스크립트를 실행 가능하게 만듭니다.
3. crontab -e를 사용하여 crontab에 스크립트를 추가합니다.
*/1 * * * * /bin/sh /root/date-script.sh
여기서 우리는 분 단위로 실행되도록 예약했습니다.
cat date-out.txt
4. date-out.txt 파일의 출력을 확인합니다. 스크립트에 따르면 시스템 날짜가 이 파일에 매 분마다 출력되어야 합니다.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# 출력
cron 문제 해결 방법
cron은 정말 유용하지만 항상 의도대로 작동하지는 않을 수 있습니다. 다행히도 문제 해결할 수 있는 효과적인 방법이 있습니다.
1. 일정을 확인합니다.
먼저, cron에 설정된 일정을 확인해 볼 수 있습니다. 위 섹션에서 본 구문을 사용하여 확인할 수 있습니다.
2. cron 로그 확인하기.
우선 cron이 지정된 시간에 실행되었는지 확인해야 합니다. Ubuntu에서는 /var/log/syslog에 있는 cron 로그로 이를 확인할 수 있습니다.
정확한 시간에 이 로그에 항목이 있으면, cron이 설정한 스케줄에 따라 실행되었음을 의미합니다.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
아래는 우리 cron 작업 예제의 로그입니다. 첫 번째 열의 타임스탬프를 참고하세요. 스크립트의 경로는 줄의 끝에 언급되어 있습니다. 라인 #1, 3, 5는 스크립트가 예상대로 실행되었음을 보여줍니다.
3. cron 출력을 파일로 리디렉션하다.
cron의 출력을 파일로 리디렉션하고 파일을 검사하여 가능한 오류를 찾을 수 있습니다.
* * * * * sh /path/to/script.sh &> log_file.log
# cron 출력을 파일로 리디렉션
8.7. 리눅스 네트워킹 기본
리눅스는 네트워크 관련 정보를 보는 여러 명령어를 제공합니다. 이 섹션에서는 몇 가지 명령어를 간단하게 다룰 것입니다.
ifconfig로 네트워크 인터페이스 보기
ifconfig
ifconfig 명령어는 네트워크 인터페이스에 대한 정보를 제공합니다. 다음은 예제 출력입니다:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 출력
ifconfig 명령어의 출력은 시스템에 설정된 네트워크 인터페이스와 IP 주소, MAC 주소, 패킷 통계 등의 자세한 정보를 보여줍니다.
이러한 인터페이스는 물리적인 장치나 가상 장치일 수 있습니다.
IPv4와 IPv6 주소를 추출하려면 각각 ip -4 addr와 ip -6 addr를 사용할 수 있습니다.
네트워크 활동을 보려면netstat
`netstat` 명령은 다음과 같은 정보를 제공하여 네트워크 활동과 통계를 보여줍니다.:
- 다음은 COMMAND LINE에서 `netstat` 명령의 사용 예이다:
- 모든 듣는과 듣지 않는 소켓을 표시합니다:
- 듣는 포트만 보기:
- 네트워크 통계 보기:
- 경로 테이블 보기:
- TCP 연결 표시:
- UDP 연결 표시:
- 네트워크 인터페이스 보기:
- 연결에 대한 PID 및 프로그램 이름 표시:
- 특정 프로토콜(예: TCP)의 통계 정보 보기:
extended information 표시:
두 장치 사이의 네트워크 연결 상태를 ping 이용하여 확인하는 것을 시도하십시오.
ping google.com
ping
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping 명령은 두 장치 사이의 네트워크 연결 가능性을 테스트하는 데 사용되며, 목적地的에 ICMP 패킷을 보내고 응답을 기다립니다.
ping 명령은 시간 경과 없이 응답을 얻을 수 있는지 여부를 시험합니다.— google.com ping 통계 —
Ctrl + C 快捷键로 응답을 중지할 수 있습니다.
curl 명령어로 端点 테스트
curl명령어는 “client URL”의 缩写으로, 서버와 데이터 교환을 위해 사용되며, API 端点 테스트를 통해 시스템과 응용 에러의 해결을 도울 수 있습니다.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- 예를 들어
http://www.official-joke-api.appspot.com/를 사용하여curl명령어를 실험할 수 있습니다.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
curl 명령어에 옵션이 없으면 기본적으로 GET 방식을 사용합니다.
curl -o명령어는 지정한 파일에 출력을 저장합니다.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# 이것은 output을 random_joke.json 파일에 저장합니다.
curl -I 명령어는 仅仅是 헤더를 가져옵니다.
