













디지털 변형 時代에는 스케일ability과 신뢰성을 제공하는 데이터베이스 솔루션이 기업의 필요입니다. AWS Aurora, MySQL와 PostgreSQL를 지원하는 관계型 데이터베이스로서, 고성능, 신뢰성, 가격 효율성을 seek하는 기업들의 인기 있는 选题이 되었습니다. 이 글에서는 AWS Aurora의 이점을 探究하고, 실제 cases에서 온라인 소셜 미디어 latform에서 어떻게 사용되는지 예를 들어 보여 드리ます.
AWS Aurora 比較: 이점 vs. 도전
| Key Benefits | Description | Challenges | Description |
|---|---|---|---|
| High Performance and Scalability |
Aurora의 설계는 스토리지와 처리 기능을 분리하여 MySQL보다 cinque 배, PostgreSQL보다 두 배의 帯宽을 제공합니다. 자동 스케일링 기능을 사용하여 فーク 트로ffic 기간에서도 일관성있는 パフォーマン스를 보장합니다. |
Financial Implications | The complex pricing structure can lead to high costs due to charges for instance, storage, replicas, and support. |
| Durability and Availability | Data in Aurora is distributed across multiple Availability Zones (AZs), with six copies stored across three AZs to ensure data availability and resilience. Failover mechanisms are automated to facilitate durable writes, incorporating retry logic for transactional integrity. | Dependency Risks | A significant dependence on AWS services may lead to vendor lock-in, making it more challenging and costly to migrate to alternative platforms in the future. |
| Security | Aurora offers robust security with encryption for data at rest and in transit, network isolation via Amazon VPC, and precise access control through AWS IAM. | Migration Challenges | Data transfer can be lengthy and may involve downtime. Compatibility issues might require modifications to existing code. |
| Cost Efficiency | Aurora’s flexible pricing structure enables businesses to reduce database costs. The automatic scaling feature guarantees that you are charged based on the actual resources utilized, resulting in a cost-effective solution for varying workloads. | Training Requirements | Teams need to dedicate a significant amount of time and resources to acquiring the necessary knowledge of AWS-specific tools and optimal practices to effectively manage Aurora. |
| Performance Optimization | Auto-scaling and read replicas help optimize performance by dynamically adjusting resources and distributing read traffic. | Performance Impacts | Latency may be introduced due to abstraction layers and networking between Aurora instances and other AWS services, impacting latency-sensitive applications. |
IMPLEMENTATION 步驟
1. Aurora cluuster 설정
- AWS 관리 콘SOLE로 이동하세요.
- Amazon Aurora를 선택하고 “Create Database”를 클릭하세요.
- 적절한 엔진(MySQL 또는 PostgreSQL)을 선택하고 인스턴스 설정을 구성하세요.
2. Auto Scaling 사용
- 처리와 스토리지 대한 자동 스케일링 정책을 구성하세요.
- 트로ffic 패턴에 따라 スケール 인 아웃 기준을 설정하세요.
3. Multi-AZ Deployment 구성
- 高可用性을 보장하기 위해 Multi-AZ 배치를 사용하세요.
- 자동 备份과 스냅샷을 설정하여 데이터 보호를 실시하세요.
4. 읽기 副本 생성
- 읽기 트래픽을 분산시키기 위해 副本을 추가합니다.
- 응용 엔드포인트를 구성하여 副本之间에 읽기 요청을 平衡시키십시오.
작동 예: 온라인 소셜 미디어 플랫폼
온라인 소셜 미디어 플랫폼 “SocialBuzz”는 전 세계 수백만 명의 사용자를 연결합니다. 높은 트rafik 용량을 처리하고, 저 latency 응답을 제공하고, 데이터 aueracity를 보장하기 위해 신뢰할 수 있는 데이터 베이스 솔루션을 필요로 합니다. AWS Aurora는 이러한 需要을 충족시키는 가장 적절한 선택입니다:
- 아키텍처 개요: SocialBuzz는 Aurora를 自己的力量 데이터 베이스 需要에 사용하고, MySQL과 PostgreSQL 엔진을 diffrent 컴포넌트에 적용합니다. 사용자 프로필, 게시물, 댓글, 및 인터랙션은 Aurora에 저장되어, 其의 высокой 성능과 스케일ability로 受益합니다.
- 스케일ability 行动: 하락 사용 시간에, 예를 들어 virial 게시물이 공유되는 것과 같은, SocialBuzz는 트래픽이 많아지는 것을 经验하고, Aurora의 자동 스케일링 기능은 이 증가한 부하를 처리하기 위한 computation 자원을 조정하여, 성능 저하가 없이 유저 경험을 seamless 하게 하는 것입니다.