8.8 리눅스 문제 해결: 도구와 기술
`sar`로 시스템 활동 보고
리눅스에서 `sar` 명령어는 시스템 활동 정보를 수집, 보고, 및 저장하는 強力한 도구입니다. 이것은 `sysstat` パッケージ의 일부입니다. 시간이 지나면서 시스템 パフォーマンス를 모니터링하는 데 널리 사용되는 것입니다.
`sar`를 사용하기 전에 `sysstat`를 설치하려면 `sudo apt install sysstat`를 사용하여 시스템stat을 설치해야 합니다.
설치가 완료되면, 서비스를 `sudo systemctl start sysstat`로 시작합니다.
상태를 `sudo systemctl status sysstat`로 확인합니다.
sar [options] [interval] [count]
상태가 활성화되면, 시스템은 다양한 통계 정보를 수집하게 되며, 이를 이용하여 이전 데이터를 접근하고 분석할 수 있습니다. 자세한 내용을 見てみましょう.
sar -u 1 3
`sar` 명령어의 문법은 다음과 같습니다:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
예를 들어 `sar -u 1 3`는 3회 동안 每一秒 CPU utilization 통계를 보여줍니다.
# 출력
이러한 일반적인 사용 사례와 `sar` 명령어를 사용하는 방법을 몇 가지 예를 들어 보여드릴 것입니다.
`sar`는 다양한 목적에 사용할 수 있습니다:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. 메모리 사용
메모리 사용(사용중, 사용 안 중)을 확인하는 것을 사용하려면:
이 명령어는 3회 동안 每一秒 메모리 통계를 보여줍니다.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. 스왑 공간 사용
스왑 공간 사용 통계를 보기 위해서는 다음을 사용하세요:
이 명령은 phyisical memory를 초과하고 있는 시스템에서 중요한 swap 사용을 모니터링하는 데 도울 수 있습니다.
sar -d 1 3
3. I/O 장치 로드
블록 장치 및 블록 장치 파티션의 활동 보고를 위해 :
이 명령은 블록 장치로부터 데이터 이전 정보를 자세하게 제공하며, I/O 밸런스 문제 diagnostics를 도울 수 있습니다.
sar -n DEV 1 3
5. 네트워크 통계
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
네트워크 인터페이스로부터 수신(전송) 됨의 패킷 수를 보기 위한 네트워크 통계를 보려면 :
# -n DEV는 sar가 네트워크 장치 인터페이스를 보고하도록 하는 것을 의미합니다.
이것은 네트워크 통로를 모니터링하는 데 tre 초에 한번씩 네트워크 통계를 표시합니다.
- 6. 이력 데이터
- # “true”와 “false”입니다. 다른 값을 입력하지 마십시오, 그들
- 데이터 수집 간격을 설정하십시오: cron 일정을 편집하여 데이터 수집 간격을 지정합니다.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
<DD>를 보고자 하는 달의 날짜로 替え십시오.
아래 명령어에서, /var/log/sysstat/sa04는 현재 달의 第四天の統計量を제공합니다.
sar -I SUM 1 3
7. 실시간 CPU 중지
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
CPU가 하루 동안 하나의 秒에 어떻게 중지를 처리하는지 보기 위해 이 명령어를 사용합니다:
# 输出
이 명령어는 CPU가 중지를 어떻게 자주 처리하는지 모니터링하는 것이 중요한지 실시간 성능 조정에 도움이 됩니다.
이 문서는 sar를 사용하여 시스템 성능의 여러方面를 모니터링하는 방법을 보여주는 예제입니다. sar의 정기적인 사용은 시스템의瓶颈을 식별하고 응용 프로그램이 효율적으로 실행되도록 하는 데 도움이 됩니다.
8.9. 서버 일반 문제 해결 전략
모니터링을 이해하는 이유는 무엇인가요?
시스템 모니터링은 시스템 관리의 중요한方面입니다. 중요한 응용 프로그램은 실패를 방지하고 중단 시간의 영향을 줄이기 위해 고도의 프로актив함을 요구합니다.
리눅스는 시스템 상태를 측정하는데 매우 강력한 도구를 제공합니다. 이 섹션에서는 시스템의 건강 상태를 점검하고瓶颈을 식별하는 데 사용할 수 있는 다양한 방법을 배울 것입니다.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
로드 average와 시스템 uptime 찾기
시스템 재부팅이 발생할 수 있으며 때로는 일부 구성을 꼬인 경우가 있습니다. 머신이 얼마나 오래 실행되고 있는지 확인하려면 uptime 명령을 사용하십시오. uptime에 더해 명령은 로드 average도 표시합니다.
로드 average는 지난 1분, 5분, 15분 동안의 시스템 로드입니다. 빠른 살펴보기는 시스템 로드가 시간이 지남에 따라 증가하고 감소하는지 여부를 나타냅니다.
노트:理想的 CPU 대기열은 0입니다. 이는 CPU 대기열이 없을 때만 가능합니다.
lscpu
개별 CPU 로드는 로드 average를 사용 가능한 CPU의 총 수로 나누어 계산할 수 있습니다.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
CPU 수를 찾으려면 lscpu 명령을 사용하십시오.
# 출력
로드 평균이 상승하고 내리지 않는다면, CPU는 과부하 상태입니다. 멈춰있는 프로세스가 있거나 메모리 누수가 발생하고 있을 수 있습니다.
free -mh
自由的 메모리를 계산하는 것
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
때때로 높은 메모리 utilization이 문제를 일으키는 것이 있습니다. 사용 가능한 메모리와 사용 중인 메모리를 확인하기 위해 free 명령을 사용하십시오.
# output
디스크 공간을 계산하는 것
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
시스템이 healthy하게 running되는지 확인하기 위해서는 디스크 공간을 잊지 마십시오. 모든 사용 가능한 마운트 포인트와 그들의 相應한 사용 률을 리스트로 표시하기 위해 아래 명령어를 사용합니다. 理想的하게, 사용 중인 디스크 공간의 사용률은 80%를 넘을 수 없습니다.
df 명령어는 디스크 공간의 상세 정보를 제공합니다.
프로세스 상태를 결정하는 것
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
멈춰있는 프로세스가 있는지 高い 메모리 또는 CPU 사용률을 보기 위해 프로세스 상태를 모니터링할 수 있습니다.
이전에 우리는 ps 명령어가 프로세스에 대한 有用한 정보를 제공하는 것을 보았습니다. CPU와 MEM 열을 보십시오.
실시간 시스템 모니터링
실시간 시스템 상태를 보는 widow를 제공하는 것
이를 실시간으로 하기 위해 사용할 수 있는 하나의 도구가 top 명령어입니다.
top 명령어는 시스템의 프로세스에 대한 동적인 보기를 보여줍니다. 정리 헤더를 표시하고 그 다음에 프로세스 또는 스레드 목록을 표시합니다. static의 反义의 ps와 differ로 top은 시스템 통계를 계속 갱신합니다.
top 명령어를 사용하면 좁은 창에서 잘 organised되어 있는 详しい 정보를 보실 수 있습니다. top와 함께 flags, 단축키, 및 하이라이팅 方法 등의 많은 기능을 사용할 수 있습니다.
top을 사용하여 프로세스를 강제 종료할 수 있습니다. 이를 위해 k キー를 눌러 프로세스 ID를 입력하십시오.
로그 해석
시스템과 응용 로그는 시스템이 어떻게 동작하는지에 대한 많은 정보를 포함합니다. 이들은 유용한 정보와 에러 코드를 포함하며 에러를 인식하는 데에 도움이 됩니다. 로그에서 에러 코드를 찾으면 이슈 인식과 수정 시간이 크게 줄어들 수 있습니다.