- 高可用性: 서비스를 중단되지 않도록 SocialBuzz는 Aurora를 Multi-AZ 조치로 구성하고, 이를 통해 하나의 AZ가 문제를 겪도록 하든지 데이터베이스가 사용할 수 있게 하고, robust 한 도입 전략을 제공합니다. Aurora의 자동 备份과 캡챠는 데이터 보호를 더욱 강화시키ます.
- 성능 최적화: 소셜버즈는 오로라에서 읽기 복제본을 구현하여 읽기 트래픽을 분산함으로써 기본 인스턴스의 부하를 줄입니다. 이 설정은 빠른 데이터 검색을 가능하게 하여 실시간 알림 및 즉각적인 게시물 업데이트와 같은 기능을 지원합니다.
- 비용 관리: SocialBuzz는 Aurora의 종량제 모델을 활용하여 운영 비용을 효과적으로 관리하고 있습니다. 사용량이 적은 시간대에는 리소스를 축소하여 비용을 절감합니다. 또한, Aurora의 서버리스 옵션을 사용하면 리소스를 과도하게 프로비저닝하지 않고도 예측 불가능한 워크로드를 처리할 수 있습니다.
개요
온라인 소셜 미디어 플랫폼인 SocialBuzz가 확장 가능하고 안정적인 데이터베이스 관리를 위해 AWS Aurora를 활용하는 방법을 자세히 살펴봅시다. 구현을 위한 코드 예제, 샘플 데이터 세트, 프로세스를 설명하기 위한 흐름도가 포함되어 있습니다.
아키텍처 개요
SocialBuzz는 사용자 프로필, 게시물, 댓글, 상호작용의 저장과 관리를 위해 AWS Aurora를 활용하고 있습니다. 시스템 아키텍처는 다음과 같은 요소로 구성됩니다:
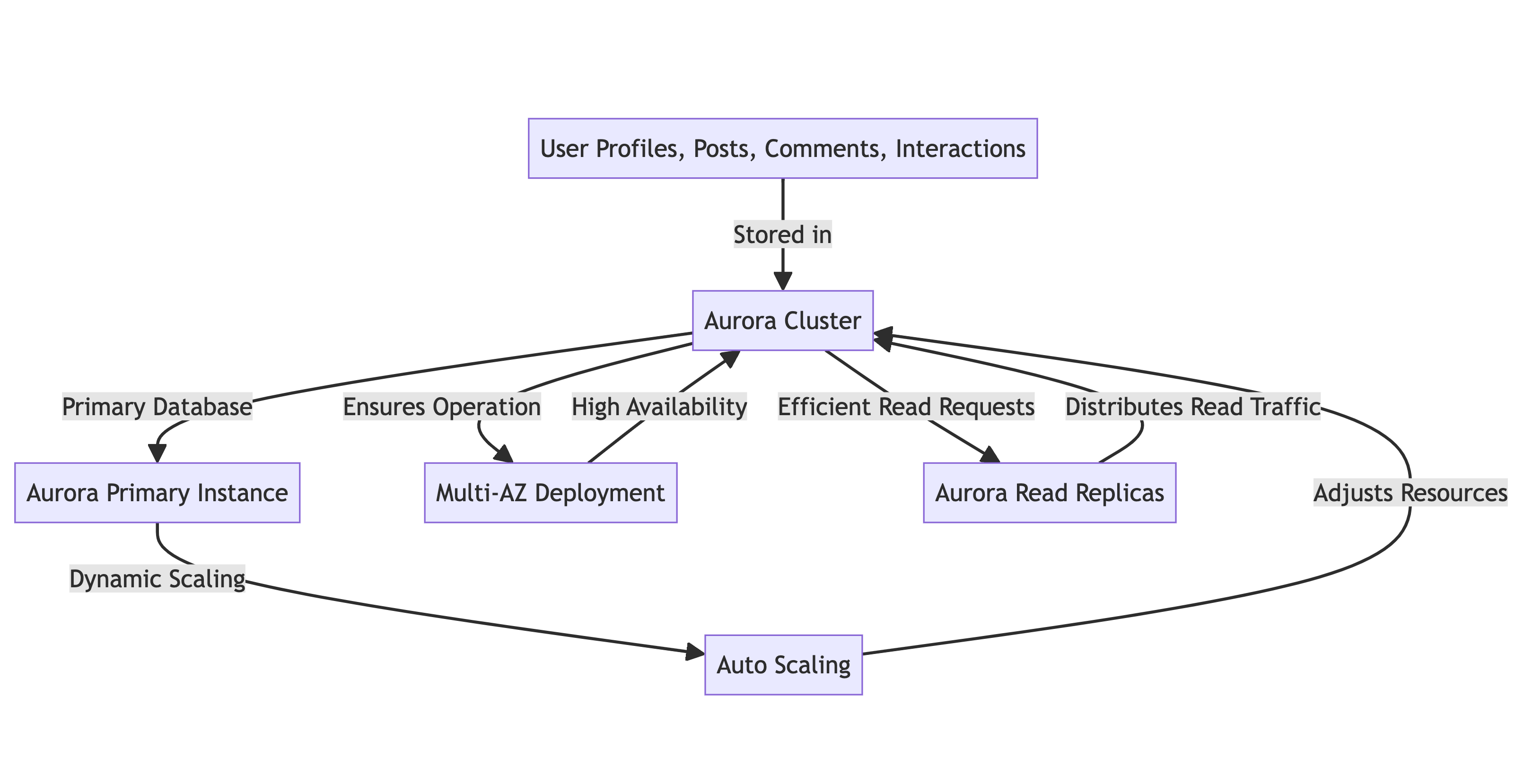
- 기본 데이터베이스: Aurora 클러스터
- 리소스 조정: 수요에 따라 리소스를 동적으로 확장하는 자동 확장 기능
- 고가용성: 지속적인 운영을 보장하기 위한 다중 AZ 배포
- 읽기 트래픽 분배: 읽기 요청의 효율적인 분배를 위한 읽기 복제본
흐름 다이어그램
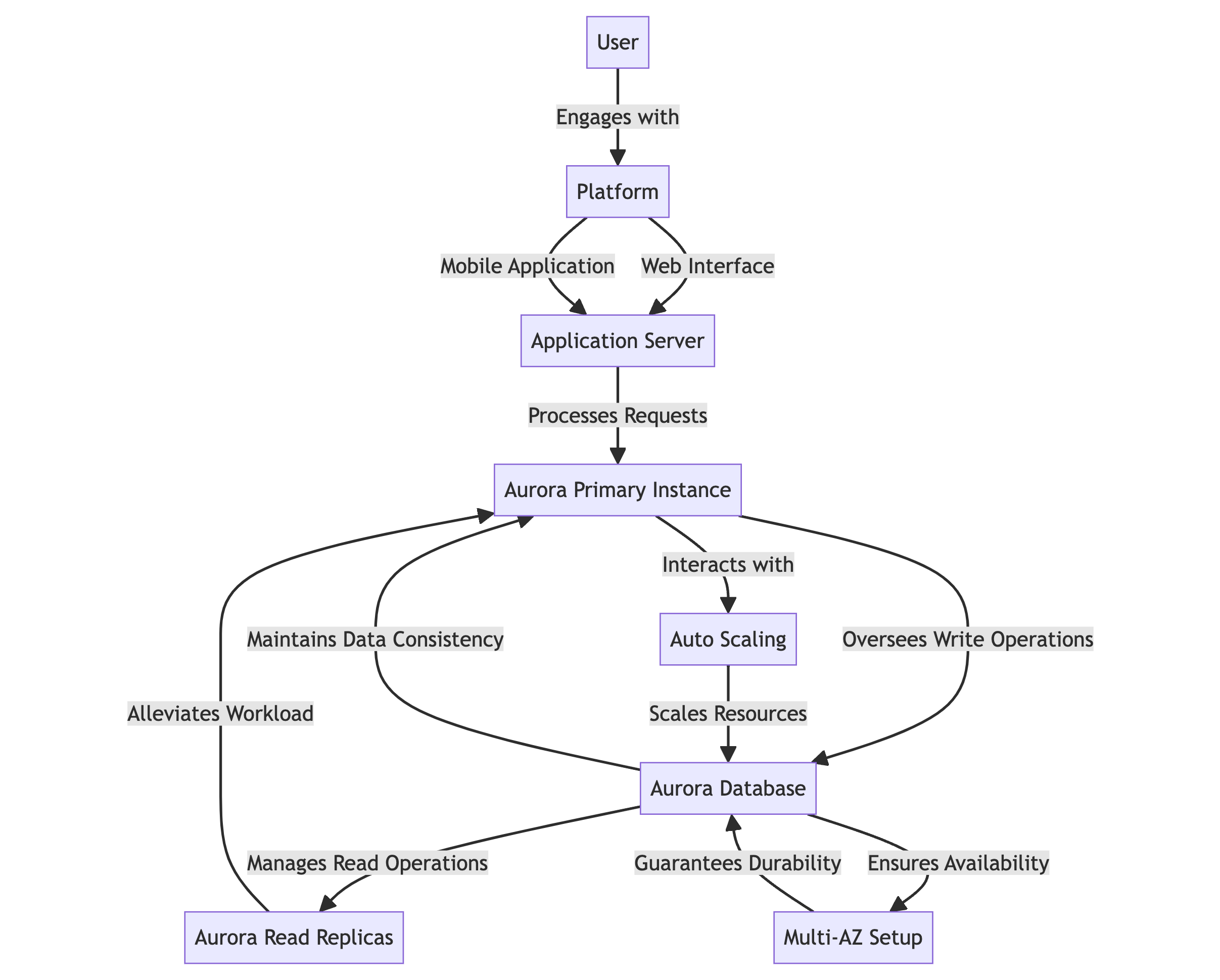
- 사용자는 웹 인터페이스 또는 모바일 应用程序을 통해 platforms에 대한 interaction을 사용합니다.