네트워크 포트 분석
네트워크 문제는 자주 발생하며 시스템과 트래픽 흐름에 영향을 미칠 수 있으며, 포트 사용 완화, 포트 strangulation, 해제되지 않은 자원 등이 일어날 수 있습니다.
| 이러한 이슈를 식별하기 위해서는 포트 상태를 이해하는 것이 중요합니다. | 하나의 포트 상태에 대해 簡単히 설명해드릴 수 있습니다. |
| 상태 | 설명 |
| LISTEN | 어떤 remote TCP와 포트에 연결 요청을 기다리고 있는 포트를 나타냅니다. |
| ESTABLISHED | 열린 연결이며 데이터가 도착하면 목적지에 도착할 수 있는 데이터를 보냅니다. |
| TIME WAIT | 자신의 연결 종료 요청의 인가를 기다리는 시간을 나타냅니다. |
FIN WAIT2
remote TCPから 연결 종료 요청을 기다리는 것을 나타냅니다.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Linux에서 포트 관련 정보를 어떻게 분석할 수 있는지 lets explore how we can analyze port-related information in Linux.
Port ranges: 시스템에서 포트 rage는 정의되어 있으며, rage가 상대적으로 증가/감소할 수 있습니다. 아래 샘플에서는 15000에서 65000까지의 rage로 총 50000(65000 – 15000)개의 사용 가능한 포트가 있다고 합니다. 사용 중인 포트가 이러한 한계를 넘어가는 것이나 이를 초과하는 것을 확인할 수 있습니다.
이러한 경우 로그에서 보고되는 에러는 Failed to bind to port나 Too many connections입니다.
패킷 잃어 went Identifying
시스템 모니터링에서는 outgoing 및 incoming 통신이 제대로 되어 있는지 확인해야 합니다.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
도움이 되는 명령어로 ping가 있습니다. ping는 목적지 시스템을 찍고 응답을 돌려줍니다. 통계 정보의 마지막 몇 行을 보면 패킷 잃어 went 비율과 시간을 note 합니다.
# ping destination IP
runtime에서 패킷을 캡쳐하는 것도 tcpdump를 사용할 수 있습니다. 稍后我们再 look into it.
issue post mortem을 위한 통계 정보 수집
- 이러한 통계 정보를 이후에 root cause를 identifier로 사용할 수 있도록 수집하는 것은 항상 좋은 惯例입니다. 시스템을 reboot 하거나 서비스를 restart 하면 이전 시스템 스냅샷과 로그를 잃게 되는 것이 일어나ます.
아래는 시스템 스냅샷을 캡쳐할 수 있는 몇 가지 方法입니다.
- Logs Backup
변경 사항을 추가하기 전에 로그 파일을 다른 위치로 복사하십시오. 이것은 문제 발생 시간에 시스템이 어떤 상태였는지 이해하는 것이 중요합니다. 로그 파일은 다른 runtime 통계가 잃어 가는 것보다 과거 시스템 상태를 보는 唯一的 수단입니다.
sudo tcpdump -i any -w
TCP Dump
TCP Dump은 들어오는 및 나가는 네트워크 트래픽을 CAPTURE하고 분석 할 수 있는 명령어 行 유틸리티입니다. 그들은 대부분 네트워크 문제 해결에 사용되며, 시스템 트래픽이 영향을 받고 있다고 느꼈다면 다음과 같이 tcpdump을 采取 할 수 있습니다 :
# 어디에서,
# -i any 모든 인터페이스의 트래픽을 수집
# -w 이름의 출력 ファイル명을 지정
# 몇 분 후에 명령어를 중지하십시오. 파일 크기가 커지기 때문입니다.
# 파일 확장자를 .pcap로 사용
一旦 tcpdump이 采取 되면, Wireshark과 같은 도구를 사용하여 시각적으로 트래픽을 분석 할 수 있습니다.
결론
本书을 끝까지 읽으시려면 감사합니다. 도움이 되었다면, 다른 사람들과 공유하고 싶으신 것 같으면
이 本书은 여기서 끝나지 않습니다. 未来 에는 계속해서 改善 하고 새로운 자료를 추가 하기 때문입니다. 문제가 있다고 느꼈거나 改善 의 제안이 필요하다고 생각하시면 PR/Issue를 개시해 주십시오.
- 연결을 유지하고 학습 여행을 계속 하세요!
-
LinkedIn: 기술에 관한 기사와 포스트를 여기서 공유합니다. LinkedIn에서 추천을 남겨주시고 관련 기술에 대해 나를 지지해 주세요.
독점 콘텐츠에 접근하기: 일대일 도움과 독점 콘텐츠를 위해서는 여기를 클릭하세요.
독점 콘텐츠에 접근하기: 일대일 도움과 독점 콘텐츠를 위해서는 여기를 클릭하세요.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/