- The application server는 요청을 처리하고 Aurora database와 인teraction을 수행합니다.
- Aurora Primary Instance는 쓰기 操作을 관리하고 데이터 일관성을 유지합니다.
- Aurora Read Replicas는 읽기 操作을 관리하여 주요 인스턴스의 일정을 완화합니다.
- Autoscaling은 트래픽 수준의 변화에 따라 자원을 자동으로 확장합니다.
- Multi-AZ 세팅은 multi Availability zones 를 사용하여 데이터 가용성과 鲁鱼亥豕를 보장합니다.
AWS Instance
- Standard을 사용하여 Aurora (MySQL)를 생성합니다.

- 템플릿, 인증 정보, DB 이름 설정을 선택합니다.
- 인스턴스 構성, 가용성, 연결성은 중요한 요인입니다. 제가 요구에 따라 EC2를 연결하지 않을 것입니다.
- VPC 설정: Read replica를 활성화하고 데이터베이스를 标识할 수 있는 태그를 사용합니다.
- DB 인가 정보와 모니터링을 선택하고, 결국 이를 통해 한 달 내 데이터베이스 비용 견적을 얻을 수 있습니다.
Code Example
SocialBuzz를 위한 Aurora クラスタ 설정을 진행하ます.
Aurora Cluster 설정
import boto3
# Amazon RDS를 사용하여 세션 초기화
client = boto3.client('rds', region_name='us-west-2')오로라 DB 클러스터 생성
response = client.create_db_cluster(
DBClusterIdentifier='socialbuzz-cluster',
Engine='aurora-mysql',
MasterUsername='admin',
MasterUserPassword='password',
BackupRetentionPeriod=7,
VpcSecurityGroupIds=['sg-0a1b2c3d4e5f6g7h'],
DBSubnetGroupName='default'
)
print(response)
오로라 인스턴스 생성
response = client.create_db_instance(
DBInstanceIdentifier='socialbuzz-instance',
DBClusterIdentifier='socialbuzz-cluster',
DBInstanceClass='db.r5.large',
Engine='aurora-mysql',
PubliclyAccessible=True
)
print(response)
샘플 데이터셋
사용자, 게시물, 댓글을 나타내는 간단한 데이터셋을 생성합니다:
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE posts (
post_id INT PRIMARY KEY,
user_id INT,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE comments (
comment_id INT PRIMARY KEY,
post_id INT,
user_id INT,
comment TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 샘플 데이터 삽입
INSERT INTO users (user_id, username, email) VALUES
(1, 'john_doe', '[email protected]'),
(2, 'jane_doe', '[email protected]');
INSERT INTO posts (post_id, user_id, content) VALUES
(1, 1, 'Hello World!'),
(2, 2, 'This is my first post.');
INSERT INTO comments (comment_id, post_id, user_id, comment) VALUES
(1, 1, 2, 'Nice post!'),
(2, 2, 1, 'Welcome to the platform!');# 읽기/쓰기 연산을 위한 애플리케이션 로직
import pymysql
# 데이터베이스 연결
connection = pymysql.connect(
host='socialbuzz-cluster.cluster-xyz.us-west-2.rds.amazonaws.com',
user='admin',
password='password',
database='socialbuzz'
)
# 쓰기 작업
def create_post(user_id, content):
with connection.cursor() as cursor:
sql = "INSERT INTO posts (user_id, content) VALUES (%s, %s)"
cursor.execute(sql, (user_id, content))
connection.commit()
# 읽기 작업
def get_posts():
with connection.cursor() as cursor:
sql = "SELECT * FROM posts"
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# 사용 예
create_post(1, 'Exploring AWS Aurora!')
get_posts()결론
AWS Aurora는 견고합니다, 확장 가능하고 신뢰할 수 있는 데이터베이스 관리 솔루션을 제공합니다. SocialBuzz의 사례 연구는 기업이 Aurora의 최첨단 기능을 활용하여 폭주하는 트래픽을 관리하고 데이터 무결성을 보장하며 효율성을 향상하는 방법을 보여줍니다. 권장 방법을 준수하고 적절한 인프라를 구축함으로써 기업은 개발과 창의성을 촉진하기 위해 AWS Aurora의 기능을 충분히 활용할 수 있습니다.
Source:
https://dzone.com/articles/aws-aurora-for-scalable-and-reliable-databases